Java8 Stream源碼分析
Stream
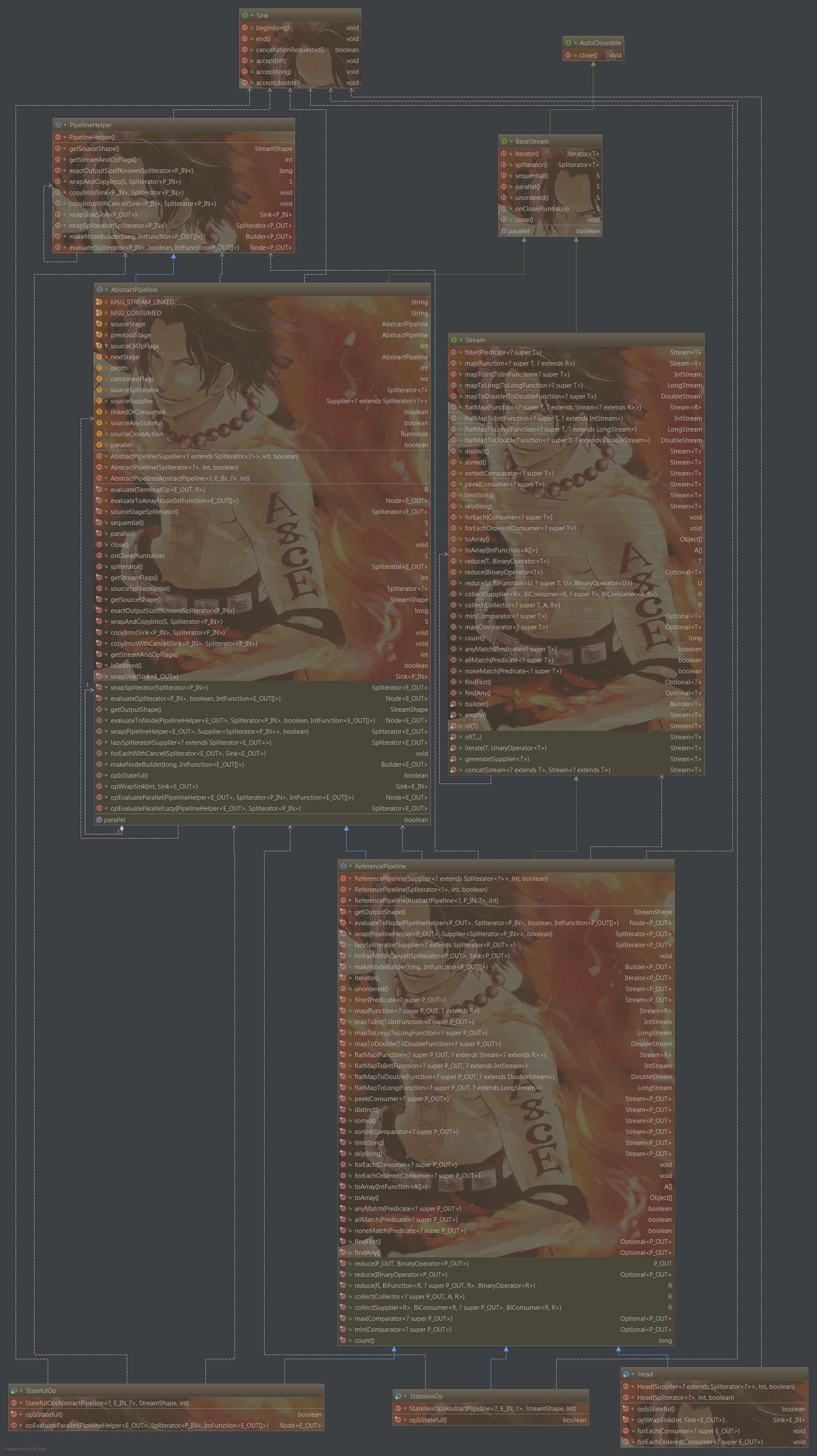
Stream是在Java SE 8 API添加的用於加強集合的操做接口,可讓你以一種聲明的方式處理集合數據。將要處理的集合看做一種流的建立者,將集合內部的元素轉換爲流而且在管道中傳輸, 而且能夠在管道的節點上進行處理, 好比篩選,排序,聚合等。元素流在管道中通過中間操做(intermediate operation)的處理,最後由最終操做(terminal operation)獲得前面處理的結果。Stream的繼承關係圖以下,且容我慢慢抽絲剝繭細細道來。java
過濾,轉換,聚合,歸約
Stream.of("one", "two", "three", "four") .filter(e -> e.length() > 3) .peek(e -> System.out.println("Filtered value: " + e)) .map(String::toUpperCase) .peek(e -> System.out.println("Mapped value: " + e)) .collect(Collectors.toList());
在沒有Stream以前,咱們對集合數據的處理到可能是外部遍歷,而後作數據的聚合用算,排序,merge等等。這屬於OO思想,在引入Java SE 8引入FP以後,FP的操做能夠提升Java程序員的生產力,,基於類型推斷的lambda表達式能夠 讓程序員寫出高效率、乾淨、簡潔的代碼。能夠避免冗餘的代碼。根據給定的集合操做經過stream()方法建立初始流,配合map(),flatMap(),filter()對集合數據進行過濾,轉換。api調用我這裏就很少說了。直接從源碼入手,看上圖最核心的就是類爲AbstractPipeline,ReferencePipeline和Sink接口.AbstractPipeline抽象類是整個Stream中流水線的高度抽象了源頭sourceStage,上游previousStage,下游nextStage,定義evaluate結束方法,而ReferencePipeline則是抽象了過濾,轉換,聚合,歸約等功能,每個功能的添加實際上能夠理解爲捲心菜,菜心就是源頭,每一次加入一個功能就至關於從新長出一片葉子包住了菜心,最後一個功能集成完畢以後整顆捲心菜就長大了。而Sink接口呢負責把整個流水線串起來,而後在執行聚合,歸約時候調AbstractPipeline抽象類的evaluate結束方法,根據是不是並行執行,調用不一樣的結束邏輯,若是不是並行方法則執行terminalOp.evaluateSequential不然就執行terminalOp.evaluateParallel,非並行執行模式下則是執行的是AbstractPipeline抽象類的wrapAndCopyInto方法去調用copyInto,調用前會先執行一下wrapSink,用於剝開這個咱們在流水線上產生的捲心菜。從下游向上游去遍歷AbstractPipeline,而後包裝到Sink,而後在copyInto方法內部迭代執行對應的方法。最後完成調用,node
並行執行其實是構建一個ForkJoinTask並執行invoke去提交到ForkJoinPool線程池。程序員
BaseStream
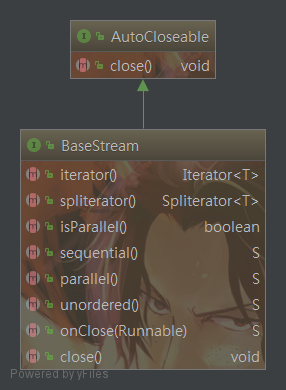
流的基本接口,該接口制定流能夠支持無序,順序,並行的,Stream實現了BaseStream接口。api
-
Iterator iterator();數組
外部迭代器app
-
Spliterator spliterator();ide
用於建立一個內部迭代器函數
-
isParallel性能
用於判斷該stream是不是並行的ui
-
S sequential();
標識該stream建立是順序執行的
-
S parallel();
標識該stream建立是並行的,須要使用
