svm支持向量機 學習筆記
1簡介
支持向量機(Support Vector Machine)是Cortes和Vapnik於1995年首先提出的,它在解決小樣本、 非線性 及 高維模式識別 中表現出許多特有的優點,並可以推廣應用到函數擬合等其餘機器學習問題中。算法
支持向量機方法是創建在統計學習理論的VC維理論和結構風險最小原理基礎上的,根據有限的樣本信息在模型的複雜性(即對特定訓練樣本的學習精度,Accuracy)和學習能力(即無錯誤地識別任意樣本的能力)之間尋求最佳折衷,以期得到最好的推廣能力(或稱泛化能力)。機器學習
概念
- 支持向量:就是支持或支撐平面上把兩類類別劃分開來的超平面的向量點
- 機:方法
- 監督學習:計算機學習已經建立好的分類系統,SVM最好的監督學習方法(深度學習)
- 非監督學習:沒有能夠學習的樣本
2介紹
用二維的例子解釋SVM,能夠拓展到n維函數
如何區分線性可分和線性不可分
- 尋找超平面(1,2,3,....n維)
- 超平面全部的變量的偏導數爲常數就說這個樣本線性可分
2.1線性可分
二維狀況下:就是能夠用一條或幾條直線把屬於不一樣類別的樣本點分開
N維狀況下:就是能夠用一個超平面(線,面,超平面,n-1維)來分隔兩類點學習
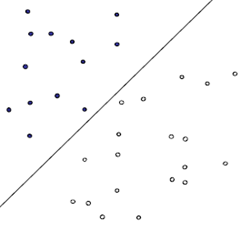
如何找到最優的那條直線?是須要解決的問題優化

方法以下:spa
從直觀上來講,就是分割的間隙越大越好,把兩個類別的點分得越開越好。就像咱們平時判斷一我的是男仍是女,就是很難出現分錯的狀況,這就是男、女兩個類別之間的間隙很是的大致使的,讓咱們能夠更準確的進行分類。
在SVM中,稱爲Maximum Marginal,是SVM的一個理論基礎之一
上圖被紅色和藍色的線圈出來的點就是所謂的支持向量!.net
上圖就是線性方程,能夠得出M:
另外支持向量位於wx + b = 1與wx + b = -1的直線上,咱們在前面乘上一個該點所屬的類別y(還記得嗎?y不是+1就是-1),就能夠獲得支持向量的表達式爲:y(wx + b) = 1,這樣就能夠更簡單的將支持向量表示出來了。code
至此二維已經能求出w和b的值,咱們擴展到n維空間裏:
咱們要優化求解的表達式:blog
||w||的意思是w的二範數(空間兩個向量的直線距離),這兩個式子是等價的,之因此要寫成這樣是爲了後邊的求導
這個式子有還有一些限制條件,完整的寫下來,應該是這樣的:ip
這個實際上是一個帶約束的二次規劃(quadratic programming, QP)問題,是一個凸問題,凸問題就是指的不會有局部最優解,能夠想象一個漏斗,無論咱們開始的時候將一個小球放在漏斗的什麼位置,這個小球最終必定能夠掉出漏斗,也就是獲得全局最優解。s.t.後面的限制條件能夠看作是一個凸多面體,咱們要作的就是在這個凸多面體中找到最優解。
轉化爲對偶問題,優化求解
這個優化問題能夠用拉格朗日乘子法去解,使用了KKT條件的理論,這裏直接做出這個式子的拉格朗日目標函數:
首先讓L關於w,b最小化,分別令L關於w,b的偏導數爲0,獲得關於原問題的一個表達式:
將兩式帶回L(w,b,a)獲得對偶問題的表達式
新問題加上其限制條件是(對偶問題):
這個就是咱們須要最終優化的式子。至此,獲得了線性可分問題的優化式子。
得出這個式子徹底是爲了之後的優化計算而來,有不少方法,如SMO(序列最小最優化)等
2.2線性不可分
方法一:用曲線分隔開(核函數)
讓空間從本來的線性空間變成一個更高維的空間,在這個高維的線性空間下,再用一個超平面進行劃分。
當維度增長到無限維的時候,必定可讓任意的兩個物體可分了
由於兩個不一樣的物體確定有不一樣的特徵
下圖是一個典型的線性不可分的狀況
事實上,上圖所述的這個數據集,是用兩個半徑不一樣的圓圈加上了少許的噪音生成獲得的,因此,一個理想的分界應該是一個「圓圈」而不是一條線(超平面)。若是用 X1 和 X2 來表示這個二維平面的兩個座標的話,咱們知道一條二次曲線(圓圈是二次曲線的一種特殊狀況)的方程能夠寫做這樣的形式:
注意上面的形式,若是咱們構造另一個五維的空間,其中五個座標的值分別爲 $Z_1=X_1, Z_2=X_1^2, Z_3=X_2, Z_4=X_2^2, Z_5=X_1X_2$,那麼顯然,上面的方程在新的座標系下能夠寫做:
這個列子爲了直觀比較特殊,不用投射到五維空間,用三維空間便可獲得:
$Z_1=X^2_1, Z_2=X_2^2, Z_3=X_2 $
那麼在新的空間中原來的數據將變成線性可分的,從而使用以前咱們推導的線性分類算法就能夠進行處理了。這正是 Kernel 方法處理非線性問題的基本思想。
核函數
用線性可分狀況下優化的公式:
咱們能夠將紅色這個部分進行改造,令:
這個式子所作的事情就是將線性的空間映射到高維的空間,k(x, xj)有不少種,下面是比較典型的兩種:
上面這個核稱爲多項式核,下面這個核稱爲高斯核,高斯核甚至是將原始空間映射爲無窮維空間,另外核函數有一些比較好的性質,好比說不會比線性條件下增長多少額外的計算量,等等,這裏也再也不深刻。通常對於一個問題,不一樣的核函數可能會帶來不一樣的結果,通常是須要嘗試來獲得的。
經常使用核函數
上面這個核稱爲多項式核,下面這個核稱爲高斯核,高斯核甚至是將原始空間映射爲無窮維空間,另外核函數有一些比較好的性質,好比說不會比線性條件下增長多少額外的計算量,等等,這裏也再也不深刻。通常對於一個問題,不一樣的核函數可能會帶來不一樣的結果,通常是須要嘗試來獲得的。
還有一個線性核,這實際上就是原始空間中的內積。這個核存在的主要目的是使得「映射後空間中的問題」和「映射前空間中的問題」二者在形式上統一塊兒來了(意思是說,我們有的時候,寫代碼,或寫公式的時候,只要寫個模板或通用表達式,而後再代入不一樣的核,即可以了,於此,便在形式上統一了起來,不用再分別寫一個線性的,和一個非線性的)。
核函數本質
上面說了這麼一大堆,讀者可能仍是沒明白核函數究竟是個什麼東西?我再簡要歸納下,即如下三點:
- 實際中,咱們會常常遇到線性不可分的樣例,此時,咱們的經常使用作法是把樣例特徵映射到高維空間中去(如上文2.2節最開始的那幅圖所示,映射到高維空間後,相關特徵便被分開了,也就達到了分類的目的);
2.但進一步,若是凡是遇到線性不可分的樣例,一概映射到高維空間,那麼這個維度大小是會高到可怕的(如上文中19維乃至無窮維的例子)。那咋辦呢?
此時,核函數就隆重登場了,核函數的價值在於它雖然也是講特徵進行從低維到高維的轉換,但核函數絕就絕在它事先在低維上進行計算,而將實質上的分類效果表如今了高維上,也就如上文所說的避免了直接在高維空間中的複雜計算。
方法二:用直線分隔開(不用去保證可分性)(軟間隔)
- 欠擬合
- 過擬合
數據中的一些特殊值是噪聲
條件限制公式:
- C是一個由用戶去指定的係數,表示對分錯的點加入多少的懲罰,當C很大的時候,分錯的點就會更少,可是過擬合的狀況可能會比較嚴重,當C很小的時候,分錯的點可能會不少,不過可能由此獲得的模型也會不太正確,因此如何選擇C是有不少學問的,不過在大部分狀況下就是經過經驗嘗試獲得的。
- 加入懲罰函數:咱們能夠爲分錯的點加上一點懲罰,對一個分錯的點的懲罰函數就是這個點到其正確位置的距離
接下來就是一樣的,求解一個拉格朗日對偶問題,獲得一個原問題的對偶問題的表達式:
藍色的部分是與線性可分的對偶問題表達式的不一樣之處。在線性不可分狀況下獲得的對偶問題,不一樣的地方就是α的範圍從[0, +∞),變爲了[0, C],增長的懲罰ε沒有爲對偶問題增長什麼複雜度。
3結構風險
模型與真實值之間的偏差叫作風險
使用分類器在樣本數據上的分類的結果與真實結果之間的差值來表示。這個差值叫作經驗風險,在驍樣本上能夠保證沒有偏差,可是真實值之間不可能保證
