淺談Service Mesh體系中的Envoy
摘要: 提到Envoy就不得不提Service Mesh,說到Service Mesh就必定要談及微服務了,那麼咱們就先放下Envoy,簡單瞭解下微服務、Service Mesh以及Envoy在Service Mesh中處於一個什麼樣的角色。html
背景
最近因工做緣由開始瞭解Service Mesh與Envoy,爲系統性梳理所學內容,所以沉澱了此文檔,但因爲所知有限,如文檔中有描述不當之處,但願不吝賜教。nginx
提到Envoy就不得不提Service Mesh,說到Service Mesh就必定要談及微服務了,那麼咱們就先放下Envoy,簡單瞭解下微服務、Service Mesh以及Envoy在Service Mesh中處於一個什麼樣的角色。git
過去幾年間,架構領域最火的方向非微服務莫屬,那麼微服務架構到底爲咱們帶來了什麼樣的好處呢?下面經過一張圖說明架構的演進,以下:
github
伴隨着業務規模的變大,微服務的好處顯而易見,例如它自己所具有的可擴展性、易維護性、故障和資源隔離性等諸多特性使得產品的生產研發效率大大提升,同時,基於微服務架構設計,研發人員能夠構建出原生對於「雲」具有超高友好度的系統,讓產品的持續集成與發佈變得更爲便捷。算法
然而沒有所謂的銀彈,微服務帶來不少好處的同時也引入了不少問題。在雲原生模型裏,一個應用能夠由數百個服務組成,每一個服務可能有數千個實例,每一個實例的狀態可能持續的發生變化,此時,服務間的通訊不只異常複雜,並且都是運行時的行爲,管理好服務間通訊對於保證端到端的性能與可靠性來講無疑成爲重中之重。在Service Mesh沒有出現以前,微服務框架之間的通信大多采用SDK方案,但該方式短板也很是明顯,例如對業務有侵入性、沒法作到SDK升級對業務透明等。編程
基於以上種種複雜緣由催生了服務間通信層的出現,這個層即不該該與應用程序的代碼耦合,又能捕獲到底層環境的動態變化並做出適當的調整,避免業務出現單點故障;同時也可讓開發者只關注自身業務,將應用雲化後帶來的諸多問題以不侵入業務代碼的方式提供給開發者。後端
上述所說的這個服務間通信層就是Service Mesh(國內一般翻譯爲服務網格),它能夠提供安全、快速、可靠的服務間通信。若是用一句話來解釋什麼是Service Mesh,能夠將其比做微服務間的TCP/IP層,負責服務之間的調用、限流、熔斷和監控等。緩存
讀到這裏你們必定仍然存在這樣的疑惑,Service Mesh究竟是什麼呢?這是一個全新的東西嗎?它的演進過程是什麼樣的呢?下面使用一張圖來講明其演進過程,以下:
從上圖能夠看到最初的Service Mesh始於一個網絡代理,在2016年1月業界第一個開源項目Linkerd發佈,同年9 月 29 日的 SF Microservices 大會上,「Service Mesh」這個詞彙第一次在公開場合被使用,隨後Envoy也發佈了本身的開源版本,但此時的Service Mesh更多停留在Sidecar層面,並無清晰的Sidecar管理面,所以屬於Service Mesh的第一代。此時雖然Service Mesh尚不成熟,但一個初具雛形的服務間通信層已然出現,以下圖:
隨後Google聯合IBM、Lyft發起了Istio項目,從架構層面明確了數據平面、控制平面,並經過集中式的控制平面概念進一步強化了Service Mesh的價值,再加上巨頭背書的緣故,所以Service Mesh、Istio概念迅速火爆起來。此時已然進入到了第二代的Service Mesh,控制平面的概念及做用被你們承認並接受,而更重要的一點是至此已經造成了一個完整意義上的SDN服務通信層。此時的Service Mesh架構以下圖: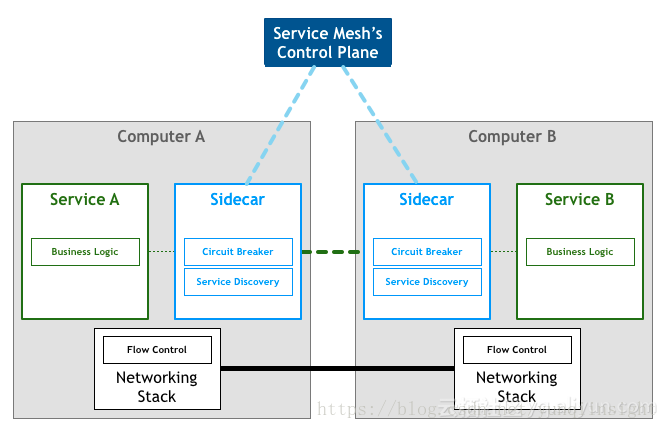
至此Service Mesh的背景信息基本介紹完畢,接下來開始進入正題說說Envoy相關的內容。其在完整的Service Mesh體系中處於一個什麼位置呢?繼續看圖:安全
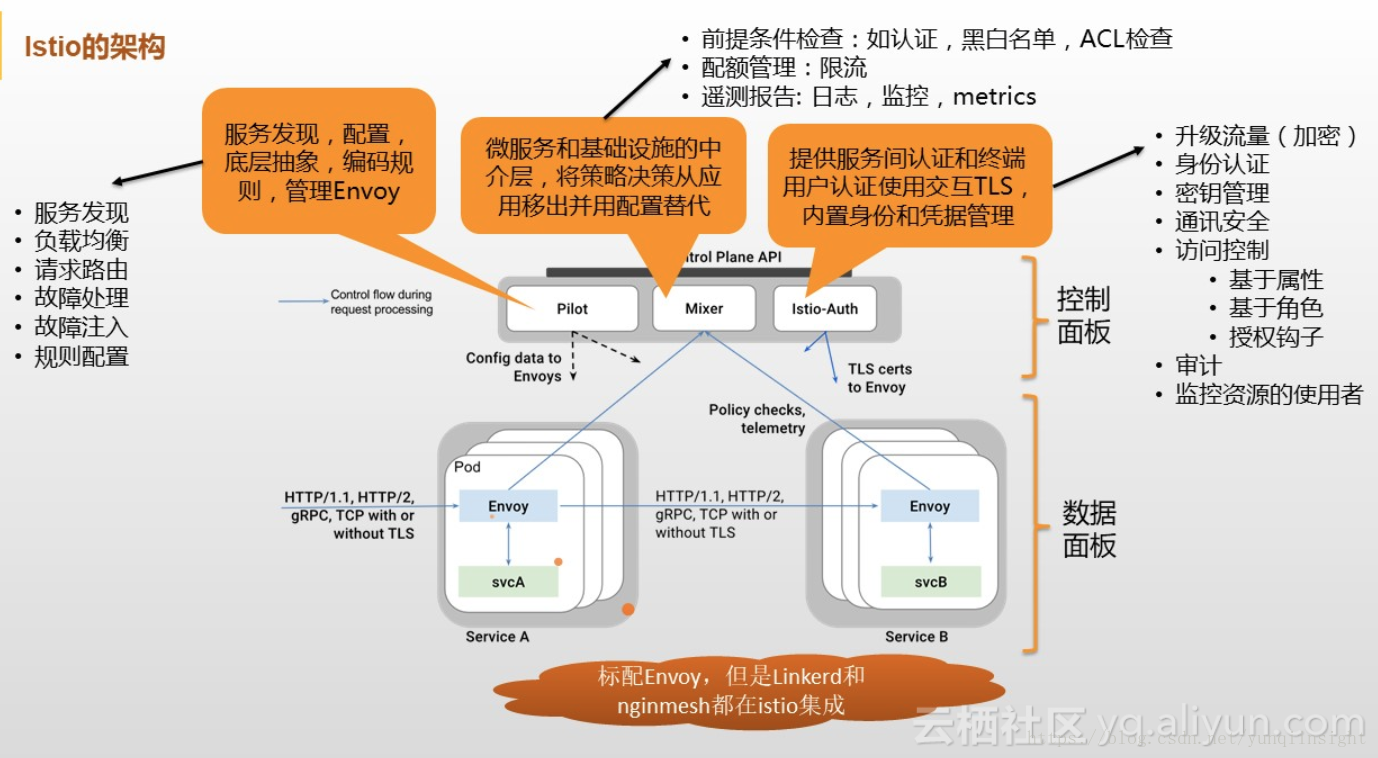
Envoy是Istio中的Sidecar官方標配,是一個面向服務架構的高性能網絡代理,由C++語言實現,擁有強大的定製化能力,經過其提供的Filter機制基本能夠對請求轉發過程當中超過50%的流程作定製化,在性能方面因爲其實現參考了Nginx,也處於主流水平,固然還有不少特性,在這裏就不作一一介紹了。性能優化
從一份配置瞭解Envoy主流程
任何軟件架構設計,其核心都是圍繞數據展開的,基本上如何定義數據結構就決定了其流程的走向,剩下的不外乎加上一些設計手法,抽離出變與不變的部分,不變的部分最終會轉化爲程序的主流程,基本固化,變的部分儘可能保證擁有良好的擴展性、易維護性,最終會轉化爲主流程中各個抽象的流程節點。
對於Envoy也不例外,做爲一個網絡代理程序,其核心職責就是完成請求的轉發,在轉發的過程當中人們又但願能夠對其作必定程度的微處理,例如附加一個Header屬性等,不然就不必使用代理程序了。那麼Envoy是如何運做的呢?它是如何定義其數據結構,並圍繞該數據結構設計軟件架構、程序流程,又是如何抽象出變得部分,保證高擴展性呢?