ForkJoinPool -
S unordered();
標識該stream建立是無序的
-
S onClose(Runnable closeHandler);
當stream關閉的時候執行一個方法回調去關閉流。
PipelineHelper
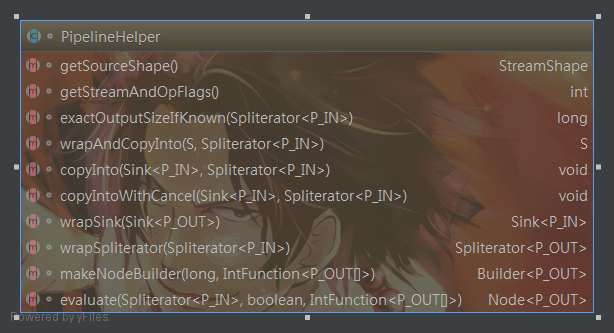
該抽象類主要定義了操做管道的核心方法,而且能收集到流管道內的全部信息。如經過
TerminalOp#evaluateParallel用於執行並行流操做,經過TerminalOp#evaluateSequential執行順序流的操做。
-
abstract StreamShape getSourceShape();
用於定義該流的中元素的原型,返回一個枚舉值,用於切片操做
limit或者skip枚舉值取值範圍 {REFERENCE:引用類型元素,INT_VALUE:int類型元素,LONG_VALUE:long類型元素,DOUBLE_VALUE:double類型元素}
-
abstract int getStreamAndOpFlags();
用於獲取流的中元素的原型和全部操做的組合,
Stream中全部的定義流類型和操做的指令都包含在`StreamOpFlag``枚舉類中。先看下補碼 掩碼的運算位掩碼的經常使用CRUD操做 a&~b: 清除標誌位b; a|b : 添加標誌位b; a&b : 取出標誌位b; a^b : 取出a與b的不一樣部分; 下面是對應流的標誌位對應的表。 /* * Characteristics belong to certain types, see the Type enum. Bit masks for * the types are constructed as per the following table: * * DISTINCT SORTED ORDERED SIZED SHORT_CIRCUIT * SPLITERATOR 01 01 01 01 00 * STREAM 01 01 01 01 00 * OP 11 11 11 10 01 * TERMINAL_OP 00 00 10 00 01 * UPSTREAM_TERMINAL_OP 00 00 10 00 00 * * 01 = set/inject SET_BITS=0b01設置指令 * 10 = clear CLEAR_BITS=0b10清除指令 * 11 = preserve PRESERVE_BITS=0b11保存指令 */ 構造函數 private StreamOpFlag(int position, MaskBuilder maskBuilder) { this.maskTable = maskBuilder.build(); // Two bits per flag position *= 2; this.bitPosition = position; this.set = SET_BITS << position; this.clear = CLEAR_BITS << position; this.preserve = PRESERVE_BITS << position; }
-
StreamOpFlag.DISTINCT
DISTINCT(0,set(Type.SPLITERATOR).set(Type.STREAM).setAndClear(Type.OP))
output:StreamOpFlag.DISTINCT: StreamOpFlag(maskTable={SPLITERATOR=1, STREAM=1, OP=3, TERMINAL_OP=0, UPSTREAM_TERMINAL_OP=0}, bitPosition=0, set=1, clear=2, preserve=3)
ok,咱們知道了StreamOpFlag.DISTINCT的[設置]偏移位是1,16進製表示:0x00000001。當getStreamAndOpFlags返回的包含
