Generative Adversarial Nets[pix2pix]
本文來自《Image-to-Image Translation with Conditional Adversarial Networks》,是Phillip Isola與朱儁彥等人的做品,時間線爲2016年11月。 做者調研了條件對抗網絡,將其做爲一種通用的解決image-to-image變換方法。這些網絡不止用來學習從輸入圖像到輸出圖像的映射,同時學習一個loss函數去訓練這個映射。這讓傳統須要各類不一樣loss函數的問題變成了能夠採用統一方法來解決成爲可能。做者發現這種方法在基於標籤maps合成圖片,從邊緣圖像重建目標以及着色圖像等方面很是有效。html
0 引言
圖像處理,計算機圖形學,計算機視覺中不少問題能夠當作是將輸入圖像「轉換」到輸出圖像上。如將RGB圖像轉換到梯度圖像,邊緣圖像,或者語義標籤map等等。而傳統解決image-to-image的問題是將該問題劃分紅幾個子問題(如[15, 24, 19, 8,10, 52, 32, 38, 17, 57, 61]),其實都是同樣的,即從pixels預測pixels。算法
<center/></center> 本文的目標是提倡一種通用架構來解決這些問題。而基於CNN的方法,還必須告知目標函數是什麼,可是卻必須當心的設計,由於假如讓CNN最小化預測值和ground-truth之間的歐式距離,那麼回致使獲得模糊的預測圖片,由於歐式距離最小化時基於全部可能的輸出上平均值最小,那麼就會致使模糊圖片生成。隨之而來的loss函數就強制讓CNN作一些設定的行爲,如輸出圖片的銳化等等,而這是一直未完美解決的問題。網絡
而若是讓模型本身去學習所須要的loss函數,咱們只須要告知這個圖片是真的仍是假的,那麼就十分完美了,最近的GAN[12,23,43,51,62]就是幹這個事情的。這時候模糊的圖片就會很容易被判別器給否掉了。即讓生成器本身去學習內在的loss函數去自適應對應的數據集。本文做者兩個目的:架構
- 證實條件GAN能夠解決不少這類問題,並生成能夠接受的結果;
- 提出一個簡單的框架去獲得好的結果,並分析幾個重要的結構選擇。
0.5 前人工做
關於圖像建模的結構化loss image-to-image變換問題一般被整理成逐像素分類或者回歸問題[27,34,38,57,61]。這些形式化描述將輸出空間視爲「非結構化」,即在給定輸入圖像的狀況下,每一個輸出像素被視爲在條件上獨立於全部其餘輸出像素。條件GAN是學習一個結構化loss(structured loss),結構化loss會懲罰輸出的聯合設置。大量的文獻都考慮這種loss,如條件隨機場[9],SSIM指標[55],特徵匹配[14],非參數化loss[36],卷積僞先驗[56],基於匹配協方差統計的損失[29]。條件GAN不一樣於學到的loss,理論上,其實懲罰介於輸出和目標之間任何可能的不一樣結構。框架
條件GAN 前人早就將條件GAN用在如離散標籤[12,22,40],文本[45],和圖像等等。圖像條件的模型是從一個標準map進行圖像預測[54],將來幀預測[39],產品照片生成[58],從稀疏標註中進行圖片生成[30,47](文獻[46]中式用一個自動迴歸方法來解決這個問題)。其餘雖然也有將GAN用在image-to-image上,可是隻用無約束GAN,並依賴其餘項(如L2迴歸)來強制輸出是約束於輸入的。這些文獻在如圖像修復[42],將來狀態預測[63],基於用戶操做的圖像編輯[64],風格轉換[37]和超分辨率[35]。每一個方法都只適用具體領域。本文方法但願作到普適,同時這就須要比那些方法相對簡單。less