帶着這些疑問,試想Envoy做爲一個高度可定製化的程序,其定製化的載體必然是配置信息,那麼咱們下面就試着從Envoy的一份配置來解讀其架構設計與程序流程。
在查看其配置前,咱們不妨先腦補一下網絡代理程序的流程,好比做爲一個代理,首先要能獲取請求流量,一般是採用監聽端口的方式實現,其次拿到請求數據後須要對其作些微處理,例如附加Header頭或校驗某個Header字段內容等,這裏針對來源數據的層次不一樣,就能夠分爲L3L4L7,而後將請求轉發出去,轉發這裏又能夠衍生出若是後端是一個集羣,須要從中挑選出一臺機器,如何挑選又涉及到負載均衡等。腦補下來大體流程應該就是這個樣子,接下來咱們看看Envoy是如何組織其配置信息的。
Envoy配置的簡單配置信息以下:
關鍵字段說明:
Listener: 服務(程序)監聽者。就是真正幹活的。 Envoy 會暴露一個或者多個listener監聽downstream的請求。
Filter: 過濾器。在 Envoy 中指的是一些「可插拔」和可組合的邏輯處理層。是 Envoy 核心邏輯處理單元。
Route_config: 路由規則配置,即請求路由到後端那個集羣(cluster)。
Cluster: 服務提供方集羣。Envoy 經過服務發現定位集羣成員並獲取服務。具體請求到哪一個集羣成員是由負載均衡策略決定。經過健康檢查服務來對集羣成員服務狀態進行檢查。
根據上面咱們腦補的流程,配合上這份配置的話,Envoy大體處理流程以下圖:
Envoy內部對請求的處理流程其實跟咱們上面腦補的流程大體相同,即對請求的處理流程基本是不變的,而對於變化的部分,即對請求數據的微處理,所有抽象爲Filter,例如對請求的讀寫是ReadFilter、WriteFilter,對HTTP請求數據的編解碼是StreamEncoderFilter、StreamDecoderFilter,對TCP的處理是TcpProxyFilter,其繼承自ReadFilter,對HTTP的處理是ConnectionManager,其也是繼承自ReadFilter等等,各個Filter最終會組織成一個FilterChain,在收到請求後首先走FilterChain,其次路由到指定集羣並作負載均衡獲取一個目標地址,而後轉發出去。
淺談Envoy架構
聊完了基本流程後,本節會試着分析其架構設計,但願從其架構設計中得到一些益處。
先賣個關子,在本節開始以前咱們不妨先思考一個有趣的問題:Envoy自己採用C++開發的,廣泛承認C++程序執行性能會更好,那麼延伸下來能夠想到Envoy的設計目標彷佛是在追求高性能,那麼真是如此嗎?
在探究Envoy架構設計以前,咱們先來看看Envoy自身是怎麼描述其設計目標的,以下:
Envoy並非很慢(咱們已經花了至關長的時間來優化關鍵路徑)。基於模塊化編碼,易於測試,而不是性能最優。咱們的觀點是,在其餘語言或者運行效率低不少的系統中,部署和使用Envoy可以帶來很好的運行效率。
很是有意思的表述,Envoy並無把追求極致性能做爲目標,那麼其架構設計會弱化性能這塊嗎?
