2017-2018-1 20155306 《信息安全系統設計基礎》第13周學習總結
2017-2018-1 20155306 《信息安全系統設計基礎》第13周學習總結
教材學習內容總結
內容要點總結:第6章 存儲器層次結構
在簡單模型中,存儲器系統是一個線性的字節數組,而CPU可以在一個常數時間內訪問每一個存儲器位置。實際上,存儲器系統是一個具備不一樣容量、成本和訪問時間的存儲設備的層次結構。CPU寄存器保存着最經常使用的數據。靠近CPU的小的、快速的高度緩存存儲器做爲一部分存儲在相對慢速的主存儲器中的數據和指令的緩衝區域。 存儲器層次結構是可行的。html
6.1 存儲結構
6.1.1隨機訪問存儲器
隨機訪問存儲器分爲兩類:靜態的(SRAM)和動態的(DRAM)。算法
1)靜態RAM編程
SRAM將每一個位存儲在一個雙穩態的存儲單元裏。只要有電,他就會永遠保持他的值。即便有干擾來擾亂電壓,當干擾消除時,電路就會恢復穩定值。數組
2)動態RAM緩存
DRAM將每一個位存儲爲對一個電容的充電。與SRAM不一樣,DRAM存儲單元易受干擾。當電容的電壓被擾亂後,他就永遠不會恢復了。安全
SRAM和DRAM的特性: 1.只要供電SRAM就會保持不變。 2.SRAM的存取比DRAM快。 3.SRAM對干擾不敏感。 4.SRAM單元比DRAM單元使用更多晶體管,密度較低,更貴,功耗更大。

AM服務器
- 行地址i:RAS
- 列地址j:CAS
- DRAM組織成二位陣列而不是線性數組的一個緣由是下降芯片上地址引腳的數量。
- 二維陣列組織的缺點是必須分兩步發送地址,這增長了訪問時間。
4)存儲器模塊網絡
- DRAM芯片包裝在存儲器模塊中,他是插到主板的擴展槽位上的。常見的包括168個引腳的雙列直插存儲器模塊,以64位爲塊傳送數據到存儲控制器和從存儲控制器傳出數據,還包括72個引腳的單列直插存儲器模塊,以32位爲塊傳送數據。
- 經過將多個存儲器模塊鏈接到存儲控制器,可以聚合主存,當控制器收到一個地址A時,控制器選擇包含A的模塊k,將A轉換爲它的(i, j)的模式,並將(i, j)發送到模塊k。
5)加強的DRAM異步
- 快頁模式DRAM(FPM DRAM):異步控制信號,容許對同一行連續的訪問能夠直接從行緩衝區獲得服務。
- 擴展數據輸出DRAM(EDO DRAM):異步控制信號,容許單獨的CAS信號在時間上靠的更緊密一點。
- 同步DRAM(SDRAM):同步的控制信號,比異步的快。
- 雙倍數據速率同步DRAM(DDR SDRAM):使用兩個時鐘沿做爲控制信號,使DRAM速度翻倍。
- Rambus DRAM(RDRAM):一種私有技術 。
- 視頻RAM(VRAM):用在圖形系統的幀緩衝區中。
6)非易失性存儲器ide
- 若是斷電,DRAM和SRAM會丟失他們的信息,因此他們是易失的。
- 非易失性存儲器,即便是在關電之後,也仍然保存着他們的信息。他們總體上都稱爲只讀存儲器(ROM)。
- ROM以他們可以被從新編程的次數和對他們進行重編程所用的機制來區分的。
- PROM 只能被編程一次。
- 可擦可編程ROM,有個透明的石英窗口,容許光到達存儲單元。
- 閃存,是一類非易失性存儲器,基於EEPROM,他已經成爲了一種重要的存儲技術。
- 存儲在ROM中的程序一般稱爲固件。
7)訪問主存
- 數據流經過稱爲總線(bus)的共享電子電路在處理器和DRAM主存之間來來回回。每次CPU和主存之間的數據傳送都是經過一系列步驟來完成的,這些步驟稱爲總線事務。
- 讀事務:從主存傳送數據到CPU
- 寫事務:從CPU傳送數據到主存
- 總線:一組並行的導線,能攜帶地址、數據和控制信號。