不一樣於以前的幾種生成器和判別器的結構選擇,本文的生成器使用的是U-Net結構[49];判別器使用的是卷積「PatchGAN」分類器,其只懲罰在圖像塊尺度規模上的結構。一個相似的PatchGAN結構在文獻[37]中早就有所說起,其實爲了抓取局部類型統計。本文展現該方法能夠適用更普遍的問題,還分析了更改patch size帶來的影響。dom
1 本文方法
GAN是生成模型,能夠學習一個隨機噪音向量$z$到輸出圖像$y$的映射:$G:z \rightarrow y$。而條件GAN是基於觀測的圖片$x$和隨機噪音向量$z$,學習映射到$y$:$G:{x,z}\rightarrow y$。該訓練過程如圖2.ide
<center/>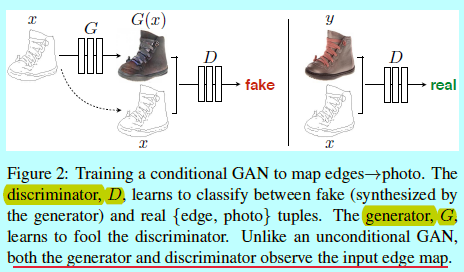</center>函數
1.1 目標函數
一個條件GAN的目標函數能夠表示爲:學習
<center/>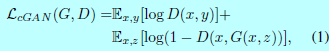</center> 這裏G試圖最小化該目標函數,而D試圖最大化該目標函數,即$G^*=\arg \min_G\max_D\mathcal{L}_cGAN(G,D)$
爲了測試條件(conditioning)判別器的重要性,須要對比一個無條件變化的判別器,即其沒有觀測變量$x$:
<center/>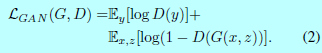</center> 以前的文獻已經證明將GAN的目標函數與一些其餘loss(如l2距離)混合起來是有好處的[42]。判別器的工做依然沒變,可是生成器不止須要愚弄判別器,還須要在受到L2約束下接近ground-truth。本文采用L1距離,由於L1能減小輸出的圖片模糊: <center/>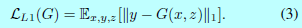</center> 最終的目標函數爲: $$G^*=\arg\min_G\max_D\mathcal{L}_cGAN(G,D)+\lambda\mathcal{L}_{L1}(G), \,\, \tag{4}$$
沒有$z$,該GAN仍是學到從$x$映射到$y$的映射,不過會生成判別性輸出,所以會沒法匹配除了delta函數的其餘任何分佈。以前的條件GAN意識到了這點,因此給生成器在$x$以外,提供高斯噪音$z$做爲輸入。在初始實驗中,做者並未找到該策略的有效性,即讓生成器簡單忽略該噪音,這與Mathieu的論證吻合[39]。在本文最終模型中,做者只在在訓練和測試階段的生成器的幾層的dropout項中採用噪音。儘管存在dropout噪音,做者只在輸出上觀察到微小的隨機性。設計的條件GAN能夠提供高隨機性輸出,從而捕獲它們建模的條件分佈的完整熵,是當前工做還沒解決的問題。
1.2 網絡結構
做者調整了[43]中的生成器和判別器結構,判別器和生成器同時使用convolution-BatchNorm-ReLU形式的模塊。
1.2.1 帶有skips的生成器
image-to-image轉換問題的一個定義特徵是它們將高分辨率輸入網格映射到高分辨率輸出網格。另外,輸入和輸出雖然看起來結果不一樣,不過底層結構都是差很少的。所以,做者設計生成器的結構也是這個思路。 許多前人的工做[29,42,54,58,63]都是基於編碼器-解碼器網絡。這樣的網絡結構中,輸入通過許多層慢慢下采樣,直到一個bottleneck層,而後再逆轉這個操做。這樣的網絡須要全部的信息通過全部層,包含bottleneck。對於許多圖像轉換問題,在輸入和輸出之間共享大量低級信息是一個很好的想法,而且但願直接在網絡上傳送該信息。例如,圖像着色桑,輸入和輸出是共享突出邊緣的位置的。
