爬蟲入門到精通-網頁的解析(正則)
本文章屬於爬蟲入門到精通系統教程第五講html
在爬蟲入門到精通第四講中,咱們瞭解了如何下載網頁,這一節就是如何從下載的網頁中獲取咱們想要的內容python
萬能匹配
html = u"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>文章的標題</title>
</head>
<body>
<div id="app" class="container">
<h1>h1文字</h1>
<label for="input">Input</label>
<textarea id="input" rows="10" class="form-control">
</body>
</html>
"""
咱們要獲取的html 如上所示,git
假如咱們要獲取文章的標題這幾個文字,那麼咱們應該怎麼作呢?github
咱們只要能定位到它,也就能獲取到它正則表達式
那麼,如何定位到它呢?express
很簡單,根據它兩邊的內容.segmentfault
咱們很簡單的能發現 它 左邊是<title> ,右邊是</title>app
因此,咱們如何找到文章的標題這幾個文字呢,只要左邊是<title> ,右邊是</title>,那麼中間就是咱們要找的spa
下面用程序寫出來.net
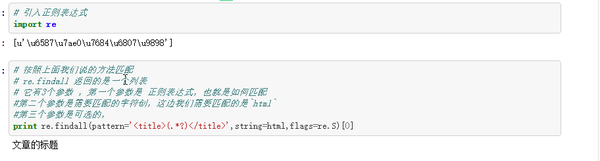
能夠看到咱們正確匹配到了文章的標題,
咱們首先來看 pattern = '<title>(.*?)</title>'
咱們能夠發現這就是咱們上面講的,左邊是<title> ,右邊是</title>,那麼中間的(.*?)是什麼呢?這實際上是來用來聲明咱們要匹配的字符串是什麼,這邊咱們用的是(.*?),表示咱們要匹配的字符串能夠是任何東西,沒有格式要求。也就是俗稱"萬能匹配",你們能夠下圖的正則表達式語法,來解釋下爲何 .*? 是萬能匹配, .*? 外面的 () 又是什麼鬼
string=html 表示咱們當前要被匹配的是咱們定義的html
最後flags=re.S 表示(.*?)中的 . 能夠匹配包括換行符(見下面表)
[0] 是取返回列表中的第一個,主要是方便演示
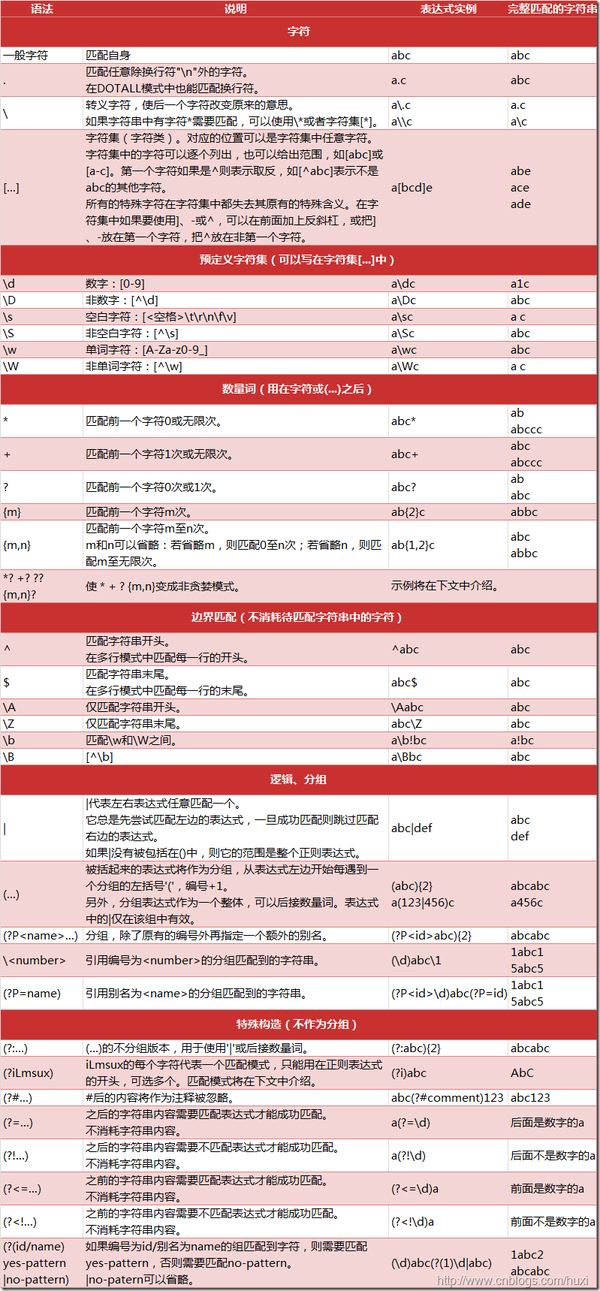
正則表達式語法(聲明咱們要匹配的字符串是什麼格式的)
圖片來自 博客園
re中全部的flags解釋

最後再來一個案例,仍是上面的html,咱們須要匹配的內容是h1文字
代碼以下
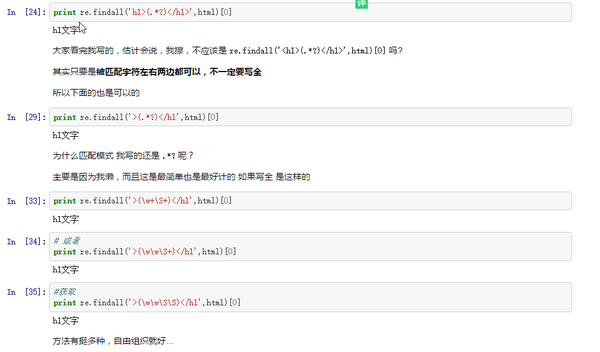
本文使用notebook編寫完成,全文在github上
總結
看完本篇文章後,你應該要:
學會最通用的一種正則表達式
re.findall('左右的字符串(.*?)右邊的字符串',等待匹配的字符串,flags)
你們想深刻了解正則表達式的話
請 先看這一篇 正則表達式30分鐘入門教程
再看這一篇 Regular expression operations
最後的最後,收藏的大哥們,能幫忙點個贊麼~
- 1. 爬蟲入門到精通-網頁的下載
- 2. python爬蟲從入門到精通
- 3. 爬蟲入門到精通-開始爬蟲之旅
- 4. Python爬蟲從入門到精通——解析庫re的使用:正則表達式
- 5. 爬蟲入門到精通-HTTP協議的講解
- 6. 網頁爬蟲--scrapy入門
- 7. Python爬蟲從入門到精通——爬蟲基礎(一):爬蟲基本原理
- 8. Python網絡爬蟲快速入門到精通
- 9. 網絡爬蟲從入門到精通 -- CSND電子書
- 10. python正則表達式網頁爬蟲
- 更多相關文章...
- • Memcached入門教程 - NoSQL教程
- • netwox網絡工具集入門教程 - TCP/IP教程
- • 互聯網組織的未來:剖析GitHub員工的任性之源
- • YAML 入門教程
-
每一个你不满意的现在,都有一个你没有努力的曾经。