目前業內公認代理程序性能最好的是Nginx,其採用了per thread one eventloop模型,這種架構被業內廣泛借鑑,那麼Envoy呢?咱們先看看下面的架構圖:
看到裏面Worker的工做方式是否是很熟悉,會不會有一點點困惑呢?呵呵,沒錯,Envoy也採用了類Nginx的架構,方式是:多線程 + 非阻塞 + 異步IO(Libevent),雖然Envoy沒有把極致性能做爲目標,但不等於沒有追求,只不過是相對於擴展性而言級別稍微低一點而已。
Envoy的另外一特色是支持配置信息的熱更新,其功能由XDS模塊完成,XDS是個統稱,具體包括ADS(Aggregated Discovery Service)、SDS(Service Discovery Service)、EDS(Endpoint Discovery Service)、CDS(Cluster Discovery Service)、RDS(Route Discovery Service)、LDS(Listener Discovery Service)。XDS模塊功能是向Istio的Pilot獲取動態配置信息,拉取配置方式分爲V1與V2版本,V1採用HTTP,V2採用gRPC。
Envoy還支持熱重啓,即重啓時能夠作到無縫銜接,其基本實現原理是:
- 將統計信息與鎖放到共享內存中。
- 新老進程採用基本的RPC協議使用Unix Domain Socket通信。
- 新進程啓動並完成全部初始化工做後,向老進程請求監聽套接字的副本。
- 新進程接管套接字後,通知老進程關閉套接字。
- 通知老進程終止本身。
Envoy一樣也支持Lua編寫的Filter,不過與Nginx同樣,都是工做在HTTP層,具體實現原理都同樣,不作贅述了。
到此爲止咱們看完了上面的架構圖,若是你對其內部實現也有興趣的話,能夠看看下面的內部實現類圖:
其內部實現爲了靈活性,作了不少抽象封裝,但基本上能夠拆分爲幾個大的功能模塊,具體如上圖,再也不贅述。
Envoy性能談
軟件的世界歷來就不存在什麼銀彈,雖然ServiceMesh優點很明顯,甚至被尊稱爲服務間的通信層,但不能否認的是ServiceMesh的到來確實對應用的性能帶來了損耗,能夠從兩個方面看待此問題:
- 數據面板中Sidecar的加入增長了業務請求的鏈路長度,必然會帶來性能的損耗,由此延伸可知請求轉發性能的高低必然會成爲各個Sidecar可否最終勝出的關鍵點之一。
- 控制面板採用的是集中式管理,統一負責請求的合法性校驗、流控、遙測數據的收集與統計,而這要求Sidecar每轉發一個請求,都須要與控制面板通信,例如對應到Istio的架構中,這部分工做是由Mixer組件負責,那麼可想而知這裏必然會成爲性能瓶頸之一,針對這個問題Istio官方給出瞭解決方案,即將Mixer的大部分工做下放到Sidecar中,對應到Envoy中就是新增一個MixerFilter來承擔請求校驗、流控、數據收集與統計工做,MixerFilter須要定時與Istio通信以批量上報數據與拉取最新配置數據。這種方式在Istio以前微博的Motan、華爲Mesher、惟品會的OSP中已經這麼作了。
本節主要談論Envoy在性能方面的努力及社區在性能方面呼聲較高的一些內容。
Envoy做爲Sidecar其提供的核心功能能夠簡單總結爲如下三點:
- 對業務透明的請求攔截。
- 對攔截請求基於必定規則作校驗、認證、統計、流量調度、路由等。
- 將請求轉發出去,在ServiceMesh中全部的流量出入都要通過Sidecar,即由Sidecar承擔起全部的網絡通信職責,由此可知請求轉出後的下一個接收方也必然是Sidecar,那麼Sidecar之間通信協議的高效與否對ServiceMesh總體性能也會產生較大影響。
從上述三點中咱們試着分析下性能優化的關鍵點,其中第一、3點是與業務基本無關的,屬於通用型功能,而第2點的性能是與業務複雜度呈現相關性的,好比請求校驗規則的多與少、遙測數據的採集精細度、數據統計的維度多樣性等,所以最有可能提高Sidecar性能的點就是對請求的攔截與Sidecar之間通信協議的高效性。
