在關係型數據庫中優雅的處理組織架構樹
咱們在項目開發中常常會遇到這樣的場景:企業組織架構,回覆評論鏈,商品類目等樹型結構。本文結合網上一些資料,以及本身在項目中的實踐來講一說幾種處理樹型結構的方式。html
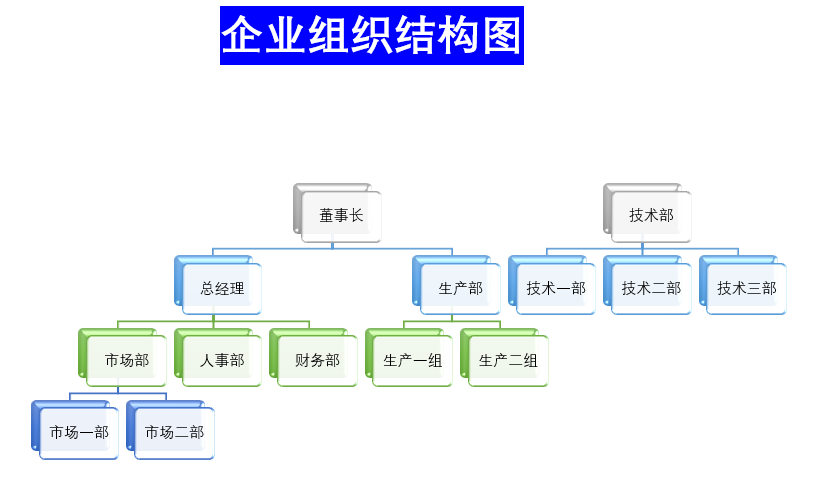
可能有很多小夥伴遇到該問題,第一個想法就是我在每條數據上都保存它的parent_id就能夠知足需求了啊,這樣一層一層都能找到, 寫一個遞歸算法就能夠拿到他的全部下級或者上級。這是一種能夠實現的方式,咱們先不評價這種方式的優劣。java
下面先說下幾種常見的處理方式:mysql
- Adjacency list (鄰接表)
- Closure table (閉包表)
- Path enumeration (路徑枚舉)
- Nested Sets(嵌套集)
本文主要講解Path enumeration (路徑枚舉),其它幾種只作簡單的展現,有須要瞭解的能夠點擊一下鏈接查看算法
-
對Closure table 講解詳細www.jianshu.com/p/951b742fd…sql
-
四種方式都有講解 www.cnblogs.com/wjq310/p/88…數據庫
-
MySQL實現嵌套集合模型 yq.aliyun.com/articles/50…bash
Adjacency list (鄰接表)
下圖是一個簡單的鄰接表結構的組織結構,也就是前面咱們的說方式閉包
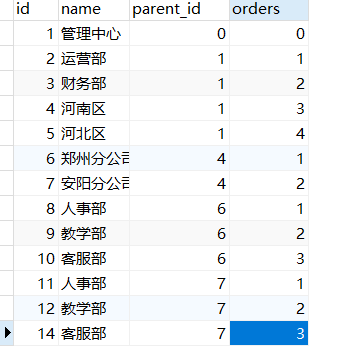
獲取數據的方式架構
- 獲取某組織下的直屬部門,咱們只需根據組織的id查詢便可
select * from org where parent_id =1;
複製代碼
- 查詢某組織下的全部組織,須要遞歸的+循環拿到子、孫...的下級節點,大概寫法以下:
public List<Org> getOrgTree(String parentId){
List<Orgs> resultOrgs = new ArrayList<>();
// 拿到下級組織
List<Org> children = getChildren(parentId);
resultOrgs.addAll(children);
for(Org org :children){
resultOrgs.addAll(getOrgTree(org.parentID));
}
return resultOrgs;
}
複製代碼
Closure table (閉包表)
這種方式用帖子評論來介紹,數據構造麻煩,借用了www.jianshu.com/p/951b742fd…中的圖,數據庫模型以下:ui
.png)

ancestor 存儲回覆的根Id,descendant 存儲當前Id,中存儲佔空間,理論上講須要O(n²)的空間來存儲關係。
-- 父查子,連表查詢comment 和 comment_path 拿到4號的評論
select c.* from comment c
left join comment_path cp on (c.id = cp.descendant)
where cp.ancestor = 4 and depth = 1;
