談談如何學習Linux內核
學習內核的好處不少,在學習過程當中不只能夠夯實大量理論基礎,還能夠學習到不少編碼慣用法,提高學習能力和分析能力。node
1、確立高度,明確目標linux
高度決定視角,視角決定行動
在學習內核過程當中最容易犯的錯誤,也是很是難掌握的實際上是你站在一個什麼樣的高度上去學習。站什麼樣的高度去學習也與自身的能力相關,因此這個問題其實更可能是在新開始學習的學習者感到很是痛苦的一件事。一方面又但願本身能學懂,可是又不知道如何開始入手。編程
我列舉幾個常見的例子:網絡
(1) 一開始就看源碼,最開始我也作過這種事,內核有什麼都不知道,結果就想着啃0.11的內核,結果很顯然,2天立馬放棄,徹底看不懂。架構
(2) 翻開書從第一頁開始往下啃,若是這本書比較薄還好,若是比較厚,好比《深刻Linux內核架構》,那看2天也得放棄。函數
(3) 不喜歡看目錄,不喜歡快速瀏覽,就想着一個一個字眼的往下摳。若是自己有必定基礎,看的時候還不會以爲膩,可是很快就發現,看了半天,什麼都沒有記住。學習
還有不少相似的問題,這些都是咱們平時學習的時候特別容易出現的一些誤區。這些其實都是沒有正確審視本身的能力,胡亂挑選高度致使。編碼
高度是什麼?
高度越高,也就是越偏向於理解各類抽象概念,傾向於構建對總體結構的一個認知,忽略一些沒必要要細節,不關心技術實現手段。高度越低,也就是越偏向於對使用技術的選擇,傾向於代碼實現的各個細節,可是前提通常會在某個抽象的概念領域內進行各類細節性的討論。spa
咱們的大腦更傾向於理解抽象的內容,可是在行動時,咱們卻更傾向於去把握細節性的內容。結果致使的內容就是,咱們老是但願經過學習細節來構造對抽象概念的理解,最後被細節性內容中各類噪聲干擾思緒,產生一種「這東西好難」的錯覺。在理解了這點,那高度對咱們的行爲有和指導意義也就呼之欲出了?
以讀書爲例。站的越高,意味着本身看的內容越粗糙,也就是看書的時候不會去逐字逐句的看,而是一個章節一個章節的看,極端的狀況就是隻看目錄,在這個過程當中主要集中精力構建總體結構,對核心的概念進行抽象。這時候學的內容都相對錶面,可是好處就是對之後的學習有很強的指導意義,缺點很明顯,會讓人底氣不足,並且在達到必定程度後,很容易到達瓶頸,發覺怎麼看都看不懂了。站的越低,意味着本身看的內容很細緻,看書的時候就是一個個字眼的扣,極端狀況就是開始閱讀源碼,去看開源社區的各類問題。可是就像詩句說的,站的越低,也就常有一種「不識廬山真面目,只緣身在此山中」的感受。這種狀況下特別容易被各類細節干擾,例如爲何要有這些參數,爲何這裏須要判斷這個條件等等這些細枝末節的問題。設計
如何運用高度
之前對一篇博文印象很深入,做者理解的學習曲線劃分紅了兩個比較大的過程,上升的過程就是一個不斷學習積累的過程,而平緩沒有增加的過程則是對以前積累到飽和的知識進行消化的過程。我將這個學習過程進行進一步的劃分,我以爲在學習積累的前半部分應該以偏向學習抽象概念爲主,而後半部分應該偏向學習實現細節。
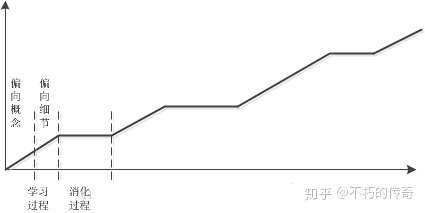
因此我的的心得是從高到低的學習,在一個新的學習階段,應該先多花點時間學習一些概念化的內容,這時候切忌去看具體的實現,而是多考慮如何在大腦中構建各類抽象模型
對總體的架構有所概念了,而後開始學習一些細節性的內容,好比開始看些源碼,摳寫書上的字眼,讀讀一些具體的博客什麼的。
2、學習小Tips
1.如何看書
不要從第一頁開始翻 不要一頁一頁的翻
- 花些時間看看前言,在不少書的前言部分,做者會告訴你,整本書的結構應該是什麼樣,應該要以什麼樣的順序去閱讀,在閱讀的時候應該站在什麼樣的角度去閱讀,這是做者的建議,有什麼比做者的建議更值得咱們聽取呢!?
