360 智能商業業務線經驗分享:TiDB 寫熱點調優實戰
做者介紹:代曉磊,現 360 商業化數據庫運維專家,TiDB User Group Ambassador,負責整個智能商業業務線數據庫運維,解決各類數據庫疑難問題,推廣 TiDB 等新開源數據庫應用。
360 智能商業業務線從 2019 年 3 月份開始使用 TiDB,目前線上有 5 套 TiDB 集羣,數據總容量 20T,主要應用在數據分析平臺、廣告主實時報表、物料庫、實時監控平臺等核心業務中。python
在使用 TiDB 的過程當中,咱們也遇到過一些問題,積攢了一些經驗。因爲篇幅有限,下面主要分享寫熱點問題現象和對應的解決方案,但願可以能對其餘 TiDB 用戶有所幫助。sql
業務簡介以及數據庫選型
360 智能商業業務線廣告主實時報表業務簡介
廣告主關鍵詞實時統計報表業務的流程是:業務數據首先進入 Kafka,每 30 秒會有程序讀 Kafka 數據,並進行聚合,而後存儲到 TiDB 中,存儲到 TiDB 的過程每批次會有幾十萬的寫入,單表數據量 1.2~1.5 億。數據庫
業務寫入 SQL 主要是:insert on duplicate key update,Batch 爲 100,併發爲 300,而且天天建立一張新表進行寫入。寫入初期因爲沒有重複的 uniq_key,因此主要是 insert 。隨着數據量到達 2000 多萬,update 的操做也愈來愈多。安全
表結構以下:服務器

數據庫選型:MySQL or TiDB?
說到 TiDB 不得不提其架構。下面結合架構圖簡單介紹一下 TiDB 對於咱們來講最有吸引力的特性。架構

- 可在線擴展:TiDB Server/PD/TiKV 這 3 大核心模塊各司其職,而且支持在線擴容,region 自動 balance,遷移過程對業務無感知。
- 高可用:基於 Raft 的多數派選舉協議實現了金融級別的數據強一致性保證,且在不丟失大多數副本的前提下,能夠實現故障的自動恢復 (auto-failover),無需人工介入。
- 無縫遷移:支持 MySQL 協議,業務遷移無需修改代碼。
-
豐富的監控+運維工具:併發
- 監控:基於 Prometheus + Grafana 的豐富監控模板;
- 運維工具:TiDB Ansible 部署+運維;
- TiDB Data Migration(DM):將數據從 MySQL 遷移+同步的工具;
- TiDB Lightning:能夠從 CSV 文件或者第三方數據源將數據直接導入到 TiKV;
- TiDB Binlog:備份工具,也能夠重放到 Kafka/MySQL/TiDB 等數據庫。
TiDB 最核心的應用場景是:大數據量下的分庫分表,好比常常須要 1 拆 4,4 拆 8 等數據庫無限制拆分狀況,而且業務端還須要本身維護路由規則,TiDB 良好的擴展性解決了這些問題。運維
爲了能知足這麼大的寫入量,咱們其實曾經嘗試過單實例 MySQL 去抗請求,測試完後發現單實例 MySQL 壓力較大,若是要分散寫壓力且不改變架構,那麼又要走 MySQL 分庫分表這種老路,TiDB 3.0 GA 發佈以後,咱們拿離線數據進行了壓測,2 小時 1.5 億的數據存儲 (tps:2W/s),整個系統負載良好,因此咱們最終決定使用 TiDB。dom
系統配置及部署架構
服務器硬件配置curl
- CPU:E5-2630v2*2
- Mem:16G DDR3*8
-
Disk:
- Intel S3500 300G*1
- flash:寶存1.6T*1
- Net:1000M*2
服務器系統版本 :CentOS Linux release 7.4.1708 (Core)
TiDB 的版本 :tidb-ansible-3.0.0
規模 :2.8 億/天
存儲 :3.8T
TiDB 部署架構圖 :

注:PD 跟 TiDB 共用服務器
