Spark 系列(五)—— Spark 運行模式與做業提交
1、做業提交
1.1 spark-submit
Spark 全部模式均使用 spark-submit 命令提交做業,其格式以下:html
./bin/spark-submit \
--class <main-class> \ # 應用程序主入口類
--master <master-url> \ # 集羣的 Master Url
--deploy-mode <deploy-mode> \ # 部署模式
--conf <key>=<value> \ # 可選配置
... # other options
<application-jar> \ # Jar 包路徑
[application-arguments] #傳遞給主入口類的參數
複製代碼
須要注意的是:在集羣環境下,application-jar 必須能被集羣中全部節點都能訪問,能夠是 HDFS 上的路徑;也能夠是本地文件系統路徑,若是是本地文件系統路徑,則要求集羣中每個機器節點上的相同路徑都存在該 Jar 包。java
1.2 deploy-mode
deploy-mode 有 cluster 和 client 兩個可選參數,默認爲 client。這裏以 Spark On Yarn 模式對二者進行說明 :git
- 在 cluster 模式下,Spark Drvier 在應用程序的 Master 進程內運行,該進程由羣集上的 YARN 管理,提交做業的客戶端能夠在啓動應用程序後關閉;
- 在 client 模式下,Spark Drvier 在提交做業的客戶端進程中運行,Master 進程僅用於從 YARN 請求資源。
1.3 master-url
master-url 的全部可選參數以下表所示:github
| Master URL | Meaning |
|---|---|
local |
使用一個線程本地運行 Spark |
local[K] |
使用 K 個 worker 線程本地運行 Spark |
local[K,F] |
使用 K 個 worker 線程本地運行 , 第二個參數爲 Task 的失敗重試次數 |
local[*] |
使用與 CPU 核心數同樣的線程數在本地運行 Spark |
local[*,F] |
使用與 CPU 核心數同樣的線程數在本地運行 Spark 第二個參數爲 Task 的失敗重試次數 |
spark://HOST:PORT |
鏈接至指定的 standalone 集羣的 master 節點。端口號默認是 7077。 |
spark://HOST1:PORT1,HOST2:PORT2 |
若是 standalone 集羣採用 Zookeeper 實現高可用,則必須包含由 zookeeper 設置的全部 master 主機地址。 |
mesos://HOST:PORT |
鏈接至給定的 Mesos 集羣。端口默認是 5050。對於使用了 ZooKeeper 的 Mesos cluster 來講,使用 mesos://zk://... 來指定地址,使用 --deploy-mode cluster 模式來提交。 |
yarn |
鏈接至一個 YARN 集羣,集羣由配置的 HADOOP_CONF_DIR 或者 YARN_CONF_DIR 來決定。使用 --deploy-mode 參數來配置 client 或 cluster 模式。 |
下面主要介紹三種經常使用部署模式及對應的做業提交方式。web
2、Local模式
Local 模式下提交做業最爲簡單,不須要進行任何配置,提交命令以下:shell
# 本地模式提交應用
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100 # 傳給 SparkPi 的參數
複製代碼
spark-examples_2.11-2.4.0.jar 是 Spark 提供的測試用例包,SparkPi 用於計算 Pi 值,執行結果以下:apache

3、Standalone模式
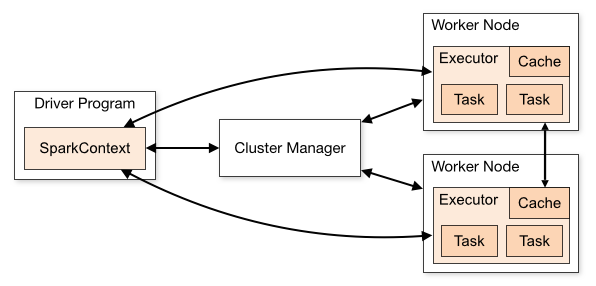
Standalone 是 Spark 提供的一種內置的集羣模式,採用內置的資源管理器進行管理。下面按照如圖所示演示 1 個 Mater 和 2 個 Worker 節點的集羣配置,這裏使用兩臺主機進行演示:bash
- hadoop001: 因爲只有兩臺主機,因此 hadoop001 既是 Master 節點,也是 Worker 節點;
- hadoop002 : Worker 節點。
3.1 環境配置
首先須要保證 Spark 已經解壓在兩臺主機的相同路徑上。而後進入 hadoop001 的 ${SPARK_HOME}/conf/ 目錄下,拷貝配置樣本並進行相關配置:app
# cp spark-env.sh.template spark-env.sh
複製代碼
在 spark-env.sh 中配置 JDK 的目錄,完成後將該配置使用 scp 命令分發到 hadoop002 上:dom
# JDK安裝位置
JAVA_HOME=/usr/java/jdk1.8.0_201
複製代碼
3.2 集羣配置
在 ${SPARK_HOME}/conf/ 目錄下,拷貝集羣配置樣本並進行相關配置:
# cp slaves.template slaves
複製代碼
指定全部 Worker 節點的主機名:
# A Spark Worker will be started on each of the machines listed below.
hadoop001
hadoop002
複製代碼
這裏須要注意如下三點:
- 主機名與 IP 地址的映射必須在
/etc/hosts文件中已經配置,不然就直接使用 IP 地址; - 每一個主機名必須獨佔一行;
- Spark 的 Master 主機是經過 SSH 訪問全部的 Worker 節點,因此須要預先配置免密登陸。
3.3 啓動
使用 start-all.sh 表明啓動 Master 和全部 Worker 服務。
./sbin/start-master.sh
複製代碼
訪問 8080 端口,查看 Spark 的 Web-UI 界面,,此時應該顯示有兩個有效的工做節點:
3.4 提交做業
# 以client模式提交到standalone集羣
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077 \
--executor-memory 2G \
--total-executor-cores 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
# 以cluster模式提交到standalone集羣
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \ # 配置此參數表明開啓監督,若是主應用程序異常退出,則自動重啓 Driver
--executor-memory 2G \
--total-executor-cores 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
複製代碼
3.5 可選配置
在虛擬機上提交做業時常常出現一個的問題是做業沒法申請到足夠的資源:
Initial job has not accepted any resources;
check your cluster UI to ensure that workers are registered and have sufficient resources
複製代碼