- 每一個網絡應用都是基於客戶端-服務器模型的。
- 一個應用是由一個服務器戶端提供某種服務。服務器管理某種資源,而且經過操做這種資源來爲它的客戶端提供某種服務。
- 客戶端-服務器模型中的基本操做是事務。
四步組成:
- 當一個客戶端須要服務時,它向服務器發送一個請求,發起一個事務。
- 服務器收到請求後,解釋它,並以適當的方式操做它的資源。
- 服務器給客戶端發送一響應,並等待下一個請求。
- 客戶端收到響應並處理它。
#### 6.1.2磁盤存儲 磁盤是保存大量數據的存儲設備。 1)磁盤構造 磁盤是由盤片構成的。每一個盤片有兩個盤面,表面覆蓋着磁性記錄材料。盤片中央有個能夠旋轉的主軸,使得盤片以固定的旋轉速率旋轉。 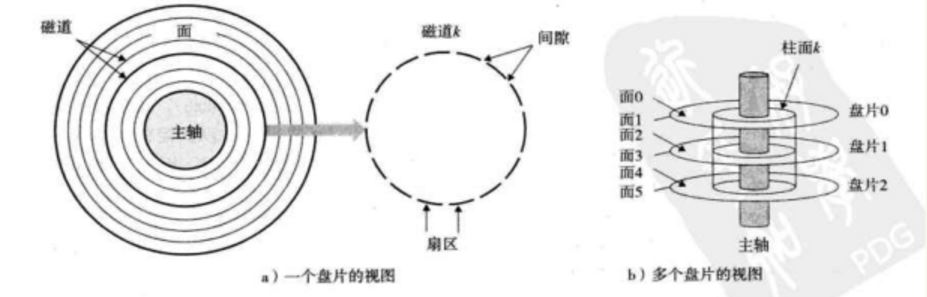 - 旋轉速率:一般5400~15000/min - 磁道:同心圓們 - 扇區:每一個磁道被劃分爲一組扇區 - 數據位:每一個扇區包含相等數量的~,一般爲512字節 - 間隙:存儲用來標識扇區的格式化位 - 磁盤驅動器-磁盤-旋轉磁盤 - 柱面:全部盤片表面上到主軸中心的距離相等的磁道的集合。 2)磁盤容量  計算磁盤容量的公式:
磁盤容量 = 字節數/扇區 X 平均磁盤數/磁道 X 磁道數/表面 X 表面數/盤片 X 盤片數/磁盤
3)磁盤操做 磁盤以扇區大小的塊來讀寫數據。 訪問時間的分類:
(1)尋道時間:
——移動傳動臂所用的時間。
依賴於讀/寫頭之前的位置和傳動臂在盤面上移動的速度。
一般爲3-9ms,最大可達20ms。
(2)旋轉時間
——驅動器等待目標扇區的第一個位旋轉到讀/寫頭下
依賴於盤面位置和旋轉速度。
最大旋轉延遲=1/RPM X 60secs/1min (s)
平均旋轉時間是最大值的一半。
(3)傳送時間
依賴於旋轉速度和每條磁道的扇區數目
平均傳送時間= 1/RPM x 1/(平均扇區數/磁道) x 60s/1min
訪問一個磁盤扇區內容的平均時間爲平均尋道時間,平均旋轉延遲和平均傳送時間之和。
3)邏輯磁盤塊 磁盤結構抽象成B個扇區所組成的邏輯序列,編號位0-(B-1),在磁盤中,有一個小的硬件/固件設備,稱爲磁盤控制器。  4)鏈接到I/O設備 - 像圖形卡、監視器、鼠標鍵盤和磁盤這樣的輸入/輸出(I/O)設備,都是經過I/O總線鏈接到CPU和主存的。 - 雖然I/O總線比系統總線和存儲器總線慢,但它能夠容納種類繁多的第三方I/O設備。 5)訪問磁盤 - DMA:直接存儲器訪問 ——設備能夠本身執行讀或者寫總線事務,而不須要CPU干涉的過程。 #### 6.1.3固態硬盤(SSD) - 一個SSD包由一個或多個閃存芯片和閃存翻譯層組成,閃存芯片代替傳統旋轉磁盤中的機械驅動器,而閃存翻譯層是一個硬件/固件設備,扮演與磁盤控制器相同的角色,將對邏輯塊的請求翻譯成對底層物理設備的訪問。 - 隨機讀和寫的性能差異是由底層閃存基本屬性決定的。 #### 6.1.4 存儲技術趨勢
不一樣的存儲技術有不一樣的價格和性能折中
不一樣存儲技術的價格和性能屬性以大相徑庭的速率變化着
增長密度從而下降成本比下降訪問時間更容易
DRAM和磁盤的性能滯後於cpu的性能
### 6.2局部性 一個編寫良好的計算機程序一般具備良好的局部性。他們傾向於引用鄰近於其餘最近引用過的數據項的數據項,或者最近引用過的數據項自己。這種傾向稱爲局部性原理,局部性原理對硬件和軟件系統的設計和性能都有着極大的影響。局部性有兩種不一樣形式:時間局部性和空間局部性。有良好局部性的程序比局部性差的程序運行的更快。 #### 6.2.1 對程序數據引用的局部性  #####下面咱們來看一些例子:
int sumvec(int v[N])
