基於Heapster的HPA
基於Heapster的HPA
概述
Horizontal Pod Autoscaling,簡稱HPA,是Kubernetes中實現POD水平自動伸縮的功能。自動擴展主要分爲兩種:php
- 水平擴展(scale out),針對於實例數目的增減
- 垂直擴展(scal up),即單個實例可使用的資源的增減, 好比增長cpu和增大內存
HPA屬於前者。它能夠根據CPU使用率或應用自定義metrics自動擴展Pod數量(支持 replication controller、deployment 和 replica set)node
節點擴縮容層面,k8s集羣的Cluster Autoscaler持續監控Pods,一旦發現Pods沒法被schedule,則基於PodConditoin進行擴展,即node節點的自動擴縮容,具體內容在後續文章中介紹。git
監控數據獲取
- Heapster: heapster收集Node節點上的cAdvisor數據,並按照kubernetes的資源類型來集合資源。可是在v1.11中已經被廢棄(heapster監控數據可用,但HPA再也不從heapster拿數據)
- metric-server: 在v1.8版本中引入,官方將其做爲heapster的替代者。metric-server依賴於kube-aggregator,所以須要在apiserver中開啓相關參數。v1.11中HPA從metric-server獲取監控數據
工做流程
- 1.建立HPA資源,設定目標CPU使用率限額,以及最大、最小實例數, 必定要設置Pod的資源限制參數: request, 不然HPA不會工做。
- 2.控制管理器每隔30s(能夠經過–horizontal-pod-autoscaler-sync-period修改)查詢metrics的資源使用狀況
- 3.而後與建立時設定的值和指標作對比(平均值之和/限額),求出目標調整的實例個數
- 4.目標調整的實例數不能超過1中設定的最大、最小實例數,若是沒有超過,則擴容;超過,則擴容至最大的實例個數
如何部署:
- 1.6-1.8版本默認使用heapster
- 1.11版本及以上默認使用metric-server(需單獨安裝,並開啓參數)
1.部署和運行php-apache並將其暴露成爲服務github