-- 查詢4號的全部子評論
select c.* from comment c join comment_path cp on (c.id = cp.descendant) where cp.ancestor = 4;
複製代碼
Nested Sets(嵌套集)
嵌套集解決方案將信息存儲在每一個節點中,每一個節點對應於其後代的集合,而不是節點的直接父節點。
在嵌套集設計中,樹的操做、插入和移動節點一般比在其餘模型中更加複雜。
插入新節點時,須要從新計算全部大於新節點左值的左、右值。
嵌套集過於複雜,本人也沒徹底搞懂,本文不作詳細介紹。能夠參考MySQL實現嵌套集合模型
Path enumeration (路徑枚舉)
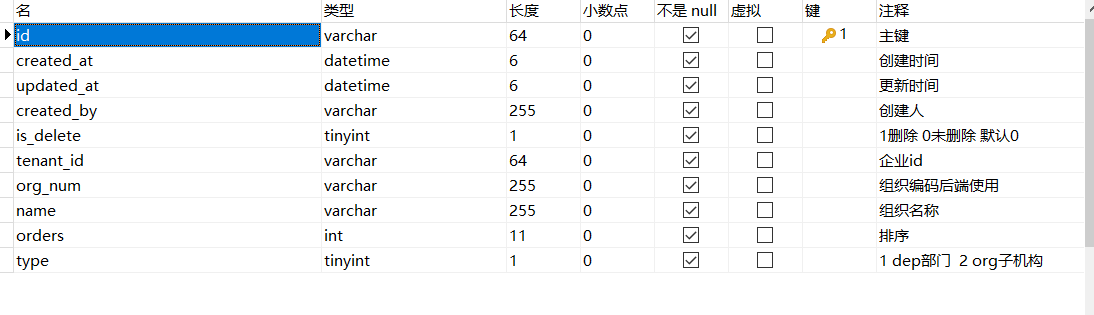
該方式以項目中組織表爲例,與路徑枚舉的區別是這裏採用org_num來代替path,
項目中咱們約定每一層級的編號長度爲2,最大層級爲20,每層的子節點數99,最大可存儲節點數爲: 2的19次方個節點
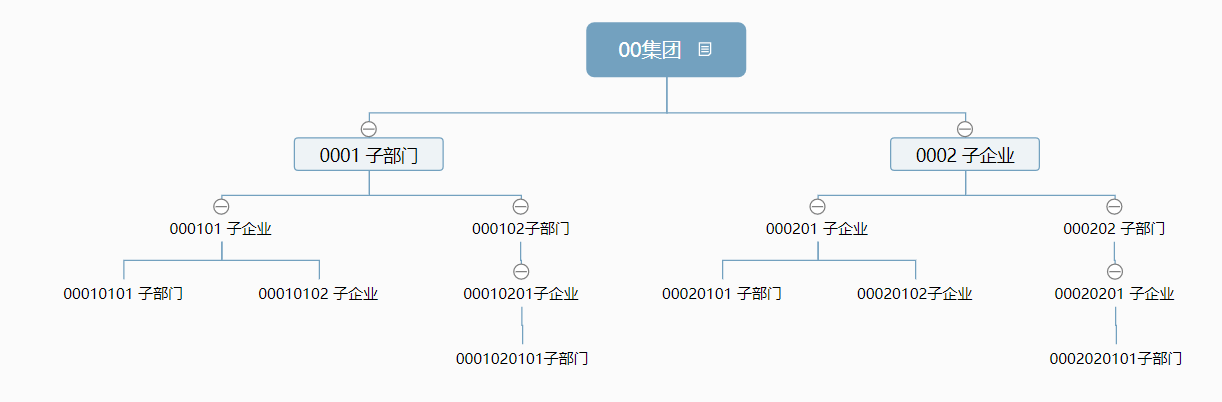
層級結構以下:
操做數據的幾種方式
約定 orgNum某節點的編號, orgLen 某節點編號的長度
- 拿到某節點的某幾層子節點
-- 在java代碼中根據當前節點orgNum獲得 orgLen和maxLength
select * from orgs where org_num like '#{orgNum}%' and length(org_num) > #{orgLen} and length(org_num) <=#{maxLength}
複製代碼
- 拿到某個節點的全部子節點
select * from orgs where org_num like '#{orgNum}%' and length(org_num) > #{orgLen}
複製代碼
- 獲取父節點或向上找幾層的父節點
-- 先在java代碼中的根據當前節點orgNum, 計算得出要找節點的orgNum,
select * from orgs where org_num = #{orgNum}
複製代碼
- 刪除組織結構
-- 刪除全部子節點,和查詢全部子節點類型
delete from orgs where org_num like '#{orgNum}%' and length(org_num) > #{orgLen}
複製代碼
- 節點移動
// 節點移動,更新當前節點的org_num以及全部下級子節點的org_num
// 若是牽扯到節點排序,則除了更新當前節點的orgNum外,還要考慮要移動到的同級節點的orders
複製代碼
- 組織樹構造
// 先從數據庫中獲得某個節點自己rootOrg及全部下級節點OrgList
private OrgTreeDTO orgTreeGenerate(List<Org> OrgList, Org rootNode, Org parent) {
List<Org> subNodes = OrgList.stream().filter(x ->
