2019第九周做業
| 這個做業屬於哪一個課程 | C語言程序設計 |
| 這個做業的要求在哪裏 | https://edu.cnblogs.com/campus/zswxy/software-engineering-class2-2018/homework/3124 |
| 我在這個課程的目標是 | 可以根據實際狀況合理定義結構,可以使用結構變量與結構數組進行熟練編程。 |
| 這個做業在哪一個具體方面幫助我實現目標 | 能熟練進行結構變量的定義和初始化,熟練運用結構變量解決問題 |
| 參考文獻 | C語言程序設計 |
一.基礎題
6-1 按等級統計學生成績 (20 分)
本題要求實現一個根據學生成績設置其等級,並統計不及格人數的簡單函數。
函數接口定義:算法
int set_grade( struct student *p, int n );
其中p是指向學生信息的結構體數組的指針,該結構體的定義爲:編程
struct student{
int num;
char name[20];
int score;
char grade;
};
n是數組元素個數。學號num、姓名name和成績score均是已經存儲好的。set_grade函數須要根據學生的成績score設置其等級grade。等級設置:85-100爲A,70-84爲B,60-69爲C,0-59爲D。同時,set_grade還須要返回不及格的人數。
裁判測試程序樣例:數組
#include <stdio.h>
#define MAXN 10
struct student{
int num;
char name[20];
int score;
char grade;
};
int set_grade( struct student *p, int n );
int main()
{ struct student stu[MAXN], *ptr;
int n, i, count;
ptr = stu;
scanf("%d\n", &n);
for(i = 0; i < n; i++){
scanf("%d%s%d", &stu[i].num, stu[i].name, &stu[i].score);
