【NLP】Google BERT詳解
11號論文放上去,12號各個公衆號推送,13號的我終於在最晚時間完成了前沿追蹤,驚覺上一篇論文居然是一個月前。。。立個flag之後保持一週一更的頻率。下週開始終於要在工做上接觸NLP了,以後但願會帶來更多本身的東西而不是論文解析。session
Attention和Transformer還不熟悉的請移步以前的文章:app
2. 【NLP】Transformer詳解函數
NLP遷移學習中的三個state of the art模型能夠參考前面的文章:學習
正文分割線spa
1.BERT模型
BERT的全稱是Bidirectional Encoder Representation from Transformers,即雙向Transformer的Encoder,由於decoder是不能獲要預測的信息的。模型的主要創新點都在pre-train方法上,即用了Masked LM和Next Sentence Prediction兩種方法分別捕捉詞語和句子級別的representation。code
1.1 模型結構
因爲模型的構成元素Transformer已經解析過,就很少說了,BERT模型的結構以下圖最左:orm
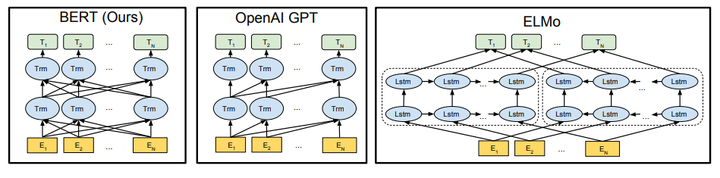
對比OpenAI GPT(Generative pre-trained transformer),BERT是雙向的Transformer block鏈接;就像單向rnn和雙向rnn的區別,直覺上來說效果會好一些。blog
對比ELMo,雖然都是「雙向」,但目標函數實際上是不一樣的。ELMo是分別以 和 做爲目標函數,獨立訓練處兩個representation而後拼接,而BERT則是以 做爲目標函數訓練LM。token
和 做爲目標函數,獨立訓練處兩個representation而後拼接,而BERT則是以 做爲目標函數訓練LM。token
1.2 Embedding
這裏的Embedding由三種Embedding求和而成:
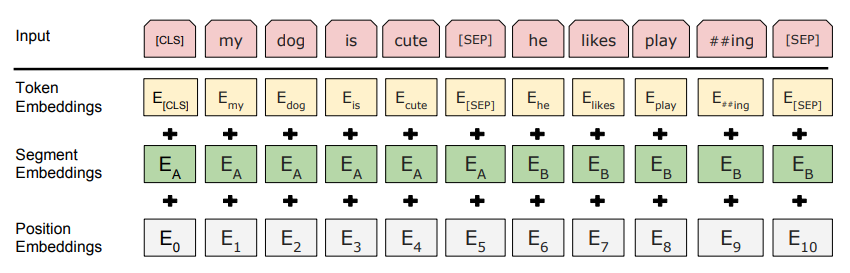
其中:
- Token Embeddings是詞向量,第一個單詞是CLS標誌,能夠用於以後的分類任務
- Segment Embeddings用來區別兩種句子,由於預訓練不光作LM還要作以兩個句子爲輸入的分類任務
- Position Embeddings和以前文章中的Transformer不同,不是三角函數而是學習出來的
1.3 Pre-training Task 1#: Masked LM
第一步預訓練的目標就是作語言模型,從上文模型結構中看到了這個模型的不一樣,即bidirectional。關於爲何要如此的bidirectional,做者在reddit上作了解釋,意思就是若是使用預訓練模型處理其餘任務,那人們想要的確定不止某個詞左邊的信息,而是左右兩邊的信息。而考慮到這點的模型ELMo只是將left-to-right和right-to-left分別訓練拼接起來。直覺上來說咱們其實想要一個deeply bidirectional的模型,可是普通的LM又沒法作到,由於在訓練時可能會「穿越」(關於這點我不是很認同,以後會發文章講一下如何作bidirectional LM)。因此做者用了一個加mask的trick。
在訓練過程當中做者隨機mask 15%的token,而不是把像cbow同樣把每一個詞都預測一遍。關於爲何這樣作,我以爲多是模型結構自己的緣由,從結構上看輸入輸出是長度同樣的sequence,這樣模型實際上在作sequence-level的LM。
