elasticsearch小白入門
elasticsearch小白入門
介紹
第一次在掘金髮表文章,有些不足之處,求勿噴!求勿噴!求勿噴! 身爲一個前端,竟然搞es緣由在於咱們公司內部的wiki文檔全棧項目的使用,因爲日益增多的文章和想要全文檢索的需求,而且本來的mongodb數據庫,查詢全文檢索時特別慢,才引入了es。 車300工具平臺,項目目前還沒公開出來,預計2021年公開。html
起源Lucene
一個叫 Doug Cutting 的美國工程師迷上了搜索引擎,他作了一個用於文本搜索的函數庫(軟件功能組件),命名爲Lucene。Lucene是JAVA寫的,目標是爲各類中小型應用軟件加入全文檢索功能。由於好用且開源,很是受程序員歡迎。 早期是由這我的本身維護,後期作大後,2001年末,成爲Apache軟件基金會jakarta項目的一個子項目。前端
Lucene 是一個信息檢索工具包,jar包,不包含搜索引擎系統! 包含了:索引結構、讀寫索引的工具、排序、搜索規則...工具類!java
Lucene 和 Elasticsearch
elasticSearch 是基於Lucene 作了一些封裝和加強。es是一個開源的、高拓展的、分佈式、全文檢索引擎。誕生於21世紀大數據時代。(Restful Api)。2016年超過solr,成爲排名第一個的搜索引擎類應用。node
Elasticsearch歷史
多年前,一個叫作Shay Banon剛結婚不久的失業開發者,因爲妻子要去倫敦學習廚師,他就跟老婆一塊兒去了,在他找工做的過程當中,爲了給妻子構建一個食譜搜索引擎,他就開始使用Lucene工具包開發。因爲直接使用原生工具包很是麻煩,因而他就開始抽象化Lucene代碼寫本身的封裝,後來他在找到工做後又重寫了 本身的封裝,並命名爲elasticsearch。 再後來,2010年2月,第一個公開版es發佈,es在短期內瞬間成爲當時 github 上最受歡迎的項目之一,一家主營es的公司就此成立,他們一邊開發新功能,一邊提供商用,並永遠開源, 遺憾的是,Shay的妻子依然在等待食譜搜索....mysql
什麼是搜索?
1)百度,谷歌。咱們能夠經過輸入一些關鍵字去搜索咱們須要的東西。 2)互聯網的搜索:電商網站。招聘網站。新聞網站。各類APP(百度外賣,美團等等) 3)windows系統的搜索等等linux
總結:搜索無處不在。經過一些關鍵字,給咱們查詢出來跟這些關鍵字相關的信息git
什麼是全文檢索?
全文檢索是指計算機索引程序經過掃描文章中的每個詞,對每個詞創建一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程序就根據事先創建的索引進行查找,並將查找的結果反饋給用戶的檢索方式。這個過程相似於經過字典中的檢索字表查字的過程。程序員
什麼是 Elasticsearch?
使用 java 語言開發的一套開源的全文搜索引擎 用於搜索、日誌管理、安全分析、指標分析、業務分析、應用性能監控等多個領域 底層基於
Lucene開源庫開發,提供restAPI,能夠被任何語言調用 支持分佈式部署,可水平擴展 更新迭代快、社區活躍、文檔豐富(2020年9月寫的這篇文章是7.9.1,而如今11月已經7.10.x了)github
自行去官網下載 win linux 及其餘版本安裝包
連接: elasticsearch下載redis
ik分詞器是一個github項目,能夠選擇git clone 或者 直接download zip
爲了方便演示,這邊是windows系統下的教程,linux後續推出如何發佈線上等等。
熟悉es目錄

bin 是啓動目錄
config 配置文件
--- log4j2 日誌配置文件
--- jvm.options java虛擬機相關配置
--- elasticsearch.yml elasticsearch配置文件,默認 9200 端口!
