虛擬機
6、堆外內存
參考:堆外內存使用分析html
Java何時用堆外內存java
5、jvm調優
4、Full GC有關問題學習分析
摘自:Full GC有關問題學習分析(轉載)併發
GC,尤爲是Full GC,每次都會致使JVM暫停工做,處理垃圾回收任務,短期內沒法響應用戶請求,大量的Full GC會致使系統響應速度下降,並且引來OOM的巨大風險。
jvm
3、對象 GC
當一個對象到GC Roots沒有任何引用鏈相連時,則證實對象須要被回收.
性能
Java可做爲GC Roots的對象包括下面幾種:學習
虛擬機棧(棧楨中的本地變量表)中的引用的對象 spa
方法區中類靜態屬性引用的對象.net
方法區中常量引用的對象線程
本地方法棧中JNI引用的對象
2、垃圾收集
回收算法相關內容轉自https://youzhixueyuan.com/detailed-explanation-of-jvm-g1.html
一、CMS和G1的區別
- CMS中,堆被分爲PermGen,YoungGen,OldGen;而YoungGen又分了eden區、兩個survivo區域。在G1中,堆被平均分紅幾個區域(region),在每一個區域中,雖然也保留了新老代的概念,可是收集器是以整個區域爲單位收集的。
- G1在回收內存後會立刻同時作合併空閒內存的工做、而CMS默認是在STW(stop the world)的時候作。
- G1會在Young GC (也在old GC)中使用、而CMS只能在O區使用。
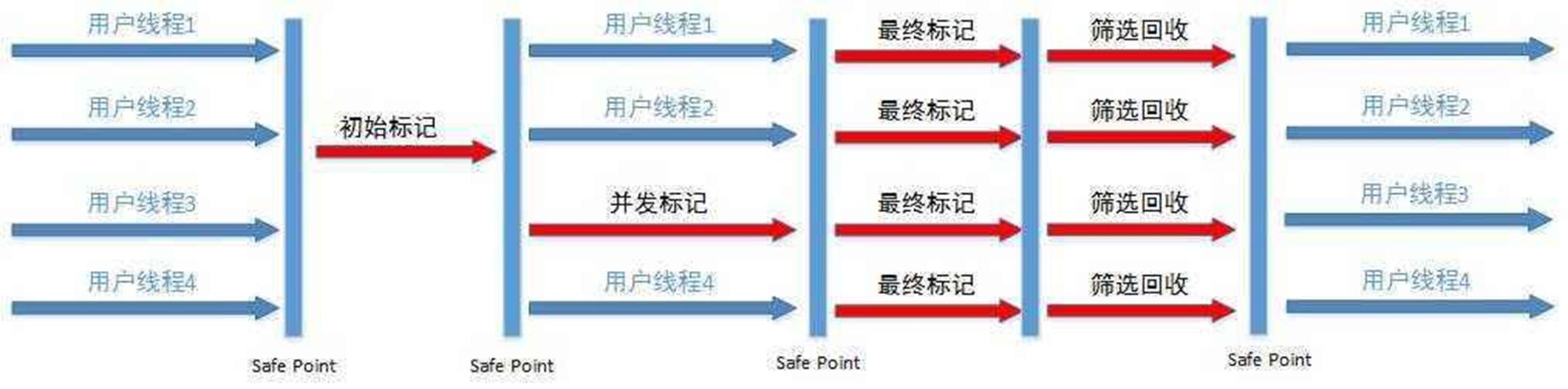
二、CMS:以獲取最短回收停頓時間爲目標的收集器,基於併發「標記清理」

過程:
- 一、初始標記:獨佔PUC,僅標記GCroots能直接關聯的對象
- 二、併發標記:能夠和用戶線程並行執行,標記全部可達對象
- 三、從新標記:獨佔CPU(STW),對併發標記階段用戶線程運行產生的垃圾對象進行標記修正
- 四、併發清理:能夠和用戶線程並行執行,清理垃圾
優勢: 併發,低停頓
缺點:
- 一、對CPU很是敏感:在併發階段雖然不會致使用戶線程停頓,可是會由於佔用了一部分線程使應用程序變慢
- 二、沒法處理浮動垃圾:在最後一步併發清理過程當中,用戶縣城執行也會產生垃圾,可是這部分垃圾是在標記以後,因此只有等到下一次gc的時候清理掉,這部分垃圾叫浮動垃圾
- 三、CMS使用「標記-清理」法會產生大量的空間碎片,當碎片過多,將會給大對象空間的分配帶來很大的麻煩,每每會出現老年代還有很大的空間但沒法找到足夠大的連續空間來分配當前對象,不得不提早觸發一次FullGC,爲了解決這個問題CMS提供了一個開關參數,用於在CMS頂不住,要進行FullGC時開啓內存碎片的合併整理過程,可是內存整理的過程是沒法併發的,空間碎片沒有了可是停頓時間變長了
三、G1:是一款面向服務端應用的垃圾收集器,基於「標記-整理」算法
特色:
- 一、並行於併發:G1能充分利用CPU、多核環境下的硬件優點,使用多個CPU(CPU或者CPU核心)來縮短stop-The-World停頓時間。部分其餘收集器本來須要停頓Java線程執行的GC動做,G1收集器仍然能夠經過併發的方式讓java程序繼續執行。