針對請求的攔截,目前常規的作法是使用iptables,在部署Sidecar時配置好iptables的攔截規則,當請求來臨後iptables會從規則表中從上至下順序查找匹配規則,若是沒遇到匹配的規則,就一條一條往下執行,若是遇到匹配的規則,那就執行本規則並根據本規則的動做(accept, reject, log等),決定下一步執行的狀況。爲了更直觀的展現iptables的執行過程,請看下圖:
瞭解iptables的基本流程後,不難發現其性能瓶頸主要是兩點:
- 在規則配置較多時,因爲其自己順序執行的特性,性能會下滑嚴重。
- 每一個request的處理都要通過內核態--->用戶態--->內核態的過程,這其中會帶來數據從內核態拷貝到用戶態的,再拷貝到內核態的性能消耗,單次請求來看這種消耗不多,可是做爲流量進出的守門人,可想而知每秒進出的請求量必然是一個很高的數字,其累積的消耗也必然很高,再進一步分析因爲網絡中大量數據包的到來,會產生頻繁的硬件中斷、上下文切換,甚至是一個數據包在多個CPU核之間切換處理,這些因素疊加起來會對性能形成更大的損耗。
既然知道了iptables的缺陷,那麼優化手段不外乎從這兩點下手,而Linux社區與Envoy社區也正在計劃對此作優化,具體以下:
- Linux內核社區最近發佈了bpfilter,一個使用Linux BPF提供的高性能網絡過濾內核模塊,計劃用來替代netfilter做爲iptables的內核底層實現,實現Linux用戶向BPF過渡的換心手術。
- Envoy社區目前正在推進官方重構其架構,目的是爲了支持自定義的network socket實現,固然最終目的是爲了添加VPP(Vector Packet Processing)、Cilium擴展支持,不管使用VPP或Cilium均可以實現數據包在純用戶態或者內核態的處理,避免內存的來回拷貝、上下文切換,且能夠繞過Linux協議棧,以提升報文轉發效率,進而達到提高請求攔截效率的目的。
爲何規避Linux正常協議處理過程當中內核態與用戶態的轉換如此重要呢?就以對咱們最直觀的內存拷貝爲例,正常狀況下,一個網絡數據包從網卡到應用程序須要通過以下的過程:數據從網卡經過 DMA 等方式傳到內核開闢的緩衝區,而後從內核空間拷貝到用戶態空間,在 Linux 內核協議棧中,這個耗時操做甚至佔到了數據包整個處理流程的 57.1%。爲了更直觀的對內存拷貝消耗有所瞭解,畫了一張簡圖,以下:
簡說DPDK
DPDK全稱Intel Data Plane Development Kit,是Intel提供的數據平面開發工具集,爲Intel Architecture(IA)處理器架構下用戶空間高效的數據包處理提供庫函數和驅動的支持,它不一樣於Linux系統以通用性設計爲目的,而是專一於網絡應用中數據包的高性能處理,它將數據包處理、內存管理、處理器調度等任務轉移到用戶空間完成,而內核僅僅負責部分控制指令的處理。這樣就解決了處理數據包時的系統中斷、上下文切換、系統調用、系統調度等問題。
VPP是the vector packet processor的簡稱,是一套基於DPDK的網絡幀處理解決方案,是一個可擴展框架,提供開箱即用的交換機/路由器功能。是Linux基金會下開源項目FD.io的一個子項目,由思科貢獻的開源版本,目前是FD.io的最核心的項目。
整個DPDK仍是很是複雜的,經過一兩篇文章很難說清楚,且本文重點也不在DPDK,所以下面只簡單介紹下其基本原理,讓咱們大體清楚爲何Envoy引入VPP後能夠大幅提高請求處理轉發效率。
爲了說清楚DPDK是如何大幅提高了數據包的處理性能,咱們先看一下普通的數據包在Linux中的收發過程,以下圖:
經過上面兩張圖咱們能夠大體清楚數據包的一個完整的收發過程,能夠看到整個處理鏈路仍是比較長的,且須要在內核態與用戶態之間作內存拷貝、上下文切換、軟硬件中斷等。雖然Linux設計初衷是以通用性爲目的的,但隨着Linux在服務器市場的普遍應用,其原有的網絡數據包處理方式已很難跟上人們對高性能網絡數據處理能力的訴求。在這種背景下DPDK應運而生,其利用UIO技術,在Driver層直接將數據包導入到用戶態進程,繞過了Linux協議棧,接下來由用戶進程完成全部後續處理,再經過Driver將數據發送出去。原有內核態與用戶態之間的內存拷貝採用mmap將用戶內存映射到內核,如此就規避了內存拷貝、上下文切換、系統調用等問題,而後再利用大頁內存、CPU親和性、無鎖隊列、基於輪詢的驅動模式、多核調度充分壓榨機器性能,從而實現高效率的數據包處理。說了這麼多,接下來咱們看下在DPDK中數據包的收發過程,以下圖:
經過對比得知,DPDK攔截中斷,不觸發後續中斷流程,並繞過內核協議棧,經過UIO(Userspace I/O)技術將網卡收到的報文拷貝到應用層處理,報文再也不通過內核協議棧。減小了中斷,DPDK的包所有在用戶空間使用內存池管理,內核空間與用戶空間的內存交互不用進行拷貝,只作控制權轉移,減小報文拷貝過程,提升報文的轉發效率。
DPDK可以繞過內核協議棧,本質上是得益於 UIO 技術,UIO技術也不是DPDK創立的,是內核提供的一種運行在用戶空間的I/O技術,Linux系統中通常的驅動設備都是運行在內核空間,在用戶空間用的程序調用便可,UIO則是將驅動的不多一部分運行在內核空間,絕大多數功能在用戶空間實現,經過 UIO 可以攔截中斷,並重設中斷回調行爲,從而繞過內核協議棧後續的處理流程。
那麼UIO是如何攔截中斷的呢?咱們先看看做爲一個設備驅動的兩個主要職責:
- 存取設備的內存。UIO 核心實現了mmap能夠處理物理內存、邏輯內存、虛擬內存。UIO驅動的編寫是就不須要再考慮這些繁瑣的細節。
- 處理設備產生的中斷。設備中斷的應答是必須在內核空間的,所以UIO只把很是小的一部分代碼邏輯放在內核,剩餘邏輯所有留給用戶空間進程處理。
UIO的實現機制實際上是對用戶空間暴露文件接口,好比當註冊一個 UIO 設備 uioX,就會出現文件 /dev/uioX,對該文件的讀寫就是對設備內存的讀寫。除此以外,對設備的控制還能夠經過 /sys/class/uio 下的各個文件的讀寫來完成。UIO架構及流程圖以下,再也不贅述。
說完了DPDK,那麼Cilium又是如何提升報文轉發效率呢?既然Cilium 是基於 eBPF 和 XDP 實現的,而XDP歸根結底也是利用eBPF爲Linux內核提供高性能、可編程的網絡數據路徑框架,既然核心是eBPF,那麼咱們先了解下eBPF是什麼。
簡說eBPF與XDP
eBPF(extended Berkeley Packet Filter)起源於BPF,它提供了內核的數據包過濾機制。Linux 3.15 開始引入 eBPF。其擴充了 BPF 的功能,豐富了指令集。它在內核提供了一個虛擬機,用戶態將過濾規則以虛擬機指令的形式傳遞到內核,由內核根據這些指令來過濾網絡數據包。直白地講就是咱們可讓內核按照咱們的規則來對數據包進行處理,包括未進入協議棧以前的處理哦,有沒有瞬間以爲eBPF很牛逼,既然都這麼強大了,有沒有什麼最佳實踐或者應用呢?請看下圖:
咱們能夠看到XDP自己就是一個eBPF的最佳實踐,因爲其餘內容跟本文檔討論內容無關,再也不展開。做爲eBPF是如何工做以提供強大的能力呢?請看下圖:
首先是將用戶的.c文件編譯後自動生成eBPF 字節碼文件,也就是一堆的指令集合,其次經過系統調用將字節碼注入到內核,而後內核驗證合法性,經過校驗後使用JIT將其run起來,用戶程序與run起來的eBPF程序使用內核提供的標準Maps作數據交換。
與DPDK的內存所有在用戶空間來避免內存拷貝、上下文切換、系統調用等不一樣,eBPF都是在內核空間執行的。但二者的核心都是經過避免數據包在內核態與用戶態之間的往復來提高轉發效率。
說完了eBPF,接下來該XDP粉墨登場了。XDP(eXpress Data Path)爲Linux內核提供了高性能、可編程的網絡數據路徑。因爲網絡包在還未進入網絡協議棧以前就處理,它給Linux網絡帶來了巨大的性能提高(性能比DPDK還要高)。
XDP在Linux內核4.8中引入,在數據包到達協議棧、分配sk_buff以前攔截,不一樣於DPDK的是XDP是做爲內核功能的一部分,是與內核協同工做的。其基本處理流程以下圖:
XDP一樣將用戶程序編譯後生成eBPF字節碼文件,注入內核執行包過濾。XDP包過濾是在數據包進入內核協議棧以前,若是判斷數據包不需進一步處理可直接在內核態轉發數據包,若是判斷TX設備來不及處理會直接丟包,若是判斷數據包需再處理則轉給協議棧。
