基於決策樹的銀行信貸風險預警模型
原文連接:http://tecdat.cn/?p=2783算法
新常態下銀行信貸風險預警之道性能
基於決策樹銀行信貸用戶分類學習

引言 業務背景測試
我國經濟高速發展,我的信貸業務也隨着快速發展,而我的信貸業務對提升內需,促進消費也有拉動做用。有正必有反,在我的信貸業務規模不斷擴大的同時,信貸的違約等風險問題也日益突出,必定程度上制約着我國的信貸市場的健康發展。優化
挑戰spa
近年來,我的消費貸款的類型呈現出多元化的變化與發展,由本來的單一貸款種類發展到今天各式各樣的貸款種類,汽車按揭貸款、教育助學貸款、耐用消費品貸款(家電、電腦、廚具等)、結婚貸款等在我國陸續開展。違約風險是指債務人因爲各類緣由不能按時歸還貸款債務的風險,對於商業銀行來講,違約風險主要是指因爲貸款人得還款能力降低或者信用水平下降從而違約。設計

相關理論概述 決策樹3d
決策樹(Decision Tree)是用於分類和預測的主要技術, 它着眼於從一組無規則的事例推理出決策樹表示形式的分類規則, 採用自頂向下的遞歸方式,在決策樹的內部節點進行屬性值的比較, 並根據不一樣屬性判斷從該節點向下分支,在決策樹的葉節點獲得結論。所以,從根節點到葉節點就對應着一條合理規則,整棵樹就對應着一組表達式規則。決策樹是數據分析中一種常常要用到且很是重要的技術,既可以用於數據分析,也可以做預測。基於決策樹算法的一個最大的優勢是它在學習過程當中不須要使用者瞭解不少背景知識,,只要訓練事例可以用屬性即結論的方式表達出來, 就能使用該算法進行學習。blog

基於決策樹的分類模型有以下幾個特色:(1)決策樹方法結構簡單,,便於理解;(2)決策樹模型效率高,對訓練集數據量較大的狀況較爲適合;(3)樹方法一般不須要接受訓練集數據外的知識;(4)決策樹方法具備較高的分類精確度。遞歸
預警方案設計
數據在進行操做的過程當中,咱們一共分了四步,分別是數據分析和分離數據集、創建訓練數據集決策樹、評估模型性能、提升模型性能。
數據分析和分離數據集
在數據進行分析時,能夠從中知道全部申請者的違約狀況。在分離數據集這一步,咱們將數據分紅兩部分:用來創建決策樹訓練數據集和用來評估模型性能的測試數據集,按照80%訓練集和20%測試集來分離樣本。總的來看,這兩個數據集的比例是大體相同的,因此分離的兩個數據集是合理的。
訓練數據集
測試數據集
違約
不違約
違約
不違約
0.31625
0.68375
0.235
0.765
25300
54700
4700
15300
表1
創建訓練數據集決策樹

圖1
圖1是訓練數據集決策樹的基本狀況。
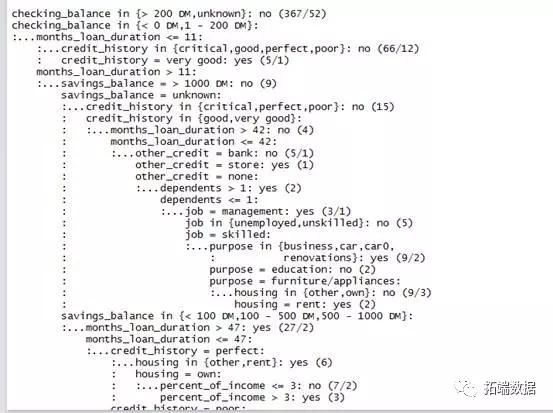
圖2
圖2是訓練數據集的部分決策樹。
因爲咱們咱們的數據龐大,生成的決策樹很是的大,上圖的輸出顯示了決策樹的部分分枝,咱們用簡單的語言來舉例解釋前五行:
(1)若是支票帳戶餘額是未知的,則歸類爲不太可能違約。
(2)不然,若是支票帳戶餘額少於0,或者1~200之間;
(3)月貸款期限少於或等於11個月的
(4)信用記錄是危及、好的、優秀的、差的,歸類爲不太可能違約。
(5)信用記錄是很是優秀的,就歸類爲頗有可能違約。
括號中的數字表示符合該決策準則的案例的數量以及根據該決策不正確分類的案例的數量。
在決策樹中咱們不難發現,爲何一個申請者的信用記錄很是優秀,卻被判成頗有可能違約,而那些支票餘額未知的申請者卻不太可能違約呢?這些決策看似沒有邏輯意義,但其實它們可能反映了數據中的一個真實模式,或者它們多是統計中的異常值。
在決策樹生成後,輸出一個混淆矩陣,這是一個交叉列表,表示模型對訓練數據錯誤分類的記錄數:


衆所周知,決策樹有一種過分擬合訓練數據模型的傾向,因爲這個緣由,訓練數據中報告的錯誤率可能過於樂觀,所以,基於測試數據集來評估決策樹模型是很是重要的。
評估模型性能
在這一步中使用測試數據集作預測,結果如圖3所示。
實際值
預測值
行合計
不違約
違約
不違約
12500
0.625
2800
0.140
15300
違約
2300
0.115
2400
0.120
4700
列合計
14800
5200
20000
表2
從表2中能夠得知,在測試集樣本中,實際不違約被判爲不違約的數量,佔比爲0.625;實際不違約被判爲違約的數量,佔比爲0.140;而實際違約被判爲不違約的數量佔比爲0.115;實際違約被判爲違約的數量,佔比爲0.120。
從銀行角度出發,申請人實際不違約被判爲違約的影響遠沒有實際違約被判爲不違約的影響大。緣由有如下幾點:1、 申請人實際不違約被判爲違約,銀行可能不會經過貸款申請,從而不發放貸款,這樣銀行不會遭受貸款發放出去卻收不回來的風險,只是少收部分貸款利息而已。2、申請人實際違約被判爲不違約,銀行可能會贊成申請人的貸款申請贊成發放貸款,在發放貸款後,被判爲不違約的申請人可能會由於缺少誠信,不遵照合約規定按時還款,這樣銀行不只損失了利息的收入,連本金都有可能收不回來。3、在測試數據集數據中,實際不違約的數量,佔比0.183;而實際違約的數量,被判爲不違約的數量,佔比0.489。
由以上三點能夠得出結論,基於訓練測試集得出的模型,用測試數據集中的數據進行檢驗,最終出來的結果並非很好。從銀行角度出發,若是使用該模型引用到實際生活中,會由於申請人實際違約被誤判爲不違約的機率太大,而使銀行作出錯誤的決定,從而產生損失。
模型優化方案——增長迭代次數、代價矩陣
由上面的評估模型性能能夠得知,基於訓練數據集得出的模型不太理想,所以咱們來提升模型的性能。
一、迭代10次
首先咱們選擇使用迭代10次的方法進行對模型性能的提升。
實際值
預測值
行合計
不違約
違約
不違約
13300
0.665
2000
0.100
15300
違約
2300
0.115
2400
0.120
4700
列合計
15600
4400
20000
表3
由表3能夠知道通過10次迭代,實際違約被判爲不違約的數量佔比0.115,與訓練數據集的模型相比沒有變化;而實際不違約被判爲違約的數量,佔比0.100。
從銀行角度出發,此次的模型性能提升沒有很大的實際意義,由於影響銀行是否虧損的最主要因素是看實際違約被判爲不違約的比重,而此次的性能提升並無減小實際違約被判爲不違約的數量,因此咱們還要繼續提升模型的性能。
二、迭代100次
根據上面的步驟知道,迭代10次出來的模型效果並非很好,因此咱們在這一步進行迭代100次的操做。
實際值
預測值
行合計
不違約
違約
不違約
12900
0.645
2400
0.120
15300
違約
2400
0.120
2300
0.115
4700
列合計
15300
4700
20000
表4
通過迭代100次的過程出來的結果由表4所示,與訓練數據集的結果圖相比,由此能夠看出該次模型性能的提高沒有較大效果。
三、代價矩陣
因爲上述兩次操做均沒有使得模型的性能獲得較大的提高,因此在這一步咱們決定採用代價矩陣的方式來進行。
這裏咱們假設將一個違約用戶錯誤的分類爲不違約相比於將不違約用戶錯誤的分類爲違約來講,前者相較於後者會給貸款方形成4倍的損失,故代價矩陣爲:
上述矩陣行表示真實值,列表示預測值,第一列和第一行表明不違約,第二列和第二行表明違約。假如該算法正確分類時,則沒有分配代價。圖6是加入代價矩陣的模型分類結果彙總。
實際值
預測值
行合計
不違約
違約
不違約
7600
0.380
7700
0.385
15300
違約
1000
0.050
3700
0.185
4700
列合計
8600
11400
20000
表5
相較於前面的結果,在加入代價矩陣後的模型效果不錯,在實際違約被判爲不違約的比例上獲得了較大程度的降低。

