深刻理解 web 協議(一)- http 包體傳輸
本文首發於 vivo互聯網技術 微信公衆號
連接: https://mp.weixin.qq.com/s/Wl...
做者:吳越
開坑這個系列的緣由,主要是在大前端學習的過程當中遇到了很多跟web協議有關的問題,以前對這一塊的瞭解僅限於用charles抓個包,基本功欠缺。強迫症發做的我決定這一次完全將web協議搞懂搞透,若是你遇到了和我同樣的問題,例如html
- 對http的瞭解,僅限於charles抓個包。
- 對https的瞭解僅限於大概知道tls,ssl,對稱加密,非對稱加密。真正一次完整的交互過程,沒法作到心中有數。
- 對h5的各類緩存字段,瞭解的不夠。
- 移動端各類深度弱網優化的文章由於基本功不紮實的緣由各類看不懂。
- 有時做爲移動端開發在定技術方案的時候,由於對前端或者服務器缺少基本的瞭解,沒法力排衆議制定出更完美的方案。
- 移動端中的網頁加載出了問題只能求助於前端工程師,沒法第一時間本身定位問題。
- 每次想深度學習web協議的時候,由於不會寫服務端程序致使只能泛泛而讀,隨意找幾篇網上的博客就得過且過了,並無真正解決心中的疑惑。沒有實際動手過。
- 沒有實際對照過瀏覽器和Android端使用okhttp在發送網絡請求的時候有什麼不一樣。
- 實話說如今okhttp的文章百分之99都忽略了真正實現http協議的部分,基本上都是簡要介紹了下okhttp的設計模式和上層的封裝,這其實對移動端工程師理解web協議自己是一個debuff(我也是其中受害者。)
但願這個系列的文章能夠幫助到和我同樣對web協議有困惑的工程師們。本系列文章中全部的服務端程序均使用 Go語言開發完成。抓包工具使用的是wireshark,沒有使用charles是由於charles看不到傳輸層的東西,不利於我理解協議的本質。本系列文章沒有複製粘貼網上太多概念性的東西,以代碼和wireshark抓包爲主。概念性的東西須要讀者自行搜索。實戰有助於真正理解協議自己。前端
本文主要分爲四塊,若是以爲文章過長能夠自行選擇感興趣的模塊閱讀:java
- chrome network面板的使用:主要以一個移動端工程師的視角來看chrome的network模塊,主要列舉了我認爲可能會對定位h5問題有幫助的幾個知識點。
- Connection-keeplive:主要闡述瞭如今客戶端/前端與服務端交互的方式,簡略介紹了服務端大概的樣子。
- http 隊頭擁塞: 主要以若干個實驗來理解http 隊頭擁塞的本質,並給出okhttp與瀏覽器在策略上的不一樣。
- http 包體傳輸:以若干個實驗來理解http 包體傳輸的過程。
1、chrome network面板的使用
打開商城的頁面,打開chrome控制檯。ios

注意看紅色標註部分,左邊disable cache 表明關閉瀏覽器緩存,打開這個選項以後,每次訪問頁面都會從新拉取而不是使用緩存,右邊的online能夠下拉菜單選擇弱網環境下訪問此頁面。在模擬弱網環境的時候此方法一般很是有效。例如咱們正常訪問的時候,耗時僅僅2s。git