<center/>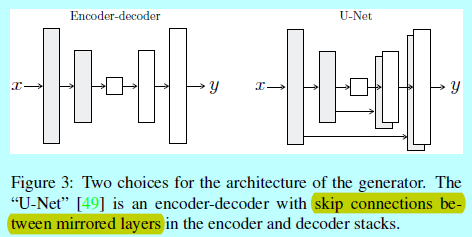</center> 爲了讓生成器有一種規避bottleneck的方法,增長了skip的鏈接,形狀如U-Net[49](如圖3)。特別的,在層$i$和層$n-i$之間增長skip 鏈接,這裏$n$是層的總量。每一個skip鏈接簡單的將層$i$與層$n-i$之間全部的通道進行concatenation。
1.2.2 馬爾可夫判別器(PatchGAN)
衆所周知L2 loss(看圖4,L1也會模糊)會讓圖像生成問題中生成的圖像變得模糊,雖然這些loss不能準確的抓取高頻紋理,但是他們仍是可以抓取低頻輪廓的。對於這種狀況,不須要一個全新的框架來強制低頻的正確性,L1就夠了。
<center/></center> 那麼受其啓發,讓GAN判別器只對高頻結構進行建模,讓L1項去對低頻進行建模,如式子4。爲了對高頻進行建模,須要將注意力限制到局部圖像塊上。所以,做者設計出一個判別器結構,這裏稱其爲PatchGAN,只懲罰圖像塊尺度上的結構。該判別器試圖區分是否圖像中每一個$N\times N$塊是真的仍是假的。將該判別器以卷積方式劃過整個圖像,平均全部的響應來提供判別器最終的輸出。
在後面,證實了雖然N能夠遠小於圖片的完整size,但是仍然能夠生成高質量的結果。這是有利的,由於更小的PatchGAN有着更少的參數,運行更快,能夠應用在任意大的圖像。 這樣鑑別器有效地將圖像建模爲馬爾可夫隨機場,其是假設像素之間的獨立可分性性超過了塊的直徑。這種聯繫在文獻[37]中有所探討,一樣對紋理模型[16,20]和風格[15,21,24,36]也有常見假設。PatchGAN所以能夠理解成一種紋理/風格 loss形式。
1.3 優化和推論
爲了優化該網絡,遵循標準方法:交替的迭代,先在D上迭代一次,而後在G上迭代一次。如最初始GAN中所述,訓練G時,不最小化$log(1-D(x,G(x,z)))$,而是最大化$\log D(x,G(x,z))$。另外,在優化D時,將目標除以2,這讓D相對G而言減慢了速度。本文使用minibatch SGD和Adam解析器,學習率爲0.0002,動量參數分別爲$\beta_1=0.5,\beta_2=0.999$。
在推論階段,運行生成器,其配置如訓練過程一致。這不一樣於傳統的,在測試時候也仍是用dropout,而且基於測試batch使用BN,而不是用訓練時候的batch。當batchsize設置爲1時,BN被稱爲「實例標準化」,而且已被證實在圖像生成任務中有效[53]。 在本實驗中,根據實驗使用1到10之間的batchsize。
2 實驗
爲了研究條件GAN的泛化性,做者在不少任務和數據集上進行了測試,包含圖形任務,如相片生成;視覺任務,如語義分割:
- 語義 labels$\leftrightarrow $photo, 基於Cityscapes數據集[11];
- 建築 labels$\leftrightarrow $photo,基於CMP Facades[44];
- Map$\leftrightarrow $aerial photo, 從谷歌地圖爬取的數據;
- BW$\rightarrow $color photos,基於[50]訓練;
- Edges$\rightarrow $ photo, 訓練數據來自[64,59];二值邊緣使用HED邊緣檢測器[57]加上後處理完成的;
- Sketch$\rightarrow $photo,測試 edges$\rightarrow $photo 人類繪製的模型來自[18];
- Day$\rightarrow $ night,基於[32];
- thermal$\rightarrow $color photos,訓練數據來自[26];
- photo withmissing pixels $\rightarrow $ inpainted photo,基於Paris streetview,來自[13].