x.getOrgNum().startsWith(rootNode.getOrgNum())
&& x.getOrgNum().length() == rootNode.getOrgNum().length() + OrgConst.ORG_NODE_LENGTH
&& !x.getId().equals(rootNode.getId())
).collect(Collectors.toList());
OrgTreeDTO orgTreeDTO = new OrgTreeDTO().setId(rootNode.getId())
.setName(rootNode.getName())
.setOrders(rootNode.getOrders())
.setType(rootNode.getType())
.setChildren(subNodes.stream().map(x ->
orgTreeGenerate(OrgList, x,rootNode)
).collect(Collectors.toList()));
if(!ObjectUtils.isEmpty(parent)){
orgTreeDTO.setParentId(parent.getId())
.setParentName(parent.getName());
}
return orgTreeDTO;
}
複製代碼
以上幾種方法幾乎能夠知足大部分的組織結構調整需求。
該種方式的優勢是能夠經過簡單查詢從數據庫中獲得想要的數據,具體組裝放在java代碼中處理。
缺點若是層級過深,org_num會愈來愈長影響查詢效率,因此項目中限制節點深度爲20,能夠知足幾乎全部的組織結構數據。
總結
本文到此結束,若是相似設計上的想法或疑問,歡迎討論。
理論明確實踐的方向,實踐鑑定理論的真僞。
- 1. 關於樹型結構,在關係型數據庫中的設計
- 2. Mybatis遍歷數據庫組織架構
- 3. 優雅的處理樹狀結構——組合模式總結
- 4. 樹形結構在關係數據庫中的設計
- 5. 關係型數據庫 --- 數據庫架構
- 6. 關係型數據庫的優勢
- 7. 關係型數據庫的優缺點
- 8. Django+zTree構建組織架構樹
- 9. 樹狀結構在關係型數據庫中一種存儲方式
- 10. 關係型與非關係型數據庫的優缺點
- 更多相關文章...
- • Rust 組織管理 - RUST 教程
- • 關係型數據庫是什麼? - NoSQL教程
- • TiDB 在摩拜單車在線數據業務的應用和實踐
- • 互聯網組織的未來:剖析GitHub員工的任性之源
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 關於樹型結構,在關係型數據庫中的設計
- 2. Mybatis遍歷數據庫組織架構
- 3. 優雅的處理樹狀結構——組合模式總結
- 4. 樹形結構在關係數據庫中的設計
- 5. 關係型數據庫 --- 數據庫架構
- 6. 關係型數據庫的優勢
- 7. 關係型數據庫的優缺點
- 8. Django+zTree構建組織架構樹
- 9. 樹狀結構在關係型數據庫中一種存儲方式
- 10. 關係型與非關係型數據庫的優缺點