15 分鐘無門檻構建服務器性能監控系統
服務器監控是每一個互聯網廠商都重視而且想要儘量作好的事情,從數據收集、數據處理、數據可視化最終再到實時監控告警,這一系列複雜的流程可能耗費企業大量的人力和時間,以致於某些時候由於其複雜性高沒法達到預期的監控效果。而當事故發生時才發現,因爲監控體系的不完善形成了不少沒必要要的損失, 讓咱們追悔莫及。php
爲了解決企業的此類煩惱,七牛雲推出了快速構建服務器性能監控報警的解決方案。七牛雲開源的日誌/信息採集工具 logkit 配合七牛雲 Pandora 大數據工做流引擎和時序數據庫服務,能夠方便地對大量服務器的海量性能指標數據進行全方位監控。而整個部署和使用的流程,您完總體驗的時間僅需15分鐘。node
監控的內容
logkit 目前收集的機器性能指標主要包括十大模塊, 上百個指標nginx
system模塊: 監控load1、load5、load15、用戶數、cpu 核數以及系統啓動時間等.processes模塊: 監控處於各類狀態的進程數量, 好比運行中/暫停/可中斷/空閒/掛起等狀態的進程數量等等.netstat: 監控處於各類狀態的網絡鏈接數, 好比syn send/syn recv等狀態的網絡鏈接數.net: 監控網絡設備的狀態,好比收發包的數量、收發包的字節數等.mem: 監控內存的實時狀態.swap: 監控 swap 分區的狀態,好比換入、換出、使用率、空閒大小等.cpu: 監控 CPU 的實時狀態,包括cpu 用量,中斷時間佔比等.kernel: 監控內核中斷次數、上下文切換次數、fork 的進程數等.disk: 監控磁盤的使用狀況, 包括磁盤用量、inode 使用狀況等.diskio: 監控磁盤讀寫狀態, 包括讀寫次數、總用時等.