圖3
圖3是測試數據集的部分決策樹。
建議
現今,我國的生活水平逐步提高,我的的消費水平也跟着上升,但仍有不少人的工資薪酬漲幅跟不上消費的增加,就會從商業銀行貸款做爲經濟生活維持,已提高本身的生活水平,不只是車輛按揭貸、房產按揭貸款、教育助學貸款、耐用消費品貸款、結婚貸款等在我國陸續開展,數量與規模也愈來愈龐大。商業銀行要從貸款中獲利,就必須增強對於貸款的風險管理,在進行單一評估的同時從大量規律中獲取經驗,對於人力沒法理解的大規模數據,就需相關研究來獲取有用的規律,幫助商業銀行及其餘金融機構作出決策,而決策樹對銀行及金融機構來講就是一種很好的決策管理方法。
經過決策樹的每個子節點能夠看出哪個自變量會對貸款違約有多大的影響,從而商業銀行能夠更加的關注客戶的這一方面,在這方面嚴格把關。算法可以爲影響較大的錯誤分類進行誤判代價值的設定,從而使模型在這類誤判中的增長重視,下降這類錯誤發生的機率。假設銀行將實際上不違約的客戶判成了違約,銀行僅僅是少得到幾筆貸款的利息,不至於把整筆貸款都虧掉變成壞帳;但假如銀行使用了這種算法,對客戶的違約可能性作出更爲準確的判斷,便能減小銀行對實際違約的客戶錯判成不違約的狀況,下降銀行出現貸款沒法追收的狀況。
- 1. 決策模型(二):風險決策法
- 2. 貸款風險預測
- 3. sklearn--決策樹和基於決策樹的集成模型
- 4. 信貸風險評分卡
- 5. 基於決策樹的分類預測
- 6. 用戶貸款風險預測
- 7. 隨機森林之信貸風險模型特徵工程
- 8. 談談信貸的風險標籤
- 9. R語言 決策樹--預測模型
- 10. 決策樹模型
- 更多相關文章...
- • 基於ARP協議進行掃描 - TCP/IP教程
- • ASP.NET MVC - 模型 - ASP.NET 教程
- • ☆基於Java Instrument的Agent實現
- • Kotlin學習(二)基本類型
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. No provider available from registry 127.0.0.1:2181 for service com.ddbuy.ser 解決方法
- 2. Qt5.7以上調用虛擬鍵盤(支持中文),以及源碼修改(可拖動,水平縮放)
- 3. 軟件測試面試- 購物車功能測試用例設計
- 4. ElasticSearch(概念篇):你知道的, 爲了搜索…
- 5. redux理解
- 6. gitee創建第一個項目
- 7. 支持向量機之硬間隔(一步步推導,通俗易懂)
- 8. Mysql 異步複製延遲的原因及解決方案
- 9. 如何在運行SEPM配置嚮導時將不可認的複雜數據庫密碼改爲簡單密碼
- 10. windows系統下tftp服務器使用
- 1. 決策模型(二):風險決策法
- 2. 貸款風險預測
- 3. sklearn--決策樹和基於決策樹的集成模型
- 4. 信貸風險評分卡
- 5. 基於決策樹的分類預測
- 6. 用戶貸款風險預測
- 7. 隨機森林之信貸風險模型特徵工程
- 8. 談談信貸的風險標籤
- 9. R語言 決策樹--預測模型
- 10. 決策樹模型