Docker 資源管理
標籤(空格分隔): Docker 資源管理 內存 CPU 磁盤 I/Ohtml
注:該文做者是 Marek Goldmann,原文是 Resource management in Docker。node
在這篇博客文章中,我想談談 Docker 容器資源管理的話題,咱們每每不清楚它是怎樣工做的以及咱們能作什麼不能作什麼。我但願你讀完這篇關於資源管理的博客文章以後,能夠幫助你更容易理解這些。python
注意:咱們假設你在一個 systemd 可用的系統上運行了 Docker。若是你是使用 RHEL/CentOS 7+ 或 Fedora 19+,
systemd確定可用,可是請注意在不一樣的 systemd 版本之間可能配置選項會有改變。有疑問時,使用你所工做的系統的 systemd 的 man pages。linux
目錄預覽git
1. 基礎概念
Docker 使用 cgroups 歸類運行在容器中的進程。這使你能夠管理一組進程的資源,可想而知,這是很是寶貴的。github
若是你運行一個操做系統,其使用 systemd 管理服務。每一個進程(不只僅是容器中的進程)都將被放入一個 cgroups 樹中。若是你運行 systemd-cgls 命令,你本身能夠看到這個結構:docker
$ systemd-cgls ├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 ├─machine.slice │ └─machine-qemu\x2drhel7.scope │ └─29898 /usr/bin/qemu-system-x86_64 -machine accel=kvm -name rhel7 -S -machine pc-i440fx-1.6,accel=kvm,usb=off -cpu SandyBridge -m 2048 ├─system.slice │ ├─avahi-daemon.service │ │ ├─ 905 avahi-daemon: running [mistress.local │ │ └─1055 avahi-daemon: chroot helpe │ ├─dbus.service │ │ └─890 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation │ ├─firewalld.service │ │ └─887 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid │ ├─lvm2-lvmetad.service │ │ └─512 /usr/sbin/lvmetad -f │ ├─abrtd.service │ │ └─909 /usr/sbin/abrtd -d -s │ ├─wpa_supplicant.service │ │ └─1289 /usr/sbin/wpa_supplicant -u -f /var/log/wpa_supplicant.log -c /etc/wpa_supplicant/wpa_supplicant.conf -u -f /var/log/wpa_supplica │ ├─systemd-machined.service │ │ └─29899 /usr/lib/systemd/systemd-machined [SNIP]
當咱們想管理資源的時候,這個方法提供了很大的靈活性,由於咱們能夠分別的管理每一個組。儘管這篇博客文章着重與容器,一樣的原則也適用於其餘的進程。後端
注意:若是你想知道更多關於 systemd 的知識,我強烈推薦 RHEL 7 的 Resource Management and Linux Containers Guide 。api
1.1 測試說明
在個人例子中,我將使用 stress 工具來幫助我生成容器的一些負載,所以我能夠實際看到資源的申請限制。我使用這個 Dockerfile 建立了一個名爲 stress 的定製的 Docker 鏡像:bash
FROM fedora:latest RUN yum -y install stress && yum clean all ENTRYPOINT ["stress"]
1.2 關於資源報告工具的說明
你使用這個工具來報告如 top, /proc/meminfo 等等 cgroups 不知道的使用狀況。這意味着你將報告關於這臺主機的信息,儘管咱們在容器中運行着它們。我發現了一篇很好來自於 Fabio Kung 的關於這個主題的文章。讀一讀它吧。
所以,咱們能作什麼?