各項指標的詳細介紹請參考 logkit 系統信息採集模塊介紹和配置git
監控效果圖
部署完成後,您能夠直接載入咱們爲您構建的監控模板,最終看到的效果圖以下。github
1. 模板變量
模板變量能夠起到過濾數據的做用, 好比經過hostname這個模板變量能夠具體查看某臺特定的服務器上的metric信息,這樣即便有數十上百臺機器您也能夠輕鬆管理。一樣的,對於某臺機器的一些具體的資源,如磁盤、CPU、網卡等等,也有相應的模板變量能夠選擇。 數據庫

2. 全局概覽
全局信息概覽能夠看到服務器的一些基本信息,好比系統 load 值、內存使用率、磁盤使用率、網絡帶寬等。以最直觀的方式全局把控整個系統的運行狀態,方便在基礎資源不夠時及時發現、及時處理。 json

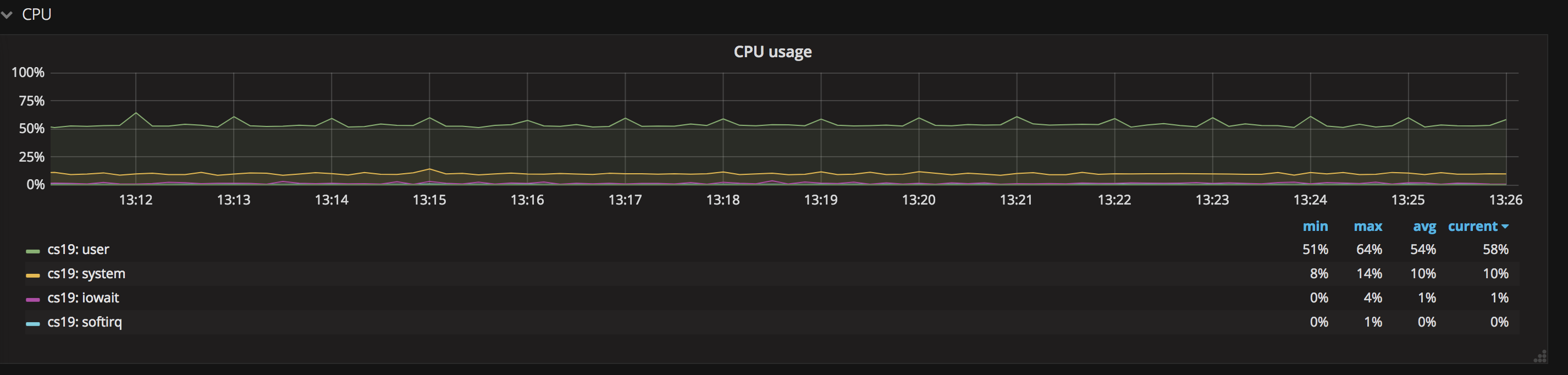
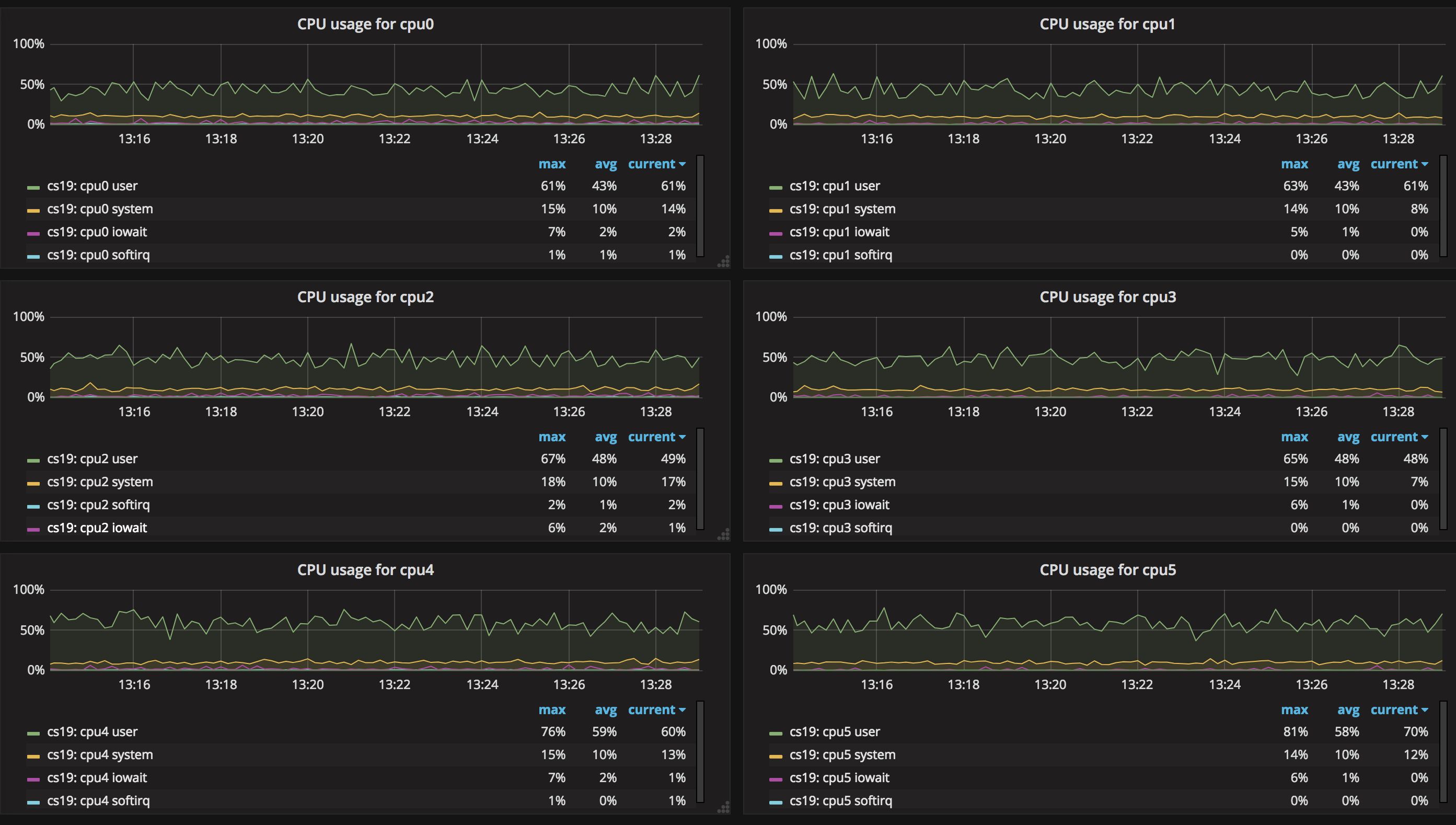
3. CPU Usage 信息
CPU Usage 顧名思義,就是指 CPU 的使用率,經過這幅圖能夠看到系統中 user、system 等對於系統 CPU 資源的佔用狀況。當 CPU 使用率較高且總體運行平穩時,說明您的業務很是健康;若 CPU 的用量曲線波動較大,那就說明服務有能夠優化的地方,或者能夠添加報警,在業務高峯時及時添加資源。 瀏覽器
