每天寫order by,你知道Mysql底層如何執行嗎?
前言
-
文章首發於微信公衆號文章,更多文章架構師資源請關注微信公衆號【碼猿技術專欄】,多謝支持!!!算法
-
在實際的開發中必定會碰到根據某個字段進行排序後來顯示結果的需求,可是你真的理解`order by`在 Mysql 底層是如何執行的嗎?
-
假設你要查詢城市是`蘇州`的全部人名字,而且按照姓名進行排序返回前 1000 我的的姓名、年齡,這條 sql 語句應該如何寫?
-
首先建立一張用戶表,sql 語句以下:
CREATE TABLE user ( id int(11) NOT NULL, city varchar(16) NOT NULL, name varchar(16) NOT NULL, age int(11) NOT NULL, PRIMARY KEY (id), KEY city (city) ) ENGINE=InnoDB;sql
-
則上述需求的 sql 查詢語句以下:
select city,name,age from user where city='蘇州' order by name limit 1000;性能優化
-
這條 sql 查詢語句相信你們都能寫出來,可是你瞭解它在 Mysql 底層的執行流程嗎?今天陳某來你們聊一聊這條 sql 語句是如何執行的以及有什麼參數會影響執行的流程。
-
本篇文章分爲以下幾個部分進行詳細的闡述:
-
**全字段排序**
-
**rowid 排序**
-
**全字段排序 VS rowid 排序**
-
**如何避免排序**
-
全字段排序
-
前面聊過索引可以避免全表掃描,所以咱們給`city`這個字段上添加了索引,固然城市的字段很小,不用考慮字符串的索引問題,以前有寫過一篇關於如何給字符串的加索引的文章,有不瞭解朋友看一下這篇文章:[Mysql 性能優化:如何給字符串加索引?](https://mp.weixin.qq.com/s/xaa8ge7LsHWYROOy4qiRJA)
-
此時用`Explain`來分析一下的這條查詢語句的執行狀況,結果以下圖: 
-
`Extra`這個字段中的`Using filesort`表示的就是須要排序,MySQL 會給每一個線程分配一塊內存用於排序,稱爲`sort_buffer`。
-
既然使用了索引進行查詢,咱們來簡單的畫一下`city`這棵索引樹的結構,以下圖: 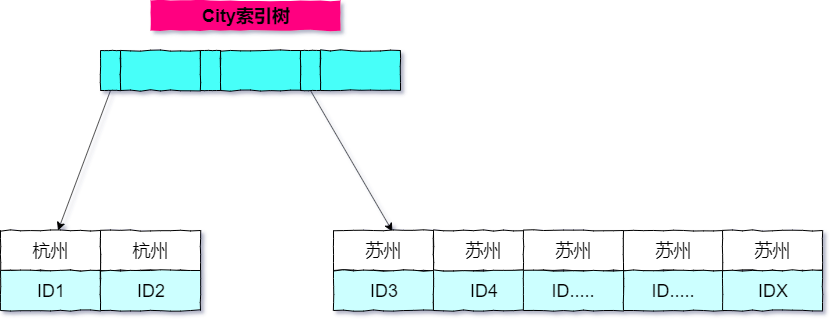
-
從上圖能夠看出,知足`city='蘇州'`是從`ID3`到`IDX`這些記錄。
-
一般狀況下,此條 sql 語句執行流程以下:
-
初始化 sort_buffer,肯定放入 name、city、age 這三個字段。
-
從索引 city 找到第一個知足`city='蘇州'`條件的`主鍵id`,也就是圖中的`ID3`。
-
到`主鍵id索引`取出整行,取`name`、`city`、`age`三個字段的值,存入`sort_buffer`中。
-
從索引`city`取下一個記錄的主鍵 id。
-
重複步驟 三、4 直到 city 的值不知足查詢條件爲止,對應的主鍵 id 也就是圖中的`IDX`。
-
對`sort_buffer`中的數據按照字段`name`作快速排序。
-
按照排序結果取前 1000 行返回給客戶端。
-
-
咱們稱這個排序過程爲`全字段排序`,執行的流程圖以下: 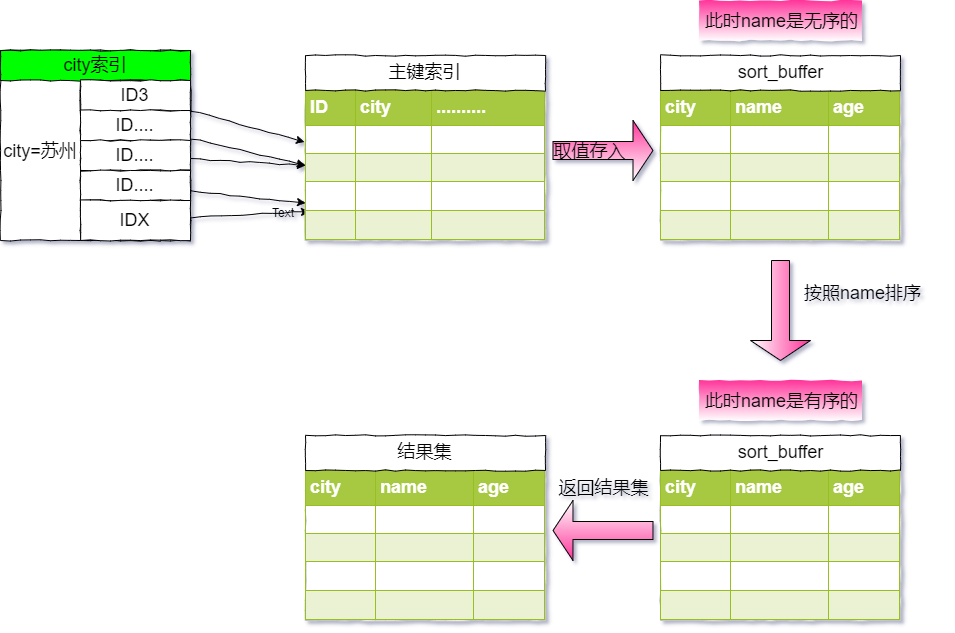
-
圖中`按name排序`這個動做,可能在內存中完成,也可能須要使用外部排序,這取決於排序所需的內存和參數`sort_buffer_size`。
-
