時間序列數據庫(TSDB)初識與選擇
時間序列數據庫(TSDB)初識與選擇
本文做者由 MageByte 團隊的 「借來方向」編寫,關注公衆號 給你更多硬核技術node
背景
這兩年互聯網行業掀着一股新風,老是聽着各類高大上的新名詞。大數據、人工智能、物聯網、機器學習、商業智能、智能預警啊等等。web
之前的系統,作數據可視化,信息管理,流程控制。如今業務已經不只僅知足於這種簡單的管理和控制了。數據可視化分析,大數據信息挖掘,統計預測,建模仿真,智能控制成了各類業務的追求。算法
「全部一切如淚水般消失在時間之中,時間正在死去「,之前咱們利用互聯網解決現實的問題。如今咱們已經不知足於現實,數據將鏈接成時間序列,往前能夠觀其歷史,揭示其規律性,日後能夠把握其趨勢性,預測其走勢。sql
咱們開始存儲大量的數據,並總結出這些數據的結構特色和常見使用場景,不斷改進和優化,創造了一種新型的數據庫分類——時間序列數據庫(time series database).數據庫
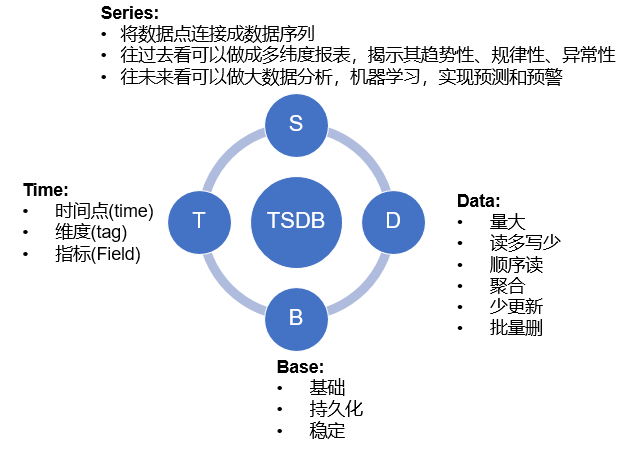
時間序列模型
時間序列數據庫主要用於處理帶時間標籤(按照時間的順序變化,即時間序列化)的數據,帶時間標籤的數據也稱爲時間序列數據。服務器
每一個時序點結構以下:數據結構
-
timestamp: 數據點的時間,表示數據發生的時間。 -
metric: 指標名,當前數據的標識,有些系統中也稱爲 name。 -
value: 值,數據的數值,通常爲 double 類型,如 cpu 使用率,訪問量等數值,有些系統一個數據點只能有一個 value,多個 value 就是多條時間序列。有些系統能夠有多個 value 值,用不一樣的 key 表示 -
tag: 附屬屬性。
實現
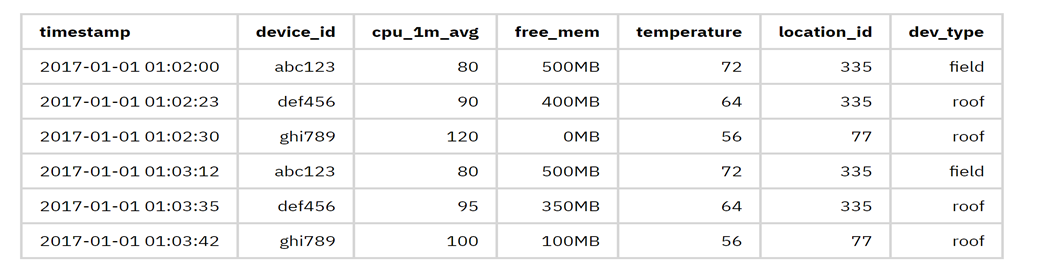
假如我想記錄一系列傳感器的時間序列數據。數據結構以下:架構
* 標識符:device_id,時間戳複製代碼
- 元數據:locationid,devtype,firmwareversion,customerid
- 設備指標:cpu1mavg,freemem,usedmem,netrssi,netloss,電池
- 傳感器指標:溫度,溼度,壓力,CO,NO2,PM10
若是使用傳統 RDBMS 存儲,建一張以下結構的表便可:

如此即是一個最簡單的時間序列庫了。但這只是知足了時間序列數據模型的須要。咱們還須要在性能,高效存儲,高可用,分佈式和易用性上作更多的事情。app你們能夠思考思考,若是讓咱們本身來實現一個時間序列數據庫,你會怎麼設計,你會考慮哪些性能上的優化,又如何作到高可用,怎樣作到簡單易用。運維
Timescale
這個數據庫其實就是一個基於傳統關係型數據庫 postgresql 改造的時間序列數據庫。瞭解 postgresql 的同窗都知道,postgresql 是一個強大的,開源的,可擴展性特別強的一個數據庫系統。