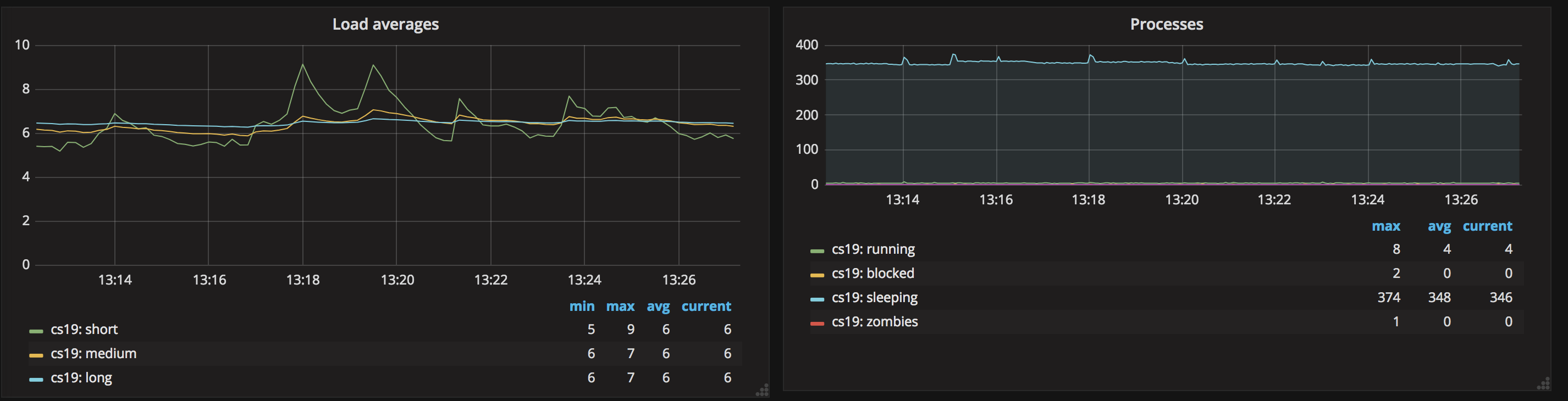
4. 系統 load 值與進程
在這張圖中你能夠看到不一樣的統計時間段中系統的負載狀況,能夠根據負載大小設置告警閾值。同時也能夠看到對應的進程數量, 如運行的進程數、在休眠中的進程數,而且能夠看到值得關注的一些異常進程,如殭屍進程(zombies)以及被阻塞的進程(blocked)。當存在殭屍進程時說明存在服務異常,須要及時關注並處理。 緩存
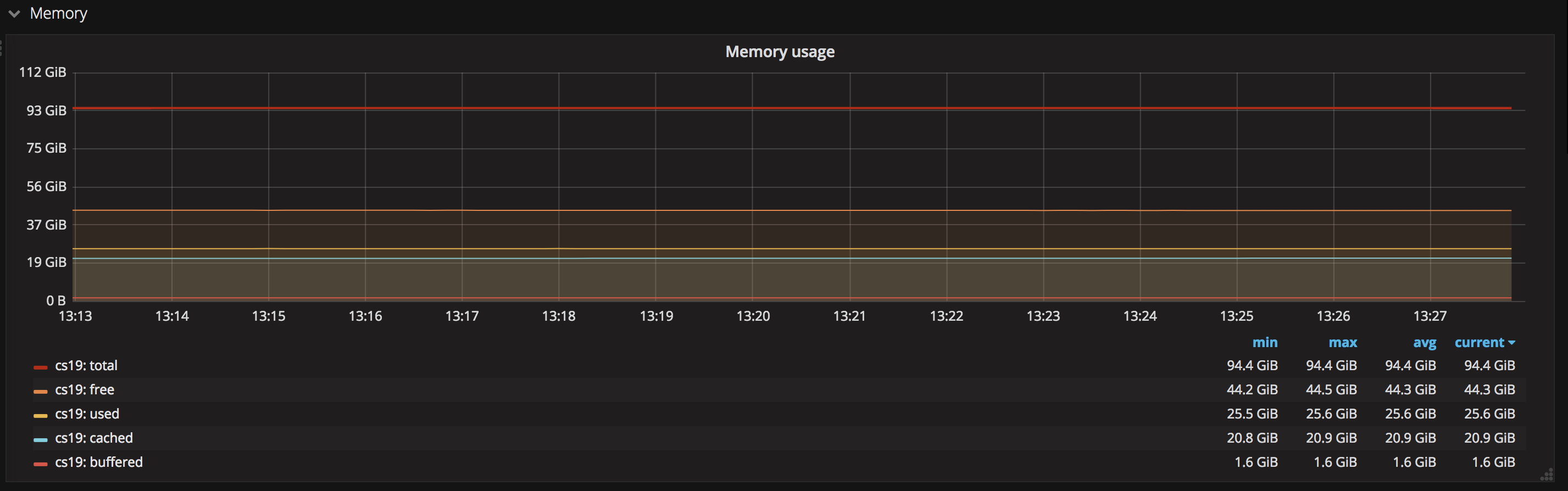
5. 內存用量
經過這張圖能夠看到總內存(total)、已使用內存(used)、空閒內存(free)等信息, 同理, 也能夠針對這些信息設置告警,及時發現系統性能短板。另外一方面要注意,當系統free的內存少或接近零,而cache部分的內存多時,說明這部分業務對內存緩存較爲依賴,雖然服務仍然能夠正常運行,但此時極有可能程序無法最大限度利用內存緩存, 致使性能出現了問題。 bash
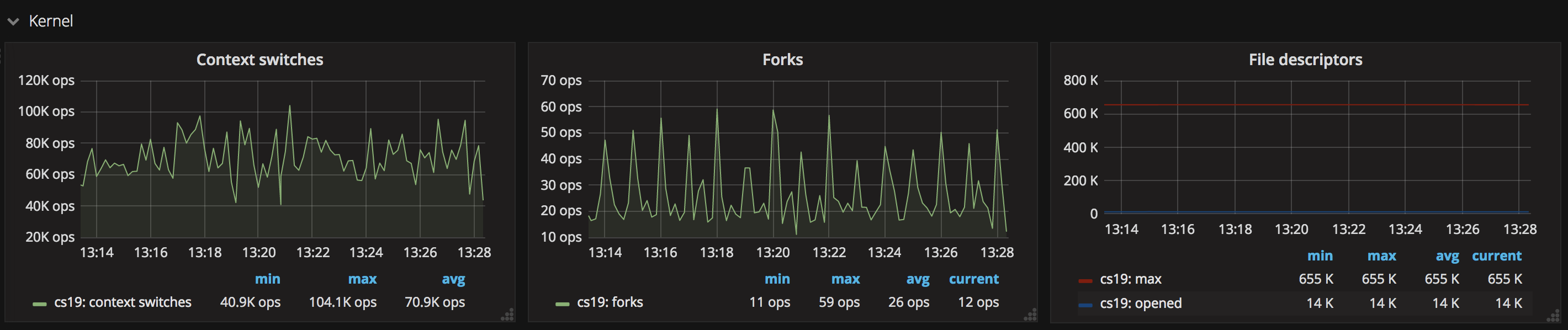
6. kernel 信息
kernel 基本信息中能夠看到內核的上下文切換(context switch)、 fork 的進程數(forks)、 已打開(opened)/最大(max)句柄數等信息。一般狀況下服務器打開的句柄數都有一個上限,超過了這個限制服務就會出現問題,而服務器的高併發訪問極有可能致使打開的句柄數過多,實時監控句柄數有助於查看服務運行情況。