打開弱網(fast 3g)程序員

時間膨脹到了26s.github

這裏說一下這2個選項的做用,Preserve log主要就是保存前一個頁面的請求日誌,好比咱們在當前頁面a點擊了一個超連接訪問了頁面b,那麼頁面a的請求在控制檯就看不到了,若是勾選此選項那麼就能夠看到這個前面一個頁面的請求。另外這個Hide data Urls,選項額外說明一下,有些h5頁面的某些資源會直接用base64轉碼之後嵌入到代碼裏面(好比截圖中data: 開頭的東西),這樣作的好處是能夠省略一些http請求,固然壞處就是開啓此選項瀏覽器針對這個資源就沒有緩存了,且base64轉碼之後的體積大小要比原大小大4/3。咱們能夠勾選此選項過濾掉這種咱們不想看的東西。web
再好比,咱們只想看看同一個頁面下某一個域名的請求(這在作競品分析時對競品使用域名數量的分析頗有幫助),那咱們也能夠以下操做:chrome
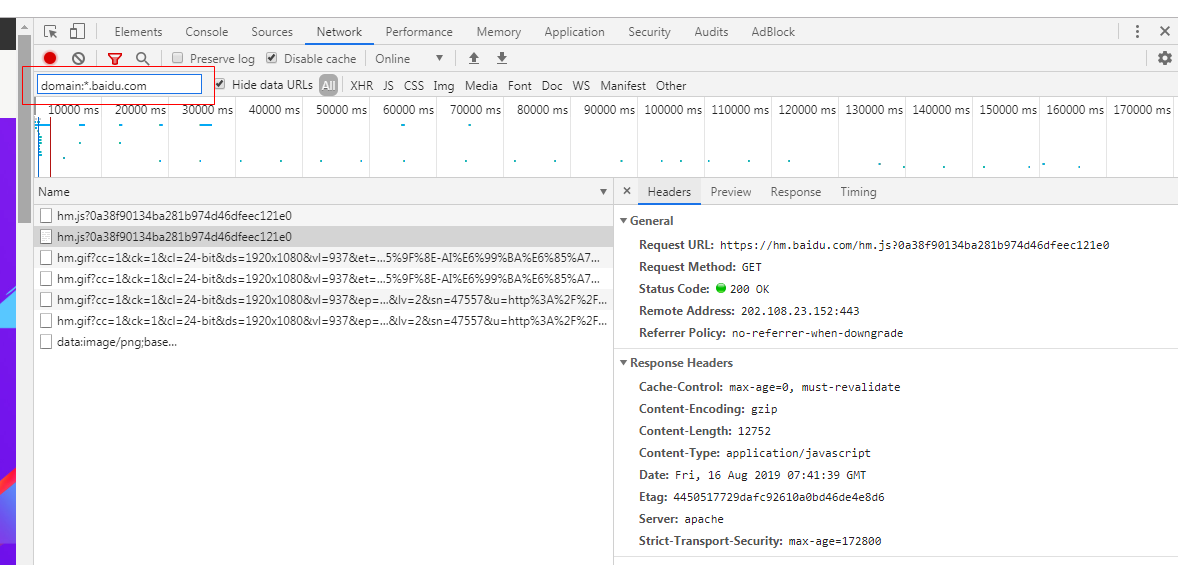
再好比說咱們只想看一下這個頁面的post請求,或者是get請求也能夠。後端

再好比咱們能夠用 is:from-cache 查看咱們當前頁面哪些資源使用了緩存。large-than:(單位是字節)這個也頗有用,一般咱們利用這個過濾出超出大小的請求,看看有多少超大的圖片資源(移動端排查h5頁面速度慢的一個手段)。
咱們也能夠點擊其中一個請求,按住shift,注意看藍色的就是咱們選定的請求,綠色的表明這個請求是藍色請求的上游,也就是說只有當綠色的請求執行完畢之後纔會發出藍色的請求,而紅色的請求就表明只有藍色的請求執行完畢之後纔會請求。這種看請求上下游關係的方法是不少時候h5優化的一個技巧。將用戶最關心的資源請求前移,能夠極大優化用戶體驗,雖然在某種程度上這種行爲並不會在數據上有所提升(例如activity之間跳轉用動畫,application啓動優化用特殊theme等等,本質上耗時都沒有減小,但給用戶的感受就是頁面和app速度很快)。

這個timing 能夠顯示一個請求的詳細分段時間,好比排隊時間,發出請求到第一個請求響應的字節時間,以及整個response都傳輸完畢的時間等等。有興趣的能夠自行搜索下相關資料。