`sort_buffer_size`:就是 MySQL 爲排序開闢的內存(sort_buffer)的大小。若是要排序的數據量小於 sort_buffer_size,排序就在內存中完成。但若是排序數據量太大,內存放不下,則不得不利用`磁盤臨時文件`輔助排序。
rowid 排序
-
在上面這個算法過程裏面,只對原表的數據讀了一遍,剩下的操做都是在`sort_buffer`和`臨時文件`中執行的。**但這個算法有一個問題,就是若是查詢要返回的字段不少的話,那麼`sort_buffer`裏面要放的字段數太多,這樣內存裏可以同時放下的行數不多,要分紅不少個臨時文件,排序的性能會不好**。
-
因此若是單行很大,這個方法效率不夠好。
-
咱們能夠修改一個`max_length_for_sort_data`這個參數使其使用另一種算法。max_length_for_sort_data,是 MySQL 中專門控制用於排序的行數據的長度的一個參數。它的意思是,若是單行的長度超過這個值,MySQL 就認爲單行太大,要換一個算法。
-
`city`、`name`、`age` 這三個字段的定義總長度是`36`,我把`max_length_for_sort_data`設置爲 16,咱們再來看看計算過程有什麼改變。設置的 sql 語句以下:
SET max_length_for_sort_data = 16;微信
-
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主鍵 id。markdown
-
但這時,排序的結果就由於少了 city 和 age 字段的值,不能直接返回了,整個執行流程就變成以下所示的樣子:架構
-
初始化`sort_buffer`,肯定放入兩個字段,即`name`和`id`。
-
從索引 city 找到第一個知足`city='蘇州'`條件的`主鍵id`,也就是圖中的`ID3`。
-
到`主鍵id索引`取出整行,取 name、id 這兩個字段,存入 sort_buffer 中。
-
從索引`city`取下一個記錄的主鍵 id。
-
重複步驟 三、4 直到 city 的值不知足查詢條件爲止,對應的主鍵 id 也就是圖中的`IDX`。
-
對`sort_buffer`中的數據按照字段`name`作快速排序。
-
遍歷排序結果,取前 1000 行,並按照 id 的值回到原表中取出 city、name 和 age 三個字段返回給客戶端。
-
-
這個執行流程的示意圖以下,我把它稱爲
rowid排序。 性能
性能 -
對比
全字段排序,rowid排序多了一次回表查詢,便是多了第7步的查詢主鍵索引樹。優化
全字段排序 VS rowid 排序
-
若是 MySQL 實在是擔憂排序內存過小,會影響排序效率,纔會採用 rowid 排序算法,這樣排序過程當中一次能夠排序更多行,可是須要再回到原表去取數據。
-
若是 MySQL 認爲內存足夠大,會優先選擇全字段排序,把須要的字段都放到 sort_buffer 中,這樣排序後就會直接從內存裏面返回查詢結果了,不用再回到原表去取數據。
-
這也就體現了 MySQL 的一個設計思想:**若是內存夠,就要多利用內存,儘可能減小磁盤訪問**。
-
**對於 InnoDB 表來講,rowid 排序會要求回表多形成磁盤讀,所以不會被優先選擇。**
如何避免排序
-
其實,並非全部的`order by`語句,都須要排序操做的。從上面分析的執行過程,咱們能夠看到,MySQL 之因此須要生成臨時表,而且在臨時表上作排序操做,其緣由是**原來的數據都是無序的**。
-
若是可以保證從`city`這個索引上取出來的行,自然就是按照 name 遞增排序的話,是否是就能夠不用再排序了呢?
