一鍵更換轉載博客的全部圖牀
一鍵更換轉載博客的全部圖牀
1、引言
有時看到一些博客寫的不錯,貼個連接當然愉快,但過段時間總會發現要麼博客中的圖片掛了,要麼直接是博客掛了。因此出於保護原博主的寶貴心血不至於白流(手動狗頭),進行了一番折騰(固然,請註明轉載並標註出處)。html
本次折騰的思路是:利用正則表達式批量導出原博的全部圖牀連接,批量下載後經過調用Tencent cos的API進行批量上傳,最後批量獲取騰訊雲中的圖片連接並以此替換掉原博客中的圖牀連接。python
2、基礎內容
1. 正則部分
做爲正則的入門,劉江的博客介紹的很是系統,以後再結合文檔等的函數說明基本就夠用了。git
須要注意的是,re.match只匹配字符串的開始,若是字符串開始不符合正則表達式,則匹配失敗,函數返回None;而re.search/re.findall匹配整個字符串,直到找到一個匹配。re.sub並不會直接替換目標字符串,通常須要藉助賦值語句。github
1-1. 關於字符串str、bytes編碼
本次匹配雖然無涉編碼正則表達式
- str
在python3中,str字符串是以Unicode進行編碼的。算法
具體的說,當咱們實例化一個字符串時,如
list ='the winter is coming'。python將默認該字符串爲str類型,同時將經過Unicode映射表將該字符串映射爲對應的Unicode編碼。全部的字符串相關的操做都將經過操做對應的Unicode編碼實現。express但當咱們要儲存這個字符串時,因爲Unicode並非具體的實現方式(即存儲編碼方式),咱們須要指定具體的編碼方式,如python默認的utf-8。api
- bytes
bytes其實應該理解爲存儲在系統中的具體的字節流對象,而不存在什麼單獨的bytes類型字符串。若是咱們要解讀一個bytes對象,咱們須要知道對應的編碼方式(不是像Unicode這樣的編碼規範,而是像utf-8這樣的具體編碼方式)。服務器
使咱們迷惑的是這麼一種聲明方式:函數