IS_DISTINCT也就是0x00000001就表示對於流中遇到的X,Y元素{@code!X.equals(Y)}。對應的是包含Spliterator.DISTINCT,標識該stream已是distinct的了。-
StreamOpFlag.SIZED
SIZED(3, set(Type.SPLITERATOR).set(Type.STREAM).clear(Type.OP))
output:StreamOpFlag.SIZED: StreamOpFlag(maskTable={SPLITERATOR=1, STREAM=1, OP=2, TERMINAL_OP=0, UPSTREAM_TERMINAL_OP=0}, bitPosition=6, set=64, clear=128, preserve=192)【0x00000040】->[Spliterator.SIZED]
表示遍歷或拆分前從
estimateSize()返回的值的特徵值表示一個有限大小,在沒有修改源結構的狀況下,該值表示完整遍歷流中元素數量的精確值,若是stream沒有SIZED|SUBSIZED屬性,則能夠將estimateSize返回爲Long.MAX_VALUE.這說明這個stream的estimateSize計算很複雜或自己就是一個infinite的steam流。這樣設置後,性能上會差一些,可是,不會對sorted方法產生影響。若是要對流進行並行操做,實現自定義的Spliterator時,則須要重寫trySplit()方法和long estimateSize()方法。經過拆分Spliterator加入fork/join線程池中,而後實現並行的處理。-
StreamOpFlag.SORTED
SORTED(1, set(Type.SPLITERATOR).set(Type.STREAM).setAndClear(Type.OP))
output:StreamOpFlag.SORTED: StreamOpFlag(maskTable={SPLITERATOR=1, STREAM=1, OP=3, TERMINAL_OP=0, UPSTREAM_TERMINAL_OP=0}, bitPosition=2, set=4, clear=8, preserve=12) 【0x00000004】->[Spliterator.SORTED]
表示流裏順序遵循定義的排序順序。若是包含該屬性,方法
getComparator()返回關聯的比較器,或者返回null,若是設置了該屬性而且,方法getComparator()返回null,這代表改流已經排好序了,若是方法getComparator()返回不爲null,那麼在fromCharacteristics方法處,該SORTED屬性會被取消掉。若是流裏面的全部元素都是實現了Comparable,那排序順序就是按它們的天然順序,在sorted(x->{...})方法執行能夠傳一個lambda進去。若是有值傳輸進去,那麼都回按照該lambda對該流進行排序-
StreamOpFlag.ORDERED
ORDERED(2, set(Type.SPLITERATOR).set(Type.STREAM).setAndClear(Type.OP).clear(Type.TERMINAL_OP) .clear(Type.UPSTREAM_TERMINAL_OP))
output:StreamOpFlag.ORDERED: StreamOpFlag(maskTable={SPLITERATOR=1, STREAM=1, OP=3, TERMINAL_OP=2, UPSTREAM_TERMINAL_OP=2}, bitPosition=4, set=16, clear=32, preserve=48)【0x00000010】->[Spliterator.ORDERED]
表示該流中的元素已經定義了順序。包含了ORDERED屬性,是拆分器保證
