mycat入門—配置
mycat主要配置文件有3個,他們各司其職前端
一、server.xml配置
server.xml配置文件主要做用是:
配置系統相關參數java
配置用戶訪問權限mysql
配置SQL防火牆及SQL攔截功能算法
server.xml中分爲兩個節點,一個是system 節點,另外一個是user節點sql
system節點主要配置mycat運行相關的屬性,經常使用的屬性以下:數據庫
<!--mycat對外提供服務的端口-->
<property name="serverPort">3306</property>
<!--mycat管理端口-->
<property name="managerPort">9066</property>
<!--
登陸mycat時是否須要密碼驗證登陸 0爲須要密碼登錄、1爲不須要密碼登錄,默認爲0,設置爲1則須要指定默認帳戶
-->
<property name="nonePasswordLogin">0</property>
<!--須要監聽那些IP地址 0.0.0.0表示所有-->
<property name="bindIp">0.0.0.0</bindIp>
<!--前端寫隊列的大小-->
<property name="frontWriteQueueSize">2048</property>
<!--數據庫的字符集-->
<property name="charset">utf8</property>
<!--數據庫隔離級別 2讀已提交 3可重複讀-->
<property name="txIsolation">2</property>
<!--等於cpu核心數-->
<property name="processors">1</property>
<!--前端與mycat鏈接超時 時間(毫秒)-->
<property name="idleTimeout">1800000</property>
<!--當一條sql執行超過多長時間後mycat與mysql斷開鏈接 秒-->
<property name="sqlExecuteTimeout">300</property>
<!-- 1爲開啓實時統計、0爲關閉 -->
<property name="useSqlStat">0</property>
<!-- 1爲開啓全加班一致性檢測、0爲關閉 -->
<property name="useGlobleTableCheck">0</property>
<property name="sequnceHandlerType">2</property>
<!--每次查詢最多返回的數據-->
<property name="defaultMaxLimit">100</property>
<property name="maxPacketSize">104857600</property>
user標籤配置了能夠訪問mycat的用戶屬性以及權限安全
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<!--訪問那個數據庫 多個數據庫能夠用逗號隔開 user,system-->
<property name="schemas">TESTDB</property>
<property name="readOnly">false</property>
<!-- 表級 DML 權限設置 -->
<privileges check="false">
<!--
dml 數字分別表明 insert update select delete 0表明無權限 1表明有權限 schema標籤中的 dml爲默認權限
-->
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
</user>
這樣配置文件中密碼爲明文,存在安全隱患,mycat提供了加密方法,進入mycat安裝目錄下的lib目錄中執行如下命令:bash
java -cp Mycat-server-1.6.5-release.jar io.mycat.util.DecryptUtil 0:root:123456
執行完成後會返回加密後的密碼服務器
GO0bnFVWrAuFgr1JMuMZkvfDNyTpoiGU7n/Wlsa151CirHQnANVk3NzE3FErx8v6pAcO0ctX3xFecmSr+976QA==
將原來的明文密碼改爲加密後的密碼,並告訴mycat所用的密碼爲加密後的密碼便可,因此加密後的user節點爲:oracle
<user name="root" defaultAccount="true">
<!--是否使用加密後的密碼-->
<property name="usingDecrypt">1</property>
<property name="password">
GO0bnFVWrAuFgr1JMuMZkvfDNyTpoiGU7n/Wlsa151CirHQnANVk3NzE3FErx8v6pAcO0ctX3xFecmSr+976QA==
</property>
<!--訪問那個數據庫 多個數據庫能夠用逗號隔開 user,system-->
<property name="schemas">TESTDB</property>
<property name="readOnly">false</property>