7. CPU 的狀態
在這張圖中能夠看到服務器中各個的CPU的狀態,是對於 CPU Usage 的詳細拓展。CPU 是一種彈性資源,即便使用量達到 100% 也不會出現直接的服務崩潰,可是極有可能致使服務響應變得極慢,密切關注 CPU 用量,並對於 CPU 設置報警監控也是運維必不可少的一環。
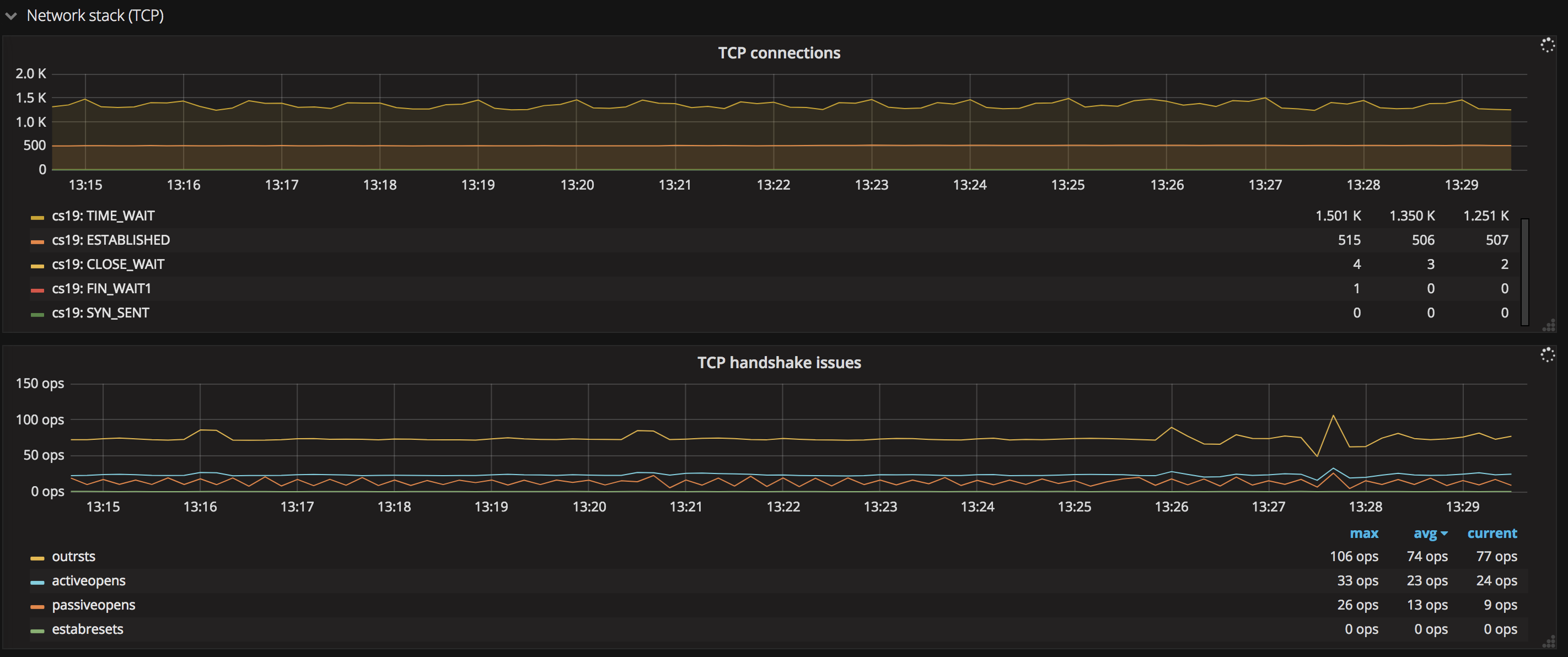
8. 網絡相關
- TCP
這張圖展現了系統中處於各個狀態的 TCP 鏈接數量,好比SYN SENT、FIN WAIT 等, 利用這些數據能夠及時發現請求的健康狀態,常見的如出現大量的FIN WAIT、CLOST WAIT等狀態的鏈接,說明出現了不少慢請求或鏈接有問題,須要排查,一般這一類指標能夠結合打開文件句柄數一同查看。
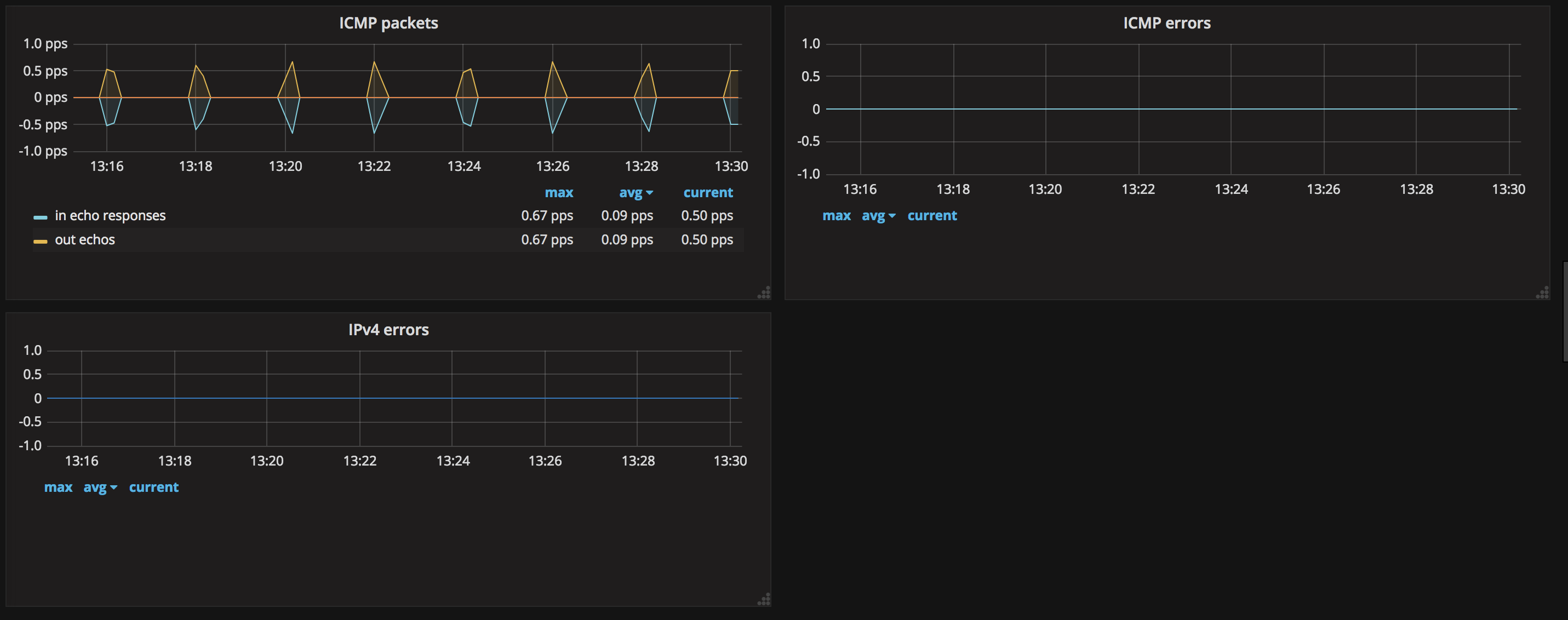
- ICMP、IPV4
這張圖中能夠看到 icmp、ipv4 等網絡協議的收發狀態。
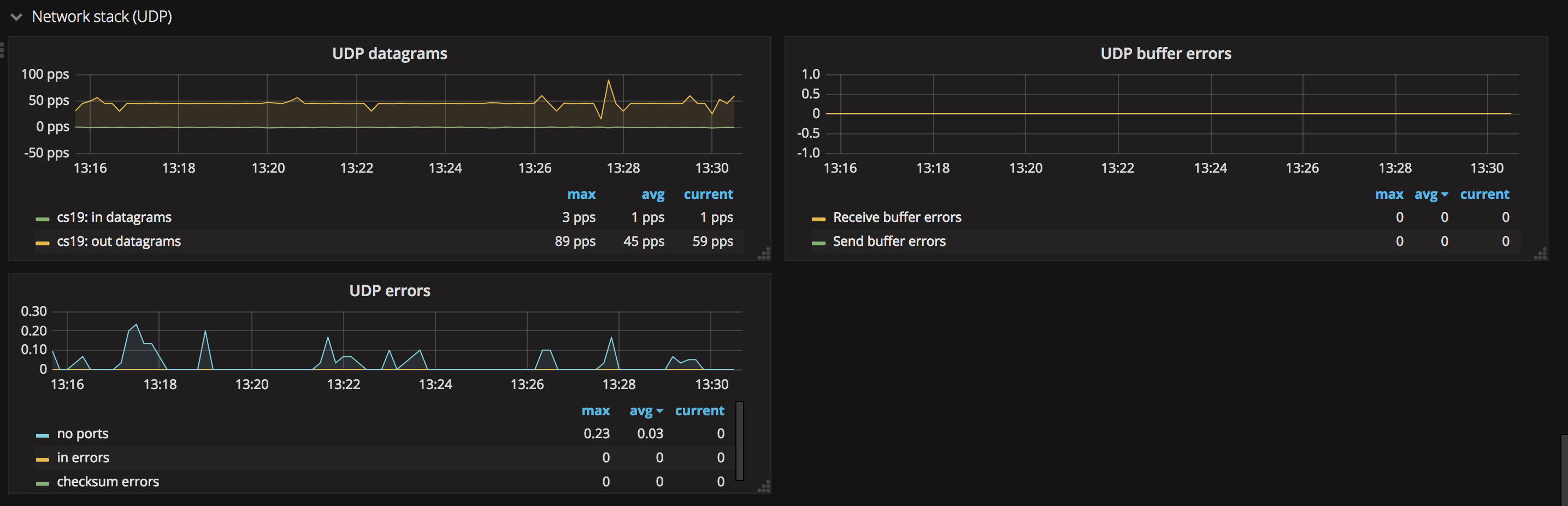
- UDP
這張圖中能夠看到 udp 數據報 以及 udp 錯誤數目等,如錯誤數過多,表示網絡情況不佳。
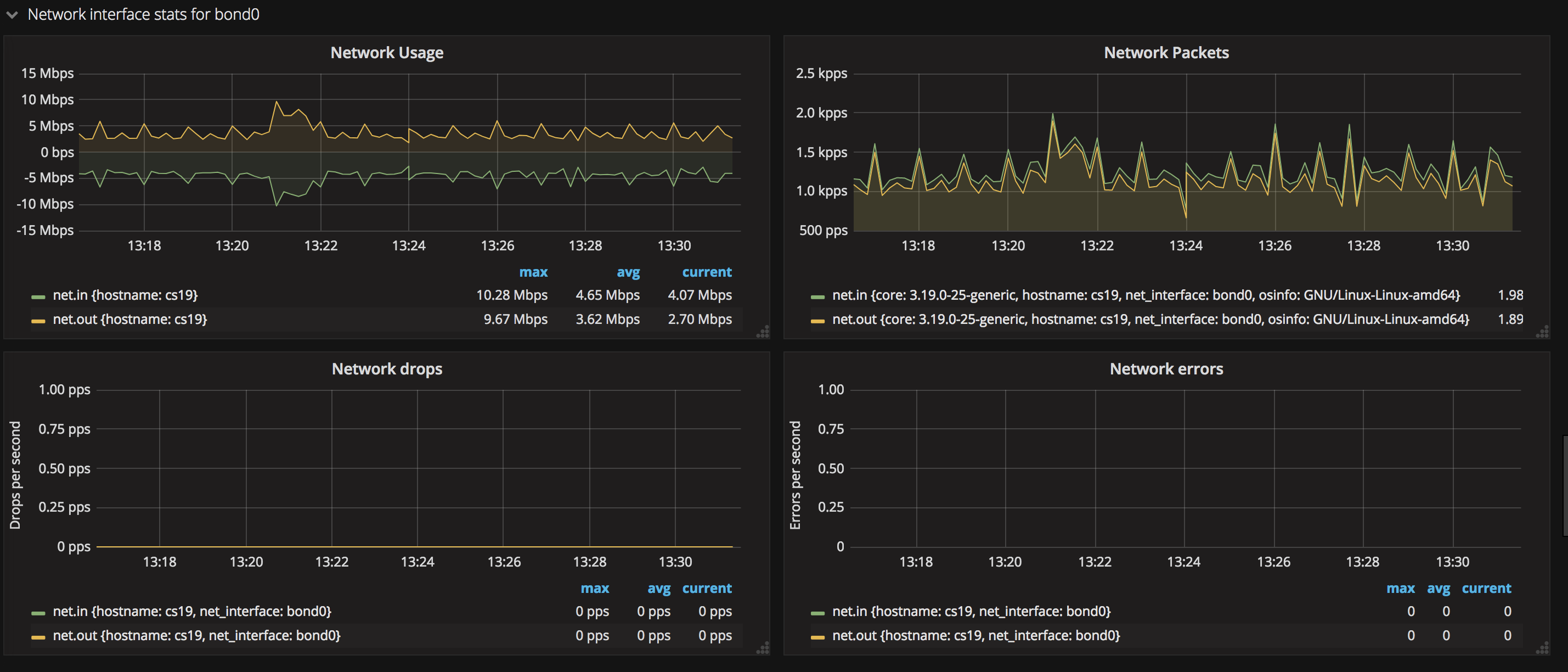
- 各個網卡的狀態
網卡狀態展現了包括網卡收發數據的速度(Network Usage)、收發包的速度(Network Packets)、丟包率(Network drops)以及出錯頻率(Network errors)等信息。