{
int i, sum = 0;
for (i = 0; i < N; i++)
sum += v[i];
return sum;
}
分析:首先,看sum變量,它在每次循環中都會被引用,所以,對於sum來講,具備好的時間局部性,可是沒有空間局部性。
再看數組v的元素是順序排列的,所以對於數組v,具備良好的空間局部性。可是時間局部性較差。
因此,綜合看來這個程序具備良好的局部性。
int sumarrayrows(int a[M][N])
{
int i, j, sum = 0;
for (i = 0; i < M; i++)
for (j = 0; j < N; j++)
sum += a[i][j];
return sum;
}
分析:這個函數的引用是步長爲1的,由於它按照數組被存儲的行優先順序來訪問的。具備很好的空間局部性。
int sumarraycols(int a[M][N])
{
int i, j, sum = 0;
for (j = 0; j < N; j++)
for (i = 0; i < M; i++)
sum += a[i][j];
return sum;
}
分析:該代碼只是把以前代碼做很小的改動,程序的訪問並非按照行優先順序的,由於C數組在存儲器中是行優先的,因此,他的步長是N,空間局部性不好。
6.2.2 取指令的局部性
循環體裏的指令是按照連續的存儲器順序執行的,所以循環有良好的空間局部性,由於循環體會被執行屢次,因此它也有良好的時間局部性。
代碼區別於程序數據的一個重要屬性時在運行時是不能被修改的。
6.2.3 局部性小結
量化評價一個程序中局部性的簡單原則: - 重複引用同一個變量的程序有良好的時間局部性 - 對於具備步長爲k的引用模式的程序,步長越小,空間局部性越好 - 對於取指令來講,循環有好的時間和空間局部性。循環體越小,循環迭代次數越多,局部性越好。
6.3 存儲器層次結構
圖片展現的是即是存儲器的層次結構,全部的現代計算機系統中都採用這種方法。
通常而言,從上到下,存儲設備變的更慢,更便宜,容量更大。
高層是寄存器,能夠在一個時鐘週期內訪問;
接下來是一個或者多個的基於SRAM的高速緩存存儲器,能夠在幾個CPU時鐘週期內訪問;
下面是基於DRAM的主存,能夠在幾個到幾百個時鐘週期內訪問到;
接下來是慢速但容量很大的磁盤系統,最後還有遠程網絡上的存儲器系統。
緩存:使用高速緩存的過程被稱爲緩存。
存儲器層次結構的中心思想:k層的更小更快的存儲設備,做爲k+1層的更大更慢的存儲設備的緩存。也就是說,層次結構中的每一層都緩存來自較低一層的數據對象。
6.3.1 存儲器層次結構中的緩存
高速緩存:是一個小而快速地存儲設備,它做爲存儲在更大、也更慢的設備中的數據對象的緩衝區域。 緩存:使用高速緩存的過程。
1)緩存命中
但程序須要第k+1層的某個數據對象d時,它首先在當前存儲在第k層的一個塊中查找d,若是d恰好緩存在第k層中,那麼就是咱們說的緩存命中。
2)緩存不命中
- 若第k層中沒有緩存數據對象d,那麼就是咱們所說的緩存不命中。
- 替換或驅逐:覆蓋一個現存的塊的過程。
- 犧牲塊:被驅逐的這個塊。
- 替換策略:決定應該替換哪一個塊。
3)緩存不命中的種類
冷緩存(強制不命中\冷不命中):一個空的緩存,對於有效位爲0的狀況 。 緩存暖身:反覆訪問存儲器使緩存暖身以後的穩定狀態
衝突不命中:限制性的放置策略會引發的一種不命中。 若發生了不命中,第k層的緩存就必須執行某個放置策略,肯定把它從第k+1層中取出來的塊放在哪裏。 硬件緩存一般使用的是更嚴格的放置策略。例如:第k+1層的塊0、四、八、12會映射到第k層的塊0;塊一、五、九、13會映射到塊1;以此類推。
