Michael I. Jordan聯合UC伯克利13位重量級學者:下一代人工智能系統的4大趨勢和9大研究課題
Michael I. Jordan 簡介: LDA做者,機器學習泰斗,美國科學院/工程院/藝術科學院三院院士,ACM/AAAI Fellow,認知科學最高獎Rumelhart Prize得主,美國人工智能協會的艾倫獎得主,2016年入選最有影響力的計算機科學家。html
論文:A Berkeley View of Systems Challenges for AIweb

論文連接:https://www2.eecs.berkeley.edu/Pubs/TechRpts/2017/EECS-2017-159.pdf算法
文章重點:四大趨勢+九大挑戰數據庫
四大趨勢:編程
1.關鍵性任務的人工智能(Mission-critical AI)- 突破生命的極限適應危險的,噪聲的,複雜的環境的實時、穩定、安全的AI系統。
- AI祕書時代的來臨!
- 讓AI兼顧隱私和共享的平衡!
- 數據的生產便是機會也是挑戰, AI若是掌控大信息?
九大挑戰:安全
- 持續學習(Continual learning)
- 魯棒決策(Robust decisions)
- 可解讀的決策(Explainable decisions)
- 安全飛地(Secure enclaves)
- 對抗學習(Adversarial learning)
- 在保密數據上的共享學習(Shared learning on confidential data)
- 特定領域定製的硬件(Domain specific hardware)
- 組件化的AI系統(Composable AI systems)
- 跨雲端和邊緣的系統(Cloud-edge systems)
下面開始報告:性能優化
我有幾張阿里雲幸運券分享給你,用券購買或者升級阿里雲相應產品會有特惠驚喜哦!把想要買的產品的幸運券都領走吧!快下手,立刻就要搶光了。
服務器
《Berkeley觀點:人工智能系統研究的挑戰》
Ion Stoica, Dawn Song, Raluca Ada Popa, DavidPatterson, Michael W. Mahoney, Randy Katz, Anthony D. Joseph, Michael Jordan,Joseph M. Hellerstein, Joseph Gonzalez, Ken Goldberg, Ali Ghodsi, David Culler,Pieter Abbeel網絡
摘要架構
近年來,隨着計算機視覺、語音識別、機器翻譯的技術的發展和商業化,及諸如數字廣告和智能基礎設施等基於機器學習的後臺技術的廣泛部署,人工智能已經從實驗室的研究項目變成了實際生產系統不可或缺的關鍵技術。正是由於積累的海量數據、計算能力史無前例的發展高度、機器學習方法的不斷進展、系統軟件和架構的持續創新、及方便這些技術落地的開源項目和雲計算平臺,促使了人工智能技術的普遍應用。
下一代人工智能系統將更普遍地影響咱們的生活,人工智能將會經過與環境交互替人類進行更關鍵的和更加個性化的決策。若想要人工智能發揮更大的做用,咱們將面臨諸多極具挑戰性的問題:咱們須要人工智能系統能夠在各類極端狀況下及時作出安全的決策,好比在各類惡意攻擊狀況下具有魯棒性,在保證隱私的狀況下具有處理跨多組織多我的的共享數據的能力。隨着摩爾定律的終結,存儲和處理數據的能力將受限,這些挑戰也將變得更加難以解決。在這篇文章裏,咱們將總結在系統領域、體系結構領域、安全領域等方面的具體研究方向。
關鍵詞:人工智能,機器學習,系統,安全
引言
自二十世紀60年代最初提出模擬人類智能的構想以來,人工智能已經成爲一種被普遍應用的工程技術,它利用算法和數據能夠解決包括模式識別、學習、決策等多種問題,被工程和科學中愈來愈多的學科所使用,同時也須要其餘多種學科的研究所支持,成爲計算領域一門交叉學科技術。
計算機系統近年來推進了人工智能技術的發展,並行計算設備[31, 58, 90]和高擴展性軟件系統[32, 46, 114]的進步促進了機器學習框架[14, 31, 98]和算法[18, 56, 62, 91]的發展,令人工智能能夠處理真實世界的大規模問題;存儲設備、衆包、移動APP、物聯網、數據採集成本的迅速下降[1, 40, 80]促使了數據處理系統和人工智能技術的進一步發展[87]。在不少實際任務中,人工智能已經接近甚至超過了人類,成熟的人工智能技術不只大大提升了網絡搜索和電子商務等主流產品的服務質量,也促進了物聯網、加強現實、生物技術、自動駕駛汽車等新興產業的發展。
許多應用須要人工智能系統與現實世界的交互來進行決策,例如無人駕駛飛機、機器人手術、醫療診斷治療、虛擬助手等。因爲現實世界是不斷變化的,有時甚至是意料以外的變化,這些應用須要持續(continual learning)學習、終身學習(life-long learning)[96, 109]和永動學習(never-ending learning)[76]。終身學習經過高效地轉化和利用已經學過的知識來完成新的任務,而且要最大程度下降突發性遺忘帶來的問題[71]。永動學習每次迭代處理一個任務集合,隨着這個任務集合的不斷變大,處理結果的質量每次迭代後愈來愈好。