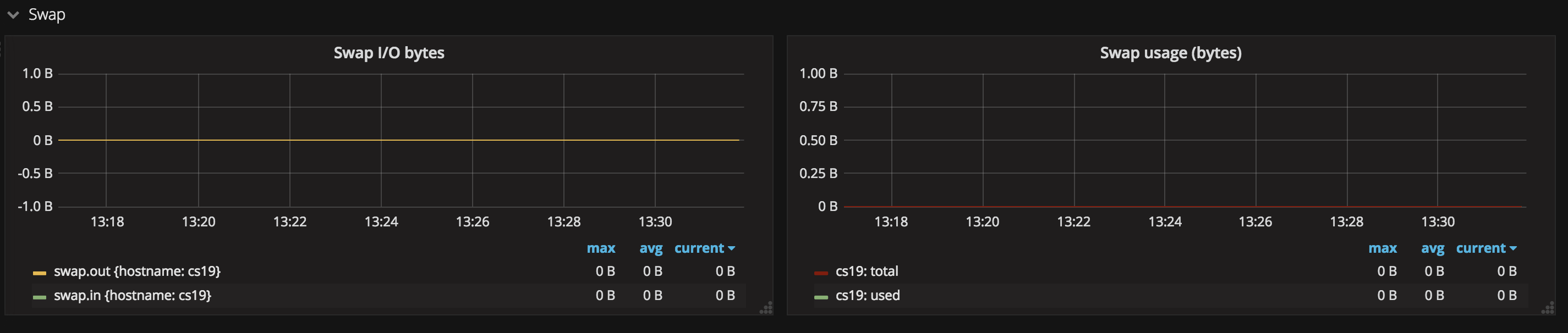
9. 交換分區狀態
這張圖展現了交換分區的換入換出狀態、交換分區的使用狀況等。
10. 磁盤用量
磁盤的重要性毋庸置疑,磁盤爆滿可能會對服務產生毀滅性打擊,無疑也是須要監控的重點。
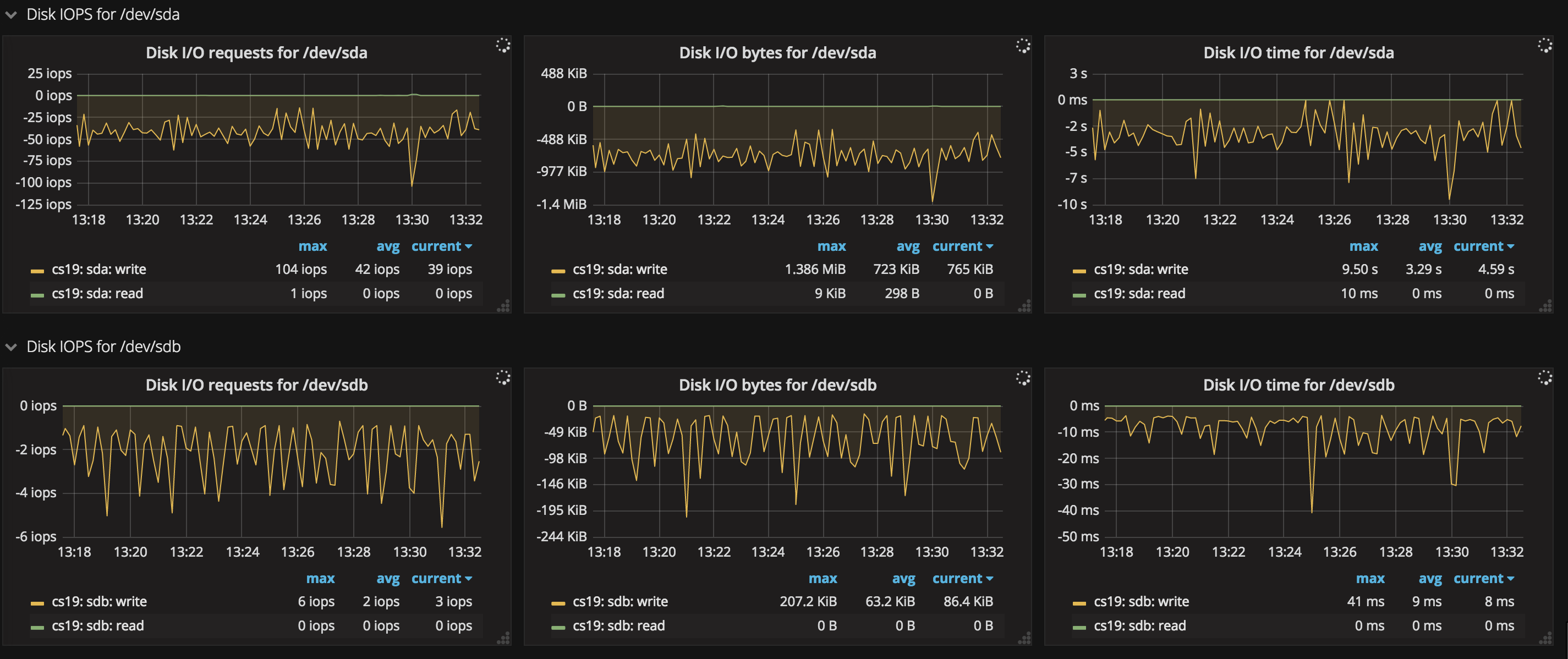
- 磁盤 IO
這張圖給出了當前各個磁盤的 IO 信息,包括磁盤請求頻率(Disk IO requests)、讀寫速度(Disk IO bytes)以及讀寫時間(Disk IO time)等,當磁盤 IO 太高時,也有可能存在性能問題,須要關注。
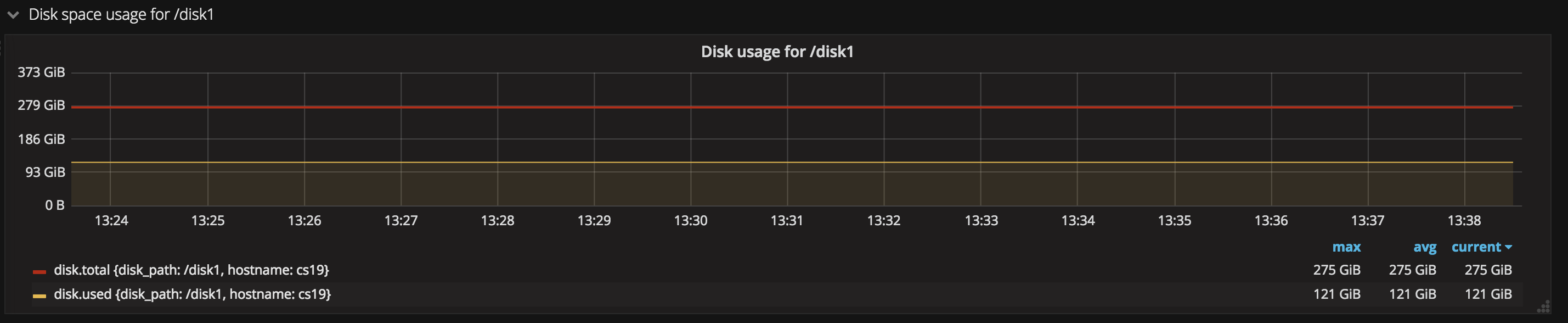
- 磁盤使用狀況
這張圖中能夠看到磁盤總空間(total)與已使用空間(used), 實時展示磁盤使用狀況,而且能夠設置告警機制,當磁盤的剩餘空間少於某個閾值時及時告警。
快速開始
下面就 Pandora 提供的組件來搭建一個運維監控應用,搭建這個應用只須要四步。
注意,爲了順利使用 Pandora 的各項服務,第一,須要一個已經實名認證的七牛帳戶;第二,申請開通 Pandora 的使用權限;
第一步:下載&啓動 logkit
從 logkit下載頁面 下載對應操做系統的 logkit 應用程序。logkit 的詳細配置能夠參考 logkit Wiki, 固然若是沒有特殊需求,只須要使用默認的配置便可。 啓動 logkit,輸入如下命令