因而 timescale.inc 在 postgresql 架構上開發了 Timescale,一款兼容 sql 的時序數據庫。 做爲一個 postgresql 的擴展提供服務。其特色以下:
基礎:
-
支持全部 PostgreSQL 原生 SQL,包含完整 SQL 接口(包括輔助索引,非時間聚合,子查詢,JOIN,窗口函數)。 -
用 PostgreSQL 的客戶端或工具,能夠直接應用到該數據庫,不須要更改。 -
時間爲導向的特性,API 功能和相應的優化。 -
可靠的數據存儲。
擴展:
-
透明時間/空間分區,用於放大(單個節點)和擴展。 -
高數據寫入速率(包括批量提交,內存中索引,事務支持,數據備份支持)。 -
單個節點上的大小合適的塊(二維數據分區),以確保即便在大數據量時也可快速讀取。 -
塊之間和服務器之間的並行操做。
劣勢:
-
由於 TimescaleDB 沒有使用列存技術,它對時序數據的壓縮效果不太好,壓縮比最高在 4X 左右 -
目前暫時不徹底支持分佈式的擴展(正在開發相關功能),因此會對服務器單機性能要求較高
其實你們均可以去深刻了解一下這個數據庫。對 RDBMS 咱們都很熟悉,瞭解這個可讓咱們對 RDBMS 有更深刻的看法,瞭解其實現機制,存儲機制。在對時間序列的特殊化處理之中,咱們又能夠學到時間序列數據的特色,並學習到如何針對時間序列模型去優化 RDBMS。
以後咱們也能夠寫一篇文章來深刻的瞭解一下這個數據庫的特色。
Influxdb
Influxdb 是業界比較流行的一個時間序列數據庫,特別是在 IOT 和監控領域十分常見。其使用 go 語言開發,突出特色是性能。
特性:
-
高效的時間序列數據寫入性能。自定義 TSM 引擎,快速數據寫入和高效數據壓縮。 -
無額外存儲依賴。 -
簡單,高性能的 HTTP 查詢和寫入 API。 -
以插件方式支持許多不一樣協議的數據攝入,如:graphite,collectd,和 openTSDB -
SQL-like 查詢語言,簡化查詢和聚合操做。 -
索引 Tags,支持快速有效的查詢時間序列。 -
保留策略有效去除過時數據。 -
連續查詢自動計算聚合數據,使頻繁查詢更有效。
Influxdb 已經將分佈式版本轉爲閉源。因此在分佈式集羣這塊是一個弱點,須要本身實現。
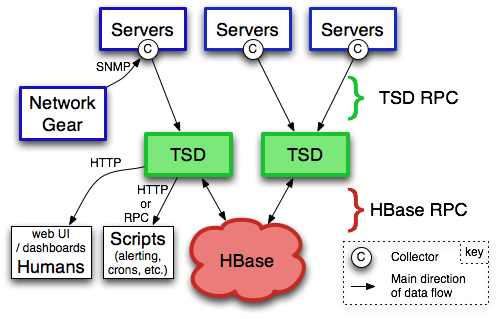
OpenTSDB
The Scalable Time Series Database. 打開 OpenTSDB 官網,第一眼看到的就是這句話。可見其將 Scalable 做爲本身重要的」賣點「。OpenTSDB 運行在 Hadoop 和 HBase 上,其充分利用 HBase 的特性。經過獨立的 Time Series Demon(TSD)提供服務,因此它能夠經過增減服務節點來輕鬆擴縮容。
tsdb-architecture
-
Opentsdb 是一個基於 Hbase 的時間序列數據庫(新版也支持 Cassandra)。
