Spring Boot+SQL/JPA實戰悲觀鎖和樂觀鎖
最近在公司的業務上遇到了併發的問題,而且仍是很常見的併發問題,算是低級的失誤了。因爲公司業務相對比較複雜且不適合公開,在此用一個很常見的業務來還原一下場景,同時介紹悲觀鎖和樂觀鎖是如何解決這類併發問題的。java
公司業務就是最多見的「訂單+帳戶」問題,在解決完公司問題後,轉頭一想,個人博客項目Fame中也有一樣的問題(雖然訪問量根本徹底不須要考慮併發問題...),那我就拿這個來舉例好了。mysql
業務還原
首先環境是:Spring Boot 2.1.0 + data-jpa + mysql + lombokgit
數據庫設計
對於一個有評論功能的博客系統來講,一般會有兩個表:1.文章表 2.評論表。其中文章表除了保存一些文章信息等,還有個字段保存評論數量。咱們設計一個最精簡的表結構來還原該業務場景。github
article 文章表web
| 字段 | 類型 | 備註 |
|---|---|---|
| id | INT | 自增主鍵id |
| title | VARCHAR | 文章標題 |
| comment_count | INT | 文章的評論數量 |
comment 評論表算法
| 字段 | 類型 | 備註 |
|---|---|---|
| id | INT | 自增主鍵id |
| article_id | INT | 評論的文章id |
| content | VARCHAR | 評論內容 |
當一個用戶評論的時候,1. 根據文章id獲取到文章 2. 插入一條評論記錄 3. 該文章的評論數增長並保存spring
代碼實現
首先在maven中引入對應的依賴sql
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
複製代碼
而後編寫對應數據庫的實體類數據庫
@Data
@Entity
public class Article {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private Long commentCount;
}
複製代碼
@Data
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long articleId;
private String content;
}
複製代碼
接着建立這兩個實體類對應的Repository,因爲spring-jpa-data的CrudRepository已經幫咱們實現了最多見的CRUD操做,因此咱們的Repository只須要繼承CrudRepository接口其餘啥都不用作。服務器
public interface ArticleRepository extends CrudRepository<Article, Long> {
}
複製代碼
public interface CommentRepository extends CrudRepository<Comment, Long> {
}
複製代碼
接着咱們就簡單的實現一下Controller接口和Service實現類。
@Slf4j
@RestController
public class CommentController {
@Autowired
private CommentService commentService;
@PostMapping("comment")
public String comment(Long articleId, String content) {
try {
commentService.postComment(articleId, content);
} catch (Exception e) {
log.error("{}", e);
return "error: " + e.getMessage();
}
return "success";
}
}
複製代碼
@Slf4j
@Service
public class CommentService {
@Autowired
private ArticleRepository articleRepository;
@Autowired
private CommentRepository commentRepository;
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
if (!articleOptional.isPresent()) {
throw new RuntimeException("沒有對應的文章");
}
Article article = articleOptional.get();
Comment comment = new Comment();
comment.setArticleId(articleId);
comment.setContent(content);
commentRepository.save(comment);
article.setCommentCount(article.getCommentCount() + 1);
articleRepository.save(article);
}
}
複製代碼
併發問題分析