lib 相關jar包
logs 日誌
modules 相關模塊
plugins 插件如ik
複製代碼
啓動
直接訪問 bin 目錄下 elasticsearch.bat
安裝可視化插件 elasticsearch-head
git clone https://github.com/mobz/elasticsearch-head.git
複製代碼
進入目錄後
cnpm install
複製代碼
訪問 localhost:9100, 發現跨域問題
去es config目錄 的 elasticsearch.yml 添加跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
複製代碼
*表明全部人均可以訪問,實際正式環境不能夠這樣配置
重啓 elasticsearch 這時再訪問 localhost:9100 便可
kibana的安裝與使用
瞭解 ELK
瞭解ELK工程師 ELK是 Elasticsearch Logstash Kibana 三大開源庫的簡稱,市面上也稱爲 Elastic Stack。其中Elasticsearch是一個基於Lucene、分佈式、經過Restful方式進行交互的近實時搜索平臺框架。像百度、谷歌這種大數據全文搜索引擎的場景均可以使用es這做爲底層支持框架,可見es提供的搜索能力確實強大,Logstash 是中央數據流引擎,用於從不一樣目標(文件/數據存儲/MQ)收集的不一樣格式數據,通過過濾後只支持輸出到不一樣目的地(文件/MQ/redis/es等)。Kibana是一個es可視化工具,提供了實時分析的能力。
收集清洗數據 ---> 搜索,存儲 --->Kibana
要保證Kibana版本和es保持一致
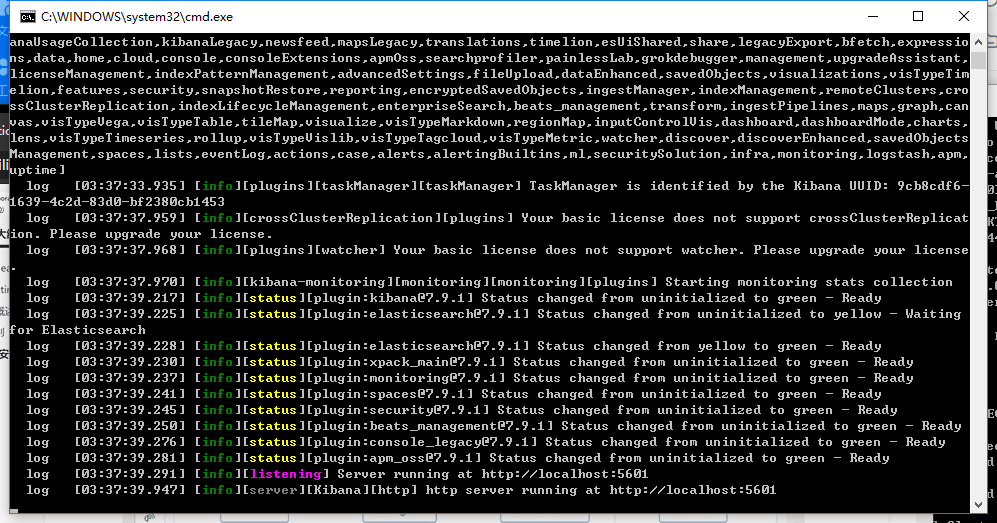
啓動
kibana-7.9.1-windows-x86_64\bin 目錄下的 kibana.bat
| 
|_
複製代碼
訪問 5601端口便可訪問
ps:開發工具!(postman等等其餘的)
修改漢化
去配置文件D:\tools\kibana-7.9.1-windows-x86_64\config\kibana.yml中修改
i18n.locale: "zh-CN"
複製代碼
es核心概念
es是面向文檔的非關係數據庫
| 關係型數據庫 | es |
|---|---|
| 數據庫 | 索引 |
| 表 | types(慢慢被棄用了,7.x.x版本使用統一的_doc,並在查詢命令中能夠省略) |
| 行 | documents(文檔) |
| 字段 | fields |
文檔
es是面向文檔的,
- 意味着索引和搜索數據的最小單位是文檔,相似關係數據庫中某張表中的一行記錄(好理解)
- 文檔會被序列化成 JSON 格式,JSON 對象由字段組成(以json格式存儲)
- 每一個字段都有對應的字段類型,類型能夠本身指定,也可使用 ElasticSearch 自動推算(智能化)
- JSON 文檔支持數組和嵌套(自由度很高)