若是你想快速發如今該主機上哪一個容器(或是最近的任何 systemd 服務)使用最多資源,我推薦 systemd-cgtop 命令:
$ systemd-cgtop Path Tasks %CPU Memory Input/s Output/s / 226 13.0 6.7G - - /system.slice 47 2.2 16.0M - - /system.slice/gdm.service 2 2.1 - - - /system.slice/rngd.service 1 0.0 - - - /system.slice/NetworkManager.service 2 - - - - [SNIP]
這個工具能馬上給你一個快速預覽什麼運行在系統上。可是若是你想獲得關係使用狀況的更詳細信息(好比,你須要建立一個好看的圖表),你將去分析 /sys/fs/cgroup/… 目錄。我將向你展現去哪裏能找到咱們將討論的每一個資源的有用文件(看下面的 CGroups fs 段落)。
2. CPU
Docker 可以指定(經過運行命令的 -c 開關)給一個容器的可用的 CPU 分配值。這是一個相對權重,與實際的處理速度無關。事實上,沒有辦法說一個容器應該只得到 1Ghz CPU。記住。
默認,每一個新的容器將有 1024 shares 的 CPU,當咱們單獨講它的時候,這個值並不意味着什麼。可是若是咱們啓動兩個容器而且兩個都將使用 100% CPU,CPU 時間將在這兩個容器之間平均分割,由於它們兩個都有一樣的 CPU shares(爲了簡單起見,我假設它們沒有任何進程在運行)。
若是咱們設置容器的 CPU shares 是 512,相對於另一個容器,它將使用一半的 CPU 時間。但這不意味着它僅僅能使用一半的 CPU 時間。若是另一個容器(1024 shares 的)是空閒的 - 咱們的容器將被容許使用 100% CPU。這是須要注意的另一件事。
限制是僅僅當它們應該被執行的時候纔會強制執行。CGroups 不限制進程預先使用(好比,不容許它們容許的更快,即便它們有空餘資源)。相反它提供了它儘量提供的,以及它僅僅在必需的時候限制(好比,當太多的進程同時大量使用 CPU)。
固然,這很難說清楚(我想說的是這不可能說清楚的)多少資源應該被分配給你的進程。這實際取決於其餘進程的行爲和多少 shares 被分配給它們。
2.1 示例:管理一個容器的 CPU 分配
正如我在前面提到的,你可使用 -c 開關來分配給運行在容器中的全部進程的 shares 值。
由於在個人機器上我有 4 核,我將使用 4 壓測:
$ docker run -it --rm stress --cpu 4 stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
若是你想以相同的方式啓動兩個容器,兩個都將使用 50% 左右的 CPU。可是當咱們修改其中一個容器的 shares 時,將發生什麼?
$ docker run -it --rm -c 512 stress --cpu 4 stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
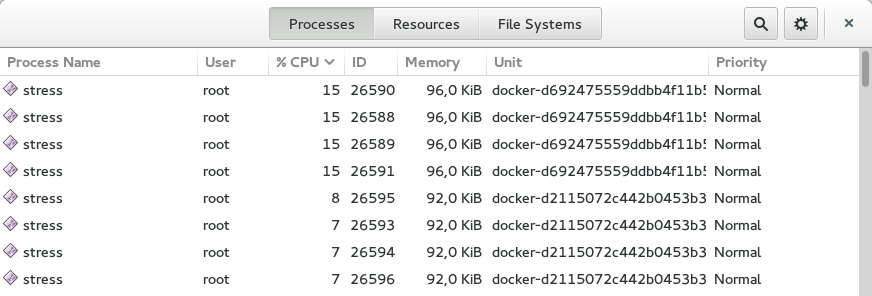
正如你所看到的,CPU 在兩個容器之間是以這樣的方式分割了,第一個容器使用了 60% 的 CPU,另一個使用了 30% 左右。這彷佛是預期的結果。
注:丟失的 10% CPU 被 GNOME,Chrome 和個人音樂播放器使用了。
2.2 Attaching containers to cores
除了限制 CPU 的 shares(股份,至關於配額的意思),咱們能夠作更多的事情,咱們能夠把容器的進程固定到特定的處理器(core)。爲了作到這個,咱們使用 docker run 命令的 --cpuset 開關。
爲了容許僅在第一個核上執行:
docker run -it --rm --cpuset=0 stress --cpu 1
爲了容許僅在第一個和第二個核上執行:
docker run -it --rm --cpuset=0,1 stress --cpu 2
你固然能夠混合使用選項 --cpuset 和 -c。
