京東面試--總結
特別喜歡一句話:不是由於看到了但願纔去堅持,而是由於堅持了纔會看到但願。
一、如今有T一、T二、T3三個線程,你怎樣保證T2在T1執行完後執行,T3在T2執行完後執行?
思路:多線程之間怎麼協同工做,如何讓一個線程執行完畢後處於什麼狀態。
Thread t1 = new Thread(new T1());
Thread t2 = new Thread(new T2());
Thread t3 = new Thread(new T3());
t1.start();
t1.join();
t2.start();
t2.join();
t3.start();
t3.join();
或者使用第二種方法,在t2裏邊放入t1.join(),在t3裏邊放入t2.join()
爲何使用了join方法呢?
熟悉一下jdk join方法的源碼就會了解:
public final synchronized void join(long millis) throws InterruptedException{
long base = System.currentTimeMills();
long now = 0;
if(millis < 0){
throw new IllegalArgumentException("timeout value is negative");
}
if(millis == 0){
while(isAlive()){
wait(0);
}
}else{
while(isAlive()){
long delay = millis-now;
if(delay <= 0){
break;
}
wait(delay);
now = System.currentTimeMillis()-base;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
}
線程會一直循環isAlive(),知道false,關鍵詞:join
二、java中的++i操做是線程安全的嗎,爲何?如何使其線程安全呢?
思路:synchronized、AtomicInteger(valitile)
AtomicInteger,一個提供原子操做的Integer類,在java語言中,++i和i++操做並非線程安全的,在使用的時候,不可避免的會用到synchronized關鍵字,而AtomicInteger則經過一種線程安全的加減操做接口。
咱們接下來看一下AtomicInteger類的jdk源碼:
1
2
3
4
5
private volatile int value;
/**
* Creates a new AtomicInteger with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicInteger(int initialValue) {
value = initialValue;
}
/**
* Creates a new AtomicInteger with initial value {@code 0}.
*/
public AtomicInteger() {
}
/**
* Gets the current value.
*
* @return the current value
*/
public final int get() {
return value;
}
/**
* Sets to the given value.
*
* @param newValue the new value
*/
public final void set(int newValue) {
value = newValue;
}
爲何不用計數器自加呢,例如count++,由於這種計數是線程不安全的,高併發訪問時統計會有誤,而AtomicInteger爲何可以達到坐懷不亂,應付自如呢?不難發現其private volatile int value;
1
你們能夠看到有這個變量,value就是你設置的自加起始值。注意看它的訪問控制符,是volatile,這個就是保證AtomicInteger線程安全的根源,熟悉併發的同窗必定知道在java中處理併發主要有兩種方式:
1,synchronized關鍵字,這個你們應當都各類面試和筆試中常常遇到。
2,volatile修飾符的使用,相信這個修飾符你們平時在項目中使用的也不是不少。
Volatile修飾的成員變量在每次被線程訪問時,都強迫從共享內存從新讀取該成員的值,並且,當成員變量值發生變化時,強迫將變化的值從新寫入共享內存,這樣兩個不一樣的線程在訪問同一個共享變量的值時,始終看到的是同一個值。
java語言規範指出:爲了獲取最佳的運行速度,容許線程保留共享變量的副本,當這個線程進入或者離開同步代碼塊時,才與共享成員變量進行比對,若是有變化再更新共享成員變量。這樣當多個線程同時訪問一個共享變量時,可能會存在值不一樣步的現象。
