雪球在股市風暴下的高可用架構改造分享 | 首席架構師親述應對30倍峯值歷程
本文根據唐福林老師在「高可用架構」微信羣所作的《股市風暴下的雪球架構改造經驗分享》整理而成。前端
轉自微信公衆號ArchNotes。java
唐福林,雪球首席架構師,負責雪球業務快速增加應對及服務性能與穩定架構優化工做。畢業於北京師範大學,碩士學位。以前曾任微博平臺資深架構師,微博技術委員會成員。長期關注並從事互聯網服務後端性能及穩定性架構優化工做。node
分享主題mysql
一. 雪球公司介紹
二. 雪球當前整體架構
三. 雪球架構優化歷程
四. 聊聊關於架構優化的一些總結和感想android
一. 雪球公司介紹ios
雪球 聰明的投資者都在這裏。nginx
web 1.0:新聞資訊,股價信息,K線圖git
web 2.0:SNS 訂閱,分享,聊天web
web 3.0:移動 APP,交易閉環redis
雪球如今員工數還不到100,其中技術人員佔一半。去年9月C輪融資4kw刀。咱們如今的技術棧由下列組件組成:Java,Scala,Akka,Finagle,Nodejs,Docker ,Hadoop。咱們當前是租用IDC機房自建私有云,正在往「公私混合雲」方向發展。
在雪球上,用戶能夠獲取滬深港美2w+股票的新聞信息,股價變化狀況,也能夠獲取債券,期貨,基金,比特幣,信託,理財,私募等等理財產品的各種信息,也能夠關注雪球用戶創建的百萬組合,訂閱它們的實時調倉信息,還能夠關注雪球大V。雪球當前有百萬日活躍用戶,天天有4億的API調用。App Store 財務免費榜第 18 名。歷史上曾排到財務第二,總免費榜第 19。
二. 雪球當前整體架構
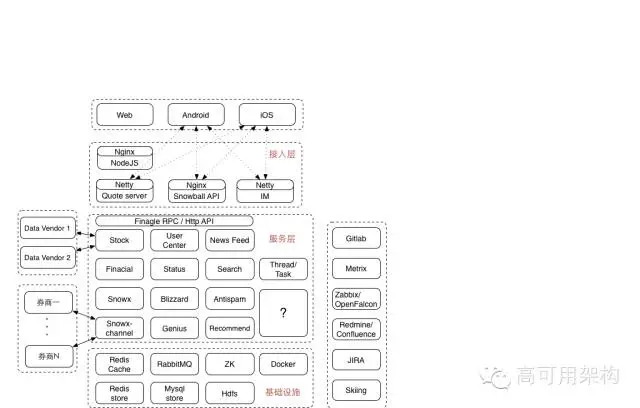
做爲一個典型的移動互聯網創業公司,雪球的整體架構也是很是典型的設計:
最上層是三個端:web端,android端和iOS端。流量比例大約爲 2:4:4 。web3.0 的交易功能,在 web 端並不提供。
接入層以及下面的幾個層,都在咱們的自建機房內部。雪球當前只部署了一個機房,還屬於單機房時代。正在進行「私有云+公有云混合部署」方案推動過程當中。
咱們當前使用 nodejs 做爲 web 端模板引擎。nodejs 模塊與android 和 ios 的 app 模塊一塊兒屬於大前端團隊負責。
再往下是位於 nginx 後面的 api 模塊。跟 linkedin 的 leo 和微博的 v4 同樣,雪球也有一個遺留的大一統系統,名字就叫 snowball 。最初,全部的邏輯都在 snowball 中實現的。後來慢慢的拆出去了不少 rpc 服務,再後來慢慢的拆出去了一些 http api 作成了獨立業務,但即使如此,snowball 仍然是雪球系統中最大的一個部署單元。
在須要性能的地方,咱們使用 netty 搭建了一些獨立的接口,好比 quoto server,是用來提供開盤期間每秒一次的股價查詢服務,單機 qps 5w+,這個一會再細說;而 IM 服務,起初設計裏是用來提供聊天服務,而如今,它最大的用途是提供一個可靠的 push 通道,提供 5w/s 的消息下發容量,這個也一會再細說。
雪球的服務化拆分及治理採用 twitter 開源的 finagle rpc 框架,並在上面進行了一些二次開發和定製。定製的功能主要集中在 access log 加強,和 fail fast,fail over 策略及降級開關等。 finagle 的實現比較複雜,debug 和二次開發的門檻較高,團隊內部對此也進行了一些討論。