>>> bytes([1,2,3,4,5,6,7,8,9]) >>> bytes("python", 'ascii') # 字符串,編碼然而,這兩種方式都是以默認或指定的方式將字符串編碼爲字節流。
參考:
python3字符串編碼總結-str(unicode)_bytes
2. Tencent COS API調用
這裏使用騰訊雲的對象存儲,是由於接口調用相對簡單,且擁有50G的免費空間,通常我的博客使用是夠用了。若是想用其餘雲盤服務也是能夠的。
2-1. 註冊cos服務
https://cloud.tencent.com/product/cos
2-2. 建立存儲桶:(bucket)
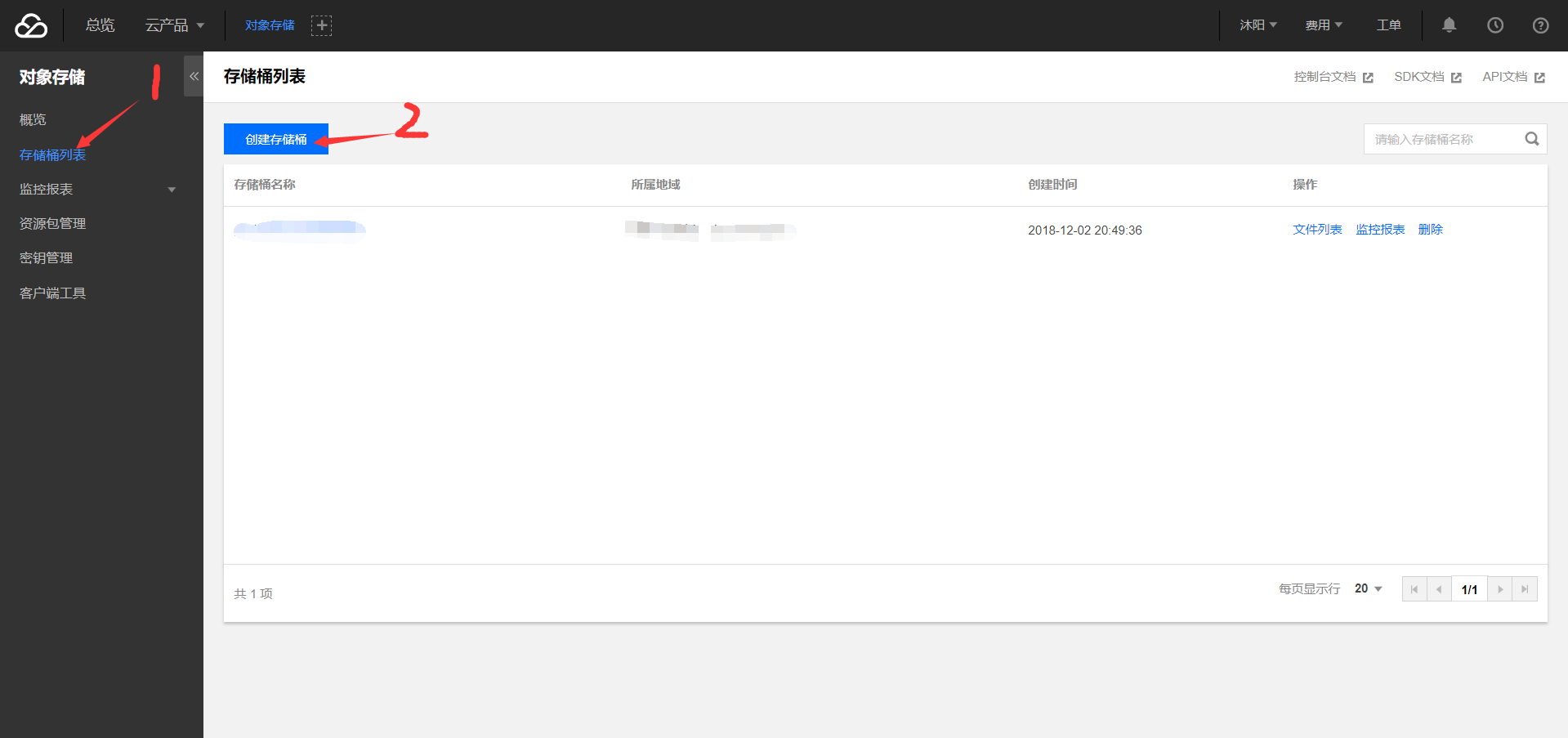
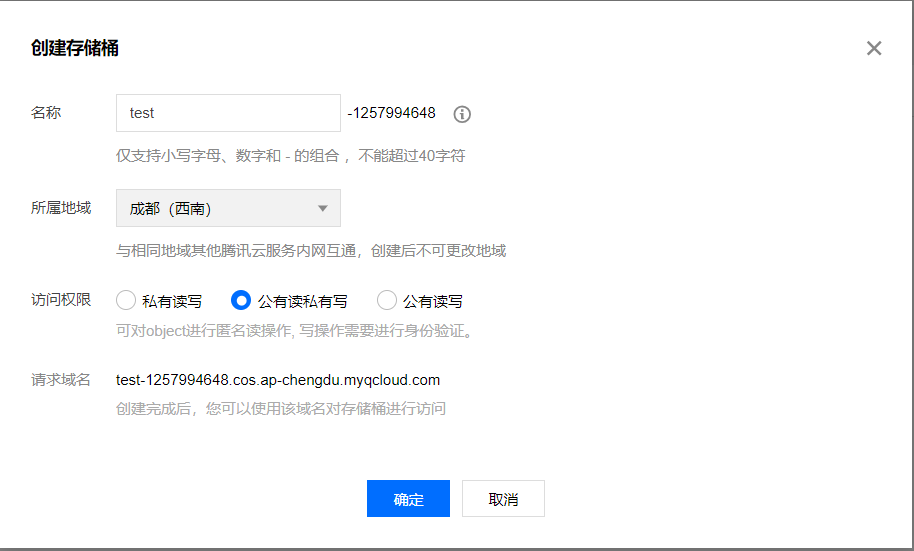
肯定後點擊基礎配置
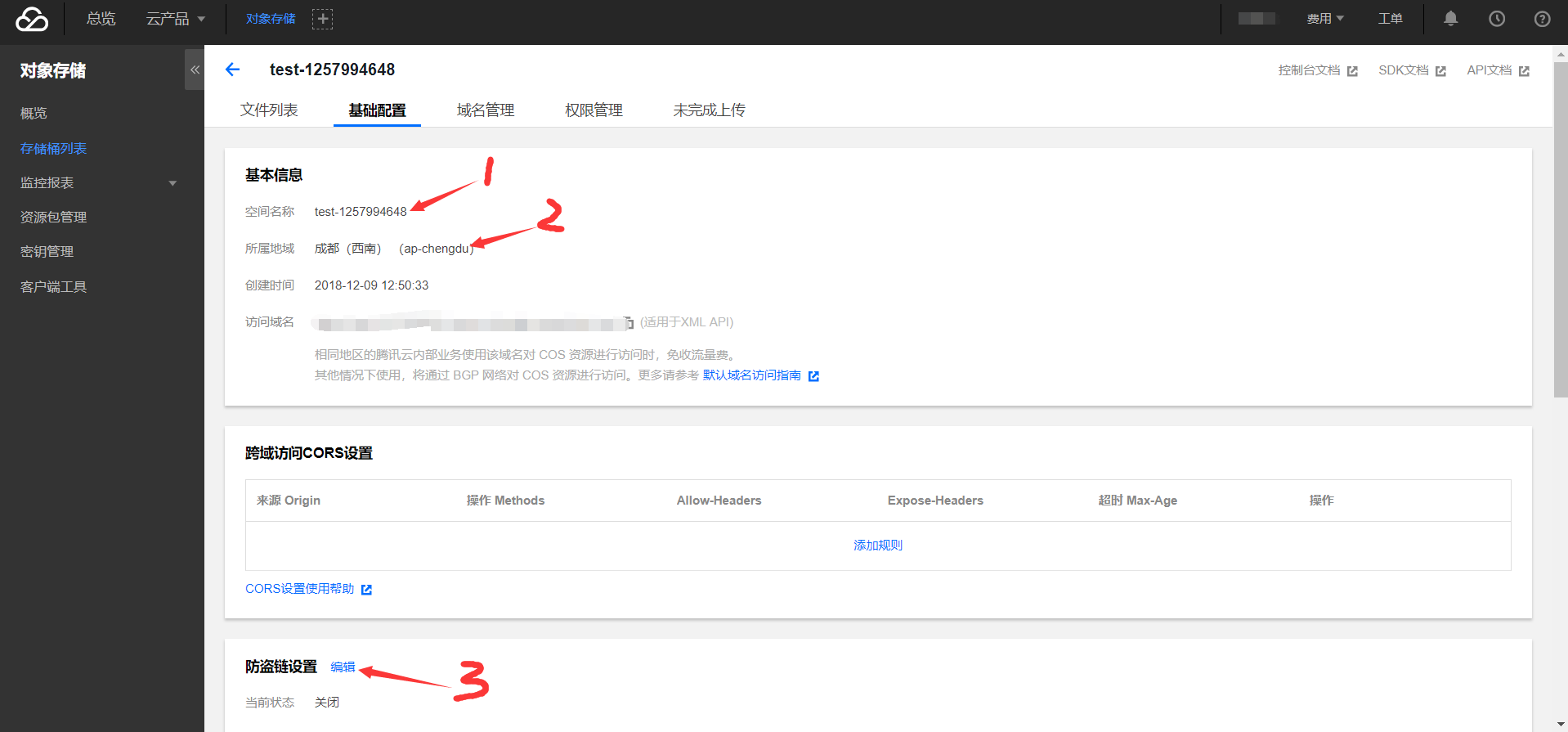
- 將空間名稱(bucket)「test-1257994648」粘貼保存。
- 所屬區域(region)的「ap-chengdu」粘貼保存,後面調用API時會用到。
- 編輯防盜鏈設置,在白名單中添加你的域名(博客連接)。
2-3. 新建祕鑰
使用調用騰訊雲API時須要簽名,雲API密鑰用於生成簽名。
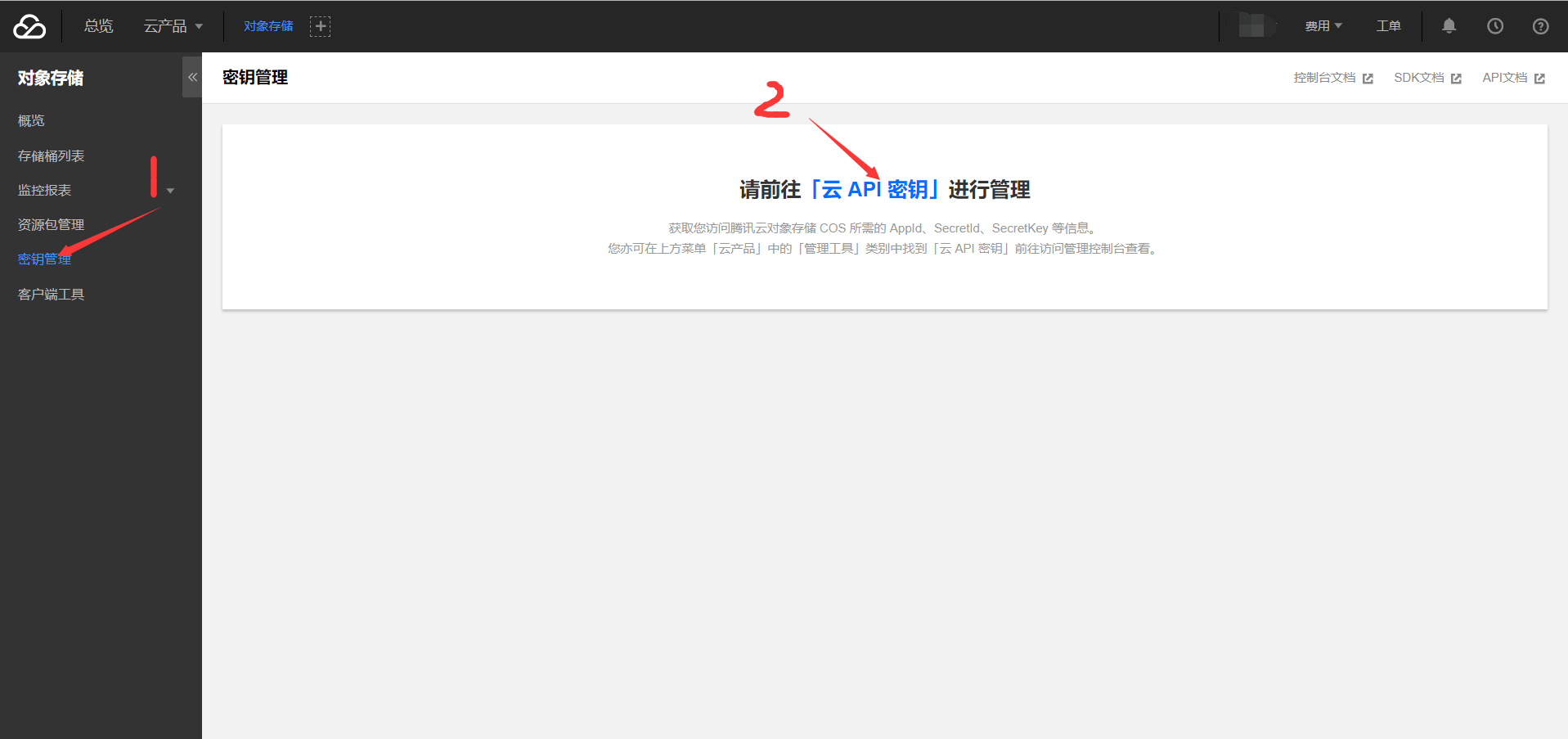
而後在打開的頁面中點擊「新建祕鑰」,將得到的SecretId和SecretKey妥善保存。
2-4. 安裝 SDK
安裝 SDK 有三種安裝方式:pip 安裝、手動安裝和離線安裝。
2-4-1. 使用 pip 安裝(推薦)
pip install -U cos-python-sdk-v5
2-4-2. 手動安裝
從 XML Python SDK 下載源碼,經過 setup 手動安裝,執行如下命令。
python setup.py install
2-4-3. 離線安裝
# 在有外網的機器下運行以下命令
mkdir cos-python-sdk-packages