}
count = set_grade(ptr, n);
printf("The count for failed (<60): %d\n", count);
printf("The grades:\n");
for(i = 0; i < n; i++)
printf("%d %s %c\n", stu[i].num, stu[i].name, stu[i].grade);
return 0;
}
/* 你的代碼將被嵌在這裏 */
輸入樣例:app
10 31001 annie 85 31002 bonny 75 31003 carol 70 31004 dan 84 31005 susan 90 31006 paul 69 31007 pam 60 31008 apple 50 31009 nancy 100 31010 bob 78
輸出樣例:函數
The count for failed (<60): 1 The grades: 31001 annie A 31002 bonny B 31003 carol B 31004 dan B 31005 susan A 31006 paul C 31007 pam C 31008 apple D 31009 nancy A 31010 bob B
1)運行代碼
int set_grade( struct student *p, int n )
{
int h=0,i;
for(i=0;i<n;i++,p++){
if(p->score>=85&&p->score<=100){
p->grade='A';
}
else if(p->score>=70&&p->score<=84){
p->grade='B';
}
else if(p->score>=60&&p->score<=69){
p->grade='C';
}
else if(p->score>=0&&p->score<=59){
p->grade='D';
h++;
}
}
return h;
}
###2)設計思路
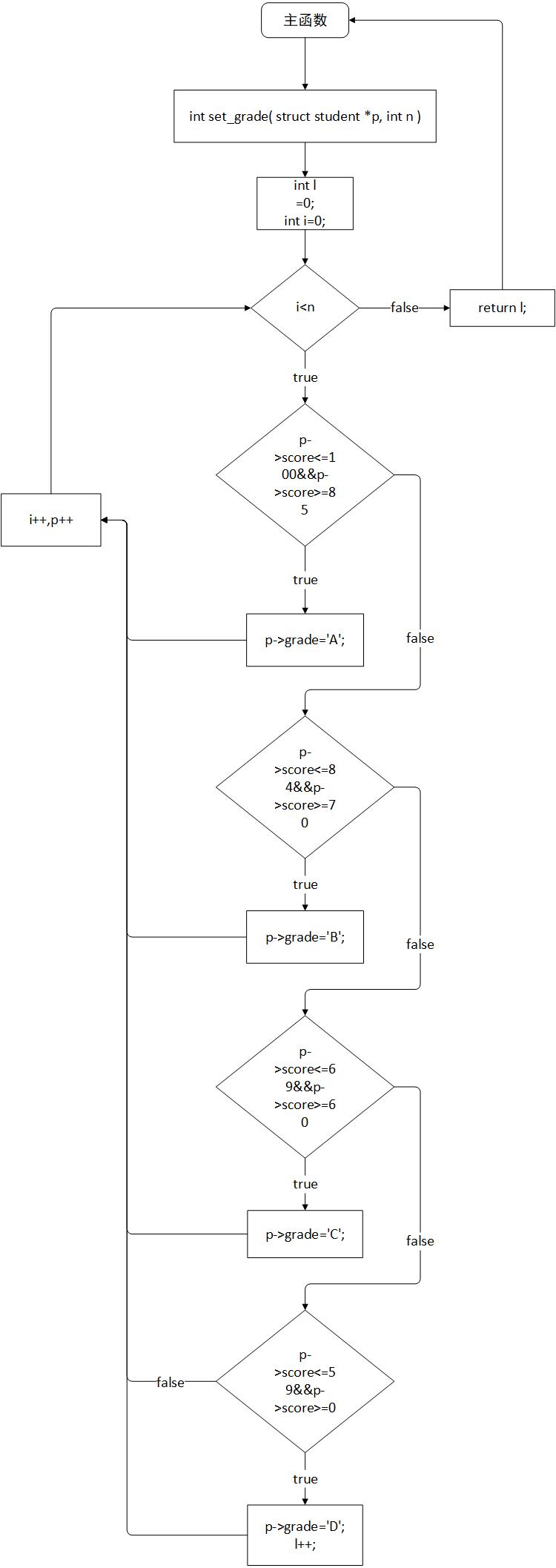
###3)本題調試過稱中遇到的問題及解決辦法
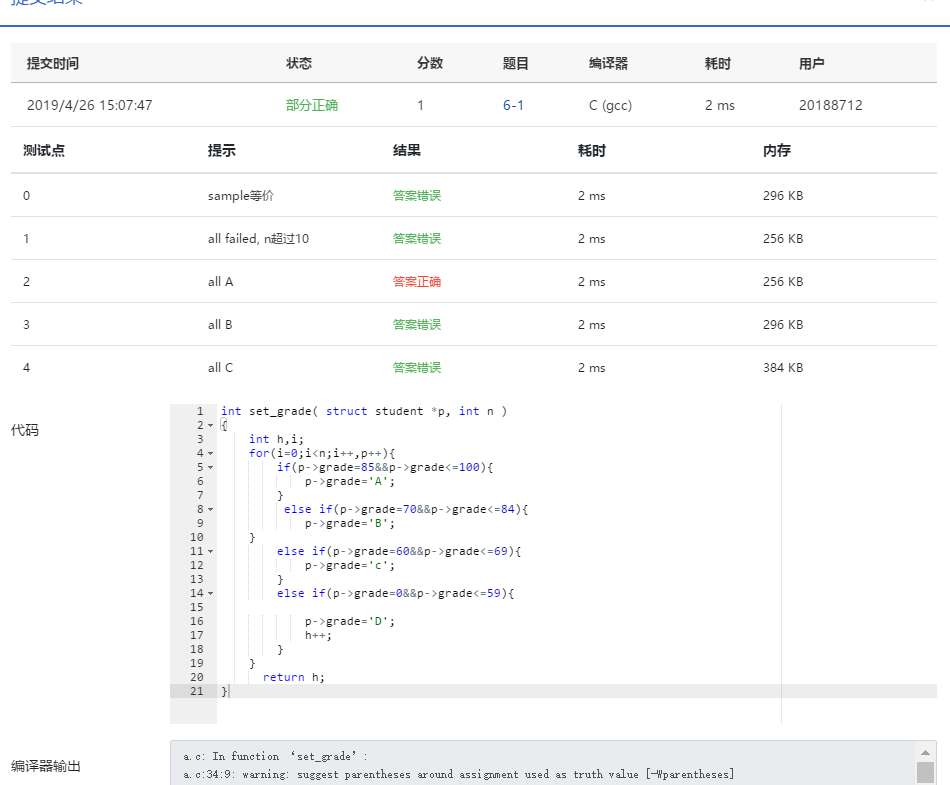
忘記給L初始化爲零了,致使本身檢查了不少遍都沒發現錯誤。
###4)運行截圖
##7-1 一幫一 (15 分)
「一幫一學習小組」是中小學中常見的學習組織方式,老師把學習成績靠前的學生跟學習成績靠後的學生排在一組。本題就請你編寫程序幫助老師自動完成這個分配工做,即在獲得全班學生的排名後,在當前還沒有分組的學生中,將名次最靠前的學生與名次最靠後的異性學生分爲一組。
輸入格式:
輸入第一行給出正偶數N(≤50),即全班學生的人數。此後N行,按照名次從高到低的順序給出每一個學生的性別(0表明女生,1表明男生)和姓名(不超過8個英文字母的非空字符串),其間以1個空格分隔。這裏保證本班男女比例是1:1,而且沒有並列名次。
輸出格式:
每行輸出一組兩個學生的姓名,其間以1個空格分隔。名次高的學生在前,名次低的學生在後。小組的輸出順序按照前面學生的名次從高到低排列。
輸入樣例:
8
0 Amy
1 Tom
1 Bill
0 Cindy
0 Maya
1 John
1 Jack
0 Linda性能
輸出樣例:
Amy Jack
Tom Linda
Bill Maya
Cindy John學習
###1)實驗代碼
include<stdio.h>
include<string.h>
struct student{
int x;
char name[10];
};
struct zy{
char names[10];
char named[10];
};測試
int main()
{
struct student a[50];
struct zy b[50];
int n,i;
scanf("%d",&n);
for(i=0;i<n;i++){
scanf("%d %s",&a[i].x,a[i].name);
}
for(i=0;i<n/2;i++){
strcpy(b[i].names,a[i].name);
}
//再從全班後一半,從最後一位開始循環和第一位組員比較性別