./logkit -f logkit.conf
複製代碼
第二步:配置 metric 採集收集器
藉助 logkit 的可視化配置界面,能夠很方便的配置須要採集的 metric 信息,在瀏覽器中輸入配置的 url 訪問 logkit 管理中心(默認爲 http://127.0.0.1:3000)。
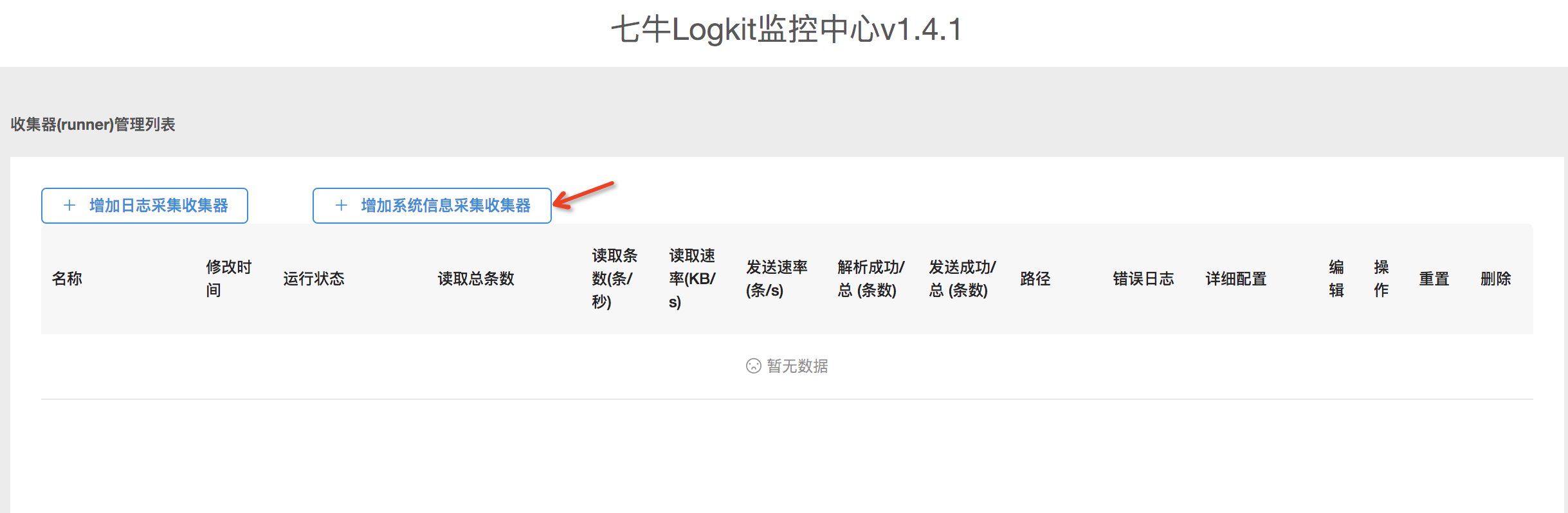
- 打開
logkit配置助手後,點擊增長系統信息採集收集器按鈕,進入編輯收集器頁面.
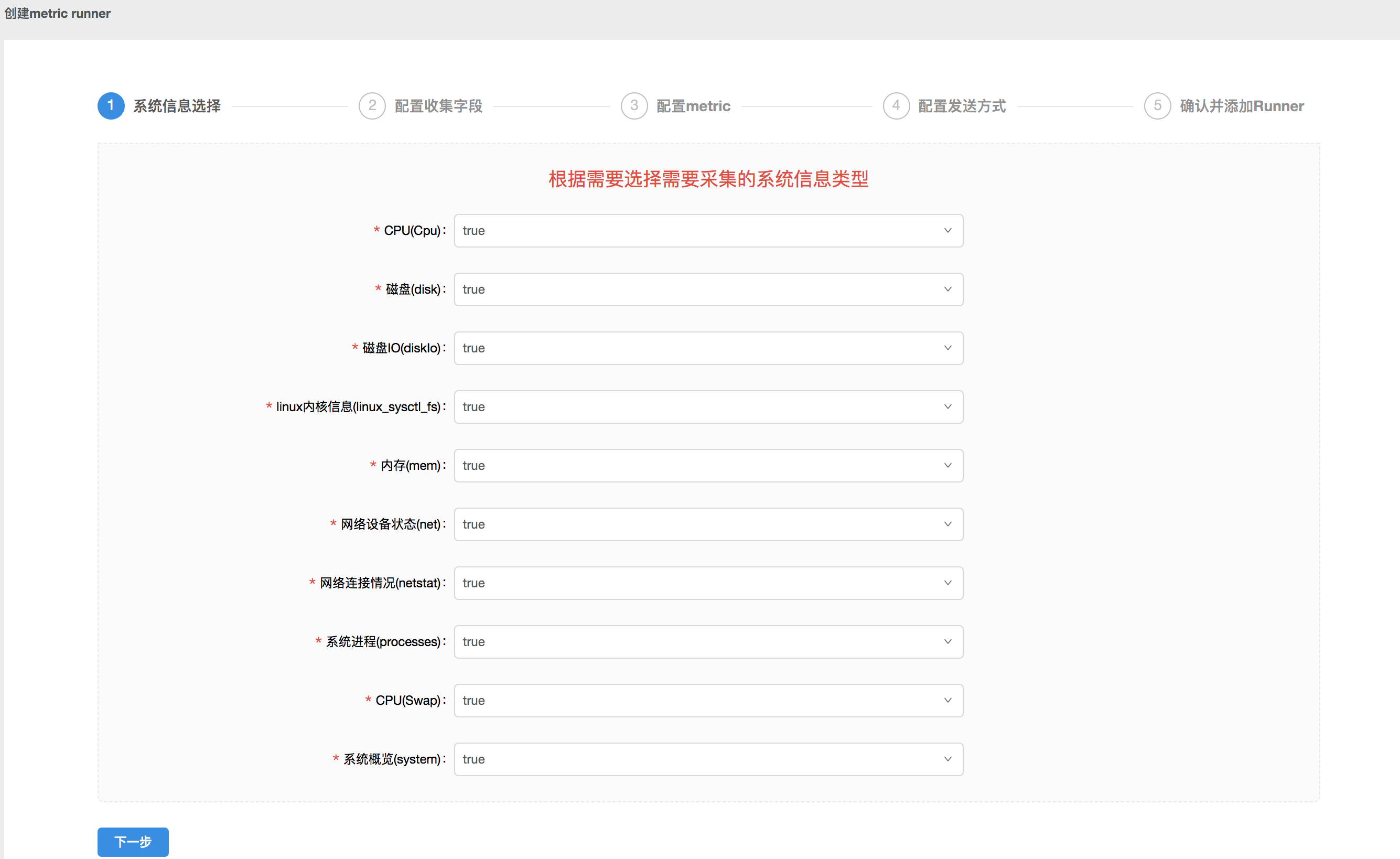
- 首先選擇要收集的 Metric 信息類型,默認收集所有信息,點擊下拉框能夠選擇再也不收集。
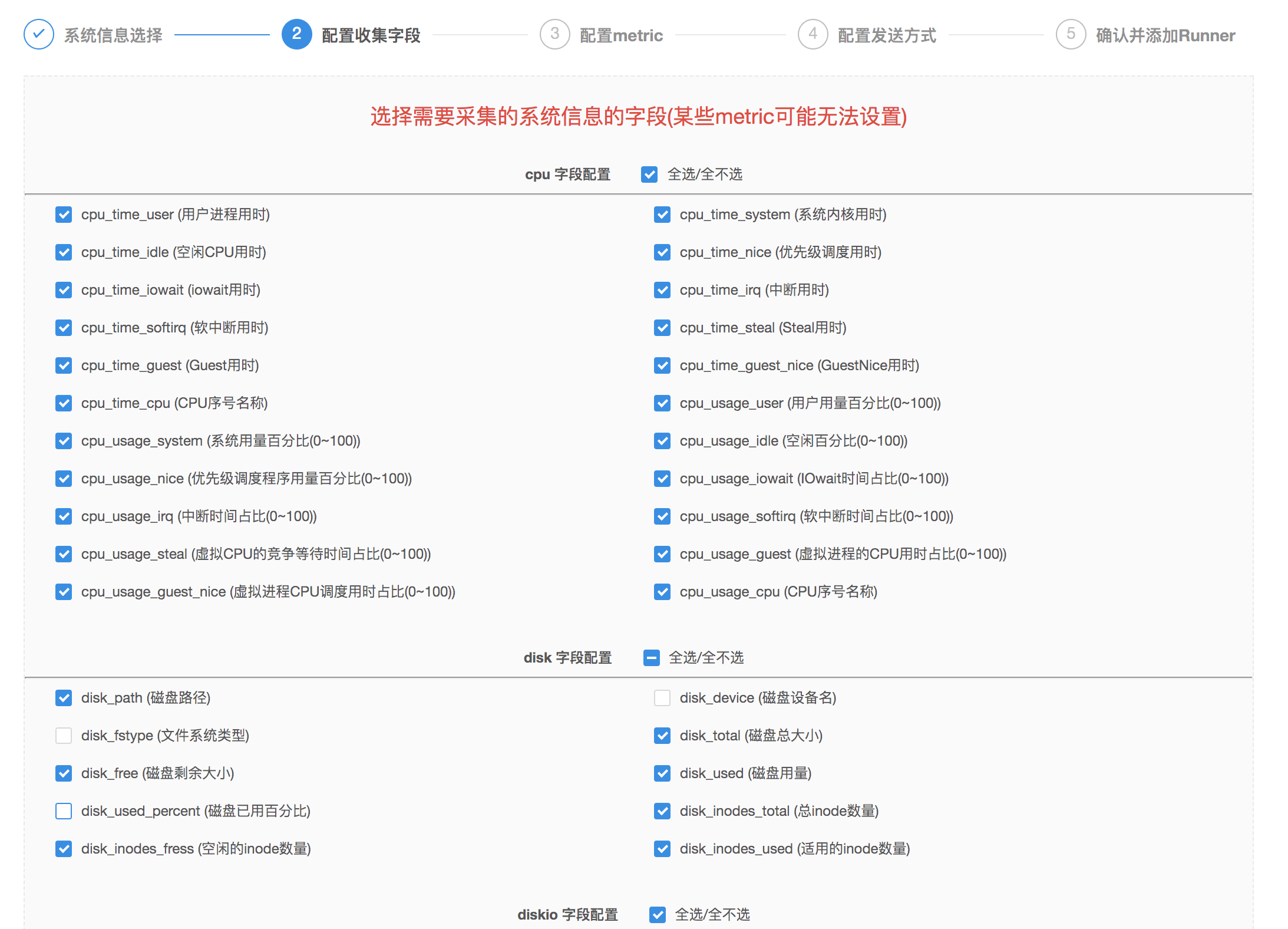
- 而後選擇每一個想要收集的
Metric的字段,經過「全選/全不選「按鈕能夠快速選中/取消選中全部的字段。注意:請至少爲每一個Metric信息選擇一個字段;
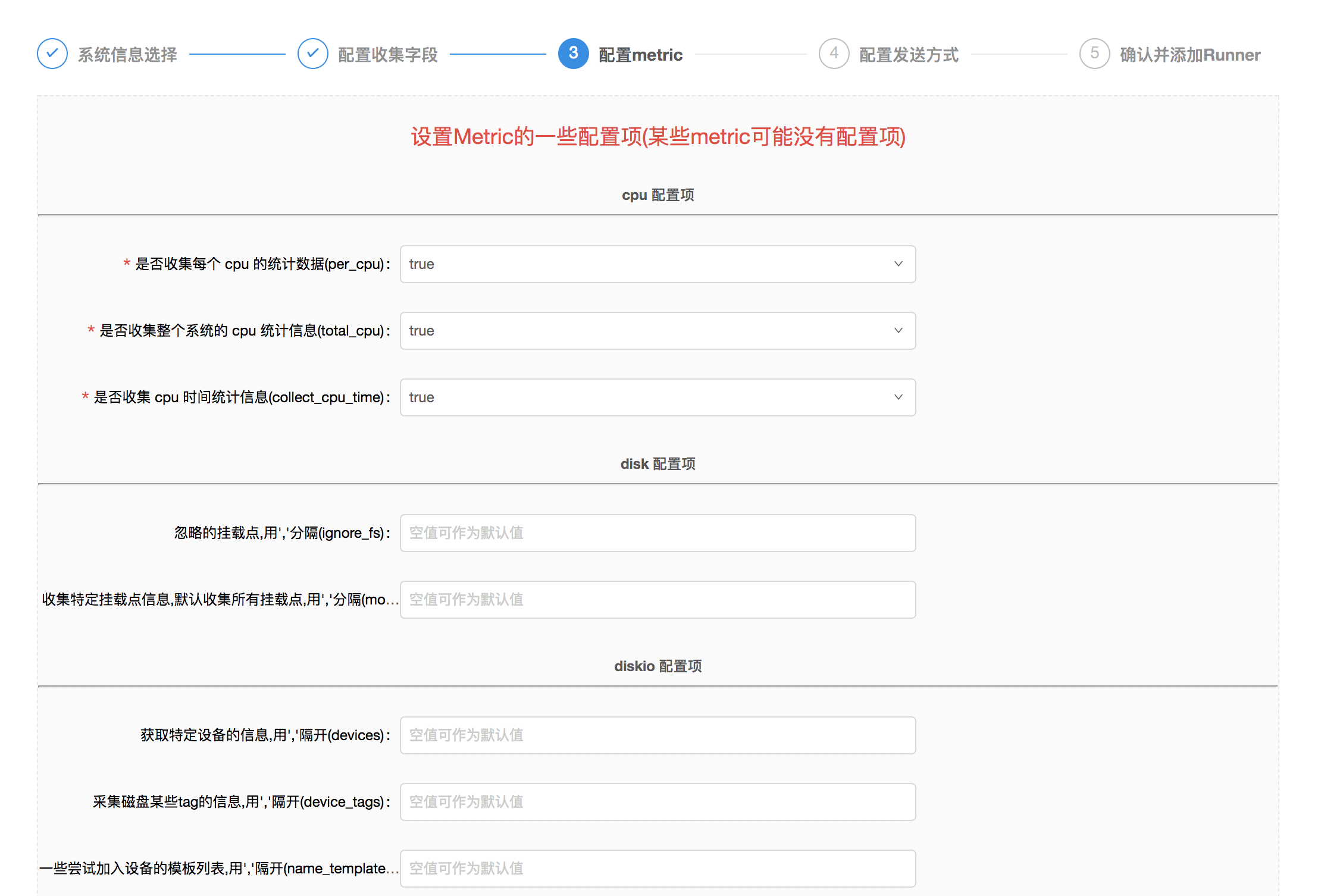
- 而後填寫相關
Metric的配置信息,注意:有些Metric沒有能夠填寫的配置,因此沒有顯示;
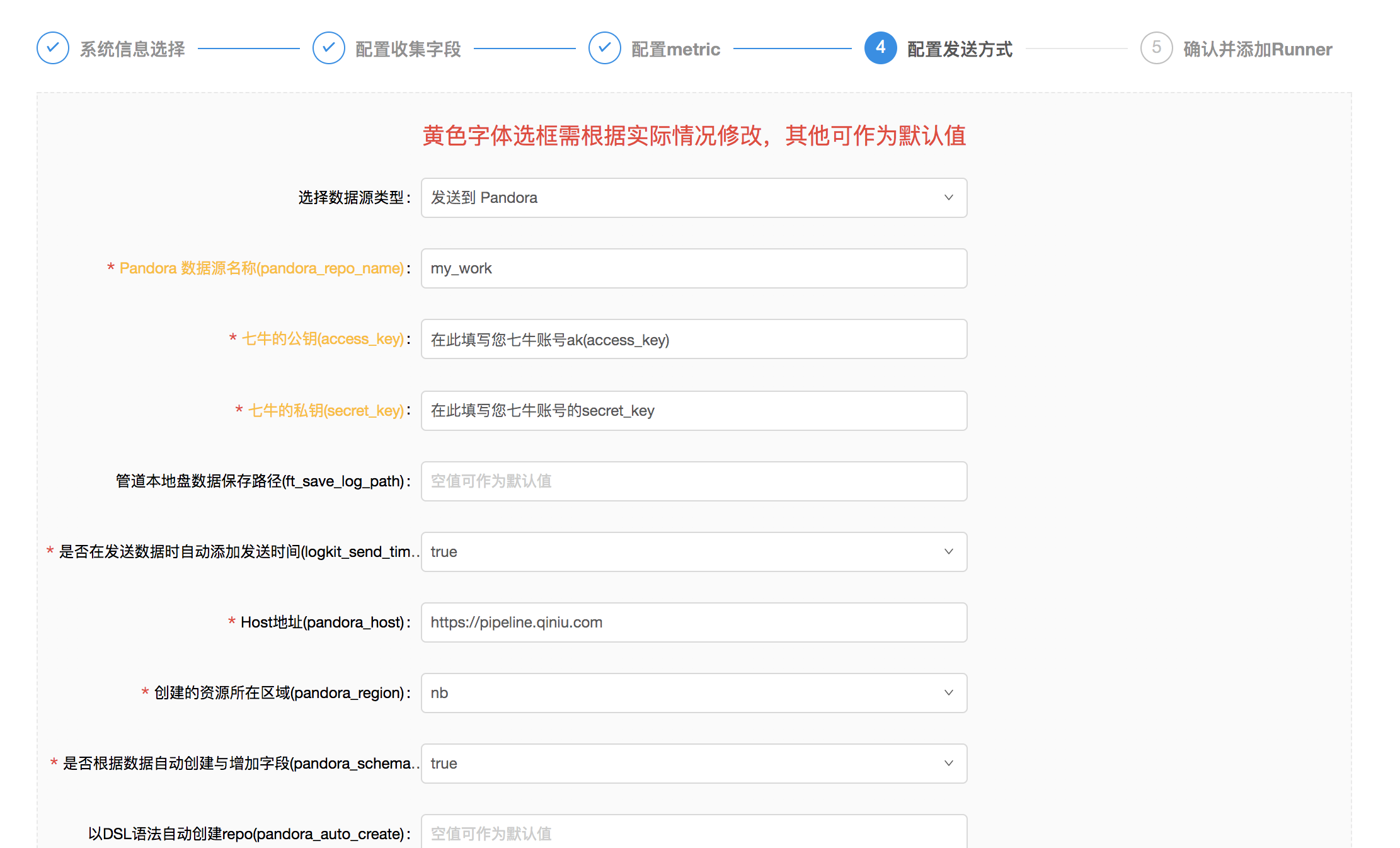
- 填寫發送的目的地,將數據發往
pandora平臺時,選擇pandora sender, 填入本身pandora帳號的ak/sk, 填入reponame,若是沒有特殊需求,其餘的選項可使用默認值, 詳細的sender信息,能夠參考Senders Wiki