寫熱點問題優化實踐
熱點現象描述
業務方向咱們反饋從 7 月份開始, Kafka 隊列裏面有大量的數據累積,等待寫入TiDB。Kafka 高峯期的待寫入 lag 有 3000 多萬,接口的調用時間由以前的 1s 變成如今的 3s-5s。咱們登陸 TiDB 發現,單表的數據量由以前的 7000 飆升到 1.2-1.5 億,雖然數據量幾乎翻了一倍,但單條 insert 的性能應該不至於這麼差,因而開始着手定位問題。
下圖是 Kafka 當時的待寫入的 lag 狀況:

查看 Grafana Overview 監控,經過 TiKV 監控項 「scheduler pending commands」,發現 TiKV 227 節點大量等待的命令。

經過 TiKV 監控項「CPU 使用」也能夠看出熱點都集中在 227 這個 TiKV 節點上。

解決方案
通常來講有三個優化方法:手動 split 熱點、參數優化、表結構優化,你們能夠根據線上寫熱點表的表結構不一樣而採用不一樣的優化方案。
對於 PK 非整數或沒有 PK 的表,數據在 Insert 時,TiDB 會使用一個隱式的自增 rowid,大量的 Insert 會把數據集中寫入單個 Region,形成寫熱點。
此時可使用 SHARD_ROW_ID_BITS 來打散熱點,若是業務表能夠新建的話(好比咱們的報表業務是按天分表),能夠結合 pre-split-regions 屬性一塊兒在建表階段就將 Region 打散。若是不知足上面的表結構(好比就是以自增 ID 爲主鍵的表),可使用手動 split region 功能。上面的兩種方法都須要 PD 的參數調整來加快熱點 Region 的調度。
手動 split 熱點
由於咱們的表結構是 ID 自增主鍵,因此咱們先使用手動 split 熱點。
1. 找出熱點 TiKV 的 Store Number
在 tidb-ansible 的 scripts 目錄下 table-regions.py 腳本能夠查看熱點表和索引 Region 分佈狀況:
python table-regions.py --host=tidb_host –port=10080 db_name tb_name [RECORD – db_name.tb_name] - Leaders Distribution: total leader count: 282 store: 1, num_leaders: 1, percentage: 0.35% store: 4, num_leaders: 13, percentage: 4.61% store: 5, num_leaders: 16, percentage: 5.67% store: 7, num_leaders: 252, percentage: 89.36%
經過執行上面的命令,能查看熱點表都在 store 7(227 服務器) 這個 TiKV 節點。 2\. 查看熱點的表 Regions 分佈
curl http:// ${tidb_host}:10080/tables/db_name/tb_name/regions > regions.log
3\. 手動切分 Region 切分命令以下:
pd-ctl -u http:// ${pd_host}:2379 operator add split-region region_id
使用命令找出 Store7 的 Region ID:
grep -B 3 ": 7" regions.log |grep "region_id"|awk -F': ' '{print $2}'|awk -F',' '{print "pd-ctl -u http://pd_host:2379 operator add split-region",$1}' > split_region.sh
4\. 執行切分腳本就實現了 Region 切分
