網易互娛的數據庫選型和 TiDB 應用實踐
做者介紹:李文傑,網易互娛計費組,高級數據庫管理工程師,TiDB User Group Ambassador。
1、業務架構簡介
計費組是爲網易互娛產品提供統一登陸和支付高效解決方案的公共支持部門,對內是互娛的各個遊戲工做室,對外是國內外數百個渠道。因爲業務場景的特殊性,咱們爲各個遊戲產品部署了不一樣的應用服務,其中大產品環境獨立,小產品集中部署。前端
隨着部門業務量的激增,單機 MySQL 在容量、性能、擴展性等方面都遇到了瓶頸,咱們開始對其餘數據庫產品進行調研選型。本文將詳細介紹網易互娛計費組針對本身場景的數據庫選型對比方案,以及使用 TiDB 後解決的問題,並分享了使用 TiDB 過程當中集羣管理、監控和數據遷移等方面的最佳實踐,以供你們參考和交流。git
1.1 MySQL 使用架構
網易互娛計費組線上 MySQL 的基本使用架構,以下圖所示,其中箭頭方向表示數據或請求的指向:github

<center>圖 1 網易互娛計費組線上 MySQL 使用架構</center>數據庫
- 線上應用 Application 經過 Keepalive + 多機部署,流量通過負載均衡,能夠有效保障應用服務的高可用;
- 數據庫層架構是 Keepalive + 主從結構,利用半同步複製特性能夠有效解決延遲和數據一致性的問題;
- Application 經過 VIP 訪問後端數據庫,在數據庫主節點宕機後經過 VIP 飄移到從節點,保證服務正常對外提供;
- 經過 Slave 節點進行數據備份和線上數據採集,通過全量和增量同步方式導出數據到數據中心,而後進行在線和離線計算任務;
- 相似這樣的架構組合線上大概有 50+ 套,涉及服務器 200~400 臺,日均新增數據 TB 級。
1.2 MySQL 使用的現狀與問題
隨着業務的發展,部門內各應用服務產生的數據量也在快速增加。業務落地數據量不斷激增,致使單機 MySQL 不可避免地會出現性能瓶頸。主要體如今如下幾個方面:後端
-
容量服務器
- 單機 MySQL 實例存儲空間有限,想要維持現有架構就得刪除和輪轉舊數據,達到釋放空間的目的;
- 網易互娛某些場景單表容量達到 700GB 以上,訂單數據需永久保存,同時也須要保持在線實時查詢,按照以前的存儲設計會出現明顯的瓶頸。
-
性能網絡
- 最大單表 15 億行,行數過大,致使讀寫性能受到影響。
-
擴展性多線程
- MySQL 沒法在線靈活擴展,沒法解決存儲瓶頸。
-
SQL 複雜架構
- 大表輪轉後出現多個分表,聯合查詢時須要 join 多個分表,SQL 很是複雜並難以維護;
- 單機 MySQL 缺少大規模數據分析的能力。
-
數據壁壘併發
- 不一樣產品的數據庫獨立部署;
- 數據不互通,致使數據相關隔離,造成數據壁壘;
- 當進行跨產品計算時,須要維護多個異構數據源,訪問方式複雜。數據分散在不一樣的數據孤島上會增長數據分析難度,不利於共性價值的挖掘。以下圖:
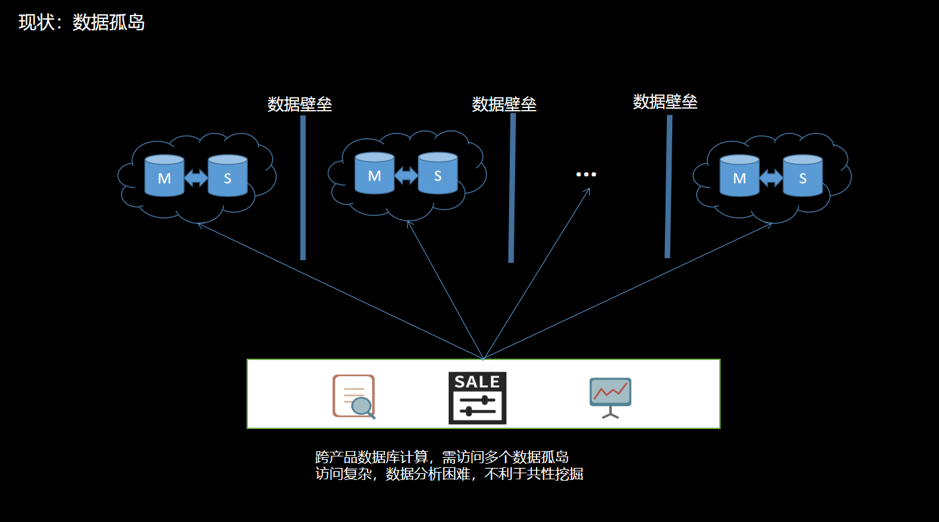 <center>圖 2 現狀之數據孤島</center>
2、數據庫選型
2.1 調研目標
針對目前存儲架構存在的問題,有須要使用其餘存儲方案的可能。考慮到目前的業務與 MySQL 高度耦合,對數據庫選型的主要要求有:
- 必須兼容 MySQL 協議;
- 支持事務,保證任務以事務爲維度來執行或遇錯回滾;
- 支持索引,尤爲是二級索引;
- 擴展性,支持靈活在線擴展能力,包括性能擴展和容量擴展。
其餘要求:
- 穩定性和可靠性;
- 備份和恢復;
- 容災等。
2.2 可選方案
| 序號 | 方案 | 說明 |
|---|---|---|
| 1 | MySQL 分庫分表 | 基於 MySQL |
| 2 | MySQL Cluster | 基於 MySQL |
| 3 | MySQL + Vitess | 基於 MySQL |
| 4 | MySQL + MyCAT | 基於 MySQL |
| 5 | CockroachDB(簡稱 CRDB) | 兼容 PostgreSQL 協議,不兼容 MySQL 協議 |
| 6 | TiDB | 兼容 MySQL 協議 |
2.3 測試
2.3.1 基於 MySQL 的解決方案
一開始仍然是傾向使用基於 MySQL 的解決方案,好比 MySQL InnoDB Cluster 或 MySQL + 中間件的方案。
咱們測試了 MySQL 集羣 5.7.25 版本對比 8.0.12 版本,在 128 併發寫各 1000 萬行的 10 個表,比較單節點、3 節點和 5 節點下的狀況,以下圖所示:

<center>圖 3 對比結果</center>
在測試中發現,使用 MySQL InnoDB 集羣的方案寫性能比單機 MySQL 差約 30%,其餘的讀寫測試結果也不甚滿意。以後陸續測試 MySQL InnoDB Cluster 或 MySQL + 中間件的方案,不是測試結果性能不達要求,就是須要修改大量代碼。
所以咱們得出了基於 MySQL InnoDB Cluster 或 MySQL + 中間件的方案的不知足咱們的業務場景的結論。總結來講,咱們不使用 MySQL 分庫分表、中間件或 MySQL 集羣,緣由主要是如下兩點:
- 方案過於複雜
- 須要改業務代碼
仔細分析來看,其實基於 MySQL InnoDB Cluster 或 MySQL + 中間件的方案,本質上是 MySQL 主從結構的延伸,並不是真正的分佈式拓展,像是以打「補丁」的方式來實現橫向擴展,不少功能特性天然也難以讓人滿意。
2.3.2 CockroachDB VS TiDB
在開源的分佈式 NewSQL 領域,知名的有 TiDB 和 CockroachDB(簡稱 CRDB),兩者都是基於 Google Spanner 論文的開源實現。咱們對這兩種數據庫的功能和性能作了大量的調研和測試。
- TiDB 自然兼容 MySQL 協議,而 CRDB 兼容 PostgreSQL ;
- 若是業務以 MySQL 爲主,那 TiDB 多是比較好的選擇;若是是 PostgreSQL,那CRDB 多是優先的選擇。
測試方面,咱們也進行了全面地對比和測試。這裏說其中一個測試案例:10 臺機器 5 存儲節點,160 併發訪問單表 2 億行,咱們於 2018 年 7 月,對 CRDB-v2.1.0 版本和 TiDB-v2.0.5 版本進行了讀寫測試(CRDB 和 TiDB 集羣均使用默認配置,未進行調優)。
集羣拓撲