trySplit拆分元素的強制前置條件,tryAdvance方法也會按定義了的順序逐個元素進行拆分,forEachRemaining方法也按定義了的順序執行內部迭代操做。通常集合的順序是升序。可是對於基於哈希的集合,例如HashSet,不保證順序。因此應該在不進行交換場景的並行計算中強制保證排序約束。-
StreamOpFlag.SHORT_CIRCUIT
SHORT_CIRCUIT(12, set(Type.OP).set(Type.TERMINAL_OP))
output:StreamOpFlag.SHORT_CIRCUIT: StreamOpFlag(maskTable={SPLITERATOR=0, STREAM=0, OP=1, TERMINAL_OP=1, UPSTREAM_TERMINAL_OP=0}, bitPosition=24, set=16777216, clear=33554432, preserve=50331648)【0x01000000】->[表示操做可能使流短路]
表示操做可能使流短路
-
-
abstract<P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator);
將此時間的管道內的元素應用到提供的
Spliterator,並將結果發送到提供的接收器sink裏
- abstract<P_IN, S extends Sink<P_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator);
用於輸出返回值的大小。
- abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
用於將從
Spliterator得到的元素推入提供的接收器中Sink。若是已知流管道中有短路階段(包含StreamOpflag#SHORT_CURRENT),則在每一個元素以後執行一下Sink#cancellationRequested(),若是返回請求true,則執行終止。這個方法被實現以後須要遵照Sink的協議即:Sink#begin->Sink#accept->Sink->end
- abstract <P_IN> void copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
用於將從
Spliterator得到的元素推入提供的接收器中Sink。在每一個元素以後執行一下Sink#cancellationRequested(),若是返回請求true,則執行終止。這個方法被實現以後須要遵照Sink的協議即:Sink#begin->Sink#accept->Sink->end
- abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
該方法主要用於包裝sink,從下游向上游去遍歷
AbstractPipeline,而後包裝到一個Sink內,用於而後在copyInto方法內部迭代執行對應的方法。
- abstract Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown,IntFunction<P_OUT[]> generator);
用於構造一個節點Builder,轉換爲數組去處理數組類型和PipelineHelper定義的輸出類型同樣。
- abstract<P_IN> Node<P_OUT> evaluate(Spliterator<P_IN> spliterator,boolean flatten,IntFunction<P_OUT[]> generator);
該方法將源拆分器應用到管道內的全部元素。針對數組處理。若是管道沒有中間(
filter,map)操做,而且源由一個節點支持(源頭),則該節點將被返回(內部遍歷而後返回)。這減小了由有狀態操做和返回數組的終端操做組成的管道的複製.例如:stream.sorted().toArray();該方法對應到AbstractPipeline內部,代碼以下:
@Override @SuppressWarnings("unchecked") final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator, boolean flatten, IntFunction<E_OUT[]> generator) { if (isParallel()) { // @@@ Optimize if op of this pipeline stage is a stateful op return evaluateToNode(this, spliterator, flatten, generator); } else { Node.Builder<E_OUT> nb = makeNodeBuilder( exactOutputSizeIfKnown(spliterator), generator); return wrapAndCopyInto(nb, spliterator).build(); } }
AbstractPipeline
「管道」類的抽象基類,是流接口及其原始專門化的核心實現。用來表示流管道的初始部分,封裝流源和零個或多箇中間操做。對於順序流和沒有狀態中間操做的並行流、並行流,管道中數據的處理是在一次「阻塞」全部操做的過程當中完成的也就是最後纔去處理。對於具備狀態操做的並行流,執行被分紅多個段,其中每一個狀態操做標記一個段的結束,每一個段被單獨評估,結果被用做下一個段的輸入。上述全部狀況,都是達到終端操做纔開始處理源數據。
- AbstractPipeline(Supplier> source,
int sourceFlags, boolean parallel)
建立源Source stage 第一個參數指定一個Supplier接口(工廠模式,只能生成Spliterator<?>的對象,根據傳入的lambda實現,
<? extends Spliterator<?泛型的PECS原則瞭解一下。)
- AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel)
建立源Source stage 第一個參數制定這個拆分器,和上面的構造方式同樣,直接分析一下這個方法:
AbstractPipeline(Spliterator<?> source, int sourceFlags, boolean parallel) { this.previousStage = null; this.sourceSpliterator = source; this.sourceStage = this; this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK; // The following is an optimization of: // StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE); this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE; this.depth = 0; this.parallel = parallel; }
建立Stream 源階段的時候
previousStage爲null,this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;用於設置當前階段的標識位。this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;添加源階段的對流的操做標識,這個combinedFlags是流在整個管道內部全部操做的合集,在最後的規約操做的時候去解析出來。
- AbstractPipeline(AbstractPipeline previousStage, int opFlags)