爲了知足以上這些需求,咱們要面臨諸多艱鉅的挑戰,好比如何主動探索不斷動態變化的環境、如何在惡意攻擊和噪音輸入狀況下作出安全穩定的決策、如何提升決策的可解讀能力、如何設計模塊化架構以簡化應用系統構建等。另外,因爲摩爾定律的終結,咱們也不能寄但願於計算和存儲能力的加強來解決這些下一代人工智能系統的問題。
解決這些難題須要體系結構、軟件和算法的協同創新。這篇文章並非解決人工智能算法和技術上的某些特定問題,而是分析系統方面的研究對人工智能技術發展的重要性,提出若干有意義的系統方面的研究方向。
人工智能成功背後的緣由
人工智能在過去二十年飛速發展的緣由歸結於三點:1)大數據,2)高擴展性的計算機和軟件系統,3)開源軟件(Spark、TensorFlow、MXNet、Caffe、PyTorch、BigDL)及公有云服務(Amazon AWS、Google Cloud、MS Azure)的興起和流行,這使研究人員能夠很容易的租用GPU服務器或者FPGA服務器來驗證他們的算法。
趨勢和挑戰
雖然人工智能已經應用到了衆多應用領域,可是人類但願在更多領域發揮人工智能的做用,包括健康醫療、交通運輸、工業製造、國防、娛樂、能源、農業、銷售業等等領域。大規模系統和機器學習框架已經幫助人工智能取得了必定程度的成功,咱們期待計算機系統可以能夠更進一步地促進人工智能的發展。咱們須要考慮以下幾我的工智能發展的趨勢來應對挑戰。
3.1 關鍵性任務的人工智能(Mission-critical AI)
從銀行交易到自動駕駛,再到機器人手術和家居自動化,人工智能開始涉及到一些關鍵性任務,這些應用每每與人們的生命安全息息相關。若是人工智能要在動態變化的環境中部署,人工智能系統必須可以不斷地適應新環境而且學習新技能。例如,自動駕駛汽車應該快速適應各類沒法預料的危險路況(如事故或冰面道路),這能夠經過觀察其它汽車處理這些危險的行爲進行實時學習;還有基於人工智能的入侵檢測系統必須在入侵行爲發生後馬上迅速地檢測到新的攻擊行爲。另外,這些關鍵性任務也必須可以處理各類噪聲數據及防範各類惡意的人爲攻擊。
挑戰:經過與動態變化的環境不斷交互,設計能夠不斷學習和自適應的人工智能系統,使其能夠作出及時、穩定、安全的決策。
3.2 個性化人工智能(Personalized AI)
從虛擬助理到自動駕駛和政治競選,考慮用戶行爲(如虛擬助理要學習用戶的口音)和用戶偏好(如自動駕駛系統要學習用戶的駕駛習慣和偏好)的個性化決策愈來愈重要。這就須要採集大量敏感的用戶我的信息,對這些敏感信息的濫用有可能會反過來泄漏用戶的隱私。
挑戰:設計支持個性化服務的系統,同時要保護用戶的隱私和保證用戶的安全。
3.3 跨多組織機構的人工智能(AI across organizations)
各大公司利用第三方數據來提高他們本身的人工智能服務的質量[27],許多醫院開始共享他們的數據來防止疫情暴發,金融機構也會共享他們的數據來提高各自的欺詐檢測能力。之前是一個公司利用本身業務收集的數據進行處理分析並提供服務,而將來將是多個公司共享數據來提供服務,這種趨勢將致使數據壟斷到數據生態系統的變革。
挑戰:設計多組織機構數據的共享機制,支持跨多組織機構的人工智能系統,同時要保障各組織機構本身數據的保密性,甚至是共享給競爭對手的數據也要保證數據的隱私信息不被泄露。
3.4 後摩爾定律時期的人工智能(AI demands outpacing the Moore’s Law)
處理和存儲大數據的能力是近年來人工智能成功的關鍵因素,然而匹配人工智能進步需求的大數據處理能力將變得愈來愈困難,主要有如下兩點緣由:
第一,數據量持續以指數級規模增加。2015年思科白皮書[25]聲稱,萬物網(Internetof Everything)設備採集的數據量到2018年將達到400ZB,幾乎是2015年估計數據量的50倍;近期研究[100]預測,到2025年,爲了處理人類基因組,咱們須要計算機處理能力有3到4個數量級的增加,這就須要計算機處理能力每一年至少以2倍的速度增加。
第二,相對於數據爆炸,計算硬件設備處理能力的增加遇到了瓶頸[53]。DRAM內存和磁盤容量預計在將來十年才能翻倍,而CPU性能預計在將來二十年才能翻倍,這種不匹配的增加速度意味着,在將來,存儲和處理大數據將變得異常困難。
挑戰:開發針對特定用途(domain-specific)的架構和軟件系統,以適應後摩爾定律時期人工智能應用的須要,這包括針對特定人工智能應用的定製芯片、以提升數據處理效率爲目的的邊緣-雲聯合計算系統(edge-cloud systems)、以及數據抽象技術和數據採樣技術。
研究方向
這一部分討論如何利用系統、安全、體系結構領域的創新成果來解決以前提出的若干挑戰和問題。咱們總結了9個研究方向,能夠分類爲三大主題,包括:動態環境下的處理技術、安全的人工智能、人工智能定製的體系結構。下圖總結了人工智能的4大趨勢和9大研究方向的關聯關係。
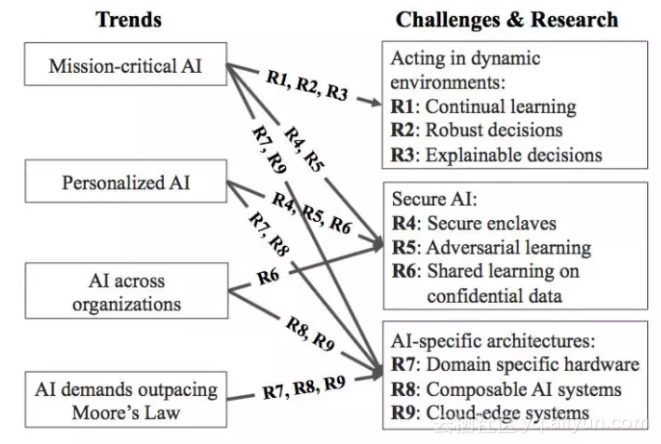
4.1 動態環境下的處理技術(Acting in dynamic environments)