從剛纔的代碼實現裏能夠看出這個簡單的評論功能的流程,當用戶發起評論的請求時,從數據庫找出對應的文章的實體類Article,而後根據文章信息生成對應的評論實體類Comment,而且插入到數據庫中,接着增長該文章的評論數量,再把修改後的文章更新到數據庫中,整個流程以下流程圖。
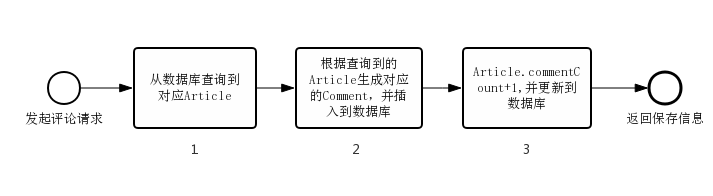
在這個流程中有個問題,當有多個用戶同時併發評論時,他們同時進入步驟1中拿到Article,而後插入對應的Comment,最後在步驟3中更新評論數量保存到數據庫。只是因爲他們是同時在步驟1拿到的Article,因此他們的Article.commentCount的值相同,那麼在步驟3中保存的Article.commentCount+1也相同,那麼原來應該+3的評論數量,只加了1。
咱們用測試用例代碼試一下
@RunWith(SpringRunner.class)
@SpringBootTest(classes = LockAndTransactionApplication.class, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class CommentControllerTests {
@Autowired
private TestRestTemplate testRestTemplate;
@Test
public void concurrentComment() {
String url = "http://localhost:9090/comment";
for (int i = 0; i < 100; i++) {
int finalI = i;
new Thread(() -> {
MultiValueMap<String, String> params = new LinkedMultiValueMap<>();
params.add("articleId", "1");
params.add("content", "測試內容" + finalI);
String result = testRestTemplate.postForObject(url, params, String.class);
}).start();
}
}
}
複製代碼
這裏咱們開了100個線程,同時發送評論請求,對應的文章id爲1。
在發送請求前,數據庫數據爲
select * from article
複製代碼

select count(*) comment_count from comment
複製代碼
發送請求後,數據庫數據爲
select * from article
複製代碼
select count(*) comment_count from comment
複製代碼
明顯的看到在article表裏的comment_count的值不是100,這個值不必定是我圖裏的14,可是必然是不大於100的,而comment表的數量確定等於100。
這就展現了在文章開頭裏提到的併發問題,這種問題其實十分的常見,只要有相似上面這樣評論功能的流程的系統,都要當心避免出現這種問題。
下面就用實例展現展現如何經過悲觀鎖和樂觀鎖防止出現併發數據問題,同時給出SQL方案和JPA自帶方案,SQL方案能夠通用「任何系統」,甚至不限語言,而JPA方案十分快捷,若是你剛好用的也是JPA,那就能夠簡單的使用上樂觀鎖或悲觀鎖。最後也會根據業務比較一下樂觀鎖和悲觀鎖的一些區別
悲觀鎖解決併發問題
悲觀鎖顧名思義就是悲觀的認爲本身操做的數據都會被其餘線程操做,因此就必須本身獨佔這個數據,能夠理解爲」獨佔鎖「。在java中synchronized和ReentrantLock等鎖就是悲觀鎖,數據庫中表鎖、行鎖、讀寫鎖等也是悲觀鎖。
利用SQL解決併發問題
行鎖就是操做數據的時候把這一行數據鎖住,其餘線程想要讀寫必須等待,但同一個表的其餘數據仍是能被其餘線程操做的。只要在須要查詢的sql後面加上for update,就能鎖住查詢的行,特別要注意查詢條件必需要是索引列,若是不是索引就會變成表鎖,把整個表都鎖住。
如今在原有的代碼的基礎上修改一下,先在ArticleRepository增長一個手動寫sql查詢方法。
public interface ArticleRepository extends CrudRepository<Article, Long> {
@Query(value = "select * from article a where a.id = :id for update", nativeQuery = true)
Optional<Article> findArticleForUpdate(Long id);
}
複製代碼
而後把CommentService中使用的查詢方法由原來的findById改成咱們自定義的方法
public class CommentService {
...
public void postComment(Long articleId, String content) {
// Optional<Article> articleOptional = articleRepository.findById(articleId);
Optional<Article> articleOptional = articleRepository.findArticleForUpdate(articleId);
...