for(int i=0;i<n/2;i++){
for(int j=n-1;j>=n/2;j--){
//若性別不一樣,且沒有和別的組員匹配
if(a[i].x!=a[j].x&&a[j].x!=5){
//將姓名儲存在第二位組員
strcpy(b[i].named,a[j].name);
//若已經匹配了,則改變性別
a[j].x=5;
//匹配完後,跳出內循環,以避免又和下一位異性匹配
break;
}
}
}
for(int i=0;i<n/2;i++){
printf("%s %s\n",b[i].names,b[i].named);
}
}設計
###2)設計思路 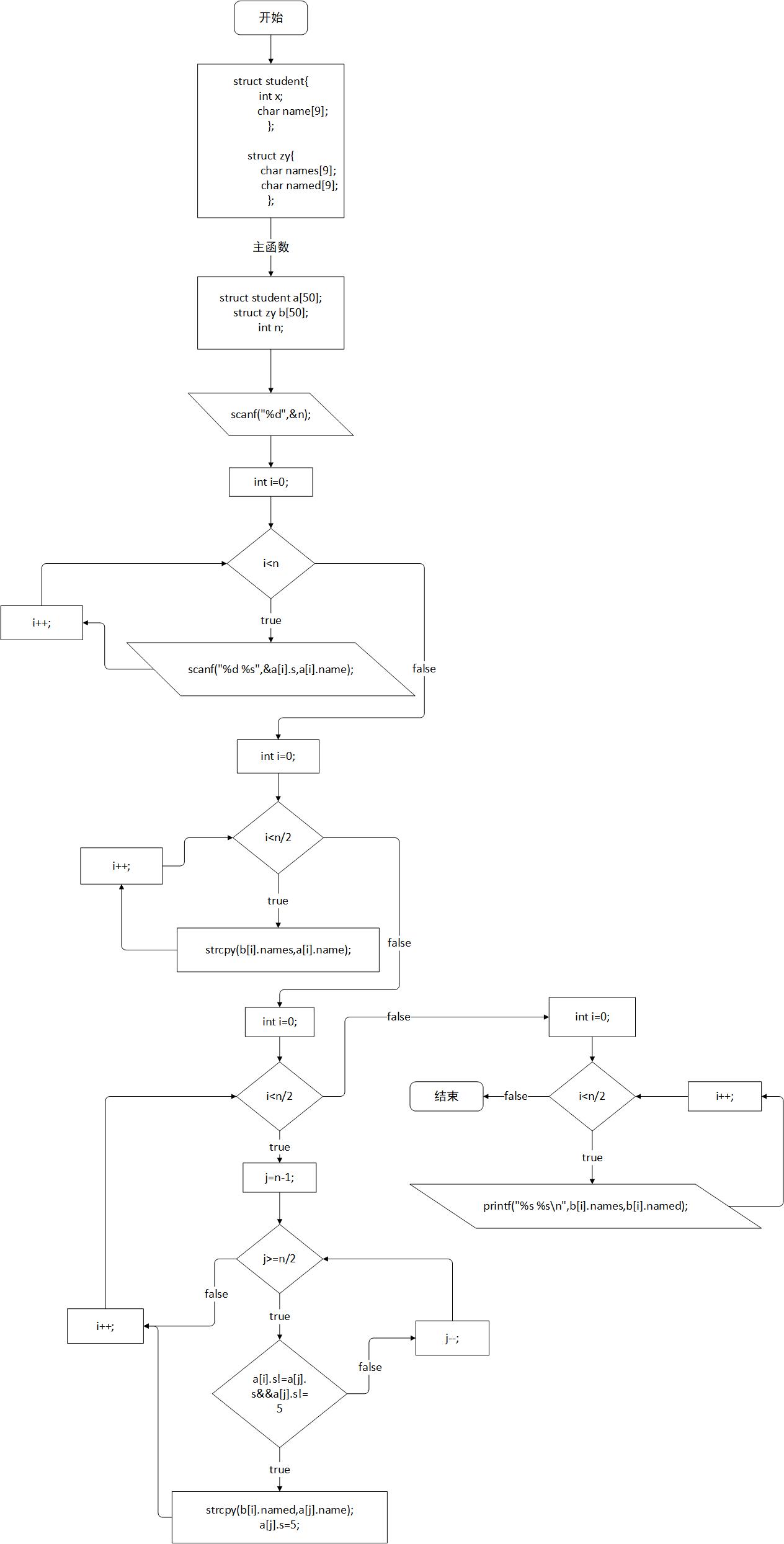 ###3)本題調試過稱中遇到的問題及解決辦法 這題好難剛開始看題感受好複雜,不知道怎樣區分已經匹配的和沒匹配的,所以詢問了下同伴, ###4)運行截圖 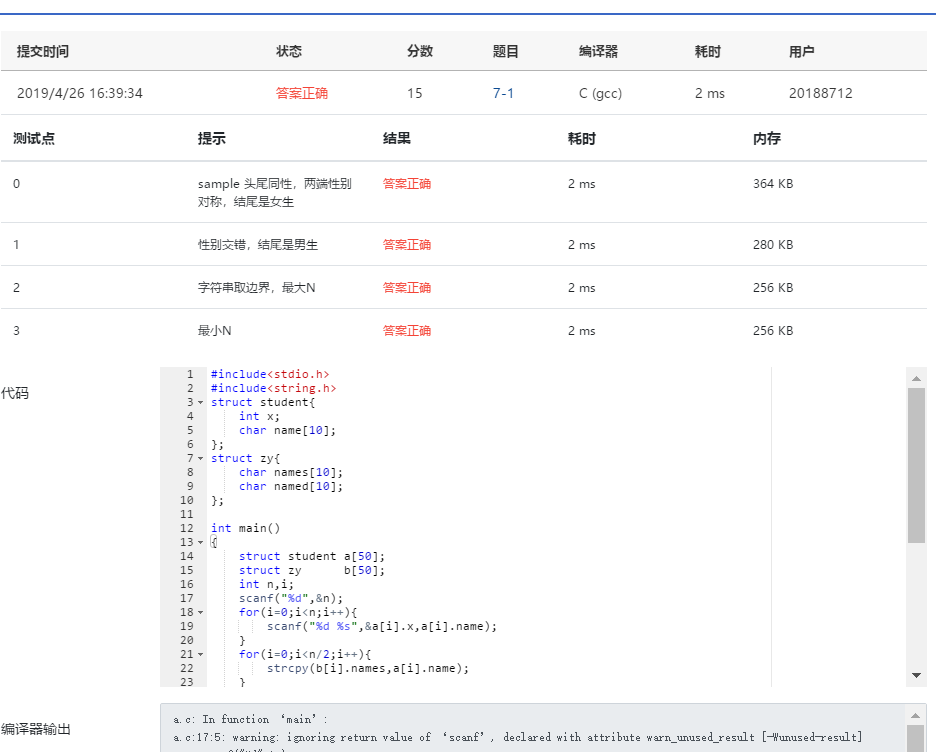 ##7-2 考試座位號 (15 分) 每一個 PAT 考生在參加考試時都會被分配兩個座位號,一個是試機座位,一個是考試座位。正常狀況下,考生在入場時先獲得試機座位號碼,入座進入試機狀態後,系統會顯示該考生的考試座位號碼,考試時考生須要換到考試座位就座。但有些考生遲到了,試機已經結束,他們只能拿着領到的試機座位號碼求助於你,從後臺查出他們的考試座位號碼。 輸入格式: 輸入第一行給出一個正整數 N(≤1000),隨後 N 行,每行給出一個考生的信息:准考證號 試機座位號 考試座位號。其中准考證號由 16 位數字組成,座位從 1 到 N 編號。輸入保證每一個人的准考證號都不一樣,而且任什麼時候候都不會把兩我的分配到同一個座位上。 考生信息以後,給出一個正整數 M(≤N),隨後一行中給出 M 個待查詢的試機座位號碼,以空格分隔。 輸出格式: 對應每一個須要查詢的試機座位號碼,在一行中輸出對應考生的准考證號和考試座位號碼,中間用 1 個空格分隔。 輸入樣例:
4
3310120150912233 2 4