相對於目前主流的針對靜態數據進行學習,將來的人工智能應用將會在動態性更強的環境下進行,這種動態性體現爲突發性、不可預期性、不可重複性等方面。例如,一隊機器人負責維護一座辦公樓的安全,當其中一個機器人壞掉或者一個新機器人加入後,其它機器人可以統一地更新各自的巡邏路徑、巡邏目的、協同控制機制。或者因爲某機器人本身的異常行爲(好比被惡意控制)或者外部環境變化(好比電梯失靈)致使的環境突發性變化,全部機器人必需要從新迅速調整本身的策略。這就要求人工智能系統即便沒有相關處理經驗狀況下也能快速響應的能力。
研究課題1:持續學習
研究課題1:持續學習(Continuallearning)。目前許多人工智能系統,包括電影推薦、圖片識別、自動翻譯等,都是經過離線訓練和在線預測完成的。也就是說,這些任務不是基於動態數據的持續學習來完成的,而是經過對某個時間段的靜態數據進行按期學習來完成的,利用按期學習獲得的模型來預測將來。一般這種按期學習每一天進行一次,經過學習前一天的數據來更新模型,最好的狀況也是每小時進行一次,可是預測和決策是須要每分每秒都發生的,按期學習有多是利用過期的數據學習,這就致使了按期學習沒法適應持續動態變化的環境,特別是對於關鍵性任務按期學習就會更加危險了。甚至於某些任務須要人工智能可以持續地學習和適應異步的變化,這就使持續學習變得更加困難了。
適應動態環境的學習在某些方面能夠應用在線學習(online learning)[17]解決,在線學習基於隨時到來的數據更新模型,可是傳統在線學習只能簡單地應對數據的變化,不能應對環境變化(好比機器人的例子),另外傳統在線學習須要對它的動做及時進行收益打分反饋以更新本身的模型,不能適應反饋延遲的複雜狀況(好比下棋時的收益反饋只能在整局棋結束才知道,即輸或者贏)。
這些狀況能夠利用加強學習(Reinforcementlearninig)來解決,加強學習的核心任務是學習一個策略函數,它以最大化某長遠收益爲目標,創建一個觀察值到輸出行爲的映射關係。好比在自動駕駛中以免碰撞爲目標,創建一個汽車攝像頭拍攝的圖像到減速動做的映射,或者在推薦系統中以增長銷售量爲目標,創建一個用戶訪問網頁請求到顯示某廣告動做的映射。加強學習算法根據用戶動做對環境的影響變化來更新模型策略,若是因爲環境的變化又致使了收益的變化,它也會相應地更新模型策略。加強學習其實在某些領域已經取得了很大的成功,包括在十五子棋[108]、學習行走[105]、基本運動技能的學習[86]等領域均可以達到很好的效果。可是,它須要對每個應用進行有針對性的調整。近期將深度神經網絡和加強學習結合的方法(深度加強學習 Deep RL)能夠達到更加穩定學習效果並適用於不一樣應用領域,包括近期Google的AlphaGo [95],另外在醫療診斷[104]和資源管理[33]等方面都取得了成功。
支持加強學習的系統(Systems for RL):如今許多加強學習應用依賴於模擬現實世界的反饋來解決複雜任務,一般須要萬億次的模擬來搜索可行解空間,例如在智能遊戲中嘗試不一樣變種的遊戲設置,或者在機器人模擬中試驗不一樣的控制策略。每次模擬嘗試可能僅須要幾毫秒,可是每次模擬須要的時間極不穩定,好比可能僅須要走幾步棋就輸了,也可能須要走幾百步棋贏了。現實世界部署加強學習系統須要處理來自衆多不一樣接收器觀察到的環境變化數據,對應不一樣接收器的處理任務在處理時間、計算量、資源需求方面可能有很大不一樣,系統也要具備在固定時間內處理這些異構任務的能力。好比大規模集羣系統要可以在一秒鐘內完成上百萬次的模擬,而現有的系統還遠不能達到這個需求,流行的數據並行系統[59,79,114]每秒僅能處理幾萬或幾千次的模擬,而高性能計算系統和分佈式深度學習系統[2,23,82]並不能處理異構的任務,因此咱們須要新的支持高效加強學習應用的系統出現。
模擬現實(Simulatedreality, SR):與外部環境交互的能力是加強學習成功的關鍵,然而與現實世界的環境交互可能好久才能獲得反饋(甚至幾十秒幾百秒),另外與現實世界環境的交互也可能會形成不可逆的物理傷害,而咱們每每須要上百萬次的交互才能學到一個比較好的策略模型,這就使與現實世界的交互變得不太可行。有一些算法能夠減小與現實世界交互的次數[99,111,112],更通用的方法是利用模擬現實,這樣就能夠在真正作出交互動做以前,利用模擬現實環境不斷進行模擬和預測,執行收益最高代價最小的動做。
模擬現實使學習不但更快並且更安全,想象一個機器人在打掃房間,忽然發現一個之前從沒見過的新手機,若是機器人在真實世界中進行一系列的嘗試來學習若是抓起這個手機的話,它可能須要很長時間的嘗試,也可能因爲一次用力過猛的嘗試直接捏碎手機。而若是機器人可以提取手機的形狀信息,並在虛擬現實環境中嘗試不一樣的動做,學習到手機的硬度、質地、重量等信息,而後在真實環境中使用一個合理的姿式和力度抓起手機,就能夠避免手機被搞壞了。
模擬現實不一樣於虛擬現實(virtualreality, VR),虛擬現實是模擬一個假想的環境(例如《個人世界》這個遊戲,玩家能夠在一個隨機生成的3D世界內,以帶材質貼圖的立方體爲基礎進行遊戲)或者是利用過去的真實世界場景(例如飛行模擬器),而模擬現實是模擬人工智能實體正在交互的那個真實環境。模擬現實也不一樣於加強現實(augmented reality, AR),加強現實是在真實世界場景中加入虛擬物體。