雪球的業務比較複雜,在服務層中,大體能夠分爲幾類:第一類是web1.0,2.0 及基礎服務,咱們稱爲社區,包括用戶,帖子,新聞,股價,搜索等等,類比對象就是新浪財經門戶+微博;第二類是組合及推薦,主要提供股票投資策略的展現和建議,類比對象是美國的motif;第三類是通道,相似股市中的「支付寶」,接入多家券商,提供瞬間開戶,一鍵下單等等各類方便操做的功能。
雪球的業務實現中,包含不少異步計算邏輯,好比搜索建索引,好比股票漲跌停發通知,好比組合收益計算等等,爲此,咱們設計了一個獨立的 Thread/Task 模塊,方便管理全部的後臺計算任務。但隨着這些 task 愈來愈多,邏輯差別愈來愈大,一個統一的模塊並非老是最佳的方案,因此,咱們又把它拆成了兩大類:流式的,和批量式的。
雪球的推薦體系包括組合推薦「買什麼」和個性化推薦。咱們最近正在從新梳理咱們的大數據體系,這個感興趣的話能夠單聊。
最下面是基礎設施層。雪球基礎設施層包括:redis,mysql,mq,zk,hdfs,以及容器 docker。
線上服務以外,咱們的開發及後臺設施也很典型:gitlab開發,jenkins打包,zabbix 監控系統向 openfalcon 遷移,redimine向confluence遷移,jira,以及內部開發的 skiing 後臺管理系統。
三. 雪球架構優化歷程
首先描述一下標題中的「股市動盪」定語修飾詞吧:
上證指數從年初的3000點半年時間漲到了5000多,6月12號達到最高點5200點,而後就急轉直下,最大單日跌幅 8.48%,一路跌回4000點如下。最近一週都在3900多徘徊。
3月最後一週,A股開戶 166萬戶,超過歷史最高紀錄 2007年5月第二週165萬戶。
4月份,證監會宣佈A股支持單用戶開設多帳戶。
6月底,證金公司表明國家隊入場救市。
7月份,證監會宣佈嚴打場外配資。
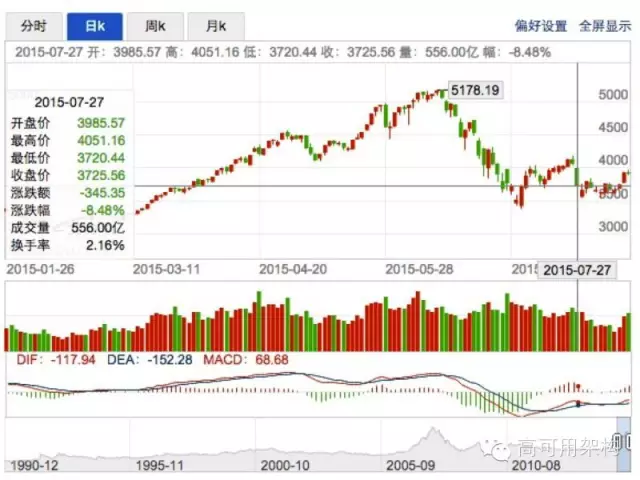
7月27號將近2000股跌停,IM推送消息數超過平時峯值300倍

外網帶寬消耗,一年10倍的增加

中國好聲音廣告第一晚,帶來超過平時峯值200倍的註冊量
挑戰:小 VS 大:
小:小公司的體量,團隊小,機器規模小
大:堪比大公司的業務線數量,業務複雜度,瞬間峯值衝擊
雪球的業務線 = 1個新浪財經 + 1 個微博 + 1 個 motif + 1 個大智慧/同花順。因爲基數小,API調用瞬間峯值大約爲平時峯值的 30+ 倍。
挑戰:快速增加,移動互聯網 + 金融,風口,A股大盤劇烈波動。
首先,在app端,在咱們核心業務從 web2.0 sns 向 3.0 移動交易閉環進化的過程當中,咱們開發了一個本身的 hybrid 框架:本地原生框架,加離線 h5 頁面,以此來支撐咱們的快速業務迭代。當前,雪球前端能夠作到 2 週一個版本,且同時並行推動 3 個版本:一個在 app store 等待審覈上線,一個在內測或公測,一個在開發。咱們的前端架構師孟祥宇在今年的 wot 上有一個關於這方面的詳細分享,有興趣的能夠稍後再深刻了解。
雪球App實踐—構建靈活、可靠的Hybrid框架 http://wot.51cto.com/2015mobile/ http://down.51cto.com/data/2080769