- 二、分代收集:分代概念在G1中依然得以保留。雖然G1能夠不須要其它收集器配合就能獨立管理整個GC堆,但它可以採用不一樣的方式去處理新建立的對象和已經存活了一段時間、熬過屢次GC的舊對象以獲取更好的收集效果。也就是說G1能夠本身管理新生代和老年代了。
- 三、空間整合:因爲G1使用了獨立區域(Region)概念,G1從總體來看是基於「標記-整理」算法實現收集,從局部(兩個Region)上來看是基於「複製」算法實現的,但不管如何,這兩種算法都意味着G1運做期間不會產生內存空間碎片。
- 四、可預測的停頓:這是G1相對於CMS的另外一大優點,下降停頓時間是G1和CMS共同的關注點,但G1除了追求低停頓外,還能創建可預測的停頓時間模型,能讓使用這明確指定一個長度爲M毫秒的時間片斷內,消耗在垃圾收集上的時間不得超過N毫秒。
(1)、G1堆內存結構
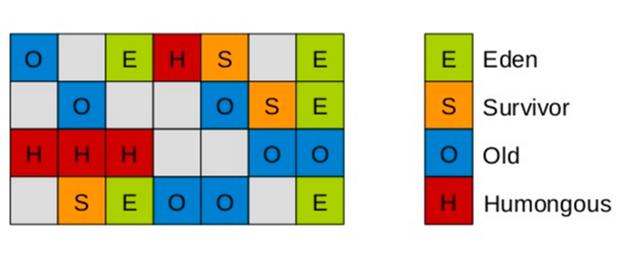
1) G1堆內存結構
- 堆內存會被切分紅爲不少個固定大小區域(Region),每一個是連續範圍的虛擬內存。
- 堆內存中一個區域(Region)的大小能夠經過-XX:G1HeapRegionSize參數指定,大小區間最小1M、最大32M,總之是2的冪次方。
- 默認把堆內存按照2048份均分。
2) G1堆內存分配
- 每一個Region被標記了E、S、O和H,這些區域在邏輯上被映射爲Eden,Survivor和老年代。
- 存活的對象從一個區域轉移(即複製或移動)到另外一個區域。區域被設計爲並行收集垃圾,可能會暫停全部應用線程。
- 如上圖所示,區域能夠分配到Eden,survivor和老年代。此外,還有第四種類型,被稱爲巨型區域(Humongous Region)。Humongous區域是爲了那些存儲超過50%標準region大小的對象而設計的,它用來專門存放巨型對象。若是一個H區裝不下一個巨型對象,那麼G1會尋找連續的H分區來存儲。爲了能找到連續的H區,有時候不得不啓動Full GC。
(2)、G1收集器的階段分如下幾個步驟:
1)G1執行的第一階段:初始標記(Initial Marking )
這個階段是STW(Stop the World )的,全部應用線程會被暫停,標記出從GC Root開始直接可達的對象。
2)G1執行的第二階段:併發標記
從GC Roots開始對堆中對象進行可達性分析,找出存活對象,耗時較長,這一階段耗時較長但能與用戶線程併發運行。
3)最終標記(標記那些在併發標記階段發生變化的對象,將被回收)
最終標記階段須要吧Remembered Set Logs的數據合併到Remembered Set中,這階段須要停頓線程,但可並行執行。
4)篩選回收(首先對各個Regin的回收價值和成本進行排序,根據用戶所期待的GC停頓時間指定回收計劃,回收一部分Region)
這一過程一樣是須要停頓線程的
最後,G1中提供了兩種模式垃圾回收模式,Young GC和Mixed GC,兩種都是Stop The World(STW)的。
