【MapReduce】1、MapReduce簡介與實例
(一)MapReduce介紹
一、MapReduce簡介
MapReduce是Hadoop生態系統的一個重要組成部分,與分佈式文件系統HDFS、分佈式數據庫HBase一塊兒合稱爲傳統Hadoop的三駕馬車,一塊兒構成了一個面向海量數據的分佈式系統的基礎架構。java
MapReduce是一個用於大規模數據(大於1TB)處理的分佈式計算模型、編程模型,它最初是由Google設計並實現的,在Google提出時,給它的定義是:Map/Reduce是一個編程模型(programming model),是一個用於處理和生成大規模數據集(processing and generating large data sets)的相關的實現。數據庫
MapReduce的主要思想「Map(映射)」和「Reduce(規約)」都來自於函數式編程語言。MapReduce極大地方便了編程人員在不會分佈式並行編程的狀況下,將本身的程序運行在分佈式系統之上。用戶只須要定義一個map函數來處理一個key/value對以生成一批中間的key/value對,再定義一個reduce函數將全部這些中間的有着相同key的values合併起來。不少現實世界中的任務均可用這個模型來表達,具備較強的實用價值。編程
具體來看,MapReuce應當是包含了如下三層含義:服務器
(1)MapReduce是一個基於集羣的高性能並行計算平臺。經過MapReduce能夠將市場上普通的商用服務器構成一個包含數10、數百甚至數千個節點的分佈和並行計算集羣。架構
(2)MapReduce是一個並行計算與運行軟件框架。它提供了一個龐大但設計精良的並行計算軟件框架,能自動完成計算任務的並行化處理,自動劃分計算數據和計算任務,在集羣節點上自動分配和執行任務以及收集計算結果,將數據分佈存儲、數據通訊、容錯處理等並行計算涉及到的不少系統底層的複雜細節交由系統負責處理,大大減小了軟件開發人員的負擔。app
(3)MapReduce是一個並行程序設計模型與方法。它藉助於函數式程序設計語言Lisp的設計思想,提供了一種簡便的並行程序設計方法,用Map和Reduce兩個函數編程實現基本的並行計算任務,提供了抽象的操做和並行編程接口,以簡單方便地完成大規模數據的編程和計算處理。框架
MapReduce的數據處理模型很是簡單:map函數和reduce函數的輸入和輸出都遵循<key,value>鍵值對的格式,簡單的用符號表示就是:編程語言
Map:(K1,V1)——> list(K2,V2)分佈式
Reduce:(K2,list< V2>)——> list<K3,V3>函數式編程
Map-Reduce框架的運做徹底基於<key,value>對,即數據的輸入是一批<key,value>對,生成的結果也是一批<key,value>對,只是有時候它們的類型不同而已。Key和value的類因爲須要支持被序列化(serialize)操做,因此它們必需要實現Writable接口,並且key的類還必須實現WritableComparable接口,使得可讓框架對數據集的執行排序操做,後面咱們經過具體的實例來展現它的用法。
二、MapReduce版本演化
MapReduce是Hadoop生態系統的一員,是一個徹底開源的分佈式計算系統。MapReduce從第一次提出到今天,並非一成不變的,雖然其主流思想和計算模型沒有大的改變,可是整個系統也是在不斷的完善和演變的。
首先經典版本的MapReduce框架,也就是初版成熟的商用框架,屬於Hadoop的V1.0版本,這個版本的主要特色是簡單易用,其思路也比較清晰,各個Client提交Job給一個統一的Job Tracker,而後Job Tracker將Job拆分紅N個Task,而後進行分發到各個節點(Node)進行並行協同運行,而後再將各自的運行結果反饋至Job Tracker,進而輸出結果。
<div align=center> 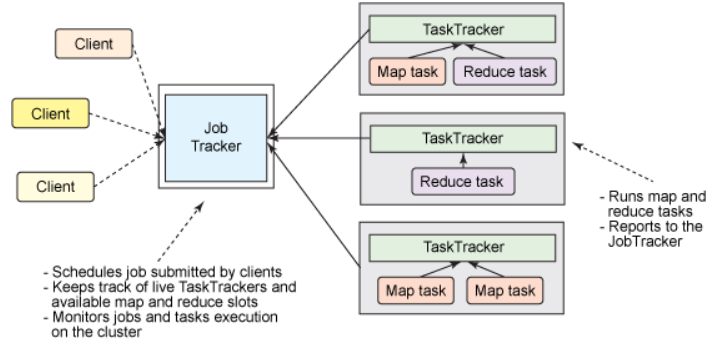 </div>