- 每一個文檔都有一個惟一性 ID,能夠本身指定,也能夠系統自動生成(智能化)
儘管咱們能夠隨意新增忽略某個字段,可是每一個字段的類型很是重要,好比一個年齡類型字段,能夠是字符串也能夠是整數,由於es中會保存字段和類型之間的映射以及其餘的設置,這種映射具體到每一個映射的每種類型,這也是爲何在es中,類型有時候也稱爲映射類型。
一個文檔主要元素大體包含如下內容:
1. _index: 文檔所屬的索引名
2. _type: 文檔所屬的類型名(廢棄品)
3. _id: 文檔的惟一ID
4. _source: 文檔存儲的 Json 數據
5. _version:文檔的版本信息
6. _score: 相關性打分
複製代碼
類型
類型是文檔的邏輯容器,就像關係型數據庫同樣,表格是行的容器。
索引
最直接的理解就是數據庫!
- 每一個索引都是一個很是大的文檔集合。
- 每一個索引有本身的 Mapping 用於定義文檔的字段名和字段類型
- 每一個索引有本身的 Settings 用於定義不一樣的數據分佈,也就是索引使用分片的狀況(我沒用過👻👻👻)
節點和集羣如何工做
一個集羣至少有一個節點,而一個節點就是一個es進程,節點能夠有多個索引(默認的),若是你建立索引,那麼索引將會有5個分片(primary shard,又稱主分片)構成的,每個主分片會有一個副本(replica shard,又稱複製分片)
由於不是專職作這個的,因此這裏關於這些東西就一帶而過了。。。,小白入門不須要了解太多底層吧
倒排索引是什麼
es使用的是一種稱爲倒排索引的結構,採用Lucene倒排索引做爲底層,這種結構適用於快速的全文索引,一個索引由文檔中全部的不重複的列表構成,對於每個詞,都有一個包含它的文檔列表。例如,如今有兩個文檔,每一個文檔包含以下內容:
Study every day, good good up, to forever # 文檔一
To forever, study every day, good good up # 文檔二
複製代碼
爲了建立倒排索引,咱們要將每一個文檔拆分紅獨立的詞(詞條),而後建立一個包含全部不重複詞條的排序列表,而後列出每一個詞條出如今哪一個文檔
如今咱們要去搜索 to forever 只須要查看包含每一個詞條的文檔
這裏產生了權重!
總結:倒排索引幫咱們徹底過濾掉了一些無用的數據,幫咱們提升了效率
一、索引(數據庫) 二、字段類型(mapping) 三、文檔 四、分片(瞭解,Lucene索引)
分詞插件(IK分詞器)
分詞就是把一段中文或者英文劃分爲一個個關鍵字,咱們在搜索的時候會把本身的信息進行分詞,會把數據庫中的或者索引庫中的數據進行分詞,而後進行一個匹配操做作,默認的中文分詞是將每個字當作一個詞,好比「我愛育儀」會被分紅「我」「愛」「育」「儀」,這裏顯然是不合理的,因此咱們須要安裝中文的分詞器。 IK提供了兩個分詞算法:ik_smart 和 ik_max_word,其中 ik_smart是最少切分,ik_max_word是最細粒度劃分!