Mask如何作也是有技巧的,若是一直用標記[MASK]代替(在實際預測時是碰不到這個標記的)會影響模型,因此隨機mask的時候10%的單詞會被替代成其餘單詞,10%的單詞不替換,剩下80%才被替換爲[MASK]。具體爲何這麼分配,做者沒有說。。。要注意的是Masked LM預訓練階段模型是不知道真正被mask的是哪一個詞,因此模型每一個詞都要關注。
1.4 Pre-training Task 2#: Next Sentence Prediction
由於涉及到QA和NLI之類的任務,增長了第二個預訓練任務,目的是讓模型理解兩個句子之間的聯繫。訓練的輸入是句子A和B,B有一半的概率是A的下一句,輸入這兩個句子,模型預測B是否是A的下一句。預訓練的時候能夠達到97-98%的準確度。
1.5 Fine-tunning
分類:對於sequence-level的分類任務,BERT直接取第一個[CLS]token的final hidden state ,加一層權重 後softmax預測label proba:
其餘預測任務須要進行一些調整,如圖:
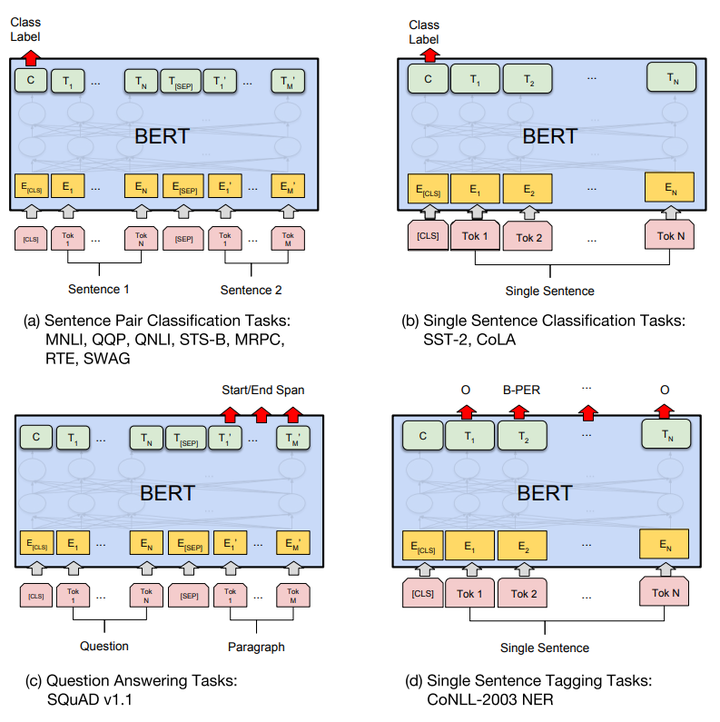
由於大部分參數都和預訓練時同樣,精調會快一些,因此做者推薦多試一些參數。
2. 優缺點
2.1 優勢
BERT是截至2018年10月的最新state of the art模型,經過預訓練和精調橫掃了11項NLP任務,這首先就是最大的優勢了。並且它還用的是Transformer,也就是相對rnn更加高效、能捕捉更長距離的依賴。對比起以前的預訓練模型,它捕捉到的是真正意義上的bidirectional context信息。
2.2 缺點
做者在文中主要提到的就是MLM預訓練時的mask問題:
- [MASK]標記在實際預測中不會出現,訓練時用過多[MASK]影響模型表現
- 每一個batch只有15%的token被預測,因此BERT收斂得比left-to-right模型要慢(它們會預測每一個token)
3. 總結
一遍讀下來,感受用到的都是現有的東西,可沒想到效果會這麼好,而別人又沒想到。不過文章中沒有具體解釋的不少點能夠看出這樣出色的結果也是經過不斷地實驗得出的,並且訓練的數據也比差很少結構的OpenAI GPT多,因此數據、模型結構,都是不可或缺的東西。
以上。
【參考資料】:
- 1. 【NLP】Google BERT詳解
- 2. Google BERT 詳解
- 3. BERT詳解
- 4. google bert模型詳解 源碼解析
- 5. K-BERT詳解
- 6. NLP---BERT
- 7. NLP---Bert
- 8. Transformer與BERT詳解
- 9. 【NLP】 一步步理解BERT
- 10. 谷歌NLP BERT
- 更多相關文章...
- • 免費ARP詳解 - TCP/IP教程
- • *.hbm.xml映射文件詳解 - Hibernate教程
- • Flink 數據傳輸及反壓詳解
- • 爲了進字節跳動,我精選了29道Java經典算法題,帶詳細講解
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 【NLP】Google BERT詳解
- 2. Google BERT 詳解
- 3. BERT詳解
- 4. google bert模型詳解 源碼解析
- 5. K-BERT詳解
- 6. NLP---BERT
- 7. NLP---Bert
- 8. Transformer與BERT詳解
- 9. 【NLP】 一步步理解BERT
- 10. 谷歌NLP BERT