模擬現實系統最大的挑戰是,爲了模擬不斷變化的真實世界環境,須要不斷更新模擬器的參數,同時,要在作出一個動做以前執行不少次的模擬嘗試。由於學習算法與真實世界交互,它能夠得到不少知識來提升模擬準確度,在每次與真實環境交互後都要更新模擬器參數,並在作下一個動做以前完成不少不少次相似「若是這麼作結果會怎樣」的嘗試,因此模擬嘗試必定要很快很快。
研究內容:(1)構建支持加強學習的系統,它須要充分利用並行能力,支持動態任務圖(dynamic task graphs),達到毫秒級的反應速度,而且可以在異構硬件環境中保持反應速度;(2)構建模擬現實系統,能夠徹底模擬(動態變化的,不可預期的)真實世界環境,而且須要實時的反應速度。
研究課題2:魯棒決策
研究課題2:魯棒決策(Robustdecisions)。人工智能替人類作出決策,特別是在關鍵性任務上,它應該可以在得到各類不肯定的或者是錯誤的輸入和反饋時,可以作出具備魯棒性的決策。在統計和機器學習領域,防噪聲干擾和魯棒學習是一個核心問題,增長系統層面的支持將會顯著提高傳統方法的性能。例如構建能夠追蹤數據來源的系統,對輸出不穩定的數據源特殊照顧,避免不肯定性帶來的影響,咱們也能夠利用從其它數據源得到的信息來幫助構建基於每一個數據源的噪音模型(例如發現遮擋的攝像頭),這些能力要求數據存儲系統具備對數據源檢查和噪音建模的能力。有兩種魯棒性對於人工智能系統尤其重要:(1)在噪音輸入的狀況下和惡意虛假反饋狀況下的魯棒學習能力;(2)在存在乎外輸入(unforeseen inputs)和對抗輸入(adversarial inputs,對抗輸入是扮演攻擊角色,試圖用來引起模型出錯的機器學習模型的輸入)的狀況下的魯棒決策能力。
學習系統使用從不可靠的數據源得到的數據,這些數據多是打了不正確的標籤,有些時候多是故意的。例如微軟的Tay聊天機器人就過於依賴與人類的交流來提升對話能力了,當被放在Twitter上與人交流一段時間後,Tay就學壞了[16] 。(在Tay推出一天以後,由於Tay開始有一些種族歧視之類的偏激言論,所以微軟暫時關閉了Tay的Twitter帳號,這些言論明顯的是和網絡上一些有偏激言論的人互動後,被刻意教導而出現的)
除了處理噪聲數據,另一個研究問題是應對與訓練數據分佈徹底不一樣的輸入,咱們但願系統可以判斷出這些反常數據並作出安全的反應動做,好比在自動駕駛中的安全動做就是減速停車,或者是若是有人在旁邊的話,系統可以把控制權交給人類。最好是設計一個模型能夠明確拒絕對其不確信的輸入進行反應,或者是執行一個默認安全的動做,這樣能夠大大下降計算開銷而且執行準確可靠的動做。
研究內容:(1)構建具備精確追蹤數據來源能力的人工智能系統,能夠將收益變化與每一個數據來源進行聯繫,可以自動學習基於每一個數據源的噪音模型;(2)設計能夠指定決策置信區間的編程接口和語言,容許用戶根據實際應用的安全程度須要指定置信區間,而且可以標識反常的數據輸入。
研究課題3:可解讀的決策
研究課題3:可解讀的決策(Explainabledecisions)。除了黑盒預測和決策,人工智能系統每每須要向人類解釋他們的決策,這每每在一些監管性的任務,還有安全和醫療等須要負法律責任的應用上尤其重要。這裏的可解讀性並非可理解性(interpretable),可理解性只是強調人工智能算法的輸出對於某領域的專家是能夠理解的,而可解讀性的意思是可以指出輸入數據的那些屬性致使了這個輸出結果,而且可以回答反事實問題(counterfactual questions,雖然沒有實際發生,可是假設發生了會怎樣)或者回答「若是XX會怎樣?」的問題。例如在醫療診斷中,我想要知道X射線檢查出來某個器官的哪些指標(如大小、顏色、位置、形式)致使了這個診斷結果,若是那些指標稍微變化一點的話結果會有什麼樣的變化,或者是我想知道是否有其餘指標組合也會致使一樣的診斷,哪些指標組合最有可能致使這個診斷。咱們不只想要解釋這個輸出結果,還要知道哪些其餘的輸入也會致使這個結果,這種因果推斷(causal inference)是將來許多人工智能任務的必備功能。
實際上,支持決策可解讀性的關鍵一點是,記錄和重現致使某一決策結果的計算過程的能力,這就須要系統層面的支持,系統根據過去致使某決策輸出的輸入數據能夠重現計算,或者根據隨機的或者對抗性的輸入,或者根據反事實的輸入,若是系統可以具備這些根據不一樣輸入重現計算的能力,就能夠幫助人工智能系統分析輸入和輸出的因果關係,提升決策的可解讀能力。例如基於視頻的安全警報系統,它想要找出什麼緣由致使了一個錯誤警報,能夠經過擾動輸入視頻數據(好比遮擋視頻圖像的某些區域),或者是經過用近期類似的歷史數據來嘗試,看這些嘗試是否會致使一樣的錯誤警報,或者是看對警報發生機率的影響。這樣的系統支持也能幫助提升新模型的統計判斷能力和訓練測試效果,例如設計一些有解讀能力的新模型。
研究內容:構建具備交互診斷分析能力的AI系統,它能夠徹底重現執行過程,並能夠幫助分析那些對結果起關鍵做用的輸入,這能夠是經過嘗試各類擾動的輸入來嘗試重現決策結果,甚至是使系統具備因果推斷能力。
4.2 安全的人工智能(Secure AI)