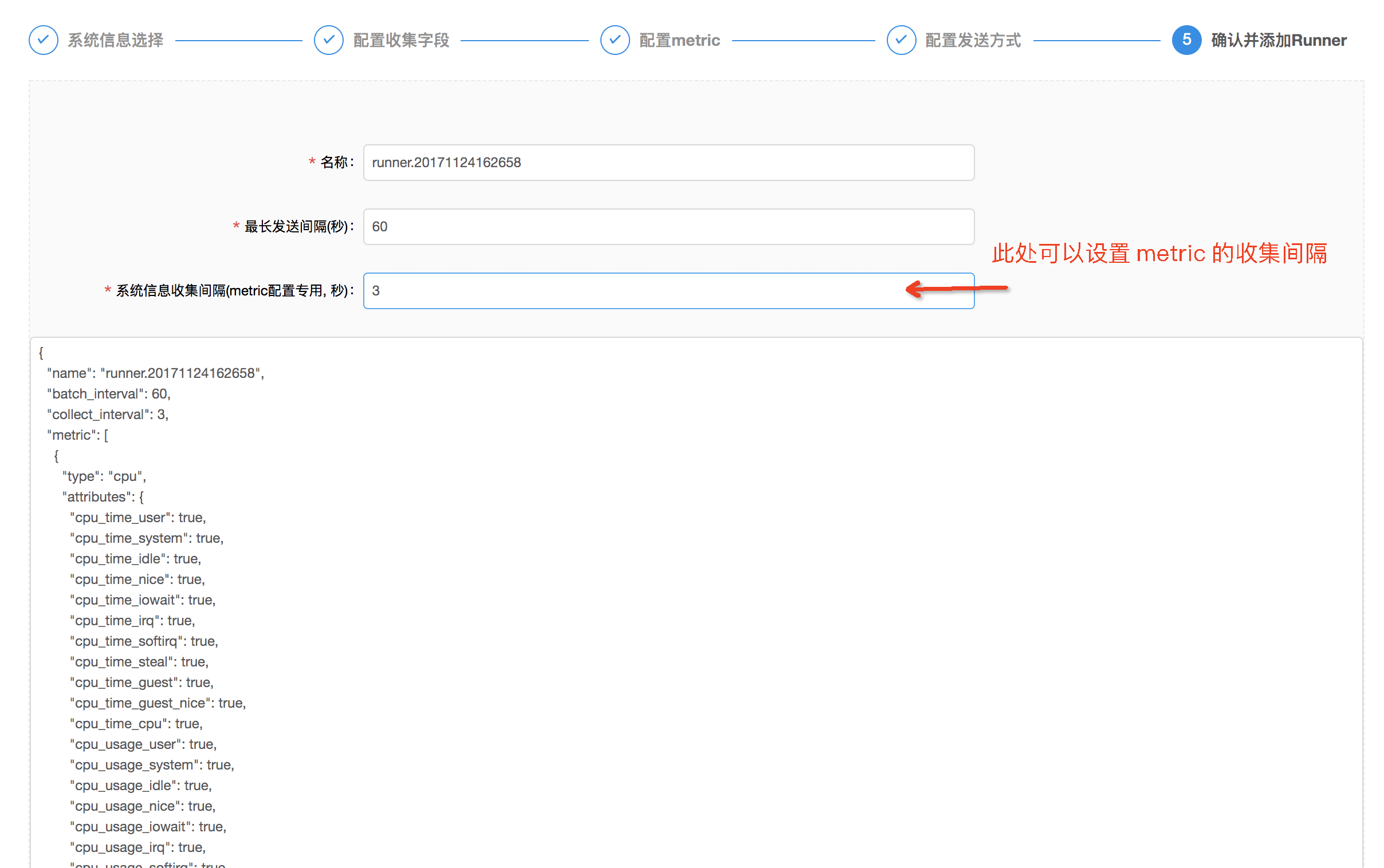
- 最後能夠瀏覽一下配置文件的內容,避免以前有忽略的錯誤,同時能夠自定義配置 metric 信息收集的頻率,默認是
3s
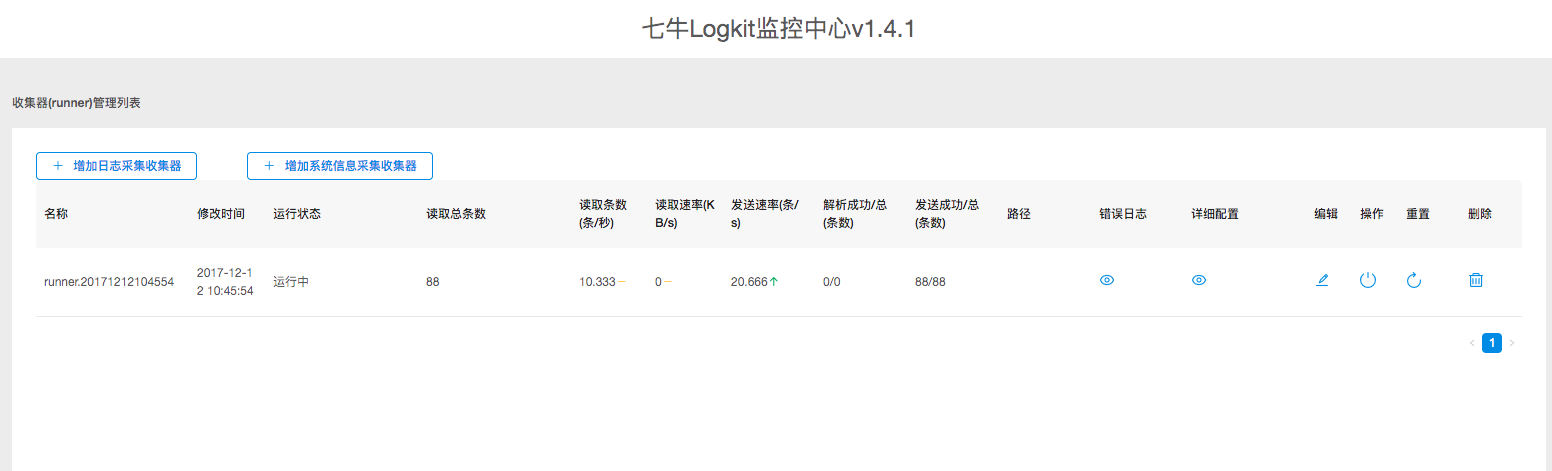
- 點擊「確認並提交「後,一條收集 metric 信息的 runner 就建立成功了。
第三步: 配置 Grafana 數據源
在七牛應用市場打開 Grafana 應用,而後按照如下步驟配置:
建立應用
1.首先登錄七牛 portal 的應用平臺 找到 Grafana
2.點擊當即部署按鈕開始建立 Grafana 應用
輸入您的 app 名和應用別名,選擇部署區域(注意!目前 TSDB 的數據在華東,因此 Grafana 只可部署在華東區域),點擊肯定建立
應用名稱:帳號內惟一應用名稱,且只能知足如下條件:(1. 只能包含字母、數字和減號,首尾字符只能爲字母或數字。 2. 字符長度不能超過 30) 應用別名:供顯示使用的標題名。
3.等待 app 啓動後,輸入密碼(密碼長度必須>=6),點擊 確認配置
注意,由於 Grafana App 具備公網域名,因此建議設置一個高強度的密碼(此密碼在進入 Grafana App 後能夠修改)。
4.訪問 Grafana 進入 Grafana 頁面
注意,該 Grafana App 是暴露在公網上的,可收藏地址用於後續訪問。
配置 TSDB 數據源
