淺談 Spark 應用程序的性能調優
Spark是基於內存的分佈式計算引擎,以處理的高效和穩定著稱。然而在實際的應用開發過程當中,開發者仍是會遇到種種問題,其中一大類就是和性能相關。在本文中,筆者將結合自身實踐,談談如何儘量地提升應用程序性能。java
分佈式計算引擎在調優方面有四個主要關注方向,分別是CPU、內存、網絡開銷和I/O,其具體調優目標以下:node
提升CPU利用率。ios
避免OOM。算法
下降網絡開銷。sql
減小I/O操做。shell
第1章 數據傾斜
數據傾斜意味着某一個或某幾個Partition中的數據量特別的大,這意味着完成針對這幾個Partition的計算須要耗費至關長的時間。數據庫
若是大量數據集中到某一個Partition,那麼這個Partition在計算的時候就會成爲瓶頸。圖1是Spark應用程序執行併發的示意圖,在Spark中,同一個應用程序的不一樣Stage是串行執行的,而同一Stage中的不一樣Task能夠併發執行,Task數目由Partition數來決定,若是某一個Partition的數據量特別大,則相應的task完成時間會特別長,由此致使接下來的Stage沒法開始,整個Job完成的時間就會很是長。apache
要避免數據傾斜的出現,一種方法就是選擇合適的key,或者是本身定義相關的partitioner。在Spark中Block使用了ByteBuffer來存儲數據,而ByteBuffer可以存儲的最大數據量不超過2GB。若是某一個key有大量的數據,那麼在調用cache或persist函數時就會碰到spark-1476這個異常。緩存
下面列出的這些API會致使Shuffle操做,是數據傾斜可能發生的關鍵點所在網絡
groupByKey
reduceByKey
aggregateByKey
sortByKey
join
cogroup
cartesian
coalesce
repartition
repartitionAndSortWithinPartitions

圖1: Spark任務併發模型
def rdd: RDD[T]
}
// TODO View bounds are deprecated, should use context bounds
// Might need to change ClassManifest for ClassTag in spark 1.0.0
case class DemoPairRDD[K <% Ordered[K] : ClassManifest, V: ClassManifest](
rdd: RDD[(K, V)]) extends RDDWrapper[(K, V)] {
// Here we use a single Long to try to ensure the sort is balanced,
// but for really large dataset, we may want to consider
// using a tuple of many Longs or even a GUID
def sortByKeyGrouped(numPartitions: Int): RDD[(K, V)] =
rdd.map(kv => ((kv._1, Random.nextLong()), kv._2)).sortByKey()
.grouped(numPartitions).map(t => (t._1._1, t._2))
}
case class DemoRDD[T: ClassManifest](rdd: RDD[T]) extends RDDWrapper[T] {
def grouped(size: Int): RDD[T] = {
// TODO Version where withIndex is cached
val withIndex = rdd.mapPartitions(_.zipWithIndex)
val startValues =
withIndex.mapPartitionsWithIndex((i, iter) =>
Iterator((i, iter.toIterable.last))).toArray().toList
.sortBy(_._1).map(_._2._2.toLong).scan(-1L)(_ + _).map(_ + 1L)
withIndex.mapPartitionsWithIndex((i, iter) => iter.map {
case (value, index) => (startValues(i) + index.toLong, value)
})
.partitionBy(new Partitioner {
def numPartitions: Int = size
def getPartition(key: Any): Int =
(key.asInstanceOf[Long] * numPartitions.toLong / startValues.last).toInt
})
.map(_._2)
}
}
定義隱式的轉換