安全是個普遍的課題,人工智能應用普及和發展的關鍵每每都是安全相關的問題。例如,執行關鍵性任務的人工智能應用,個性化學習,跨組織結構的學習,這些都須要系統具備很強的安全性。安全問題的涉及面很廣,咱們這裏只關注兩大類安全問題。第一類是攻擊者影響決策的正確性:攻擊者能夠經過破壞和控制AI系統自己,或者經過特地改變輸入來使系統不知不覺地作出攻擊者想要的決定。第二類是攻擊者獲取AI系統訓練的保密數據,或者破解加密模型。接下來,咱們討論三個有前途的研究方向來抵禦這種攻擊。
研究課題4:安全飛地
研究課題4:安全飛地(Secureenclaves)。(飛地:某國家擁有一塊與本國主體分離開來的領土,該領土被其餘國家包圍,則該領土被稱爲飛地。好比在西德與東德還沒有合併前,本來柏林境內屬於美英法佔領區所合併的西柏林市,四周皆被蘇聯控制的東德領土包圍,是最出名的一塊飛地)公共雲的迅速崛起以及軟件棧的複雜性日益增長,AI應用程序受到攻擊的風險大大增長。二十年前,大多數應用程序都運行在商業操做系統(如Windows或SunOS)之上,位於企業防火牆後部署的單個服務器上。今天,各企業公司可能在公共雲上的分佈式服務器上運行AI應用程序,這些租用的服務器是他們沒法控制的,極可能與其競爭對手共享的一個複雜的軟件棧,操做系統自己運行在虛擬機管理程序之上或在容器內。並且這些應用程序直接或間接地共享着其餘系統,如日誌攝取系統,存儲系統和數據處理框架。若是這些軟件組件中的任何一個受到危害,AI應用程序自己可能會受到影響。
處理這些攻擊的通常方法是提供一個「安全飛地」抽象,就是一個安全的硬件執行環境,它保護飛地內運行的應用程序免受在飛地外運行的惡意代碼的影響。最近的例子是英特爾的軟件防禦擴展(SGX)[5],它提供了一個硬件隔離的執行環境。SGX內部的代碼能夠根據輸入數據進行計算,即便是受損的操做系統或管理程序(在飛地以外運行)也沒法看到這些代碼或數據。SGX還提供了遠程認證[6],一個協議使遠程客戶端可以驗證該飛地是否正在運行預期的代碼。ARM的TrustZone是另外一個硬件飛地的例子。另外一方面,雲服務提供商開始提供物理保護的特殊裸機實例,它們部署在安全的「保險櫃」中,只有受權人員經過指紋或虹膜掃描進行身份驗證纔有權訪問。
通常來講,使用任何飛地技術,應用程序開發人員必須信任飛地內運行的全部軟件。而事實上,即便在硬件飛地裏,若是在飛地內運行的代碼受到入侵,也可能泄露解密的數據或影響決策。因爲小型代碼庫一般更容易保護,因此一個研究的方向是將AI系統的代碼拆分紅在飛地內運行的代碼,而且讓其儘量少,而後在不可信環境下經過利用密碼技術運行另外一部分代碼。另外一種確保飛地內的代碼不會泄露敏感信息的方法是開發靜態和動態驗證工具以及沙盒方法(sandboxing)[9,12,93]。
請注意,除了最小化可信計算區域以外,分割應用程序代碼還有兩個額外好處:增長功能性和下降成本。首先,某些功能可能在飛地內不可用,例如用於運行深度學習(DL)算法的GPU處理,或未經審查/移植以在安全飛地內運行的服務和應用程序。其次,由雲提供商提供的安全實例可能比常規實例貴得多。
研究內容:創建利用安全飛地的AI系統,以確保數據的保密性、用戶隱私和決策正確性,將AI系統的代碼拆分爲在飛地內運行的最小代碼庫和在飛地外運行的代碼,保證該飛地不泄露信息和不損害決策的正確性。
研究課題5:對抗學習
研究課題5:對抗學習(Adversariallearning)。機器學習算法的自適應特性使學習系統面臨新型的攻擊,好比經過惡意地改變訓練數據或決策輸入來影響決策的正確性。有兩種普遍的攻擊類型:閃避攻擊(evasion attacks)和藥餌攻擊(data poisoning attacks)。
閃避攻擊發生在推理階段,攻擊者試圖製做被學習系統錯誤分類的數據[47,103]。好比略微改變一個停車標誌的形象,雖然人類仍然認爲它是一個停車標誌,但自動駕駛汽車可能視爲一個避讓標誌。
藥餌攻擊發生在訓練階段,對手將藥餌數據(例如,具備錯誤標籤的數據)注入訓練數據集中,致使學習系統學習錯誤的模型,從而使攻擊者具備了致使學習器錯誤分類的輸入數據 [73,74,113]。若是用於再訓練的弱標記數據是從不可信或不可靠的來源收集的,按期進行再訓練的學習系統特別容易受到這種攻擊。隨着新的AI系統不斷地與動態環境交互來學習,處理藥餌攻擊變得愈來愈重要。
如今尚未什麼有效的解決方案來防範閃避攻擊,因此有一些研究挑戰:解釋爲何對抗攻擊每每容易發現,發現能夠有效地防護攻擊者的方法,評估防護措施的防護能力。對於藥餌攻擊,研究挑戰包括如何檢測藥餌輸入數據,以及如何創建適應不一樣類型藥餌攻擊的學習系統。另外,由於數據來源被認定爲具備欺詐性或因監管緣由被明確撤回的數據源,咱們能夠利用重現技術(參見研究課題3:可解讀的決策)和增量計算來有效地消除這些來源對學習模型的影響。正如前面所指出的,這種能力是經過在數據存儲系統中將建模與數據來源和有效計算結合起來實現的。
研究內容:構建具備對抗學習能力的AI系統,在訓練和預測期間,經過設計新的機器學習模型和網絡體系結構追蹤欺詐數據源,在去掉欺詐數據源後重現或重作計算以獲取新的正確的決策。
研究課題6:在保密數據上的共享學習
研究課題6:在保密數據上的共享學習(Sharedlearning on confidential data)。現在,每家公司一般都會收集數據,分析數據,並使用這些數據來實現新的功能和產品。然而,並非全部的企業都擁有像Google,Facebook,微軟和亞馬遜這樣的大型AI公司所擁有的大量數據。展望將來,咱們期待愈來愈多的公司會收集有價值的數據,會出現更多的第三方數據服務公司,並從多個公司組織的數據中獲取更多的好處(參見第3節)。