而volatile這個值的做用就是告訴VM:對於這個成員變量不能保存它的副本,要直接與共享成員變量交互。
建議:當多個線程同時訪問一個共享變量時,可使用volatile,而當訪問的變量已在synchronized代碼塊中時,沒必要使用。
缺點:使用volatile將使得VM優化失去做用,致使效率較低,因此要在必要的時候使用。
例子
 html
html
借用Google JEREMY MANSON 的解釋,上圖表示兩個線程併發執行,並且代碼順序上爲Thread1->Thread2
1. 不用 volatile
假如ready字段不使用volatile,那麼Thread 1對ready作出的修改對於Thread2來講未必是可見的,是否可見是不肯定的.假如此時thread1 ready泄露了(leak through)了,那麼Thread 2能夠看見ready爲true,可是有可能answer的改變並無泄露,則thread2有可能會輸出 0 (answer=42對thread2並不可見)
2. 使用 volatile
使用volatile之後,作了以下事情
* 每次修改volatile變量都會同步到主存中
* 每次讀取volatile變量的值都強制從主存讀取最新的值(強制JVM不可優化volatile變量,如JVM優化後變量讀取會使用cpu緩存而不從主存中讀取)
* 線程 A 中寫入 volatile 變量以前可見的變量, 在線程 B 中讀取該 volatile 變量之後, 線程 B 對其餘在 A 中的可見變量也可見. 換句話說, 寫 volatile 相似於退出同步塊, 而讀取 volatile 相似於進入同步塊
1
2
3
因此若是使用了volatile,那麼Thread2讀取到的值爲read=>true,answer=>42,固然使用volatile的同時也會增長性能開銷
優缺點:volatile解決了線程間共享變量的可見性問題
使用volatile會增長性能開銷
volatile並不鞥解決線程同步問題
解決了i++或者++i這樣的線程同步問題須要使用synchronized或者AtomicXX系列下的包裝類,同時也會增長性能的開銷
Volatileg關鍵字保證了在多線程環境下,被修飾的變量在別的線程修改後會立刻同步到主存,這樣改線程對這個變量的修改就是對其餘線程的可見性,其餘線程可以立刻讀到這個修改後的值。
三、3*0.1 == 0.3將會返回什麼,true或者false?
false,試着輸出一下3*0.1的值會是0.300000000000004,由於3*0.1運算過程當中自動類型提高了,有些浮點數不能徹底精確 表示出來,浮點數精度默認爲6位。
四、說下Java堆空間結構,及經常使用的jvm內存分析命令和工具
Java堆空間結構圖:http://www.cnblogs.com/SaraMoring/p/5713732.html
JVM內存情況查看方法和分析工具:
http://blog.csdn.net/neosmith/article/details/47753733
五、用什麼工具和方法分析線程問題
六、列舉幾個索引失效的狀況
索引並非時時都會生效的,好比如下幾種狀況,將致使索引失效:
1. 若是條件中有or,即便其中有條件帶索引也不會使用(這也是爲何儘可能少用or的緣由)
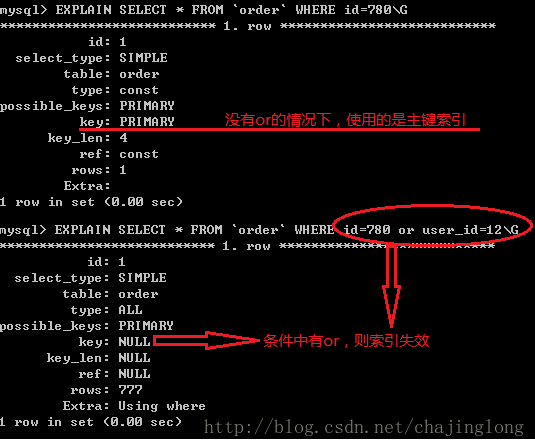
1
2
注意:要想使用or,又想讓索引生效,只能將or條件中的每一個列都加上索引
2.對於多列索引,不是使用的第一部分,則不會使用索引
3.like查詢是以%開頭
java
4.若是列類型是字符串,那必定要在條件中將數據使用引號引用起來,不然不使用索引
mysql
5.若是mysql估計使用全表掃描要比使用索引快,則不使用索引
七、或一個時序圖描述從用戶在瀏覽器地址欄輸入url並按回車,到瀏覽器顯示相關內容的各個過程
其實考察的就是一次HTTP請求所通過的過程和Spring或者SpringMVC怎麼調用dispatcherServlet的過程
面試
八、有一個servlet,提供對外服務,10個請求下建立了幾個servlet實例
servlet共享一個,感受首先內存佔用少,畢竟併發上來以後若是每次都建立的話,內存消耗很大,另外一方面servlet只有一個對象的話,能夠只在第一次請求過來時候建立一個對象,而後調用init初始化一些參數以後就能夠在後面直接使用了。
connection連接利用連接池的概念,這樣在服務啓動時候直接建立固定數量的連接,避免在高併發線程請求時候不斷的建立連接,這樣會消耗大量的資源,這樣就把這資源消耗的過程放在了服務啓動的過程當中。
九、有以下表:
Create table T_A{
id bigint primary key,
status int
}