每一個數據集的詳細訓練過程在附錄材料中。在全部狀況中,輸入和輸出都是1-3通道的圖片。結果在圖8,9,10,11,12,13,14,15,16,17,18,19中。
<center/>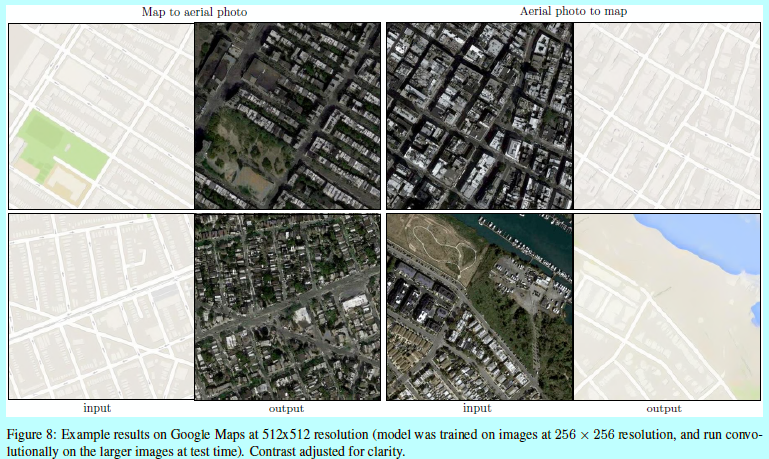           </center> 在圖20中,是幾個失敗的案例。 <center/></center>
數據要求和速度 即便在小型數據集上也能夠得到不錯的結果。 其中正面訓練集只包含400張圖片(結果在圖13)。 而day to night訓練集之包含91張圖片(結果在圖14)。這種量級的數據集下,訓練天然是很快的;例如圖13中的結果只須要在單張titian x gpu上訓練小於2個小時就夠了,在測試階段,全部的模型之須要少於1s的時間。
2.1 評估指標
評估合成圖片的質量一直是一個未解決的難題[51]。傳統的評估指標如逐像素均值平方偏差不會評估結果的聯合統計信息,因此不會測量這個意在抓取結構化loss的結構。爲了更全面地評估結果的視覺質量,做者採用了兩種策略:
- 首先,在亞馬遜標註平臺上(Amazon Mechanical Turk,AMT)運行"real vs fake"項目,其中涉及的圖形問題,如着色和照片生成,讓真人來給出結果,這裏的map生成,aerial photo 生成和圖像着色都是用這個方法;
- 其次,基於現有的識別系統測量是否生成的cityscapes足夠真實。該指標類似於[51]中的"inception score",[54]中的目標檢測評估,[61,41]中的「semantic interpretability」評估。
AMT perceptual studies 對於AMT實驗,遵循[61]的協議方式:給Turker展示的是一系列圖片,其實包含真實和生成的。每次測試,每張圖片只出現1s,而後圖片會消失,這時候讓Turker在後續時間中給出那一張是假的。略
在着色實驗中,真實和假的圖片都從一樣的灰度輸入上生成;對於Map$\leftrightarrow $aerial photo,真實和假的圖片不是從一樣的輸入上生成的,爲了讓任務變得更困難,和避免floor-level現象,是基於256x256分辨率圖片訓練的,可是利用全卷積變換在512x512的分辨率上測試,而後下采樣並以256x256分辨率呈現給Turker。對於着色,是在256x256分辨率上訓練和測試,並以一樣的分辨率呈現給Turker。
FCN-score 近些的工做[51,54,61,41]嘗試使用預訓練的語義分類器去測量。直觀的原理是若是生成的圖像是真實的,基於真實圖片訓練的分類器能夠很好的區分合成的圖片。本文采用主流的作語義分割的FCN-8s[38]結構,基於cityscapes數據集訓練。而後經過對合成的圖片進行分類來區分是不是合成的。
2.2 目標函數的分析
