大廠面試--京東
京東
後端
有了解哪些數據結構嗎?
鏈表、數組、棧、隊列、樹、圖、堆、散列表
鏈表有哪些特色?
1)數組在內存中是逐個存放的,也就是說假若數組的第一個元素在地址A,則數組第二個元素就在地址A+1。 而鏈表則不是,鏈表每一個節點沒有相對固定的位置關係。某個節點在地址A其後的節點不必定是A+1,而在內存的其餘空閒區域,呈現一種隨機的狀態。 2)數組一旦顯式的被申明後,其大小就固定了,不能動態進行擴充。而鏈表則能夠,能夠動態生成節點而且添加到已有的鏈表後面。 3)鏈表靈活,可是空間和時間額外耗費較大;數組大小固定,元素位置固定,可是操做不靈活,且容易浪費空間,可是時間耗費較小,尤爲是元素變化不大的時候效率很高。雙向鏈表比單向的更靈活,可是空間耗費也更大 。。。。。 鏈表的特性是在中間任意位置添加刪除元素的都很是的快,不須要移動其它的元素。 鏈表顧名思義,要把各個元素連接起來纔算撒。 一般鏈表每個元素都要保存一個指向下一個元素的指針(單鏈表)。 雙鏈表的化每一個元素即要保存到下一個元素的指針,還要保存一個上一個元素的指針。 循環鏈表則把最後一個元素中保存下一個元素指針指向第一個元素。 數組是一組具備相同類型和名稱的變量的集合。這些變量稱爲數組的元素,每一個數組元素都有一個編號, 這個編號叫作下標,咱們能夠經過下標來區別這些元素。數組元素的個數有時也稱之爲數組的長度。 數組查改方便,鏈表增刪效率高。
冒泡排序的複雜度是多少?
O(n^2)
進程和線程的區別是什麼?
一、功能不一樣 進程是計算機中的程序關於某數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位,是操做系統結構的基礎。 線程是操做系統可以進行運算調度的最小單位。它被包含在進程之中,是進程中的實際運做單位。 二、工做原理不一樣 在早期面向進程設計的計算機結構中,進程是程序的基本執行實體;在當代面向線程設計的計算機結構中,進程是線程的容器。程序是指令、數據及其組織形式的描述,進程是程序的實體。 線程是獨立調度和分派的基本單位。線程能夠爲操做系統內核調度的內核線程,如Win32線程;由用戶進程自行調度的用戶線程,如Linux平臺的POSIX Thread;或者由內核與用戶進程,如Windows 7的線程,進行混合調度。 三、做用不一樣 進程是操做系統中最基本、重要的概念。是多道程序系統出現後,爲了刻畫系統內部出現的動態狀況,描述系統內部各道程序的活動規律引進的一個概念,全部多道程序設計操做系統都創建在進程的基礎上。 一般在一個進程中能夠包含若干個線程,它們能夠利用進程所擁有的資源。在引入線程的操做系統中,一般都是把進程做爲分配資源的基本單位,而把線程做爲獨立運行和獨立調度的基本單位。
如何實現進程間通訊?
https://blog.csdn.net/qq_1952...javascript
進程間通訊的意思就是在不一樣進程之間傳遞信息。它是一組編程接口,讓程序員協調不一樣進程,使可以相互傳遞消息。 IPC目的 1)數據傳輸:一個進程須要將它的數據發送給另外一個進程,發送的數據量在一個字節到幾兆字節之間。 2)共享數據:多個進程想要操做共享數據,一個進程對共享數據的修改,別的進程應該馬上看到。 3)通知事件:一個進程須要向另外一個或一組進程發送消息,通知它(它們)發生了某種事件(如進程終止時要通知父進程)。 4)資源共享:多個進程之間共享一樣的資源。爲了做到這一點,須要內核提供鎖和同步機制。 5)進程控制:有些進程但願徹底控制另外一個進程的執行(如Debug進程),此時控制進程但願可以攔截另外一個進程的全部陷入和異常,並可以及時知道它的狀態改變。 IPC方式包括:管道、系統IPC(信號量、消息隊列、共享內存)和套接字(socket)。 管道: 3種。管道是面向字節流,自帶互斥與同步機制,生命週期隨進程。 1)普通管道PIPE, 一般有兩種限制,一是半雙工,數據同時只能單向傳輸;二是隻能在父子或者兄弟進程間使用., 2)命令流管道s_pipe: 去除了第一種限制,爲全雙工,能夠同時雙向傳輸, 3)命名管道FIFO, 去除了第二種限制,能夠在許多並不相關的進程之間進行通信。 ①無名管道:沒有磁盤節點,僅僅做爲一個內存對象,用完就銷燬了。所以沒有顯示的打開過程,實際在建立時自動打開,而且生成內存iNode,其內存對象和普通文件的一致,因此讀寫操做用的一樣的接口,可是專用的。由於不能顯式打開(沒有任何標示),因此只能用在父子進程,兄弟進程, 或者其餘繼承了祖先進程的管道文件對象的兩個進程間使用【具備共同祖先的進程】 int pipe(int fd[2]);//由參數fd返回兩個文件描述符,fd[0]爲讀而打開 fd[1]爲寫而打開 int read(fd[0], buff, int size); int write(fd[1], buff, int size); ②有名管道:任意兩個或多個進程間通信。由於它在文件目錄樹中有一個文件標示(FIFO) 實際不佔據磁盤空間,數據緩存在內存上。它與普通文件相似,都遵循打開,讀,寫,關閉的過程,但讀寫的內部實現和普通文件不一樣,和無名管道同樣。 命令:mkfifo a=filename //mkfifo(char *path,int flag)系統調用。 標識符與鍵:每一個內核的IPC結構(消息隊列、信號量或共享內存)都用一個非負整數標識符引用。 標識符是IPC對象的內部名。爲了是多個進程間可以訪問到同一IPC對象,須要提供一個外部名。即「鍵(key)」,鍵與每一個IPC對象關聯,並做爲對象的外部名。鍵的數據類型爲key_t,由內核變換成標識符。 內核對象:用於進程間通信時,多進程能訪問同一資源的記錄,用標識符標識。。 信號量: 1.臨界資源:同一時刻,只能被一個進程訪問的資源 2.臨界區:訪問臨界資源的代碼區 3.原子操做:任何狀況下不能被打斷的操做。 它是一個計數器,記錄資源能被多少個進程同時訪問。用於控制多進程對臨界資源的訪問(同步)),而且是非負值。主要做爲進程間以及同一進程的不一樣線程間的同步手段。 操做:建立或獲取,如果建立必須初始化,不然不用初始化。 int semget((key_t)key, int nsems, int flag);//建立或獲取信號量 int semop(int semid, stuct sembuf*buf, int length);//加一操做(V操做):釋放資源;減一操做(P操做):獲取資源 int semct(int semid, int pos, int cmd);//初始化和刪除 注:咱們能夠封裝成庫,實現信號量的建立或初始化,p操做,V操做,刪除操做。。 消息隊列: 消息隊列是消息的鏈表,是存放在內核中並由消息隊列標識符標識。所以是隨內核持續的,只有在內核重起或者顯示刪除一個消息隊列時,該消息隊列纔會真正被刪除。。消息隊列克服了信號傳遞信息少,管道只能承載無格式字節流以及緩衝區受限等特色。容許不一樣進程將格式化的數據流以消息隊列形式發送給任意進程,對消息隊列具備操做權限的進程均可以使用msgget完成對消息隊列的操做控制,經過使用消息類型,進程能夠按順序讀信息,或爲消息安排優先級順序。 與信號量相比,都之內核對象確保多進程訪問同一消息隊列。但消息隊列發送實際數據,信號量進行進程同步控制。 與管道相比,管道發送的數據沒有類型,讀取數據端無差異從管道中按照先後順序讀取;消息隊列有類型,讀端能夠根據數據類型讀取特定的數據。 操做:建立或獲取消息隊列, int msgget((key_tkey, int flag);//若存在獲取,不然建立它 發送消息:int msgsnd(int msgid, void *ptr, size_t size, int flag); ptr指向一個結構體存放類型和數據 size 數據的大小 接受消息:int msgrcv(int msgid, void *ptr, size_t size, long type, int flag); 刪除消息隊列: int msgctl(int msgid, int cmd, struct msgid_ds*buff); 共享內存: 共享內存就是映射一段能被其餘進程所訪問的內存,這段共享內存由一個進程建立,但多個進程均可以訪問。 共享內存是最快的一種IPC,由於不須要在客戶進程和服務器進程之間賦值。使用共享內存的惟一注意的是是多個進程對一給定的存儲區的同步訪問。【若服務器進程正在向共享存儲區寫入數據,則寫完數據以前客戶進程不該讀取數據,或者客戶進程正在從共享內存中讀取數據,服務進程不該寫入數據。。因此咱們要對共享內存進行同步控制,一般是信號量。】 int shmget((key_t)key, size_t size, int flag); //size 開闢內存空間的大小,flag:若存在則獲取,不然建立共享內存存儲段,返回一個標識符。 void *shmat(int shmid, void *addr, int flag); //將共享內存段鏈接到進程的地址空間中,返回一個共享內存首地址 函數shmat將標識號爲shmid共享內存映射到調用進程的地址空間中,映射的地址由參數shmaddr和shmflg共同肯定,其準則爲: (1) 若是參數shmaddr取值爲NULL,系統將自動肯定共享內存連接到進程空間的首地址。 (2) 若是參數shmaddr取值不爲NULL且參數shmflg沒有指定SHM_RND標誌,系統將運用地址shmaddr連接共享內存。 (3) 若是參數shmaddr取值不爲NULL且參數shmflg指定了SHM_RND標誌位,系統將地址shmaddr對齊後連接共享內存。其中選項SHM_RND的意思是取整對齊,常數SHMLBA表明了低邊界地址的倍數,公式「shmaddr – (shmaddr % SHMLBA)」的意思是將地址shmaddr移動到低邊界地址的整數倍上。 int shmdt(void *ptr); //斷開進程與共享內存的連接 進程脫離共享內存區後,數據結構 shmid_ds 中的 shm_nattch 就會減 1 。可是共享段內存依然存在,只有 shm_attch 爲 0 後,即沒有任何進程再使用該共享內存區,共享內存區纔在內核中被刪除。通常來講,當一個進程終止時,它所附加的共享內存區都會自動脫離。 int shmctl(int shmid, int cmd, struct shmid_ds *buff); //刪除共享內存(內核對象) shmid是shmget返回的標識符; cmd是執行的操做:有三種值,通常爲 IPC_RMID 刪除共享內存段; buff默認爲0. 若是共享內存已經與全部訪問它的進程斷開了鏈接,則調用IPC_RMID子命令後,系統將當即刪除共享內存的標識符,並刪除該共享內存區,以及全部相關的數據結構; 若是仍有別的進程與該共享內存保持鏈接,則調用IPC_RMID子命令後,該共享內存並不會被當即從系統中刪除,而是被設置爲IPC_PRIVATE狀態,並被標記爲」已被刪除」(使用ipcs命令能夠看到dest字段);直到已有鏈接所有斷開,該共享內存纔會最終從系統中消失。 須要說明的是:一旦經過shmctl對共享內存進行了刪除操做,則該共享內存將不能再接受任何新的鏈接,即便它依然存在於系統中!因此,能夠確知, 在對共享內存刪除以後不可能再有新的鏈接,則執行刪除操做是安全的;不然,在刪除操做以後如仍有新的鏈接發生,則這些鏈接都將可能失敗! 消息隊列和管道基本上都是4次拷貝,而共享內存(mmap, shmget)只有兩次。 4次:1,由用戶空間的buf中將數據拷貝到內核中。2,內核將數據拷貝到內存中。3,內存到內核。4,內核到用戶空間的buf. 2次: 1,用戶空間到內存。 2,內存到用戶空間。 消息隊列、共享內存和管道都是內核對象,所執行的操做也都是系統調用,而這些數據最終是要存儲在內存中執行的。所以不可避免的要通過4次數據的拷貝。可是共享內存不一樣,當執行mmap或者shmget時,會在內存中開闢空間,而後再將這塊空間映射到用戶進程的虛擬地址空間中,即返回值爲一個指向邏輯地址的指針。當用戶使用這個指針時,例如賦值操做,會引發一個從邏輯地址到物理地址的轉化,會將數據直接寫入對應的物理內存中,省去了拷貝到內核中的過程。當讀取數據時,也是相似的過程,所以總共有兩次數據拷貝。 socket通訊 適合同一主機的不一樣進程間和不一樣主機的進程間進行全雙工網絡通訊。但並不僅是Linux有,在全部提供了TCP/IP協議棧的操做系統中幾乎都提供了socket,而全部這樣操做系統,對套接字的編程方法幾乎是徹底同樣的,即「網絡編程」。
nodecss
> 原生的 cluster 和 fork 模式都有 API 封裝好的進行通訊。若是是 execfile 這樣形式調起第三方插件形式,想要與第三方插件進行通訊,能夠本身封裝一個相似 promisyfy 形式進行通訊,維護這塊,子進程能夠監聽到異常,一旦發現異常,馬上通知主進程,殺死這個異常的子進程,而後從新開啓一個子進程~
java中如何建立一個進程?
https://blog.csdn.net/wangxin...html
java建立進程有兩種方法:
1.使用Runtime的exec(String cmdarray[])方法建立進程
代碼以下:
String [] cmd={"cmd","/c","start dir"};
Runtime rt = Runtime.getRuntime();
Process proc=rt.exec(cmd);
執行結果以下:
2.使用ProcessBuilder的start()方法建立進程
代碼以下:
ProcessBuilder pb=new ProcessBuilder("cmd","/C","start","netstat");
Process ps=pb.start();
執行結果以下:
除以上列出的命令外,還能夠經過進程調起計算機、文本編輯器等。
調起計算器代碼爲:Runtime.getRuntime.exec("calc");
調起文本編輯器爲:Runtime.getRuntime.exec("notepad");
瀏覽器中的DOM樹的數據結構是怎麼存儲的?
今天經過對 DOM 模型、HTML 解釋器和 JavaScript 的執行的介紹,來初步學習 HTML 解釋器是如何將從網絡或者本地文件獲取的字節流轉成 DOM 樹的。 DOM 模型 一、DOM 標準 DOM (Document Object Model) 的全稱是文檔對象模型,它能夠以一種獨立於平臺和語言的方式訪問和修改一個文檔的內容和結構。好比,Web開發中,用 JavaScript 語言來訪問、建立、刪除或者修改 HTML 的文檔結構。 目前 W3C 已經定義了一系列 DOM 接口(三個版本的 DOM 接口,每個版本都加入了一些新功能,有興趣的同窗請自行查閱),使用這些接口能夠對 DOM 樹結構進行操做。 二、 DOM 樹 在介紹 DOM 樹以前,首先要清楚,DOM 規範中,對於文檔的表示方法並無任何限制,所以,DOM 樹只是多種文檔結構中的一種較爲廣泛的實現方式。 DOM 結構構成的基本要素是 「節點「,而文檔的結構就是由層次化的節點組成。在 DOM 模型中,節點的概念很寬泛,整個文檔 (Document) 就是一個節點,稱爲文檔節點。除此以外還有元素(Element)節點、屬性節點、Entity節點、註釋(Comment)節點等。 瞭解了 DOM 的結構是由各類的子節點組成的,那麼以 HTMLDocument 爲根節點,其他節點爲子節點,組織成一個樹的數據結構的表示就是 DOM樹。 HTML 網頁和它的 DOM 樹表示 HTML 解釋器 一、解釋過程 HTML 解釋器的工做就是將網絡或者本地磁盤獲取的 HTML 網頁和資源從字節流解釋成 DOM 樹結構。 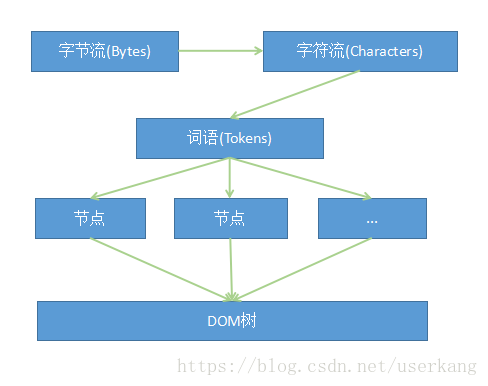 從資源的字節流到 DOM 樹 經過上圖能夠清楚的瞭解這一過程:首先是字節流,通過解碼以後是字符流,而後經過詞法分析器會被解釋成詞語(Tokens),以後通過語法分析器構建成節點,最後這些節點被組建成一顆 DOM 樹。 在這個過程當中,每個環節都會調用對應的類去處理 詞法分析: HTMLTokenizer 類 詞語驗證:XSSAuditor 類 從詞語到節點: HTMLDocumentParser 類、 HTMLTreeBuilder 類 從節點到 DOM 樹: HTMLConstructionSite 類 對於線程化的解釋器,字符流後的整個解釋、佈局和渲染過程基本會交給一個單獨的渲染線程來管理(不是絕對的)。因爲 DOM 樹只能在渲染線程上建立和訪問,因此構建 DOM 樹的過程只能在渲染線程中進行。可是,從字符串到詞語這個階段能夠交給單獨的線程來作,Chromium 瀏覽器使用的就是這個思想。在解釋成詞語以後,Webkit 會分批次將結果詞語傳遞迴渲染線程。 JavaScript 的執行 在 HTML 解釋器的工做過程當中,可能會有 JavaScript 代碼須要執行,它發生在將字符串解釋成詞語以後、建立各類節點的時候。這也是爲何全局執行的 JavaScript 代碼不能訪問 DOM 的緣由——由於 DOM 樹尚未被建立完呢。 WebKit 將 DOM 樹建立過程當中須要執行的 JavaScript 代碼交由 HTMLScriptRunner 類來負責,其利用 JavaScript 引擎來執行 Node 節點中包含的代碼。 由於 JavaScript 代碼可能會修改文檔結構,因此代碼的執行會阻礙後面節點的建立,同時也會阻礙後面的資源下載,這樣就會致使資源不能併發下載的性能問題。因此通常建議: 一、在 「script「 標籤上加上 「async「 或 「defer「 屬性。 二、將 「script「 元素放在 「body「 元素後面。 對於此,WebKit 也經過預掃描和預加載來實現對資源併發下載的優化。 具體過程就是當須要執行 JavaScript 代碼的時候,WebKit 先暫停代碼的執行,使用預掃描器 HTMLPreloadScanner 類來掃描後面的詞語, 若是發現須要使用其餘資源,那麼就會使用與資源加載器 HTMLResourcePreloader 類來發送請求,在這以後,才執行 JavaScript 代碼。因爲預掃描器自己並不建立節點對象,也不會構建 DOM 樹,因此速度比較快。就算如此,仍是推薦不要在頭部寫入大量 JavaScript 代碼,畢竟不是全部渲染引擎都作了這樣的優化。 在 DOM 樹構建完成後,WebKit 會觸發 「DOMContentLoaded」 事件,當全部資源都被加載完成後,會觸發 「onload」 事件。
https://blog.csdn.net/weixin_...前端
這幾天下了Chrome的源碼,安裝了一個debug版的Chromium研究了一下,雖然不少地方都只知其一;不知其二,可是仍是有一點收穫,將在這篇文章介紹DOM樹是如何構建的,看了本文應該能夠回答如下問題:
IE用的是Trident內核,Safari用的是Webkit,Chrome用的是Blink,到底什麼是內核,它們的區別是什麼?