另外,爲了保障服務的可用性,咱們作了一系列的「端到端服務質量監控」。感興趣的能夠搜索我今年4月份在環信SM meetup上作的分享《移動時代端到端的穩定性保障》。其中在 app 端,咱們採用了一種代價最小的數據傳輸方案:對用戶的網絡流量,電池等額外消耗幾乎爲0
每一個請求裏帶上前一個請求的結果
succ or fail : 1 char
失敗緣由:0 - 1 char
請求接口編號: 1 char
請求耗時:2 - 3 char
其它:網絡制式,etc
炒股的人大多都會盯盤:即在開盤期間,開着一個web頁面或者app,實時的看股價的上下跳動。說到「實時」,美股港股當前都是流式的數據推送,但國內的A股,基本上都是每隔一段時間給出一份系統中全部股票現價的一個快照。這個時間間隔,理論上是3秒,實際上通常都在5秒左右。 交了錢簽了合同,雪球做爲合做方就能夠從交易所下屬的數據公司那裏拿到數據了,而後提供給本身的用戶使用。
剛纔介紹整體架構圖的時候有提到 quote server ,說到這是須要性能的地方。
業務場景是這樣的,雪球上我的主頁,開盤期間,每秒輪詢一次當前用戶關注的股票價格變更狀況。在內部,全部的組合收益計算,每隔一段時間須要獲取一下當前全部股票的實時價格。起初同時在線用戶很少,這個接口就是一個部署在 snowball 中的普通接口,股價信息被實時寫入 redis ,讀取的時候就從 redis 中讀。後來,A股大漲,snowball 抗不住了。因而咱們就作了一個典型的優化:獨立 server + 本地內存存儲。開盤期間每次數據更新後,數據接收組件主動去更新 quote server 內存中的數據。 後續進一步優化方案是將這個接口以及相關的處理邏輯都遷移到公有云上去。
對於那些不盯盤的人,最實用的功能就是股價提醒了。在雪球上,你除了能夠關注用戶,還能夠關注股票。若是你關注的某隻股票漲了或跌了,咱們均可以很是及時的通知你。雪球上熱門股票擁有超過 50w 粉絲(招商銀行,蘇寧雲商)粉絲能夠設置:當這支股票漲幅或跌幅超過 x%(默認7%)時提醒我。曾經連續3天,天天超過1000股跌停,證監會開了一個會,因而接下來2天超過1000股漲停
原來作法:
-
股票漲(跌)x%,掃一遍粉絲列表,過濾出全部符合條件的粉絲,推送消息
新作法:
預先創建索引,開盤期間載入內存
1%:uid1,uid2
2%:uid3,uid4,uid5
3%:uid6
問題:有時候嫌太及時了:頻繁跌停,打開跌停,再跌停,再打開。。。的時候
內部線上記錄:
4臺機器。
單條消息延時 99% 小於 30秒。
下一步優化目標:99% 小於 10 秒
IM 系統最初的設計目標是爲雪球上的用戶提供一個聊天的功能:
送達率第一
雪球IM:Netty + 自定義網絡協議
Akka : 每一個在線client一個actor
推模式:client 在線狀況下使用推模式
多端同步:單帳號多端可登陸,並保持各類狀態同步
移動互聯網時代,除了微信qq之外的全部IM,都轉型成了推送通道,核心指標變成了瞬間峯值性能。原有架構不少地方都不太合適了。
優化:
分配更多資源:推送帳號actor池
精簡業務邏輯:重複消息只存id,實時提醒內容不推歷史設備,不更新非活躍設備的session列表等等
本地緩存:拉黑等沒法精簡的業務邏輯遷移到本地緩存
優化代碼:異步加密存儲,去除不合理的 akka 使用
