MySQL學習筆記之MySQL架構
MySQL 最重要、最不同凡響的特性是它的存儲引擎架構,這種架構的設計將查詢處理及其餘系統任務和數據的存儲/提取相分離。這種處理和存儲分離的設計能夠在使用時根據性能、特性,以及其餘需求來選擇數據存儲的方式。git
MySQL 的邏輯架構
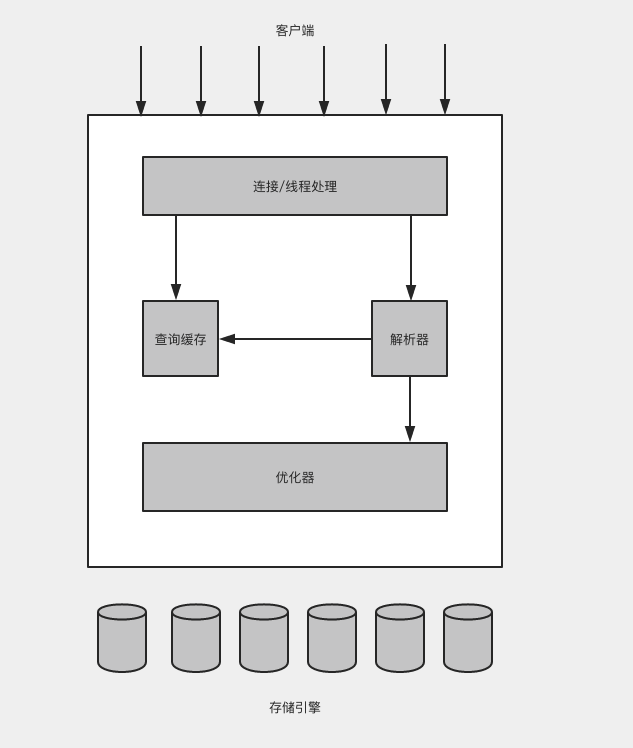
MySQL 邏輯架構圖github
最上層的服務並非MySQL 所獨有的,大多數基於網絡的客戶端/服務器的工具或者服務都有相似的架構。好比鏈接處理、受權驗證、安全等。數據庫
第二層架構是MySQL 比較有意思的部分。大多數MySQL的核心服務功能都在這一層,包括查詢解析、分析、優化、緩存以及全部的內置函數(例如,日期、時間、數學和加密函數),全部跨存儲引擎的功能都在這一層實現:存儲過程、觸發器、視圖等。緩存
第三層包含了存儲引擎。存儲引擎負責MySQL中數據的存儲和提取。和GNU/Linux下的各類文件系統同樣,每一個存儲引擎都有它的優點和劣勢。服務器經過API於存儲引擎進行通訊。這些接口屏蔽了不一樣存儲引擎之間的差別,使得這些差別對上層的查詢過程透明。存儲引擎API包含了幾十個底層函數,用於執行諸如「開始一個事務」或者「根據主鍵提取一行記錄」等操做。但存儲引擎不會去解析SQL,不一樣存儲引擎之間也不會相互通訊,而只是簡單地響應上層服務器的請求。安全
鏈接管理與安全性
每一個客戶端鏈接都會在服務器進行中擁有一個線程,這個鏈接的查詢只會在這個單獨的線程中執行,該線程只能輪流在某個CPU核心或者CPU中運行。服務器會負責緩存線程,所以不須要爲每個新建的鏈接建立或者銷燬線程。服務器
當客戶端(應用)鏈接到MySQL 服務器時,服務器須要對其進行認證。認證基於用戶名、原始主機信息和密碼。若是使用了安全套接字(SSL)的方式鏈接,還可使用X.509證書認證。一旦客戶端鏈接成功,服務器會繼續認證該客戶端是否具備執行某個特定查詢對方的權限(例如,是否容許客戶端對world數據庫的Country表執行SELECT語句)。網絡
優化與執行
MySQL 會解析查詢,並建立內部數據結構(解析樹),而後對其進行各類優化,包括重寫查詢、決定表的讀寫順序,以及選擇合適的索引等。用戶能夠經過特殊的關鍵字提示(hint)優化器,影響它的決策過程。也能夠請求優化解釋器(explain)優化過程的各個因素,使用戶能夠知道服務器是如何進行優化決策的,並提供一個參考基準,便於用戶重構查詢和schema、修改相關配置,使應用盡量高效運行。數據結構
優化器並不關心表使用的是什麼存儲引擎,但存儲引擎對優化查詢是有影響的。優化器會請求存儲引擎提供容量或某個操做的開銷信息,以及表數據的統計信息等。例如,某些存儲引擎的某種索引,可能對一些特定的查詢有優化。架構
對於SELECT語句,在解析查詢以前,服務器會線檢查查詢緩存(Query Cache),若是可以在其中找到對應的查詢,服務器就沒必要再執行查詢解析、優化和執行的整個過程,而是直接返回查詢緩存中的結果集。併發
併發控制
不管什麼時候,只要有多個查詢須要在同一時刻修改數據,都會產生併發控制的問題。
以Unix 系統的email box爲例,典型的mbox文件格式是很是簡單的。一個mbox郵箱中全部的郵件都串行在一塊兒,彼此首位相連。這種格式對於讀取和分析郵件信息很是友好,同時投遞郵件也很容易,只要在文件末尾加新的郵件內容便可。
但若是兩個進程在同一時刻對同一個郵箱投遞郵件,會發生什麼狀況?顯然,郵箱的數據會被破壞,兩封郵件的內容會交叉地附加在郵箱文件的莫問。設計良好的郵箱投遞系統會經過鎖(lock)來防止數據損壞。若是客戶駛入投遞郵件,而郵箱已經被其餘客戶鎖住,那就必須等待,直到鎖釋放才能進行投遞。