若是沒有聲明<!DOCTYPE html>會形成什麼影響?
瀏覽器如何處理自定義的標籤,如寫一個<data></data>?
查DOM的過程是怎麼樣的?
先說一下,怎麼安裝一個能夠debug的Chrome
1. 從源碼安裝Chrome
爲了能夠打斷點debug,必須得從頭編譯(編譯的時候帶上debug參數)。因此要下載源碼,Chrome把最新的代碼更新到了Chromium的工程,是徹底開源的,你能夠把它整一個git工程下載下來。Chromium的下載安裝可參考它的文檔, 這裏把一些關鍵點說一下,以Mac爲例。你須要先下載它的安裝腳本工具,而後下載源碼:
fetch chromium --no-history
–no-history的做用是不把整個git工程下載下來,那個實在是太大了。或者是直接執行git clone:
git clone https://chromium.googlesource.com/chromium/src
這個就是整一個git工程,下載下來有6.48GB(那時)。博主就是用的這樣的方式,若是下載到最後提示出錯了:
fatal: The remote end hung up unexpectedly
fatal: early EOF
fatal: index-pack failed
能夠這樣解決:
git config --global core.compression 0
git clone --depth 1 https://chromium.googlesource.com/chromium/src
就不用重頭開始clone,由於實在太大、太耗時了。
下載好以後生成build的文件:
gn gen out/gn --ide=xcode
–ide=xcode是爲了可以使用蘋果的XCode進行可視化進行調試。gn命令要下載Chrome的devtools包,文檔裏面有說明。
準備就緒以後就能夠進行編譯了:
ninja -C out/gn chrome
在筆者的電腦上編譯了3個小時,firfox的源碼須要編譯七、8個小時,因此相對來講已經快了不少,同時沒報錯,一次就過,至關順利。編譯組裝好了以後,會在out/gn目錄生成Chromium的可執行文件,具體路徑是在:
out/gn/Chromium.app/Contents/MacOS/Chromium
運行這個就能夠打開Chromium了:
那麼怎麼在可視化的XCode裏面進行debug呢?
2. 在XCode裏面Debug
在上面生成build文件的同時,會生成XCode的工程文件:sources.xcodeproj,具體路徑是在:
out/gn/sources.xcodeproj
雙擊這個文件,打開XCode,在上面的菜單欄裏面點擊Debug -> AttachToProcess -> Chromium,要先打開Chrome,才能在列表裏面看到Chrome的進程。而後小試牛刀,打個斷點試試,看會不會跑進來:
在左邊的目錄樹,打開chrome/browser/devtools/devtools_protocol.cc這個文件,而後在這個文件的ParseCommand函數裏面打一個斷點,按照字面理解這個函數應該是解析控制檯的命令。打開Chrome的控制檯,輸入一條命令,例如:new Date(),按回車能夠看到斷點生效了:
經過觀察變量值,能夠看到剛剛敲進去的命令。這就說明了咱們安裝成功,而且能夠經過可視化的方式進行調試。
可是咱們要debug頁面渲染過程,Chrome的blink框架使用多進程技術,每打開一個tab都會新開一個進程,按上面的方式是debug不了構建DOM過程的,從Chromium的文檔能夠查到,須要在啓動的時候帶上一個參數:
Chromium --renderer-startup-dialog
Chrom的啓動進程就會緒塞,而且提示它的渲染進程ID:
[7339:775:0102/210122.254760:ERROR:child_process.cc(145)] Renderer (7339) paused waiting for debugger to attach. Send SIGUSR1 to unpause.
7339就是它的渲染進程id,在XCode裏面點 Debug -> AttachToProcess By Id or Name -> 填入id -> 肯定,attach以後,Chrome進程就會恢復,而後就能夠開始調試渲染頁面的過程了。
在content/renderer/render_view_impl.cc這個文件的1093行RenderViewImpl::Create函數裏面打個斷點,按照上面的方式,從新啓動Chrome,在命令行帶上某個html文件的路徑,爲了打開Chrome的時候就會同時打開這個文件,方便調試。執行完以後就能夠看到斷點生效了。能夠說render_view_impl.cc這個文件是第一個具體開始渲染頁面的文件——它會初始化頁面的一些默認設置,如字體大小、默認的viewport等,響應關閉頁面、OrientationChange等事件,而在它再往上的層主要是一些負責通訊的類。
3. Chrome建DOM源碼分析
先畫出構建DOM的幾個關鍵的類的UML圖,以下所示:
第一個類HTMLDocumentParser負責解析html文本爲tokens,一個token就是一個標籤文本的序列化,並藉助HTMLTreeBuilder對這些tokens分類處理,根據不一樣的標籤類型、在文檔不一樣位置,調用HTMLConstructionSite不一樣的函數構建DOM樹。而HTMLConstructionSite藉助一個工廠類對不一樣類型的標籤建立不一樣的html元素,並創建起它們的父子兄弟關係,其中它有一個m_document的成員變量,這個變量就是這棵樹的根結點,也是js裏面的window.document對象。
爲做說明,用一個簡單的html文件一步步看這個DOM樹是如何創建起來的:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div>
<h1 class="title">demo</h1>
<input value="hello">
</div>
</body>
</html>
而後按照上面第2點提到debug的方法,打開Chromium並開始debug:
chromium ~/demo.html --renderer-startup-dialog
咱們先來研究一下Chrome的加載和解析機制
1. 加載機制
以發http請求去加載html文本作爲咱們分析的第一步,在此以前的一些初始化就不考慮了。Chrome是在DocumentLoader這個類裏面的startLoadingMainResource函數裏去加載url返回的數據,如訪問一個網站則返回html文本:
FetchRequest fetchRequest(m_request, FetchInitiatorTypeNames::document,
mainResourceLoadOptions);
m_mainResource =
RawResource::fetchMainResource(fetchRequest, fetcher(), m_substituteData);
把參數裏的m_request打印出來,在這個函數裏面加一行代碼:
LOG(INFO) << "request url is: " << m_request.url().getString()
並從新編譯Chrome運行,控制檯輸出:
[22731:775:0107/224014.494114:INFO:DocumentLoader.cpp(719)] request url is: 「file:///Users/yincheng/demo.html」
能夠看到,這個url確實是咱們傳進的參數。
發請求後,每次收到的數據塊,會經過Blink封裝的IPC進程間通訊,觸發DocumentLoader的dataReceived函數,裏面會去調它commitData函數,開始處理具體業務邏輯:
void DocumentLoader::commitData(const char* bytes, size_t length) {
ensureWriter(m_response.mimeType());
if (length)
m_dataReceived = true;
m_writer->addData(bytes, length);
}
這個函數關鍵行是最2行和第7行,ensureWriter這個函數會去初始化上面畫的UML圖的解析器HTMLDocumentParser (Parser),並實例化document對象,這些對象都是經過實例m_writer去帶動的。也就是說,writer會去實例化Parser以後,第7行writer傳遞數據給Parser去解析。
檢查一下收到的數據bytes是什麼東西:
能夠看到bytes就是請求返回的html文本。
在ensureWriter函數裏面有個判斷:
void DocumentLoader::ensureWriter(const AtomicString& mimeType,
const KURL& overridingURL) {
if (m_writer)
return;
}
若是m_writer已經初始化過了,則直接返回。也就是說Parser和document只會初始化一次。
在上面的addData函數裏面,會啓動一條線程執行Parser的任務:
if (!m_haveBackgroundParser)
startBackgroundParser();
並把數據傳遞給這條線程進行解析,Parser一旦收到數據就會序列成tokens,再構建DOM樹。
2. 構建tokens
這裏咱們只要關注序列化後的token是什麼東西就行了,爲此,寫了一個函數,把tokens的一些關鍵信息打印出來:
String getTokenInfo(){
String tokenInfo = "";
tokenInfo = "tagName: " + this->m_name + "|type: " + getType() + "|attr:" + getAttributes() + "|text: " + this->m_data;
return tokenInfo;
}
打印出來的結果:
tagName: html |type: DOCTYPE |attr: |text: " tagName: |type: Character |attr: |text: \n" tagName: html |type: startTag |attr: |text: "
tagName: |type: Character |attr: |text: \n" tagName: head |type: startTag |attr: |text: " tagName: |type: Character |attr: |text: \n "
tagName: meta |type: startTag |attr:charset=utf-8 |text: " tagName: |type: Character |attr: |text: \n" tagName: head |type: EndTag |attr: |text: "
tagName: |type: Character |attr: |text: \n" tagName: body |type: startTag |attr: |text: " tagName: |type: Character |attr: |text: \n "
tagName: div |type: startTag |attr: |text: " tagName: |type: Character |attr: |text: \n " tagName: h1 |type: startTag |attr:class=title |text: "
tagName: |type: Character |attr: |text: demo" tagName: h1 |type: EndTag |attr: |text: " tagName: |type: Character |attr: |text: \n "
tagName: input |type: startTag |attr:value=hello |text: " tagName: |type: Character |attr: |text: \n " tagName: div |type: EndTag |attr: |text: "
tagName: |type: Character |attr: |text: \n" tagName: body |type: EndTag |attr: |text: " tagName: |type: Character |attr: |text: \n"
tagName: html |type: EndTag |attr: |text: " tagName: |type: Character |attr: |text: \n" tagName: |type: EndOfFile |attr: |text: "
這些內容有標籤名、類型、屬性和innerText,標籤之間的文本(換行和空白)也會被看成一個標籤處理。Chrome總共定義了7種標籤類型:
enum TokenType {
Uninitialized,
DOCTYPE,
StartTag,
EndTag,
Comment,
Character,
EndOfFile,
};
有了一個根結點document和一些格式化好的tokens,就能夠構建dom樹了。
3. 構建DOM樹
(1)DOM結點
在研究這個過程以前,先來看一下一個DOM結點的數據結構是怎麼樣的。以p標籤HTMLParagraphElement爲例,畫出它的UML圖,以下所示:
Node是最頂層的父類,它有三個指針,兩個指針分別指向它的前一個結點和後一個結點,一個指針指向它的父結點;
ContainerNode繼承於Node,添加了兩個指針,一個指向第一個子元素,另外一個指向最後一個子元素;
Element又添加了獲取dom結點屬性、clientWidth、scrollTop等函數
HTMLElement又繼續添加了Translate等控制,最後一級的子類HTMLParagraphElement只有一個建立的函數,可是它繼承了全部父類的屬性。
須要提到的是每一個Node都組合了一個treeScope,這個treeScope記錄了它屬於哪一個document(一個頁面可能會嵌入iframe)。
構建DOM最關鍵的步驟應該是創建起每一個結點的父子兄弟關係,即上面提到的成員指針的指向。
到這裏咱們能夠先回答上面提出的第一個問題,什麼是瀏覽器內核
(2)瀏覽器內核
瀏覽器內核也叫渲染引擎,上面已經看到了Chrome是如何實例化一個P標籤的,而從firefox的源碼裏面P標籤的依賴關係是這樣的:
在代碼實現上和Chrome沒有任何關係。這就好像W3C出了道題,firefox給了一個解法,取名爲Gecko,Safari也給了本身的答案,取名Webkit,Chrome以爲Safari的解法比較好直接拿過來用,又結合自身的基礎又封裝了一層,取名Blink。因爲W3C出的這道題「開放性」比較大,出的時間比較晚,致使各家實現各有花樣。
明白了這點後,繼續DOM構建。下面開始再也不說Chrome,叫Webkit或者Blink應該更準確一點
(3)處理開始步驟
Webkit把tokens序列好以後,傳遞給構建的線程。在HTMLDocumentParser::processTokenizedChunkFromBackgroundParser的這個函數裏面會作一個循環,把解析好的tokens作一個遍歷,依次調constructTreeFromCompactHTMLToken進行處理。
根據上面的輸出,最開始處理的第一個token是docType的那個:
"tagName: html |type: DOCTYPE |attr: |text: "
在那個函數裏面,首先Parser會調TreeBuilder的函數:
m_treeBuilder->constructTree(&token);
而後在TreeBuilder裏面根據token的類型作不一樣的處理:
void HTMLTreeBuilder::processToken(AtomicHTMLToken* token) {
if (token->type() == HTMLToken::Character) {
processCharacter(token);
return;
}
switch (token->type()) {
case HTMLToken::DOCTYPE:
processDoctypeToken(token);
break;
case HTMLToken::StartTag:
processStartTag(token);
break;
case HTMLToken::EndTag:
processEndTag(token);
break;
//othercode
}
}
它會對不一樣類型的結點作相應處理,從上往下依次是文本節點、doctype節點、開標籤、閉標籤。doctype這個結點比較特殊,單獨做爲一種類型處理
(3)DOCType處理
在Parser處理doctype的函數裏面調了HTMLConstructionSite的插入doctype的函數:
void HTMLTreeBuilder::processDoctypeToken(AtomicHTMLToken* token) {
m_tree.insertDoctype(token);
setInsertionMode(BeforeHTMLMode);
}
在這個函數裏面,它會先建立一個doctype的結點,再建立插dom的task,並設置文檔類型:
void HTMLConstructionSite::insertDoctype(AtomicHTMLToken* token) {
//const String& publicId = ...
//const String& systemId = ...
DocumentType* doctype =
DocumentType::create(m_document, token->name(), publicId, systemId); //建立DOCType結點
attachLater(m_attachmentRoot, doctype); //建立插DOM的task
setCompatibilityModeFromDoctype(token->name(), publicId, systemId); //設置文檔類型
}
咱們來看一下不一樣的doctype對文檔類型的設置有什麼影響,以下:
// Check for Quirks Mode.
if (name != "html" ) {
setCompatibilityMode(Document::QuirksMode);
return;
}
若是tagName不是html,那麼文檔類型將會是怪異模式,如下兩種就會是怪異模式:
<!DOCType svg>
<!DOCType math>
而經常使用的html4寫法:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
在源碼裏面這個將是有限怪異模式:
// Check for Limited Quirks Mode.
if (!systemId.isEmpty() &&
publicId.startsWith("-//W3C//DTD HTML 4.01 Transitional//",
TextCaseASCIIInsensitive))) {
setCompatibilityMode(Document::LimitedQuirksMode);
return;
}
上面的systemId就是」http://www.w3.org/TR/html4/loose.dtd」,它不是空的,因此判斷成立。而若是systemId爲空,則它將是怪異模式。若是既不是怪異模式,也不是有限怪異模式,那麼它就是標準模式:
// Otherwise we are No Quirks Mode.
setCompatibilityMode(Document::NoQuirksMode);
經常使用的html5的寫法就是標準模式,若是連DOCType聲明也沒有呢?那麼會默認設置爲怪異模式:
void HTMLConstructionSite::setDefaultCompatibilityMode() {
setCompatibilityMode(Document::QuirksMode);
}
這些模式有什麼區別,從源碼註釋可窺探一二:
// There are three possible compatibility modes:
// Quirks - quirks mode emulates WinIE and NS4. CSS parsing is also relaxed in
// this mode, e.g., unit types can be omitted from numbers.
// Limited Quirks - This mode is identical to no-quirks mode except for its
// treatment of line-height in the inline box model.
// No Quirks - no quirks apply. Web pages will obey the specifications to the
// letter.