akka這個解釋一下:akka 有一個本身的 log adapter,內部使用一個 actor 來處理全部的 log event stream 。當瞬間峯值到來的時候,這個 event stream 一會兒就堵了上百萬條 log ,致使 gc 顛簸很是嚴重。最後的解決辦法是,繞過 akka 的 log adapter,直接使用 logback 的 appender
線上記錄:5w/s (主動限速)的推送持續 3 分鐘,p99 性能指標無明顯變化
7月10號咱們在中國好聲音上作了3期廣告。在廣告播出以前,咱們針對廣告可能帶來的對系統的衝擊進行了壓力測試,主要是新用戶註冊模塊,當時預估廣告播出期間2小時新註冊100萬
壓測發現 DB 成爲瓶頸:
暱稱檢測 cache miss > 40%
暱稱禁用詞 where like 模糊查詢
手機號是否註冊 cache miss > 80%
註冊新用戶:5 insert
優化:
redis store:暱稱,手機號
本地存儲:暱稱禁用詞
業務流程優化:DB insert 操做同步改異步
下一步優化計劃:
將 sns 系統中全部的上行操做都改爲相似的異步模式
接口調用時中只更新緩存,並且主動設置5分鐘過時,而後寫一個消息到 mq 隊列,隊列處理程序拿到消息再作其它耗時操做。
爲了支持失敗重試,須要將主要的資源操做步驟都作成冪等。
前置模塊HA:
合做方合規要求:業務單元部署到合做方內網,用戶的敏感數據不容許離開進程內存
業務自己要求:業務單元自己爲有狀態服務,業務單元高可用
解決方案:
使用 Hazelcast In-Memory Data Grid 的 replication map 在多個 jvm 實例之間作數據同步。
java 啓動參數加上 -XX:+DisableAttachMechanism -XX:-UsePerfData,禁止 jstack,jmap 等等 jdk 工具鏈接
組合淨值計算性能優化:
一支股票可能在超過20萬個組合裏(南車北車中車,暴風科技)
離線計算,存儲計算後的結果
股價3秒變一次,涉及到這支股票的全部組合理論上也須要每 3 秒從新計算一次
你們可能會問,爲何不用戶請求時,實時計算呢?這是由於「組合淨值」中還包括分成送配,分股,送股,拆股,合股,現金,紅利等等,業務太過複雜,開發初期常常須要調整計算邏輯,因此就設計成後臺離線計算模式了。當前正在改造,將分成送配邏輯作成離線計算,股價組成的淨值實時計算。接口請求是,將實時計算部分和離線計算部分合併成最終結果。
實際上,咱們的計算邏輯是比較低效的:循環遍歷全部的組合,對每一個組合,獲取全部的價值數據,而後計算。完成一遍循環後,當即開始下一輪循環。
優化:
分級:活躍用戶的活躍組合,其它組合。
批量:拉取當前全部股票的現價到 JVM 內存裏,這一輪的全部組合計算都用這一份股價快照。
關於這個話題的更詳細內容,感興趣的能夠參考雪球組合業務總監張巖楓在今年的 arch summit 深圳大會上的分享:構建高可用的雪球投資組合系統技術實踐 http://sz2015.archsummit.com/speakers/201825
最後,咱們還作了一些通用的架構和性能優化,包括jdk升級到8,開發了一個基於 zookeeper 的 config center 和開關降級系統
四. 聊聊關於架構優化的一些總結和感想
在各類場合常常據說的架構優化,通常都是優化某一個具體的業務模塊,將性能優化到極致。而在雪球,咱們作的架構優化更多的是從問題出發,解決實際問題,解決到能夠接受的程度便可。可能你們看起來會以爲很凌亂,並且每一個事情單獨拎出來好像都不是什麼大事。