其基於 Hbase 的分佈式列存儲特性實現了數據高可用,高性能寫的特性。受限於 Hbase,存儲空間較大,壓縮不足。依賴整套 HBase, ZooKeeper
-
採用無模式的 tagset 數據結構(sys.cpu.user 1436333416 23 host=web01 user=10001)
結構簡單,多 value 查詢不友好
-
HTTP-DSL 查詢
OpenTSDB 在 HBase 上針對 TSDB 的表設計和 RowKey 設計值得咱們深刻學習的一個特色。有興趣的同窗能夠找一些詳細的資料學習學習。
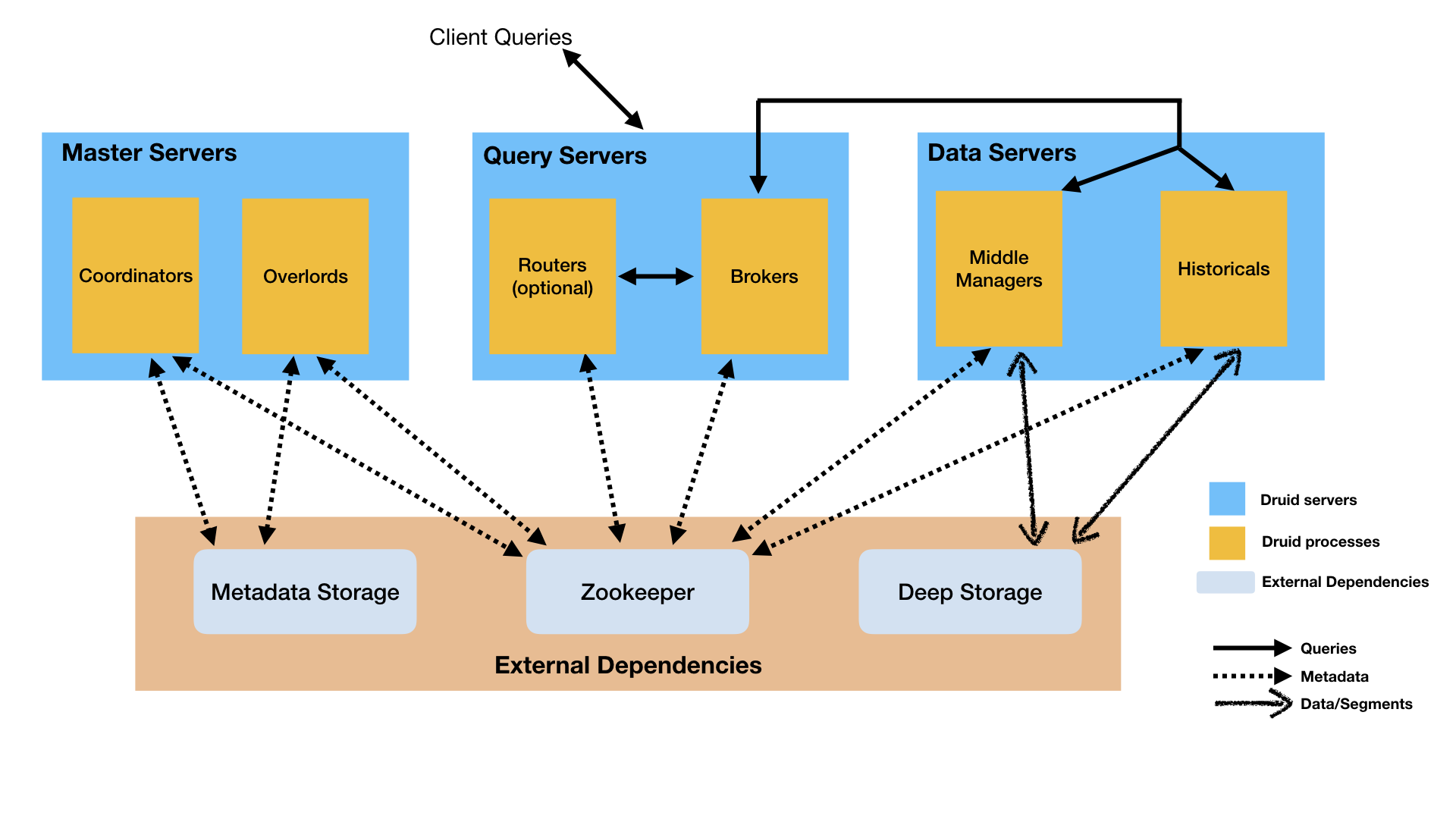
Druid
Druid 是一個實時在線分析系統(LOAP)。其架構融合了實時在線數據分析,全文檢索系統和時間序列系統的特色,使其能夠知足不一樣使用場景的數據存儲。
-
採用列式存儲:支持高效掃描和聚合,易於壓縮數據。 -
可伸縮的分佈式系統:Druid 自身實現可伸縮,可容錯的分佈式集羣架構。部署簡單。 -
強大的並行能力:Druid 各集羣節點能夠並行地提供查詢服務。 -
實時和批量數據攝入:Druid 能夠實時攝入數據,如經過 Kafka。也能夠批量攝入數據,如經過 Hadoop 導入數據。 -
自恢復,自平衡,易於運維:Druid 自身架構即實現了容錯和高可用。不一樣的服務節點能夠根據負載需求添加或減小節點。 -
容錯架構,保證數據不丟失:Druid 數據能夠保留多副本。另外能夠採用 HDFS 做爲深度存儲,來保證數據不丟失。 -
索引:Druid 對 String 列實現反向編碼和 Bitmap 索引,因此支持高效的 filter 和 groupby。 -
基於時間分區:Druid 對原始數據基於時間作分區存儲,因此 Druid 對基於時間的範圍查詢將更高效。 -
自動預聚合:Druid 支持在數據攝入期就對數據進行預聚合處理。
Druid 架構蠻複雜的。其按功能將整個系統細分爲多種服務,query、data、master 不一樣職責的系統獨立部署,對外提供統一的存儲和查詢服務。其以分佈式集羣服務的方式提供了一個底層數據存儲的服務。
druid-architecture Druid 在架構上的設計很值得咱們學習。若是你不只僅對時間序列存儲感興趣,對分佈式集羣架構也有興趣,不妨看看 Druid 的架構。另外 Druid 在 segment(Druid 的數據存儲結構)的設計上也是一大亮點,即實現了列式存儲,又實現了反向索引。
Elasticsearch
Elasticsearch 是一個分佈式的開源搜索和分析引擎,適用於全部類型的數據,包括文本、數字、地理空間、結構化和非結構化數據。Elasticsearch 在 Apache Lucene 的基礎上開發而成,由 Elasticsearch N.V.(即如今的 Elastic)於 2010 年首次發佈。Elasticsearch 以其簡單的 REST 風格 API、分佈式特性、速度和可擴展性而聞名。