而爲何會有XDP比DPDK更高效的結論呢?也許經過下面這張圖你能夠本身找到答案。
做爲數據報文處理的新貴,其帶來的性能優點是不言而喻,但XDP真的那麼完美嗎?答案必定是否認的,其缺點有二:
- XDP不提供緩存隊列(qdisc),TX設備太慢時直接丟包,於是不要在RX比TX快的設備上使用XDP。
- XDP程序是專用的,不具有網絡協議棧的通用性。
聊了那麼多關於eBPF與XDP的內容,其在業界存在最佳實踐嗎?是的,目前facebook開源的katran項目,使用的正是這兩項技術,據稱其從IPVS轉到eBPF後,使其性能提升了10倍。Linux社區中有人用XDP編寫的一個簡單的入口防火牆就能夠輕鬆實現每秒處理1100萬個數據包的性能。
簡說QUIC協議
說完了如何高效的轉發請求,接下來咱們聊聊Sidecar之間如何高效的通信。
提到通信那就必定要說起通信協議了,做爲咱們耳熟能詳的兩大基本通信協議TCP與UDP的優缺點這裏就再也不贅述了,那麼咱們是否能整合TCP與UDP二者的優勢呢,這樣既保證了TCP的可靠與安全性,又兼具UDP的速度與效率,不能否認的是每每正是出於人們對美好事物的嚮往,才持續不斷的推進咱們前進的腳本。QUIC在這種期許下誕生,旨在建立幾乎等同於TCP的獨立鏈接,但有着低延遲,並對相似SPDY的多路複用流協議有更好的支持。
QUIC協議自己就內置TLS棧,實現本身的傳輸加密層,而沒有使用現有的TLS 1.2。同時QUIC還包含了部分HTTP/2的實現,所以QUIC的地位看起來是這樣的:
QUIC協議的誕生就是爲了下降網絡延遲,開創性的使用了UDP協議做爲底層傳輸協議,經過多種方式減小了網絡延遲。所以帶來了性能的極大提高,且具體的提高效果在Google旗下的YouTube已經驗證。
既然QUIC協議相比現有其餘的協議更具優點 ,那是否也能夠將其應用到Envoy中呢?Envoy社區正在推進官方重構其架構的目的之一就是爲了QUIC,最終目的是但願使用QUIC做爲Sidecar之間的通信協議。
試想一下若是Envoy應用了上述技術,性能會有怎樣的提高呢?這個就留給各位看官自行腦補吧。
讀到這裏不知各位是否會產生這樣的疑問,目前做爲ServiceMesh中數據面板的Sidecar有好幾個,爲何只有Envoy社區在性能方面呼聲最高呢?這就牽扯到一個老掉牙的話題了,由於Envoy是C系語言編寫的,在應用OS特性時有着先天優點。
雜談
上節內容提到目前有與Envoy同類的幾個程序,包括Linkerd、Conduit、NginMesh,下面就以我的所知簡單描述下各自的特色,僅供諸位參考。
就我的而言,其實挺但願Conduit的壯大,正如其設計初衷說的那樣:輕量化,相比Istio這種重部署模式來說,很是適合小規模業務的快速上手,且Conduit與Linkerd系出同門,足以保證其設計理念的先進性,雖然Buoyant公司宣稱Conduit與Linkerd的目標不一樣,但細想下來何嘗Buoyant公司沒有存在一絲不甘,但願推出一個完整的Service Mesh方案來顛覆Istio一家獨大的局面,奪回Service Mesh開創者的殊榮。
下面是各自的特性簡述。
NginMesh:
- Golang實現。
- Sidecar實現模式:agent + nginx,agent負責監聽Istio的配置變化(例如路由規則、集羣信息、服務發現等),並將其轉換爲nginx的配置,而後經過重啓nginx應用配置。
- 與istio、k8s強綁定,使用k8s的Initializer機制實現sidecar的自動注入。
- 目前還沒有在生產環境驗證。
- 雖然nginx也可使用ngixscript/lua進行擴展,但大多侷限於http處理上,對於L3L4的過濾上就無能無力了。
- 部署圖以下:
NginMesh給人的感受更多的像是作了一個Istio的橋接器,只負責把Istio的配置信息翻譯成Nginx所知的,經過重啓Nginx的方式應用配置。給個人感受僅僅是爲了搭上ServiceMesh的順風車而臨時推出的一個方案。
Linkerd:
- Scala語言開發,運行在Java虛擬機上,「Service Mesh」概念的締造者,經生產環境驗證可靠的。
- 構建基於Netty、Finagle上,工做於RPC層。
- 插入式的服務發現,例如File-based、Zookeeper、k8s。
- 因爲工做在RPC層,可根據實時觀測到的RPC延遲、要處理請求隊列大小決定如何分發請求,優於傳統啓發式負責均衡算法,例如LRU、TCP活動請求等。
- 提供多種負載均衡算法如:Power of Two Choices (P2C): Least Loaded、Power of Two Choices: Peak EWMA、Aperture: Least Loaded、Heap: Least Loaded以及Round-Robin。
- 數據流程圖以下:
做爲「Service Mesh」概念的締造者、佈道者,最終卻在Service Mesh的大潮中,被由Google、IBM、Lft聯手打造的Istio + Envoy戰勝,不得不感嘆巨頭的強大與初創公司的弱小與艱辛,由衷的但願看到Conduit的崛起,逆殺Istio。話說這是否是典型的弱者心態啊,哈哈。
Conduit:
- 脫胎於Linkerd,針對Linkerd部署模型過重的問題,其秉承的設計目標是成爲最快、最輕、最簡單的Service Mesh,使用Rust構建數據平面,使用Go構建控制平面。與Linkerd同出Buoyant公司。
- 不一樣於Envoy、Linkerd是數據平面,Istio是控制平面,Conduit中既包括數據平面,也包括控制平面,控制平面提供API,用戶經過Conduit CLI與Web UI使用。
- 只能運行在K8s上。
- 目前發佈了0.3版本,仍然處於初期開發階段。
- 對通過Conduit proxy的流量,產生一系列的監控指標,指標格式是Prometheus的,內容存放在proxy監控端口的metrics路徑下面,Prometheus能夠直接抓取指標內容,作聚合展現。
- 利用Rust自己的語言安全特性來保證自身的安全性。
- 1. 淺談Service Mesh體系中的Envoy
- 2. Service Mesh體驗
- 3. Service Mesh 初體驗
- 4. 淺談服務治理、微服務與Service Mesh(三): Service Mesh與Serverless
- 5. 淺談服務治理、微服務與Service Mesh(三) Service Mesh與Serverless
- 6. 淺談 Android Service
- 7. Envoy service mesh、Prometheus和Grafana下的微服務監控(翻譯)
- 8. 深入解讀Service Mesh的數據面Envoy
- 9. 微軟開源基於 Envoy 的服務網格 Open Service Mesh
- 10. 深刻解讀Service Mesh的數據面Envoy
- 更多相關文章...
- • 網絡體系的構成和類型 - TCP/IP教程
- • Spring體系結構詳解 - Spring教程
- • 漫談MySQL的鎖機制
- • Docker容器實戰(七) - 容器眼光下的文件系統
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 淺談Service Mesh體系中的Envoy
- 2. Service Mesh體驗
- 3. Service Mesh 初體驗
- 4. 淺談服務治理、微服務與Service Mesh(三): Service Mesh與Serverless
- 5. 淺談服務治理、微服務與Service Mesh(三) Service Mesh與Serverless
- 6. 淺談 Android Service
- 7. Envoy service mesh、Prometheus和Grafana下的微服務監控(翻譯)
- 8. 深入解讀Service Mesh的數據面Envoy
- 9. 微軟開源基於 Envoy 的服務網格 Open Service Mesh
- 10. 深刻解讀Service Mesh的數據面Envoy