雖然實現簡單,可是這個1.0版本存在着其固有的侷限性,其中最主要的一點就是:單點故障問題。全部的Job的完成都得益於JobTracker的調度和分配,一旦此節點宕機就意味着整個平臺的癱瘓,固然,在實際中大部分經過一個備用機來解決。可是,在一個以分佈式運算爲特性的框架中,將這種核心的計算集中與一臺機器不是一個最優的方案。其次,這個設計擴展性不強,容易形成資源的浪費。
所以,爲了減輕單個JobTracker的職責,mapreduce的2.0版本開始引入了YARN做爲集羣的資源管理器,JobTracker的職責分爲兩大部分:集羣資源管理和任務協調,YARN做爲資源管理器,專一於負責整個平臺的資源管理,而任務的調度和協調交給下屬的任務節點來完成。其主要的運行機制後面具體解析。
目前爲止,Hadoop已經發展到了3.0版本,3.0和2.0版本在編程模型和運行機制上沒有太大的變化,仍然使用YARN做爲其資源管理器,可是在穩定性、存儲開銷和兼容性等方面有所優化。
(二)MapReduce實例(WordCount)
下面經過實例來對MapReduce的過程進行說明。
WordCount是Hadoop自帶的一個例子,目標是統計文本文件中單詞的個數。假設有以下的兩個文本文件來運行WorkCount程序:
第一個文件內容:Hello World Bye World
第二個文件內容:Hello Hadoop GoodBye Hadoop
(1)Map數據的輸入
MapReduce針對文本文件缺省使用LineRecordReader類來實現讀取,一行一個key/value對,key取偏移量,value爲行內容。所以,對於給出的文件,假設每一個文件正好是一個分片,那麼會有兩個Map任務,MapReduce會將其映射爲以下所示的鍵值對做爲Map過程的輸入。
<div align=center>
| Map任務 | key | value |
|---|---|---|
| map1 | 0(偏移量) | Hello World Bye World |
| map2 | 0(偏移量) | Hello Hadoop GoodBye Hadoop |
</div> (2)Map的輸出
用戶經過定義map函數對輸入的鍵值對進行處理,目標是統計每一個單詞的個數,這至關於一個數據預處理的過程,通過處理後,會輸出一系列的鍵值對,鍵是每一個單詞,而值是個數(也就是1)。
<div align=center>
| Map任務 | key | value |
|---|---|---|
| map1 | Hello | 1 |
| map1 | World | 1 |
| map1 | Bye | 1 |
| map1 | World | 1 |
| map2 | Hello | 1 |
| map2 | Hadoop | 1 |
| map2 | GoodBye | 1 |
| map2 | Hadoop | 1 |
</div>   這裏須要注意,MapReduce還有一個能夠在此時用的功能是Combiner,它能夠將相同key的值合併起來,它也用Reducer的實現。可是,有些狀況,Combiner並不適用,只有中間結果合併以後不會影響最終結果的纔可使用Combiner,如這裏計算單詞次數,這就可使用Comniner,使用後,map1任務中的World會合併爲1個,個數成爲2,一樣map2任務的Hadoop也合併爲1個,個數成爲2。
(3)Reduce的輸入
Map或者Combiner的輸出(若是有的話)會經歷一個shuffle的過程,這個過程將key相同的數據進行合併,並按照字符順序進行排序。
如這裏Combiner輸出進行shuffle以後會獲得:
<div align=center>
| Key | Value |
|---|---|
| Bye | [1] |
| GoodBye | [1] |
| Hadoop | [2] |
| Hello | [1,1] |
| World | [2] |
</div> (4)Reduce的輸出
最後,Reducer實現將相同key的值合併起來,獲得最後的結果。
<div align=center>
| Key | Value |
|---|---|
| Bye | 1 |
| GoodBye | 1 |
| Hadoop | 2 |
| Hello | 2 |
| World | 2 |