sh split_region.sh
**參數優化** 1\. 調整 PD 調度參數
pd-ctl -u http://pd_host:2379 config set 參數值
"hot-region-schedule-limit": 8
"leader-schedule-limit": 8,
"region-schedule-limit": 16
上面 3 個參數分別是控制進行 hot-region\leader\region 調度的任務個數。這個值主要影響相應 Region balance 的速度,值越大調度得越快,可是也不宜過大,能夠先增長一倍看效果。 2\. TiKV 參數之:sync-log 跟 MySQL 的 `innodb_flush_log_at_trx_commit(0,1,2)` 相似,TiDB 也有一個 sync-log 參數,該參數控制數據、log 落盤是否 sync。注意:若是是非金融安全級別的業務場景,能夠考慮設置成 false,以便得到更高的性能,但可能會丟數據。 該參數是 TiKV 參數,須要調整 tidb-ansible 下 conf 目錄中 tikv.yml,而後使用下面的命令,只滾動升級 TiKV 節點。
ansible-playbook rolling_update.yml --tags=tikv
>注:本次優化保持默認 `true`。 **下面介紹幾個查看參數優化效果的方式:** 1\. 經過命令查看 Leader 調度狀況
pd-ctl -u http:// ${pd_host}:2379 operator show leader
2\. 經過 Grafana 監控圖查看 在 PD 監控模塊中找到 Scheduler 模塊->Scheduler is running->balance-hot-region-scheduler,balance-hot-region-scheduler 有值,則表明有熱點 Region 調度,以下圖所示: 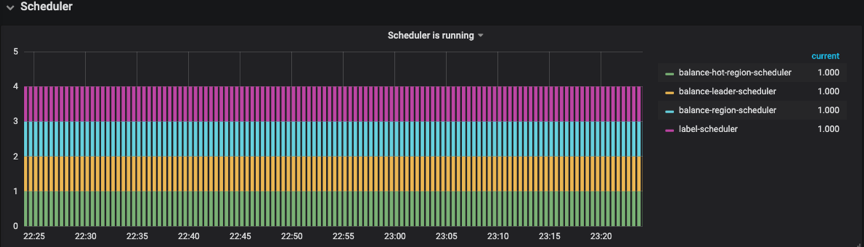 在 PD 監控模板中找到 Operator->Schedule operator create->balance-leader,這個參數表明以下圖所示: 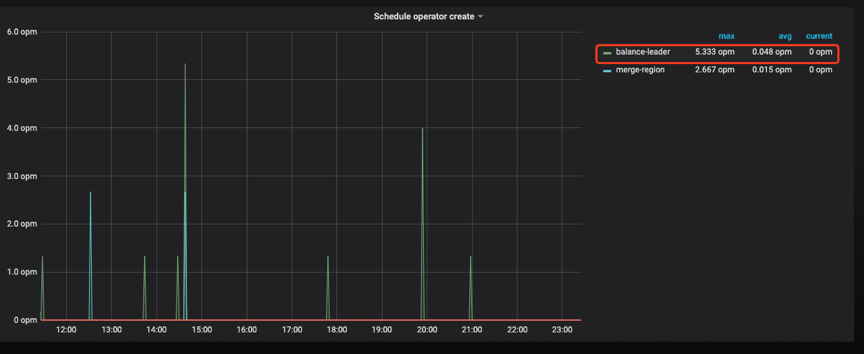 而後從 Overview 中,查看 TiKV 模塊的 Leader、Region,CPU、Scheduler Pending Commands 等變化狀況,對優化效果進行綜合分析。 #### 終極大招之表結構優化 咱們發現經過手 split 的方式並無較好地解決業務的寫熱點問題,因此又採用了`SHARD_ROW_ID_BITS` 結合 `PRE_SPLIT_REGION` 的方式來打散熱點。 對於 PK 非整數或沒有 PK 的表,在 insert 的時候 TiDB 會使用一個隱式的自增 rowid,大量 INSERT 會把數據集中寫入單個 Region,形成寫入熱點。經過設置 `SHARD_ROW_ID_BITS` 來適度分解 Region 分片,以達到打散 Region 熱點的效果。使用方式:
ALTER TABLE t SHARD_ROW_ID_BITS = 4; #值爲 4 表示 16 個分片