Elasticsearch 以 ELK stack 被人所熟知。許多公司基於 ELK 搭建日誌分析系統和實時搜索系統。以前我所在團隊在 ELK 的基礎上開始開發 metric 監控系統。即想到了使用 Elasticsearch 來存儲時間序列數據庫。對 Elasticserach 的 mapping 作相應的優化,使其更適合存儲時間序列數據模型,收穫了不錯的效果,徹底知足了業務的需求。後期發現 Elasticsearch 新版本居然也開始發佈 Metrics 組件和 APM 組件,並大量的推廣其全文檢索外,對時間序列的存儲能力。真是和咱們當時的想法不謀而合。
Elasticsearch 的時序優化能夠參考一下這篇文章:《elasticsearch-as-a-time-series-data-store》
也能夠去了解一下 Elasticsearch 的 Metric 組件Elastic Metrics
Beringei
Beringei 是 Facebook 在 2017 年最新開源的一個高性能內存時序數據存儲引擎。其具備快速讀寫和高壓縮比等特性。
2015 年 Facebook 發表了一篇論文《Gorilla: A Fast, Scalable, In-Memory Time Series Database 》,Beringei 正是基於此想法實現的一個時間序列數據庫。
Beringei 使用 Delta-of-Delta 算法存儲數據,使用 XOR 編碼壓縮數值。使其能夠用不多的內存便可存儲下大量的數據。
如何選擇一個適合本身的時間序列數據庫
-
Data model
時間序列數據模型通常有兩種,一種無 schema,具備多 tag 的模型,還有一種 name、timestamp、value 型。前者適合多值模式,對複雜業務模型更適合。後者更適合單維數據模型。
-
Query language
目前大部分 TSDB 都支持基於 HTTP 的 SQL-like 查詢。
-
Reliability
可用性主要體如今系統的穩定高可用上,以及數據的高可用存儲上。一個優秀的系統,應該有一個優雅而高可用的架構設計。簡約而穩定。
-
Performance
性能是咱們必須考慮的因素。當咱們開始考慮更細分領域的數據存儲時,除了數據模型的需求以外,很大的緣由都是通用的數據庫系統在性能上沒法知足咱們的需求。大部分時間序列庫傾向寫多讀少場景,用戶須要平衡自身的需求。下面會有一份各庫的性能對比,你們能夠作一個參考。
-
Ecosystem
我一直認爲生態是咱們選擇一個開源組件必須認真考慮的一個問題。一個生態優秀的系統,使用的人多了,未被發現的坑也將少了。另外在使用中遇到問題,求助於社區,每每能夠獲得一些比較好的解決方案。另外好的生態,其周邊邊界系統將十分紅熟,這讓咱們在對接其餘系統時會有更多成熟的方案。
-
Operational management