那麼式子4中哪部分是最重要的?做者經過每次丟失一項來分別研究L1項,GAN項的影響,而後將無條件GAN(式子2)與條件GAN(式子1)上的判別器進行對比。 圖4表示在$labels \rightarrow photo$問題上不一樣變化的影響,L1會生成合理可是很模糊的結果。cGAN(此時式子4中$\lambda=0$)會生成更銳化的結果,可是在某些應用上會引入視覺造假的狀況。將這兩項合起來($、lambda=100$)能夠減小這種造假現象。
做者在cityscapes $labels \rightarrow photo$任務上使用FCN-score方式進行評估質量(如表1)。
<center/>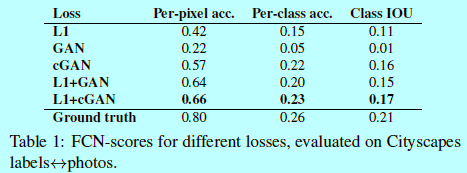</center> 如表1,基於GAN的目標能夠得到更高的得分,代表合成的圖片包含更多可識別的結構。同時做者測試了從判別器D上移除條件以後(稱其爲GAN)的影響。在這種狀況下,loss不會懲罰輸入和輸出之間的誤匹配,而這種結果十分很差;經過檢測該結果發現生成器會坍縮到接近準確輸出的位置,而全不顧輸入是什麼狀況(即騙過判別器,但是沒視覺意義)。因此能夠發現這種狀況下,loss其實是測量輸入和輸出之間的匹配質量,的確cGAN比GAN好太多。然而,增長的L1項代表輸出會更關心輸入,由於L1 loss會懲罰ground-truth與合成輸出之間的距離(其中ground-truth與輸入是項匹配的,而合成輸出並非,因此經過懲罰合成輸出與ground-truth,等於間接強制合成輸出去匹配輸入部分)。L1+GAN一樣會生成關於輸入label的合成輸出。因此結合全部項,L1+cGAN是最好的。
色彩 條件GAN的一個影響是它還能生成清晰的圖片,超分辨空間結構即便在輸入label map中並不存在。咱們能夠想象cGAN在空間維度上有相似"銳化"的效果,即讓圖像更具色彩性。就如L1在某個位置不肯定是什麼邊緣紋理時會賦予模糊同樣,當不肯定像素應該採用的幾個合理顏色值中的哪個時,它也會賦予平均的淺灰色。具體而言,L1會經過選擇基於可能的顏色基礎上條件機率密度函數的中值來達到最小化的目的。另外一方不,對抗Loss能夠在實際中對那些非真實淺灰色輸出變得敏感,並傾向匹配真實顏色分佈。
<center/>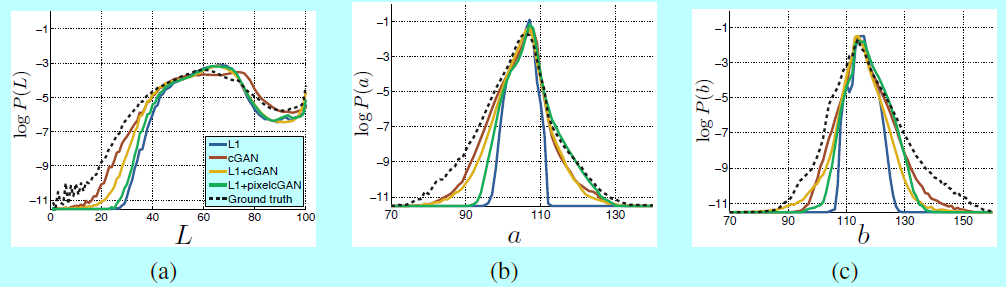  </center> 圖7中,做者調研了是否cGAG能夠在Cityscapes數據集上得到這樣的效果。該圖顯示了在Lab顏色空間中基於輸出顏色上的邊際距離。很明顯L1會生成ground-truth更窄的分佈,這也證實了L1的確會傾向生成平均,淺灰色顏色。另外一方面,使用cGAN會將輸出分佈更推向ground-truth。
2.3 生成器結構的分析
U-Net結構運行low-level的信息可以快捷(shortcuts)的穿插於網絡中。不過這會讓結果更好麼?