}
}
複製代碼
這樣咱們查出來的Article,在咱們沒有將其提交事務以前,其餘線程是不能獲取修改的,保證了同時只有一個線程能操做對應數據。
如今再用測試用例測一下,article.comment_count的值一定是100。
利用JPA自帶行鎖解決併發問題
對於剛纔提到的在sql後面增長for update,JPA有提供一個更優雅的方式,就是@Lock註解,這個註解的參數能夠傳入想要的鎖級別。
如今在ArticleRepository中增長JPA的鎖方法,其中LockModeType.PESSIMISTIC_WRITE參數就是行鎖。
public interface ArticleRepository extends CrudRepository<Article, Long> {
...
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select a from Article a where a.id = :id")
Optional<Article> findArticleWithPessimisticLock(Long id);
}
複製代碼
一樣的只要在CommentService裏把查詢方法改成findArticleWithPessimisticLock(),再測試用例測一下,確定不會有併發問題。並且這時看一下控制檯打印信息,發現實際上查詢的sql仍是加了for update,只不過是JPA幫咱們加了而已。
樂觀鎖解決併發問題
樂觀鎖顧名思義就是特別樂觀,認爲本身拿到的資源不會被其餘線程操做因此不上鎖,只是在插入數據庫的時候再判斷一下數據有沒有被修改。因此悲觀鎖是限制其餘線程,而樂觀鎖是限制本身,雖然他的名字有鎖,可是實際上不算上鎖,只是在最後操做的時候再判斷具體怎麼操做。
樂觀鎖一般爲版本號機制或者CAS算法
利用SQL實現版本號解決併發問題
版本號機制就是在數據庫中加一個字段看成版本號,好比咱們加個字段version。那麼這時候拿到Article的時候就會帶一個版本號,好比拿到的版本是1,而後你對這個Article一通操做,操做完以後要插入到數據庫了。發現哎呀,怎麼數據庫裏的Article版本是2,和我手裏的版本不同啊,說明我手裏的Article不是最新的了,那麼就不能放到數據庫了。這樣就避免了併發時數據衝突的問題。
因此咱們如今給article表加一個字段version
article 文章表
| 字段 | 類型 | 備註 |
|---|---|---|
| version | INT DEFAULT 0 | 版本號 |
而後對應的實體類也增長version字段
@Data
@Entity
public class Article {
...
private Long version;
}
複製代碼
接着在ArticleRepository增長更新的方法,注意這裏是更新方法,和悲觀鎖時增長查詢方法不一樣。
public interface ArticleRepository extends CrudRepository<Article, Long> {
@Modifying
@Query(value = "update article set comment_count = :commentCount, version = version + 1 where id = :id and version = :version", nativeQuery = true)
int updateArticleWithVersion(Long id, Long commentCount, Long version);
}
複製代碼
能夠看到update的where有一個判斷version的條件,而且會set version = version + 1。這就保證了只有當數據庫裏的版本號和要更新的實體類的版本號相同的時候纔會更新數據。
接着在CommentService裏稍微修改一下代碼。
// CommentService
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
...
int count = articleRepository.updateArticleWithVersion(article.getId(), article.getCommentCount() + 1, article.getVersion());
if (count == 0) {
throw new RuntimeException("服務器繁忙,更新數據失敗");
}
// articleRepository.save(article);
}
複製代碼
首先對於Article的查詢方法只須要普通的findById()方法就行不用上任何鎖。
而後更新Article的時候改用新加的updateArticleWithVersion()方法。能夠看到這個方法有個返回值,這個返回值表明更新了的數據庫行數,若是值爲0的時候表示沒有符合條件能夠更新的行。
這以後就能夠由咱們本身決定怎麼處理了,這裏是直接回滾,spring就會幫咱們回滾以前的數據操做,把此次的全部操做都取消以保證數據的一致性。
如今再用測試用例測一下
select * from article
複製代碼
select count(*) comment_count from comment
複製代碼
如今看到Article裏的comment_count和Comment的數量都不是100了,可是這兩個的值一定是同樣的了。由於剛纔咱們處理的時候假如Article表的數據發生了衝突,那麼就不會更新到數據庫裏,這時拋出異常使其事務回滾,這樣就能保證沒有更新Article的時候Comment也不會插入,就解決了數據不統一的問題。
這種直接回滾的處理方式用戶體驗比較差,一般來講若是判斷Article更新條數爲0時,會嘗試從新從數據庫裏查詢信息並從新修改,再次嘗試更新數據,若是不行就再查詢,直到可以更新爲止。固然也不會是無線的循環這樣的操做,會設置一個上線,好比循環3次查詢修改更新都不行,這時候纔會拋出異常。
利用JPA實現版本現解決併發問題
JPA對悲觀鎖有實現方式,樂觀鎖天然也是有的,如今就用JPA自帶的方法實現樂觀鎖。
首先在Article實體類的version字段上加上@Version註解,咱們進註解看一下源碼的註釋,能夠看到有部分寫到:
The following types are supported for version properties: int, Integer, short, Short, long, Long, java.sql.Timestamp.