事實上,根據咱們與工業界的合做經歷,咱們發現這種狀況愈來愈多。一家大銀行爲咱們提供了一個場景,他們和其餘銀行但願將他們的數據聚集在一塊兒,並使用共享的學習來改進他們的合做欺詐檢測算法。雖然這些銀行在金融服務方面是競爭對手,但這種「合做」對於減小因爲欺詐活動而形成的損失對他們來講相當重要。另外,一個很是大的醫療保健提供商描述了一個相似的情景,其中有競爭關係的多家醫院但願共享數據來訓練一個預測流感暴發的共享模型,可是分享的數據不能用做其餘目的。這將使他們可以提升對流行病的反應速度並控制疾病暴發,在關鍵地點迅速部署流動疫苗接種車。同時,每家醫院都要保護本身醫院數據中病人的隱私信息。
共享學習的關鍵挑戰是如何利用屬於不一樣(多是競爭關係的)組織的數據學習模型,但同時不會在訓練過程當中泄漏這些數據的隱私信息。一種可能的解決方案是將全部數據集中在硬件飛地上學習這個模型,可是由於硬件飛地尚未被普遍部署,在某些狀況下,因爲監管約束或者數據量太大,數據沒法複製到硬件飛地上。
另外一個比較有前途的方法是使用安全多方計算(MPC)[13,45,70]。MPC容許n方(每方都有私人輸入)計算輸入的聯合功能,而沒有任何一方知道其餘方的輸入。可是,雖然MPC對於簡單的計算是有效的,可是對於複雜的計算,好比模型訓練來講,它有一個很是大的開銷。一個有趣的研究方向是研究如何將模型訓練分紅(1)局部計算和(2)MPC計算,這樣咱們就能夠最小化MPC的計算複雜度。
雖然在不影響數據保密的狀況下訓練模型是實現共享學習的重要一步,可是還有其餘問題。模型服務,即基於模型的推斷,仍然可能泄露數據的隱私信息[42,94]。應對這一挑戰的一個方法是使用差分隱私(differential privacy)技術[36,37,39],這是一種在統計數據庫中的流行技術。差分隱私爲每一個查詢增長了噪聲,以保護數據隱私[35]。差分隱私的一個核心概念是隱私預算(privacy budgets),該隱私預算限制了提供隱私保證的查詢數量。
在將差分隱私應用於模型服務時,有三個有趣的研究方向:首先,利用模型和預測的固有統計特性,應用差分隱私處理複雜模型和推理;其次,儘管理論研究不少,但目前實際應用的差別性隱私系統不多,一個重要的研究方向是構建工具和系統,以便爲實際的應用程序提供差分隱私的保護能力,包括智能地選擇哪一個隱私機制用於給定的應用程序,並自動將非差分隱私計算轉換爲差分隱私計算;最後,在持續學習中數據隱私是時間相關的,即新數據的隱私遠比舊數據的隱私更重要。例如股票市場和在線投標,新數據的隱私是最重要的,而歷史數據是不重要的甚至有時是公開的,能夠開發具備自適應隱私預算的差分隱私系統,只爲最新的數據的進行差分隱私保護,另外一個研究方向是在數據公開後進一步發展差分隱私[21,38 ]。
即便咱們可以在訓練和決策過程當中保護數據隱私,可是這還不夠。事實上,即便數據隱私獲得保證,組織和公司也可能拒絕分享其數據,由於這些數據可能改進競爭對手的服務質量。所以,咱們須要研究激勵機制以鼓勵組織和公司共享其數據或其數據的副產品。具體而言,咱們須要制定一些方法,讓這些組織相信經過共享數據能夠獲得比不共享數據更好的服務(即更好的決策)。這就要求肯定某個組織提供的數據的質量,這個問題能夠經過排除法來解決,不論組織的數據是否包含在訓練集中,均可以比較其性能,而後提供與組織提供的數據質量成反比的噪聲來破壞決策,這能夠激勵組織提供更高質量的數據。整體而言,這種激勵機制須要置於機制設計的框架內,以便組織機構制定我的數據共享策略。
研究內容:構建具備以下兩個功能的人工智能系統(1)能夠跨多個數據源進行學習,而不會在訓練或決策期間泄漏數據的隱私信息;(2)提供激勵策略,以促使潛在競爭組織共享其數據。
4.3 AI定製的體系結構(AI-speci!carchitectures)
對AI的需求將會帶來系統和硬件架構的雙重革新。這些新式架構既能夠提高性能,同時也會經過提供易於組合的豐富的模塊化庫來簡化下一代AI應用的開發。研究課題7:特定領域定製的硬件
研究課題7:特定領域定製的硬件(Domainspecific hardware)。處理和存儲巨量的數據的能力是AI成功的關鍵因素之一(見2.1節),可是維持這種處理存儲能力增加的速度將會愈來愈具備挑戰性。正如第3部分所說,數據持續仍然呈指數級地增加,但40多年來支撐計算機工業發展的性能、成本、能耗方面的改進速度將放緩:
- 摩爾定律的終結致使晶體管不會變得過小,
- 登納德縮放定律(Dennardscaling)的失效使得電能限制了芯片的承載規模,
- 咱們已經從一個低效的處理器/芯片過渡到了一個芯片裝載多個高效處理器,