implicit def toDemoRDD[T: ClassManifest](rdd: RDD[T]): DemoRDD[T] =
new DemoRDD[T](rdd)
implicit def toDemoPairRDD[K <% Ordered[K] : ClassManifest, V: ClassManifest](
rdd: RDD[(K, V)]): DemoPairRDD[K, V] = DemoPairRDD(rdd)
implicit def toRDD[T](rdd: RDDWrapper[T]): RDD[T] = rdd.rdd
}
在spark-shell中就可使用了
import RDDConversions._ yourRdd.grouped(5)
第2章 減小網絡通訊開銷
Spark的Shuffle過程很是消耗資源,Shuffle過程意味着在相應的計算節點,要先將計算結果存儲到磁盤,後續的Stage須要將上一個Stage的結果再次讀入。數據的寫入和讀取意味着Disk I/O操做,與內存操做相比,Disk I/O操做是很是低效的。
使用iostat來查看disk i/o的使用狀況,disk i/o操做頻繁通常會伴隨着cpu load很高。
若是數據和計算節點都在同一臺機器上,那麼能夠避免網絡開銷,不然還要加上相應的網絡開銷。 使用iftop來查看網絡帶寬使用狀況,看哪幾個節點之間有大量的網絡傳輸。
圖2是Spark節點間數據傳輸的示意圖,Spark Task的計算函數是經過Akka通道由Driver發送到Executor上,而Shuffle的數據則是經過Netty網絡接口來實現。因爲Akka通道中參數spark.akka.framesize決定了可以傳輸消息的最大值,因此應該避免在Spark Task中引入超大的局部變量。
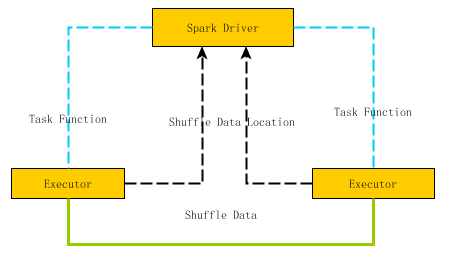
圖2: Spark節點間的數據傳輸
第1節 選擇合適的併發數
爲了提升Spark應用程序的效率,儘量的提高CPU的利用率。併發數應該是可用CPU物理核數的兩倍。在這裏,併發數太低,CPU得不到充分的利用,併發數過大,因爲spark是每個task都要分發到計算結點,因此任務啓動的開銷會上升。
併發數的修改,經過配置參數來改變spark.default.parallelism,若是是sql的話,可能經過修改spark.sql.shuffle.partitions來修改。
第1項 Repartition vs. Coalesce
repartition和coalesce都能實現數據分區的動態調整,但須要注意的是repartition會致使shuffle操做,而coalesce不會。
第2節 reduceByKey vs. groupBy
groupBy操做應該儘量的避免,第一是有可能形成大量的網絡開銷,第二是可能致使OOM。以WordCount爲例來演示reduceByKey和groupBy的差別
reduceByKey
sc.textFile(「README.md」).map(l=>l.split(「,」)).map(w=>(w,1)).reduceByKey(_ + _)
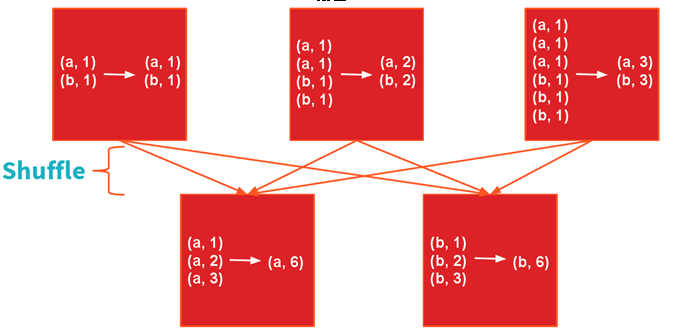
圖3:reduceByKey的Shuffle過程
Shuffle過程如圖2所示
groupByKey
sc.textFile(「README.md」).map(l=>l.split(「,」)).map(w=>(w,1)).groupByKey.map(r=>(r._1,r._2.sum))
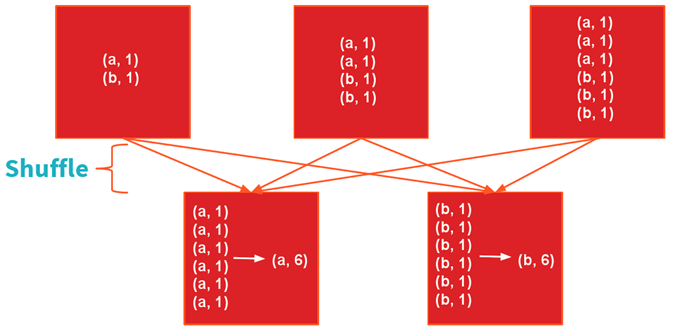
圖4:groupByKey的Shuffle過程
建議: 儘量使用reduceByKey, aggregateByKey, foldByKey和combineByKey
假設有一RDD以下所示,求每一個key的均值
val data = sc.parallelize( List((0, 2.), (0, 4.), (1, 0.), (1, 10.), (1, 20.)) )
方法一:reduceByKey
data.map(r=>(r._1, (r.2,1))).reduceByKey((a,b)=>(a._1 + b._1, a._2 + b._2)).map(r=>(r._1,(r._2._1/r._2._2)).foreach(println)
方法二:combineByKey
data.combineByKey(value=>(value,1),
(x:(Double, Int), value:Double)=> (x._1+value, x._2 + 1), (x:(Double,Int), y:(Double, Int))=>(x._1 + y._1, x._2 + y._2))
第3節 BroadcastHashJoin vs. ShuffleHashJoin