注意:Share enforcement 僅僅發生在當進程運行在相同的核上的時候。這意味着若是你把一個容器固定在第一個核,而把另一個容器固定在另一個核,兩個都將使用各自核的 100%,即便它們有不一樣的 CPU shares 設置(再一次,我假設僅僅有兩個容器運行在主機上)。
2.3 變動一個正在運行的容器的分配值
有可能改變一個正在運行的容器的 shares(或是任何進程)。你能夠直接與 cgroups 文件系統交互,可是由於咱們有 systemds,咱們能夠經過它來爲咱們管理。
爲了這個目的,咱們將使用 systemctl 命令和 set-property 參數。使用 docker run 命令新的容器將有一個 systemd scope,自動分配到其內的全部進程都將被執行。爲了改變容器中全部進程的 CPU share,咱們僅僅須要在 scope 內改變它,像這樣:
$ sudo systemctl set-property docker-4be96b853089bc6044b29cb873cac460b429cfcbdd0e877c0868eb2a901dbf80.scope CPUShares=512
注意:添加
--runtime暫時的改變設置。不然,當主機重起的時候,這個設置會被記住。
把默認值從 1024 變動到 512。你能夠在下面看到結果。這一變化發生在記錄的中間。請注意 CPU 使用率。在 systemd-cgtop 中 100% 意味着滿額使用了一核,而且這是正確的,由於我綁定了兩個容器在相同的核上。
注意:爲了顯示全部的屬性,你可使用
systemctl show docker-4be96b853089bc6044b29cb873cac460b429cfcbdd0e877c0868eb2a901dbf80.scope命令。爲了列出全部可用的屬性,請看下man systemd.resource-control。
2.4 CGroups fs
你能夠在 /sys/fs/cgroup/cpu/system.slice/docker-$FULL_CONTAINER_ID.scope/ 下面發現指定容器的關於 CPU 的全部信息,例如:
$ ls /sys/fs/cgroup/cpu/system.slice/docker-6935854d444d78abe52d629cb9d680334751a0cda82e11d2610e041d77a62b3f.scope/ cgroup.clone_children cpuacct.usage_percpu cpu.rt_runtime_us tasks cgroup.procs cpu.cfs_period_us cpu.shares cpuacct.stat cpu.cfs_quota_us cpu.stat cpuacct.usage cpu.rt_period_us notify_on_release
注意:關於這些文件的更多信息,請移步 RHEL Resource Management Guide 查看。
2.5 概要重述
須要記住的一些事項:
- CPU share 僅僅是一個數字 - 與 CPU 速度無關
- 新容器默認有
1024shares - 在一臺空閒主機上,低 shares 的容器仍可使用 100% 的 CPU
- 若是你想,你能夠把容器固定到一個指定核
3. 內存
如今讓我看下限制內存。
第一件事須要注意的是,默認一個容器可使用主機上的全部內存。
若是你想爲容器中的全部進程限制內存,使用 docker run 命令的 -m 開關便可。你可使用 bytes 定義它的值或是(k, m 或 g)。
3.1 示例:管理一個容器的內存分配
你能夠像這樣使用 -m 開關:
$ docker run -it --rm -m 128m fedora bash
爲了顯示限制的實際狀況,我將再次使用個人 stress 鏡像。考慮一下的運行:
$ docker run -it --rm -m 128m stress --vm 1 --vm-bytes 128M --vm-hang 0 stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress 工具將建立一個進程,並嘗試分配 128MB 內存給它。它工做的很好,可是若是咱們使用的比實際分配給容器的更多,將發生什麼?