3310120150912119 4 1
3310120150912126 1 3
3310120150912002 3 2
2
3 4指針
輸出樣例:
3310120150912002 2
3310120150912119 1
###1)實驗代碼
include<stdio.h>
define MAXN 1000
struct student{
char xh[20];
int a;
int k;
};
int main()
{
struct student b[MAXN];
int n,m,x[MAXN],i;
scanf("%d",&n);
for(int i=0;i<n;i++){
scanf("%s %d %d",b[i].xh,&b[i].a,&b[i].k);
}
scanf("%d",&m);
for(i=0;i<m;i++){
scanf("%d",&x[i]);
}
//查詢
for(i=0;i<m;i++){
for(int j=0;j<n;j++){
if(x[i]==b[j].a){
printf("%s %d\n",b[j].xh,b[j].k);
break;
}
}
}
}
2)設計思路

3)本題調試過稱中遇到的問題及解決辦法
本身忽視了字符串會以‘/0‘結尾所以第一次寫的時候定義數組char【16】.
4)運行截圖
二.預習題
1.什麼是遞歸函數?
遞歸函數是有條件終止的死循環函數,能夠把它理解成是for循環與死循環的結合的函數。
優勢:代碼簡潔,好理解
缺點:1.遞歸因爲是函數調用自身,而函數調用是有時間和空間的消耗的:每一次函數調用,都須要在內存棧中分配空間以保存參數、返回地址以及臨時變量,而往棧中壓入數據和彈出數據都須要時間。->效率
2.遞歸中不少計算都是重複的,因爲其本質是把一個問題分解成兩個或者多個小問題,多個小問題存在相互重疊的部分,則存在重複計算,如fibonacci斐波那契數列的遞歸實現。->效率
3.調用棧可能會溢出,其實每一次函數調用會在內存棧中分配空間,而每一個進程的棧的容量是有限的,當調用的層次太多時,就會超出棧的容量,從而致使棧溢出。->性能
3.如何概括出遞歸式?