在Join過程當中,常常會遇到大表和小表的join. 爲了提升效率可使用BroadcastHashJoin, 預先將小表的內容廣播到各個Executor, 這樣將避免針對小表的Shuffle過程,從而極大的提升運行效率。
其實BroadCastHashJoin核心就是利用了BroadCast函數,若是理解清楚broadcast的優勢,就能比較好的明白BroadcastHashJoin的優點所在。
如下是一個簡單使用broadcast的示例程序。
val lst = 1 to 100 toList val exampleRDD = sc.makeRDD(1 to 20 toSeq, 2) val broadcastLst = sc.broadcast(lst) exampleRDD.filter(i=>broadcastLst.valuecontains(i)).collect.foreach(println)
第4節 map vs. mapPartitions
有時須要將計算結果存儲到外部數據庫,勢必會創建到外部數據庫的鏈接。應該儘量的讓更多的元素共享同一個數據鏈接而不是每個元素的處理時都去創建數據庫鏈接。
在這種狀況下,mapPartitions和foreachPartitons將比map操做高效的多。
第5節 數據就地讀取
移動計算的開銷遠遠低於移動數據的開銷。
Spark中每一個Task都須要相應的輸入數據,所以輸入數據的位置對於Task的性能變得很重要。按照數據獲取的速度來區分,由快到慢分別是:
PROCESS_LOCAL
NODE_LOCAL
RACK_LOCAL
Spark在Task執行的時候會盡優先考慮最快的數據獲取方式,若是想盡量的在更多的機器上啓動Task,那麼能夠經過調低spark.locality.wait的值來實現, 默認值是3s。
除了HDFS,Spark可以支持的數據源愈來愈多,如Cassandra, HBase,MongoDB等知名的NoSQL數據庫,隨着Elasticsearch的日漸興起,spark和elasticsearch組合起來提供高速的查詢解決方案也成爲一種有益的嘗試。
上述提到的外部數據源面臨的一個相同問題就是如何讓spark快速讀取其中的數據, 儘量的將計算結點和數據結點部署在一塊兒是達到該目標的基本方法,好比在部署Hadoop集羣的時候,能夠將HDFS的DataNode和Spark Worker共享一臺機器。
以cassandra爲例,若是Spark的部署和Cassandra的機器有部分重疊,那麼在讀取Cassandra中數據的時候,經過調低spark.locality.wait就能夠在沒有部署Cassandra的機器上啓動Spark Task。
對於Cassandra, 能夠在部署Cassandra的機器上部署Spark Worker,須要注意的是Cassandra的compaction操做會極大的消耗CPU,所以在爲Spark Worker配置CPU核數時,須要將這些因素綜合在一塊兒進行考慮。
這一部分的代碼邏輯能夠參考源碼TaskSetManager::addPendingTask
private def addPendingTask(index: Int, readding: Boolean = false) {
// Utility method that adds `index` to a list only if readding=false or it's not already there
def addTo(list: ArrayBuffer[Int]) {
if (!readding || !list.contains(index)) {
list += index
}
}
for (loc <- tasks(index).preferredLocations) {
loc match {
case e: ExecutorCacheTaskLocation =>
addTo(pendingTasksForExecutor.getOrElseUpdate(e.executorId, new ArrayBuffer))
case e: HDFSCacheTaskLocation => {
val exe = sched.getExecutorsAliveOnHost(loc.host)
exe match {
case Some(set) => {
for (e <- set) {
addTo(pendingTasksForExecutor.getOrElseUpdate(e, new ArrayBuffer))
}
logInfo(s"Pending task $index has a cached location at ${e.host} " +
", where there are executors " + set.mkString(","))
}
case None => logDebug(s"Pending task $index has a cached location at ${e.host} " +
", but there are no executors alive there.")