設計專用領域的處理器是保持處理器消耗能源帶來性能上提高的方法之一。這些處理器只會作少許的特定任務可是會將它們作到極致。所以摩爾定律下的處理器性能的快速提高必定是基於計算機架構的革新而不是半導體工藝的改進。將來的服務將會涉及到比過去更加多元化的處理器。一個具備開拓性的專用領域處理器的例子就是谷歌的張量處理單元(Tensor Processing Unit, TPU),它在2015被部署在谷歌的數據中心並由數十億人使用。相較於同期的CPU和GPU,它將深度神經網絡的前饋階段的執行速度提高了15到30倍,並且每瓦特的性能也提高了30到80倍。此外,微軟已宣佈在他的Azure雲平臺上部署了FPGA[88]。一系列的包括英特爾、IBM以及一些例如Cerebras和Graphcore這種初創公司在內的公司都在開發針對AI的特殊硬件,這會保持超越當前主流處理器的巨大性能提高的規律[19,48,54,78]。
考慮到DRAM也顯露出了一樣的極限,人們正在開發一些新奇的技術成爲它的繼任者。來自英特爾和鎂光的3D XPoint旨在保持類DRAM訪存性能的基礎上提供10倍的存儲能力。STTMRAM想要發展有相似於DRAM的擴展限制的閃存技術。所以雲端可能會有更多級的存儲和記憶能力,包含更普遍的技術。有了這些愈來愈多樣化的處理、記憶和存儲的設備以後,如何讓服務匹配到硬件資源便成爲一個挑戰性更大的難題。相比於包括一個機櫃頂部交換機和數十臺服務器每一個配備兩個CPU、1TB的DRAM和4TB的閃存的經典標準機架設計,這些快速的變化要求咱們建設更加靈活的雲計算平臺。
例如,UCBerkeley Firebox項目[41]提出了一種多機架的超級計算機,它能夠經過光纖將數以千計的處理器芯片與DRAM芯片和非易失性的存儲介質連接起來,提供低延時、高帶寬和長距離的傳輸能力。像這樣的硬件系統能夠支撐系統軟件基於恰當比例和類型的專用領域的處理器、DRAM和NVRAM來提供計算服務。這種大規模分離式的資源能夠極大提高越發多樣化的任務到與之匹配的多樣化資源的分配。這對AI的工做負載十分有價值,它能夠從大規模存儲中得到顯著的性能提高,而且適合應對多樣化的資源需求。
除了性能提高以外,新的硬件架構也會帶來其餘額外功能,例如對安全的支持。儘管英特爾的SGX和ARM的TrustZone正在涉足硬件安全環境,但在它們能夠徹底應用於AI應用以前還有不少工做要作。特別是現存的安全環境顯示出包括定址存儲在內的多種資源極限,它們僅是服務於通常目的的CPU。打破這種限制,提供這些包括GPU和TPU在內的專用處理器之上的通用硬件抽象即是將來的研究方向。此外,像RISC-V的開放指令集處理器表明着一種使人激動的開發新安全特性的大環境趨勢。
研究內容:(1)設計專用領域的硬件架構來以數量級爲單位提高性能下降AI應用消耗的能源,或者增強這些應用的安全性。(2)設計AI軟件系統,利用這些專用領域的架構、資源分離式的結構和將來的非易失性存儲技術。
研究課題8:組件化的AI系統
研究課題8:組件化的AI系統(Composable AI systems)。模塊化和組件化技術在軟件系統快速更新中扮演着重要的角色,他們使開發人員可以基於現有組件快速構建產生新的系統。這樣的例子包括微內核操做系統,LAMP棧,微服務架構和網絡。與此相反的是,現有的AI系統則是一整塊的,這便致使系統很難開發測試和更新。
與此相似,模塊化和組件化將會成爲提高AI系統開發速度和應用度的關鍵,這會使在複雜系統中集成AI更加地容易。接下來,咱們探討幾個關於模型和動做組合的研究問題。
模型組合(modelcomposition)對於開發更加複雜強大的AI系統相當重要。在一個模型服務系統中組合多種模型並以不一樣模式應用它們能夠取得決策精度、延遲和吞吐量之間的折中效果。例如,咱們能夠序列化的查詢模型,每個模型能夠反饋一個高準確度的決策或者說「我不知道」,而後決策會被傳遞到下一個模型。按照從最高到最低的「我不知道」比率和從最低到最高的延遲度來對模型加以排序,咱們就能夠同時優化延遲度和精確度了。
要想充分應用模型組合,仍然有不少難題亟待解決。例如(1)須要設計一種聲明式語言(declarative language)來描述這些組件之間的拓撲結構和應用的性能目標,(2)爲每一個組件提供包括資源需求量、延時和產能在內的精確的性能模型,(3)經過調度和優化算法來計算出這些組件執行的計劃,以及以最低消耗將組件匹配到相應的資源上來知足延時和吞吐量要求。
動做組合(actioncomposition)是將基本的決策/動做序列組織成低級原語,也稱爲選項(options)。例如對於無人駕駛汽車,某一個選項能夠是當在高速公路上行駛時變動車道,執行的動做包括了加速減速,左右轉向,打開轉向燈等。對於機器人,某一個原語能夠是抓取物體,執行的工做包括轉動機器人的關節。選項已經在層級學習中被普遍的研究[30,34,84,97,102,110],它能夠經過讓代理選擇一系列既存的選項來完成給定的任務而不是從更長的低級動做列表中選擇,以此來極大地加速對新環境的學習或適應性。
豐富的選項庫會使得新AI應用的開發就像當前的web開發人員經過調用強大的web接口以幾行代碼開發出應用同樣,經過簡單的組合恰當的選項來實現。另外,選項能夠提高響應能力,由於基於選項來選擇下一個動做要比在原始動做空間中選擇一個動做簡單得多。
研究內容:設計AI系統和接口,使得模型和動做以一種模塊化和靈活的方式進行組合,同時應用這些接口來開發豐富的模型和選項庫以此極大簡化AI應用的開發。
研究課題9:跨雲端和邊緣的系統