附件中有IK分詞器的安裝包 一、安裝 二、直接解壓到es安裝目錄的plugin目錄中命名爲ik 三、重啓es
驗證 分詞器是否安裝完成, 四、使用 elasticsearch-plugin
五、用kibana測試!
ik_smart 最少劃分
ik_max_word 最多劃分
兩種分詞器使用的最佳實踐是:索引時用ik_max_word,在搜索時用ik_smart。 即:索引時最大化的將文章內容分詞,搜索時更精確的搜索到想要的結果。
一、ik_max_word
會將文本作最細粒度的拆分,好比會將「中華人民共和國人民大會堂」拆分爲「中華人民共和國、中華人民、中華、華人、人民共和國、人民、共和國、大會堂、大會、會堂等詞語。
二、ik_smart 會作最粗粒度的拆分,好比會將「中華人民共和國人民大會堂」拆分爲中華人民共和國、人民大會堂。
發現問題
這種本身須要的詞,須要咱們本身加上咱們的分詞器中,纔會實現真正的分詞
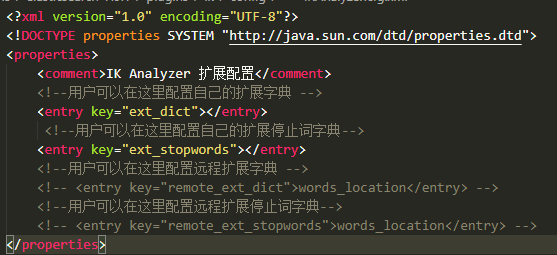
本身添加詞典
D:\tools\elasticsearch-7.9.1\plugins\ik\config\IKAnalyzer.cfg.xml(這是個人路徑,別人和我不同的) 在這個目錄下修改
| 
|_
複製代碼
在elasticsearch-7.9.1\plugins\ik\config 目錄下新建 自定義的詞典例如: 一、新建yuyi.dic 二、在 該文件中寫入 三、在下圖位置加上本身的配置文件名 四、重啓es 五、再次測試
GET _analyze
{
"analyzer": "ik_smart",
"text": "超級喜歡育儀講"
}
複製代碼
返回值發生了變化
{
"tokens" : [
{
"token" : "超級",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "喜歡",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "育儀",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "講",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
}
]
}
複製代碼
之後須要本身配置,就須要本身在分詞中設置便可
Rest 風格說明
這是一種架構風格而不是標準,他用於客戶端與服務器交互 類的軟件,基於這個風格設計軟件能夠更簡潔、更有層次等。
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名稱/類型名稱/文檔id | 建立文檔(指定文檔id) |
| POST | localhost:9200/索引名稱/類型名稱 | 建立文檔(隨機文檔id) |
| POST | localhost:9200/索引名稱/_update/文檔id | 修改文檔 |
| DELETE | localhost:9200/索引名稱/類型名稱/文檔id | 刪除文檔 |
| GET | localhost:9200/索引名稱/類型名稱/文檔id | 經過文檔id查詢文檔 |
| POST | localhost:9200/索引名稱/類型名稱/_search | 查詢全部數據 |
建立文檔
示例1
PUT /test1/type1/1
{
"name":"育儀",
"age":24
}
複製代碼
類型名將來在 8版本中會被刪除
示例2
PUT /test3/_doc/1
{
"name":"育儀分享會",
"age":24,
"birth":"1996-09-12"
}
複製代碼
這裏的_doc是將來es官方指定的類型,將來將去掉類型名稱,統一爲一個系統指定的_doc
若是咱們沒有指定 文檔類型,es默認會幫咱們指定類型
字段指定類型
- 字符串類型:text、keyword
- 數值類型:long、integer、short、byte、double、float、half float、scaled float
- 日期類型:date
- te布爾類型:boolean
- 二進制類型:binary
- 等等......
