開篇 | 揭祕 Flink 1.9 新架構,Blink Planner 你會用了嗎?
本文爲 Apache Flink 新版本重大功能特性解讀之 Flink SQL 系列文章的開篇,Flink SQL 系列文章由其核心貢獻者們分享,涵蓋基礎知識、實踐、調優、內部實現等各個方面,帶你由淺入深地全面瞭解 Flink SQL。java
1. 發展歷程
今年的8月22日 Apache Flink 發佈了1.9.0 版本(下文簡稱1.9),在 Flink 1.9 中,Table 模塊迎來了核心架構的升級,引入了阿里巴巴Blink團隊貢獻的諸多功能,本文對Table 模塊的架構進行梳理並介紹如何使用 Blink Planner。算法
Flink 的 Table 模塊 包括 Table API 和 SQL,Table API 是一種類SQL的API,經過Table API,用戶能夠像操做表同樣操做數據,很是直觀和方便;SQL做爲一種聲明式語言,有着標準的語法和規範,用戶能夠不用關心底層實現便可進行數據的處理,很是易於上手,Flink Table API 和 SQL 的實現上有80%左右的代碼是公用的。做爲一個流批統一的計算引擎,Flink 的 Runtime 層是統一的,但在 Flink 1.9 以前,Flink API 層 一直分爲DataStream API 和 DataSet API, Table API & SQL 位於 DataStream API 和 DataSet API 之上。sql

Flink 1.8 Table 架構apache
在 Flink 1.8 架構裏,若是用戶須要同時流計算、批處理的場景下,用戶須要維護兩套業務代碼,開發人員也要維護兩套技術棧,很是不方便。 Flink 社區很早就設想過將批數據看做一個有界流數據,將批處理看做流計算的一個特例,從而實現流批統一,阿里巴巴的 Blink 團隊在這方面作了大量的工做,已經實現了 Table API & SQL 層的流批統一。 幸運的是,阿里巴巴已經將 Blink 開源回饋給 Flink 社區。爲了實現 Flink 整個體系的流批統一,在結合 Blink 團隊的一些先行經驗的基礎上,Flink 社區的開發人員在多輪討論後,基本敲定了Flink 將來的技術架構。編程
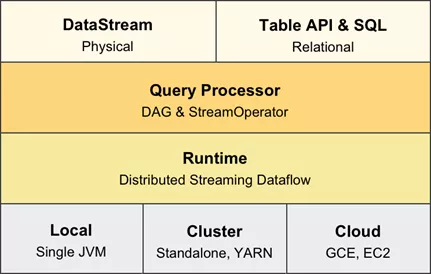api
Flink 將來架構微信
在Flink 的將來架構中,DataSet API將被廢除,面向用戶的API只有 DataStream API 和 Table API & SQL,在實現層,這兩個API共享相同的技術棧,使用統一的 DAG 數據結構來描述做業,使用統一的 StreamOperator 來編寫算子邏輯,以及使用統一的流式分佈式執行引擎,實現完全的流批統一。 這兩個API都提供流計算和批處理的功能,DataStream API 提供了更底層和更靈活的編程接口,用戶能夠自行描述和編排算子,引擎不會作過多的干涉和優化;Table API & SQL 則提供了直觀的Table API、標準的SQL支持,引擎會根據用戶的意圖來進行優化,並選擇最優的執行計劃。數據結構
2.Flink 1.9 Table 架構
Blink 的 Table 模塊的架構在開源時就已經實現了流批統一,向着 Flink 的將來架構邁進了第一步,走在了 Flink 社區前面。 所以在 Flink 1.9 合入 Blink Table 代碼時,爲了保證 Flink Table 已有架構和 Blink Table的架構可以並存並朝着 Flink 將來架構演進,社區的開發人員圍繞FLIP-32(FLIP 即 Flink Improvement Proposals,專門記錄一些對Flink 作較大修改的提議。FLIP-32是:Restructure flink-table for future contributions) 進行了重構和優化,從而使得 Flink Table 的新架構具有了流批統一的能力,能夠說 Flink 1.9 是 Flink 向着流批完全統一這個將來架構邁出的第一步。架構
Flink 1.9 Table 架構分佈式
在 Flink Table 的新架構中,有兩個查詢處理器:Flink Query Processor 和 Blink Query Processor,分別對應兩個Planner,咱們稱之爲 Old Planner 和 Blink Planner。查詢處理器是 Planner 的具體實現, 經過parser(解析器)、optimizer(優化器)、codegen(代碼生成技術)等流程將 Table API & SQL做業轉換成 Flink Runtime 可識別的 Transformation DAG (由Transformation組成的有向無環圖,表示做業的轉換邏輯),最終由 Flink Runtime 進行做業的調度和執行。
Flink 的查詢處理器針對流計算和批處理做業有不一樣的分支處理,流計算做業底層的 API 是 DataStream API, 批處理做業底層的 API 是 DataSet API;而 Blink 的查詢處理器則實現流批做業接口的統一,底層的 API 都是Transformation。
3.Flink Planner 與 Blink Planner
Flink Table 的新架構實現了查詢處理器的插件化,社區完整保留原有 Flink Planner (Old Planner),同時又引入了新的 Blink Planner,用戶能夠自行選擇使用 Old Planner 仍是 Blink Planner。