這種鎖的方案在實際應用環境中雖然工做良好,但並不支持併發處理。由於在任意一個時刻,只有一個進程能夠修改郵箱數據,這在大容量的郵箱系統中是個問題。
讀寫鎖
從郵箱中讀取數據沒有這樣的麻煩,即便同一時刻多個用戶併發讀取也不會有什麼問題。由於讀取不會修改數據,因此不會出錯。但若是某個客戶正在讀取郵箱,同時另外一個用戶試圖刪除編號爲25的郵件,會產生什麼結果?結論是不肯定,讀的客戶可能會報錯退出,也可能讀到不一致的郵箱數據。因此,爲安全起見,即便讀取郵箱也須要特別注意。
若是把上述的郵箱當成數據庫中的一張表,把郵件當成表中的一行記錄,就很容易看出,一樣的問題依然存在。從不少方面來講,郵箱就是一張簡單的數據庫表。修改數據庫表中的記錄,和刪除或者修改郵箱中的郵件信息,十分相似。
解決這類經典問題的方法就是併發控制,其實很是簡單。在處理併發讀或者寫時,能夠經過實現一個由兩種類型的鎖組成的鎖系統來解決問題。這兩種類型的鎖一般被稱爲共享鎖(shared lock)和排他鎖(exclusive lock),也叫讀鎖(read lock)和寫鎖(write lock)。
鎖的概念以下:讀鎖是共享的,或者說是相互不阻塞的。多個客戶在同一時刻能夠同時讀取同一個資源,而互不干擾。寫鎖則是排他的,也就是說一個寫鎖會阻塞其餘的寫鎖和讀鎖,這是處於安全策略的考慮,只有這樣,才能確保在給定的時間裏,只有一個用戶能執行寫入,並防止其餘用戶讀取正在寫入的同一資源。
在實際的數據庫系統中,每時每刻都在發生鎖定,當某個用戶在修改某一部分數據時,MySQL 會經過鎖定防止其餘用戶讀取同一數據。大多數時候,MySQL 鎖的內部管理都是透明的。
鎖粒度
一種提升共享資源併發性的方式就是讓鎖定對象更有選擇性。儘可能只鎖定須要修改的部分數據,而不是全部的資源。更理想的方式是,只對會修改的數據片進行精確的鎖定。任什麼時候候,在給定的資源上,鎖定的數據量越少,則系統的併發程度越高,只要相互之間不發生衝突便可。
問題是加鎖也須要消耗資源。鎖的各類操做,包括得到鎖、檢查鎖是否已經解除、釋放鎖等,都會增長系統的開銷。若是系統話費大量的時間來管理鎖,而不是存取數據,那麼系統的性能可能會所以受到影響。
所謂的鎖策略,就是在鎖的開銷和數據安全性之間尋求平衡,這種平衡固然也會影響到性能。
MySQL 數據庫提供了多種選擇。每種MySQL存儲引擎均可以實現本身的鎖策略和鎖粒度。在存儲引擎設計中,鎖管理是個很是重要的決定。將鎖粒度固定在某個級別,能夠爲某些特定的應用場景提供更好的性能,但同時會失去對另一些應用場景的良好支持。
表鎖(table lock)
表鎖是 MySQL中最基本的鎖策略,而且是開銷最小的策略。表鎖很是相似於前文中描述的郵箱加鎖機制:它會鎖定整張表。一個用戶對錶進行寫操做(插入、刪除、更新等)前,須要先得到寫鎖,這回阻塞其餘用戶對該表的全部讀寫操做。只有沒有寫鎖時,其餘讀取的用戶才能得到讀鎖,讀鎖之間是不互相阻塞的。
在特定的場景中,表鎖也可能有良好的性能。例如,READ LOCK 表鎖支持某些類型的併發寫操做。另外,寫鎖也比讀鎖有更高的優先級,所以一個寫鎖的請求可能會被插入到讀鎖隊列的前面(寫鎖能夠插入到鎖隊列的前面,反之讀鎖則不能插入到寫鎖的前面)。
進過存儲引擎能夠管理本身的鎖,MySQL 自己仍是會使用各類有效的表鎖來實現不一樣的目的。例如,服務器會爲諸如ALTER TABLE之類的語句使用表鎖,而忽略存儲引擎的鎖機制。
行級鎖(row lock)
行級鎖能夠最大成都的支持併發處理(同時也帶來了最大的開銷)。衆所周知,在InnoDB和XtraDB,以及其餘一些存儲引擎中實現了行級鎖。行級鎖只在存儲引擎層實現,而MySQL服務器沒有實現。服務器層徹底不瞭解存儲引擎中的鎖實現。
事務