註釋裏面說版本號的類型支持int, short, long三種基本數據類型和他們的包裝類以及Timestamp,咱們如今用的是Long類型。
@Data
@Entity
public class Article {
...
@Version
private Long version;
}
複製代碼
接着只須要在CommentService裏的評論流程修改回咱們最開頭的「會觸發併發問題」的業務代碼就好了。說明JPA的這種樂觀鎖實現方式是非侵入式的。
// CommentService
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
...
article.setCommentCount(article.getCommentCount() + 1);
articleRepository.save(article);
}
複製代碼
和前面一樣的,用測試用例測試一下可否防止併發問題的出現。
select * from article
複製代碼
select count(*) comment_count from comment
複製代碼
一樣的Article裏的comment_count和Comment的數量也不是100,可是這兩個數值確定是同樣的。看一下IDEA的控制檯會發現系統拋出了ObjectOptimisticLockingFailureException的異常。
這和剛纔咱們本身實現樂觀鎖相似,若是沒有成功更新數據則拋出異常回滾保證數據的一致性。若是想要實現重試流程能夠捕獲ObjectOptimisticLockingFailureException這個異常,一般會利用AOP+自定義註解來實現一個全局通用的重試機制,這裏就是要根據具體的業務狀況來拓展了,想要了解的能夠自行搜索一下方案。
悲觀鎖和樂觀鎖比較
悲觀鎖適合寫多讀少的場景。由於在使用的時候該線程會獨佔這個資源,在本文的例子來講就是某個id的文章,若是有大量的評論操做的時候,就適合用悲觀鎖,不然用戶只是瀏覽文章而沒什麼評論的話,用悲觀鎖就會常常加鎖,增長了加鎖解鎖的資源消耗。
樂觀鎖適合寫少讀多的場景。因爲樂觀鎖在發生衝突的時候會回滾或者重試,若是寫的請求量很大的話,就常常發生衝突,常常的回滾和重試,這樣對系統資源消耗也是很是大。
因此悲觀鎖和樂觀鎖沒有絕對的好壞,必須結合具體的業務狀況來決定使用哪種方式。另外在阿里巴巴開發手冊裏也有提到:
若是每次訪問衝突機率小於 20%,推薦使用樂觀鎖,不然使用悲觀鎖。樂觀鎖的重試次 數不得小於 3 次。
阿里巴巴建議以衝突機率20%這個數值做爲分界線來決定使用樂觀鎖和悲觀鎖,雖說這個數值不是絕對的,可是做爲阿里巴巴各個大佬總結出來的也是一個很好的參考。
- 1. 悲觀鎖和樂觀鎖
- 2. 樂觀鎖和悲觀鎖
- 3. 悲觀鎖 和 樂觀鎖
- 更多相關文章...
- • Hibernate悲觀鎖 - Hibernate教程
- • Hibernate樂觀鎖 - Hibernate教程
- • 漫談MySQL的鎖機制
- • Spring Cloud 微服務實戰(三) - 服務註冊與發現
-
每一个你不满意的现在,都有一个你没有努力的曾经。