在模型上,Old Planner 沒有考慮流計算做業和批處理做業的統一,針對流計算做業和批處理做業的實現不盡相同,在底層會分別翻譯到 DataStream API 和 DataSet API 上。而 Blink Planner 將批數據集看做 bounded DataStream (有界流式數據) ,流計算做業和批處理做業最終都會翻譯到 Transformation API 上。 在架構上,Blink Planner 針對批處理和流計算,分別實現了BatchPlanner 和 StreamPlanner ,二者共用了大部分代碼,共享了不少優化邏輯。 Old Planner 針對批處理和流計算的代碼實現的是徹底獨立的兩套體系,基本沒有實現代碼和優化邏輯複用。
除了模型和架構上的優勢外,Blink Planner 在阿里巴巴集團內部的海量業務場景下沉澱了許多實用功能,集中在三個方面:
- Blink Planner 對代碼生成機制作了改進、對部分算子進行了優化,提供了豐富實用的新功能,如維表 join、Top N、MiniBatch、流式去重、聚合場景的數據傾斜優化等新功能。
- Blink Planner 的優化策略是基於公共子圖的優化算法,包含了基於成本的優化(CBO)和基於規則的優化(CRO)兩種策略,優化更爲全面。同時,Blink Planner 支持從 catalog 中獲取數據源的統計信息,這對CBO優化很是重要。
- Blink Planner 提供了更多的內置函數,更標準的 SQL 支持,在 Flink 1.9 版本中已經完整支持 TPC-H ,對高階的 TPC-DS 支持也計劃在下一個版本實現。
總體看來,Blink 查詢處理器在架構上更爲先進,功能上也更爲完善。出於穩定性的考慮,Flink 1.9 默認依然使用 Flink Planner,用戶若是須要使用 Blink Planner,能夠做業中顯式指定。
4.如何啓用 Blink Planner
在IDE環境裏,只須要引入兩個 Blink Planner 的相關依賴,就能夠啓用 Blink Planner。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.9.0</version>
</dependency>
複製代碼
對於流計算做業和批處理做業的配置很是相似,只須要在 EnvironmentSettings 中設置 StreamingMode 或 BatchMode 便可,流計算做業的設置以下:
// **********************
// BLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.java.StreamTableEnvironment;
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
// or TableEnvironment bsTableEnv = TableEnvironment.create(bsSettings);
bsTableEnv.sqlUpdate(…);
bsTableEnv.execute();
複製代碼
批處理做業的設置以下 :
// ******************
// BLINK BATCH QUERY
// ******************
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);
bbTableEnv.sqlUpdate(…)
bbTableEnv.execute()
複製代碼
若是做業須要運行在集羣環境,打包時將 Blink Planner 相關依賴的 scope 設置爲 provided,表示這些依賴由集羣環境提供。這是由於 Flink 在編譯打包時, 已經將 Blink Planner 相關的依賴打包,不須要再次引入,避免衝突。
5. 社區長遠計劃
目前,TableAPI & SQL 已經成爲 Flink API 的一等公民,社區也將投入更大的精力在這個模塊。在不遠的未來,待 Blink Planner 穩定以後,將會做爲默認的 Planner ,而 Old Planner 也將會在合適的時候退出歷史的舞臺。目前社區也在努力賦予 DataStream 批處理的能力,從而統一流批技術棧,屆時 DataSet API 也將退出歷史的舞臺。
▼ Apache Flink 社區推薦 ▼
Apache Flink 及大數據領域盛會 Flink Forward Asia 2019 將於 11月28-30日在北京舉辦,阿里、騰訊、美團、字節跳動、百度、英特爾、DellEMC、Lyft、Netflix 及 Flink 創始團隊等近 30 家知名企業資深技術專家齊聚國際會議中心,與全球開發者共同探討大數據時代核心技術與開源生態。瞭解更多精彩議程請點擊:
developer.aliyun.com/special/ffa…
Flink 社區公衆號後臺回覆「門票」,少許免費門票搶先拿。
Flink 社區官方微信公衆號
- 1. 開篇 | 揭祕 Flink 1.9 新架構,Blink Planner 你會用了嗎?
- 2. 揭祕 Flink 1.9 新架構,Blink Planner 你會用了嗎?
- 3. Go 1.9 sync.Map揭祕
- 4. 如何在 Flink 1.9 中使用 Hive?
- 5. Electron架構揭祕
- 6. ZooKeeper架構原理你學會了嗎?
- 7. 阿里的Blink開源了,如何部署你知道嗎?
- 8. 阿里blink架構
- 9. Spring架構揭祕-AOP
- 10. 程序員工資大揭祕,你拖後腿了嗎?
- 更多相關文章...
- • Docker 架構 - Docker教程
- • 互聯網系統應用架構基礎分析 - 紅包項目實戰
- • 再有人問你分佈式事務,把這篇扔給他
- • PHP開發工具
-
每一个你不满意的现在,都有一个你没有努力的曾经。