<center>圖 4 CockroachDB 測試集羣搭建</center>

<center>圖 5 TiDB 測試集羣搭建</center>
測試語句
-
範圍查詢:
SELECT c FROM sbtest%u WHERE id BETWEEN ? AND ? SELECT SUM(k) FROM sbtest%u WHERE id BETWEEN ? AND ? SELECT c FROM sbtest WHERE id BETWEEN ? AND ? ORDER BY c SELECT DISTINCT c FROM sbtest%u WHERE id BETWEEN ? AND ? ORDER BY c
-
隨機 IN 查詢:
SELECT id, k, c, pad FROM sbtest1 WHERE k IN (?)
-
隨機範圍查詢:
SELECT count(k) FROM sbtest1 WHERE k BETWEEN ? AND ? OR k BETWEEN ? AND ?
-
更新索引列:
UPDATE sbtest%u SET k=k+1 WHERE id=?
-
更新非索引列:
UPDATE sbtest%u SET c=? WHERE id=?
- 讀寫混合:範圍查詢 + 更刪改混合
其中一個重要的測試結果以下:

<center>圖 6 測試結果</center>
結論:
-
CRDB 和 TiDB 在性能表現上不相上下;
注:上面是 2018 年 7 月的基於 TiDB 2.0.5 版本的測試結果,如今 TiDB 已發佈 3.0 GA 版本,在性能上有了質的提高,咱們在近期進行了補充測試,大多數場景下 3.0 版本較 2.1 版本有數倍的性能提高,最新的測試結果圖以下:

<center>圖 7 TiDB 2.1.15 vs 3.0.3:OLTP 峯值比較</center>
<center>圖 8 TiDB 2.1.15 vs 3.0.3:TPC-C</center>
- CRDB 兼容 PostgreSQL,若是須要遷移則須要轉協議,需 MySQL → PostgreSQL → CRDB。遷移過程複雜,成本高;
- TiDB 兼容 MySQL,代碼修改量很少,遷移成本低。


2.3.3 最終選型
綜合對比結果以下表:
| 數據庫 | 擴展 | TP | AP | 文檔程度 | 社區活躍度 |
|---|---|---|---|---|---|
| MySQL | 否 | 是 | 否 | 豐富 | 高 |
| PostgreSQL | 否 | 是 | 是 | 豐富 | 高 |
| MySQL InnoDB Cluster | 否 | 是 | 否 | 少 | 低 |
| MysQL + 中間件 Vitess | 是 | 是 | 否 | 豐富 | 中 |
| CRDB | 是 | 是 | 是 | 少 | 低 |
| TiDB | 是 | 是 | 是 | 豐富 | 高 |
通過謹慎的考量,咱們選擇了 TiDB。

<center>圖 9 選擇 TiDB 的重要理由</center>
3、TiDB 在網易互娛計費組的使用
3.1 TiDB 使用架構
網易互娛使用 TiDB 的架構設計以下:

<center>圖 10 基於 TiDB 的架構設計</center>
- 整個集羣分爲 TiDB、TiKV 和 PD 3 個模塊分層部署;
- 使用 Nginx 做爲前端負載均衡。
3.2 TiDB 解決了哪些需求
| 需求 | 解決方案 |
|---|---|
| 大容量存儲 | TiDB 在線實時伸縮,無需停機和頻繁清理數據 |
| 性能需求 | TiDB 支持多點讀寫,QPS 隨節點數量增長而增加,理論上無限制 |
| 高可用需求 | TiDB 強一致性多副本存儲,節點宕機不影響服務 |
| 數據備份和容災 | 數據多副本;支持跨機房、跨地域部署;Mydumper + Loader 多線程併發導出和恢復 |
| 分庫分表 | 無需分庫分表,自然支持超大表的高效讀寫 |
| 打破數據壁壘 | 支持 |
3.3 TiDB 使用現狀
-
業務
- TiDB 做爲線上 MySQL 數據鏡像,負責線上數據的收集和集中管理,造成數據湖泊;
- 應用於數據平臺服務,包括報表、監控、運營、用戶畫像、大數據計算等場景;
- HTAP:OLTP + OLAP。
-
集羣
- 測試集羣:v2.1.15,用於功能測試、特性嚐鮮;
- 線上集羣:v2.1.15,80% 離線大數據計算任務 + 20% 線上業務。
-
規模
- 41 臺服務器,88 個實例節點,38 個 Syncer 實時同步流(將升級爲 DM);
- 存儲:20TB/總 50TB,230 萬個 Region;
- QPS 均值 4k/s,高峯期萬級 QPS,讀寫比約 1:5;
- 延遲時間:80% 在 8ms 之內,95% 在 125ms 如下,99.9% 在 500ms 如下。
4、最佳實踐分享
4.1 集羣管理
-
Ansible(推薦)
- 一鍵部署;
- 彈性伸縮,可在線靈活擴縮容;
- 升級,單節點輪轉平滑升級;
- 集羣啓停和下線;
- Prometheus 監控。
- Docker
-
K8s
- 使用 TiDB Operator 能夠在私有云和公有云上一鍵管理。
4.2 運維實踐
4.2.1 Prometheus 監控
官方集成了 Prometheus + Grafana 的實時監控平臺,從集羣的各個方面進行了完善的監控,包括:
- 服務器基礎資源的監控:內存、CPU、存儲空間、IO 等;
- 集羣組件的監控:TiDB、PD、TiKV 等;
- 數據監控:實時同步流、上下游數據一致性檢驗等。
PD 監控示意圖以下,集羣管理員能夠很方便地掌握集羣的最新狀態,包括集羣的空間 Region 等全部狀況。

<center>圖 11 最佳運維實踐:Prometheus 實時監控</center>
若是集羣運行過程出錯,在監控面板上很容易就發現,下圖是使用過程當中的一個案例:

<center>圖 12 最佳運維實踐案例</center>
應用訪問 TiDB 寫入數據時發現特別慢,讀請求正常。排查後,根據 TiKV 面板發現 Raft Store CPU 這項指標異常。深刻了解緣由是由於數據庫副本複製是單線程操做,目前已經到了集羣的瓶頸。解決辦法有如下兩點:
- Region 數量過多,Raft Store 還要處理 heartbeat message。
解決方法:刪除過時數據。
- Raft Store 單線程處理速度跟不上集羣寫入速度。
解決方法:從 2.1.5 升級到 2.1.15,開啓自動 Region Merge 功能。
4.2.2 部分運維問題及解決方案
| 問題 | 問題版本 | 緣由及解決方案 |
|---|---|---|
| 大表建索引時對業務有影響 | 2.0 | 官方建議在業務低峯期操做,在 2.1 版本中已經增長了操做優先級以及併發讀的控制,狀況有改善。 |
| 上下游表結構不一致,同步異常 | 2.1 | TiDB 下游表比上游 MySQL 多增長几列時,DM 同步異常,其沒法按指定列同步(insert into A (a,b,c) values ...)。官方表示已經在增長該功能,預計 2019 年 Q4 推出支持上下游表結構不一致的版本。 |
| 在一個 DDL 裏不能對多個列或者多個索引作操做 | 2.1 | ADD/DROP INDEX/COLUMN 操做不支持同時建立或刪除多個索引或列,須要拆分單獨執行,官方表示 3.0 版本有計劃改進。 |
| 重啓 PD 節點,業務報 PD server timeout | 2.1 | 重啓 Leader 節點前需手動切換 Leader。官方建議經過重啓前作 Leader 遷移來減緩,後續也會對通信相關參數進行優化。 |
| 建表語句執行速度相比 MySQL 較慢。 | 2.0 & 2.1 | 多實例 TiDB 部署時,DDL Owner 和接收Create 語句的 Server 不是同一個時間,可能比 MySQL慢一些,耗時約 0.5s,官方表示會再完善。 |
| Delete 大量數據,GC 跟不上 | 2.1 | GC 是單線程的,當刪除數據量很是大時會致使 GC 速度較慢,極可能 GC 的速度跟不上寫入,可經過擴容和縮短 GC 週期間隔解決,長期須要實現分佈式 GC,官方表示對此已經在 3.0 版本實現。 |
| 存儲空間放大 | 2.1 & 2.0 | 該問題屬於 RocksDB。RocksDB 的空間放大係數最理想的值爲 1.111。官方建議在合適場景下經過 TiKV 開啓 RocksDB 的 dynamic-level-bytes 以減小空間放大。 |
| Truncate Table 空間沒法徹底回收 | 2.0 | Truncate 一張大表後,發現 2 個現象:一是空間回收較慢,二是最終也沒有徹底回收。目前 2.1 版本優化底層 RocksDB 的機制,使用 DeleteFilesInRange 接口刪除整個表佔用的空間,而後清理少許殘留數據,已經解決。 |
4.3 全網數據庫遍歷
之前部分業務遍歷全網數據庫獲取所需數據,須要維護多個源,並且是異構源,很是複雜和繁瑣。使用 TiDB 很好地解決了這個問題,只須要訪問一個源就能夠獲取到全部想要的數據。