這時候能夠查看 Web UI,我這裏是內存空間不足:提交命令中要求做業的 executor-memory 是 2G,可是實際的工做節點的 Memory 只有 1G,這時候你能夠修改 --executor-memory,也能夠修改 Woker 的 Memory,其默認值爲主機全部可用內存值減去 1G。

關於 Master 和 Woker 節點的全部可選配置以下,能夠在 spark-env.sh 中進行對應的配置:
| Environment Variable(環境變量) | Meaning(含義) |
|---|---|
SPARK_MASTER_HOST |
master 節點地址 |
SPARK_MASTER_PORT |
master 節點地址端口(默認:7077) |
SPARK_MASTER_WEBUI_PORT |
master 的 web UI 的端口(默認:8080) |
SPARK_MASTER_OPTS |
僅用於 master 的配置屬性,格式是 "-Dx=y"(默認:none),全部屬性能夠參考官方文檔:spark-standalone-mode |
SPARK_LOCAL_DIRS |
spark 的臨時存儲的目錄,用於暫存 map 的輸出和持久化存儲 RDDs。多個目錄用逗號分隔 |
SPARK_WORKER_CORES |
spark worker 節點可使用 CPU Cores 的數量。(默認:所有可用) |
SPARK_WORKER_MEMORY |
spark worker 節點可使用的內存數量(默認:所有的內存減去 1GB); |
SPARK_WORKER_PORT |
spark worker 節點的端口(默認: random(隨機)) |
SPARK_WORKER_WEBUI_PORT |
worker 的 web UI 的 Port(端口)(默認:8081) |
SPARK_WORKER_DIR |
worker 運行應用程序的目錄,這個目錄中包含日誌和暫存空間(default:SPARK_HOME/work) |
SPARK_WORKER_OPTS |
僅用於 worker 的配置屬性,格式是 "-Dx=y"(默認:none)。全部屬性能夠參考官方文檔:spark-standalone-mode |
SPARK_DAEMON_MEMORY |
分配給 spark master 和 worker 守護進程的內存。(默認: 1G) |
SPARK_DAEMON_JAVA_OPTS |
spark master 和 worker 守護進程的 JVM 選項,格式是 "-Dx=y"(默認:none) |
SPARK_PUBLIC_DNS |
spark master 和 worker 的公開 DNS 名稱。(默認:none) |
3、Spark on Yarn模式
Spark 支持將做業提交到 Yarn 上運行,此時不須要啓動 Master 節點,也不須要啓動 Worker 節點。
3.1 配置
在 spark-env.sh 中配置 hadoop 的配置目錄的位置,可使用 YARN_CONF_DIR 或 HADOOP_CONF_DIR 進行指定:
YARN_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# JDK安裝位置
JAVA_HOME=/usr/java/jdk1.8.0_201
複製代碼
3.2 啓動
必需要保證 Hadoop 已經啓動,這裏包括 YARN 和 HDFS 都須要啓動,由於在計算過程當中 Spark 會使用 HDFS 存儲臨時文件,若是 HDFS 沒有啓動,則會拋出異常。
# start-yarn.sh
# start-dfs.sh
複製代碼
3.3 提交應用
# 以client模式提交到yarn集羣
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 2G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
# 以cluster模式提交到yarn集羣
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-memory 2G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
複製代碼
更多大數據系列文章能夠參見 GitHub 開源項目: 大數據入門指南
- 1. Spark 系列(五)—— Spark 運行模式與做業提交
- 2. Spark 做業提交
- 3. 關於spark做業提交:spark運行example爲例
- 4. Spark學習(四) -- Spark做業提交
- 5. spark提交模式
- 6. Spark Yarn 提交做業
- 7. Spark-submit提交做業
- 8. spark 運行模式
- 9. Spark做業提交的方式
- 10. Spark 運行模式與運行流程
- 更多相關文章...
- • SVN 提交操作 - SVN 教程
- • PHP PDO 事務與自動提交 - PHP參考手冊
- • 委託模式
- • Git五分鐘教程
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 安裝cuda+cuDNN
- 2. GitHub的使用說明
- 3. phpDocumentor使用教程【安裝PHPDocumentor】
- 4. yarn run build報錯Component is not found in path 「npm/taro-ui/dist/weapp/components/rate/index「
- 5. 精講Haproxy搭建Web集羣
- 6. 安全測試基礎之MySQL
- 7. C/C++編程筆記:C語言中的複雜聲明分析,用實例帶你完全讀懂
- 8. Python3教程(1)----搭建Python環境
- 9. 李宏毅機器學習課程筆記2:Classification、Logistic Regression、Brief Introduction of Deep Learning
- 10. 阿里雲ECS配置速記