咱們在對一個大服務作架構優化時,通常是往深刻的本質進行挖掘;當咱們面對一堆架構各異的小服務時,「架構優化」的含義實際上是有一些不同的。大部分時候,咱們並不須要(也沒有辦法)深刻到小服務的最底層進行優化,而是去掉或者優化原來明顯不合理的地方就能夠了。
在快速迭代的創業公司,咱們可能不會針對某一個服務作很完善的架構設計和代碼實現,當出現各類問題時,也不會去追求極致的優化,而是以解決瓶頸問題爲先。
即便咱們經歷過一回將 snowball 拆分服務化的過程,但當咱們從新上一個新的業務時,咱們依然選擇將它作成一個大一統的服務。只是這一次,咱們會提早定義好每一個模塊的 service 接口,爲之後可能的服務化鋪好路。
在創業公司裏,重寫是不能接受的;大的重構,從時間和人力投入上看,通常也是沒法承擔的。而「裱糊匠」式作法,哪裏有性能問題就加機器,加緩存,加數據庫,有可用性問題就加劇試,加log,出故障就加流程,加測試,這也不是雪球團隊工做方式。咱們通常都採用最小改動的方式,即,準肯定義問題,定位問題根源,找到問題本質,制定最佳方案,以最小的改動代價,將問題解決到可接受的範圍內。
咱們如今正在全部的地方強推3個數據指標:qps,p99,error rate。每一個技術人員對本身負責的服務,必定要有最基本的數據指標意識。數字,是發現問題,定位根源,找到本質的最重要的依賴條件。沒有之一。
咱們的原則:保持技術棧的一致性和簡單性,有節制的嘗試新技術,保持全部線上服務依賴的技術可控,簡單來講,能 hold 住。
能用cache的地方毫不用db,能異步的地方,毫不同步。俗稱的:吃一塹,長一智。
特事特辦:業務在發展,需求在變化,實現方式也須要跟着變化。簡單的來講:遺留系統的優化,最佳方案就是砍需求,呵呵。
當前,雪球內部正在推行每一個模塊的方案和代碼實現的 review,在 review 過程當中,我通常是這樣要求的:
技術方案:
20倍設計,10倍實現,3倍部署
-
擴展性:凡事留一線,之後好相見
技術實現:
DevOps:上線後仍是你本身維護的項目,實現的時候記得考慮各類出錯的處理
用戶投訴的時候須要你去解釋,實現的時候注意各類邊界和異常
快速實現,不是「隨便實現」,萬一火了呢:性能,方便擴容
_
Q&A
Q1:im能詳細講下嗎?
關於雪球 im 和推模式,有羣友問到了,我就再展開講一下(其實下週我約了去給一家號稱很文藝的公司內部交流IM實現):雪球本身設計了一套 IM 協議,內部使用 netty 作網絡層,akka 模式,即爲每個在線的 client new 一個 actor ,這個 actor 裏面保持了這個在線 client 的全部狀態和數據。若是有新消息給它,代碼裏只要把這個消息 tell 給這個 actor 便可。actor 裏面會經過 netty 的 tcp 鏈接推給實際的 client。
Q2:問一個小問題,App的接口可用上報裏 若是是網絡問題引發的故障 怎麼兼容?
app 若是發起一個請求,由於網絡問題失敗了(這實際上是咱們的上報體系設計時,最主要針對的場景),那麼 app 會把這個失敗的請求記錄到本地內存,等下一次發請求時,把上次的這個失敗請求結果及相關信息帶上。若是連續屢次失敗,當前咱們的作法是,只記錄最後一次失敗的請求結果,下次成功的請求裏會帶上它。
Q3:監控系統爲什麼從zabbix切換到openfalcon,緣由是什麼?