測試
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
複製代碼
返回上圖則成功
mappings、properties爲指定字段類型的必須格式,內部的name、age、birthday爲用戶想要的類型,相似mysql的建表。
經過get請求獲取信息
GET /test2
複製代碼
能夠經過get請求,直接獲取test2索引的所有信息
拓展:經過命令 查看 es 索引狀況
查看數據庫健康值
GET _cat/health
複製代碼
查看es不少信息
GET _cat/indices?v
複製代碼
等等還有不少
修改
修改提交仍是使用PUT 而後覆蓋便可!(曾經的方法)
PUT /test3/_doc/1
{
"name":"育儀分享會20200921",
"age":24,
"birth":"1996-09-12"
}
複製代碼
這種修改更新方式是總體修改,一旦丟掉數據則會產生修改錯誤的字段
更新的方法(新的)
POST /test3/_update/1
{
"doc":{
"name":"育儀大魔王"
}
}
複製代碼
更新成功,再調用查看方法便可發現就name字段發生了變化。 值得注意的是 doc是固定寫法
刪除
刪除整個索引
DELETE /test1
複製代碼
返回值:
刪除一條數據
Delete /test3/_doc/1
複製代碼
使用RESTFUL風格是咱們ES推薦你們使用的!
關於文檔的操做
基本操做
一、先建立一個索引並加入數據
PUT /yuyi/_doc/1
{
"name":"朱育儀",
"age":24,
"desc":"我明天就要分享了,我慌的一批",
"tags":["技術宅","溫暖","直男"]
}
PUT /yuyi/_doc/2
{
"name":"張三",
"age":24,
"desc":"我是張三",
"tags":["傻叉","旅遊","渣男"]
}
PUT /yuyi/_doc/3
{
"name":"李四",
"age":30,
"desc":"我是李四",
"tags":["靚女","旅遊","唱歌"]
}
複製代碼
二、查詢 查詢yuyi索引下的 1號人物
GET /yuyi/_doc/1
複製代碼
三、搜索 條件查詢 獲取一號用戶的
GET /yuyi/_doc/_search?q=name:朱育儀
複製代碼
咱們發現 上圖中有一個 _score這個字段,若是有多條數據,匹配度越高則分值越高
略複雜的查詢方式
GET /yuyi/_doc/_search
{
"query":{
"match":{
"name":"朱育儀"
}
}
}
複製代碼
仍是同樣返回上文圖片的返回值
經過 _source 指定返回值
GET /yuyi/_doc/_search
{
"query":{
"match":{
"name":"朱育儀"
}
},
"_source":["name","age"]
}
複製代碼
![]
咱們以後使用nodejs 操做es,全部的方法和對象就是這裏面的key!
排序
GET /yuyi/_doc/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"age":{
"order":"desc"
}
}
]
}
複製代碼
match_all表明全文匹配 sort 字段是個數組裏面傳遞對象用來排序,上面的語句是對age進行排序,order表明排序規則「desc降序 asc升序」 有了固定的排序後,_score分值就沒了。
分頁
GET /yuyi/_doc/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"age":{
"order":"desc"
}
}
],
"from":0,
"size":2
}
複製代碼
from表明了從第幾個開始,size表示每頁多少個
布爾值查詢
GET /yuyi/_doc/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"育儀"
}
},
{
"match":{
"age":24
}
}
]
}
}
}
複製代碼
採用 bool字段, 內部可選參數:must(必須包含)must_not(必須不包含)should(有一個就能夠了)(minimum_should_match: 用來控制至少匹配多少個should匹配的) 上面匹配的是 name包含 育儀字段 age 是 24的數據
should查詢測試
GET /yuyi/_doc/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"育儀"
}
},
{
"match":{
"age":24
}
}
]
}
},
"from":0,
"size":2
}
複製代碼
會返回只要符合name 是育儀 或者 age是 24的就能夠了。
過濾查詢
GET /yuyi/_doc/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"育儀"
}
}
],
"filter":{
"range":{
"age":{
"gte":10,
"lte":30
}
}
}
}
}
}
複製代碼
經過 filter查詢過濾數據,將過濾age大於等於10小於等於30的 gt大於 lt小於 gte大於等於 lte小於等於