易於運維,易於操做。
-
Company and support
一個系統其背後的支持公司也是比較重要的。背後有一個強大的公司或組織,這在項目可用性保證和後期維護更新上都會有較大的體驗。
性能對比
Timescale InfluxDB OpenTSDB Druid Elasticsearch Beringei write(single node) 15K/sec 470k/sec 32k/sec 25k/sec 30k/sec 10m/sec write(5 node) 128k/sec 100k/sec 120k/sec 總結
最後總結一下:
-
若是你想要一個極限性能的系統能夠考慮 Beringei 和 InfluxDB,在數據高可用方面,能夠採用客戶端雙寫模式來對數據作一個副本,保證數據的可用性。 -
若是你數據量不大,性能要求也不是特別高,卻又點查詢,刪除和關聯查詢等需求,不妨考慮一下 Timescale。 -
若是你間距索引和時間序列的需求。那麼 Druid 和 Elasticsearch 是最好的選擇。其性能都不差,而且都是高可用容錯架構。
最後
以後咱們能夠來深刻了解一兩個 TSDB,好比 Influxdb,Druid,Elasticsearch 等。並能夠學習一下行存儲與列存儲的不一樣,LSM 的實現原理,數值數據的壓縮,MMap 提高讀寫性能的知識等。
關注公衆號,掌握更多硬核技術
-
- 1. 時間序列數據庫(TSDB)初識與選擇(InfluxDB,OpenTSDB,Druid)
- 2. 時間序列數據庫(TSDB)初識與選擇
- 3. 時間序列數據庫TSDB排名
- 4. [轉帖]時間序列數據庫 (TSDB)
- 5. 時序數據庫(TSDB)
- 6. 時間序列數據庫Time series database(TSDB)
- 7. 時序數據庫的選擇?
- 8. 時序列數據庫武鬥大會之什麼是 TSDB ?
- 9. 時序列數據庫武鬥大會之TSDB名錄 Part 2
- 10. [轉]時序列數據庫武鬥大會之什麼是TSDB
- 更多相關文章...
- • MySQL選擇數據庫(MySQL USE語句) - MySQL教程
- • SQLite 日期 & 時間 - SQLite教程
- • Flink 數據傳輸及反壓詳解
- • TiDB 在摩拜單車在線數據業務的應用和實踐
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Window下Ribbit MQ安裝
- 2. Linux下Redis安裝及集羣搭建
- 3. shiny搭建網站填坑戰略
- 4. Mysql8.0.22安裝與配置詳細教程
- 5. Hadoop安裝及配置
- 6. Python爬蟲初學筆記
- 7. 部署LVS-Keepalived高可用集羣
- 8. keepalived+mysql高可用集羣
- 9. jenkins 公鑰配置
- 10. HA實用詳解