<center/> 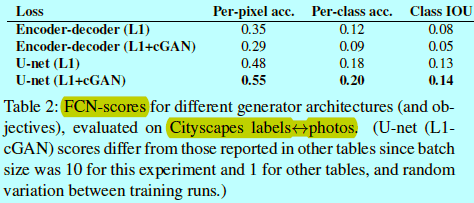</center> 圖5和表2對比了在cityscape生成上編碼-解碼器與U-Net的結構效果。其中編碼-解碼器是基於U-Net切斷其中的skip鏈接實現的。能夠發現編碼-解碼器不能生成真實的圖片,而U-Net的優點不僅限於讓cGAN變得更好:不過當U-Net和編碼-解碼器都基於L1 loss訓練時,U-Net得到更好的效果。
2.4 從pixelGAN到PatchGAN到ImageGAN
做者測試了變化判別器感覺野的patch size N帶來的影響,從1x1的PixelGAN到一個完整的286x286的ImageGAN。
<center/></center> 圖6顯示了這些差異的結果。 <center/>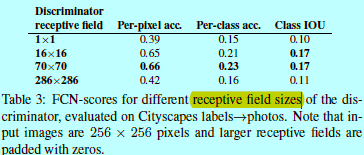</center> 表3基於FCN-score對結果進行了評估。除非特別之處,本文中都基於70x70的PatchGAN進行實驗,並採用L1+cGAN做爲loss。 PixelGAN無心於空間清晰度,可是提高告終果的多彩性(如圖7)。例如圖6中,bus在使用L1 loss時是灰色的,而用PixelGAN是紅色的。顏色直方圖匹配是圖像處理中一個常見的問題,PixelGAN是一個輕量級的解決方法。 使用16x16的PatchGAN足以提高結果的銳化程度並得到好的FCN-scores,可是也會生成造假的現象。70x70 PatchGAN會減輕造假現象,並得到稍微更好的得分結果。對於286x296的ImageGAN,不會明顯提高結果的視覺質量,的確也會獲得相對較低的FCN-scores。這多是由於ImageGAN有更多參數和更深的通道,因此更難訓練。
全卷積變換 PatchGAN的一個優點是一個固定size的patch 判別器能夠應用到任意大小的圖像上。一樣做者會將該生成器應用在比訓練時候更大的圖像上。做者在$map \leftrightarrow aerial photo$任務上。在256x256圖像上訓練好一個生成器,在512x512上進行測試。圖8展現了該方法的效果。
2.5 感知驗證(Perceptual validation)
做者在$map \leftrightarrow aerial photograph$和$grascale \rightarrow color$任務結果上進行了感性真實性的驗證。基於AMT對$map \leftrightarrow aerial photograph$進行評估的結果在表4。
<center/></center> aerial photos中用算法生成的圖片愚弄了18.9%的真人,明顯高於L1的結果;在$photo \rightarrow map$方向中,本方法只愚弄了6.1%的真人,這相比L1的方法就並沒高太多。這多是由於在map中微小的結構化偏差會更明顯,由於map(地圖)有網格幾何,而aerial photographs相比更混亂一些。
做者在ImageNet上訓練了着色,並經過[61,34]引入了測試分割進行測試。本文方法,基於L1+cGAN,愚弄了22.5%的真人(表5).
<center/></center> 同時測試了[61]的結果,和基於[61]的方法使用L2 loss的變種。cGAN得分類似於[61]的L2變種(不過在自舉測試上有明顯的不一樣),可是要比[61]的方法要短,只愚弄了27.8%的貞二年。做者發現他們的方法在着色上有特別的工程實現。
2.6 語義分割
cGAN在那些輸出是高度細節相關或者photographic的問題上有效果,而這在圖像處理和圖形任務中是很廣泛的,那麼對於視覺任務,如語義分割,其中輸出要比輸入相對簡單。 爲了作該任務測試,在cityscape $photo \rightarrow labels$上訓練cGAN(分有和沒L1 loss)。圖10就是對應結果,定量分類準確度在表6.
<center/>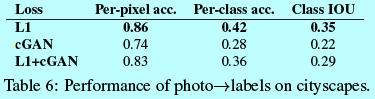</center> 有趣的是,基於沒有L1 loss下訓練的cGAN獲得一個相對合理的準確度結果。雖然cGAN得到很多成功,還遠不到最好解決的程度:如表6中,簡單實用L1迴歸能夠獲得比cGAN更好的結果。做者認爲對於視覺任務,目標(預測的輸出接近ground-truth)相比圖形任務沒那麼模糊,因此重構loss如L1會更有效。
2.7 社區驅動研究
略
reference:
[1] Bertrand gondouin. https://twitter.com/ bgondouin/status/818571935529377792. Accessed, 2017-04-21. 9 [2] Brannon dorsey. https://twitter.com/ brannondorsey/status/806283494041223168. Accessed, 2017-04-21. 9 [3] Christopher hesse. https://affinelayer.com/ pixsrv/. Accessed: 2017-04-21. 9 [4] Gerda bosman, tom kenter, rolf jagerman, and daan gosman. https://dekennisvannu.nl/site/artikel/ Help-ons-kunstmatige-intelligentie-testen/ 9163. Accessed: 2017-08-31. 9 [5] Jack qiao. http://colormind.io/blog/. Accessed: 2017-04-21. 9 [6] Kaihu chen. http://www.terraai.org/ imageops/index.html. Accessed, 2017-04-21. 9 [7] Mario klingemann. https://twitter.com/ quasimondo/status/826065030944870400. Accessed, 2017-04-21. 9 [8] A. Buades, B. Coll, and J.-M. Morel. A non-local algorithm for image denoising. In CVPR, volume 2, pages 60–65. IEEE, 2005. 1 [9] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2015. 2 [10] T. Chen, M.-M. Cheng, P. Tan, A. Shamir, and S.-M. Hu. Sketch2photo: internet image montage. ACM Transactions on Graphics (TOG), 28(5):124, 2009. 1 [11] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR), 2016. 4, 16 [12] E. L. Denton, S. Chintala, R. Fergus, et al. Deep generative image models using a laplacian pyramid of adversarial networks. In NIPS, pages 1486–1494, 2015. 2 [13] C. Doersch, S. Singh, A. Gupta, J. Sivic, and A. Efros. What makes paris look like paris? ACM Transactions on Graphics, 31(4), 2012. 4, 13, 17 [14] A. Dosovitskiy and T. Brox. Generating images with perceptual similarity metrics based on deep networks. arXiv preprint arXiv:1602.02644, 2016. 