- 不要寄但願與一次看懂一本書,越是好的書越是要反覆的看,可是不少人對這個反覆理解有問題,認爲反覆的看就是一頁頁翻,重複看幾遍。其實不是這樣,每次反覆應該讓本身換一個高度,第一次翻的時候能夠站在很高的高度,看一本書甚至只須要1天的時間,重複幾回後,站的高度應該越低,極可能看一個章節須要1天時間,甚至有時候看一頁就須要1天的時間。
- 一本書的目錄就像你在沙漠中的指南針,不要忽略目錄的做用。每次翻開書,在決定本身看什麼以前,花點時間瀏覽下目錄,讓本身回憶(瞭解)要看的章節的架構,帶着這個結構去學習事半功倍。
- 帶着問題去看書,這點很難,由於提什麼樣的問題和你選擇的高度密切相關,站的高度越高,那就越不要給本身提一些細節性的問題,反之則反之。
2.如何看代碼
若是開始看代碼,必定要記住,本身已經站在一個很是底層的高度度了,可以有能力閱讀代碼,就意味着你必須對總體的結構有比較清晰的認識,若是你都不知道這個結構,那看代碼爲時太早。
不管是什麼樣的代碼,其實思路都很相似,即便Linux內核是用C這種面相過程的語言編寫,可是這麼多年發展下來,Linux內核已經帶有了大量面對對象編程的特色。
在看代碼的時候也是有兩種不一樣的高度能夠選擇,我先解釋其中最細緻的一種:
(1)如何閱讀函數
一個函數寫下來常常上百行,可是你須要一行一行的看麼?確定不能,那清晰認識一個函數的結構就很重要。
一個函數就是爲了解決一個問題,函數名基本都能說明其功能,函數參數是輸入,返回值就是輸出,函數體就是總體的執行邏輯。在函數體內部,也基本都是相似的邏輯,先是對各類輸入參數進行檢查,而後書寫功能邏輯,而後構造輸出的結果。因此一個函數寫下來老是這樣的一種結構。
輸出結果 函數名(輸入)
{
if (輸入的參數有問題)
{
異常處理,跳出
}
準備參數
功能邏輯
構造輸出結果
返回輸出結果
}
一個函數其實就是一個方法,閱讀的難度比書寫的難度要低,書寫代碼須要考慮的問題很是多,可是在閱讀代碼的時候問題就簡單不少,不少書寫代碼過程當中須要考慮的問題在閱讀代碼的過程當中就不須要考慮 。
- 函數名:在書寫代碼過程當中須要考慮一個函數的函數名須要可以精確表達出這個函數所具有的功能,因此常常存在各類名目規範。而閱讀代碼過程則能夠經過閱讀函數名大體瞭解這個函數的功能。
- 註釋:在編寫代碼的時候,都會建議添加對應的函數註釋,解釋函數體的功能和一些注意事項;在閱讀過程當中能夠選擇性的閱讀這些註釋(注意:是選擇性閱讀,千萬不要每一個註釋都讀)
- 輸入參數:在書寫代碼的時候,這部分的內容也是很頭疼的內容,不只須要肯定須要哪些輸入,還須要輸入的形式,並且還須要精肯定義每一個輸入參數的語義;可是在閱讀代碼的過程當中,這部份內容基本能夠忽略,咱們不多會關係所看到的函數須要哪些參數輸入。
- 輸出結果:在書寫代碼的時候,這部分也是很頭疼的一件事,由於精肯定義輸出結果也是很是困難和麻煩的一件事;在閱讀代碼過程當中,也須要注意輸出結果,否則一個函數執行了老半天,結果連輸出結果是什麼都沒概念,也太失敗了點。
- 參數檢測:在編寫代碼過着中很是煩的一件事,每一個人都但願調用函數的人會傳入正確的參數,可是根本作不到,結果每次都要花費必定精力對輸入參數的邊界、非空等進行檢查;在閱讀代碼過程當中,根本不須要閱讀這部分的代碼,偏偏這部份內容在每一個函數體中佔據了至關一部分的位置;
- 參數準備:編寫代碼的過程當中,由於函數體內部的邏輯須要進行不少準備,因此經常須要有一個參數準備的過程;而閱讀代碼的過程基本能夠忽略這部分的邏輯,或者快速瀏覽這部分邏輯,這裏偏偏是不少新手花費大量精力糾纏的內容,其實不必在這裏糾結,跳過就好。
- 功能邏輯:這部分是函數體中最爲精華的部分,並且代碼編寫起來也是至關的麻煩,被各類邏輯弄的死去火來,最後還須要重構等等手段;在閱讀代碼過程當中,這部分其實很難把握,由於功能邏輯可能被封裝在另一個函數內部,這時候你們會習慣性的繼續深刻看,結果弄的本身更加混亂,又好比有的時候幾個功能邏輯點組成了一套邏輯,可是你們卻將這部分邏輯割裂來看,結果總感受讀的很彆扭。這部份內容須要一些經驗,可是有一個指導,就是在看這部分代碼的時候要注意本身所站的高度,選擇採用何種策略。
- 構造輸出結果:函數體內部還會花費大量的代碼進行對最後返回結果的構造工做,就像搭積木同樣;不過在閱讀代碼的時候,咱們並不須要花費太多精力在這些邏輯上,多注意注意一些返回結果的語義。