2.建立HPA apache
apache
若是爲1.8及如下的k8s集羣,指標正常,若是爲1.11集羣,須要執行以下操做。 api
api
4.向php-apache服務增長負載,驗證自動擴縮容服務器
啓動一個容器,並經過一個循環向php-apache服務器發送無限的查詢請求(請在另外一個終端中運行如下命令)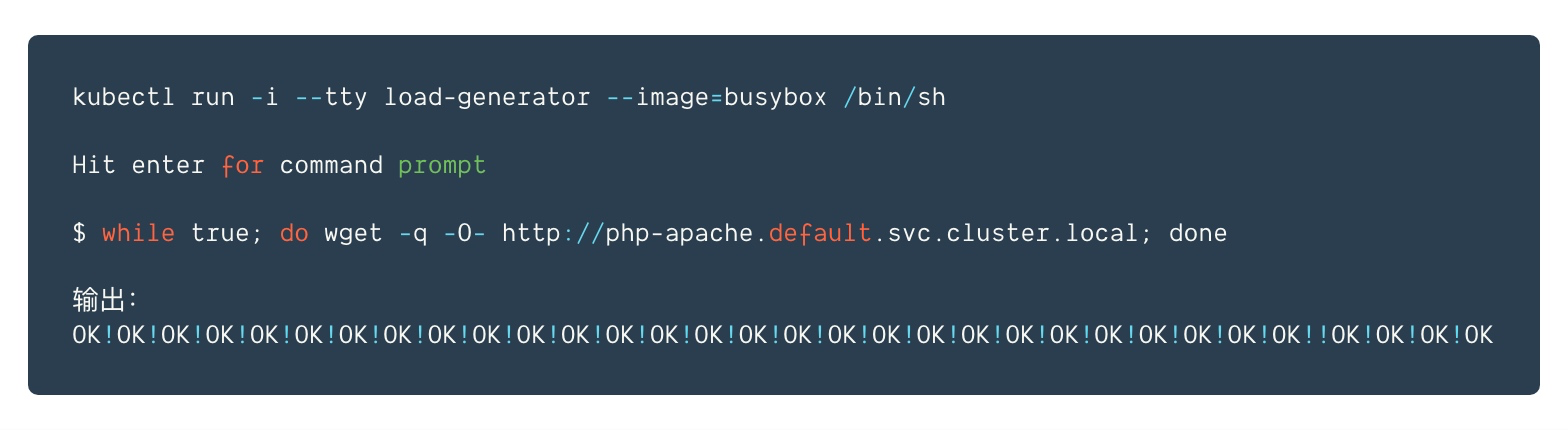 spa
spa
5.觀察HPA是否生效 3d
3d
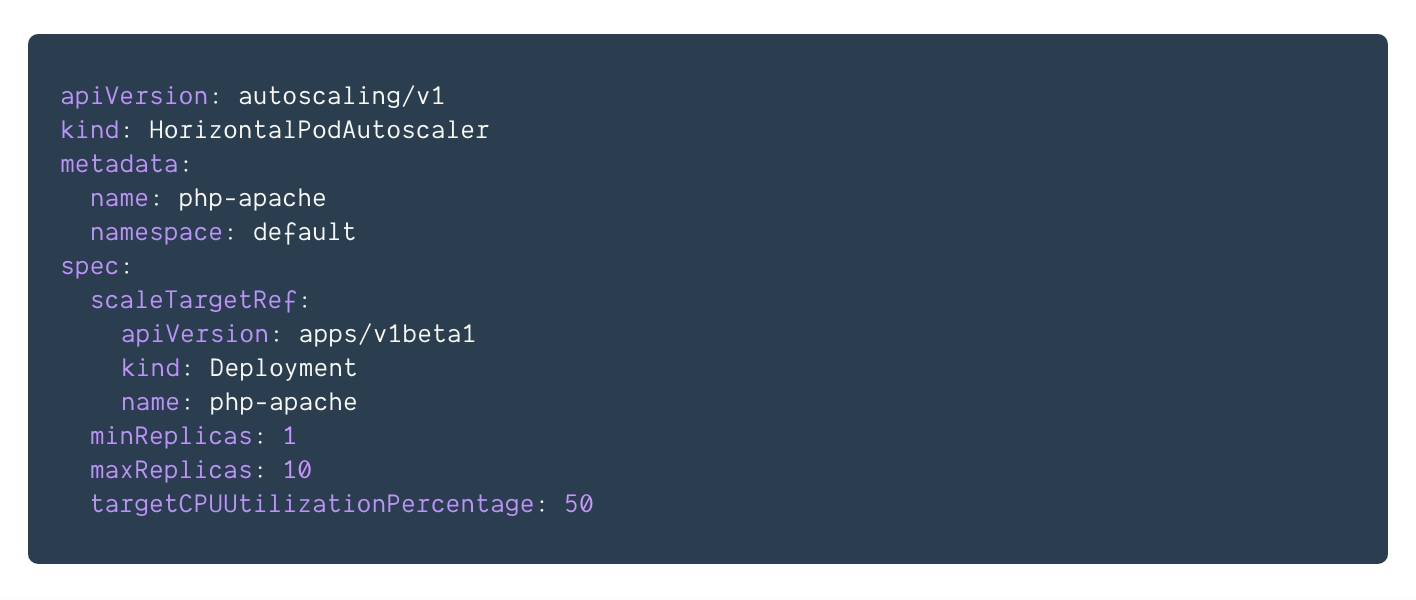
用yaml建立HPA的方式爲:code
實現細節
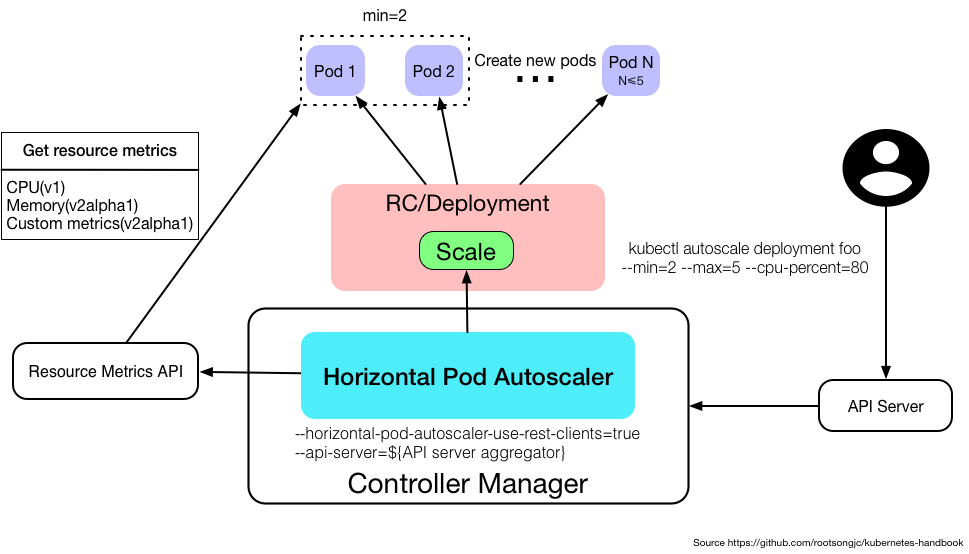
HPA由一個控制循環實現,循環週期由--horizontal-pod-autoscaler-sync-period 標誌指定,默認是30秒,每一個週期內,controller-manager會查詢HPA中定義的metric的資源利用率。
如上例子,pod的request定義爲200M,而HPA定義的target爲50%,即HPA將經過增長或者減小Pod副本的數量(經過Deployment)以保持全部Pod的平均CPU利用率在50%之內(即200*0.5=100M之內),循環週期到達時,獲取pod的1分鐘內的平均cpu利用率(從heaspter),發現超過了100M,爲332M,因而經過下面的公式,決定最終的pod數量
TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)
即 332/50 =6.xxx ceil爲向上取整,獲得7。若是獲得的結果大於10,則爲10
由於每次HPA生效都會建立或者刪除pod,而這些操做其實會影響到metric監控值,如建立pod會暫時性的升高cpu,所以每次擴容都要間隔3分鐘,縮容須要間隔5分鐘。且須要知足:avg(CurrentPodsConsumption)/ Target降低9%,進行縮容,增長至10%才進行擴容
這樣作好處是:
一、判斷的精度高,不會頻繁的擴縮pod,形成集羣壓力大。
二、避免頻繁的擴縮pod,防止應用訪問不穩定
實現hpa的條件:
一、hpa不能autoscale daemonset類型control