2、關於Connection:Keep-Alive
在現代服務器架構中,客戶端的長鏈接大部分時候並非直接和源服務器打交道(所謂源服務器能夠粗略理解爲服務端開發兄弟實際代碼部署的那臺服務器),而是會通過不少代理服務器,這些代理服務器有的負責防火牆,有的負責負載均衡,還有的負責對消息進行路由分發(例如對客戶端的請求根據客戶端的版本號,ios仍是Android等等分別將請求映射到不一樣的節點上)等等。

客戶端的長鏈接僅僅意味着客戶端發起的這條tcp鏈接是和第一層代理服務器保持鏈接關係。並不會直接命中到原始服務器。
再看一張圖:

一般來說,咱們的請求客戶端發出之後會通過若干個代理服務器纔會到咱們的源服務器。若是咱們的源服務器想基於客戶端的請求的ip地址來作一些操做,理論上就須要額外的http頭部支持了。由於基於上述的架構圖,咱們的源服務器拿到的地址是跟源服務器創建tcp鏈接的代理服務器的地址,壓根拿不到咱們真正發起請求的客戶端ip地址。
http RFC規範中,規定了X-Forwarded-For 用於傳遞真正的ip地址。固然了在實際應用中有些代理服務器並不遵循此規定,例如Nginx就是利用的X-Real-IP 這個頭部來傳遞真正的ip地址(Nginx默認不開啓此配置,須要手動更改配置項)。
在實際生產環境中,咱們是能夠在http response中將上述通過的代理服務器信息一一返回給客戶端的。

看這個reponse的返回裏面的頭部信息有一個X-via 裏面的信息就是代理服務器的信息了。
再好比說 咱們打開淘寶的首頁,找個請求。

這裏的代理服務器信息就更多了,說明這條請求通過了多個代理服務器的轉發。另外有時咱們在技術會議上會聽到正向代理和反向代理,其實這2種代理都是指的代理服務器,做用都差很少,只不過應用的場景有一些區別。
正向代理:好比咱們kexue上網的時候,這種是咱們明確知道咱們想訪問外網的網站好比facebook、谷歌等等,咱們能夠主動將請求轉發到一個代理服務器上,由代理服務器來轉發請求給facebook,而後facebook將請求返回給代理服務器,服務器再轉發給咱們。這種就叫正向代理了。
反向代理:這個其實咱們天天都在用,咱們訪問的服務器,99%都是反向代理而來的,現代計算機系統中指的服務器每每都是指的服務器集羣了,咱們在使用一個功能的時候,根本不知道到底要請求到哪一臺服務器,一般這種狀況都是由Nginx來完成,咱們訪問一個網站,dns返回給咱們的地址,一般都是一臺Nginx的地址,而後由Nginx本身來負責將這個請求轉發給他以爲應該轉發的那臺服務器。
這裏咱們屢次提到了Nginx服務器和代理服務器的概念,考慮到不少前端開發可能不太瞭解後端開發的工做,暫且在這裏簡單介紹一下。一般而言咱們認爲的服務器開發工程師天天大部分的工做都是在應用服務器上開發,所謂http的應用服務器就是指能夠動態生成內容的http服務器。好比 java工程師寫完代碼之後打出包交給Tomcat,Tomcat自己就是一個應用服務器。再好比Go語言編譯生成好的可執行文件,也是一個http的應用服務器,還有Python的simpleServer等等。而Nginx或者Apache更像是一個單純的http server,這個單純的http server 幾乎沒有動態生成http response的能力,他們只能返回靜態的內容,或者作一次轉發,是一個很單純的http server。嚴格意義上說,無論是Tomcat仍是Go語言編譯出來的可執行文件仍是Python等等,本質上他們也是http server,也能夠拿來作代理服務器的,只是一般狀況下沒有人這麼幹,由於術業有專攻,這種工做一般而言都是交給Nginx來作。
下圖是Nginx的簡要介紹:用一個Master進程來管理n個worker進程,每一個worker進程僅有一個線程在執行。