用戶A 和 B幾乎同時對錶裏同一條數據的status字段進行更新,其中A用戶時字段從0變到1,B用戶時從0變到2;如何保證最早執行的結果不被後面執行的幹掉
考察悲觀鎖和樂觀鎖的,使用樂觀鎖加版本號。
十、在jdbc編程中,如何避免sql注入漏洞
1.傳統JDBC,採用PreparedStatement 。預編譯語句集,內置了處理SQL注入的能力
String sql= 「select * from users where username=? and password=?」; //若是把?改成:username1,按參數名綁定
PreparedStatement preState = conn.prepareStatement(sql);
preState.setString(1, userName); //則此處變爲.setString(「username1」,username)
preState.setString(2, password);
ResultSet rs = preState.executeQuery();
2. 採用正則表達式,將輸入的全部特殊符號轉換爲空格或其餘字符
public static String TransactSQLInjection(String str)
{
return str.replaceAll(「.([‘;]+|(–)+).「, 」 「);
// 我認爲 應該是return str.replaceAll(「([‘;])+|(–)+」,」「);–>這是原做者的註釋,我的不是很贊同。
}
userName=TransactSQLInjection(userName);
password=TransactSQLInjection(password);
String sql=」select * from users where username=’」+userName+」’ and password=’」+password+」’ 「;
Statement sta = conn.createStatement();
ResultSet rs = sta.executeQuery(sql);
JAVA Web中,編寫Fileter,實現對renquest請求中參數的不合法字符替換
for(String word : invalidsql){
if(word.equalsIgnoreCase(value) || value.contains(word)){
if(value.contains(「<」)){
value = value.replace(「<」, 「<」); //這個我的認爲括號中第二個<應該替換成其餘符號
}
if(value.contains(「>」)){
value = value.replace(「>」, 「>」);
}
request.getSession().setAttribute(「sqlInjectError」, 「the request parameter \」「+value+」\」 contains keyword: \」「+word+」\」「);
response.sendRedirect(request.getContextPath()+error);
return;
}
}
四、經過Hibernate框架的sql注入防範
11,若是由你編寫一個相似於guava中的緩存組件,有哪些場景須要考慮,有什麼解決方式
最後一道,由大家自由發揮吧,針對部門不同,考察的重點不同,基本上都是多線程,多線程會出現什麼問題?高併發怎麼處理?但願大家本身有本身的理解!
參考原文:https://blog.csdn.net/chajinglong/article/details/78470351
正則表達式
- 1. iOS京東面試總結
- 2. 京東面試總結
- 3. 試作「京東界面」的總結
- 4. 京東頁面總結
- 5. 京東筆試題總結
- 6. 2019.04.13 京東筆試總結
- 7. 京東面試
- 8. 2020京東java面試筆試總結 (含面試題解析)
- 9. 京東面 彙總
- 10. JAVA京東社招面試經歷【面試流程+面試總結】
- 更多相關文章...
- • Lua 調試(Debug) - Lua 教程
- • Eclipse Debug 調試 - Eclipse 教程
- • 算法總結-雙指針
- • 算法總結-回溯法
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. iOS京東面試總結
- 2. 京東面試總結
- 3. 試作「京東界面」的總結
- 4. 京東頁面總結
- 5. 京東筆試題總結
- 6. 2019.04.13 京東筆試總結
- 7. 京東面試
- 8. 2020京東java面試筆試總結 (含面試題解析)
- 9. 京東面 彙總
- 10. JAVA京東社招面試經歷【面試流程+面試總結】