大意是說,怪異模式會模擬IE,同時CSS解析會比較寬鬆,例如數字單位能夠省略,而有限怪異模式和標準模式的惟一區別在於在於對inline元素的行高處理不同。標準模式將會讓頁面遵照文檔規定。
怪異模式下的input和textarea的默認盒模型將會變成border-box:
標準模式下的文檔高度是實際內容的高度:
而在怪異模式下的文檔高度是窗口可視域的高度:
在有限怪異模式下,div裏面的圖片下方不會留空白,以下圖左所示;而在標準模式下div下方會留點空白,以下圖右所示:
<div><img src="test.jpg" style="height:100px"></div>
這個空白是div的行高撐起來的,當把div的行高設置成0的時候,就沒有下面的空白了。在怪異模和有限怪異模式下,爲了計算行內子元素的最小高度,一個塊級元素的行高必須被忽略。
這裏的敘述雖然跟解讀源碼沒有直接的關係(咱們還沒解讀到CSS處理),可是頗有必要提一下。
接下來咱們開始正式說明DOM構建
(4)開標籤處理
下一個遇到的開標籤是<html>標籤,處理這個標籤的任務應該是實例化一個HTMLHtmlElement元素,而後把它的父元素指向document。Webkit源碼裏面使用了一個m_attachmentRoot的變量記錄attach的根結點,初始化HTMLConstructionSite也會初始化這個變量,值爲document:
HTMLConstructionSite::HTMLConstructionSite(
Document& document)
: m_document(&document),
m_attachmentRoot(document)) {
}
因此html結點的父結點就是document,實際的操做過程是這樣的:
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomicHTMLToken* token) {
HTMLHtmlElement* element = HTMLHtmlElement::create(*m_document);
attachLater(m_attachmentRoot, element);
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element, token));
executeQueuedTasks();
}
第二行先建立一個html結點,第三行把它加到一個任務隊列裏面,傳遞兩個參數,第一個參數是父結點,第二個參數是當前結點,第五行執行隊列裏面的任務。代碼第四行會把它壓到一個棧裏面,這個棧存放了未遇到閉標籤的全部開標籤。
第三行attachLater是如何創建一個task的:
void HTMLConstructionSite::attachLater(ContainerNode* parent,
Node* child,
bool selfClosing) {
HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert);
task.parent = parent;
task.child = child;
task.selfClosing = selfClosing;
// Add as a sibling of the parent if we have reached the maximum depth
// allowed.
if (m_openElements.stackDepth() > maximumHTMLParserDOMTreeDepth &&
task.parent->parentNode())
task.parent = task.parent->parentNode();
queueTask(task);
}
代碼邏輯比較簡單,比較有趣的是發現DOM樹有一個最大的深度:maximumHTMLParserDOMTreeDepth,超過這個最大深度就會把它子元素看成父無素的同級節點,這個最大值是多少呢?512:
static const unsigned maximumHTMLParserDOMTreeDepth = 512;
咱們重點關注executeQueuedTasks幹了些什麼,它會根據task的類型執行不一樣的操做,因爲本次是insert的,它會去執行一個插入的函數:
void ContainerNode::parserAppendChild(Node* newChild) {
if (!checkParserAcceptChild(*newChild))
return;
AdoptAndAppendChild()(*this, *newChild, nullptr);
}
notifyNodeInserted(*newChild, ChildrenChangeSourceParser);
}
在插入裏面它會先去檢查父元素是否支持子元素,若是不支持,則直接返回,就像video標籤不支持子元素。而後再去調具體的插入:
void ContainerNode::appendChildCommon(Node& child) {
child.setParentOrShadowHostNode(this);
if (m_lastChild) {
child.setPreviousSibling(m_lastChild);
m_lastChild->setNextSibling(&child);
} else {
setFirstChild(&child);
}
setLastChild(&child);
}
上面代碼第二行,設置子元素的父結點,也就是會把html結點的父結點指向document,而後若是沒有lastChild,會將這個子元素做爲firstChild,因爲上面已經有一個docype的子結點了,因此已經有lastChild了,所以會把這個子元素的previousSibling指向老的lastChild,老的lastChild的nexSibling指向它。最後倒數第二行再把子元素設置爲當前ContainerNode(即document)的lastChild。這樣就創建起了html結點的父子兄弟關係。
能夠看到,藉助上一次的m_lastChild創建起了兄弟關係。
這個時候你可能會有一個問題,爲何要用一個task隊列存放將要插入的結點呢,而不是直接插入呢?一個緣由是放到task裏面方便統一處理,而且有些task可能不能當即執行,要先存起來。不過在咱們這個案例裏面都是存完後下一步就執行了。
當遇到head標籤的token時,也是先建立一個head結點,而後再建立一個task,插到隊列裏面:
void HTMLConstructionSite::insertHTMLHeadElement(AtomicHTMLToken* token) {
m_head = HTMLStackItem::create(createHTMLElement(token), token);
attachLater(currentNode(), m_head->element());
m_openElements.pushHTMLHeadElement(m_head);
}
attachLater傳參的第一個參數爲父結點,這個currentNode爲開標籤棧裏面的最頂的元素:
ContainerNode* currentNode() const {
return m_openElements.topNode();
}
咱們剛剛把html元素壓了進去,則棧頂元素爲html元素,因此head的父結點就爲html。因此每當遇到一個開標籤時,就把它壓起來,下一次再遇到一個開標籤時,它的父元素就是上一個開標籤。
因此,初步能夠看到,藉助一個棧創建起了父子關係。
而當遇到一個閉標籤呢?
(5)處理閉標籤
當遇到一個閉標籤時,會把棧裏面的元素一直pop出來,直到pop到第一個和它標籤名字同樣的:
m_tree.openElements()->popUntilPopped(token->name());
咱們第一個遇到的是閉標籤是head標籤,它會把開的head標籤pop出來,棧裏面就剩下html元素了,因此當再遇到body時,html元素就是body的父元素了。
這個是棧的一個典型應用。
如下面的html爲例來研究壓棧和出棧的過程:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"></meta>
</head>
<body>
<div>
<p><b>hello</b></p>
<p>demo</p>
</div>
</body>
</html>
把push和pop打印出來是這樣的:
push "HTML" m_stackDepth = 1
push "HEAD" m_stackDepth = 2
pop "HEAD" m_stackDepth = 1
push "BODY" m_stackDepth = 2
push "DIV" m_stackDepth = 3
push "P" m_stackDepth = 4
push "B" m_stackDepth = 5
pop "B" m_stackDepth = 4
pop "P" m_stackDepth = 3
push "P" m_stackDepth = 4
pop "P" m_stackDepth = 3
pop "DIV" m_stackDepth = 2
"tagName: body |type: EndTag |attr: |text: "
"tagName: html |type: EndTag |attr: |text: "
這個過程確實和上面的描述一致,遇到一個閉標籤就把一次的開標籤pop出來。
而且能夠發現遇到body閉標籤後,並不會把body給pop出來,由於若是body閉標籤後面又再寫了標籤的話,就會自動當成body的子元素。
假設上面的b標籤的閉標籤忘記寫了,又會發生什麼:
<p><b>hello</p>
打印出來的結果是這樣的:
push "P" m_stackDepth = 4
push "B" m_stackDepth = 5
"tagName: p |type: EndTag |attr: |text: "
pop "B" m_stackDepth = 4
pop "P" m_stackDepth = 3
push "B" m_stackDepth = 4
push "P" m_stackDepth = 5
pop "P" m_stackDepth = 4
pop "B" m_stackDepth = 3
pop "DIV" m_stackDepth = 2
push "B" m_stackDepth = 3
一樣地,在上面第3行,遇到P閉標籤時,會把全部的開標籤pop出來,直到遇到P標籤。不一樣的是後續的過程當中會不斷地插入b標籤,最後渲染的頁面結構:
由於b等帶有格式化的標籤會特殊處理,遇到一個開標籤時會它們放到一個列表裏面:
// a, b, big, code, em, font, i, nobr, s, small, strike, strong, tt, and u.
m_activeFormattingElements.append(currentElementRecord()->stackItem());
遇到一個閉標籤時,又會從這個列表裏面刪掉。每處理一個新標籤時就會進行檢查和這個列表和棧裏的開標籤是否對應,若是不對應則會reconstruct:從新插入一個開標籤。所以b就不斷地被從新插入,直到遇到下一個b的閉標籤爲止。
若是上面少寫的是一個span,那麼渲染以後的結果是正常的:
而對於文本節點是實例化了Text的對象,這裏再也不展開討論。
(6)自定義標籤的處理
在瀏覽器裏面能夠看到,自定義標籤默認不會有任何的樣式,而且它默認是一個行內元素:
初步觀察它和span標籤的表現是同樣的:
在blink的源碼裏面,不認識的標籤默認會被實例化成一個HTMLUnknownElement,這個類對外提供了一個create函數,這和HTMLSpanElement是同樣的,只有一個create函數,而且你們都是繼承於HTMLElement。而且建立span標籤的時候和unknown同樣,並無作特殊處理,直接調的create。因此從本質上來講,能夠把自定義的標籤看成一個span看待。而後你能夠再設置display: block改爲塊級元素之類的。
可是你能夠用js定義一個自定義標籤,定義它的屬性等,Webkit會去讀它的定義:
// "4. Let definition be the result of looking up a custom element ..." etc.
CustomElementDefinition* definition =
m_isParsingFragment ? nullptr
: lookUpCustomElementDefinition(document, token);
例如給自定義標籤建立一個原生屬性:
<high-school country="China">NO. 2 high school</high-school>
上面定義了一個country,爲了能夠直接獲取這個屬性:
console.log(document.getElementsByTagName("high-school")[0].country);
註冊一個自定義標籤:
window.customElements.define("high-school", HighSchoolElement);
這個HighSchoolElement繼承於HTMLElement:
class HighSchoolElement extends HTMLElement{
constructor(){
super();
this._country = null;
}
get country(){
return this._country;
}
set country(country){
this.setAttribute("country", _country);
}
static get observedAttributes() {
return ["country"];
}
attributeChangedCallback(name, oldValue, newValue) {
this._country = newValue;
this._updateRender(name, oldValue, newValue);
}
_updateRender(name, oldValue, newValue){
console.log(name + " change from " + oldValue + " " + newValue);
}
}
就能夠直接取到contry這個屬性,而不用經過getAttribute的函數,而且能夠在屬性發生變化時更新元素的渲染,改變color等。詳見Custom Elements – W3C.
經過這種方式建立的,它就不是一個HTMLUnknownElement了。blink經過V8引擎把js的構造函數轉化成C++的函數,實例化一個HTMLElement的對象。
最後再來看查DOM的過程
4. 查DOM過程
(1)按ID查找
在頁面添加一個script:
<script>document.getElementById("text")</script>
Chrome的V8引擎把js代碼層層轉化,最後會調:
DocumentV8Internal::getElementByIdMethodForMainWorld(info);
而這個函數又會調TreeScope的getElementById的函數,TreeScope存儲了一個m_map的哈希map,這個map以標籤id字符串做爲key值,Element爲value值,咱們能夠把這個map打印出來:
Map::iterator it = m_map.begin();
while(it != m_map.end()){
LOG(INFO) << it->key << " " << it->value->element->tagName();
++it;
}
html結構是這樣的:
<div class="user" id="id-yin">
<p id="id-name" class="important">yin</p>
<p id="id-age">20</p>
<p id="id-sex">mail</p>
</div>
打印出來的結果爲:
"id-age" "P"
"id-sex" "P"
"id-name" "P"
"id-yin" "DIV"
能夠看到, 這個m_map把頁面全部有id的標籤都存了進來。因爲map的查找時間複雜度爲O(1),因此使用ID選擇器能夠說是最快的。
再來看一下類選擇器:
(2)類選擇器
js以下:
var users = document.getElementsByClassName("user");
users.length;
在執行第一行的時候,Webkit返回了一個ClassCollection的列表:
return new ClassCollection(rootNode, classNames);
而這個列表並非去查DOM獲取的,它只是記錄了className做爲標誌。這與咱們的認知是一致的,這種HTMLCollection的數據結構都是在使用的時候纔去查DOM,因此在上面第二行去獲取它的length,就會觸發它的查DOM,在nodeCount這個函數裏面執行:
NodeType* currentNode = collection.traverseToFirst();
unsigned currentIndex = 0;
while (currentNode) {
m_cachedList.push_back(currentNode);
currentNode = collection.traverseForwardToOffset(
currentIndex + 1, *currentNode, currentIndex);
}
第一行先獲取符合collection條件的第一個結點,而後不斷獲取下一個符合條件的結點,直到null,並把它存到一個cachedList裏面,下次再獲取這個collection的東西時便不用再重複查DOM,只要cached仍然是有效的:
if (this->isCachedNodeCountValid())
return this->cachedNodeCount();
怎麼樣找到有效的節點呢:
ElementType* element = Traversal<ElementType>::firstWithin(current);
while (element && !isMatch(*element))
element = Traversal<ElementType>::next(*element, ¤t, isMatch);
return element;
第一行先獲取第一個節點,若是它沒有match,則繼續next,直到找到符合條件或者空爲止。咱們的重點在於,它是怎麼遍歷的,如何next獲取下一個節點,核心代碼:
if (current.hasChildren())
return current.firstChild();
if (current == stayWithin)
return 0;
if (current.nextSibling())
return current.nextSibling();
return nextAncestorSibling(current, stayWithin);
第一行先判斷當前節點有沒有子元素,若是有的話返回它的第一個子元素,若是當前節點沒有子元素,而且這個節點就是開始找的根元素(用document.getElement*,則爲document),則說明沒有下一個元素了,直接返回0/null。若是這個節點不是根元素了(例如已經到了子元素這一層),那麼看它有沒有相鄰元素,若是有則返回下一個相鄰元素,若是相鄰無素也沒有了,因爲它是一個葉子結點(沒有子元素),說明它已經到了最深的一層,而且是當前層的最後一個葉子結點,那麼就返回它的父元素的下一個相鄰節點,若是這個也沒有了,則返回null,查找結束。能夠看出這是一個深度優先的查找。
(3)querySelector
a)先來看下selector爲一個id時發生了什麼:
document.querySelector("#id-name");
它會調ContainerNode的querySelecotr函數:
SelectorQuery* selectorQuery = document().selectorQueryCache().add(
selectors, document(), exceptionState);
return selectorQuery->queryFirst(*this);
先把輸入的selector字符串序列化成一個selectorQuery,而後再queryFirst,經過打斷點能夠發現,它最後會調的TreeScope的getElementById:
rootNode.treeScope().getElementById(idToMatch);
b)若是selector爲一個class:
document.querySelector(".user");
它會從document開始遍歷:
for (Element& element : ElementTraversal::descendantsOf(rootNode)) {
if (element.hasClass() && element.classNames().contains(className)) {
SelectorQueryTrait::appendElement(output, element);
if (SelectorQueryTrait::shouldOnlyMatchFirstElement)
return;
}
}
咱們重點查看它是怎麼遍歷,即第一行的for循環。表面上看它好像把全部的元素取出來而後作個循環,其實否則,它是重載++操做符:
void operator++() { m_current = TraversalNext::next(*m_current, m_root); }
只要咱們看下next是怎麼操做的就能夠得知它是怎麼遍歷,而這個next跟上面的講解class時是調的同一個next。不同的是match條件判斷是:有className,而且className列表裏面包含這個class,如上面代碼第二行。
c)複雜選擇器
例如寫兩個class:
document.querySelector(".user .important");
最終也會轉成一個遍歷,只是判斷是否match的條件不同:
for (Element& element : ElementTraversal::descendantsOf(*traverseRoot)) {
if (selectorMatches(selector, element, rootNode)) {
SelectorQueryTrait::appendElement(output, element);
if (SelectorQueryTrait::shouldOnlyMatchFirstElement)
return;
}
}
怎麼判斷是否match比較複雜,這裏再也不展開討論。
同時在源碼能夠看到,若是是怪異模式,會調一個executeSlow的查詢,而且判斷match條件也不同。不過遍歷是同樣的。
查看源碼確實是一件很費時費力的工做,可是經過一番探索,可以瞭解瀏覽器的一些內在機制,至少已經能夠回答上面提出來的幾個問題。同時知道了Webkit/Blink藉助一個棧,結合開閉標籤,一步步構建DOM樹,並對DOCType的標籤、自定義標籤的處理有了必定的瞭解。最後又討論了查DOM的幾種狀況,明白了查找的過程。
經過上面的分析,對頁面渲染的第一步構建DOM應該會有一個基礎的瞭解。
css
@import和link的區別是什麼?
href標識超文本引用,用在link和a等元素上,href是引用和頁面關聯,是在當前元素和引用資源之間創建聯繫 若在文檔中添加href ,瀏覽器會識別該文檔爲 CSS 文件,就會並行下載資源而且不會中止對當前文檔的處理。這也是爲何建議使用 link 方式加載 CSS,而不是使用 @import 方式。
用flex實現左右兩欄佈局,左欄有一個div,右側有兩個div
.container{
display: flex;
flex-direction: row;
width:100%;
}
.row{
flex:1;
display:flex;
}
.col{
width:100%;
}
<div class="container">
<div class="row">
<span class="col" style="background-color:red;">111</span>
</div>
<div class="row">
<span class="col" style="background-color:yellow;">222</span>
<span class="col" style="background-color:green;">333</span>
</div>
</div>
如何實現水平垂直居中?
- 絕對定位水平垂直居中
<div style="position: absolute;
width: 500px;
height: 300px;
margin: auto;
top: 0;
left: 0;
bottom: 0;
right: 0;
background-color: green;">水平垂直居中</div>
- 水平垂直居中
<div style="position: relative;
width:400px;
height:200px;
top: 50%;
left: 50%;
margin: -100px 0 0 -200px;
background-color: red;">水平垂直居中</div>
- 水平垂直居中
<div style="position: absolute;
width:300px;
height:200px;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
background-color: blue;">水平垂直居中</div>
- flex 佈局居中
<div style="display: flex;align-items: center;justify-content: center;">
<div style="width: 100px;height: 100px;background-color: gray;">flex 佈局</div>
</div>
原生js
如何實現es6中的const?
https://blog.csdn.net/Allan_L...vue
前言
剛剛看了掘金上一篇文章《做爲技術面試官,爲何把你pass了》,裏面第一題就是用es5實現const,據做者反饋 這一題全部的面試者都沒有回答出來,感受挺惋惜的,其實這是一道比較簡單的題目,可是因爲涉及到了一些Object對象屬性描述符的知識,這些描述符每每用到的場景很少,因此不容易記住。
屬性描述符:
對象裏目前的屬性描述符有兩種:
數據描述符:具備值的屬性
存取描述符:由getter與setter函數對描述的屬性
描述符功能:
數據描述符與存取描述符皆可修改:
configurable:當前對象元素的屬性描述符是否可改,是否可刪除
enumerable:當前對象元素是否可枚舉
惟有數據描述符能夠修改:
value: 當前對象元素的值
writable:當前對象元素的值是否可修改
惟有存取描述符能夠修改:
get:讀取元素屬性值時的操做
set:修改元素屬性值時的操做
描述符可同時具備的鍵值:
configurable enumerable value writable get set
數據描述符 Yes Yes Yes Yes No No
存取描述符 Yes Yes No No Yes Yes
const 實現原理
因爲ES5環境沒有block的概念,因此是沒法百分百實現const,只能是掛載到某個對象下,要麼是全局的window,要麼就是自定義一個object來當容器
var __const = function __const (data, value) {
window.data = value // 把要定義的data掛載到window下,並賦值value
Object.defineProperty(window, data, { // 利用Object.defineProperty的能力劫持當前對象,並修改其屬性描述符
enumerable: false,
configurable: false,
get: function () {
return value
},
set: function (data) {
if (data !== value) { // 當要對當前屬性進行賦值時,則拋出錯誤!
throw new TypeError('Assignment to constant variable.')