pip download cos-python-sdk-v5 -d cos-python-sdk-packages
tar -czvf cos-python-sdk-packages.tar.gz cos-python-sdk-packages
# 將安裝包拷貝到沒有外網的機器後運行以下命令
# 請確保兩臺機器的 python 版本保持一致,不然會出現安裝失敗的狀況
tar -xzvf cos-python-sdk-packages.tar.gz
pip install cos-python-sdk-v5 --no-index -f cos-python-sdk-packages
2-5. 調用API
完成上面的步驟後,調用API就很簡單了。查查文檔,修改便可。
不過最新版的SDK中未貼出建立、刪除目錄等操做(歷史版本下的SDK對此卻提供了支持)。經過摸索,發現多個函數方法中都包含的一個關鍵參數的說明是這樣的:

解決之道就在此中。
- 建立文件夾:調用client.put_object方法實現。在上傳文件時,在文件名(就是後面demo中的file_name/key)中給出想建立的文件夾,將會自動建立。
- 刪除文件夾:調用client.delete_object方法實現。須要先刪除文件夾下全部文件後才能刪除文件夾。要刪除文件夾時,只要將文件夾名傳給key參數就行。好比要刪除「EM算法」,則傳入「EM算法/」。
2-5-1. python SDK的參考文檔連接以下:
2-5-2. 大概流程:
- 導入SDK的相關包
- 使用上面建立的祕鑰和ID來生成包含了簽名的client對象
- 調用client的相應方法完成咱們須要的功能
2-5-3. demo:
# 下面是調用前的重複性工做
## 1. 設置用戶配置, 包括 secretId,secretKey 以及 Region
## -*- coding=utf-8
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
import sys
import logging