(3)、G1的GC模式
1. YoungGC年輕代收集
在分配通常對象(非巨型對象)時,當全部eden region使用達到最大閥值而且沒法申請足夠內存時,會觸發一次YoungGC。每次younggc會回收全部Eden以及Survivor區,而且將存活對象複製到Old區以及另外一部分的Survivor區。
YoungGC的回收過程以下:
- 根掃描,跟CMS相似,Stop the world,掃描GC Roots對象。
- 處理Dirty card,更新RSet.
- 掃描RSet,掃描RSet中全部old區對掃描到的young區或者survivor去的引用。
- 拷貝掃描出的存活的對象到survivor2/old區
- 處理引用隊列,軟引用,弱引用,虛引用
2. mixed gc
當愈來愈多的對象晉升到老年代old region時,爲了不堆內存被耗盡,虛擬機會觸發一個混合的垃圾收集器,即mixed gc,該算法並非一個old gc,除了回收整個young region,還會回收一部分的old region,這裏須要注意:是一部分老年代,而不是所有老年代,能夠選擇哪些old region進行收集,從而能夠對垃圾回收的耗時時間進行控制。
G1沒有fullGC概念,須要fullGC時,調用serialOldGC進行全堆掃描(包括eden、survivor、o、perm)
1、類的加載
一、解析(resolve)就是將一個符號引用轉換成直接引用的一個過程。
當一個java文件編譯成class以後,方法都是以符號引用的方式保存。而在加載類時,部分符合條件的符號引用會被轉換成「直接引用」,這個過程咱們稱之爲「解析(Resolution)」。
- 1. Dalvik虛擬機、Java虛擬機與ART虛擬機
- 2. android -------- java虛擬機和Dalvik虛擬機
- 3. 虛擬機04:新建虛擬機-Win7
- 4. Java虛擬機-虛擬機工具
- 5. 虛擬機01:虛擬機的安裝
- 6. Java虛擬機---虛擬機概述
- 7. java虛擬機:虛擬機棧
- 8. Android 虛擬機 Vs Java 虛擬機
- 9. 虛擬機——windows安裝VMware虛擬機
- 10. java虛擬機與Dalvik虛擬機
- 更多相關文章...
- • SQL 主機 - SQL 教程
- • 網站主機提供商 - 網站主機教程
- • 漫談MySQL的鎖機制
- • Docker容器實戰(六) - 容器的隔離與限制
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 字節跳動21屆秋招運營兩輪面試經驗分享
- 2. Java 3 年,25K 多嗎?
- 3. mysql安裝部署
- 4. web前端開發中父鏈和子鏈方式實現通信
- 5. 3.1.6 spark體系之分佈式計算-scala編程-scala中trait特性
- 6. dataframe2
- 7. ThinkFree在線
- 8. 在線畫圖
- 9. devtools熱部署
- 10. 編譯和鏈接