} else {
return value
}
}
})
}
__const('a', 10)
console.log(a)
delete a
console.log(a)
for (let item in window) { // 由於const定義的屬性在global下也是不存在的,因此用到了enumerable: false來模擬這一功能
if (item === 'a') { // 由於不可枚舉,因此不執行
console.log(window[item])
}
}
a = 20 // 報錯
複製代碼
題外話
Vue目前雙向綁定的核心實現思路就是利用Object.defineProperty對get跟set進行劫持,監聽用戶對屬性進行調用以及賦值時的具體狀況,從而實現的雙向綁定~~
實現一個方法,隨機打亂一個數組
function shuffle_simple(arr){
return arr.sort(()=>Math.random()- .5)
}
或html5
function fisher_yates_shuffle(arr){
for(let i=0;i<arr.length-1;i++){
const j=i+Math.floor(Math.random()*(arr.length-1));
[arr[i],[arr[j]]]=[arr[j],arr[i]]
}
return arr
}
或java
function shuffle(arr){
const m=[];
const N=arr.length*arr.length*arr.length;
for(let i=0;i<arr.length-1;i++){
m[i]=Math.floor(Math.random(1,N))
}
return arr.sort((i,j)=>m[i]-m[j])
}
請簡述一下原型和原型鏈
什麼是原型鏈:只要是對象就有原型, 而且原型也是對象, 所以只要定義了一個對象, 那麼就能夠找到他的原型, 如此反覆, 就能夠構成一個對象的序列, 這個結構就被稱爲原型鏈 全部的實例有一個內部指針(prototype),指向它的原型對象,而且能夠訪問原型對象上的全部屬性和方法。
如何判斷類型爲數組?
Object.prototype.toString.call()
請簡述一下深拷貝和淺拷貝
function clone(obj){
let newObj={};
for(let key in obj){
newObj[key]=obj[key];
}
return newObj;
}
簡版:node
function clone(obj){
if(obj===null){
return null
};
if({}.toString.call(obj)==='[object Array]'){
let newArr=[];
newArr=obj.slice();
return newArr;
};
let newObj={};
for(let key in obj){
if(typeof obj[key]!=='object'){
newObj[key]=obj[key];
}else{
newObj[key]=clone(obj[key]);
}
}
}
完整版:jquery
const clone = parent => {
const isType = (obj, type) => {
if (typeof obj !== "object") return false;
const typeString = Object.prototype.toString.call(obj);
let flag;
switch (type) {
case "Array":
flag = typeString === "[object Array]";
break;
case "Date":
flag = typeString === "[object Date]";
break;
case "RegExp":
flag = typeString === "[object RegExp]";
break;
default:
flag = false;
}
return flag;
};
const getRegExp = re => {
var flags = "";
if (re.global) flags += "g";
if (re.ignoreCase) flags += "i";
if (re.multiline) flags += "m";
return flags;
};
const parents = [];
const children = [];
const _clone = parent => {
if (parent === null) return null;
if (typeof parent !== "object") return parent;
let child, proto;
if (isType(parent, "Array")) {
child = [];
} else if (isType(parent, "RegExp")) {
child = new RegExp(parent.source, getRegExp(parent));
if (parent.lastIndex) child.lastIndex = parent.lastIndex;
} else if (isType(parent, "Date")) {
child = new Date(parent.getTime());
} else {
proto = Object.getPrototypeOf(parent);
child = Object.create(proto);
}
const index = parents.indexOf(parent);
if (index != -1) {
return children[index];
}
parents.push(parent);
children.push(child);
for (let i in parent) {
child[i] = _clone(parent[i]);
}
return child;
};
return _clone(parent);
};
call、bind和apply的區別
一、call,apply和bind的區別 它們在功能上是沒有區別的,都是改變this的指向,它們的區別主要是在於方法的實現形式和參數傳遞上的不一樣。call和apply方法都是在調用以後當即執行的。而bind調用以後是返回原函數,須要再調用一次才行, 二、①:函數.call(對象,arg1,arg2....) ②:函數.apply(對象,[arg1,arg2,...]) ③:var ss=函數.bind(對象,arg1,arg2,....) 三、總結一下call,apply,bind方法: a:第一個參數都是指定函數內部中this的指向(函數執行時所在的做用域),而後根據指定的做用域,調用該函數。 b:均可以在函數調用時傳遞參數。call,bind方法須要直接傳入,而apply方法須要以數組的形式傳入。 c:call,apply方法是在調用以後當即執行函數,而bind方法沒有當即執行,須要將函數再執行一遍。有點閉包的味道。 d:改變this對象的指向問題不只有call,apply,bind方法,也能夠使用that變量來固定this的指向。
JSON.parse(JSON.stringify)深拷貝須要注意什麼?
https://segmentfault.com/a/11...android
在js中,怎麼用一行代碼實現深拷貝?它能夠實現: JSON.parse(JSON.stringify(obj))。
這行代碼的運行過程,就是利用 JSON.stringify 將js對象序列化(JSON字符串),再使用JSON.parse來反序列化(還原)js對象;序列化的做用是存儲和傳輸。(對象自己存儲的是一個地址映射,若是斷電,對象將不存在,因此要將對象的內容轉換成字符串的形式再保存在磁盤上)
不過,這種實現深拷貝的方法有侷限性,它只適用於通常數據的拷貝(對象、數組),有如下狀況須要注意:
1.若是json裏面有時間對象,則序列化結果:時間對象=>字符串的形式;
{
let obj = {
age: 18,
date: new Date()
};
let objCopy = JSON.parse(JSON.stringify(obj));
console.log('obj', obj);
console.log('objCopy', objCopy);
console.log(typeof obj.date); // object
console.log(typeof objCopy.date); // string
}
clipboard.png
2.若是json裏有RegExp、Error對象,則序列化的結果將只獲得空對象 RegExp、Error => {};
{
let obj = {
age: 18,
reg: new RegExp('\\w+'),
err: new Error('error message')
};
let objCopy = JSON.parse(JSON.stringify(obj));
console.log('obj', obj);
console.log('objCopy', objCopy);
}
clipboard.png
3.若是json裏有 function,undefined,則序列化的結果會把 function,undefined 丟失;
{
let obj = {
age: 18,
fn: function () {
console.log('fn');
},
hh: undefined
};
let objCopy = JSON.parse(JSON.stringify(obj));
console.log('obj', obj);
console.log('objCopy', objCopy);
}
clipboard.png
4.若是json裏有NaN、Infinity和-Infinity,則序列化的結果會變成null;
{
let obj = {
age: 18,
hh: NaN,
isInfinite: 1.7976931348623157E+10308,
minusInfinity: -1.7976931348623157E+10308
};
let objCopy = JSON.parse(JSON.stringify(obj));
console.log('obj', obj);
console.log('objCopy', objCopy);
}
clipboard.png
5.若是json裏有對象是由構造函數生成的,則序列化的結果會丟棄對象的 constructor;
{
function Person(name) {
this.name = name;
}
let obj = {
age: 18,
p1: new Person('lxcan')
};
let objCopy = JSON.parse(JSON.stringify(obj));
console.log('obj', obj);
console.log('objCopy', objCopy);
console.log(obj.p1.__proto__.constructor === Person); // true
console.log(objCopy.p1.__proto__.constructor === Object); // true
}
clipboard.png
6.若是對象中存在循環引用的狀況也沒法實現深拷貝
{
let obj = {
age: 18
};
obj.obj = obj;
let objCopy = JSON.parse(JSON.stringify(obj));
console.log('obj', obj);
console.log('objCopy', objCopy);
}
clipboard.png
以上,若是拷貝的對象不涉及上面的狀況,能夠使用 JSON.parse(JSON.stringify(obj)) 實現深拷貝。
關於js深拷貝的相關知識以及更多解決方案,能夠閱讀這篇文章 深拷貝的終極探索(99%的人都不知道)
什麼是json安全?
JSON 對值的類型和格式有嚴格的規定。 複合類型的值只能是數組或對象,不能是函數、正則表達式對象、日期對象。 簡單類型的值只有四種:字符串、數值(必須以十進制表示)、布爾值和null(不能使用NaN, Infinity, -Infinity和undefined)。 字符串必須使用雙引號表示,不能使用單引號。 對象的鍵名必須放在雙引號裏面。 數組或對象最後一個成員的後面,不能加逗號。
請簡述一下你對閉包的理解,會有什麼問題?怎麼解決?
- 閉包是函數和聲明該函數的詞法環境的組合。(MDN定義) A clousure is the combination of a function and the lexical environment within which that function was declared. 注:離散數學中是對集合間關係的一種描述 - ECMAScript支持閉包,於是js中的閉包表現爲:外層函數調用後,外層函數變量被內層函數對象的[[scope]]引用着而致使外層函數的做用域對象AO沒法釋放(垃圾回收)); - js中閉包常見做用:<1>.實現共有變量,如:函數累加器;<2>.能夠作緩存(存儲結構);<3>.屬性私有化;<4>.模塊化開發,防止污染全局變量 - js閉包的缺點:比普通函數佔有更多內存(多的是外層函數做用域對象AO始終存在),容易形成內存泄漏
請簡述一下V8引擎的垃圾回收機制
https://segmentfault.com/a/11...
前言
咱們知道,JavaScript之因此能在瀏覽器環境和NodeJS環境運行,都是由於有V8引擎在幕後保駕護航。從編譯、內存分配、運行以及垃圾回收等整個過程,都離不開它。
在寫這篇文章以前,我也在網上看了不少博客,包括一些英文原版的內容,因而想經過這篇文章來作一個概括整理,文中加入了我本身的思考,以及純手工製做流程圖~~
但願這篇文章能幫到你,同時本文也會收錄到我本身的我的網站。
爲何要有垃圾回收
在C語言和C++語言中,咱們若是想要開闢一塊堆內存的話,須要先計算須要內存的大小,而後本身經過malloc函數去手動分配,在用完以後,還要時刻記得用free函數去清理釋放,不然這塊內存就會被永久佔用,形成內存泄露。
可是咱們在寫JavaScript的時候,卻沒有這個過程,由於人家已經替咱們封裝好了,V8引擎會根據你當前定義對象的大小去自動申請分配內存。
不須要咱們去手動管理內存了,因此天然要有垃圾回收,不然的話只分配不回收,豈不是沒多長時間內存就被佔滿了嗎,致使應用崩潰。
垃圾回收的好處是不須要咱們去管理內存,把更多的精力放在實現複雜應用上,但壞處也來自於此,不用管理了,就有可能在寫代碼的時候不注意,形成循環引用等狀況,致使內存泄露。
內存結構分配
因爲V8最開始就是爲JavaScript在瀏覽器執行而打造的,不太可能遇到使用大量內存的場景,因此它能夠申請的最大內存就沒有設置太大,在64位系統下大約爲1.4GB,在32位系統下大約爲700MB。
在NodeJS環境中,咱們能夠經過process.memoryUsage()來查看內存分配。
clipboard.png
process.memoryUsage返回一個對象,包含了 Node 進程的內存佔用信息。該對象包含四個字段,含義以下:
clipboard.png
rss(resident set size):全部內存佔用,包括指令區和堆棧
heapTotal:V8引擎能夠分配的最大堆內存,包含下面的 heapUsed
heapUsed:V8引擎已經分配使用的堆內存
external: V8管理C++對象綁定到JavaScript對象上的內存
以上全部內存單位均爲字節(Byte)。
若是說想要擴大Node可用的內存空間,能夠使用Buffer等堆外內存內存,這裏不詳細說明了,你們有興趣能夠去看一些資料。
下面是Node的總體架構圖,有助於你們理解上面的內容:
clipboard.png
Node Standard Library: 是咱們天天都在用的標準庫,如Http, Buffer 模塊
Node Bindings: 是溝通JS 和 C++的橋樑,封裝V8和Libuv的細節,向上層提供基礎API服務
第三層是支撐 Node.js 運行的關鍵,由 C/C++ 實現:
1. V8 是Google開發的JavaScript引擎,提供JavaScript運行環境,能夠說它就是 Node.js 的發動機
2. Libuv 是專門爲Node.js開發的一個封裝庫,提供跨平臺的異步I/O能力
3. C-ares:提供了異步處理 DNS 相關的能力
4. http_parser、OpenSSL、zlib 等:提供包括 http 解析、SSL、數據壓縮等其餘的能力
垃圾回收機制
如何判斷是否能夠回收
1.1 標記清除
當變量進入環境(例如,在函數中聲明一個變量)時,就將這個變量標記爲「進入環境」。從邏輯上講,永遠不能釋放進入環境的變量所佔用的內存,由於只要執行流進入相應的環境,就可能會用到它們。而當變量離開環境時,則將其標記爲「離開環境」。
能夠使用任何方式來標記變量。好比,能夠經過翻轉某個特殊的位來記錄一個變量什麼時候進入環境,或者使用一個「進入環境的」變量列表及一個「離開環境的」變量列表來跟蹤哪一個變量發生了變化。如何標記變量並不重要,關鍵在於採起什麼策略。
(1)垃圾收集器在運行的時候會給存儲在內存中的全部變量都加上標記(固然,能夠使用任何標記方式)。
(2)而後,它會去掉運行環境中的變量以及被環境中變量所引用的變量的標記
(3)此後,依然有標記的變量就被視爲準備刪除的變量,緣由是在運行環境中已經沒法訪問到這些變量了。
(4)最後,垃圾收集器完成內存清除工做,銷燬那些帶標記的值並回收它們所佔用的內存空間。
目前,IE、Firefox、Opera、Chrome和Safari的JavaScript實現使用的都是標記清除式的垃圾回收策略(或相似的策略),只不過垃圾收集的時間間隔互有不一樣。
clipboard.png
活動對象就是上面的root,若是不清楚活動對象的能夠先查一下資料,當一個對象和其關聯對象再也不經過引用關係被當前root引用了,這個對象就會被垃圾回收。
1.2 引用計數
引用計數的垃圾收集策略不太常見。含義是跟蹤記錄每一個值被引用的次數。當聲明瞭一個變量並將一個引用類型值賦給該變量時,則這個值的引用次數就是1。
若是同一個值又被賦給另外一個變量,則該值的引用次數加1。相反,若是包含對這個值引用的變量改變了引用對象,則該值引用次數減1。
當這個值的引用次數變成0時,則說明沒有辦法再訪問這個值了,於是就能夠將其佔用的內存空間回收回來。
這樣,當垃圾收集器下次再運行時,它就會釋放那些引用次數爲0的值所佔用的內存。
Netscape Navigator 3.0是最先使用引用計數策略的瀏覽器,但很快它就遇到了一個嚴重的問題:循環引用。
循環引用是指對象A中包含一個指向對象B的指針,而對象B中也包含一個指向對象A的引用,看個例子:
function foo () {
var objA = new Object();
var objB = new Object();
objA.otherObj = objB;
objB.anotherObj = objA;
}
這個例子中,objA和objB經過各自的屬性相互引用,也就是說,這兩個對象的引用次數都是2。
在採用標記清除策略的實現中,因爲函數執行後,這兩個對象都離開了做用域,所以這種相互引用不是問題。
但在採用引用次數策略的實現中,當函數執行完畢後,objA和objB還將繼續存在,由於它們的引用次數永遠不會是0。
加入這個函數被重複屢次調用,就會致使大量內存沒法回收。爲此,Netscape在Navigator 4.0中也放棄了引用計數方式,轉而採用標記清除來實現其垃圾回收機制。
還要注意的是,咱們大部分人時刻都在寫着循環引用的代碼,看下面這個例子,相信你們都這樣寫過:
var el = document.getElementById('#el');
el.onclick = function (event) {
console.log('element was clicked');
}
咱們爲一個元素的點擊事件綁定了一個匿名函數,咱們經過event參數是能夠拿到相應元素el的信息的。
你們想一想,這是否是就是一個循環引用呢?
el有一個屬性onclick引用了一個函數(其實也是個對象),函數裏面的參數又引用了el,這樣el的引用次數一直是2,即便當前這個頁面關閉了,也沒法進行垃圾回收。
若是這樣的寫法不少不少,就會形成內存泄露。咱們能夠經過在頁面卸載時清除事件引用,這樣就能夠被回收了:
var el = document.getElementById('#el');
el.onclick = function (event) {
console.log('element was clicked');
}
// ...
// ...