在Nginx以前,多數服務器都是開啓多線程或者多進程的工做模式,然而進程或者線程的切換是有成本的,若是訪問量太高,那麼cpu就會消耗大量的資源在建立進程或者建立線程,還有線程和進程以前的切換上,而Nginx則沒有使用相似的方案,而是採用了「進程池單線程」的工做模式,Nginx服務器在啓動的時候會建立好固定數量的進程,而後在以後的運行中不會再額外建立進程,並且能夠將這些進程和cpu綁定起來,完美的使用現代cpu中的多核心能力。

此外,web服務器有io密集型的特色(注意是io密集不是cpu密集),大部分的耗時都在網絡開銷而非cpu計算上,因此Nginx使用了io多路複用的技術,Nginx會將到來的http請求一一打散成一個個碎片,將這些碎片安排到單一的線程上,這樣只要發現這個線程上的某個碎片進入io等待了就當即切換出去處理其餘請求,等肯定可讀可寫之後再切回來。這樣就能夠最大限度的將cpu的能力利用到極致。注意再次強調這裏的切換不是線程切換,你能夠把他理解爲這個線程中要執行的程序裏面有不少go to 的錨點,一旦發現某個執行碎片進入了io等待,就立刻利用go to能力跳轉到其餘碎片(這裏的碎片就是指的http請求了)上繼續執行。
其實這個地方Nginx的工做模式有一點點相似於Go語言的協程機制,只不過Go語言中的若干個協程下面並非只有一個線程,也可能有多個。可是思路都是同樣的,就是下降線程切換的開銷,儘可能用少的線程來執行業務上的「高併發」需求。
然而Nginx再優秀,也抵不過歲月的侵蝕,提及來距離今天也有15年的時間了。仍是有一些天生缺陷的,好比Nginx只要你修改了配置就必須手動將Nginx進程重啓(master進程),若是你的業務很是龐大,一旦遇到要修改配置的狀況,幾百臺甚至幾千臺Nginx手動修改配置重啓不但容易出錯並且重複勞動意義也不大。此外Nginx可擴展性通常,由於Nginx是c語言寫的,咱們都知道c語言其實仍是挺難掌握的,尤爲是想要掌握的好更加難。不是每一個人都有信心用C語言寫出良好可維護的代碼。尤爲你的代碼還要跑在Nginx這種天天都要用的基礎服務上。
基於上述缺陷,阿里有一個綽號爲「春哥」的程序員章亦春,在Nginx的基礎上開發了更爲優秀的OpenResty開源項目,也是老羅錘子發佈會上說要贊助的那個開源項目。此項目能夠對外暴露Lua腳本的接口,80後玩過魔獸世界的同窗必定對Lua語言不陌生,大名鼎鼎的魔獸世界的插件機制就是用Lua來完成的。OpenResty出現之後終於能夠用Lua腳本語言來操做咱們的Nginx服務器了,這裏Lua也是用「協程」的概念來完成併發能力,與Go語言也是保持一致的。此外OpenResty對服務器配置的修改也能夠及時生效,不須要再重啓服務器。大大提升運維的效率。等等等等。。。
3、http協議中「隊頭擁塞」的真相
前文咱們數次提到了服務器,高併發等關鍵字。咱們印象中的服務器都是與高併發這3個字強關聯的。那麼所謂 http中的「隊頭擁塞」到底指的是什麼呢?咱們先來看一張圖:

這張互聯網中流傳許久的圖,到底應該怎麼理解?有的同窗認爲http所謂的擁塞是由於傳輸協議是tcp致使的,由於tcp天生有擁塞的缺點。其實這句話並不全對。考慮以下場景:
- 網絡狀況很好。
- 客戶端先用socket發送一組數據a,2s之後發送數據b。
- 服務端收到數據a 而後開始處理數據a,而後收到數據b,開始處理數據b(這裏固然是開線程作)
- 此時服務端處理數據b的線程將數據b處理完畢之後開始將b的 responseb發到客戶端,過了一段時間之後數據a的線程終於把數據處理完畢也將responsea發給客戶端。
- 在發送responseb的時候,客戶端甚至還能夠同時發送數據c,d,e。
上述的通訊場景就是完美詮釋tcp做爲全雙工傳輸的能力了。至關於客戶端和服務端是有2條傳輸信道在工做。因此從這個角度上來看,tcp不是致使http 協議 「隊頭擁塞」的根本緣由。由於你們都知道http使用的傳輸層協議是tcp. 只有在網絡環境很差的狀況下,tcp做爲可靠性協議,確實會出現不停重複發送數據包和等待數據包確認的狀況。可是這不是http 「隊頭擁塞「」的根本緣由。
從這張圖上看,彷佛http 1.x 協議是隻有等前面的http request的 response回來之後 後面的http request 纔會發出去。可是這個角度上理解的話,服務器的效率是否是過低了一點?若是是這樣的話怎麼解釋咱們天天打開網頁的速度都很快,打開app的速度也很快呢?通過一段時間的探索,我發現上述的圖是針對單tcp鏈接來講的,所謂的http 隊頭擁塞 是指單條tcp鏈接上 纔會發生。而咱們與服務器的一個域名交互的時候每每不止一條tcp鏈接。好比說Chrome瀏覽器就默認了最大限度能夠和一個域名有6條tcp鏈接,這樣的話,即便有隊頭擁塞的現象,也能夠保證我一臺服務器最多能夠同時處理你這個ip發出來的6條http請求了。
爲何瀏覽器會限制6條?按照這個理論難道不是越多的tcp鏈接速度就越快嗎?但若是這樣作每一個瀏覽器都針對單域名開多條tcp鏈接來加快訪問速度的話,服務器的tcp資源很快就會被耗盡,以後就是拒絕訪問了。然而道高一尺魔高一丈,既然瀏覽器限制了單一域名最多隻能使用6條tcp鏈接,那乾脆咱們在一個頁面訪問多個域名不就好了?實際上單一頁面訪問多域名也是前端優化中的一個點,瀏覽器只能限制你單一域名6條tcp鏈接,可是可沒限制你一個頁面能夠有多個域名,咱們多開幾個域名不就至關於多開了幾條tcp鏈接麼?這樣頁面的訪問速度就會大大增長了。
這裏咱們有人可能會以爲好奇,瀏覽器限制了單一域名的tcp鏈接數量,那麼Android中咱們天天使用的okhttp限制了嗎?限制了多少?來看下源碼:

okhttp中默認對單一域名的tcp鏈接數量限制爲5,且對外暴露了設置這個值的方法。可是問題到這裏還沒完,單一tcp鏈接上,http爲何要作成前一個消息的response回來之後,後面的http request才能發出去?這樣的設計是否是有問題?速度太慢了?仍是說咱們理解錯了?是否是還有一種多是:
- http消息能夠在單一的tcp鏈接上 不停的發送,不須要等待前面一個http消息的返回之後再發送。
- 服務器接收了http消息之後先去處理這些消息,消息處理完畢準備發response的時候 再判斷一下,必定等到前面到達的request的response先發出去之後 再發,就好像一個先進先出的隊列那樣。這樣彷佛也能夠符合「隊頭擁塞」的設計?
帶着這個疑問,我作了一組實驗,首先咱們寫一段服務端的代碼,提供fast和slow2個接口,其中slow接口 延遲10秒返回消息,fast接口延遲5秒返回消息。
package main
import (
"io"
"net/http"
"os"
"time"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
e.GET("/slow", slowRes)
e.GET("/fast", fastRes)
e.Logger.Fatal(e.Start(":1329"))
}
func fastRes(c echo.Context) error {
println("get fast request!!!!!")
time.Sleep(time.Duration(5) * time.Second)
return c.String(http.StatusOK, "fast reponse")
}
func slowRes(c echo.Context) error {
println("get slow request!!!!!")
time.Sleep(time.Duration(10) * time.Second)
return c.String(http.StatusOK, "slow reponse")
}
而後咱們將這個服務器程序部署在雲上,另外再寫一段Android程序,咱們讓這個程序發http請求的時候單一域名只能使用一條tcp鏈接,而且設置超時時間爲20s(不然默認的okhttp響應超時時間過短 等不到服務器的返回就斷開鏈接了):
dispatcher = new Dispatcher();
dispatcher.setMaxRequestsPerHost(1);
client = new OkHttpClient.Builder().connectTimeout(20, TimeUnit.SECONDS).readTimeout(20, TimeUnit.SECONDS).dispatcher(dispatcher).build();
new Thread() {
@Override
public void run() {
Request request = new Request.Builder().get().url("http://www.dailyreport.ltd:1329/slow").build();
Call call = client.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
Log.v("wuyue","slow e=="+e.getMessage());
}
@Override
public void onResponse(Call call, Response response) throws IOException {
Log.v("wuyue", "slow reponse==" + response.body().string());
}
});
}
}.start();
new Thread() {
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Request request = new Request.Builder().get().url("http://www.dailyreport.ltd:1329/fast").build();
Call call = client.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
Log.v("wuyue","fast e=="+e.getMessage());
}
@Override
public void onResponse(Call call, Response response) throws IOException {
Log.v("wuyue", "fast reponse==" + response.body().string());
}
});
}
}.start();
這裏要注意必定要使用enqueue也就是異步的方法來發送http請求,不然你設置的域名tcp鏈接數量限制是失效的。而後咱們用wireshark來抓包看看:

這裏能夠清晰的看出來,首先這2個http request 都是使用的同一條tcp鏈接, 都是源端口號60465到服務器1329. 而後看下time的時間,差很少0s開始發送了slow的請求,10s左右收到了slow的http response,而後立刻 fast這個接口的request 就發出去了,過了5秒 fast的http response 也返回了。
若是將這個域名tcp數量限制爲1改爲5 那麼再次抓包運行能夠看到:

這個時候就能夠清晰的看到,這一次fast大約在slow接口2秒之後就發出去了,並無等待slow回來之後再發,且注意看這2條http消息使用的源端口號是不一樣的,一個是64683,一個是64684。也就是說這裏使用了不一樣的tcp鏈接來傳輸咱們的http消息。
綜上所述,咱們能夠對http 1.x 中的「隊頭擁塞」 來下結論了:
- 所謂http1.x中的「隊頭擁塞」,除了自己傳輸層協議tcp的緣由致使的tcp包擁塞機制之外,更多的是指的http 應用層上的限制。這種限制具體表如今,對於http協議來講,單條tcp鏈接上客戶端要保證前面一條的request的response返回之後,才能發送後續的request。
- http 1.x 中的 「隊頭擁塞」 本質上來講是由http的客戶端來保證明現的。
- 若是你訪問的網頁裏面的請求都指向着同一個域名,那麼無論服務器有多麼高的併發能力,他也最多隻能同時處理你的6條http請求,由於大多數瀏覽器限制了針對單一域名只能開6條tcp鏈接。想翻過這個限制提升頁面加載速度只能依靠開啓多域名來實現。
- 雖然okhttp中對外暴露了這個單域名下的tcp鏈接數的設置,可是也沒法經過將這個值調的特別高來增長你應用的請求響應速度,由於大多數服務器都會限制單一ip的tcp鏈接數,好比Nginx的默認設置就是10。因此你客戶端單一將這個數值調的特別大也沒用,除非你和服務器約定好。可是這樣還不如使用多域名方便了。
通過上面的分析,咱們得知其實http 1.x協議並無徹底發揮tcp 全雙工通道的潛能,(也有多是http協議出現的太早當時的設計者沒有考慮如今的場景)因此從1.1協議開始,又有了一個Pipelining 也就是管道的約定。這個約定可讓http的客戶端不用等前面一個request的response回來就能夠繼續發後面的request。可是各類緣由下,現代瀏覽器都沒有開啓這個功能(相關資料感興趣的能夠自行查詢Pipelining關鍵字,這裏就不復制粘貼了)。我帶着好奇搜索了一下okhttp的代碼,想看看他們有沒有相似的實現。最終咱們在這個類中找到了線索:

看樣子貌似這個tunnel的命名和咱們http1.1中所謂的pipelining好似一個意思?那麼okhttp中是可使用這個瀏覽器默認關閉的技術了嗎?繼續看代碼:

咱們看到這個值使用的地方是來自於connectTunnel這個方法,咱們看看這個方法是在connect方法裏調用的:

咱們看下這個方法的實現:
/**
* Returns true if this route tunnels HTTPS through an HTTP proxy. See <a
* href="http://www.ietf.org/rfc/rfc2817.txt">RFC 2817, Section 5.2</a>.
*/
public boolean requiresTunnel() {
return address.sslSocketFactory != null && proxy.type() == Proxy.Type.HTTP;
}
從註釋和rfc文檔中能夠看出來,要開啓這個所謂的tunnel的功能,須要你的目標地址是https的,講白了是tls來作報文的傳輸,此外還須要一個http代理服務器。同時知足這2個條件之後纔會觸發這部分代碼。這部分因爲涉及到tls協議的相關知識,咱們將這一塊的內容放到後續的第三個章節中再來解釋。這裏你們只須要大概清楚tunnel主要用來直接轉發傳輸層的tcp報文到目標服務器,而不須要通過http的代理服務器額外進行應用層報文的轉發便可。
4、http包體傳輸的本質
好比說Referer(我在谷歌中搜索github,而後點擊github的連接,而後看請求信息)

這個字段一般一般被利用作防盜鏈,頁面來源統計分析,緩存優化等等。可是要注意的是,這個Referer字段瀏覽器在自動幫咱們添加的時候有一個策略:要麼來源是http 目標也是http,要麼來源是https 目標也是https,一旦出現來源是http目標是https或者反着來的狀況,瀏覽器就不會幫咱們添加這個字段了。
此外,在http包體傳輸的時候,定長包體與不定長包體使用的單位是不同的。

好比Content-Length這個字段後面的單位就是10進制。傳輸的就是這個「Hello, World!」。可是對於Chunk非定長包體來講 這個單位倒是16進制的,且對於Chunk傳輸方式來講,有一些response的header是等待body傳輸完畢之後才繼續傳的。咱們來簡單寫個server端的例子,返回一個叫hellowuyue的response,可是使用chunk的傳輸方式。這裏我簡單使用Go語言來完成對應的代碼。
package main
import (
"net/http"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
//採用chunk傳輸 不使用默認的定長包體
e.GET("/", func(c echo.Context) error {
c.Response().WriteHeader(http.StatusOK)
c.Response().Write([]byte("hello"))
c.Response().Flush()
c.Response().Write([]byte("wuyue"))
c.Response().Flush()
return nil
})
e.Logger.Fatal(e.Start(":1323"))
}
咱們在瀏覽器訪問一下,看看network的展現信息:

而後咱們用wireshark 詳細的看一下chunk的傳輸機制:這裏要注意的是,我沒有選擇將咱們服務端的代碼部署在外網服務器上,只是簡單的在本地,因此咱們要選擇環回地址,不要選擇本地鏈接。同時監聽1323端口.而且作 port 1323的過濾器。

而後咱們來看下wireshark完整的還原過程:

能夠看一下這個chunk的結構,每個chunk的結束都會伴隨着一個0d0a的16進制,這個咱們能夠把他理解成就是/r/n 也就是crlf換行符。而後看一下 當chunk所有結束之後 還會有一個end chunked 這裏面 也是包含了一個0d0a 。(這裏篇幅所限就不放ABNF範式對chunk使用的規範了。有興趣的同窗能夠自行對照ABNF的規範語法和wireshark實際抓包的內容進行對比加深理解)