根據上游建立下游
Pipeline。
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) { if (previousStage.linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED); previousStage.linkedOrConsumed = true; previousStage.nextStage = this; this.previousStage = previousStage; this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK; this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags); this.sourceStage = previousStage.sourceStage; if (opIsStateful()) sourceStage.sourceAnyStateful = true; this.depth = previousStage.depth + 1; }
this.sourceStage = previousStage.sourceStage;,用於上游和下游關聯,this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);將上游的操做標識位添加到本階段的操做標識位中。depth記錄整個管道的中間操做數。
- final R evaluate(TerminalOp<E_OUT, R> terminalOp)
進行終端匯聚計算。執行最終的計算,獲得結果,根據是不是並行執行,調用不一樣的結束邏輯,若是不是並行方法則執行
terminalOp.evaluateSequential不然就執行terminalOp.evaluateParallel。
- final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator)
處理流轉換數組。
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator) { if (linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED); linkedOrConsumed = true; if (isParallel() && previousStage != null && opIsStateful()) { depth = 0; return opEvaluateParallel(previousStage, previousStage.sourceSpliterator(0), generator); } else { return evaluate(sourceSpliterator(0), true, generator); } }
轉換數組的時候,若是是並行流而且不是源階段,並且調用過sorted||limit||skip||distinct這些有狀態的操做以後,這裏是個模版方法調用。其實是經過調用DistinctOps||SortedOps||SliceOps這些實現的opEvaluateParallel方法,提交到ForkJoin線程池來轉換數組。串行執行的時候直接執行evaluate(sourceSpliterator(0), true, generator);
- evaluate(sourceSpliterator(0), true, generator);
具體的執行方法,用於吧管道內部的輸出結果放到Node中。