<!-- 表級 DML 權限設置 -->
<privileges check="false">
<!--
dml 數字分別表明 insert update select delete 0表明無權限 1表明有權限 schema標籤中的 dml爲默認權限
-->
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
</user>
二、rule.xml配置文件
配置水平分片表的分片規則
配置分片規則對應的分片函數
rule.xml中分爲兩部分,一個爲tableRule,主要做用是指定分片列和分片函數,一個爲function(分片函數),用於指定分片算法
<!--name屬性指定分片表規則的名字,這個名字要惟一-->
<tableRule name="rule1">
<rule>
<!--分片列:mycat會對指定的分片列進行計算,最終肯定數據存放在哪一個分片上,通常選擇表的主鍵-->
<columns>id</columns>
<!--分片函數 取<function>的name屬性-->
<algorithm>func1</algorithm>
</rule>
</tableRule>
<!--name表明函數名 class表明該算法所在的類 property表明函數所需的參數-->
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的數據庫節點數量,必須指定,不然無法分片 -->
</function>
**經常使用的數據分片算法:**
簡單取模分片算法
簡單取模分片算法是經過對分片列進行取模,取模後將不一樣的結果存入對應的數據庫節點中:
例如:對下表經過簡單取模算法分片,分片列爲id,分爲2個節點,則對id進行取模,結果爲1的存入DB01,結果爲0的存入DB02

**簡單取模算法配置以下:**
<tableRule name="customer_login">
<rule>
<columns>id</columns><!--指定分片列-->
<algorithm>mod-long</algorithm><!--簡單取模分片函數name-->
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!--節點數量 -->
<property name="count">2</property>
</function>
哈希取模分片算法
哈希取模算法是經過對分片列進行哈希計算獲得一個整數值,而後進行取模運算
** 哈希取模算法配置以下:**
<tableRule name="customer_login">
<rule>
<columns>login_name</columns><!--指定分片列-->
<algorithm>mod-long</algorithm><!--哈希取模分片函數name-->
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByHashMod">
<!--節點數量 -->
<property name="count">2</property>
</function>
- 枚舉分片算法
枚舉分片算法是經過指定特定的枚舉值將數據存入特色的節點
例如:以area\_id做爲分片列,經過枚舉算法將不一樣的數據存入不一樣的節點,在mapFile中指定area\_id爲1000的存入DB01,將area_id爲10001的數據存入DB02,而後設置默認其他值存入DB01
** 枚舉分片算法配置以下:**
<tableRule name="jch">
<rule>
<columns>area_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property><!--mapFile配置文件-->
<property name="type">0</property><!--枚舉值類型 0表明整數類型 1表明字符串類型 默認爲0-->
<property name="defaultNode">0</property><!-- >=0:啓用默認節點 <0:不啓用默認節點 -->
</function>
字符串範圍取模分片算法
字符串取模分片算法是經過取一個字符串前n個字符,經過計算其ASCII碼的和,取模後存入對應的節點: 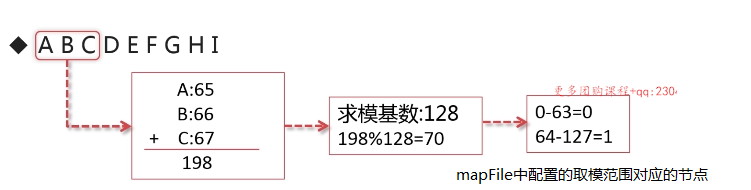
** 字符串範圍取模分片算法配置以下:**
<function name="sharding-by-prefix-pattern" class="io.mycat.route.function.PartitionByPrefixPattern">
<property name="patternValue">128</property><!--取模基數-->
<property name="prefixLength">2</property><!--前綴長度-->
<property name="mapFile">prefix-partition-pattern.txt</property><!--mapFile配置文件-->
</function>
三、schema.xml配置文件
邏輯庫邏輯表的配置
邏輯表所存儲的數據節點的配置