最後咱們看一下,瀏覽器和服務端在利用form表單上傳文件時的交互過程以及okhttp完成相似功能時候的異同,加深對包體傳輸的理解。首先咱們定義一個很是簡單的html,提供一個表單。
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>上傳文件</title>
</head>
<body>
<h1>上傳文件</h1>
<form action="/uploadresult" method="post" enctype="multipart/form-data">
Name: <input type="text" name="name"><br>
Files: <input type="file" name="file"><br><br>
Files2: <input type="file" name="file2"><br><br>
<input type="submit" value="Submit">
</form>
</body>
</html>
而後定義一下咱們的服務端:
package main
import (
"io"
"net/http"
"os"
"time"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
//直接返回一個預先定義好的html
e.GET("/uploadtest", func(c echo.Context) error {
return c.File("html/upload.html")
})
//html裏預先定義好點擊上傳之後就跳轉到這個uri
e.POST("/uploadresult", getFile)
e.Logger.Fatal(e.Start(":1329"))
}
func getFile(c echo.Context) error {
name := c.FormValue("name")
println("name==" + name)
file, _ := c.FormFile("file")
file2, _ := c.FormFile("file2")
src, _ := file.Open()
src2, _ := file2.Open()
dst, _ := os.Create(file.Filename)
dst2, _ := os.Create(file2.Filename)
io.Copy(dst, src)
io.Copy(dst2, src2)
return c.String(http.StatusOK, "上傳成功")
}
而後咱們訪問這個表單,上傳一下文件之後用wireshark抓個包來體會一下瀏覽器在背後幫咱們作的事情。


關於這個Content-Disposition有興趣的能夠自行搜索其含義。
最後咱們用okhttp來完成這個操做,看看okhttp作這個操做的時候,wireshark顯示的結果又是什麼樣子:
//注意看 contentType 是須要你手動去設置的,咱們這裏故意將這個contentType值寫錯 看看能不能上傳文件成功
RequestBody requestBody1 = RequestBody.create(MediaType.parse("image/gifccc"), new File("/mnt/sdcard/ccc.txt"));
RequestBody requestBody2 = RequestBody.create(MediaType.parse("text/plain111"), new File("/mnt/sdcard/Gif.gif"));
RequestBody requestBody = new MultipartBody.Builder()
.setType(MultipartBody.FORM).addFormDataPart("file2", "Gif.gif", requestBody1)
.addFormDataPart("file", "ccc.txt", requestBody2)
.addFormDataPart("name","吳越")
.build();
Request request = new Request.Builder().get().url("http://47.100.237.180:1329/uploadresult").post(requestBody).build();

5、總結
本章節初步介紹瞭如何使用chrome的network面板和wireshark抓包工具進行http協議的分析,重點介紹了http1.x協議中的「隊頭擁塞」的概念,以及該問題的應對方式和瀏覽器的限制策略。在後續的第二個章節中,將會詳細介紹http協議中緩存,dns以及websocket的相關知識。在第三個章節中,將會詳細分析http2以及tls協議的每個細節。
更多內容敬請關注 vivo 互聯網技術 微信公衆號

注:轉載文章請先與微信號:labs2020 聯繫。
- 1. 深刻理解 web 協議(一)- http 包體傳輸
- 2. 深刻理解 Web 協議 (三):HTTP 2
- 3. 深刻理解Http協議
- 4. 深刻理解 HTTP 協議
- 5. 深刻理解HTTP協議
- 6. 深刻理解http協議
- 7. HTTP協議詳解(深刻理解)
- 8. Http協議詳解(深刻理解)
- 9. 深刻http協議原理
- 10. 深刻理解HTTP協議、HTTP協議原理分析
- 更多相關文章...
- • SOAP HTTP 協議 - SOAP 教程
- • Swift 協議 - Swift 教程
- • Flink 數據傳輸及反壓詳解
- • 適用於PHP初學者的學習線路和建議
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 深刻理解 web 協議(一)- http 包體傳輸
- 2. 深刻理解 Web 協議 (三):HTTP 2
- 3. 深刻理解Http協議
- 4. 深刻理解 HTTP 協議
- 5. 深刻理解HTTP協議
- 6. 深刻理解http協議
- 7. HTTP協議詳解(深刻理解)
- 8. Http協議詳解(深刻理解)
- 9. 深刻http協議原理
- 10. 深刻理解HTTP協議、HTTP協議原理分析