<center>圖 13 全網數據庫遍歷</center>
4.4 數據遷移
4.4.1 MySQL 到 TiDB

<center>圖 14 數據從 MySQL 遷移到 TiDB</center>
MySQL 數據庫遷移到 TiDB 分爲兩個部分:全量和增量。
-
全量
- 使用工具 (Mydumper 或 MySQL Dump 等)從 MySQL 導出數據,而且記錄當前數據的 binlog 位置;
- 使用工具(Loader 或 Lightning 等)將數據導入到 TiDB 集羣;
- 能夠用做數據的備份和恢復操做。
-
增量
- TiDB 假裝成爲上游 MySQL 的一個 Slave,經過工具(Syncer 或 DM)實時同步 binlog 到 TiDB 集羣;
- 一般狀況上游一旦有數據更新,下游就會實時同步過來。同步速度受網絡和數據量大小的影響。
4.4.2 數據遷出 TiDB

<center>圖 15 數據遷出 TiDB</center>
若是數據須要反向導入或同步,能夠利用 TiDB Binlog 工具將 TiDB 集羣的 binlog 同步到 MySQL。TiDB Binlog 支持如下功能場景:
- 數據同步:同步 TiDB 集羣數據到其餘數據庫;
- 實時備份和恢復:備份 TiDB 集羣數據,同時能夠用於 TiDB 集羣故障時恢復。
導入的方式:
- 全量:TiDB 兼容 MySQL 協議,在 MySQL 容量足夠大的狀況下,也可用工具將數據從 TiDB 導出後再導入 MySQL。
- 增量:打開 TiDB 的 binlog 開關,部署 binlog 收集組件(Pump+Drainer),能夠將 binlog 數據同步到下游存儲架構(MySQL、TiDB、Kafka、S3 等)。
4.5 優雅地「去分庫分表」

<center>圖 16 去分庫分表舉例</center>
舉例:一個超級大表按天分表,如今打算查詢某個帳號一年間的信息。
-
上游 MySQL
SELECT xx FROM HFeeall join HFee20190101 join ... join ...join ... join HFee20190917 WHERE xx;
須要鏈接 N 個 join 條件,查詢須要等待較長時間。
-
下游 TiDB
SELECT xx FROM SuperHfeeall WHERE xx ;
應用此方案,最大單表 700+GB,13+ 億行,索引查詢秒返回。
4.6 業務遷移
目標:利用 TiDB 的水平擴展特性,解決容量瓶頸和系統吞吐量瓶頸。
遷移原則:
- 數據完整和準確:數據很重要,保證數據不錯、不丟;
- 遷移平滑和迅速:服務敏感度高,停服時間要短;
- 可回滾:遇到問題可隨時切回到 MySQL。
1)數據同步
使用 DM 或者 Syncer 將上游 MySQL 的數據同步到 TiDB 集羣。同步流搭建後注意須要檢查上下游數據一致性。
觀察一段時間,同步無誤後,能夠根據業務須要遷移部分讀流量到 TiDB 集羣。