數據節點所對應的物理數據庫服務器信息的配置
schema.xml分爲三個節點,schema節點用於定義邏輯庫,dataNode,dataHost
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--name:表示邏輯庫庫名 sqlMaxLimit:表示每次查詢返回的最大行數,若取消限制 設置值爲-1
serverx.xml中配置的defaultMaxLimit是mycat系統默認的返回行數,
checkSQLschema:是否檢查sql中含有數據庫名稱,便是否是經過庫名.代表的方式查詢
-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!--
邏輯表配置
name:邏輯表名稱,必須與物理表名稱一致
primaryKey:物理表中的主鍵
dataNode:表數據存在物理節點的名稱,用逗號分開
rule:分片規則
-->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- <table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
</schema>
<!--
定義邏輯表存儲的物理數據庫
name:定義數據節點名稱,必須惟一
dataHost:定義分片所在的物理主機 這裏是主機名稱 這個名稱下可能包含多個物理主機
database:定義屋裏數據庫的名稱
-->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--
定義了一組主從複製的集羣
writeHost:處理寫請求的數據庫
readHost:處理讀請求的數據庫 通常爲從服務器
name:數據庫集羣的名稱 惟一
maxCon:最大鏈接數
minCon:初始化最小鏈接數
balance:讀寫分離和讀的負載均衡
0表明不開啓不寫分離 讀寫所有在主服務器處理
1所有的readHost與stand by writeHost參與select語句的負載均衡
2所有的readHost與writeHost參與select語句的負載均衡
3所有的readHost參與select語句的負載均衡
writeType:寫操做類型
0表明所有的寫操做在第一個writeHost數據庫進行 當第一個宕機後 寫操做在第二個writeHost執行
1表明寫請求隨機發送到writeHost執行
dbType:數據庫類型
dbDriver:數據庫驅動 native mysql原生驅動 其餘數據庫用jdbc
switchType:
slaveThreshold:
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!--心跳檢測語句-->
<heartbeat>select user()</heartbeat>
<!--通常爲主次那個數據庫中的主數據庫-->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root" password="123456" />
</dataHost>
</mycat:schema>
相關文章
- 1. Mycat配置入門
- 2. Ubuntu 安裝 MyCat 初入門 與 ThinkPHP 連接MyCat配置 ( 親測 )
- 3. 【Mycat】Mycat簡單入門
- 4. Mycat入門
- 5. MyCat入門
- 6. Mycat - 配置
- 7. MYCAT 配置(轉)
- 8. Windows配置mycat
- 9. Mycat 配置
- 10. Mycat(配置篇)
- 更多相關文章...
- • Memcached入門教程 - NoSQL教程
- • Eclipse Debug 配置 - Eclipse 教程
- • YAML 入門教程
- • IntelliJ IDEA 代碼格式化配置和快捷鍵
相關標籤/搜索
每日一句
-
每一个你不满意的现在,都有一个你没有努力的曾经。
最新文章
- 1. Appium入門
- 2. Spring WebFlux 源碼分析(2)-Netty 服務器啓動服務流程 --TBD
- 3. wxpython入門第六步(高級組件)
- 4. CentOS7.5安裝SVN和可視化管理工具iF.SVNAdmin
- 5. jedis 3.0.1中JedisPoolConfig對象缺少setMaxIdle、setMaxWaitMillis等方法,問題記錄
- 6. 一步一圖一代碼,一定要讓你真正徹底明白紅黑樹
- 7. 2018-04-12—(重點)源碼角度分析Handler運行原理
- 8. Spring AOP源碼詳細解析
- 9. Spring Cloud(1)
- 10. python簡單爬去油價信息發送到公衆號
歡迎關注本站公眾號,獲取更多信息

相關文章
- 1. Mycat配置入門
- 2. Ubuntu 安裝 MyCat 初入門 與 ThinkPHP 連接MyCat配置 ( 親測 )
- 3. 【Mycat】Mycat簡單入門
- 4. Mycat入門
- 5. MyCat入門
- 6. Mycat - 配置
- 7. MYCAT 配置(轉)
- 8. Windows配置mycat
- 9. Mycat 配置
- 10. Mycat(配置篇)