數組類型也能夠匹配
GET /yuyi/_doc/_search
{
"query":{
"match":{
"tags":"男"
}
}
}
複製代碼
想要匹配多個條件直接空格隔開便可
GET /yuyi/_doc/_search
{
"query":{
"match":{
"tags":"男 技術"
}
}
}
複製代碼
咱們發現只要匹配到了這兩個詞中的任意一個,就會被返回,然而第二條數據並不太符合技術這個關鍵詞。 這個時候能夠經過返回值中的分值進行基本的判斷,匹配程度。
精確查詢
term 直接經過倒排索引精確查找的
關於分詞,term會直接查詢精確值,match會使用分詞器解析,再經過分析的文檔查詢
兩個類型 text keyword text類型會被分詞器進行解析 keyword不會被分割解析
測試代碼一個一個請求
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type": "keyword"
}
}
}
}
PUT testdb/_doc/1
{
"name":"育儀準備分享會",
"desc":"育儀準備分享會"
}
PUT testdb/_doc/2
{
"name":"育儀準備分享會 name",
"desc":"育儀準備分享會 desc"
}
複製代碼
查看分詞結果
GET _analyze
{
"analyzer": "keyword",
"text":"育儀準備分享會"
}
複製代碼
如上圖所示,keyword形式將再也不進行分詞
GET _analyze
{
"analyzer": "ik_smart",
"text":"育儀準備分享會"
}
複製代碼
使用ik分詞器後是這個結果
精準查詢的測試
GET /testdb/_search
{
"query":{
"term":{
"name":"育"
}
}
}
複製代碼
查詢name中含有育的數據,因爲name屬性是text類型,會被分詞
GET /testdb/_search
{
"query":{
"term":{
"desc":"育"
}
}
}
複製代碼
此時咱們發現 desc查詢育字時無值,因爲咱們使用了keyword類型 ,因此咱們必須使用育儀準備分享會 所有文字才能匹配到值。以下方的測試
GET /testdb/_search
{
"query":{
"term":{
"desc":"育儀準備分享會"
}
}
}
複製代碼
總結:keyword不會被分詞器解析
多個值匹配的精確查詢
測試代碼(插入多個數據)
PUT testdb/_doc/3
{
"t1":"22",
"t2":"2020-09-23"
}
PUT testdb/_doc/4
{
"t1":"33",
"t2":"2020-09-24"
}
複製代碼
使用 term精確查詢多個值
GET /testdb/_search
{
"query":{
"bool":{
"should": [
{
"term":{
"t1":"22"
}
},
{
"term":{
"t1":"33"
}
}
]
}
}
}
複製代碼
高亮查詢
GET /yuyi/_search
{
"query":{
"match":{
"name":"育儀"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
複製代碼
經過 上文方式能夠實現高亮,highlight``fields爲固定寫法
咱們這裏不想用em標籤 想用其餘的
GET /yuyi/_search
{
"query":{
"match":{
"name":"育儀"
}
},
"highlight": {
"pre_tags": "<p class='myClassName' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
複製代碼
這裏使用 pre_tags post_tags 來自定義標籤高亮
參考文檔:
Elasticsearch 之(24)IK分詞器配置文件講解以及自定義詞庫
還有不少借鑑其餘的出處忘記了。。。
- 1. JAVA 小白入門
- 2. Python入門小白
- 3. 小白laravel入門
- 4. construct2——小白入門
- 5. vuejs小白入門
- 6. Redis小白入門
- 7. Vizceral小白入門
- 8. 小白入門Mybatis
- 9. MyBatis小白入門
- 10. Servlet小白入門
- 更多相關文章...
- • Memcached入門教程 - NoSQL教程
- • Neo4j數據庫入門教程 - NoSQL教程
- • YAML 入門教程
- • Java Agent入門實戰(一)-Instrumentation介紹與使用
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. JAVA 小白入門
- 2. Python入門小白
- 3. 小白laravel入門
- 4. construct2——小白入門
- 5. vuejs小白入門
- 6. Redis小白入門
- 7. Vizceral小白入門
- 8. 小白入門Mybatis
- 9. MyBatis小白入門
- 10. Servlet小白入門