-
所以想到了聯合索引,建立`(city,name)`聯合索引,sql 語句以下:
alter table user add index city_user(city, name);spa
-
此時的索引樹以下: 
-
在這個索引裏面,咱們依然能夠用樹搜索的方式定位到第一個知足`city='蘇州'`的記錄,而且額外確保了,接下來按順序取「下一條記錄」的遍歷過程當中,只要 city 的值是杭州,name 的值就必定是有序的。
-
按照上圖,整個查詢的流程以下:
-
從索引(city,name)找到第一個知足 city='蘇州’條件的主鍵 id。
-
到主鍵 id 索引取出整行,取 name、city、age 三個字段的值,做爲結果集的一部分直接返回。
-
從索引(city,name)取下一個記錄主鍵 id。
-
重複步驟 二、3,直到查到第 1000 條記錄,或者是不知足 city='蘇州'條件時循環結束。
-
-
對應的流程圖以下: 
-
能夠看到,這個查詢過程不須要臨時表,也不須要排序。接下來,咱們用 explain 的結果來印證一下。 
-
從圖中能夠看到,`Extra`字段中沒有`Using filesort`了,也就是不須要排序了。並且因爲`(city,name)`這個聯合索引自己有序,**因此這個查詢也不用把 4000 行全都讀一遍,只要找到知足條件的前 1000 條記錄就能夠退出了**。也就是說,在咱們這個例子裏,只須要掃描 1000 次。
-
難道僅僅這樣就能知足了?此條查詢語句是否能再優化呢? 
-
朋友們還記得覆蓋索引嗎?覆蓋索引的好處就是可以避免再次回表查詢,不瞭解的朋友們能夠看一下陳某以前寫的文章:[Mysql 性能優化:如何使用覆蓋索引?](https://mp.weixin.qq.com/s/-IRhK4KyDCkTd_lojeEolw)。
-
咱們建立`(city,name,age)`聯合索引,這樣在執行上面的查詢語句就能使用覆蓋索引了,避免了回表查詢了,sql 語句以下:
alter table user add index city_user_age(city, name, age);線程
-
此時執行流程圖以下: 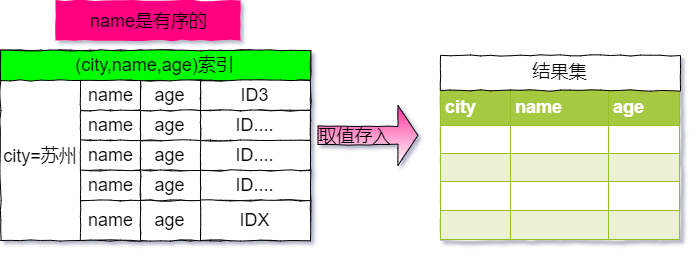
-
**固然,覆蓋索引可以提高效率,可是維護索引也是須要代價的,所以還須要權衡使用。**
總結
-
今天這篇文章,我和你介紹了 MySQL 裏面`order by`語句的幾種算法流程。
-
在開發系統的時候,你老是不可避免地會使用到 order by 語句。內心要清楚每一個語句的排序邏輯是怎麼實現的,還要可以分析出在最壞狀況下,每一個語句的執行對系統資源的消耗,這樣才能作到下筆若有神,不犯低級錯誤。
相關文章
- 1. 每天寫order by,你知道Mysql底層如何執行嗎?
- 2. 每天寫order by,你知道Mysql底層執行原理嗎?
- 3. 每天寫 order by,你知道Mysql底層執行流程嗎?
- 4. 每天寫order by ,你知道Mysql底層的執行原理嗎?
- 5. Node的底層調用你知道嗎?
- 6. 【精讀】你知道Spring中BeanFactoryPostProcessors是如何執行的嗎?
- 7. MySQL如何優化ORDER BY
- 8. Spark(29) -- SparkSQL底層如何執行
- 9. 你知道mySQL底層工作的幾大原理嗎?我們帶你飛
- 10. 和產品爭論MySQL底層如何實現order by的,慘敗!
- 更多相關文章...
- • SQLite Order By - SQLite教程
- • PHP MySQL Order By 關鍵詞 - PHP教程
- • 漫談MySQL的鎖機制
- • 再有人問你分佈式事務,把這篇扔給他
相關標籤/搜索
每日一句
-
每一个你不满意的现在,都有一个你没有努力的曾经。
最新文章
歡迎關注本站公眾號,獲取更多信息

相關文章
- 1. 每天寫order by,你知道Mysql底層如何執行嗎?
- 2. 每天寫order by,你知道Mysql底層執行原理嗎?
- 3. 每天寫 order by,你知道Mysql底層執行流程嗎?
- 4. 每天寫order by ,你知道Mysql底層的執行原理嗎?
- 5. Node的底層調用你知道嗎?
- 6. 【精讀】你知道Spring中BeanFactoryPostProcessors是如何執行的嗎?
- 7. MySQL如何優化ORDER BY
- 8. Spark(29) -- SparkSQL底層如何執行
- 9. 你知道mySQL底層工作的幾大原理嗎?我們帶你飛
- 10. 和產品爭論MySQL底層如何實現order by的,慘敗!