// 頁面卸載時將綁定的事件清空
window.onbeforeunload = function(){
el.onclick = null;
}
V8垃圾回收策略
自動垃圾回收有不少算法,因爲不一樣對象的生存週期不一樣,因此沒法只用一種回收策略來解決問題,這樣效率會很低。
因此,V8採用了一種代回收的策略,將內存分爲兩個生代:新生代(new generation)和老生代(old generation)。
新生代中的對象爲存活時間較短的對象,老生代中的對象爲存活時間較長或常駐內存的對象,分別對新老生代採用不一樣的垃圾回收算法來提升效率,對象最開始都會先被分配到新生代(若是新生代內存空間不夠,直接分配到老生代),新生代中的對象會在知足某些條件後,被移動到老生代,這個過程也叫晉升,後面我會詳細說明。
分代內存
默認狀況下,32位系統新生代內存大小爲16MB,老生代內存大小爲700MB,64位系統下,新生代內存大小爲32MB,老生代內存大小爲1.4GB。
新生代平均分紅兩塊相等的內存空間,叫作semispace,每塊內存大小8MB(32位)或16MB(64位)。
新生代
1. 分配方式
新生代存的都是生存週期短的對象,分配內存也很容易,只保存一個指向內存空間的指針,根據分配對象的大小遞增指針就能夠了,當存儲空間快要滿時,就進行一次垃圾回收。
2. 算法
新生代採用Scavenge垃圾回收算法,在算法實現時主要採用Cheney算法。
Cheney算法將內存一分爲二,叫作semispace,一塊處於使用狀態,一塊處於閒置狀態。
clipboard.png
處於使用狀態的semispace稱爲From空間,處於閒置狀態的semispace稱爲To空間。
我畫了一套詳細的流程圖,接下來我會結合流程圖來詳細說明Cheney算法是怎麼工做的。
垃圾回收在下面我統稱爲 GC(Garbage Collection)。
step1. 在From空間中分配了3個對象A、B、C
cheney-step1
step2. GC進來判斷對象B沒有其餘引用,能夠回收,對象A和C依然爲活躍對象
cheney-step1
step3. 將活躍對象A、C從From空間複製到To空間
cheney-step1
step4. 清空From空間的所有內存
cheney-step1
step5. 交換From空間和To空間
cheney-step1
step6. 在From空間中又新增了2個對象D、E
cheney-step1
step7. 下一輪GC進來發現對象D沒有引用了,作標記
cheney-step1
step8. 將活躍對象A、C、E從From空間複製到To空間
cheney-step1
step9. 清空From空間所有內存
cheney-step1
step10. 繼續交換From空間和To空間,開始下一輪
cheney-step1
經過上面的流程圖,咱們能夠很清楚的看到,進行From和To交換,就是爲了讓活躍對象始終保持在一塊semispace中,另外一塊semispace始終保持空閒的狀態。
Scavenge因爲只複製存活的對象,而且對於生命週期短的場景存活對象只佔少部分,因此它在時間效率上有優異的體現。Scavenge的缺點是隻能使用堆內存的一半,這是由劃分空間和複製機制所決定的。
因爲Scavenge是典型的犧牲空間換取時間的算法,因此沒法大規模的應用到全部的垃圾回收中。但咱們能夠看到,Scavenge很是適合應用在新生代中,由於新生代中對象的生命週期較短,偏偏適合這個算法。
3. 晉升
當一個對象通過屢次複製仍然存活時,它就會被認爲是生命週期較長的對象。這種較長生命週期的對象隨後會被移動到老生代中,採用新的算法進行管理。
對象重新生代移動到老生代的過程叫做晉升。
對象晉升的條件主要有兩個:
對象從From空間複製到To空間時,會檢查它的內存地址來判斷這個對象是否已經經歷過一次Scavenge回收。若是已經經歷過了,會將該對象從From空間移動到老生代空間中,若是沒有,則複製到To空間。總結來講,若是一個對象是第二次經歷從From空間複製到To空間,那麼這個對象會被移動到老生代中。
當要從From空間複製一個對象到To空間時,若是To空間已經使用了超過25%,則這個對象直接晉升到老生代中。設置25%這個閾值的緣由是當此次Scavenge回收完成後,這個To空間會變爲From空間,接下來的內存分配將在這個空間中進行。若是佔比太高,會影響後續的內存分配。
老生代
1. 介紹
在老生代中,存活對象佔較大比重,若是繼續採用Scavenge算法進行管理,就會存在兩個問題:
因爲存活對象較多,複製存活對象的效率會很低。
採用Scavenge算法會浪費一半內存,因爲老生代所佔堆內存遠大於新生代,因此浪費會很嚴重。
因此,V8在老生代中主要採用了Mark-Sweep和Mark-Compact相結合的方式進行垃圾回收。
2. Mark-Sweep
Mark-Sweep是標記清除的意思,它分爲標記和清除兩個階段。
與Scavenge不一樣,Mark-Sweep並不會將內存分爲兩份,因此不存在浪費一半空間的行爲。Mark-Sweep在標記階段遍歷堆內存中的全部對象,並標記活着的對象,在隨後的清除階段,只清除沒有被標記的對象。
也就是說,Scavenge只複製活着的對象,而Mark-Sweep只清除死了的對象。活對象在新生代中只佔較少部分,死對象在老生代中只佔較少部分,這就是兩種回收方式都能高效處理的緣由。
咱們仍是經過流程圖來看一下:
step1. 老生代中有對象A、B、C、D、E、F
clipboard.png
step2. GC進入標記階段,將A、C、E標記爲存活對象
clipboard.png
step3. GC進入清除階段,回收掉死亡的B、D、F對象所佔用的內存空間
clipboard.png
能夠看到,Mark-Sweep最大的問題就是,在進行一次清除回收之後,內存空間會出現不連續的狀態。這種內存碎片會對後續的內存分配形成問題。
若是出現須要分配一個大內存的狀況,因爲剩餘的碎片空間不足以完成這次分配,就會提早觸發垃圾回收,而此次回收是沒必要要的。
2. Mark-Compact
爲了解決Mark-Sweep的內存碎片問題,Mark-Compact就被提出來了。
Mark-Compact是標記整理的意思,是在Mark-Sweep的基礎上演變而來的。Mark-Compact在標記完存活對象之後,會將活着的對象向內存空間的一端移動,移動完成後,直接清理掉邊界外的全部內存。以下圖所示:
step1. 老生代中有對象A、B、C、D、E、F(和Mark—Sweep同樣)
clipboard.png
step2. GC進入標記階段,將A、C、E標記爲存活對象(和Mark—Sweep同樣)
clipboard.png
step3. GC進入整理階段,將全部存活對象向內存空間的一側移動,灰色部分爲移動後空出來的空間
clipboard.png
step4. GC進入清除階段,將邊界另外一側的內存一次性所有回收
clipboard.png
3. 二者結合
在V8的回收策略中,Mark-Sweep和Mark-Conpact二者是結合使用的。
因爲Mark-Conpact須要移動對象,因此它的執行速度不可能很快,在取捨上,V8主要使用Mark-Sweep,在空間不足以對重新生代中晉升過來的對象進行分配時,才使用Mark-Compact。
總結
V8的垃圾回收機制分爲新生代和老生代。
新生代主要使用Scavenge進行管理,主要實現是Cheney算法,將內存平均分爲兩塊,使用空間叫From,閒置空間叫To,新對象都先分配到From空間中,在空間快要佔滿時將存活對象複製到To空間中,而後清空From的內存空間,此時,調換From空間和To空間,繼續進行內存分配,當知足那兩個條件時對象會重新生代晉升到老生代。
老生代主要採用Mark-Sweep和Mark-Compact算法,一個是標記清除,一個是標記整理。二者不一樣的地方是,Mark-Sweep在垃圾回收後會產生碎片內存,而Mark-Compact在清除前會進行一步整理,將存活對象向一側移動,隨後清空邊界的另外一側內存,這樣空閒的內存都是連續的,可是帶來的問題就是速度會慢一些。在V8中,老生代是Mark-Sweep和Mark-Compact二者共同進行管理的。
會產生內存泄漏的操做有哪些?
https://www.jianshu.com/p/763...
1.背景介紹 什麼是內存泄漏 內存泄漏是指一塊被分配的內存既不能使用,又不能回收,直到瀏覽器進程結束。在C++中,由於是手動管理內存,內存泄漏是常常出現的事情。而如今流行的C#和Java等語言採用了自動垃圾回收方法管理內存,正常使用的狀況下幾乎不會發生內存泄漏。瀏覽器中也是採用自動垃圾回收方法管理內存,但因爲瀏覽器垃圾回收方法有bug,所以會產生內存泄漏。 2.知識剖析 2.一、js的回收機制 垃圾回收機制—GC Javascript具備自動垃圾回收機制(GC:Garbage Collecation),也就是說,執行環境會負責管理代碼執行過程當中使用的內存。 JavaScript垃圾回收的機制很簡單:找出再也不使用的變量,而後釋放掉其佔用的內存,可是這個過程不是實時的,由於其開銷比較大,因此垃圾回收系統(GC)會按照固定的時間間隔,週期性的執行。 到底哪一個變量是沒有用的?因此垃圾收集器必須跟蹤到底哪一個變量沒用,對於再也不有用的變量打上標記,以備未來收回其內存。用於標記的無用變量的策略可能因實現而有所區別,一般狀況下有兩種實現方式:標記清除和引用計數。引用計數不太經常使用,標記清除較爲經常使用。 2.二、標記清除 js中最經常使用的垃圾回收方式就是標記清除。當變量進入環境時,例如,在函數中聲明一個變量,就將這個變量標記爲「進入環境」。從邏輯上講,永遠不能釋放進入環境的變量所佔用的內存,由於只要執行流進入相應的環境,就可能會用到它們。而當變量離開環境時,則將其標記爲「離開環境」。 2.三、引用計數 引用計數的含義是跟蹤記錄每一個值被引用的次數。當聲明瞭一個變量並將一個引用類型值(function object array)賦給該變量時,則這個值的引用次數就是1。若是同一個值又被賦給另外一個變量,則該值的引用次數加1。相反,若是包含對這個值引用的變量又取得了另一個值,則這個值的引用次數減1。當這個值的引用次數變成0時,則說明沒有辦法再訪問這個值了,於是就能夠將其佔用的內存空間回收回來。這樣,當垃圾回收器下次再運行時,它就會釋放那些引用次數爲0的值所佔用的內存。 3.常見問題 JS哪些操做會形成內存泄漏? 4.解決方案 雖然JavaScript 會自動垃圾收集,可是若是咱們的代碼寫法不當,會讓變量一直處於「進入環境」的狀態,沒法被回收。下面列一下內存泄漏常見的幾種狀況。 4.一、意外的全局變量引發的內存泄漏 你能夠經過加上 'use strict' 啓用嚴格模式來避免這類問題, 嚴格模式會阻止你建立意外的全局變量. 4.二、閉包引發的內存泄漏 閉包能夠維持函數內局部變量,使其得不到釋放。 上例定義事件回調時,因爲是函數內定義函數,而且內部函數--事件回調的引用外暴了,造成了閉包 解決之道,將事件處理函數定義在外部,解除閉包,或者在定義事件處理函數的外部函數中,刪除對dom的引用 4.三、沒有清理的DOM元素引用 雖然咱們用removeChild移除了button, 可是還在elements對象裏保存着#button的引用,換言之, DOM元素還在內存裏面 4.四、被遺忘的定時器或者回調 這樣的代碼很常見, 若是 id 爲 Node 的元素從 DOM 中移除, 該定時器仍會存在, 同時, 由於回調函數中包含對 someResource 的引用, 定時器外面的 someResource 也不會被釋放. 4.五、子元素存在引用引發的內存泄漏 黃色是指直接被 js變量所引用,在內存裏,紅色是指間接被 js變量所引用,如上圖,refB 被 refA 間接引用,致使即便 refB 變量被清空,也是不會被回收的子元素 refB 因爲 parentNode 的間接引用,只要它不被刪除,它全部的父元素(圖中紅色部分)都不會被刪除。 5.擴展思考 IE7/8引用計數使用循環引用產生的問題。 fn()執行完畢後,兩個對象都已經離開環境,在標記清除方式下是沒有問題的,可是在引用計數策略下,由於a和b的引用次數不爲0,因此不會被垃圾回收器回收內存,若是fn函數被大量調用,就會形成內存泄漏。在IE7與IE8上,內存直線上升。 IE中有一部分對象並非原生js對象。例如,其內存泄漏DOM和BOM中的對象就是使用C++以COM對象的形式實現的,而COM對象的垃圾回收機制採用的就是引用計數策略。所以,即便IE的js引擎採用標記清除策略來實現,但js訪問的COM對象依然是基於引用計數策略的。換句話說,只要在IE中涉及COM對象,就會存在循環引用的問題。 上面的例子在一個DOM元素(element)與一個原生js對象(myObject)之間建立了循環引用。其中,變量myObject有一個名爲e的屬性指向element對象;而變量element也有一個屬性名爲o回指myObject。因爲存在這個循環引用,即便例子中的DOM從頁面中移除,它也永遠不會被回收。 看上面的例子,有人會以爲太弱了,誰會作這樣無聊的事情,可是其實咱們常常會這樣作 這段代碼看起來沒什麼問題,可是obj引用了document.getElementById(「element」),而document.getElementById(「element」)的onclick方法會引用外部環境中的變量,天然也包括obj,是否是很隱蔽啊。 最簡單的解決方式就是本身手工解除循環引用,好比剛纔的函數能夠這樣 將變量設置爲null意味着切斷變量與它此前引用的值之間的鏈接。當垃圾回收器下次運行時,就會刪除這些值並回收它們佔用的內存。 要注意的是,IE9+並不存在循環引用致使Dom內存泄漏問題,多是微軟作了優化,或者Dom的回收方式已經改變 6.參考文獻 javascript的垃圾回收機制與內存管理 js內存泄漏常見的四種狀況 7.更多討論 7.一、如何分析JS內存使用狀況 Google Chrome瀏覽器提供了很是強大的JS調試工具,Memory 視圖 profiles 視圖讓你能夠對 JavaScript 代碼運行時的內存進行快照,而且能夠比較這些內存快照。它還讓你能夠記錄一段時間內的內存分配狀況。在每個結果視圖中均可以展現不一樣類型的列表,可是對咱們最有用的是 summary 列表和 comparison 列表。 summary 視圖提供了不一樣類型的分配對象以及它們的合計大小:shallow size (一個特定類型的全部對象的總和)和 retained size (shallow size 加上保留此對象的其它對象的大小)。distance 顯示了對象到達 GC 根(校者注:最初引用的那塊內存,具體內容可自行搜索該術語)的最短距離。 comparison 視圖提供了一樣的信息可是容許對比不一樣的快照。這對於找到泄漏頗有幫助。 7.二、Chrome開發者工具初窺-Profiles面板 7.三、你能想哪些避免內存泄漏的姿式 1.減小沒必要要的全局變量,或者生命週期較長的對象,及時對無用的數據進行垃圾回收 2.注意程序邏輯,避免「死循環」之類的 3.避免建立過多的對象 原則:不用了的東西要及時歸還。
web端H5頁面如何和ios端和android端交互?如何處理返回回來的回調函數?
https://blog.csdn.net/zgd8262...
這裏寫自定義目錄標題
1、寫在前面
2、H5 端代碼
一、初始化 `WebViewJavascriptBridge`
二、註冊與原生交互的事件函數
三、調用原生註冊的事件函數
3、IOS 端代碼
一、引入 WebViewJavascriptBridge
直接使用方式
Cocopad 使用方式
二、初始化 WebViewJavascriptBridge
三、註冊與 H5 端交互的事件函數
四、調用 H5 端事件函數
4、Android 端代碼
一、引入 BridgeWebView
二、初始化 BridgeWebView
在 `activity_main.xml` 文件中添加布局
在 MainActivity 中初始化 BridgeWebView
三、註冊與 H5 交互的事件函數
四、調用 H5 端事件函數
五、添加網絡權限
5、參考連接
6、Demo 地址
**[jsbridge-example](https://github.com/beichensky/jsbridge-example)**
本文詳細講述瞭如何使用 JSBridge 在 H5 和原生 Android、IOS之間進行交互。IOS 端包含 OC 和 Swift 的版本,Android 端包含 Java 和 Kotlin 版本。
1、寫在前面
本文主要是經過代碼講述瞭如何使用 JSBridge 在 H5 和 原生之間進行通訊。文中包含 H五、IOS、Android 三部分的代碼。
IOS 中使用 OC 和 Swift 分別進行了代碼實現。Android 中使用 Java 和 Kotlin 分別進行了代碼實現。
Demo 地址:jsbridge-example
JSBridgeH5:H5 端代碼實現
JSBridgeIOSOC:原生 IOS 端 OC 代碼實現
JSBridgeIOSSwift:原生 IOS 端 Swift 代碼實現
JSBridgeAndroidJava:原生 Android 端 Java 代碼實現
JSBridgeAndroidKotlin:原生 IOS 端 Kotlin 代碼實現
本文沒有講解關於原理的部分,只是詳細使用代碼介紹了 JSBridge 的使用。想要了解原理的朋友,能夠另行搜索關於原理的博客。
2、H5 端代碼
初始化 WebViewJavascriptBridge,方式代碼以下
註冊供原生調用的事件函數:
window.setupWebViewJavascriptBridge(bridge => bridge.registerHandler('fnName', function) )
調用原生事件函數:
window.setupWebViewJavascriptBridge(bridge => bridge.callHandler('fnName', data, callback) )
一、初始化 WebViewJavascriptBridge
在項目入口文件或者根 js 文件下,添加如下代碼:
// 這裏根據移動端原生的 userAgent 來判斷當前是 Android 仍是 ios
const u = navigator.userAgent;
// Android終端
const isAndroid = u.indexOf('Android') > -1 || u.indexOf('Adr') > -1;
// IOS 終端
const isIOS = !!u.match(/\(i[^;]+;( U;)? CPU.+Mac OS X/);
/**
* 配合 IOS 使用時的初始化方法
*/
const iosFunction = (callback) => {
if (window.WebViewJavascriptBridge) { return callback(window.WebViewJavascriptBridge) }
if (window.WVJBCallbacks) { return window.WVJBCallbacks.push(callback) }
window.WVJBCallbacks = [callback];
var WVJBIframe = document.createElement('iframe');
WVJBIframe.style.display = 'none';
WVJBIframe.src = 'wvjbscheme://__BRIDGE_LOADED__';
document.documentElement.appendChild(WVJBIframe);
setTimeout(function(){
document.documentElement.removeChild(WVJBIframe);
}, 0);
}
/**
* 配合 Android 使用時的初始化方法
*/
const androidFunction = (callback) => {
if (window.WebViewJavascriptBridge) {
callback(window.WebViewJavascriptBridge);
} else {
document.addEventListener('WebViewJavascriptBridgeReady', function () {
callback(window.WebViewJavascriptBridge);
}, false)
}
}
window.setupWebViewJavascriptBridge = isAndroid ? androidFunction : iosFunction;
isAndroid && window.setupWebViewJavascriptBridge(function (bridge) {
// 註冊 H5 界面的默認接收函數(與安卓交互時,安卓端能夠不調用函數名,直接 send 數據過來,就可以在這裏接收到數據)
bridge.init(function (msg, responseCallback) {
console.log(msg);
responseCallback("JS 返回給原生的消息內容");
})
});
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
二、註冊與原生交互的事件函數
/*
window.setupWebViewJavascriptBridge(bridge => {
bridge.registerHandler('事件函數名',fun 執行函數);
})
*/
window.setupWebViewJavascriptBridge(bridge => {
/**
* data:原生傳過來的數據
* fn: 原生傳過來的回調函數
*/
bridge.registerHandler("H5Function", (data, fn) => {
console.log(data);
fn && fn();
});
});
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
三、調用原生註冊的事件函數
調用原生註冊的時間函數時使用以下的代碼:
/*
window.setupWebViewJavascriptBridge(bridge => {
bridge.callHandler('安卓端函數名', "傳給原生端的數據", callback 回調函數);
})
*/
window.setupWebViewJavascriptBridge(bridge => {
bridge.callHandler('changeData', data, (result) => {
console.log(result);
});
})
1
2
3
4
5
6
7
8
9
10
3、IOS 端代碼
初始化 WebViewJavascriptBridge:
+ (instancetype)bridgeForWebView:(id)webView;
+ (instancetype)bridge:(id)webView;
1
2
註冊與 H5 端交互的事件函數:
- (void)registerHandler:(NSString*)handlerName handler:(WVJBHandler)handler;
調用 H5 端事件函數:
- (void)callHandler:(NSString*)handlerName;
- (void)callHandler:(NSString*)handlerName data:(id)data;
- (void)callHandler:(NSString*)handlerName data:(id)data responseCallback:(WVJBResponseCallback)responseCallback;
1
2
3
一、引入 WebViewJavascriptBridge
直接使用方式
下載 WebViewJavascriptBridge
找到 WebViewJavascriptBridge文件夾,直接拖入到 XCode 項目中,在提示的彈窗中選擇 Copy items if needed 和 Create groups,以下圖:
在 ViewController.h 頭文件中引入 #import "WebViewJavascriptBridge.h" 便可
Cocopad 使用方式
如必須使用這種方式請自行 Google。
二、初始化 WebViewJavascriptBridge
// 啓用 WebViewJavascriptBridge Log
[WebViewJavascriptBridge enableLogging];
// 初始化 WKWebViewConfiguration 對象
self.webConfig = [[WKWebViewConfiguration alloc] init];
// 設置偏好設置
_webConfig.preferences = [[WKPreferences alloc] init];
// 默認爲0
_webConfig.preferences.minimumFontSize = 10;
// 默認認爲YES
_webConfig.preferences.javaScriptEnabled = YES;
// 在iOS上默認爲NO,表示不能自動經過窗口打開
_webConfig.preferences.javaScriptCanOpenWindowsAutomatically = NO;
// TODO: 請替換成頁面的 url 地址
NSString *URLSTR = @"http://xxx.xxx.xxx.xx:xxxx";
self.webView = [[WKWebView alloc] initWithFrame:self.view.bounds configuration:_webConfig];
// 設置 UserAgent 後綴
_webView.customUserAgent = [NSString stringWithFormat:self.webView.customUserAgent, @"app"];
_webView.UIDelegate = self;
_webView.navigationDelegate = self;
NSURL *url = [NSURL URLWithString:URLSTR];
NSURLRequest *urlRequest = [NSURLRequest requestWithURL:url];
[_webView loadRequest:urlRequest];
[self.view addSubview:_webView];
self.bridge = [WebViewJavascriptBridge bridgeForWebView:self.webView];
[_bridge setWebViewDelegate:self];
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
三、註冊與 H5 端交互的事件函數
// 例:註冊修改 User 名稱的 changeUser 函數
[self.bridge registerHandler:@"changeUser" handler:^(id data, WVJBResponseCallback responseCallback) {
// 在這裏處理邏輯
NSLog(@"JS 傳過來的數據%@", data);
if (responseCallback) {
// 執行回調函數
responseCallback(@"返回給 JS 的數據");
}
}];
1
2
3
4
5
6
7
8
9
四、調用 H5 端事件函數
// 調用 H5 界面的 changeName 事件函數
[self.bridge callHandler:@"changeName" data:name responseCallback:^(id responseData) {
NSLog(@"JS 調用 OC 回調函數返回的值:%@", responseData);
}];
1
2
3
4
4、Android 端代碼
註冊與 H5 交互的事件函數:
public void registerHandler(String handlerName, BridgeHandler handler) {
if (handler != null) {
messageHandlers.put(handlerName, handler);
}
}
1
2
3
4
5
調用 H5 端事件函數
public void callHandler(String handlerName, String data, CallBackFunction callBack) {
doSend(handlerName, data, callBack);
}
1
2
3
註冊與 H5 交互的默認事件,即 H5 端不調用函數名,直接使用 send 函數傳遞數據,安卓端也能夠在這個事件中接收到數據
// 設置默認接收函數
public void setDefaultHandler(BridgeHandler handler) {
this.defaultHandler = handler;
}
1
2
3
4
調用 H5 端註冊的默認事件函數
@Override
public void send(String data, CallBackFunction responseCallback) {
doSend(null, data, responseCallback);
}
1
2
3
4
一、引入 BridgeWebView
在項目的 build.gradle 文件中添加以下代碼:
buildTypes {
// ...