之前的機器學習方法都把經驗風險最小化做爲努力的目標,但後來發現不少分類函數可以在樣本集上輕易達到100%的正確率,在真實分類時卻一塌糊塗,即所謂的推廣能力差,或泛化能力差
泛化偏差界,由兩部分刻畫:
- 經驗風險,表明了分類器在給定樣本上的偏差
- 置信風險,表明了咱們在多大程度上能夠信任分類器在未知文本上分類的結果
- 樣本數量,顯然給定的樣本數量越大,咱們的學習結果越有可能正確,此時置信風險越小
- 分類函數的VC維,顯然VC維越大,推廣能力越差,置信風險會變大
泛化偏差界的公式爲:
R(w)≤Remp(w)+Ф(n/h)
公式中R(w)就是真實風險,Remp(w)就是經驗風險,Ф(n/h)就是置信風險。
統計學習的目標從經驗風險最小化變爲了尋求經驗風險與置信風險的和最小,即結構風險最小。
SVM正是這樣一種努力最小化結構風險的算法。
VC維
定義:對一個指標函數集,若是存在H個樣本可以被函數集中的函數按全部可能的2的H次方種形式分開,則稱函數集可以把H個樣本打散;函數集的VC維就是它能打散的最大樣本數目H。
二維:VC維爲3
VC維反映了函數集的學習能力,VC維越大則學習機器越複雜(容量越大),遺憾的是,目前尚沒有通用的關於任意函數集VC維計算的理論,只對一些特殊的函數集知道其VC維。例如在N維空間中線形分類器和線形實函數的VC維是N+1。(經過2維的推導)
小樣本 : 並非說樣本的絕對數量少(實際上,對任何算法來講,更多的樣本幾乎老是能帶來更好的效果),而是說與問題的複雜度比起來,SVM算法要求的樣本數是相對比較少的。
是指SVM擅長應付樣本數據線性不可分的狀況,主要經過鬆弛變量(也有人叫懲罰變量)和核函數技術來實現,這一部分是SVM的精髓,之後會詳細討論。多說一句,關於文本分類這個問題到底是不是線性可分的,尚沒有定論,所以不能簡單的認爲它是線性可分的而做簡化處理,在水落石出以前,只好先當它是線性不可分的(反正線性可分也不過是線性不可分的一種特例而已,咱們向來不怕方法過於通用)。
- 高維模式識別是指樣本維數很高,例如文本的向量表示,若是沒有通過另外一系列文章(《文本分類入門》)中提到過的降維處理,出現幾萬維的狀況很正常,其餘算法基本就沒有能力應付了,SVM卻能夠,主要是由於SVM 產生的分類器很簡潔,用到的樣本信息不多(僅僅用到那些稱之爲「支持向量」的樣本,此爲後話),使得即便樣本維數很高,也不會給存儲和計算帶來大麻煩
- VC維是對函數類的一種度量,能夠簡單的理解爲問題的複雜程度,VC維越高,一個問題就越複雜。
- 1. 支持向量機 SVM-學習筆記
- 2. 支持向量機學習筆記-SVM
- 3. 學習筆記-支持向量機(SVM)
- 4. 機器學習:支持向量機(SVM)
- 5. 機器學習——支持向量機(SVM)
- 6. [機器學習] 支持向量機(SVM)
- 7. 【機器學習】支持向量機(SVM)
- 8. 機器學習:支持向量機(svm)
- 9. 機器學習(支持向量機-SVM)
- 10. 機器學習————SVM支持向量機
- 更多相關文章...
- • R 繪圖 - 中文支持 - R 語言教程
- • 您已經學習了 XML Schema,下一步學習什麼呢? - XML Schema 教程
- • Tomcat學習筆記(史上最全tomcat學習筆記)
- • 適用於PHP初學者的學習線路和建議
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 支持向量機 SVM-學習筆記
- 2. 支持向量機學習筆記-SVM
- 3. 學習筆記-支持向量機(SVM)
- 4. 機器學習:支持向量機(SVM)
- 5. 機器學習——支持向量機(SVM)
- 6. [機器學習] 支持向量機(SVM)
- 7. 【機器學習】支持向量機(SVM)
- 8. 機器學習:支持向量機(svm)
- 9. 機器學習(支持向量機-SVM)
- 10. 機器學習————SVM支持向量機