容量不命中:當工做集的大小超過緩存的大小時。工做集:程序是按照一系列階段來運行的,每一個階段訪問緩存塊的某個相對穩定不變的集合。
4)緩存管理
緩存管理:某個東西要將緩存劃分紅塊,在不一樣的層之間傳送塊,斷定是命中仍是不命中,並處理它們。
- 編譯器管理寄存器文件,緩存層次結構的最高層。
- L一、L二、L3層的緩存徹底是由內置在緩存中的硬件邏輯來管理的。
- DRAM主存是有操做系統軟件和CPU上的地址翻譯硬件共同管理的。
- 每一個以太網適配器都有—個全球惟一的48位地址,它存儲在這個適配器的非易失性存儲器上。一臺主機能夠發送一段位,稱爲幀。每一個主機適配器都能看到這個幀,可是隻有目的主機實際讀取它。
這個圖展現了存儲器層次結構中緩存的通常性概念。能夠看到,第k+1層的存儲器被劃分紅連續的數據塊。每一個塊都有一個惟一的地址或名字,使之區別於其餘的塊。塊能夠是固定大小的,也能夠可變大小的。例如,第k+1層存儲器被劃分爲16個大小固定的塊,編號爲0—15。 相似的,第k層的存儲器被劃分較小的塊的集合,每一個塊的大小與k+1層的塊的大小同樣。在任什麼時候刻,第k層的緩存包含第k+1層塊的一個子集的拷貝。例如,在圖中,第k層緩存中有4個塊的空間。當前包含塊4,9,14和3的拷貝。 eg.如上圖所示,思考這麼幾個問題:在第k層讀取塊4中的一個數據對象,是什麼結果?在第k層中讀取塊12中的一個數據對象,是什麼結果?在讀取塊4以後,讀取塊12,而後再讀取塊4,是什麼結果? 答案:依次產生上面所講的緩存命中,緩存不命中,緩存不命中(衝突不命中)。
6.3.2 存儲器層次結構概念小結
存儲結構的本質:每一層存儲設備都是較低一層的緩存。
歸納來講,基於緩存的存儲層次結構行之有效,是由於較慢的存儲設備比較快的存儲設備更便宜,還由於程序傾向於展現局部性。
利用時間局部性
因爲時間局部性,同一數據對象可能會被屢次使用。由於緩存比第一層的存儲設備更快,對後面的命中的服務迴避最開始的不命中的更快。利用空間局部性
塊一般包含有多個對象。因爲空間局部性,咱們會指望後面對該快中其餘對象的訪問可以補償不命中後複製該塊的花費。
現代系統中處處都使用了緩存。
6.4 高速緩存存儲器
早期計算機系統的存儲器層次結構只有三層:CPU寄存器、DRAM主存儲器和磁盤存儲。
6.4.1 通用的高速緩存存儲器組織結構
- 每一個存儲器地址有m位,造成M=2^m個不一樣的地址。 - 高速緩存組:S = 2^m個高速緩存組的數組 - 高速緩存行:B = 2^m字節的數據塊組成 - 有效位:指明這個行是否包含有意義的信息 - 標記位:惟一地標識存儲在這個高速緩存行中的塊,t = m -(b+s)
通常而言,高速緩存的結構能夠用元組(S,E,B,m)來描述。高速緩存的大小(或容量)C指的是全部塊的大小的和。標記位和有效位不包括在內。所以,C=SEB。
6.4.2 直接映射高速緩存
直接映射高速緩存:每一個組只有一行的高速緩存。
高速緩存肯定一個請求是否命中,而後抽取出被請求的字的過程,分爲三步:組選擇、行匹配、字抽取。
- 首先,第一步 組選擇:高速緩存從w的地址中間抽取出s個組索引位;
- 第二步 行匹配:當且僅當設置了有效位,並且高速緩存行中的標記與w的地址中的標記相匹配時,這一行中包含w的一個副本;
- 第三步字抽取:塊偏移位提供了所須要的字的第一個字節的偏移。
根據E(每一個組的高速緩存行數)高速緩存被分爲不一樣的類。每一個組只有一行的高速緩存被稱爲直接映射高速緩存。
1)直接映射高速緩存中的組選擇