repositories {
// ...
maven { url "https://jitpack.io" }
}
}
1
2
3
4
5
6
7
添加依賴:implementation 'com.github.lzyzsd:jsbridge:1.0.4'
二、初始化 BridgeWebView
在 activity_main.xml 文件中添加布局
<com.github.lzyzsd.jsbridge.BridgeWebView
android:id="@+id/main_wv"
android:layout_width="match_parent"
android:layout_height="match_parent">
</com.github.lzyzsd.jsbridge.BridgeWebView>
1
2
3
4
5
在 MainActivity 中初始化 BridgeWebView
mWebView = findViewById(R.id.main_wv);
mWebView.getSettings().setAllowFileAccess(true);
mWebView.getSettings().setAppCacheEnabled(true);
mWebView.getSettings().setDatabaseEnabled(true);
// 開啓 localStorage
mWebView.getSettings().setDomStorageEnabled(true);
// 設置支持javascript
mWebView.getSettings().setJavaScriptEnabled(true);
// 進行縮放
mWebView.getSettings().setBuiltInZoomControls(true);
// 設置UserAgent
mWebView.getSettings().setUserAgentString(mWebView.getSettings().getUserAgentString() + "app");
// 設置不用系統瀏覽器打開,直接顯示在當前WebView
mWebView.setWebChromeClient(new WebChromeClient());
mWebView.setWebViewClient(new MyWebViewClient(mWebView));
mWebView.loadUrl(URL);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
三、註冊與 H5 交互的事件函數
// 默認事件函數
mWebView.setDefaultHandler(new BridgeHandler() {
@Override
public void handler(String data, CallBackFunction function) {
Toast.makeText(MainActivity.this, data, Toast.LENGTH_LONG).show();
function.onCallBack("安卓返回給 JS 的消息內容");
}
});
// 普通事件函數
mWebView.registerHandler("reloadUrl", new BridgeHandler() {
@Override
public void handler(String data, CallBackFunction function) {
mWebView.reload();
Toast.makeText(MainActivity.this, "刷新成功~", Toast.LENGTH_SHORT).show();
function.onCallBack("");
}
});
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
四、調用 H5 端事件函數
// 調用 H5 端默認事件函數
mWebView.send("安卓傳遞給 JS 的消息", new CallBackFunction() {
@Override
public void onCallBack(String data) {
Toast.makeText(MainActivity.this, data, Toast.LENGTH_LONG).show();
}
});
// 調用 H5 端普通事件函數
mWebView.callHandler("changeName", mEditName.getText().toString(), new CallBackFunction() {
@Override
public void onCallBack(String data) {
Toast.makeText(MainActivity.this, "name 修改爲功", Toast.LENGTH_SHORT).show();
mEditName.setText("");
}
});
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
五、添加網絡權限
這一步是必須的,不然的話, WebView 加載不出來,手機界面會提示 Webpage not available。
在 AndroidManifest.xml 清單文件中添加:
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" />
1
2
3
添加了權限以後,網頁可能仍是加載不出來,多是由於對未加密的流量不信任,在 AndroidManifest.xml 的 application 中添加一個屬性:android:usesCleartextTraffic="true"。以下:
<?xml version="1.0" encoding="utf-8"?>
<manifest ...>
<application
...
android:usesCleartextTraffic="true">
...
</application>
</manifest>
1
2
3
4
5
6
7
8
5、參考連接
JsBridge
WebViewJavascriptBridge
iOS開發-WKWebView設置cookie
iOS相似Android上toast效果
6、Demo 地址
jsbridge-example
若是有所幫助,歡迎 Star!
瀏覽器存儲有哪些?它們的區別是什麼?
(1)Local Storage (2)Session Storage (3)IndexedDB (4)Web SQL (5)Cookie
- 相同點:都存儲在客戶端
- 不一樣點:
- 存儲大小:
- cookie數據大小不能超過4k
- sessionStorage和localStorage雖然也有存儲大小的限制,但比cookie大的多,能夠達到5M或更大,就是爲了解決cookie存儲空間不足而誕生的
- 有限時間:
- localStorage存儲持久數據,瀏覽器關閉後數據不丟失除非主動刪除數據
- sessionStorage數據在當前瀏覽器窗口關閉後自動刪除
- cookie設置的cookie過時時間以前一直有效,即便窗口或瀏覽器關閉
- 數據域服務器之間的交互方式
- cookie的數據會自動的傳遞到服務器,服務器端也能夠寫cookie到客戶端
- sessionStorage和localStorage不會自動把數據發給服務器,僅在本地保存
客戶端能夠更改cookie嗎?服務器端能夠更改cookie嗎?
https://blog.csdn.net/qq_3920...
在客戶端(document.cookie)添加或修改cookie
Cookie的來源
因爲HTTP協議是無狀態的,而服務器端的業務必須是要有狀態的。Cookie誕生的最初目的是爲了存儲web中的狀態信息,以方便服務器端使用。好比判斷用戶是不是第一次訪問網站。目前最新的規範是RFC 6265,它是一個由瀏覽器服務器共同協做實現的規範。
Cookie的處理分爲:
服務器像客戶端發送cookie
瀏覽器將cookie保存
以後每次http請求瀏覽器都會將cookie發送給服務器端
服務器端的發送與解析
發送cookie
服務器端像客戶端發送Cookie是經過HTTP響應報文實現的,在Set-Cookie中設置須要像客戶端發送的cookie,cookie格式以下:
Set-Cookie: 「name=value;domain=.domain.com;path=/;expires=Sat, 11 Jun 2016 11:29:42 GMT;HttpOnly;secure」
其中name=value是必選項,其它都是可選項。Cookie的主要構成以下:
name:一個惟一肯定的cookie名稱。一般來說cookie的名稱是不區分大小寫的。
value:存儲在cookie中的字符串值。最好爲cookie的name和value進行url編碼
domain:cookie對於哪一個域是有效的。全部向該域發送的請求中都會包含這個cookie信息。這個值能夠包含子域(如:yq.aliyun.com),也能夠不包含它(如:.aliyun.com,則對於aliyun.com的全部子域都有效).
path: 表示這個cookie影響到的路徑,瀏覽器跟會根據這項配置,像指定域中匹配的路徑發送cookie。
expires:失效時間,表示cookie什麼時候應該被刪除的時間戳(也就是,什麼時候應該中止向服務器發送這個cookie)。若是不設置這個時間戳,瀏覽器會在頁面關閉時即將刪除全部cookie;不過也能夠本身設置刪除時間。這個值是GMT時間格式,若是客戶端和服務器端時間不一致,使用expires就會存在誤差。
max-age: 與expires做用相同,用來告訴瀏覽器此cookie多久過時(單位是秒),而不是一個固定的時間點。正常狀況下,max-age的優先級高於expires。
HttpOnly: 告知瀏覽器不容許經過腳本document.cookie去更改這個值,一樣這個值在document.cookie中也不可見。但在http請求張仍然會攜帶這個cookie。注意這個值雖然在腳本中不可獲取,但仍然在瀏覽器安裝目錄中以文件形式存在。這項設置一般在服務器端設置。
secure: 安全標誌,指定後,只有在使用SSL連接時候才能發送到服務器,若是是http連接則不會傳遞該信息。就算設置了secure 屬性也並不表明他人不能看到你機器本地保存的 cookie 信息,因此不要把重要信息放cookie就對了
1
2
3
4
5
6
7
8
9
服務器端設置cookie示例
var http = require('http');
var fs = require('fs');
http.createServer(function(req, res) {
res.setHeader('status', '200 OK');
res.setHeader('Set-Cookie', 'isVisit=true;domain=.yourdomain.com;path=/;max-age=1000');
res.write('Hello World');
res.end();
}).listen(8888);
console.log('running localhost:8888')
1
2
3
4
5
6
7
8
9
10
11
1
2
3
4
5
6
7
8
9
10
11
這裏寫圖片描述
這裏寫圖片描述
直接設置Set-Cookie過於原始,咱們能夠對cookie的設置過程作以下封裝:
var serilize = function(name, val, options) {
if (!name) {
throw new Error("coolie must have name");
}
var enc = encodeURIComponent;
var parts = [];
val = (val !== null && val !== undefined) ? val.toString() : "";
options = options || {};
parts.push(enc(name) + "=" + enc(val));
// domain中必須包含兩個點號
if (options.domain) {
parts.push("domain=" + options.domain);
}
if (options.path) {
parts.push("path=" + options.path);
}
// 若是不設置expires和max-age瀏覽器會在頁面關閉時清空cookie
if (options.expires) {
parts.push("expires=" + options.expires.toGMTString());
}
if (options.maxAge && typeof options.maxAge === "number") {
parts.push("max-age=" + options.maxAge);
}
if (options.httpOnly) {
parts.push("HTTPOnly");
}
if (options.secure) {
parts.push("secure");
}
return parts.join(";");
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
須要注意的是,若是給cookie設置一個過去的時間,瀏覽器會當即刪除該cookie;此外domain項必須有兩個點,所以不能設置爲localhost:
something that wasn’t made clear to me here and totally confused me for a while was that domain names must contain at least two dots (.),hence ‘localhost’ is invalid and the browser will refuse to set the cookie!
服務器端解析cookie
cookie能夠設置不一樣的域與路徑,因此對於同一個name value,在不一樣域不一樣路徑下是能夠重複的,瀏覽器會按照與當前請求url或頁面地址最佳匹配的順序來排定前後順序
這裏寫圖片描述
因此當前端傳遞到服務器端的cookie有多個重複name value時,咱們只須要最匹配的那個,也就是第一個。服務器端解析代碼以下:
var parse = function(cstr) {
if (!cstr) {
return null;
}
var dec = decodeURIComponent;
var cookies = {};
var parts = cstr.split(/\s*;\s*/g);
parts.forEach(function(p){
var pos = p.indexOf('=');
// name 與value存入cookie以前,必須通過編碼
var name = pos > -1 ? dec(p.substr(0, pos)) : p;
var val = pos > -1 ? dec(p.substr(pos + 1)) : null;
//只須要拿到最匹配的那個
if (!cookies.hasOwnProperty(name)) {
cookies[name] = val;
}/* else if (!cookies[name] instanceof Array) {
cookies[name] = [cookies[name]].push(val);
} else {
cookies[name].push(val);
}*/
});
return cookies;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
先後端跨域發送cookie的問題
1.jquery ajax
$.ajax({
url: '本身要請求的url',
method:'請求方式', //GET POST PUT DELETE
xhrFields:{withCredentials:true},
success:function(data){
//自定義請求成功作什麼
},
error:function(){
//自定義請求失敗作什麼
}
})
2.angular.js
$http.get(url, {withCredentials: true});
$http.post(url,data, {withCredentials: true});
後臺:java spring
response().setHeader("Access-Control-Allow-Credentials", "true");
response().setHeader("Access-Control-Allow-Origin", "login.com");
注意,這裏login.com 不能設置爲 * 來容許所有,若是在 Credentials 是true 的狀況下。由於瀏覽器會報錯以下:
A wildcard '*' cannot be used in the 'Access-Control-Allow-Origin' header when the credentials flag is true. Origin 'http://10.0.0.3:18080' is therefore not allowed access
因此要設置成客戶端頁面的 域名。
3.vue-cli能夠經過配置代理來解決跨域的問題:
proxyTable: {
'/list': {
target: 'http://api.xxxxxxxx.com',
changeOrigin: true,
pathRewrite: {
'^/list': '/list'
}
}
}
1
2
3
4
5
6
7
8
9
10
具體能夠看這篇文章:Vue-cli proxyTable 解決開發環境的跨域問題
假如不用代理,那須要怎樣設置呢?
最簡單的方法是服務端將響就頭設置成Access-Control-Allow-Origin:域名,若是客戶端發送請求時,不須要攜帶cookie等信息,能夠設置成Access-Control-Allow-Origin:*,表示任何域均可以向服務端發送請求,客戶端不須要任何配置,就能夠進行跨域調試了。
可是通常的網站,都須要向後端發送cookie來進行身份驗證,此時,服務器還需向響應頭設置Access-Control-Allow-Credentials:true,表示跨域時,容許cookie添加到請求中。設置Access-Control-Allow-Credentials:true後,要將Access-Control-Allow-Origin指定到具體的域,不然cookie不會帶到客戶端,例如設置成Access-Control-Allow-Origin:http://192.168.0.1:8088,http://192.168.0.1:8088是前端服務器的域名,這就要求用webpack的時候,要指定具體的域來啓動,不要直接用localhost。
要向後端發送cookie,前端也須要有相應的配置。我在項目中,引用了fetch的polyfill,直接用fetch來發送ajax請求,須要將credentials設置成include,表示容許跨越傳遞cookie,不要將credentials設置成same-origin,若是設置成same-origin,只會在同源的時候發送cookie。另外還要將withCredentials設爲true。
客戶端的存取
瀏覽器將後臺傳遞過來的cookie進行管理,而且容許開發者在JavaScript中使用document.cookie來存取cookie。可是這個接口使用起來很是蹩腳。它會由於使用它的方式不一樣而表現出不一樣的行爲。
當用來獲取屬性值時,document.cookie返回當前頁面可用的(根據cookie的域、路徑、失效時間和安全設置)全部的字符串,字符串的格式以下:
「name1=value1;name2=value2;name3=value3」;
當用來設置值的時候,document.cookie屬性可設置爲一個新的cookie字符串。這個字符串會被解釋並添加到現有的cookie集合中。如:
document.cookie = "_fa=aaaffffasdsf;domain=.dojotoolkit.org;path=/"
1
2
設置document.cookie並不會覆蓋cookie,除非設置的name value domain path都與一個已存在cookie重複。
因爲cookie的讀寫很是不方便,咱們能夠本身封裝一些函數來處理cookie,主要是針對cookie的添加、修改、刪除。
var cookieUtils = {
get: function(name){
var cookieName=encodeURIComponent(name) + "=";
//只取得最匹配的name,value
var cookieStart = document.cookie.indexOf(cookieName);
var cookieValue = null;
if (cookieStart > -1) {
// 從cookieStart算起
var cookieEnd = document.cookie.indexOf(';', cookieStart);
//從=後面開始
if (cookieEnd > -1) {
cookieValue = decodeURIComponent(document.cookie.substring(cookieStart + cookieName.length, cookieEnd));
} else {
cookieValue = decodeURIComponent(document.cookie.substring(cookieStart + cookieName.length, document.cookie.length));
}
}
return cookieValue;
},
set: function(name, val, options) {
if (!name) {
throw new Error("coolie must have name");
}
var enc = encodeURIComponent;
var parts = [];
val = (val !== null && val !== undefined) ? val.toString() : "";
options = options || {};
parts.push(enc(name) + "=" + enc(val));
// domain中必須包含兩個點號
if (options.domain) {
parts.push("domain=" + options.domain);
}
if (options.path) {
parts.push("path=" + options.path);
}
// 若是不設置expires和max-age瀏覽器會在頁面關閉時清空cookie
if (options.expires) {
parts.push("expires=" + options.expires.toGMTString());
}
if (options.maxAge && typeof options.maxAge === "number") {
parts.push("max-age=" + options.maxAge);
}
if (options.httpOnly) {
parts.push("HTTPOnly");
}
if (options.secure) {
parts.push("secure");
}
document.cookie = parts.join(";");
},
delete: function(name, options) {
options.expires = new Date(0);// 設置爲過去日期
this.set(name, null, options);
} }
https://blog.csdn.net/adley_a...