(一)代換法:
實質上就是數學概括法,先對一個小的值作假設,而後推測更大的值得正確性。因爲是數學概括法,那麼咱們就須要對值進行猜想。如今,咱們看下面這個例子:
咱們先假設一個結論T(n) = O(lg(n - b)),而且假設對T(n / 2上取整)成立(這就是數學概括法了),那麼把T(n / 2上取整)用假設的結論進行代換,咱們有T(n) <= lg((n - b)) / 2上取整)
<= lg((n - b) / 2 + 1) + 1 = lg(n - b + 2),對於任意的b >= 2,即知足要求T(n) <= lg(n) = O(lgn)。證畢。
這是一個很簡單的例子,可是其中有些事情仍是要交代的。
一個是結論的猜想不是一個容易的事情。另外一個是在上面的例子中我沒有直接下結論說T(n) = O(lg(n)),而是減去了一個常數b,這是爲何呢?答案是:we can prove something stronger for a given value by assuming something stronger for smaller values.還有一點值得說明,請看下面這個例子:
這裏出現了sqrt(n),咱們採用變量代換的方法:令n = 2 ^ m,則上式變爲T(2 ^ m) = 2T(2 ^ (m / 2) ),再設S(m) = T(2 ^ m),則獲得S(m) = 2S(m / 2) + 1。咱們先假設S(m) = m - b <= O(m),且對S(m / 2)成立,那麼S(m) = 2 * (m - b) / 2 + 1 = m - b + 1,對於任意的b >= 1都有S(m) = O(m),而後回代有T(n) = T( 2 ^ m) = S(m) = O(m) = O(lgn)。
這裏咱們採用了變量代換的方法。若是假設時,感受變量不明朗,那麼這是一種頗有效的方法。
(二)遞歸樹方法:
利用遞歸樹方法求算法複雜度我想最好的例子就是歸併排序了,這裏我不想拿歸併排序作例子,而只是用書中一些更簡單形象的例子來講明:
根據上式咱們創建遞歸式T(n) = 3T(n / 4) + cn^2,這裏咱們拋去上下界函數的影響(sloppiness that we can tolerate),而且把Theta(n ^ 2)用cn^2代替。下面創建遞歸樹模型:
在遞歸樹中,每個結點都表明一個子代價,每層的代價是該層全部子代價的總和,總問題的代價就是全部層的代價總和。
因此,咱們利用遞歸樹求解代價,須要知道什麼呢,一個是每一層的代價,一個是層數,就是這兩個。
這些,都須要咱們用覺察的態度來發現,而事實證實,這不是一件難事,不少狀況下是有規律可循的。
咱們且看上面這個例子,遞歸樹的構造很簡單,當遞歸調用到邊界是,就達到了常量T(1),達到常量T(1)所用到的遞歸次數就是整個遞歸樹的深度,咱們從圖中能夠獲得第i層的結點的代價爲n / ( 4 ^ i ),當n / (4 ^ i) = 1即i = log4(n)時,遞歸到達了邊界,因此,整個遞歸樹的深度就是i = log4(n)。咱們要求的總的代價是全部的總和,結果爲O(n ^ 2)。計算過程我就再也不累述了。可是,遞歸樹並非都是這樣的滿的樹,也就是否是每一層的結點都是相同的結構,因此咱們在構造遞歸樹的時候要仔細看好這一點,才能保證在計算時不會出錯。
(三)主方法:
其實應該叫作主定理方法,利用這個方法,咱們只須要記住主定理的三種狀況,而且在知足必定的條件下,就能夠速度解出遞歸式。主定理的三種狀況不在這裏給出,必定條件我只說一下我對於多項式大於(或小於)的理解,好比x和1.1x,那麼x就是多項式小於1.1x,兩者差了一個多項式(0.1x),而至於x與xlgx就不存在多項式大於(或小於)的關係。
三.預習的主要內容。
1.遞歸函數基本概念。