簡單來講,機器數上百以後,zabbix就會有不少問題,我的感覺最大的問題是,新增 key 很是不方便。小米由於這些問題,本身作一個 falcon,而後開源了。咱們碰到的問題很相似,看了看小米的,以爲能夠不用本身再折騰了,就用它了。
Q4:前置模塊的Hazelcast In-Memory Data Grid 的穩定性怎麼樣,採用的考慮是什麼呢?用sharding redis 怎麼樣呢?
穩定性不能算很好,只能說還好。由於上線幾個月,已經出了一次故障了。採用它,主要是開發簡單,由於它就只有一個 jar 包依賴,不像其它備選項,一個比一個大。至於爲何不用 redis,由於這是要部署到別人的內網的啊,更新很麻煩的啊,運維幾乎沒有的啊,各類悲劇啊。咱們當前爲了作到「一鍵更新」,把shell腳本和全部jar包都打成一個自解壓的文件這事我會隨便說嗎?
Q5:雪球im如何判斷用戶是否在線?要給給定的用戶發消息,怎麼找到對應的actor?不在線的時候消息如何存儲? IM 用戶在線判斷(轉化成指定的 actor 是否存在)和路由,這些都是 akka 內置提供的,感興趣的,算了,我我的建議是不要去碰 akka 這貨。用戶不在線的時候,消息會進 mysql 和 redis Q6:大師,爲了支持失敗重試,須要將主要的資源操做步驟都作成冪等。這個怎麼理解,具體怎麼玩?
舉個例子:用戶發一個帖子,api調用的時候已經給用戶返回成功了,但後端寫 db 的時候超時了,怎麼辦?不能再告訴用戶發帖失敗了吧?那就重試重試再重試,直到寫 db 成功。但萬一重試的時候發現,上次寫入超時,其實是已經寫成功了呢?那就須要把這個寫入作成冪等,支持屢次寫入同一條記錄。簡單來講,db 層就是每一個表都要有業務邏輯上的惟一性檢查
Q7:另外用戶對應的Actor需不須要持久化呢?
actor 不持久化。重啓 server 的話,app 端會自動重連的
Q8:基於zookeeper的config center設計有什麼指導原則或遇到什麼坑嗎?如何方便業務開發修改又不影響到其餘?
咱們的 config center 有兩個版本:一個是參考 netflix 的 archaius,另外一個是純粹的 zk style 。風格問題,我我的的回答是:你們喜歡就好。 config center 原本就不影響業務開發修改啊?沒有太明白問題點,sorry
Q9:剛纔的追問下 若是隻報最後一次故障 那麼會不會不能準確評估影響?
不會的,由於這種狀況通常都是用戶進電梯或者進地鐵了,呵呵
Q10:rpc是怎麼選的呢,好比爲何不用thrift呢?
finagle 底層就是 thrift 啊。就我我的而言,我我的對於任何須要預先定義 proto 的東西都深惡痛絕。因此如今咱們也在嘗試作一個基於 jsonrpc 的簡單版本的 rpc 方案,做爲咱們後續微服務容器的默認 rpc
Q11:實質上是用actor包住了netty的session吧?不建議用akka的緣由是量大了後承載能力的問題嗎?雪球im的dau約在50萬左右吧?
是的,actor 內部持有網絡鏈接。不建議用 akka 的緣由是:我我的的原則是,我 hold 不住的東西就不作推薦。就當前來講,我以爲我 hold 不住 akka:使用太簡單太方便,但坑太多,不知道何時就踩上了,想用好太難了
Q12:唐老師您好,雪球的架構中,rabbitmq 主要用在哪些場景,rabbit的 負載是經過哪些手段來作呢?
當前咱們的 mq 功能都是有 rabbitmq 提供的,咱們在內部封裝了一個叫 event center 的模塊,全部的跟 queue 打交道的地方,只須要調用 event center 提供的 api 便可。咱們對於 rabbit 並無作太多的調優,大約也是由於如今消息量不大的緣故。後續咱們的大數據體系裏,queue 的角色會由 kafka 來承擔
Q13:大師,能說說akka爲啥不推薦麼
看上面問題 12
Q14:唐大師,關於交易這塊,能說下大家的帳戶體系嗎?