1、爲何Cookie須要防篡改 爲何要作Cookie防篡改,一個重要緣由是 Cookie中存儲有判斷當前登錄用戶會話信息(Session)的會話票據-SessionID和一些用戶信息。 當發起一個HTTP請求,HTTP請求頭會帶上Cookie,Cookie裏面就包含有SessionID。 後端服務根據SessionID,去獲取當前的會話信息。若是會話信息存在,則表明該請求的用戶已經登錄。 服務器根據登錄用戶的權限,返回請求的數據到瀏覽器端。 由於Cookie是存儲在客戶端,用戶能夠隨意修改。因此,存在必定的安全隱患。 2、例子 用戶wall在瀏覽器端輸入用戶名密碼,發起POST請求到後端服務器。後端服務器驗證合法,返回Response,並Set-Cookie爲sessionid=*;username=wall;。 瀏覽器端在接收到HTTP響應後,發現Set-Cookie,將其存入本地內存或硬盤中。 瀏覽器端再次發起請求,帶上Cookie信息sessionid=*;username=wall;,請求修改本身的頭像信息。 服務器根據sessionid驗證當前用戶已登錄,根據username,查找數據庫中的對應數據,修改頭像信息。 若是當前用戶知道username的做用,修改username=pony。再次發起請求,則服務器接收到請求後,會去修改username爲pony的數據。 這樣,就暴露出數據被惡意篡改的風險。 3、防篡改簽名 服務器爲每一個Cookie項生成簽名。若是用戶篡改Cookie,則與簽名沒法對應上。以此,來判斷數據是否被篡改。 原理以下: 服務端提供一個簽名生成算法secret 根據方法生成簽名secret(wall)=34Yult8i 將生成的簽名放入對應的Cookie項username=wall|34Yult8i。其中,內容和簽名用|隔開。 服務端根據接收到的內容和簽名,校驗內容是否被篡改。 舉個栗子: 好比服務器接收到請求中的Cookie項username=pony|34Yult8i,而後使用簽名生成算法secret(pony)=666。 算法獲得的簽名666和請求中數據的簽名不一致,則證實數據被篡改。 4、敏感數據的保護 鑑於Cookie的安全性隱患,敏感數據都應避免存儲在Cookie。 應該根據SessionID,將敏感數據存儲在後端。取數據時,根據SessionID去後端服務器獲取便可。 另外,對一些重要的Cookie項,應該生成對應的簽名,來防止被惡意篡改。 ———————————————— 版權聲明:本文爲CSDN博主「adley_app」的原創文章,遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處連接及本聲明。 原文連接:https://blog.csdn.net/adley_app/article/details/80734247
web worker有了解嗎?PWA有什麼弊端?
https://www.cnblogs.com/pqjwy...
1、傳統web 應用
當前web應用在移動時代並無達到其在桌面設備上流行的程度,下面有張圖來對比與原生應用之間的差異。
究其緣由,無外乎下面不可避免的幾點:
移動設備網絡限制-不可忽略的加載時間
web應用依賴於瀏覽器做爲入口
體驗與原生的差距
假如能解決以上的幾點,對web app 來講會有多大的提高能夠想象。
2、PWA是什麼
PWA 全稱Progressive Web Apps(漸進式Web應用程序),旨在使用現有的web技術提供用戶更優的使用體驗。
基本要求
可靠(Reliable)
即便在不穩定的網絡環境下,也能瞬間加載並展示
快速響應(Fast)
快速響應,而且有平滑的動畫響應用戶的操做
粘性(Engaging)
像設備上的原生應用,具備沉浸式的用戶體驗,用戶能夠添加到桌面
PWA 自己強調漸進式,並不要求一次性達到安全、性能和體驗上的全部要求,開發者能夠經過 PWA Checklist 查看現有的特徵。
除以上的基準要求外,還應該包括如下特性:
漸進式 - 適用於全部瀏覽器,由於它是以漸進式加強做爲宗旨開發的
鏈接無關性 - 可以藉助 Service Worker 在離線或者網絡較差的狀況下正常訪問
相似應用 - 因爲是在 App Shell 模型基礎上開發,由於應具備 Native App 的交互和導航,給用戶 Native App 的體驗
持續更新 - 始終是最新的,無版本和更新問題
安全 - 經過 HTTPS 協議提供服務,防止窺探和確保內容不被篡改
可索引 - 應用清單文件和 Service Worker 可讓搜索引擎索引到,從而將其識別爲『應用』
粘性 - 經過推送離線通知等,可讓用戶迴流
可安裝 - 用戶能夠添加經常使用的 webapp 到桌面,免去去應用商店下載的麻煩
可連接 - 經過連接便可分享內容,無需下載安裝
看起來有點眼花繚亂,這又是一個新的飛起的輪子嗎?這裏重申一下,PWA背後不是一種新的技術,而是集合當前多種web技術的一種集合。分別利用各自的功能來完成漸進式的總體需求。下面就沿着前面提出的問題分別瞭解一下相關技術
3、技術組成
由如下幾種技術構成:
App Manifest
Service Worker
Notifications API
Push API
其中Service Worker是PWA技術的關鍵,它們可讓app知足上面的三基準。其餘技術則是錦上添花,讓app更加的強大。
3.1 service worker背景
離線緩存背景
針對網頁的體驗,從前到後都作了不少努力,極力去下降響應時間,這裏就不表述多樣的技術手段。
另外一個方向的就是緩存,減小與服務器非必要的交互,不過對於離線的狀況下瀏覽器緩存就無力了,
這樣離線緩存的需求就出現了。
離線緩存的歷程
web應用在離線緩存發展的過程當中也不是一簇而就的,經歷了逐漸完善的過程。
初期的解決方案是AppCache
然而,事實證實這是一個失敗的嘗試,缺陷太多,已經被廢棄了。具體能夠查看Application Cache is a douchebag
可是方向仍是正確的,那就繼續孜孜不倦的探索。
workers
持久化先放一邊,來談談另外一個問題
基於瀏覽器中的 javaScript 單線程的現實逐漸不能知足現代web需求的現狀,例如耗時的計算,用戶的交互顯然會受影響。
爲了將這些耗時操做從主線程中解放出來,早期W3C新增了一個Web Worker 的 API,能夠脫離主線程單獨執行,而且能夠與主線程交互。
不過Web Worker是臨時性的依賴於建立頁面 ,不能知足咱們持久化的需求。
衝着這個目標,下面就比較容易解決了,搞個能持久存在的就好了。
在Web Worker的基礎上,W3C新增了service worker來知足咱們持久化的需求。
其生命週期與頁面無關,關聯頁面未關閉時,它也能夠退出,沒有關聯頁面時,它也能夠啓動
功能
Service Worker雖然知足了離線緩存來,其功能可不只僅侷限於此。 能夠提供
豐富的離線體驗,
週期的後臺同步,
消息推送通知,
攔截和處理網絡請求,
管理資源緩存
這些正好也是PWA的目的,因此說Service Worker是PWA的關鍵技術。
前提條件
Service Worker 出於安全性和其實現原理,在使用的時候有必定的前提條件。
因爲 Service Worker 要求 HTTPS 的環境
固然通常瀏覽器容許調試 Service Worker 的時候 host 爲 localhost 或者 127.0.0.1
Service Worker 的緩存機制是依賴 Cache API (略過)
依賴 HTML5 fetch API(略過)
依賴 Promise 實現
由上可知,不是全部的瀏覽器都支持的,支持狀況大概以下:
iOS 內的全部的瀏覽器都基於 safari,因此iOS要在11.3以上
IE是放棄支持了,不過Edge好歹支持了。
3.2 Cache
Cache是Service Worker衍生出來的API,配合Service Worker實現對資源請求的緩存。
不過cache並不直接緩存字符串,而是直接緩存資源請求(css、js、html等)。
cache也是key-value形式,通常來講key就是request,value就是response
caches.open(cacheName) 打開一個cache
caches是global對象,返回一個帶有cache返回值的Promise
cache.keys() 遍歷cache中全部鍵,獲得value的集合
cache.match(Request|url) 在cache中匹配傳入的request,返回Promise;
cache.matchAll只有第一個參數與match不一樣,須要一個request的數組,固然返回的結果也是response的數組
cache.add(Request|url) 並非單純的add,由於傳入的是request或者url,在cache.add內部會自動去調用fetch取回request的請求結果,而後纔是把response存入cache;
cache.addAll相似,一般在sw install的時候用cache.addAll把全部須要緩存的文件都請求一遍
cache.put(Request, Response) 這個至關於cache.add的第二步,即fetch到response後存入cache
cache.delete(Request|url) 刪除緩存
3.3 註冊Service Worker
註冊即聲明sw文件的位置,顯然應該在主js中引入。大概以下:
//基於promise
function registerServiceWorker(){
// 註冊service worker
return navigator.serviceWorker.register('./sw1.js').then(registration => {
console.log('註冊成功');
// 返回
return registration;
})
.catch(err => {
console.error('註冊失敗', err);
});
}
window.onload = function () {
//是否支持
if (!('serviceWorker' in navigator)) {
return;
}
registerServiceWorker()
}
3.4 生命週期
Service worker 有一個獨立於web 頁面的生命週期。
若是在網站上安裝 serice worker ,你須要註冊,註冊後瀏覽器會在後檯安裝 service worker。而後進入下面的不一樣階段。
激活以後,service worker 將控制全部的頁面,歸入它的範圍,不過第一次在頁面註冊 service worker 時不會控制頁面,直到它再次加載。
service worker 生效以後,它會處於下面兩種狀態之一:
service worker 終止來節省內存,
頁面發起網絡請求後,它將處理請求獲取和消息事件。
由上圖看知,分爲這麼幾個階段:
Installing
發生在 Service Worker 註冊以後,表示開始安裝,觸發 install 事件回調指定一些靜態資源進行離線緩存
Installed
Service Worker 已經完成了安裝,而且等待其餘的 Service Worker 線程被關閉。
Activating
在這個狀態下沒有被其餘的 Service Worker 控制的客戶端,容許當前的 worker 完成安裝
Activated
在這個狀態會處理 activate 事件回調 (提供了更新緩存策略的機會)。並能夠處理功能性的事件 fetch (請求)、sync (後臺同步)、push (推送)
Redundant
被替換,即被銷燬
瞭解聲明週期實際上是爲了咱們在不一樣時間段去監聽事件來完成相應操做。對PWA來講主要兩個事件。
install 事件回調:
event.waitUntil():傳入一個 Promise 爲參數,等到該 Promise 爲 resolve 狀態爲止。
self.skipWaiting():self 是當前 context 的 global 變量,執行該方法表示強制當前處在 waiting 狀態的 Service Worker 進入 activate 狀態。
activate 回調:
event.waitUntil():傳入一個 Promise 爲參數,等到該 Promise 爲 resolve 狀態爲止。
self.clients.claim():在 activate 事件回調中執行該方法表示取得頁面的控制權, 這樣以後打開頁面都會使用版本更新的緩存。舊的 Service Worker 腳本再也不控制着頁面,以後會被中止。
const CURCACHE = 'CURCACHE_test_1'
const RUNTIME = 'runtime';
const CURCACHE_URLS = [
'./',
'/asset/sw.jpg',
'index.js'
]
self.addEventListener('install',e=>{
e.waitUntil(
//存儲緩存路徑對應的資源
caches.open(CURCACHE).then(cache=>{
cache.addAll(CURCACHE_URLS)
}).then(
self.skipWaiting()
)
)
})
//代理請求,使用緩存,請求發送以前
self.addEventListener('fetch', e => {
e.respondWith(
//緩存是否匹配
caches.match(e.request).then(function(response) {
if (response != null) {
//命中緩存返回緩存,結束請求
return response
}
//未命中緩存,正常請求
return fetch(e.request.url)
})
)
});
更新service worker
service worker 更新步驟以下:
更新 service worker 的文件
網頁打開時服務器會進行對比,保持最新
新的 service worker 啓動install
當前頁面生效的依然是老的service worker,新的 service worker 會進入 「waiting」 狀態。
頁面關閉以後,老的 service worker 會被幹掉,新的 servicer worker 接管頁面
新的 service worker 生效後會觸發 activate 事件。
const CURCACHE = 'precache_test_1'
//假設上個版本的key爲precache_test_2 反正不等於CURCACHE
self.addEventListener('activate', e => {
e.waitUntil(
//遍歷當前緩存keys
caches.keys().then(cacheNames=>{
return Promise.all(
cacheNames.map(function(cacheName) {
//是否等於當前key,保留本身
if (cacheName !== CURCACHE) {
return caches.delete(cacheName);
}
})
)}).then(() => self.clients.claim())
)
})
這樣一個簡單的service worker離線緩存完成了。控制檯能夠看到,來源是service worker
關閉網絡以後再次訪問,能夠一樣獲得上面的結果,而且sw.js請求未能拿到,可是不影響,舊的文件依然在,這裏證實了每次都回去對比sw文件以確保更新
到這裏,離線緩存就實現了。
4、添加到主屏幕
容許將站點添加至主屏幕,是 PWA 提供的一項重要功能。這樣就不用再依賴於瀏覽器做爲平臺,符合移動端的用戶習慣。
manifest.json
須要 manifest.json 文件去配置應用的圖標、名稱等基本信息以下:
{
//被提示安裝應用時出現的文本
"name": "PQJ-PWA",
//添加至主屏幕後的文本
"short_name":"PQJ",
"description": "測試demo",
//添加以後,啓動地址
"start_url": "/index.html",
//圖標信息
"icons": {
"128": "/asset/sw.jpg"
},
"developer": {
"name": "pqj",
"url": ""
},
"display": "standalone",
"background_color": "#287fc5",
"theme_color": "#fff",
"permissions": {
"desktop-notification": {
"description": "Needed for creating system notifications."
}
}
}
而後以以下方式在html中引入
<link rel="manifest" href="/mainfest.json" />
這樣完成以後,移動端安卓使用chrome(親測),首次訪問時會提示是否容許安裝到主屏幕,以應用icon的形式出現。
圖片和文字即由配置決定。
5、消息通知
消息通知也是使用service worker的通知功能進行的,容許服務器想用戶發生通知,而非用戶主動請求才去響應某些行爲。
正常的通知邏輯須要服務器來參與實現,此次展現只實現功能。
首先申請通知權限
註冊service worker
處理邏輯,發送通知
function getPermission(){
return new Promise((resolve, reject) => {
//權限獲取
const permissionPromise = Notification.requestPermission(result => {
resolve(result);
});
}).then(result => {
//判斷條件
if (result === 'granted') {
execute();
}
else {
console.log('no permission');
}
});
}
發送通知
function execute() {
// 容許以後執行
registerServiceWorker().then(registration => {
// 通知
registration.showNotification('Hello World!');
});
}
前言
最近在翻紅寶書,看到 Web Worker 那章,猛然意識到,經過它居然能夠把幾個緩存相關的概念串起來,甚是有趣,撰文記之。最後我也寫了一個完整的離線應用 Demo,以供運行調試。
瀏覽器緩存
傳統意義上的瀏覽器緩存,分爲強緩存和協商緩存,其共同點都是經過設置 HTTP Header 實現。關於二者的異同已經被討論得不少,我就不贅述了,附兩個參考資料。
瀏覽器的緩存機制, By Aitter
http協商緩存VS強緩存, By wonyun
這種瀏覽器緩存(我稱之爲 Header 緩存)有兩個共同的缺點:
當沒有網絡的時候,應用沒法訪問,由於 HTML 頁面總得去服務器獲取。
緩存不可編程,沒法經過 JS 來精細地對緩存進行增刪改查。
應用緩存
爲了在無網絡下也能訪問應用,HTML5 規範中設計了應用緩存(Application Cache)這麼一個新的概念。經過它,咱們能夠作離線應用。然而,因爲這個 API 的設計有太多的缺陷,被不少人吐槽,最終被廢棄。廢棄的緣由能夠看看這些討論:
爲何app cache沒有獲得大規模應用?它有哪些硬傷嗎?
Application Cache is a Douchebag, By Jake Archibald
PS:我當年畢設也用到過這種技術,沒想到短短几年就被廢棄了,技術迭代何其之快也!