@Override @SuppressWarnings("unchecked") final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator, boolean flatten, IntFunction<E_OUT[]> generator) { if (isParallel()) { // @@@ Optimize if op of this pipeline stage is a stateful op return evaluateToNode(this, spliterator, flatten, generator); } else { Node.Builder<E_OUT> nb = makeNodeBuilder( exactOutputSizeIfKnown(spliterator), generator); return wrapAndCopyInto(nb, spliterator).build(); } } @Override final <P_IN> Node<P_OUT> evaluateToNode(PipelineHelper<P_OUT> helper, Spliterator<P_IN> spliterator, boolean flattenTree, IntFunction<P_OUT[]> generator) { return Nodes.collect(helper, spliterator, flattenTree, generator); } // Nodes.collect方法 public static <P_IN, P_OUT> Node<P_OUT> collect(PipelineHelper<P_OUT> helper, Spliterator<P_IN> spliterator, boolean flattenTree, IntFunction<P_OUT[]> generator) { long size = helper.exactOutputSizeIfKnown(spliterator); if (size >= 0 && spliterator.hasCharacteristics(Spliterator.SUBSIZED)) { if (size >= MAX_ARRAY_SIZE) throw new IllegalArgumentException(BAD_SIZE); P_OUT[] array = generator.apply((int) size); new SizedCollectorTask.OfRef<>(spliterator, helper, array).invoke(); return node(array); } else { Node<P_OUT> node = new CollectorTask.OfRef<>(helper, generator, spliterator).invoke(); return flattenTree ? flatten(node, generator) : node; } }
若是是源是並行流的狀況,以ReferencePipeline引用管道來看主要執行的是 return Nodes.collect(helper, spliterator, flattenTree, generator);,該collect方法內部根據切割器有無Spliterator.SUBSIZED肯定了生成的Node的長度,主要工做是建立一個Task提交到線程池。而後調用invoke拿到結果。示例代碼Arrays.asList("2","22","222").parallelStream().skip(2).toArray(); 整個流程以下:
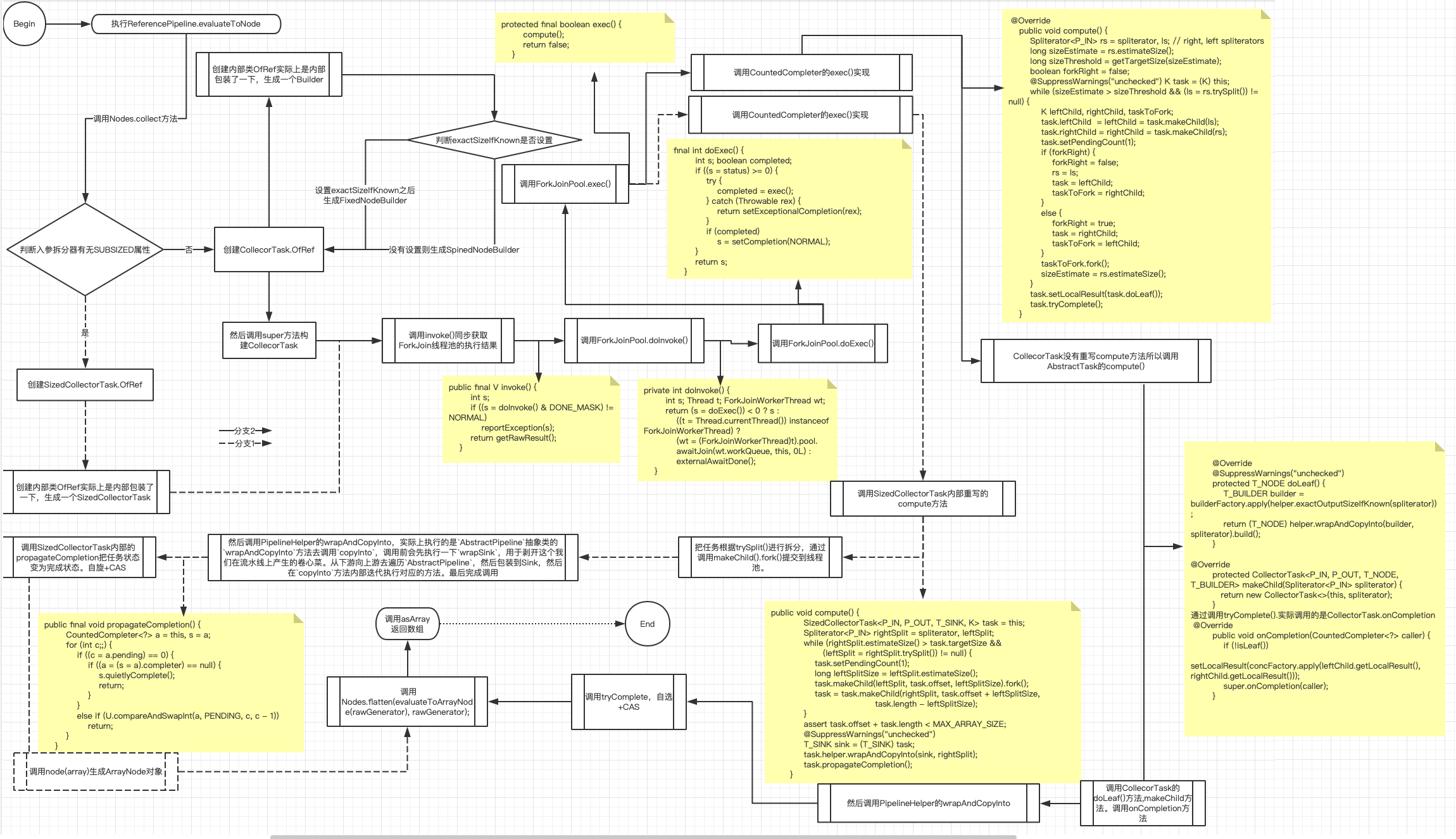
串行執行示例代碼Arrays.asList("2","22","222").stream().skip(2).toArray(); 整個流程以下:
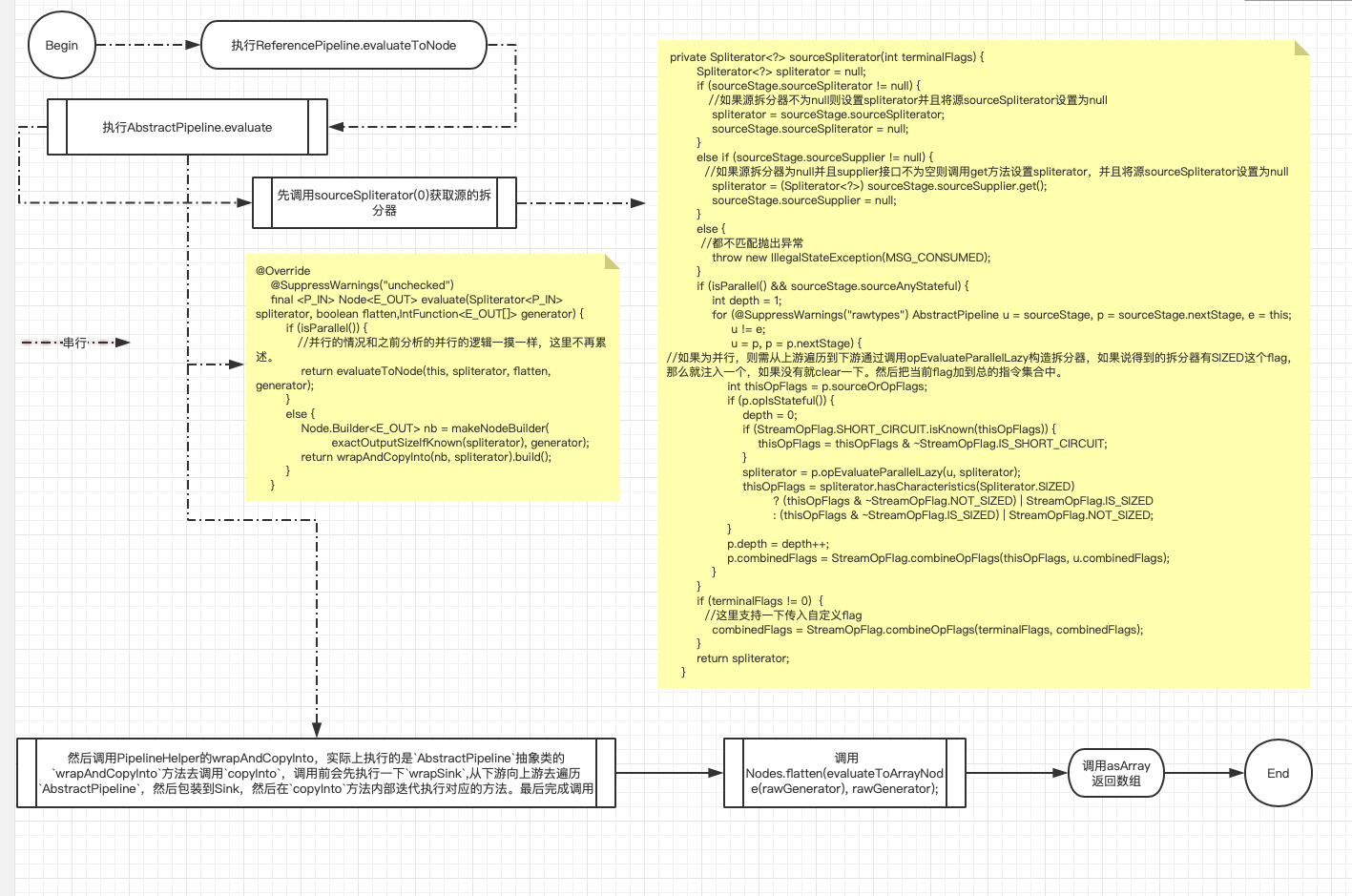