組選擇就是緩存從地址A中抽取出中間的s 位,這 s 爲的數值就標記了該地址所在的組。這裏能夠把緩存看成是一維數組,其中每一個元素是一個組,而地址中的 s 位則是這些組的索引。如圖中的組標記爲 0001 對應組 set1。這要把地址中間的 s 爲提取,就能獲得該地址在緩存中對應的組。
2)直接映射高速緩存中的行匹配
在組選擇以後是行匹配,選好組 i 以後,肯定地址A在組 i 的哪一行。由於直接映射緩存的每一組只有一個行。因此只要看A地址中的行標記是否和緩存中的行標記位匹配。匹配則地址A中的數據在緩存中。 另外一方面,若是有效位沒有設置,或者標記不相匹配,那麼咱們就出現了緩存不命中。
3)直接映射高速緩存中的字選擇
直接映射高速緩存中的行匹配和字選擇。在高速緩存塊中,w0表示字w的低位字節,w1是下一字節,以此類推
行匹配肯定後就是字選擇,一旦命中,咱們就知道A就在這個塊中的某個地方。最後一步肯定所須要的字在塊中的哪裏。仍是這張圖,塊偏移位提供了所須要的字的第一個字節的偏移。 咱們把cache塊當作一個字節的數組,而字節偏移是到這個數組的一個索引。
4)直接映射高速緩存中不命中時的行替換
- 若是緩存不命中,那麼須要從存儲器層次結構中的下一層取出被請求的塊,而後將新的塊存儲在組索引位指示的組中的一個高速緩行中。
- 就是從下一層存儲中取出數據,放入緩存的某個位置中,放入的位置就由請求地址A中的組索引肯定所在緩存的組,行因此肯定應該放置的行。若是組中的行都是有效緩存行了,就必需要驅逐現有的一個行。
- 替換策略:用新取出的行替換當前的行。
5)綜合:運行中的直接映射高速緩存
傳統的DRAM:DRAM芯片中的單元(位)被分紅d個超單元,每一個超單元都由w個DRAM單元組成,一個d*w的DRAM總共存儲了dw位信息。超單元被組織成一個r行c列的長方形矩陣。
- 標記位和索引位連起來惟一地標識了內存中的每一個塊。
- 由於有8個內存塊,可是隻有4個高速緩存組,因此多個塊會映射到同一個高速緩存組(即它們有相同的組索引)。
- 映射到同一個高速緩存組的塊由標記位惟一地標識。
6)直接映射高速緩存中的衝突不命中
當程序訪問大小爲2的冪的數組時,直接映射高速緩存中一般會發生衝突不命中。
在這裏咱們舉個例子看看:
1.當CPU須要讀取地址爲0的數據: - 地址 0000 - 組號 0 - 有效位 0——1 - 標記位 0 分析:當CPU須要讀取地址爲0的數據,由於地址是(0000),因此,對應的組號是0,由於組0的開始有效位是0,因此不命中,那麼高速緩存直接從內存中取出塊0,放到組0中,而且置有效位爲1,標記位爲0(由於地址是0000)。 2.當須要讀取地址爲1的數據: -地址 0001 -組號 0 -有效位 1 -標記位 0 分析:當須要讀取地址爲1的數據,由於地址是(0001),因此,對應的組號是0,而且組0的有效位爲1,而且標記位匹配,因此命中了,那就將塊中偏移爲1的字節取出來。高速緩存的狀態不變。 3.當CPU須要讀取地址爲13的數據: -地址1101 -組號 2 -有效位 0——1 -標記位 1 分析:當須要讀取地址13的數據時,由於地址是(1101),因此,對應的組號是2,組2的開始有效位是0,不命中,直接從內存中取出來,放到組2中,而且置有效位爲1,標記位爲1. 4.當須要讀取地址爲8的數據: -地址1000 -組號 0 -有效位 1 -標記位 0——1(不匹配) 分析:當讀取地址8的數據時,會發生不命中,由於地址爲(1000),此時,組0的標記位爲0,高速緩存行中的標記位和地址中的標記位不匹配,因此高數緩存將其餘塊加載到組0中,從新重新的高速緩存行塊0中返回數據,置標記位爲1.