閱讀代碼還有不少技巧,例如如何在帶有goto語句的代碼中快速理解邏輯,如何界定那些註釋是能夠忽略的,如何將一些代碼邏輯當作一塊總體內容,什麼時候應該跳到更深的一層函數閱讀等等。這些都須要平時的經驗積累。
(2)如何在大量的代碼中游刃有餘
看代碼有一個粒度問題,咱們不能一行一行的看,也不能一個一個函數的看,我以前提到了,Linux內核有大量面向對象編程的影子,因此在看大量代碼的時候,必須學會面向對象編程的思惟模式。這樣對本身在大量代碼閱讀中提供大量參考意見。
或許有人會告訴你,面向對象編程就是弄明白什麼是對象、如何寫一個class就能夠了。確實,學習面向對象編程,弄明白對象是基礎,不過我以爲能夠再拔高一點,理解一些更抽象的概念,在這些抽象概念的指導下去學習,能夠有更多的指導意義。
- 層:層並非面向對象編程特有,可是理解層是很重要的,咱們遇到的典型的層就是網絡協議棧,爲何咱們網絡協議會有那麼多層,就由於須要處理的事情太多,咱們不得不將內容一塊塊的分割,分割的時候,發現用層進行組織,可讓結構更加清晰,因此你之後會發現,大量的系統都會帶有層的味道。linux內核中帶有大量的層設計,如網絡協議棧有層,內存管理與尋址有層,文件I/O也有層。
- 領域模型:領域模型就是一個系統中最爲核心的幾個抽象實體,一個系統,基本就是圍繞着領域模型展開,在學習內核不一樣的子系統的時候,必定要花大量的精力在領域模型上,切記!!!在Linux內核上也有大量的領域模型,例如在虛擬文件系統部分存在4大抽象inode,dentry,file等。在進程調度系統的最核心抽象是task_struct。在進程地址空間則有mm_struct,address_space等這些核心的領域模型。我感受能夠花費80%的時間在理解這些領域模型上。
- 領域驅動類:領域模型內部實際上是大量的屬性組成,可是若是隻有屬性,沒有一個執行的方法,那這個領域模型也不能發揮做用,面向對象編程的作法就是將這些方法編程領域驅動類,說的直白一些就是接口。在Linux中就是那些函數指針和對應的回調函數。平時看代碼,你們會花費大量的時間去看各個回調函數,這個實際上是吃力不討好的辦法,與其花大量的心思去看各個回調函數的實現,不如多思考下,爲何會有這些操做方法,它們是如何抽象出來的。
若是可以理解上述的這幾個抽象,那在大量代碼中如何遊刃有餘就相對容易了,有一個簡單的套路:
(1) 在較高的角度,弄明白一個系統爲了解決什麼問題,應該有哪些抽象
(2) 在對總體結構有所瞭解之後,花心思看看這些抽象對應的領域模型,由於通常狀況領域模型很龐大,因此看的時候也須要有步驟的進行拆解學習。
(3) 在對領域模型有所瞭解後,開始看領域驅動類,想明白爲何會有這些操做。
(4) 在上述準備好後,就能夠花費一些時間去看各個函數的具體實現,而且在看的過程當中多思考領域模型爲何這麼設計。
- 1. 談談如何學習Linux內核
- 2. 談談Tomcat內核
- 3. 談談Linux內核驅動的coding style
- 4. 獻給初學者:談談如何學習Linux
- 5. 談談如何學Linux和它在如今社會的影響
- 6. 談談Linux內存釋放
- 7. 獻給初學者:談談如何系統學習大數據?
- 8. 漫談Linux內核哈希表(1)
- 9. Linux內核分析方法談
- 10. 淺談 Linux 內核無線子系統
- 更多相關文章...
- • XSD 如何使用? - XML Schema 教程
- • 如何僞造ARP響應? - TCP/IP教程
- • 三篇文章瞭解 TiDB 技術內幕 —— 談調度
- • 漫談MySQL的鎖機制
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 談談如何學習Linux內核
- 2. 談談Tomcat內核
- 3. 談談Linux內核驅動的coding style
- 4. 獻給初學者:談談如何學習Linux
- 5. 談談如何學Linux和它在如今社會的影響
- 6. 談談Linux內存釋放
- 7. 獻給初學者:談談如何系統學習大數據?
- 8. 漫談Linux內核哈希表(1)
- 9. Linux內核分析方法談
- 10. 淺談 Linux 內核無線子系統