研究課題9:跨雲端和邊緣的系統(Cloud-edgesystems)。當今不少AI應用例如語音識別、天然語言翻譯是部署在雲上的。接下來咱們預計跨邊緣設備和雲端的AI系統將快速增長。一方面,將當前僅在雲上部署的AI系統例如用戶推薦系統,遷移他們的部分功能到邊緣設備上,這樣能夠提升安全性、保護隱私和下降時延(包括解決沒法鏈接網絡的問題)。另外一方面,當前部署在邊緣設備上的AI系統例如自動駕駛汽車、無人機和家用機器人都須要與雲端共享數據且利用雲端的計算資源來更新模型和策略[6]。
然而因爲多種緣由,要開發跨雲和邊緣的系統富有挑戰。首先,邊緣設備和雲端數據中心服務器之間的計算能力相差很大。將來這種差距會更大,由於包括智能手機和輸入板在內的邊緣設備相較於數據中心的服務器有嚴格的電量和體積大小的極限。第二,各邊緣設備之間在計算資源和能力上存在異構性,從低級的ARM或支持物聯網設備的RISC-V CPU到自動駕駛汽車和軟件平臺的高性能GPU。這種異構性致使應用開發的難度加大。第三,邊緣設備的硬件和軟件更新週期要遠遠慢於數據中心。第四,隨着存儲能力提高速度的放緩而數據產生速度的持續加快,再去存儲這些海量數據可能再也不可行或者變得低效。
有兩種方法能夠解決雲和邊緣設備的融合。一個是經過多目標軟件設計和編譯技術將代碼重定義到多樣化的平臺上面。爲了解決邊緣設備多樣化的狀況和升級運行在這些設備上的應用的困難,咱們須要定義新的軟件棧來抽象多種設備,將硬件能力以通用API的形式暴露給應用。另外一個可能的方向是開發編譯器和及時編譯技術從而有效的編譯正在運行的複雜算法,使它們可以在邊緣設備上運行。這可使用近期的代碼生成工具,例如TensorFlow和XLA、Halide和Weld。
第二個通用方法是設計適應於在雲和邊緣雲上分割執行的AI系統。例如,模型組合(見4.3)能夠是在邊緣設備上運行輕量級低精度的模型而在雲上運行計算密集型高精度的模型。這種架構能夠在不損失精確度的狀況降低低延時,並且已經在最近的視頻推薦系統中被採用[59,115]。再好比,動做組合能夠是將對層級選項的學習放在雲端,而這些選項的執行放在邊緣設備上。
機器人是另外一個能夠利用邊緣雲架構的領域。當前非常缺少機器人應用的開源平臺。做爲當今普遍使用的這種平臺的ROS被限制只在本地運行並且缺乏實時應用所須要的性能優化。爲了利用AI研究的新成果,例如共享學習和持續學習,咱們須要跨雲和邊緣雲的系統,他能夠容許開發者在機器人和雲之間無縫地遷移功能,從而優化決策延時和學習收斂。雲平臺能夠經過利用來自實時分佈式的機器人收集到的信息運行復雜算法持續更新模型,而機器人能夠基於以前下載的模型策略在本地持續地執行動做。
爲了解決從邊緣設備收集到的大量數據,能夠採用適應於學習的壓縮方法來減小處理開銷,例如經過採樣(sampling)和梗概(sketching),這些方法都已經成功的應用在分析工做負載的任務上了[4,10,28,51,81]。一個研究方向就是以系統化的方式利用採樣和梗概的方法來支持多種學習算法和預測任務。一個更大的挑戰是減少存儲消耗,這可能須要刪除數據。關鍵是咱們不知道將來數據會如何被使用。這是一個壓縮問題,並且是針對於機器學習算法的壓縮。此外,基於採樣和梗概的分佈式方法能夠幫助解決該問題,就像機器學習方法在特徵選擇或模型選擇策略上的應用同樣。
研究方向:設計跨雲端和邊緣的AI系統,(1)利用邊緣設備減少延時、提高安全性並實現智能化的數據記憶技術,(2)利用雲平臺來共享各邊緣設備的數據和模型,訓練複雜的計算密集型的模型和採起高質量的決策。
結論
人工智能在過去十年中取得的驚人進展,使其從研究實驗室的研究項目成功轉化爲目前能夠取代大量人力的商業應用核心技術。人工智能系統和機器人不但取代了部分人類工做者,並且有挖掘人類潛力和促進新形式合做的做用[44]。
若想令人工智能更好地服務咱們,要克服許多艱鉅的挑戰,其中許多挑戰與系統和基礎設施有關。人工智能系統須要作出更快、更安全和更易於解讀的決策,確保這些決策在針對多種攻擊類型的學習過程當中獲得準確的結果,在摩爾定律終結的前提下不斷提升計算能力,以及構建易於整合到現有應用程序中的可組合系統,而且具備跨越雲端和邊緣的處理能力。
本文總結了幾個系統、體系結構和安全方面的研究課題,咱們但願這些問題可以啓發新的研究來推進人工智能的發展,使其計算能力更強,具備可解釋性、安全性和可靠性。
- 1. Michael I. Jordan聯合UC伯克利13位重量級學者:下一代人工智能系統的4大趨勢和9大研究課題
- 2. 伯克利人工智能研究院最新研究:協作型工業機器人如何更智能?
- 3. 伯克利人工智能研究:FaSTrack——一種確保動態系統的安全導航工具
- 4. 大智能時代,未來人工智能發展新趨勢
- 5. 哈佛大學研究新人工智能系統:超越人類大腦
- 6. 人工智能,大數據下的 Python語言發展趨勢
- 7. 致研究者:2018 AI 研究趨勢
- 8. 大數據、物聯網與人工智能三大趨勢的將來預測
- 9. 大數據、物聯網與人工智能三大趨勢的未來預測
- 10. 大數據和人工智能未來發展趨勢
- 更多相關文章...
- • 事務的四大特性和隔離級別 - Hibernate教程
- • Docker 命令大全 - Docker教程
- • Docker容器實戰(七) - 容器眼光下的文件系統
- • 適用於PHP初學者的學習線路和建議
-
每一个你不满意的现在,都有一个你没有努力的曾经。