2 [15] A. A. Efros and W. T. Freeman. Image quilting for texture synthesis and transfer. In SIGGRAPH, pages 341–346. ACM, 2001. 1, 4 [16] A. A. Efros and T. K. Leung. Texture synthesis by nonparametric sampling. In ICCV, volume 2, pages 1033–1038. IEEE, 1999. 4 [17] D. Eigen and R. Fergus. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, pages 2650–2658, 2015. 1 [18] M. Eitz, J. Hays, and M. Alexa. How do humans sketch objects? SIGGRAPH, 31(4):44–1, 2012. 4, 12 [19] R. Fergus, B. Singh, A. Hertzmann, S. T. Roweis, and W. T. Freeman. Removing camera shake from a single photograph. ACM Transactions on Graphics (TOG), 25(3):787– 794, 2006. 1 [20] L. A. Gatys, A. S. Ecker, and M. Bethge. Texture synthesis and the controlled generation of natural stimuli using convolutional neural networks. arXiv preprint arXiv:1505.07376, 12, 2015. 4 [21] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. CVPR, 2016. 4 [22] J. Gauthier. Conditional generative adversarial nets for convolutional face generation. Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter semester, 2014(5):2, 2014. 2 [23] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D.Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014. 2, 4, 6, 7 [24] A. Hertzmann, C. E. Jacobs, N. Oliver, B. Curless, and D. H. Salesin. Image analogies. In SIGGRAPH, pages 327–340. ACM, 2001. 1, 4 [25] G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006. 3 [26] S. Hwang, J. Park, N. Kim, Y. Choi, and I. So Kweon. Multispectral pedestrian detection: Benchmark dataset and baseline. In CVPR, pages 1037–1045, 2015. 4, 13, 16 [27] S. Iizuka, E. Simo-Serra, and H. Ishikawa. Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification. ACM Transactions on Graphics (TOG), 35(4), 2016. 2 [28] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. 2015. 3, 4 [29] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. 2016. 2, 3 [30] L. Karacan, Z. Akata, A. Erdem, and E. Erdem. Learning to generate images of outdoor scenes from attributes and semantic layouts. arXiv preprint arXiv:1612.00215, 2016. 2 [31] D. Kingma and J. Ba. Adam: A method for stochastic optimization. ICLR, 2015. 4 [32] P.-Y. Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Transactions on Graphics (TOG), 33(4):149, 2014. 1, 4, 16 [33] A. B. L. Larsen, S. K. Sønderby, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015. 3 [34] G. Larsson, M. Maire, and G. Shakhnarovich. Learning representations for automatic colorization. ECCV, 2016. 2, 8, 16 [35] C. Ledig, L. Theis, F. Husz´ar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802, 2016. 2 [36] C. Li and M. Wand. Combining markov random fields and convolutional neural networks for image synthesis. CVPR, 2016. 2, 4 [37] C. Li and M. Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. ECCV, 2016. 2, 4 [38] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431– 3440, 2015. 1, 2, 5 [39] M. Mathieu, C. Couprie, and Y. LeCun. Deep multi-scale video prediction beyond mean square error. ICLR, 2016. 2, 3 [40] M. Mirza and S. Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014. 2 [41] A. Owens, P. Isola, J. McDermott, A. Torralba, E. H. Adelson, and W. T. Freeman. Visually indicated sounds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2405–2413, 2016. 5 [42] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros. Context encoders: Feature learning by inpainting. CVPR, 2016. 2, 3, 13, 17 [43] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015. 