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
secret_id = 'xxxxxxxx' # 替換爲用戶的 secretId
secret_key = 'xxxxxxx' # 替換爲用戶的 secretKey
region = 'ap-beijing-1' # 替換爲用戶的 Region
token = None # 使用臨時密鑰須要傳入 Token,默認爲空,可不填
scheme = 'https' # 指定使用 http/https 協議來訪問 COS,默認爲 https,可不填
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token, Scheme=scheme)
## 2. 獲取客戶端對象
client = CosS3Client(config)
## 參照下文的描述。或者參照 Demo 程序,詳見 https://github.com/tencentyun/cos-python-sdk-v5/blob/master/qcloud_cos/demo.py
# 下面是API調用的實例,你能夠根據需求從文檔找到須要的方法。
file_name = 'test.txt'
with open('D://test.txt', 'rb') as fp:
response = client.put_object(
Bucket='test04-123456789',
Body=fp,
Key=file_name,
StorageClass='STANDARD',
ContentType='text/html; charset=utf-8'
)
print(response['ETag'])
3、實踐
1. 匹配原博圖片連接
第一步是匹配出原博中全部的圖片連接(固然,其餘連接也能夠)。
此次我轉載的是CSDN上的一篇博客,CSDN的圖片連接是這樣的:[](圖片地址2)
對應的正則表達式爲:\\[!\\[.*?\\]\\(.*?\\)\\]\\((.*?)\\)