股票交易跟支付寶模式仍是很大不同的,本質上,雪球上只是一個純粹的通道:錢和股票都不在雪球內部。因此,咱們當前的帳戶體系就像咱們頁面上描述的那樣:將用戶的券商帳號跟雪球id作綁定
Q15:性能規劃上有什麼經驗或者推薦資料閱讀嗎?謝謝。
通讀 allthingsdistributed 上的精華文章 http://www.allthingsdistributed.com/
Q16:唐大師,雪球的docker是怎麼用?怎麼管理的?
參考雪球sre高磊在 dockercn 上的分享
Q17:追加一個問題:對業務合規要求的需求不是很瞭解,可是「-XX:+DisableAttachMechanism -XX:-UsePerfData」這樣沒法禁止「jstack -F」的吧,只是禁止了普通的jstack。
應該是能夠禁止的,由於 jvm 內部全部掛載機制都沒有啓動,jstack 加 -f 也掛不上去。要不我一會測一下再給你確認?
Q18:幫我問個問題:這麼多系統,如何保證迭代保質保量按時交付?
這就要感謝咱們雪球的全部技術,產品,運營同事們了 [Tongue]
Q19:爲何用kafka替換rbt?
由於 rbt 是 erlang 寫的啊,我不會調優啊,出了問題我也不會排查啊。事實上,event center 模塊極偶發的出現丟消息,但咱們一直沒有定位到根源。因此,只好換了
Q20:請問百萬活躍用戶session是怎麼存儲的?怎麼有效防止大面積退出登陸?
用戶登陸 session 就存在 jvm 內部。由於是集羣,只要不是集羣忽然所有掛,就不會出現大面積從新登陸的
Q21:每一個請求裏帶上前一個請求的結果,這個得和用戶請求綁定上吧? 收集 app 端的訪問結果,大部分狀況下用於統計服務質量,偶爾也用於用戶靈異問題的追逐
Q22:akka的設計竟然和Erlang的搶佔式調度很像,也存在單進程瓶頸問題?
能夠這麼說,主要是它的 log actor 是單個的
Q23:集羣環境下如何保存在jvm內部?各個jvm如何共享的?
咱們的 im 系統其實分 2 層,前面有一層接入層,後面是集羣。接入層到集羣的連接是按 uid 一致性 hash。簡單來講,一個用戶就只連一個 jvm 服務節點。因此咱們只在收盤後更新服務。在雪球,盤中嚴禁更新服務的
Q24:接入層的實現架構方便描述一下嗎?
雪球IM的接入層分爲2類:app接入層和web接入層。app接入層是一個 netty 的 server,開在 443 端口,但沒有使用 ssl ,而是本身用 rsa 對消息體加密。netty 收到消息後,解包,根據包裏的描述字段選擇發日後端的業務節點。web 接入層是一個基於 play 的 webserver,實現了 http 和 websocket 接口,供 web 使用。 青雲QingCloud討論組歡迎你:https://community.qingcloud.com
- 1. 在首席架構師手裏,應用架構如此設計
- 2. 在首席架構師眼裏,架構的本質是……
- 3. 易寶集團首席架構師分享架構師成長之路
- 4. [轉]在首席架構師手裏,應用架構如此設計
- 5. ArchSummit全球架構師峯會 從新定位架構師的價值
- 6. 阿里首席架構師分享的Java工程師職業規劃
- 7. 阿里首席架構師分享的Java工程師職業規劃。
- 8. ArchSummit全球架構師峯會向架構師們招手!
- 9. 首席架構師眼裏的架構本質
- 10. 首席架構師能力模型
- 更多相關文章...
- • Docker 架構 - Docker教程
- • 互聯網系統應用架構基礎分析 - 紅包項目實戰
- • TiDB 在摩拜單車在線數據業務的應用和實踐
- • C# 中 foreach 遍歷的用法
-
每一个你不满意的现在,都有一个你没有努力的曾经。