}
}
case _ => Unit
}
addTo(pendingTasksForHost.getOrElseUpdate(loc.host, new ArrayBuffer))
for (rack <- sched.getRackForHost(loc.host)) {
addTo(pendingTasksForRack.getOrElseUpdate(rack, new ArrayBuffer))
}
}
if (tasks(index).preferredLocations == Nil) {
addTo(pendingTasksWithNoPrefs)
}
if (!readding) {
allPendingTasks += index // No point scanning this whole list to find the old task there
}
}
若是準備讓spark支持新的存儲源,進而開發相應的RDD,與位置相關的部分就是自定義getPreferredLocations函數,以elasticsearch-hadoop中的EsRDD爲例,其代碼實現以下。
override def getPreferredLocations(split: Partition): Seq[String] = {
val esSplit = split.asInstanceOf[EsPartition]
val ip = esSplit.esPartition.nodeIp
if (ip != null) Seq(ip) else Nil
}
第6節 序列化
使用好的序列化算法可以提升運行速度,同時可以減小內存的使用。
Spark在Shuffle的時候要將數據先存儲到磁盤中,存儲的內容是通過序列化的。序列化的過程牽涉到兩大基本考慮的因素,一是序列化的速度,二是序列化後內容所佔用的大小。
kryoSerializer與默認的javaSerializer相比,在序列化速度和序列化結果的大小方面都具備極大的優點。因此建議在應用程序配置中使用KryoSerializer.
spark.serializer org.apache.spark.serializer.KryoSerializer
默認的cache沒有對緩存的對象進行序列化,使用的StorageLevel是MEMORY_ONLY,這意味着要佔用比較大的內存。能夠經過指定persist中的參數來對緩存內容進行序列化。
exampleRDD.persist(MEMORY_ONLY_SER)
須要特別指出的是persist函數是等到job執行的時候纔會將數據緩存起來,屬於延遲執行; 而unpersist函數則是當即執行,緩存會被當即清除。
更多內容能夠訪問 community.qingcloud.com
- 1. 淺談Apache性能調優
- 2. 淺談Nginx性能調優
- 3. Spark的性能調優雜談
- 4. 淺談優化程序性能(下)
- 5. Spark 任務性能優化淺談
- 6. 揭祕Spark應用性能調優
- 7. Spark 程序性能調優(一)
- 8. 開發高性能的MongoDB應用—淺談MongoDB性能優化
- 9. Spark性能調優
- 10. spark性能調優
- 更多相關文章...
- • XML 應用程序 - XML 教程
- • ASP.NET MVC - Internet 應用程序 - ASP.NET 教程
- • TiDB 在摩拜單車在線數據業務的應用和實踐
- • 三篇文章瞭解 TiDB 技術內幕 —— 談調度
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 升級Gradle後報錯Gradle‘s dependency cache may be corrupt (this sometimes occurs
- 2. Smarter, Not Harder
- 3. mac-2019-react-native 本地環境搭建(xcode-11.1和android studio3.5.2中Genymotion2.12.1 和VirtualBox-5.2.34 )
- 4. 查看文件中關鍵字前後幾行的內容
- 5. XXE萌新進階全攻略
- 6. Installation failed due to: ‘Connection refused: connect‘安卓studio端口占用
- 7. zabbix5.0通過agent監控winserve12
- 8. IT行業UI前景、潛力如何?
- 9. Mac Swig 3.0.12 安裝
- 10. Windows上FreeRDP-WebConnect是一個開源HTML5代理,它提供對使用RDP的任何Windows服務器和工作站的Web訪問
- 1. 淺談Apache性能調優
- 2. 淺談Nginx性能調優
- 3. Spark的性能調優雜談
- 4. 淺談優化程序性能(下)
- 5. Spark 任務性能優化淺談
- 6. 揭祕Spark應用性能調優
- 7. Spark 程序性能調優(一)
- 8. 開發高性能的MongoDB應用—淺談MongoDB性能優化
- 9. Spark性能調優
- 10. spark性能調優