$ docker run -it --rm -m 128m stress --vm 1 --vm-bytes 200M --vm-hang 0 stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
它照樣正常工做,是否是很奇怪?是的,我贊成。
咱們將在 libcontainer 源碼 找到解釋(cgroups 的 Docker 接口)。咱們能夠看到源碼中默認的 memory.memsw.limit_in_bytes 值是被設置成咱們指定的內存參數的兩倍,當咱們啓動一個容器的時候。memory.memsw.limit_in_bytes 參數表達了什麼?它是 memory 和 swap 的總和。這意味着 Docker 將分配給容器 -m 內存值以及 -m swap 值。
當前的 Docker 接口不容許咱們指定(或者是徹底禁用它)多少 swap 應該被使用,因此咱們如今須要一塊兒使用它。
有了以上信息,咱們能夠再次運行咱們的示例。此次咱們嘗試分配超過咱們分配的兩倍內存。它將使用全部的內存和全部的 swap,而後玩完了。
$ docker run -it --rm -m 128m stress --vm 1 --vm-bytes 260M --vm-hang 0 stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [1] (415) <-- worker 6 got signal 9 stress: WARN: [1] (417) now reaping child worker processes stress: FAIL: [1] (421) kill error: No such process stress: FAIL: [1] (451) failed run completed in 5s
若是你嘗試再次分配好比 250MB(--vm-bytes 250M),它將工做的很好。
警告:若是你不經過
-m開關限制內存,swap 也被不會被限制1。
不限制內存將致使將致使一個容器能夠很容易使得整個系統不可用的問題。所以請記住要一直使用 -m 參數2。
3.2 CGroups fs
你能夠在 /sys/fs/cgroup/memory/system.slice/docker-$FULL_CONTAINER_ID.scope/ 下面發現關於內存的全部信息,例如:
$ ls /sys/fs/cgroup/memory/system.slice/docker-48db72d492307799d8b3e37a48627af464d19895601f18a82702116b097e8396.scope/ cgroup.clone_children memory.memsw.failcnt cgroup.event_control memory.memsw.limit_in_bytes cgroup.procs memory.memsw.max_usage_in_bytes memory.failcnt memory.memsw.usage_in_bytes memory.force_empty memory.move_charge_at_immigrate memory.kmem.failcnt memory.numa_stat memory.kmem.limit_in_bytes memory.oom_control memory.kmem.max_usage_in_bytes memory.pressure_level memory.kmem.slabinfo memory.soft_limit_in_bytes memory.kmem.tcp.failcnt memory.stat memory.kmem.tcp.limit_in_bytes memory.swappiness memory.kmem.tcp.max_usage_in_bytes memory.usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.use_hierarchy memory.kmem.usage_in_bytes notify_on_release memory.limit_in_bytes tasks memory.max_usage_in_bytes
注意:想了解關於這些文件的更多信息,請移步到 RHEL Resource Management Guide, memory section。
4. 塊設備(磁盤)
對於 塊設備,咱們能夠考慮兩種不一樣類型的限制:
- 讀寫速率
- 可寫的空間 (定額)
第一個是很是容易實施的,可是第二個仍未解決。
注意:我假設你正在使用 devicemapper storage 做爲 Docker 的後端。使用其餘後端,任何事情都將不是肯定的。
4.1 限制讀寫速率
Docker 沒有提供任何的開關來定義咱們能夠多快的讀或是寫數據到塊設備中。可是 CGroups 內建了。它甚至經過 BlockIO* 屬性暴露給了 systemd。
爲了限制讀寫速率咱們能夠分別使用 BlockIOReadBandwidth 和 BlockIOWriteBandwidth 屬性。
默認 bandwith 是沒有被限制的。這意味着一個容器可使得硬盤」熱「,特別是它開始使用 swap 的時候。
4.2 示例:限制寫速率
讓我測試沒有執行限制的速率:
$ docker run -it --rm --name block-device-test fedora bash bash-4.2# time $(dd if=/dev/zero of=testfile0 bs=1000 count=100000 && sync) 100000+0 records in 100000+0 records out 100000000 bytes (100 MB) copied, 0.202718 s, 493 MB/s real 0m3.838s user 0m0.018s sys 0m0.213s
花費了 3.8秒來寫入 100MB 數據,大概是 26MB/s。讓咱們嘗試限制一點磁盤的速率。
爲了能調整容器可用的 bandwitch,咱們須要明確的知道容器掛載的文件系統在哪裏。當你在容器裏面執行 mount 命令的時候,你能夠發現它,發現設備掛載在 root 文件系統:
$ mount /dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88 on / type ext4 (rw,relatime,context="system_u:object_r:svirt_sandbox_file_t:s0:c447,c990",discard,stripe=16,data=ordered) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) tmpfs on /dev type tmpfs (rw,nosuid,context="system_u:object_r:svirt_sandbox_file_t:s0:c447,c990",mode=755) [SNIP]
