大數據開發:剖析Hadoop和Spark的Shuffle過程差別
1、前言面試
對於基於MapReduce編程範式的分佈式計算來講,本質上而言,就是在計算數據的交、並、差、聚合、排序等過程。而分佈式計算分而治之的思想,讓每一個節點只計算部分數據,也就是隻處理一個分片,那麼要想求得某個key對應的全量數據,那就必須把相同key的數據聚集到同一個Reduce任務節點來處理,那麼Mapreduce範式定義了一個叫作Shuffle的過程來實現這個效果。算法
2、編寫本文的目的編程
本文旨在剖析Hadoop和Spark的Shuffle過程,並對比二者Shuffle的差別。緩存
3、Hadoop的Shuffle過程網絡
Shuffle描述的是數據從Map端到Reduce端的過程,大體分爲排序(sort)、溢寫(spill)、合併(merge)、拉取拷貝(Copy)、合併排序(merge sort)這幾個過程,大致流程以下:架構
- 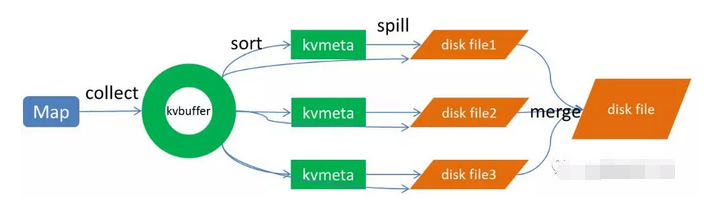
上圖的Map的輸出的文件被分片爲紅綠藍三個分片,這個分片的就是根據Key爲條件來分片的,分片算法能夠本身實現,例如Hash、Range等,最終Reduce任務只拉取對應顏色的數據來進行處理,就實現把相同的Key拉取到相同的Reduce節點處理的功能。下面分開來講Shuffle的的各個過程。分佈式
Map端作了下圖所示的操做:函數
- 一、Map端sort
Map端的輸出數據,先寫環形緩存區kvbuffer,當環形緩衝區到達一個閥值(能夠經過配置文件設置,默認80),便要開始溢寫,但溢寫以前會有一個sort操做,這個sort操做先把Kvbuffer中的數據按照partition值和key兩個關鍵字來排序,移動的只是索引數據,排序結果是Kvmeta中數據按照partition爲單位彙集在一塊兒,同一partition內的按照key有序。oop
二、spill(溢寫) 學習
當排序完成,便開始把數據刷到磁盤,刷磁盤的過程以分區爲單位,一個分區寫完,寫下一個分區,分區內數據有序,最終實際上會屢次溢寫,而後生成多個文件
三、merge(合併)
spill會生成多個小文件,對於Reduce端拉取數據是至關低效的,那麼這時候就有了merge的過程,合併的過程也是同分片的合併成一個片斷(segment),最終全部的segment組裝成一個最終文件,那麼合併過程就完成了,以下圖所示

至此,Map的操做就已經完成,Reduce端操做即將登場
Reduce操做
整體過程以下圖的紅框處:
- 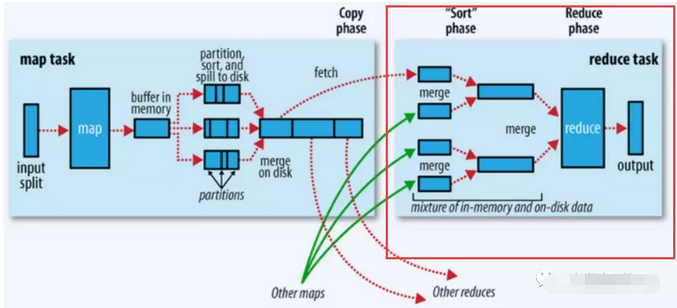
- 一、拉取拷貝(fetch copy)
Reduce任務經過向各個Map任務拉取對應分片。這個過程都是以Http協議完成,每一個Map節點都會啓動一個常駐的HTTP server服務,Reduce節點會請求這個Http Server拉取數據,這個過程徹底經過網絡傳輸,因此是一個很是重量級的操做。
- 二、合併排序
Reduce端,拉取到各個Map節點對應分片的數據以後,會進行再次排序,排序完成,結果丟給Reduce函數進行計算。
4、總結
至此整個shuffle過程完成,最後總結幾點:
- shuffle過程就是爲了對key進行全局聚合
- 排序操做伴隨着整個shuffle過程,因此Hadoop的shuffle是sort-based的
Spark shuffle相對來講更簡單,由於不要求全局有序,因此沒有那麼多排序合併的操做。Spark shuffle分爲write和read兩個過程。咱們先來看shuffle write。
- 1、shuffle write
shuffle write的處理邏輯會放到該ShuffleMapStage的最後(由於spark以shuffle發生與否來劃分stage,也就是寬依賴),final RDD的每一條記錄都會寫到對應的分區緩存區bucket,以下圖所示:

說明:
- 上圖有2個CPU,能夠同時運行兩個ShuffleMapTask
- 每一個task將寫一個buket緩衝區,緩衝區的數量和reduce任務的數量相等
- 每一個buket緩衝區會生成一個對應ShuffleBlockFile
- ShuffleMapTask 如何決定數據被寫到哪一個緩衝區呢?這個就是跟partition算法有關係,這個分區算法能夠是hash的,也能夠是range的
- 最終產生的ShuffleBlockFile會有多少呢?就是ShuffleMapTask 數量乘以reduce的數量,這個是很是巨大的
那麼有沒有辦法解決生成文件過多的問題呢?有,開啓FileConsolidation便可,開啓FileConsolidation以後的shuffle過程以下:

在同一核CPU執行前後執行的ShuffleMapTask能夠共用一個bucket緩衝區,而後寫到同一份ShuffleFile裏去,上圖所示的ShuffleFile其實是用多個ShuffleBlock構成,那麼,那麼每一個worker最終生成的文件數量,變成了cpu核數乘以reduce任務的數量,大大縮減了文件量。
- 2、Shuffle read
Shuffle write過程將數據分片寫到對應的分片文件,這時候萬事具有,只差去拉取對應的數據過來計算了。
那麼Shuffle Read發送的時機是什麼?是要等全部ShuffleMapTask執行完,再去fetch數據嗎?理論上,只要有一個 ShuffleMapTask執行完,就能夠開始fetch數據了,實際上,spark必須等到父stage執行完,才能執行子stage,因此,必須等到全部 ShuffleMapTask執行完畢,纔去fetch數據。fetch過來的數據,先存入一個Buffer緩衝區,因此這裏一次性fetch的FileSegment不能太大,固然若是fetch過來的數據大於每個閥值,也是會spill到磁盤的。
fetch的過程過來一個buffer的數據,就能夠開始聚合了,這裏就遇到一個問題,每次fetch部分數據,怎麼能實現全局聚合呢?以word count的reduceByKey(《Spark RDD操做之ReduceByKey 》)爲例,假設單詞hello有十個,可是一次fetch只拉取了2個,那麼怎麼全局聚合呢?Spark的作法是用HashMap,聚合操做其實是map.put(key,map.get(key)+1),將map中的聚合過的數據get出來相加,而後put回去,等到全部數據fetch完,也就完成了全局聚合。
- 3、總結
Hadoop的MapReduce Shuffle和Spark Shuffle差異總結以下:
- Hadoop的有一個Map完成,Reduce即可以去fetch數據了,沒必要等到全部Map任務完成,而Spark的必須等到父stage完成,也就是父stage的map操做所有完成才能去fetch數據。
- Hadoop的Shuffle是sort-base的,那麼不論是Map的輸出,仍是Reduce的輸出,都是partion內有序的,而spark不要求這一點。
- Hadoop的Reduce要等到fetch徹底部數據,纔將數據傳入reduce函數進行聚合,而spark是一邊fetch一邊聚合。
以爲不錯請點贊支持,歡迎留言或進個人我的羣855801563領取【架構資料專題目合集90期】、【BATJTMD大廠JAVA面試真題1000+】,本羣專用於學習交流技術、分享面試機會,拒絕廣告,我也會在羣內不按期答題、探討。
- 1. 大數據開發:剖析Hadoop和Spark的Shuffle過程差異
- 2. 剖析Hadoop和Spark的Shuffle過程差別(二)
- 3. 剖析Hadoop和Spark的Shuffle過程差別(一)
- 4. 剖析Hadoop和Spark的Shuffle過程差異(二)
- 5. 剖析Hadoop和Spark的Shuffle過程差異(一)
- 6. Spark的shuffle剖析!
- 7. 對比 Hadoop MapReduce 和 Spark 的 Shuffle 過程
- 8. MapReduce過程、Spark和Hadoop以Shuffle爲中心的對比分析
- 9. 【Spark二八Spark Shuffle讀過程源代碼代碼剖析
- 10. spark Shuffle過程分析
- 更多相關文章...
- • Swift 析構過程 - Swift 教程
- • 事務的四大特性和隔離級別 - Hibernate教程
- • PHP開發工具
- • TiDB 在摩拜單車在線數據業務的應用和實踐
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 外部其他進程嵌入到qt FindWindow獲得窗口句柄 報錯無法鏈接的外部符號 [email protected] 無法被([email protected]@[email protected]@@引用
- 2. UVa 11524 - InCircle
- 3. The Monocycle(bfs)
- 4. VEC-C滑窗
- 5. 堆排序的應用-TOPK問題
- 6. 實例演示ElasticSearch索引查詢term,match,match_phase,query_string之間的區別
- 7. 數學基礎知識 集合
- 8. amazeUI 復擇框問題解決
- 9. 揹包問題理解
- 10. 算數平均-幾何平均不等式的證明,從麥克勞林到柯西
- 1. 大數據開發:剖析Hadoop和Spark的Shuffle過程差異
- 2. 剖析Hadoop和Spark的Shuffle過程差別(二)
- 3. 剖析Hadoop和Spark的Shuffle過程差別(一)
- 4. 剖析Hadoop和Spark的Shuffle過程差異(二)
- 5. 剖析Hadoop和Spark的Shuffle過程差異(一)
- 6. Spark的shuffle剖析!
- 7. 對比 Hadoop MapReduce 和 Spark 的 Shuffle 過程
- 8. MapReduce過程、Spark和Hadoop以Shuffle爲中心的對比分析
- 9. 【Spark二八Spark Shuffle讀過程源代碼代碼剖析
- 10. spark Shuffle過程分析