6.4.3 組相聯高速緩存
每一個組都保存有多於一個的高速緩存行
組相聯高速緩存(I<E<C/B)。在一個組相聯高速緩存中,每一個組包含多於一個行。這裏的特例就是一個2路組相聯高速緩存。
1)組相聯高速緩存中的組選擇
同直接映射高速緩存的組選擇,組索引位標識組。
2)組相聯高速緩存中的行匹配和字選擇
基本思路:組中的任何一行均可以包含任何映射到這個組的內存塊。因此高速緩存必須搜索組中的每一行,尋找一個有效的行,器標記和地址中的標記相匹配。若是找到了這一行,便會命中,再利用字偏移選擇一個字。
3)組相聯高速緩存中不命中時的行替換
- 隨機選擇替換策略:最簡單
- 最不常使用策略:替換在過去某個時間窗口內引用次數最少的那一行
- 最近最少使用策略:替換最後一次訪問時間最久遠的那一行
6.4.4 全相聯高速緩存
全相聯高速緩存是由一個包含全部高速緩存行的組(即E=C/B)組成的。
1)全相聯高速緩存中的組選擇
只有一個組,默認組0,沒有索引位,地址只被劃分紅了一個標記和一個塊偏移。
2)全相聯高速緩存中的行匹配和字選擇
- 步驟同組相聯高速緩存同樣。
- 由於全相聯高速緩存中須要並行的搜索續做相匹配的標記,構造一個又大又塊的相聯高速緩存很難,並且比較昂貴,因此全相聯高速緩存只適合作小的高速緩存。
6.4.5 有關寫的問題
直寫,當即將w的高速緩存塊協會到緊接着的低一層中 優勢:簡單 缺點:每次寫都會引發總線流量
寫回,只有當替換算法要驅逐更新過的塊時,才寫到緊接着的低一層中 優勢:符合局部性原理,顯著的減小總線流量 缺點:增長了複雜性,必須爲每一個高速緩存行維護一個額外的修改位
寫分配---一般寫回對應 加載相應的低一層中的塊到高速緩存中,而後更新這個高速緩存塊。
非寫分配---一般直寫對應 避開高速緩存,直接把這個字寫在低一層中。
6.4.6 一個真實的高速緩存層次結構的解剖
存數據,也保存指令。
- 只保存指令的:i-cache
- 只保存程序數據的:d-cache
- 既保存指令又保存數據的:統一的高速緩存
6.4.7 高速緩存參數的性能影響
不命中率:不命中數量/引用數量 命中率:1-不命中率 命中時間:組選擇、行確認和字選擇的時間 不命中處罰:不命中須要的額外的時間
1)高度緩存大小的影響
較大的高速緩存可能會提升命中率,但也可能增長命中時間。
2)塊大小的影響
較大的塊能利用程序中可能存在的空間局部性,幫助提升命中率。快越大意味着高速緩存行數越少,對不命中處罰也有負面影響。
3)相聯度的影響
相聯度E較高,下降了高速緩存因爲衝突不命中出現抖動的可能性。 但價格昂貴,運行速度慢,不命中處罰增長。
4)寫策略的影響
直寫高速緩存能使用獨立於高速緩存的寫緩衝區,用來更新存儲器。高速緩存越往下層,可能使用寫回而不是直寫。
6.5編寫高速緩存友好的代碼
- 讓最多見的狀況運行得快
- 儘可能減少每一個循環內部的緩存不命中數量
- 對局部變量的反覆引用是好的,由於編譯器可以將它們緩存在寄存器文件中(時間局部性)
- 步長爲1的引用模式是好的,由於存儲器層次結構中全部層次上的緩存都是將數據存儲爲連續的塊(空間侷限性)
6.6 綜合:高速緩存對程序性能的影響
6.6.1存儲器山
- 存儲器山是一個數字能夠描述的。它是時間和空間局部性的存儲器山。構造程序,是程序運行在山峯而不是山谷,利用時間局部性,使得頻繁使用的字從L1取出,還要利用空間局部性,使盡量多的字從一個L1高速緩存行中訪問到。
- 咱們看到,存儲器山由三個座標肯定點位。底面右邊的座標是工做集大小(wording set size),按字節計數;底面左邊的座標是步長(stride),按字計數,這裏能夠把字理解成4字節;垂直的座標就是讀吞吐量,根據吞吐量的大小判斷程序性能的優劣。
6.6.2 從新排列循環以提升空間侷限性
與存儲器訪問總數相比,不命中率是一個較好的性能指示
6.6.3 在程序中利用局部性
- 有良好局部性的程序從快速的高速緩存存儲器中訪問它的大部分數據
- 局部性差的程序從DRAM主存中訪問它的大部分數據
在本章最後,給你們推薦一些技術: 將你的注意力集中在內循環上,大部分計算和存儲器訪問都發生在這裏。 經過按照數據對象存儲在存儲器中的順序、以步長爲1來讀數據,從而使空間局部性最大。 一旦從存儲器中讀入了一個數據對象,就儘量多地使用它,從而使得程序中的時間局部性最大。
教材習題
6.22
6.23
6.24
6.25-6.26
6.27-6.28
6.29-6.30
6.31-6.32
6.33
6.36-6.37
6.38-6.40
6.41-6.43
教材學習中的問題和解決過程
- 問題1:書本402頁中圖6-4所示,若是示例的128位DRAM被組織成一個16個超單元的線性數組,地址爲0~15,爲何芯片會須要4個地址引腳而不是2個?