- final Spliterator<E_OUT> sourceStageSpliterator()
獲取Stream源頭設置的拆分器,若是設置有則返回而且把源拆分器置空,若是有Supplier則調用get方法返回拆分器而且把源拆分器置空。
- public final S sequential()
設置爲串行流 ,設置源的paraller屬性爲false。終態方法不容許重寫
- public final S sequential()
設置爲並行流 ,設置源的paraller屬性爲true。終態方法不容許重寫
- public void close()
關閉管道的方法,在關閉的時候會把管道使用標誌設置爲false,拆分器設置爲null,若是源的回調關閉Job存在不爲null時則invoker這個回調Job。
- public S onClose(Runnable closeHandler)
用於註冊關閉的回調job,在調用close的時候用於去執行這個回調job。
- public Spliterator<E_OUT> spliterator()
和
sourceStageSpliterator方法同樣的功能,只不過不是終態方法,能夠重寫用於自定義的拓展。
- public final boolean isParallel()
用於盤帶你當前管道是不是並行流。
- final int getStreamFlags()
獲取流的標誌和Stream的包含的全部操做。
- private Spliterator<?> sourceSpliterator(int terminalFlags) {
獲取源拆分器,和sourceStageSpliterator方法同樣的功能,針對是並行流時候,而且是建立Stream階段的話有中間狀態,會組合流標誌和操做構建拆分器。若是傳入的操做碼不等於0,那麼則添加到拆分器的操做碼中。
- final StreamShape getSourceShape()
輸出Stream源的類型。(引用 OR int OR Double OR Long)
- final <P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator)
獲取指望的size,若是拆分器若是有SIZE標誌,調用拆分器的getExactSizeIfKnown方法,不然返回-1。
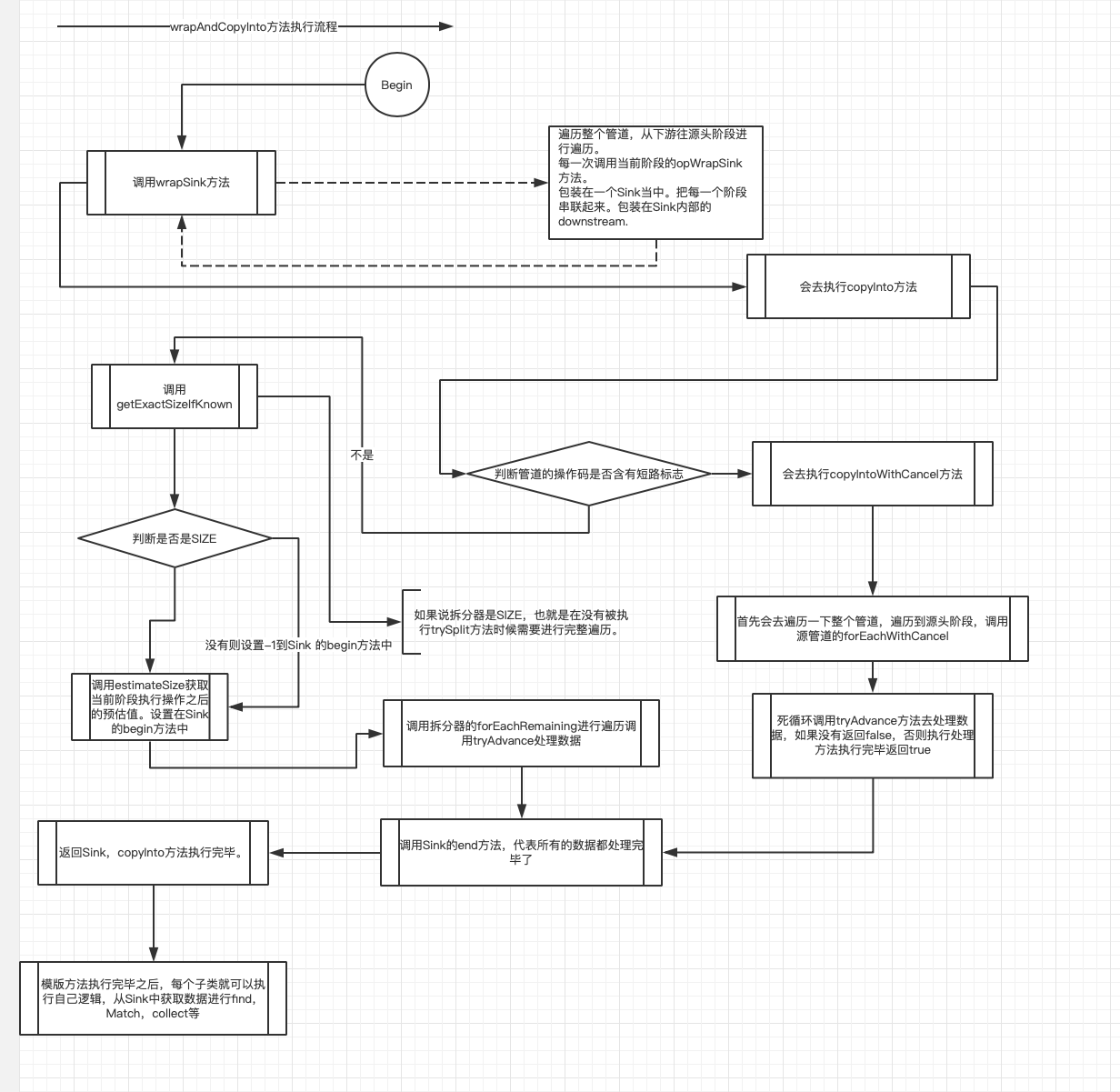
- final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator)
封裝整個管道的階段,包裝在Sink中。把每個階段串聯起來。包裝在Sink內部的downstream.
wrapAndCopyInto代碼執行流程以下:
看完三件事❤️
若是你以爲這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有大家的 『點贊和評論』,纔是我創造的動力。
-
關注公衆號 『 java爛豬皮 』,不按期分享原創知識。
-
同時能夠期待後續文章ing🚀

- 1. Stream源碼分析
- 2. Java Stream 源碼分析
- 3. Java8 ArrayList源碼分析
- 4. Java8 HashMap源碼分析
- 5. java8 Stream Pipelines 淺析
- 6. 2020了你還不會Java8新特性?(六)Stream源碼剖析
- 7. NodeJS stream 流 原理分析(附源碼)
- 8. Java8 Stream
- 9. java8-Stream
- 10. java8 Stream
- 更多相關文章...
- • ADO Stream 對象 - ADO 教程
- • Docker 資源彙總 - Docker教程
- • Java 8 Stream 教程
- • 互聯網組織的未來:剖析GitHub員工的任性之源
-
每一个你不满意的现在,都有一个你没有努力的曾经。