<center>圖 17 業務遷移之數據同步</center>
2)讀寫驗證
這一階段是驗證應用訪問 MySQL 和訪問 TiDB 能夠獲得相同的結果,驗證業務訪問的準確性問題。
中止數據同步,使用流量複製工具將線上流量徹底拷貝出來,同時讀寫 MySQL 和 TiDB。將兩邊的訪問結果進行對比,覈查 TiDB 是否可靠和可信。根據須要,這個階段能夠測試較長時間。

<center>圖 18 業務遷移之讀寫驗證</center>
3)灰度切換
將步驟 2 的雙寫中止,即關雙寫,同時拉起上游的 DM 同步。
把訪問部分非核心業務的庫表寫操做遷移到 TiDB,打開 TiDB 的 Binlog 開關對線上 MySQL 進行反向同步。這個操做,保證只寫 MySQL 的數據同步到 TiDB ,只寫 TiDB 的數據也能夠反向同步到 MySQL,保證出了問題,隨時能夠回滾。當業務長時間訪問正常,能夠增長切換流量,進行灰度切換。建議觀察一段時間,至少一個月。

<center>圖 19 業務遷移之灰度切換</center>
4)遷移完成
當流量徹底遷移完成,保持 TiDB 反同步到 MySQL 過程,繼續觀察一段時間,確認無誤後,斷開反向同步,100% 遷移完成。

<center>圖 20 完成遷移</center>
5、總結與展望
TiDB 兼容 MySQL 協議,支持 TP/AP 事務且擴展性好,能很好地解決網易互娛計費組業務大容量、高可用等問題。目前咱們的業務在不斷深刻和擴大規模使用 TiDB,由於看好它,因此這裏提出一些使用中的問題以幫助原廠持續打磨產品:
- 集羣數據備份:但願提供集羣更高效地備份和恢復 SST 文件的方式;
- 事務限制:但願能夠放寬大事務的限制,如今仍須要人工切分大事務,比較複雜;
- 同步:但願 DM 支持上下游表結構不一致的同步;
- 數據熱點問題:建議增強自動檢測和清除熱點功能;
- 客戶端重試:目前客戶端代碼須要封裝重試邏輯,對用戶不友好,但願能夠改進。
最後,根據網易互娛計費組已有的使用狀況,咱們計劃繼續加大、加深 TiDB 的使用場景,豐富業務類型和使用規模,期待 TiDB 給咱們的業務帶來更多便利。
原文閱讀:https://pingcap.com/cases-cn/user-case-wangyihuyu/
更多案例閱讀:https://pingcap.com/cases-cn/
- 1. 網易互娛的數據庫選型和 TiDB 應用實踐
- 2. 網易嚴選數據產品實踐
- 3. 網易互娛我來辣
- 4. 網易互娛面經
- 5. TiDB 在小米的應用實踐
- 6. Shopee的數據庫選型之路
- 7. TiDB 4.0 在 VIPKID 的應用實踐
- 8. 網易嚴選ServiceMesh實踐
- 9. TiDB數據庫
- 10. TiDB 分佈式數據庫在轉轉公司的應用實踐
- 更多相關文章...
- • TiDB數據庫的應用場景 - NoSQL教程
- • 網站 數據庫 - 網站主機教程
- • TiDB 在摩拜單車在線數據業務的應用和實踐
- • 互聯網組織的未來:剖析GitHub員工的任性之源
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 網易互娛的數據庫選型和 TiDB 應用實踐
- 2. 網易嚴選數據產品實踐
- 3. 網易互娛我來辣
- 4. 網易互娛面經
- 5. TiDB 在小米的應用實踐
- 6. Shopee的數據庫選型之路
- 7. TiDB 4.0 在 VIPKID 的應用實踐
- 8. 網易嚴選ServiceMesh實踐
- 9. TiDB數據庫
- 10. TiDB 分佈式數據庫在轉轉公司的應用實踐