二、要實現autoscale,pod必須設置request
參考:https://github.com/kubernetes...
本文爲容器監控實踐系列文章,完整內容見:container-monitor-book
- 1. K8S集羣基於heapster的HPA測試
- 2. Kubernetes基於Metrics Server的HPA
- 3. Kubernetes 基於 Metrics Server 與 HPA 的使用
- 4. kubernetes基於Metrics Server的HPA彈性伸縮pod
- 5. k8s與HPA--基於Kubernetes的事件驅動自動縮放
- 6. 基於Custom-metrics-apiserver實現Kubernetes的HPA(內含踩坑)
- 7. Kubernetes heapster 搭建
- 8. Kubernetes1.5 集成Heapster
- 9. 探索Kubernetes HPA
- 10. 終於成功部署 Kubernetes HPA 基於 QPS 進行自動伸縮
- 更多相關文章...
- • Spring基於Annotation裝配Bean - Spring教程
- • Spring基於XML裝配Bean - Spring教程
- • ☆基於Java Instrument的Agent實現
- • 適用於PHP初學者的學習線路和建議
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. K8S集羣基於heapster的HPA測試
- 2. Kubernetes基於Metrics Server的HPA
- 3. Kubernetes 基於 Metrics Server 與 HPA 的使用
- 4. kubernetes基於Metrics Server的HPA彈性伸縮pod
- 5. k8s與HPA--基於Kubernetes的事件驅動自動縮放
- 6. 基於Custom-metrics-apiserver實現Kubernetes的HPA(內含踩坑)
- 7. Kubernetes heapster 搭建
- 8. Kubernetes1.5 集成Heapster
- 9. 探索Kubernetes HPA
- 10. 終於成功部署 Kubernetes HPA 基於 QPS 進行自動伸縮