2, 3, 16 [44] R. ˇ S. Radim Tyleˇcek. Spatial pattern templates for recognition of objects with regular structure. In Proc. GCPR, Saarbrucken, Germany, 2013. 4, 16 [45] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. arXiv preprint arXiv:1605.05396, 2016. 2 [46] S. Reed, A. van den Oord, N. Kalchbrenner, V. Bapst, M. Botvinick, and N. de Freitas. Generating interpretable images with controllable structure. Technical report, Technical report, 2016. 2, 2016. 2 [47] S. E. Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele, and H. Lee. Learning what and where to draw. In Advances In Neural Information Processing Systems, pages 217–225, 2016. 2 [48] E. Reinhard, M. Ashikhmin, B. Gooch, and P. Shirley. Color transfer between images. IEEE Computer Graphics and Applications, 21:34–41, 2001. 7 [49] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241. Springer, 2015. 2, 3 [50] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. IJCV, 115(3):211–252, 2015. 4, 8, 16 [51] T. Salimans, I. Goodfellow,W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training gans. arXiv preprint arXiv:1606.03498, 2016. 2, 4, 5 [52] Y. Shih, S. Paris, F. Durand, andW. T. Freeman. Data-driven hallucination of different times of day from a single outdoor photo. ACM Transactions on Graphics (TOG), 32(6):200, 2013. 1 [53] D. Ulyanov, A. Vedaldi, and V. Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022, 2016. 4 [54] X. Wang and A. Gupta. Generative image modeling using style and structure adversarial networks. ECCV, 2016. 2, 3, 5 [55] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004. 2 [56] S. Xie, X. Huang, and Z. Tu. Top-down learning for structured labeling with convolutional pseudoprior. 2015. 2 [57] S. Xie and Z. Tu. Holistically-nested edge detection. In ICCV, 2015. 1, 2, 4 [58] D. Yoo, N. Kim, S. Park, A. S. Paek, and I. S. Kweon. Pixellevel domain transfer. ECCV, 2016. 2, 3 [59] A. Yu and K. Grauman. Fine-Grained Visual Comparisons with Local Learning. In CVPR, 2014. 4 [60] A. Yu and K. Grauman. Fine-grained visual comparisons with local learning. In CVPR, pages 192–199, 2014. 16 [61] R. Zhang, P. Isola, and A. A. Efros. Colorful image colorization. ECCV, 2016. 1, 2, 5, 7, 8, 16 [62] J. Zhao, M. Mathieu, and Y. LeCun. Energy-based generative adversarial network. arXiv preprint arXiv:1609.03126, 2016. 2 [63] Y. Zhou and T. L. Berg. Learning temporal transformations from time-lapse videos. In ECCV, 2016. 2, 3, 8 [64] J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In ECCV, 2016. 2, 4, 16
- 1. Conditional Generative Adversarial Nets
- 2. Triangle Generative Adversarial Networks
- 3. Generative Adversarial Nets(譯)
- 4. paper:Conditional Generative Adversarial Nets
- 5. Generative Adversarial Nets[CycleGAN]
- 6. Graphical Generative Adversarial Networks
- 7. Generative Adversarial Nets_GAN_paperReading
- 8. Generative Adversarial Nets
- 9. cGAN:Conditional Generative Adversarial Nets
- 10. Contrastive Generative Adversarial Networks
- 更多相關文章...
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Conditional Generative Adversarial Nets
- 2. Triangle Generative Adversarial Networks
- 3. Generative Adversarial Nets(譯)
- 4. paper:Conditional Generative Adversarial Nets
- 5. Generative Adversarial Nets[CycleGAN]
- 6. Graphical Generative Adversarial Networks
- 7. Generative Adversarial Nets_GAN_paperReading
- 8. Generative Adversarial Nets
- 9. cGAN:Conditional Generative Adversarial Nets
- 10. Contrastive Generative Adversarial Networks