CacheStorage
爲了可以精細地、可編程地控制緩存,CacheStorage 被設計出來。有了它,就能夠用 JS 對緩存進行增刪改查,你也能夠在 Chrome 的 DevTools 裏面直觀地查看。對於傳統的 Header 緩存,你是無法知道有哪些緩存,更加無法對緩存進行操做的。你只能被動地修改 URL 讓瀏覽器拋棄舊的緩存,使用新的資源。
image
PS:CacheStorage 並不是只有在 Service Worker 中才能用,它是一個全局性的 API,你在控制檯中也能夠訪問到 caches 全局變量。
Web Worker
一直以來,一個網頁只會有兩個線程:GUI 渲染線程和 JS 引擎線程。即使你的 JS 寫得再天花亂墜,也只能在一個進程裏面執行。然而,JS 引擎線程和 GUI 渲染線程是互斥的,所以在 JS 執行的時候,UI 頁面會被阻塞住。爲了在進行高耗時 JS 運算時,UI 頁面仍可用,那麼就得另外開闢一個獨立的 JS 線程來運行這些高耗時的 JS 代碼,這就是 Web Worker。
Web Worker 有兩個特色:
只能服務於新建它的頁面,不一樣頁面之間不能共享同一個 Web Worker。
當頁面關閉時,該頁面新建的 Web Worker 也會隨之關閉,不會常駐在瀏覽器中。
PS:還有一個相關的概念:Shared Worker,不過這個東西比較複雜,我並未深刻研究,感興趣的讀者能夠了解,也能夠看看 Shared Worker 跟 Service Worker 的區別。
Service Worker
終於說到本文的主角了。Service Worker 與 Web Worker 相比,相同點是:它們都是在常規的 JS 引擎線程之外開闢了新的 JS 線程。不一樣點主要包括如下幾點:
Service Worker 不是服務於某個特定頁面的,而是服務於多個頁面的。(按照同源策略)
Service Worker 會常駐在瀏覽器中,即使註冊它的頁面已經關閉,Service Worker 也不會中止。本質上它是一個後臺線程,只有你主動終結,或者瀏覽器回收,這個線程纔會結束。
生命週期、可調用的 API 等等也有很大的不一樣。
總而言之,Service Worker 是 Web Worker 進一步發展的產物。關於如何使用 Service Worker,能夠參考下面的資料。
藉助Service Worker和cacheStorage緩存及離線開發, By 張鑫旭
使用Service Worker作一個PWA離線網頁應用, By 會編程的銀豬
【譯】理解Service Worker, 做者 By Adnan Chowdhury, 譯者 By 安秦
我也寫了一個 Service Worker 用做離線應用的 Demo,你們能夠調試觀察。下面咱們討論幾個 Service Worker 容易被忽略的地方,以個人 Demo 爲例。
Service Worker 只是 Service Worker
一開始我覺得 Service Worker 就是用來作離線應用的,後來漸漸研究才發現不是這樣的。→ Service Worker 只是一個常駐在瀏覽器中的 JS 線程,它自己作不了什麼。它能作什麼,全看跟哪些 API 搭配使用。
跟 Fetch 搭配,能夠從瀏覽器層面攔截請求,作數據 mock;
跟 Fetch 和 CacheStorage 搭配,能夠作離線應用;
跟 Push 和 Notification 搭配,能夠作像 Native APP 那樣的消息推送,這方面能夠參考 villainhr 的文章:Web 推送技術
……
假如把這些技術融合在一塊兒,再加上 Manifest 等,就差很少成了 PWA 了。
總之,Service Worker 是一種很是關鍵的技術,有了它,咱們能更接近瀏覽器底層,能作更多的事情。
The idea is that we, as browser developers, acknowledge that we are not better at web development than web developers. And as such, we shouldn't provide narrow high-level APIs that solve a particular problem using patterns we like, and instead give you access to the guts of the browser and let you do it how you want, in a way that works best for your users.
出處:https://developers.google.com/web/fundamentals/primers/service-workers/lifecycle#handling_updates
初次訪問不會觸發 fetch 事件
按照官方給的 Demo,Service Worker 註冊的代碼是放在 HTML 的最後。可是,當我嘗試把 Service Worker 的註冊代碼提到最開頭,而且 console 出時間戳,我發現一個現象:即使 Service Worker 註冊成功以後再請求資源,這些資源也不會觸發 fetch 請求,只有再次訪問頁面纔會觸發 fetch 事件。這是爲何呢?後來我在官方文檔中找到了答案:若是你的頁面加載時沒有 Service Worker,那麼它所依賴的其餘資源請求也不會觸發 fetch 事件。
The first time you load the demo, even though dog.svg is requested long after the service worker activates, it doesn't handle the request, and you still see the image of the dog. The default is consistency, if your page loads without a service worker, neither will its subresources. If you load the demo a second time (in other words, refresh the page), it'll be controlled. Both the page and the image will go through fetch events, and you'll see a cat instead.
出處:https://developers.google.com/web/fundamentals/primers/service-workers/lifecycle#activate
cache.add VS cache.put
在 install 事件中用 cache.addAll,在 fetch 事件中用 cache.put,add 和 put 有什麼區別嗎?→ cache.add = fetch + cache.put
The add() method of the Cache interface takes a URL, retrieves it, and adds the resulting response object to the given cache. The add() method is functionally equivalent to the following:
fetch(url).then(function(response) {
if (!response.ok) {
throw new TypeError('bad response status');
}
return cache.put(url, response);
})
出處:https://developer.mozilla.org/en-US/docs/Web/API/Cache/add
event.waitUntil 和 event.respondWith
先說 event.waitUntil
只能在 Service Worker 的 install 或者 activate 事件中使用;
看起來像是一個 callback,可是,即使你不使用它,程序也可能正常運行。若是你傳遞了一個 Promise 給它,那麼只有當該 Promise resolved 時,Service Worker 纔會完成 install;若是 Promise rejected 掉,那麼整個 Service Worker 便會被廢棄掉。所以,cache.addAll 裏面,只要有一個資源獲取失敗,整個 Service Worker 便會失效。
再說 event.respondWith
只能在 Service Worker 的 fetch 事件中使用;
做用至關於一個 callback,當傳入的 Promise resolved 以後,纔會將對應的 response 返回給瀏覽器。
總之,雖然 event.waitUntil 和 event.respondWith 中的 event 都是繼承於 Event 類,可是它們與常見的 event 對象差別很大,這些方法也只有在 Service Worker 的那些對應的事件中才存在。
資源的更新
之前咱們用強緩存的時候,若是資源須要更新,那麼咱們只須要改變資源的 URL,換上新的 MD5 戳就行了。若是使用 Service Worker + CacheStorage + Fetch 作離線應用,又該如何處理資源的更新呢?
當有任何的資源(HTML、JS、Image、甚至是 sw.js 自己)須要更新時,都須要改變 sw.js。由於有了 sw.js,整個應用的入口變成了 sw.js,而非原先的 HTML。每當用戶訪問頁面時,無論你當前是否是命中了緩存,瀏覽器都會請求 sw.js,而後將新舊 sw.js 進行字節對比,若是不同,說明須要更新。所以,你能看到在 Demo 中,咱們有一個 VERSION 字段,它不只表明 sw.js 自己的版本,更表明整個應用的版本。
不要試圖經過改變 sw.js 的名字(如改爲 sw_v2.js)來觸發瀏覽器的更新,由於 HTML 自己會被 sw.js 緩存,而緩存的 HTML 中永遠都指向 sw.js,致使瀏覽器沒法得知 sw_v2.js 的更新。雖然,你能夠像上面提到的文章:使用Service Worker作一個PWA離線網頁應用 那樣,再結合其餘的手段來判斷 HTML 的更新狀態,可是會更加複雜,官方並不推薦。
you may consider giving each version of your service worker a unique URL. Don't do this! This is usually bad practice for service workers, just update the script at its current location.
出處:https://developers.google.com/web/fundamentals/primers/service-workers/lifecycle#avoid_changing_the_url_of_your_service_worker_script
每次 sw.js 的更新,都會根據 VERSION 字段新建一個緩存空間,而後把新的資源緩存在裏面。等到舊的 sw.js 所控制的網頁所有關閉以後,新的 sw.js 會被激活,而後 在 activate 事件中刪除舊緩存空間。這樣既能保證在同時打開多個網頁時更新 sw.js 不出差錯,也能及時刪除冗餘的緩存。
雙重緩存
上面咱們談到,當新的 sw.js install 的時候,會從新 fetch addAll 裏面的全部資源,無論裏面的資源是否須要更新,這顯然違背了 Web 增量下載的原則,怎麼辦呢? → 結合使用強緩存和 Service Worker,作一個雙重緩存。強緩存在前, Service Worker 在後。舉個例子,假若有兩個強緩存 a_v1.js 和 b_v1.js,如今 a 不變,b 要改爲 b_v2.js,修改 sw.js 的 addAll 和 VERSION。當新的 sw.js install 的時候,addAll 要 fetch a_v1.js ,可是瀏覽器發現 a_v1.js 是強緩存,因此根本不會發起網絡請求,只有 b_v2.js 纔會發起網絡請求。具體的能夠調試個人 Demo 查看現象。
關於這種方法,有兩點要說明一下。
須要在 cache.addAll 中指定資源的版本號,就如同在 html 中指定那般。由於在使用 Service Worker 以後,HTML 只是加載資源的入口,判斷資源是否改變的功能,已經轉移到 sw.js 中了。
return cache.addAll([
'./',
'getList',
'img/avatar_v1.jpg',
'js/index_v2.js',
'js/jquery_v1.js'
]);
上面提到的文章:使用Service Worker作一個PWA離線網頁應用 中也有提到這種多重緩存的作法,可是做者認爲瀏覽器會先讀取 Service Worker,沒有的話纔會讀取強緩存,這與個人 Demo 實踐結果不相符。
框架
Vue實現雙向數據綁定的原理是什麼?
> 實現mvvm的雙向綁定,是採用數據劫持結合發佈者-訂閱者模式的方式,經過Object.defineProperty()來劫持各個屬性的setter,getter,在數據變更時發佈消息給訂閱者,觸發相應的監聽回調。 輸入框內容變化時,Data 中的數據同步變化。即 View => Data 的變化。 Data 中的數據變化時,文本節點的內容同步變化。即 Data => View 的變化。 其中,View 變化更新 Data ,能夠經過事件監聽的方式來實現,因此 Vue 的數據雙向綁定的工做主要是如何根據 Data 變化更新 View。 Vue 主要經過如下 4 個步驟來實現數據雙向綁定的: 實現一個監聽器 Observer:對數據對象進行遍歷,包括子屬性對象的屬性,利用 Object.defineProperty() 對屬性都加上 setter 和 getter。這樣的話,給這個對象的某個值賦值,就會觸發 setter,那麼就能監聽到了數據變化。 實現一個解析器 Compile:解析 Vue 模板指令,將模板中的變量都替換成數據,而後初始化渲染頁面視圖,並將每一個指令對應的節點綁定更新函數,添加監聽數據的訂閱者,一旦數據有變更,收到通知,調用更新函數進行數據更新。 實現一個訂閱者 Watcher:Watcher 訂閱者是 Observer 和 Compile 之間通訊的橋樑 ,主要的任務是訂閱 Observer 中的屬性值變化的消息,當收到屬性值變化的消息時,觸發解析器 Compile 中對應的更新函數。 實現一個訂閱器 Dep:訂閱器採用 發佈-訂閱 設計模式,用來收集訂閱者 Watcher,對監聽器 Observer 和 訂閱者 Watcher 進行統一管理。
Vue都有哪些生命週期函數?
Vue 實例從建立到銷燬的過程,就是生命週期。從開始建立、初始化數據、編譯模板、掛載Dom→渲染、更新→渲染、銷燬等一系列過程,稱之爲 Vue 的生命週期。 生命週期中有多個事件鉤子,以下: - beforeCreate(建立前) 在數據觀測和初始化事件還未開始 - created(建立後) 完成數據觀測,屬性和方法的運算,初始化事件,$el屬性尚未顯示出來 - beforeMount(載入前) 在掛載開始以前被調用,相關的render函數首次被調用。實例已完成如下的配置:編譯模板,把data裏面的數據和模板生成html。注意此時尚未掛載html到頁面上。 - mounted(載入後) 在el 被新建立的 vm.$el 替換,並掛載到實例上去以後調用。實例已完成如下的配置:用上面編譯好的html內容替換el屬性指向的DOM對象。完成模板中的html渲染到html頁面中。此過程當中進行ajax交互。 - beforeUpdate(更新前) 在數據更新以前調用,發生在虛擬DOM從新渲染和打補丁以前。能夠在該鉤子中進一步地更改狀態,不會觸發附加的重渲染過程。 - updated(更新後) 在因爲數據更改致使的虛擬DOM從新渲染和打補丁以後調用。調用時,組件DOM已經更新,因此能夠執行依賴於DOM的操做。然而在大多數狀況下,應該避免在此期間更改狀態,由於這可能會致使更新無限循環。該鉤子在服務器端渲染期間不被調用。 - beforeDestroy(銷燬前) 在實例銷燬以前調用。實例仍然徹底可用。 - destroyed(銷燬後) 在實例銷燬以後調用。調用後,全部的事件監聽器會被移除,全部的子實例也會被銷燬。該鉤子在服務器端渲染期間不被調用。
Vue 的父組件和子組件生命週期鉤子函數執行順序?
Vue 的父組件和子組件生命週期鉤子函數執行順序能夠歸類爲如下 4 部分: - 加載渲染過程: 父 beforeCreate -> 父 created -> 父 beforeMount -> 子 beforeCreate -> 子 created -> 子 beforeMount -> 子 mounted -> 父 mounted - 子組件更新過程: 父 beforeUpdate -> 子 beforeUpdate -> 子 updated -> 父 updated - 父組件更新過程: 父 beforeUpdate -> 父 updated - 銷燬過程: 父 beforeDestroy -> 子 beforeDestroy -> 子 destroyed -> 父 destroyed
子組件如何向父組件傳遞數據?
https://blog.csdn.net/qq_3376...
方法一:使用prop和emit。
父頁面
<template>
<div>
<child :valueC="value1" @getChidC="getChid"></child> //等號右邊表明當前頁面要傳到子頁面的值。子頁面用左邊的變量接收。@表明函數,左邊是子頁面emit要用的,右邊是當前頁接收的子。右當前左子頁面
<button @click="changeA">點擊獲取子組件值</button>
</div>
</template>
<script>
export default{
components: {
child: resolve => {
require(['@/components/child'], resolve)
},
},
data(){
return {
value1:'',
}
},
methods:{
getChid(e){
console.log(e)
},
}
</script>
子頁面child.vue
<template>
<div class="children">
父組件的值value1:{{value1}}
<input type="text" v-model="inputValue">
<button @click="sendToP">點擊傳值給父組件</button>
</div>
</template>
<script>
export default{
props:['valueC'],
data(){
return{
inputValue:'',
}
},
methods:{
sendToP(){
this.$emit("getChidC",this.inputValue)
}
},
}
</script>
方法2.使用$parent 和$children。$children 的值是數組,而$parent是個對象
在子頁面使用this.$parent能獲取父組件裏面的變量和函數
在父頁面使用this.$children獲取全部的子組件的數組形式。而後根據下標能夠獲取具體子頁面的變量和函數.this.$children[0].messageA
父組件
<template>
<div>
<child :value1="value1" @getChid="getChid"></child>
<button @click="changeA">點擊獲取子組件值</button>
</div>
</template>
<script>
export default{
components: {
child: resolve => {
require(['@/components/child'], resolve)
},
},
data(){
return {
value1:'123',
}
},
methods:{
getChid(e){
console.log(e)
},
changeA(){
console.log(this.$children[0].parentVal);
this.$children[0].parentVal ='this is new value';
console.log(this.$children[0].parentVal)
}
},
}
</script>
子組件
<template>
<div class="children">
父組件的值value1:{{parentVal}}
</div>
</template>
<script>
export default{
data(){
return{
parentVal:'',
}
},
mounted(){
this.parentVal=this.$parent.value1
},
}
</script>
方法3:ref / refs
子組件ref="child".父組件中使用refs獲取子組件的內容。
父組件
<template>
<div>
<child :value1="value1" @getChid="getChid" ref="child"></child>
<button @click="changeA">點擊獲取子組件值</button>
</div>
</template>
<script>
export default{
components: {
child: resolve => {
require(['@/components/child'], resolve)
},
},
data(){
return {
value1:'123',
}
},
methods:{
getChid(e){
console.log(e)
},
changeA(){
console.log(this.$refs.child.parentVal);
}
},
}
</script>
若是想要強制初始化組件,應該使用Vue中的哪一個命令?
https://blog.csdn.net/qq_3998...
前言: 在開發過程當中,有時候會遇到這麼一種狀況,經過動態的賦值,可是dom沒有及時更新,可以獲取到動態賦的值,可是沒法獲取到雙向綁定的dom節點,這就須要咱們手動進行強制刷新組件。 官網是這樣說的: 可能你還不大理解,請繼續往下看,下面是個人一個例子,來詳細解說了這個方法的使用, 第一個打印結果 第二個打印結果 /************************************************************************************************************************************/ 1、問題描述:父組件經過v-for渲染子組件,刪除子組件數據出現異常。 <code class="language-plain"><section v-if="isrefresh" v-for="(sign,index) in signs"> <sign-card></sign-card> </section></code> 2、問題緣由:出現異常的數據不是響應式依賴,是從vuex讀取的。經過測試發現,父組件刪除數據,沒有從新建立子組件,懷疑是子組件異常的數據是讀取的緩存副本。 3、問題解決:根據v-if改變dom結構的特性,手動使子組件從新建立。 1.設置一個數據變量isrefresh=true 2.初始v-if=isrefresh 3.刪除時,配合$nextTick()DOM渲染回調函數,使子組件從新建立
相關文章
- 1. Android崗BAT、網易、京東大廠試水面經,有幸拿到京東offer
- 2. 京東面試
- 3. 2019年_BATJ大廠面試題總結-京東篇
- 4. 【大廠面試】字節跳動、京東等大廠面試題分享,已拿字節offer~
- 5. 京東商城大數據面試題
- 6. 京東Android面試記錄
- 7. 京東實習面試
- 8. 京東面試--總結
- 9. iOS京東面試總結
- 10. 京東面試題收集
- 更多相關文章...
- • Lua 調試(Debug) - Lua 教程
- • Eclipse Debug 調試 - Eclipse 教程
- • JDK13 GA發佈:5大特性解讀
- • 使用阿里雲OSS+CDN部署前端頁面與加速靜態資源
相關標籤/搜索
每日一句
-
每一个你不满意的现在,都有一个你没有努力的曾经。
歡迎關注本站公眾號,獲取更多信息

相關文章
- 1. Android崗BAT、網易、京東大廠試水面經,有幸拿到京東offer
- 2. 京東面試
- 3. 2019年_BATJ大廠面試題總結-京東篇
- 4. 【大廠面試】字節跳動、京東等大廠面試題分享,已拿字節offer~
- 5. 京東商城大數據面試題
- 6. 京東Android面試記錄
- 7. 京東實習面試
- 8. 京東面試--總結
- 9. iOS京東面試總結
- 10. 京東面試題收集