事務就是一組原子性的SQL查詢,或者說是一個獨立的工做單元。若是數據庫存儲引擎可以成功地對接數據庫應用該組查詢的所有語句,那麼就執行該組查詢。若是其中有任何一條語句由於崩潰或者其餘緣由沒法執行,那麼全部的語句都不會執行。也就是說,事務內的語句,要麼所有執行成功,要麼所有執行失敗。
原子性(atomicity)
一是個事務必須被視爲一個不可分割的最小工做單元,整個事務中的全部操做要麼所有提交成功,要麼所有失敗回滾,對於一個事務來講,不可能只執行其中的一部分操做,這就是事務的原子性。
一致性(consistency)
數據庫老是從一個一致性狀態轉換到另外一個一致性的狀態。
隔離性(isolation)
一般來講,一個事務所作的修改在最終提交之前,對其餘事務是不可見的。
持久性(durability)
一旦事務提交,則其所作的修改就會永久保存到數據庫中。
隔離級別
READ UNCOMMITTED(未提交讀)
在READ UNCOMMITED級別,事務中的修改,即便沒有提交,對其餘事務也都是可見的。事務能夠讀取未提交的數據,這也被稱爲脹讀(Dirty Read)。
READ COMMITED(提交讀)
大多數數據庫系統的默認隔離級別都是READ COMMITED(但MySQL不是)。READ COMMITED知足前面提到的隔離性的簡單定義:一個事務開始時,只能「看見」已經提交的事務所作的修改。換句話說,一個事務從開始直到提交以前,所作的任何修改對其餘事務都是不可見的。這個級別有時候也叫作不可重複讀,由於兩次執行一樣的查詢,可能會獲得不同的結果。
REPEATABLE READ(可重複讀)
REPEATABLE READ 解決了髒讀的問題。該級別保證了在同一個事務中屢次讀取一樣記錄的結果是一致的。可是理論上,可重複讀隔離級別仍是沒法解決另外一個幻讀的問題。所謂幻讀,指的是當某個事務在讀取某個範圍內的記錄時,另外一個事務又在該範圍內插入了新的記錄,當以前的事務再次讀取該範圍內的記錄時,會產生幻行。InnoDB和XtraDB 存儲引擎經過過版本併發控制(MVCC)解決了幻讀的問題。
SERIALIZABLE(可串行化)
SERIALIZABLE 是最高的隔離級別。它經過強制事務串行化執行,避免了幻讀問題。簡單來講,SERIALIZABLE 會在讀取的每一行數據上都加鎖,因此可能致使大量的超時和鎖爭用問題。實際應用中也不多用到這個隔離級別,只有在很是須要確保數據的一致性並且能夠接受沒有併發的狀況下,才考慮採用該級別。
ANSI SQL 隔離級別
死鎖
死鎖是指兩個或者多個事務在同一資源上互相佔用,並請求鎖定對方佔用的資源,從而致使而行循環的現象。當多個事務試圖以不一樣順序鎖定資源時,就可能會產生死鎖。多個事務同時鎖定同一個資源時,也會產生死鎖。
多版本併發控制
MySQL 的大多數事務型存儲引擎實現的都不是簡單的行級鎖。基於提高併發性能的考慮,它們通常都同時實現了多版本併發控制(MVCC)。不只是MySQL,包括Oracle、PostgreSQL 等其餘數據庫系統也都實現了MVCC,但各自的實現機制不盡相同,由於MVCC沒有一個統一的實現標準。
能夠認爲MVCC是行級鎖的一個變種,可是它在不少狀況下避免了加鎖操做,所以開銷更低。雖然實現機制有所不一樣,但大都實現了非阻塞的讀操做,寫操做也只鎖定必要的行。
MVCC的實現,是經過保存數據在某一個時間點的快照來實現的。也就是說,無論須要執行多長時間,每一個事務看到的數據都是一致的。根據事務開始的時間不一樣,每一個事務對同一張表,同一時刻看到的數據多是不同的。
不一樣存儲引擎的MVCC的實現是不一樣的,典型的有樂觀併發控制和悲觀併發控制。
InnoDB的MVCC,是經過在每行記錄後面保存兩個隱藏的列來實現的。這兩個列,一個保存了行的建立時間,一個保存了行的過時時間(或刪除時間)。固然存儲的並非實際的時間值,而是系統版本號。每開始一個新的事務,系統版本號都會自動遞增。事務開始時刻的系統版本號會做爲事務的版本號,用來和查詢到的每行記錄的版本號進行比較。下面是在REPPEATABLE READ隔離級別下,MVCC具體是如何操做的。