因爲咱們天天都會新建表,因此爲了更好的效果,也使用了 `PRE_SPLIT_REGIONS` 建表預切分功能,經過配置能夠預切分 `2^(pre_split_regions-1)` 個 Region。 下面是最新的表結構,其中最重要的優化是刪除了自增主鍵 ID,建表時添加了 `SHARD_ROW_ID_BITS` 結合 `PRE_SPLIT_REGION` 配置。 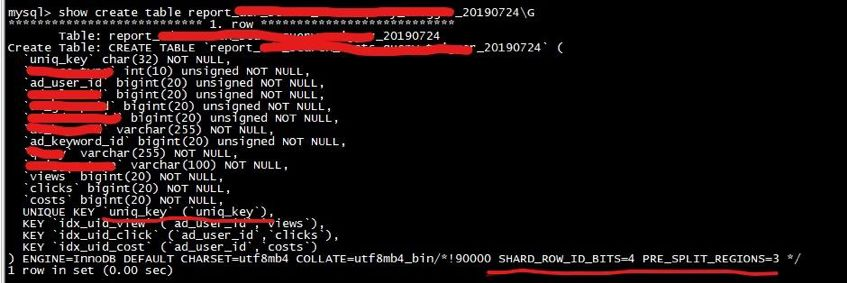 該建表語句會對這個表 t 預切分出 4 + 1 個 Region。4 *(2^(3-1)) 個 Region 來存 table 的行數據,1 個 Region 是用來存索引的數據。 關於 `SHARD_ROW_ID_BITS` 和 `PRE_SPLIT_REGION` 這 2 個參數使用詳情參見官方文檔: * [https://pingcap.com/docs-cn/v3.0/faq/tidb/#6-1-2-如何打散熱點](https://pingcap.com/docs-cn/stable/faq/tidb/#6-1-2-%E5%A6%82%E4%BD%95%E6%89%93%E6%95%A3%E7%83%AD%E7%82%B9) * [https://pingcap.com/docs-cn/v3.0/reference/sql/statements/split-region/#pre-split-region](https://pingcap.com/docs-cn/v3.0/reference/sql/statements/split-region/#pre-split-region) 此外,針對自增主鍵 ID 形成寫入熱點的問題,TiDB 將會在 4.0 版本爲提供一個新的列屬性:`Auto_Random`。這個屬性相似於 `Auto_Increment`,能夠定義在整型主鍵上,由 TiDB 自動分配一個保證不重複的隨機 ID。有了這個特性後,上面的例子能夠作到不刪除主鍵 ID,同時避免寫入熱點。 ### 最終優化效果 從監控上看,TiKV 的 CPU 使用很是均衡: 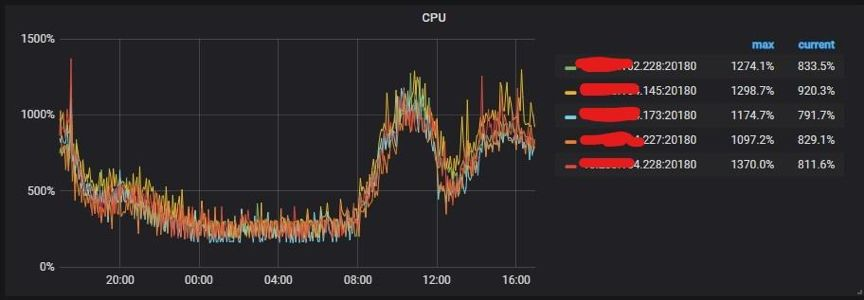 從命令調度的結果來看也比較均衡: 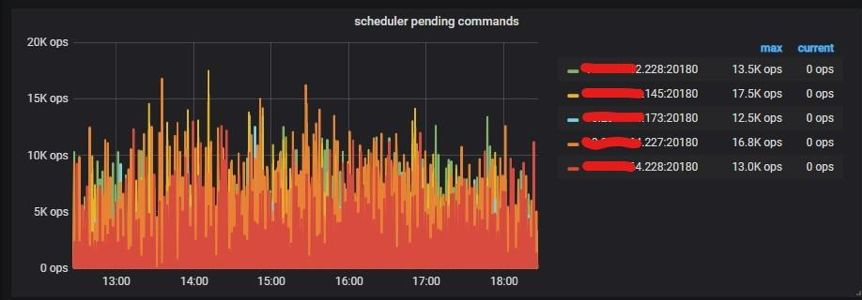 ## 總結 本文只是拿 360 智能商業業務線的一個業務場景分享了熱點 Region 的打散方法,目的是提供寫熱點優化的思路,但願能對你們有必定的幫助。本文調優過程當中獲得了 PingCAP 公司技術人員的大力支持,在此表示衷心的感謝。 TiDB 的存儲和計算分離的架構,結合高可用、高性能、易擴展、易運維等特性,給大數據量的數據拆分帶來了曙光,將來會在 360 智能商業業務線有更多的項目落地。在將來,咱們指望用 TiFlash 解決 TiDB 下游數據治理問題,並作到跨數據中心部署的方案。 **原文閱讀**:[https://pingcap.com/cases-cn/user-case-360-business/](https://pingcap.com/cases-cn/user-case-360-business/) 
- 1. BI商業智能
- 2. MYSQL企業經常使用架構與調優經驗分享
- 3. BI (商業智能)
- 4. TiDB 在轉轉的業務實戰
- 5. 精讀《智能商業》
- 6. jvm調優經驗分享
- 7. JVM調優經驗分享
- 8. MYSQL企業常用架構與調優經驗分享
- 9. Uber微服務實戰經驗分享
- 10. 微服務實戰經驗分享
- 更多相關文章...
- • MySQL的優勢(優點) - MySQL教程
- • 電子商務網站主機 - 網站主機教程
- • TiDB 在摩拜單車在線數據業務的應用和實踐
- • Spring Cloud 微服務實戰(三) - 服務註冊與發現
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. BI商業智能
- 2. MYSQL企業經常使用架構與調優經驗分享
- 3. BI (商業智能)
- 4. TiDB 在轉轉的業務實戰
- 5. 精讀《智能商業》
- 6. jvm調優經驗分享
- 7. JVM調優經驗分享
- 8. MYSQL企業常用架構與調優經驗分享
- 9. Uber微服務實戰經驗分享
- 10. 微服務實戰經驗分享