注意:
- 因爲‘[ ] ( )’等在正則表達式中都有別義,因此須要單獨加上轉義符‘\’。須要指出的是,此處使用python的原生字符串(即在字符串前加上一個「r」)實際效果區別不大。具體區別可參考:python正則表達式轉義注意事項
- 這裏須要加上?來進行非貪婪匹配,以防會漏掉連接。
- 後面的一對未轉義的圓括號是爲了僅僅將括號裏的連接輸出出來。
2. 下載圖片到本地
將所得的圖片連接下載到本地,爲下一步上傳作準備。
3. 上傳圖片到雲端
調用API實現。
4. 得到圖牀連接
本應該經過API批量生成分享連接,但實踐發現,騰訊的分享連接接口有個expire參數,用於控制連接有效時間,默認300秒,很是不便。後來經過觀察發現,存儲桶中的文件直鏈結構很是簡單,直接由桶的域名加上文件名就構成了。若是你的連接訪問不了,請檢查桶的讀權限是否爲公有。
5. 將原博中的圖片連接更換爲本身的圖牀連接
這個簡單,經過正則匹配就能夠了。
4、完整代碼
最後貼上代碼,有須要的能夠本身修改使用。
# -*- coding=utf-8
import re
import os
import urllib
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
import sys
import logging
# 將本地md中的圖片連接提取出並儲存於urllist中,
blog_url = 'C:\\Users\\zzp\OneDrive - stu.xjtu.edu.cn\\文檔\\typora\\草稿.md'
blog_name = re.match(u'(.*)\.md$',os.path.basename(blog_url)).group(1)
pic_type = []
try:
f = open(blog_url, encoding='utf-8')
lines = f.readlines()
except FileNotFoundError as e:
print("夭壽啦,文件沒找到!")