SELECT
InnoDB 會根據如下兩個條件去檢查每行記錄:
- InnoDB只查找版本早於當前事務版本的數據行(也就是,行的系統版本號小於或等於事務的系統版本號),這樣能夠確保事務讀取的行,要麼是在事務開始前已經存在的,要麼是事務自身插入或者修改過的。
- 行的刪除版本要麼未定義,要麼大於當前事務版本號。這能夠確保事務讀取到的行,在事務開始以前未被刪除。
INSERT
InnoDB 爲新插入的每一行保存當前系統版本號做爲行版本號。
DELETE
InnoDB 爲刪除的每一行保存當前系統版本號做爲刪除標識。
UPDATE
InnoDB 爲插入一行新紀錄,保存當前系統版本號做爲行版本號,同時保存當前系統版本號到原來的行做爲刪除標識。
保存這兩個額外系統版本號,使大多數讀操做均可以不通加鎖。這樣設計使得讀操做很簡單,性能很好,而且也能保證只會讀取到符合標準的行。不足之處是每行記錄都須要額外的存儲空間,須要作不少的行檢查工做,以及一些額外的維護工做。
MVCC只在REPEATABLE READ和READ COMMITED兩個隔離級別下工做。其餘兩個隔離級別都和MVCC不兼容,由於READ UNCOMMITED老是讀取最新的數據行,而不是符合當前事務版本的數據行。而SERIALIZABLE則會對全部讀取的行都加鎖。
總結
MySQL 擁有分層的架構。上層是服務器層的服務和查詢執行引擎,下層則是存儲引擎。雖然有不少不一樣做用的插件API,但存儲引擎API仍是最重要的。若是能理解MySQL 在存儲引擎和服務層之間處理查詢時如何經過API來回交互,就能抓住MySQL 的核心基礎架構的精髓。
書讀百遍,其義自現。
有時候不得不認可本身的無知。從大二就開始接觸MySQL,可是一直都在嘗試着去用。隨着時間的流逝,現在用MySQL 對我來講問題已經不大了,到了學習MySQL是如何實現的階段了。
這裏面的InnoDB的MVCC給我十分深入的印象,由於我最近作的一個供應商信息版本控制,實現的設計和這裏大體相同,這種思想上的共通,給人以啓迪。
本文做者: 荒古
本文連接: https://haxianhe.com/2019/08/...
版權聲明: 本博客全部文章除特別聲明外,均採用 CC BY-NC-SA 3.0 許可協議。轉載請註明出處!
歡迎關注個人公衆號:荒古傳說

- 1. Mysql學習筆記------架構
- 2. MySQL 學習筆記(1)-基礎架構
- 3. Mysql學習筆記--架構與歷史
- 4. MySQL學習筆記(一)基礎架構
- 5. MySQL讀書學習筆記(一)——架構
- 6. mysql架構學習,小記
- 7. MySQL學習筆記之二
- 8. MySQL學習筆記之一
- 9. MYSQL學習筆記之鎖
- 10. 學習筆記之MySQL
- 更多相關文章...
- • Docker 架構 - Docker教程
- • 您已經學習了 XML Schema,下一步學習什麼呢? - XML Schema 教程
- • Tomcat學習筆記(史上最全tomcat學習筆記)
- • 漫談MySQL的鎖機制
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Mysql學習筆記------架構
- 2. MySQL 學習筆記(1)-基礎架構
- 3. Mysql學習筆記--架構與歷史
- 4. MySQL學習筆記(一)基礎架構
- 5. MySQL讀書學習筆記(一)——架構
- 6. mysql架構學習,小記
- 7. MySQL學習筆記之二
- 8. MySQL學習筆記之一
- 9. MYSQL學習筆記之鎖
- 10. 學習筆記之MySQL