</div>   用圖表示以下: <div align=center> 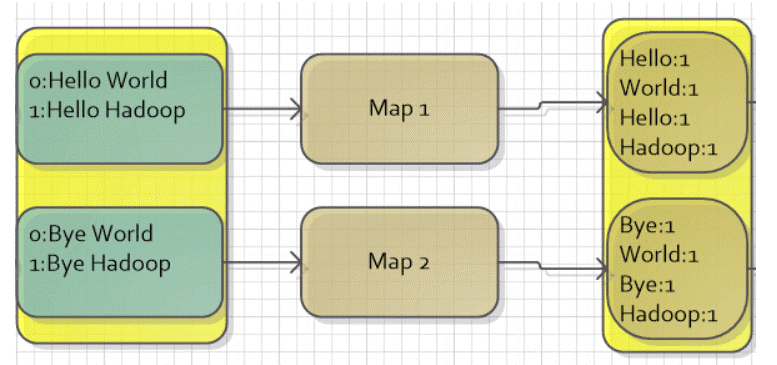 </div> <div align=center> 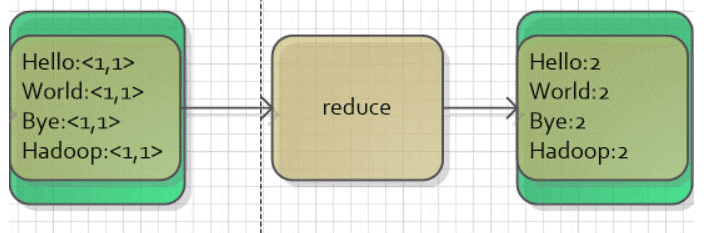 </div>
這就是一個MapReduce應用的實例,其編程實現也很是簡單,用戶只須要定義map函數和reduce函數,而後寫一個驅動程序來運行做業便可。
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); //輸出的key的類型,能夠理解爲String
public void map(LongWritable key, Text value, Context context) {
String line = value.toString(); //每行句子
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one); //輸出
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
//在這裏,reduce步的輸入至關於<單詞,valuelist>,如<Hello,<1,1>>
public void reduce(Text key, Iterable<IntWritable> values,Context context) {
int sum = 0;
for (IntWritable val : values)
sum += val.get();
context.write(key, new IntWritable(sum));
}
}
以上就是map函數和reduce函數的實現,邏輯都很簡單,最後咱們只須要寫一個主函數,設置一個Job做業,進行相對設置,就能夠運行,好比以下的Job做業設置了處理該做業的類、做業名字、輸入輸出數據的路徑、map和reduce對應的類、輸出結果類型,最後調用執行命令進行執行便可。
Job job = new Job(); // 建立一個做業對象
job.setJarByClass(WordCount.class); // 設置運行/處理該做業的類
job.setJobName("WordCount");
FileInputFormat.addInputPath(job, new Path(args[0])); //設置這個做業輸入數據的路徑
FileOutputFormat.setOutputPath(job, new Path(args[1])); //設置這個做業輸出結果的路徑
job.setMapperClass(Map.class); //設置實現了Map步的類
job.setReducerClass(Reduce.class); //設置實現了Reduce步的類
job.setOutputKeyClass(Text.class); //設置輸出結果key的類型
job.setOutputValueClass(IntWritable.class); //設置輸出結果value的類型
System.exit(job.waitForCompletion(true) ? 0 : 1); //執行做業
- 1. 《MapReduce 1》--MapReduce的簡介、編寫簡單的MapReduce程序
- 2. 【Mapreduce】Mapreduce實例——WordCount
- 3. MapReduce 簡介
- 4. MapReduce簡介
- 5. mapreduce簡介
- 6. Mapreduce實例
- 7. Mapreduce實例——WordCount
- 8. hadoop mapreduce實例
- 9. MapReduce實例——WordCount
- 10. HDFS、YARN、Mapreduce簡介
- 更多相關文章...
- • PHP 實例 - AJAX 與 XML - PHP教程
- • XML DOM 實例 - XML DOM 教程
- • Java Agent入門實戰(一)-Instrumentation介紹與使用
- • Github 簡明教程
-
每一个你不满意的现在,都有一个你没有努力的曾经。