f.close()
urllist =[]
compile_eurl = re.compile('\[!\[.*?\]\(.*?\)\]\((.*?)\)')
for line in lines:
try:
urllist.extend(compile_eurl.findall(line))
except AttributeError as e:
print("error")
# 獲取圖片後綴,以備後面命名使用
pic_type = re.match('.*?\.([a-zA-Z]{3}$)', urllist[0]).group(1)
# 批量下載連接對應圖片到本地
for i in range(len(urllist)):
try:
urllib.request.urlretrieve(urllist[i], "D:/臨時/"+blog_name+'_'+str(i) + '.'+pic_type)
except:
print('夭壽啦,下載失敗啦!')
print('完成圖片下載')
## 利用騰訊提供的cos存儲官網sdk進行批量上傳
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
## 設置用戶屬性, 包括secret_id, secret_key, region
secret_id = 'AKERXXXXXXXXXXXXXXXXXXXXXXXX' # 替換爲你的secret_id
secret_key = 'TmxxXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # 替換爲你的的secret_key
region = 'ap-chengdu' # 替換爲你的region/服務器地域編號
token = None # 使用臨時祕鑰須要傳入Token,默認爲空,可不填
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token) # 獲取配置對象
client = CosS3Client(config)
# 文件流 簡單上傳
for i in range(len(urllist)):
with open("D:/臨時/"+blog_name+'_'+str(i) + '.'+pic_type, 'rb') as fp:
response = client.put_object(
Bucket='test-1257994648', # 咱們上面保存的空間名
Body=fp,
Key=blog_name + '_' + str(i) + '.' + pic_type,
StorageClass='STANDARD',
ContentType='text/html; charset=utf-8'
)
print('完成圖片上傳')
# 更換博客圖片連接
i = len(urllist)
compile_url = re.compile(u'\[!\[.*?\]\(.*?\)\]\(.*?\)')
for x in range(len(lines)):
while compile_url.findall(lines[x]):
lines[x] = re.sub(compile_url, ') + '.' + pic_type+')', lines[x], count=1)
i = i+1
print(lines)
# 寫入博客
with open(blog_url, encoding='utf-8', mode='w') as f:
f.writelines(lines)
- 1. 一鍵轉載CSDN博客
- 2. (轉)如何一鍵轉載CSDN博客()
- 3. (轉)PicGo+GitHub圖牀+微博圖牀
- 4. 博客圖牀遷移記
- 5. Typora+騰訊雲圖牀+Picgo實現真正的博客圖片一鍵上傳
- 6. 使用Github做爲博客的圖牀
- 7. 博客的轉載
- 8. 全部博客
- 9. 轉載博客
- 10. 博客轉載
- 更多相關文章...
- • XSLT - 轉換 - XSLT 教程
- • C# 類型轉換 - C#教程
- • Tomcat學習筆記(史上最全tomcat學習筆記)
- • IntelliJ IDEA 代碼格式化配置和快捷鍵
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 一鍵轉載CSDN博客
- 2. (轉)如何一鍵轉載CSDN博客()
- 3. (轉)PicGo+GitHub圖牀+微博圖牀
- 4. 博客圖牀遷移記
- 5. Typora+騰訊雲圖牀+Picgo實現真正的博客圖片一鍵上傳
- 6. 使用Github做爲博客的圖牀
- 7. 博客的轉載
- 8. 全部博客
- 9. 轉載博客
- 10. 博客轉載