一、 MCMC抽樣
也許讀者會覺得詫異,爲什麼在一本介紹主題模型的書中卻看到了抽樣的知識?作者是不是偏題了?
答案當然是沒有。
相信你應該聽說過有一門課程叫做統計學,在這門課程中,抽樣佔據着舉足輕重的地位。當統計學的研究者們想要了解一個總體的某些參數時,他們的方案是,先去抽樣獲得樣本,通過樣本參數去估計總體參數。比如,想知道某財經高校學生們(總體)的平均月消費水平(總體參數),做法是:a.先抽樣一部分樣本,如從每個學院抽取20個人去調查他們的月消費水平,假設有20個學院,那麼就獲得了400個人(樣本)的月消費水平;b.算出這400個樣本的平均月消費水平(樣本參數);c.可以認爲該財經高校學生們的平均月消費水平估計爲這400個樣本的平均月消費水平。
本篇的MCMC抽樣與LDA主題模型的關係類比統計學裏的抽樣。在LDA主題模型的參數求解中,我們會使用MCMC抽樣去做。
MCMC四個字母的含義
第一個MC ,是Monte Carlo(蒙特卡洛)的首字母縮寫。本篇的蒙特卡洛指一種隨機模擬方法,以概率和統計理論方法爲基礎的一種計算方法,是使用隨機數(或更常見的僞隨機數)來解決很多計算問題的方法。採樣過程通常通過計算機來來實現。
蒙特卡洛此名由烏拉姆提出,事實上蒙特卡洛是摩納哥公國的一座城市,是著名的賭場,世人稱之爲「賭博之國」。衆人皆知,賭博總是和統計密切關聯的,所以這個命名風趣而貼切、不僅有意思而且有意義。
第二個MC:Markov Chain(馬爾科夫鏈)。這是MCMC抽樣中很重要的一個思想,將會在後篇細講。
(一)逆變換採樣
剛剛有提到,蒙特卡洛指一種隨機模擬方法,通常通過計算機來實現。然而,從本質上來說,計算機只能實現對均勻分佈的採樣。在此基礎上對更爲複雜的分佈進行採樣,應該怎麼做呢?這就需要用到逆變換採樣:
溫故兩個定義
對於隨機變量 X,如下定義的函數 F:
F(x)=PX≤x,−∞<x<∞
稱爲X 的
累積分佈函數。對於連續型隨機變量 X 的累積分佈函數 F(x),如果存在一個定義在實數軸上的非負函數 f(x),使得對於任意實數 x,有下式成立:
F(x)=∫f(t)dt
則稱 f(x) 爲 X 的
概率密度函數。顯然,當概率密度函數存在的時候,累積分佈函數是概率密度函數的積分。概率等於區間乘概率密度。
步驟
欲對密度函數
f(x)
採樣,並得到m 個觀察值,則重複下面的步驟 m 次:
1、從Uniform(0,1)中隨機生成一個值,用 u 表示。
2、計算反函數
F(−1)(u)
的值 x,則x 就是從
f(x)
中得出的一個採樣點。
舉例:
想對一個複雜概率密度函數
f(x)
抽樣,其概率密度形式如下:
F(x)=⎧⎩⎨⎪⎪8x,if0≤x<0.2583−83x,if0.25≤x<1 0,otherwise
1、求
f(x)
的累計分佈函數
F(x)
:
F(x)=⎧⎩⎨⎪⎪⎪⎪⎪⎪0,ifx<04x2,if0≤x<0.2583x−43x2−13,if0.25≤x<1 1,ifx>1
2、求
F(x)
的反函數:
F(−1)(u)
F(x)=⎧⎩⎨u√2,if0≤u<0.251−3(1−u)√2,if0.25≤x<1
重複m次逆變換採樣以下步驟:從Uniform(0,1)中隨機生成一個值,用 u 表示。計算反函數
F(−1)(u)
的值 x,則x 就是從
f(x)
中得出的一個採樣點。最終將採樣點圖像(藍色)與實際密度函數(紅色)比較,得圖如下:
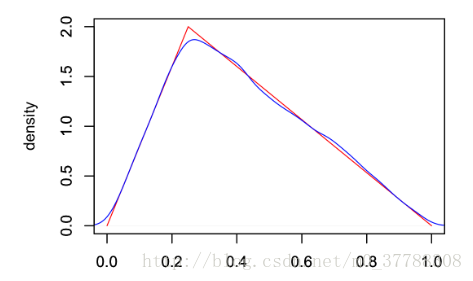 可以看到兩條線幾乎重合,這表明逆變換採樣可以很好的模擬出某些複雜分佈。 **存在問題:** 逆變換採樣有求解累積分佈函數和反函數這兩個過程,而有些分佈的概率分佈函數可能很難通過對概率密度p(x)的積分得到,再或者概率分佈函數的反函數也很不容易求。這個時候應該怎麼辦呢?此時提出了拒絕採樣的解決方案。
(二)拒絕採樣
欲對逆變換採樣不再適用的密度函數
p(x)
採樣,如果能找到另外一個概率密度爲
q(x)
的函數,它相對容易採樣。如採用逆變換採樣方法可以很容易對
q(x)
進行採樣,甚至
q(x)
就是計算機可以直接模擬的均勻分佈。此時我們可直接對
q(x)
採樣,然後按照一定的方法拒絕某些樣本,達到接近
p(x)
分佈的目的。
步驟
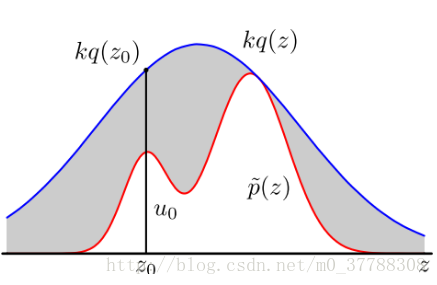 當我們將
q(x)
與一個常數 K 相乘之後,可以實現下圖所示之關係,即 K⋅q(x)將p(x)完全「罩住」:p(x) ≤Kq(x)。重複以下步驟抽樣: •x 軸方向:從q(x)分佈抽樣得到
Z0
。 •y 軸方向:從均勻分佈
(0,Kq(Z0))
中抽樣得到
u0
。 •如果剛好落到灰色區域,否則接受這次抽樣:
u0
>
p(Z0)
, 拒絕該樣本。 •重複以上過程。
舉例:利用拒絕採樣計算
π
值
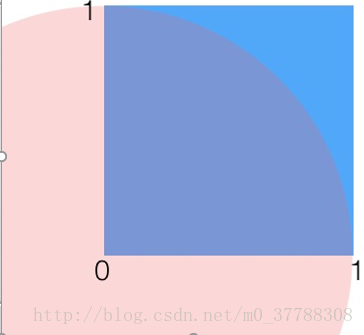 如圖所示,陰影區域有一個邊長爲1的正方形,正方形裏有一個半徑爲1的1/4圓。則有:S(1/4圓)= 1/4*π*R^2= 1/4π;S(正方形)=1。現在對這個正方形隨機取點,某點到原點的距離小於1,則說明它在1/4圓內。可以認爲,落在圓內的次數/取點總次數=1/4圓的面積/正方形的面積。即:
π=4∗s(正方形)∗落在圓內的次數取點總次數
隨着採樣點的增多,最後的結果π會越精準。 這裏也就是用到了拒絕採樣的思想。要計算
π
值,即尋求對圓這個複雜分佈抽樣,圓不好搞定,於是我們選擇了一個相對容易的正方形分佈,在對正方形隨機取點的時候,如果某點到原點的距離小於1,則說明它在1/4圓內,接受這個樣本,否則拒絕它。 而抽樣的時候; 基於以上思想我們可以利用計算機建模。
(三)馬爾科夫鏈
馬爾科夫鏈就是第二個MC:Markov Chain。定義爲:根據概率分佈,可以從一個狀態轉移到另一個狀態,但是狀態轉移之間服從馬氏性的一種分佈。
解釋一下定義中提到的兩個名詞:
馬氏性:狀態轉移的概率只依賴與他的前一狀態。數學表達爲:
P(Xn+1=k|Xn=kn,Xn−1=kn−1,…,X1=k1)=P(Xn+1=k|Xn=kn)
狀態轉移:狀態的改變叫做轉移(狀態可以向自身轉移),與不同的狀態改變相關的概率叫做轉移概率。
q(i,j)=q(j|i)=q(i→j):
表示狀態 i轉移到狀態j的概率。
如在天氣事件中,由前天的下雨轉移到昨天的多雲,昨天的多雲轉變到今天的豔陽天。這裏所說的下雨、多雲、豔陽天都是一種狀態。從下雨轉移到多雲,稱之爲狀態轉移。而今天的豔陽天只與昨天的多雲有關,與前天的天氣沒有半點關係,這就是所謂馬氏性。
案例
社會學家經常把人按其經濟狀況分成三類:下、中、上層;我們用1,2,3分別代表這三個階層(對應於馬氏鏈中環境下的三個狀態)。如果一個人的收入屬於下層類別,則他的孩屬於下層收入的概率是0.665,屬於中層的概率是0.28,屬於上層的概率是0.07。這裏彙總了階層收入變化的轉移概率如下圖所示:
 狀態轉移的概率只依賴與他的前一狀態,也就是考察父代爲第i層則子代爲第j層的概率。 由此得出轉移概率矩陣:
⎡⎣⎢0.650.150.120.280.670.360.070.180.52⎤⎦⎥
給定當前這一代人處於下、中、上層的概率分佈向量是:
π0=(π0(1),π0(2),π0(3))
,那麼他們的子女的分佈比例將是
π1=π0P
,孫子代的分佈比例將是
π2=π1P=π0P2
,以此類推,第n代的分佈比例將是
πn=π0Pn
. 顯然,第n+1代中處於第j個階層的概率爲:
π(Xn+1=j)=∑i=0nπ(Xn=i).P(Xn+1=j|Xn=i)
給定初始概率
π0=(0.21,0.68,0.11)
,即第0代的時候各階層佔比是(0.21,0.68,0.11)。顯然由此公式我們可以分別計算第一代的第1、2、3階層的佔比,第二代的第1、2、3階層的佔比,….。
如:計算第一代的第1階層的佔比爲:
0.21∗.65+0.68∗0.15+0.11∗0.12=0.2517≈0.252
以此類推,各代各階層的佔比如下:
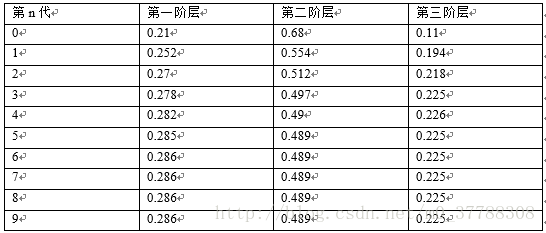 可以看到,從第5代開始,各階層的分佈就穩定不變了。這個是偶然的嗎?如若不是,那是初始概率決定的還是轉移概率矩陣決定的呢?接下來驗證一下。 換一個初始概率
π0=(0.75,0.15,0.1)
,迭代結果如下:
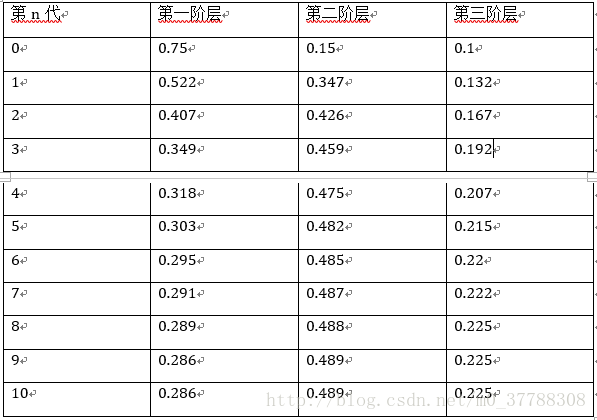 我們發現,到第9代的時候,分佈又收斂了,而且收斂的分佈都是
π=(0.286,0.489,0.225)
,也就是說收斂的分佈與初始概率無關。 這裏還有一個神奇的地方:我們計算一下轉移矩陣P的n次冪,發現:
P20=P21=⋯=P100=Pn=⎡⎣⎢0.2860.2860.2860.4890.4890.4890.2250.2250.225⎤⎦⎥
也就是說,當n足夠大的時候,
Pn
矩陣每一行都收斂到
π=(0.286,0.489,0.225)
這個概率分佈。於是關於馬氏鏈我們有定理如下:
定理一:(馬氏鏈的平穩分佈)
如果一個非週期馬氏鏈具有概率轉移矩陣 P,且它的任何兩個狀態都是連通的,則
limn→∞Pnij
存在且與 i 無關(也即矩陣 P^n 的每一行元素都相同),記
limn→∞Pnij=π(j)
,我們有:
(1)
limn→∞Pn=⎡⎣⎢π(1)...π(1).........π(n)...π(n)⎤⎦⎥
(2)
π(j)=∑∞0π(i)Pij也即π=πP。
(3)π 是方程 π=πP 的唯一非負解。
其中,
π=[π(1),π(2),⋯,π(j),⋯],∑∞0π(i)=1
(符合概率上對分佈的要求),π 稱爲馬氏鏈的平穩分佈。
定理二(細緻平穩條件)
如果非週期馬氏鏈的轉移矩陣
P和分布π(x)滿足:π(i)Pij=π(j)Pji,則π(x)是馬氏鏈的平穩分布,上式被稱爲細致平穩條件。
以上兩個定理極其重要,是MCMC理論不可缺少的理論基礎。
(四)從馬爾科夫鏈到抽樣
對於給定的概率分佈
π(x)
,我們希望有快捷的方式生成它對應的樣本。由於馬氏鏈能收斂到平穩分佈,於是一個很漂亮的想法是:如果我們能夠構造一個轉移矩陣爲 P的馬氏鏈,使得該馬氏鏈的平穩分佈恰好是
π(x)
,那麼我們從任何一個初始狀態出發沿着馬氏鏈轉移,得到一個轉移序列
x1,x2,…,xn,x(n+1),…,
如果馬氏鏈在第 n 步已經收斂了,於是
x1,x2,…,xn,x(n+1),…
自然是分佈
π(x)
的樣本。
馬氏鏈的收斂性質主要有轉移矩陣 P決定,所以基於馬氏鏈做採樣(比如MCMC)