四.學習進度條
| 周/日期 | 這周所花的時間 | 代碼行 | 學到的知識點簡介 | 目前比較迷惑的問題 |
|---|---|---|---|---|
| 2/25-3/3 | 5h | 39 | 一維數組的定義和引用及初始化 | 字符數組和整型數組的區別 |
| 3/4-3/10 | 5h | 47 | 文件的讀取、寫入, 處理和開關;文件的打開方. | 文件的分類,什麼是二進制文件;字符數組的讀取和寫入 |
| 3/11-3/17 | 6h | 57 | 二維數組的定義及應用 | 二維數組的行和列的嵌套循環輸入和輸出 |
| 3/18-3/24 | 3h | 33 | 選擇排序法、冒泡排序法和二分查找法 | 不清楚選擇排序法和冒泡排序法的區別 |
| 3/25-3/31 | 10h | 40 | 字符數組和字符串的區別,字符串的輸入輸出方式和格式,二維數組更高級的運用。 | 不清楚指針在程序中的做用與使用 |
| 4/1-4/7 | 6h | 50 | 變量、內存單元和地址之間的關係;指針變量的定義及初始化,指針變量的基本運算,指針、數組和地址間的關係 | 冒泡排序法不太明白 |
| 4/8-4/14 | 12h | 99 | 掌握數組名做爲函數參數的用法,理解指針、數組和地址之間的關係,理解指針和數組能夠實現相同的操做 | 作基礎題第二題時發現之前的知識不少都忘記了 |
| 4/15-4/21 | 12h | 132 | 掌握經常使用字符串函數以及使用指針操做字符串的方法,理解動態內存分配 | 各個動態內存分配函數的區別仍是不太清楚 |
| 4/22-4/28 | 12h | 135 | 合理定義結構,使用結構變量與結構數組編程,掌握結構指針的操做,並應用於函數傳遞 | 解遞歸式的三種方法不懂 |
五.學習感悟
這周題目的第一題和最後一題還好就是第二題很難,第二題的困難讓我發覺了問同窗的重要性和查資料的重要性。
六.結對編程感想
過程:此次我在第二題上遇到了很大的阻礙感謝同伴的幫忙。
感想:結隊編程真的對咱們有很大的幫助啊,假若不是同伴幫忙我應該作不出來的。
七.表格和折線圖
| 時間 | 代碼行數 | 博客字數 |
|---|---|---|
| 第一週 | 39 | 400 |
| 第二週 | 47 | 500 |
| 第三週 | 57 | 550 |
| 第四周 | 98 | 600 |
| 第五週 | 88 | 700 |
| 第六週 | 70 | 800 |
| 第七週 | 99 | 900 |
| 第八週 | 150 | 1500 |
| 第九周 | 120 | 2500 |
|
- 1. 2019春第九周做業
- 2. 2019 第九周做業
- 3. 2019春季第九周做業
- 4. 第九周做業
- 5. linux第九周做業
- 6. [python做業] [第九周]
- 7. 2019春第八週做業
- 8. 2019春第六週做業
- 9. 2019春第四周做業
- 10. 2019 第八週做業
- 更多相關文章...
- • Rust 生命週期 - RUST 教程
- • SVN 生命週期 - SVN 教程
- • 使用Rxjava計算圓周率
- • RxJava操作符(九)Connectable Observable Operators
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 2019春第九周做業
- 2. 2019 第九周做業
- 3. 2019春季第九周做業
- 4. 第九周做業
- 5. linux第九周做業
- 6. [python做業] [第九周]
- 7. 2019春第八週做業
- 8. 2019春第六週做業
- 9. 2019春第四周做業
- 10. 2019 第八週做業