解決:查閱百度,根據CSAPP第六章-存儲器的層次結構得知:DRAM組成二維陣列而不是一維線性數組的一個緣由是下降芯片上地址引腳的數量。例如,16個超單元組成的陣列,二維和一維分別須要2個和4個地址引腳。二維組織的缺點是,地址必須分兩步發送,增長了訪問時間。(一個行地址,一個列地址)。
但仍是想不出來爲何線性是4個引腳。- 問題2:爲何要用中間的位做爲組的索引,而不是組索引,標記位,和偏移量來定義地址
解決:在書上找到了答案,若是用高位作索引,那麼一些連續的內存塊就會映射到相同的高速緩存塊。這樣的話,順序掃描一個數組的元素,任什麼時候刻,高速緩存都只保存着一個塊的大小的數組內容,對高速緩存的使用效率很低。
學習進度條
| 代碼行數(新增/累積) | 博客量(新增/累積) | 學習時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標 | 5000行 | 30篇 | 400小時 | |
| 第一週 | 20/20 | 1/2 | 10/15 | 第一章 |
| 第三週 | 130/210 | 1/2 | 21/36 | 第二章 |
| 第四周 | 70/ 280 | 1/4 | 10/46 | 第十章 |
| 第五週 | 91 / 371 | 1/6 | 23/69 | 第三章 |
| 第六週 | 308 / 648 | 1/8 | 31/100 | 第8、十章 |
| 第七週 | 2200 / 2848 | 1/10 | 25/125 | 第四章 |
| 第八週 | 1072 / 3492 | 1/12 | 41/166 | 第十一,十二章 |
| 第九周 | 508/4000 | 1/14 | 30/196 | 第六章 |
| 第十週 | 1377 / 3492 | 1/14 | 12/208 | 實驗 實時系統 |
| 第十一週 | 350 / 5727 | 1/16 | 35/243 | 第九章 |
嘗試一下記錄「計劃學習時間」和「實際學習時間」,到期末看看能不能改進本身的計劃能力。這個工做學習中很重要,也頗有用。
耗時估計的公式
:Y=X+X/N ,Y=X-X/N,訓練次數多了,X、Y就接近了。
計劃學習時間:30小時
實際學習時間:35小時
改進狀況:
(有空多看看現代軟件工程 課件
軟件工程師能力自我評價表)
參考資料
- 1. 20145222《信息安全系統設計基礎》第13周學習總結
- 2. 20145312 《信息安全系統設計基礎》第13周學習總結
- 3. 20145321 《信息安全系統設計基礎》第13周學習總結
- 4. 20145236《信息安全系統設計基礎》第13周學習總結
- 5. 信息安全系統設計基礎第十五週總結
- 6. 《信息安全系統設計基礎》第2周總結
- 7. 信息安全系統設計基礎第九周總結
- 8. 信息安全設計基礎第十週學習總結
- 9. 信息安全系統設計基礎第九周學習總結
- 10. 信息安全系統設計基礎第一週學習總結
- 更多相關文章...
- • 移動設備 統計 - 瀏覽器信息
- • 操作系統(OS)平臺 統計 - 瀏覽器信息
- • Tomcat學習筆記(史上最全tomcat學習筆記)
- • Kotlin學習(二)基本類型
-
每一个你不满意的现在,都有一个你没有努力的曾经。