的關鍵問題是如何構造轉移矩陣,使得其對應的平穩分佈恰是我們需要的分佈
π(x)
。
MCMC採樣
根據細緻平穩理論,只要我們找到了可以使概率分佈
π(x)
滿足細緻平穩分佈的矩陣P即可。這給了我們尋找從平穩分佈π, 找到對應的馬爾科夫鏈狀態轉移矩P的新思路。
假設我們已經有一個轉移矩陣爲Q的馬氏鏈。
q(i,j)
表示狀態 i轉移到狀態j的概率.通常情況下,細緻平穩條件不成立,即:
p(i)q(i,j)≠p(j)q(j,i)
對上式改造使細緻平穩條件成立:引入一個α(i,j)和α(j,i) ,並讓等式兩端取等:
p(i)q(i,j)α(i,j)=p(j)q(j,i)α(j,i)
問題是什麼樣的α(i,j)和α(j,i)可以使等式成立呢?按照對稱性,可以取:
α(i,j)=p(j)q(j,i)
α(j,i)=p(i)q(i,j)
所以我們改造後的馬氏鏈
Q′
如下。並且
Q′
恰好滿足細緻平穩條件,所以馬氏鏈
Q′
的平穩分佈就是
P(x)
。
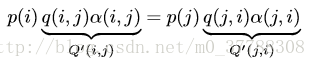 **步驟** (1)初始化馬氏鏈初始狀態
X0=x0
(2)對
t=0,1,2,3,…
循環一下過程進行採樣: 第
t
時刻馬氏鏈狀態爲
Xt=xt
,採樣
y∼q(x|x(t))
; 從均勻分佈採樣
u∼Uniform[0,1];
如果
u<α(xt,y)=p(y)q(xt│y),
則接受
xt→y,
即
xt+1)→y
;否則不接受概率轉移,即
Xt+1=xt。
(五)Metropolis-Hastings採樣
以上過程不論是離散或是連續分佈,都適用。
以上的MCMC採樣算法已經能正常採樣了,但是馬氏鏈Q在轉移的過程中的接受率α(i,j)可能偏小,這樣我們會拒絕大量的跳轉,這使得收斂到平穩分佈的速度太慢。有沒有辦法提升接受率呢?
我們回到MCMC採樣的細緻平穩條件:
p(i)q(i,j)α(i,j)=p(j)q(j,i)α(j,i)
我們採樣效率低的原因是
α(i,j)α(i,j)
太小了,比如爲
α(j,i)爲0.1,而α(j,i)
爲0.2。即:
p(i)q(i,j)∗0.1=p(j)q(j,i)∗0.2
這時我們可以看到,如果兩邊同時擴大五倍,接受率提高到了0.5,但是細緻平穩條件卻仍然是滿足的,即:
p(i)q(i,j)∗0.5=p(j)q(j,i)∗0.2
這樣我們的接受率可以做如下改進,即:
α(i,j)=min{p(j)q(j│i)p(i)p(i│j),1}
此時便得到了常見的
Metropolis−Hastings
採樣算法。
步驟
(1)初始化馬氏鏈初始狀態
X0=x0
(2)對
t=0,1,2,3,…
循環一下過程進行採樣:
第t時刻馬氏鏈狀態爲
Xt=xt
,採樣
y∼q(x|x(t))
;
從均勻分佈採樣
u∼Uniform[0,1];
如果
u<α(xt,y)=min{p(j)q(j│i)p(i)p(i│j),1}
,則接受
xt→y
,即
xt+1→y
;否則不接受概率轉移,即
Xt+1=xt。
以上M-H算法只針對低維的情況,對於高維情況,我們採用Gibbs採樣。
(六)Gibbs採樣
對於高維情況,我們採用Gibbs採樣。
以二維爲例,假設
p(x,y)
是一個二維聯合數據分佈,考察x座標相同的兩個點
A(x1,y1)和B(x1,y2)
,容易發現下面兩式成立:
p(x1,y1)p(y2│x1)=p(x1)p(y1│x1)p(y2|x1)
p(x1,y2
p(x1,y2)p(y1│x1)=p(x1)p(y2│x1)p(y1|