在咱們的示例中是 /dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88。
你也可使用 nsenter 獲得這個值,像這樣:
$ sudo /usr/bin/nsenter --target $(docker inspect -f '{{ .State.Pid }}' $CONTAINER_ID) --mount --uts --ipc --net --pid mount | head -1 | awk '{ print $1 }'
/dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88
如今咱們能夠改變 BlockIOWriteBandwidth 屬性的值,像這樣:
$ sudo systemctl set-property --runtime docker-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88.scope "BlockIOWriteBandwidth=/dev/mapper/docker-253:0-3408580-d2115072c442b0453b3df3b16e8366ac9fd3defd4cecd182317a6f195dab3b88 10M"
這應該把磁盤的速率限制在 10MB/s,讓咱們再次運行 dd:
bash-4.2# time $(dd if=/dev/zero of=testfile0 bs=1000 count=100000 && sync) 100000+0 records in 100000+0 records out 100000000 bytes (100 MB) copied, 0.229776 s, 435 MB/s real 0m10.428s user 0m0.012s sys 0m0.276s
能夠看到,它花費了 10s 來把 100MB 數據寫入磁盤,所以這速率是 10MB/s。
注意:你可使用
BlockIOReadBandwidth屬性一樣的限制你的讀速率
4.3 限制磁盤空間
正如我前面提到的,這是艱難的話題,默認你每一個容器有 10GB 的空間,有時候它太大了,有時候不能知足咱們全部的數據放在這裏。不幸的是,咱們不能爲此作點什麼。
咱們能作的惟一的事情就是新容器的默認值,若是你認爲一些其餘的值(好比 5GB)更適合你的狀況,你能夠經過指定 Docker daemon 的 --storage-opt來實現,像這樣:
docker -d --storage-opt dm.basesize=5G
你能夠調整一些其餘的東西,可是請記住,這須要在後面重起你的 Docker daemon,想了解更多的信息,請看這裏。
4.4 CGroups fs
你能夠在 /sys/fs/cgroup/blkio/system.slice/docker-$FULL_CONTAINER_ID.scope/ 目錄下發現關於塊設備的全部信息,例如:
$ ls /sys/fs/cgroup/blkio/system.slice/docker-48db72d492307799d8b3e37a48627af464d19895601f18a82702116b097e8396.scope/ blkio.io_merged blkio.sectors_recursive blkio.io_merged_recursive blkio.throttle.io_service_bytes blkio.io_queued blkio.throttle.io_serviced blkio.io_queued_recursive blkio.throttle.read_bps_device blkio.io_service_bytes blkio.throttle.read_iops_device blkio.io_service_bytes_recursive blkio.throttle.write_bps_device blkio.io_serviced blkio.throttle.write_iops_device blkio.io_serviced_recursive blkio.time blkio.io_service_time blkio.time_recursive blkio.io_service_time_recursive blkio.weight blkio.io_wait_time blkio.weight_device blkio.io_wait_time_recursive cgroup.clone_children blkio.leaf_weight cgroup.procs blkio.leaf_weight_device notify_on_release blkio.reset_stats tasks blkio.sectors
注意:想了解關於這些文件的更多信息,請移步到 RHEL Resource Management Guide, blkio section。
總結
正如你所看到的,Docker 容器的資源管理是可行的。甚至很是簡單。惟一的事情就是咱們不能爲磁盤使用設置一個定額,這有一個上游問題列表 -- 跟蹤它而且評論。
但願你發現個人文章對你有用。
- 1. Docker資源管理
- 2. Docker Swarm資源管理
- 3. Kubernetes資源管理
- 4. Docker管理控制相關資源
- 5. 資源管理
- 6. Kubernetes資源管理之--資源預留
- 7. Kubernetes--Pod資源管理
- 8. k8s管理存儲資源
- 9. 95-280-035-源碼-資源管理-計算資源管理-TaskSlot
- 10. yarn資源管理
- 更多相關文章...
- • Docker 資源彙總 - Docker教程
- • Docker 倉庫管理 - Docker教程
- • Docker 清理命令
- • 使用阿里雲OSS+CDN部署前端頁面與加速靜態資源
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Docker資源管理
- 2. Docker Swarm資源管理
- 3. Kubernetes資源管理
- 4. Docker管理控制相關資源
- 5. 資源管理
- 6. Kubernetes資源管理之--資源預留
- 7. Kubernetes--Pod資源管理
- 8. k8s管理存儲資源
- 9. 95-280-035-源碼-資源管理-計算資源管理-TaskSlot
- 10. yarn資源管理