在 Grafana 中使用 Pandora TSDB 以前,咱們須要先添加數據源。
-
登陸 Grafana,點擊菜單中的 Data Sources
-
點擊 Add data source 按鈕
-
在
Name填入數據源的名字, Type 選擇 Pandora TSDB
-
填入相應參數,點擊添加按鈕便可 若是在上面
metric收集器的sender配置中沒有額外配置pandora_tsdb_reponame的話,此處的Name填寫上面配置的pandora_repo_name
注意: url 必須填入 http://localhost:8999
第四步: 導入 Grafana dashboard 配置文件
下載 Grafana dashboard 配置文件
下載配置文件模板 https://pandora-dl.qiniu.com/MetricMemo.json
將下載的 dashboard 導入 Grafana
至此,您就能夠看到一張酷炫的可視化運維監控圖啦,固然沒有報警的監控是不完整的,下面咱們配置一下監控的告警。
配置 Grafana 告警
就在Grafana上,咱們爲您提供了完善的報警功能。
-
設置 Grafana 報警的 Channel
-
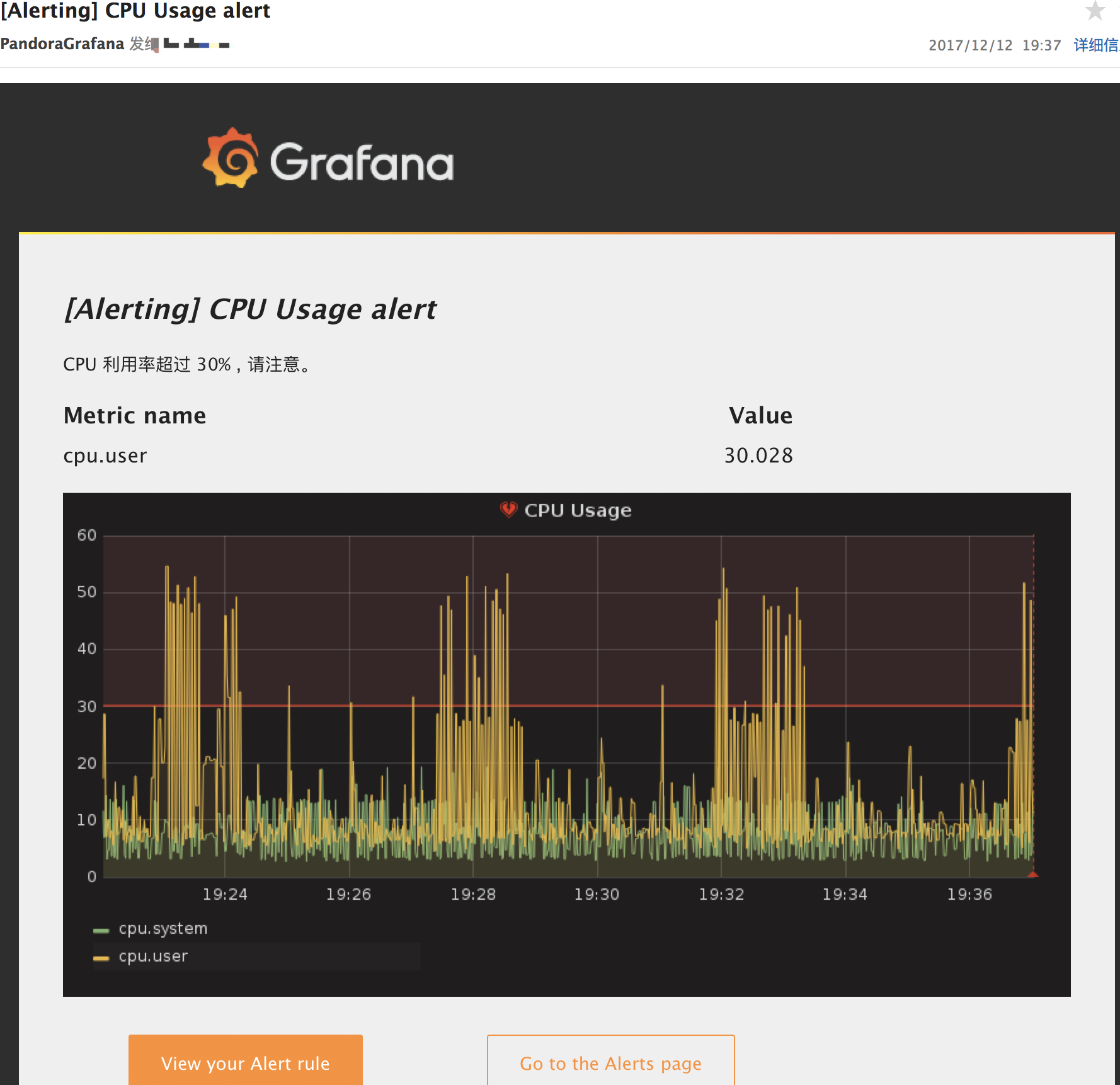
以
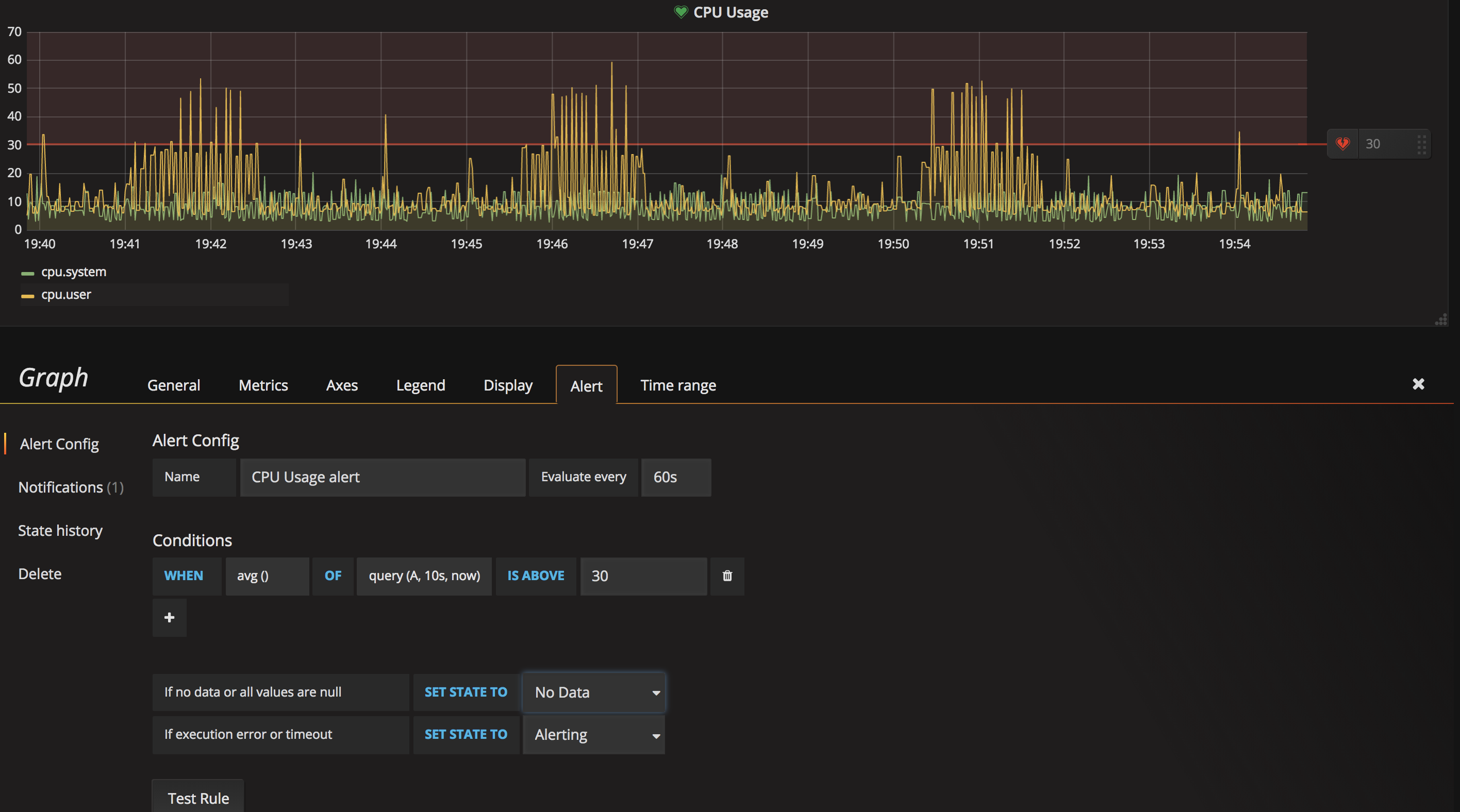
cpu usage高於 30% 發郵件報警爲例(僅作測試使用,實際生產環境使用時請結合實際狀況配置), 配置方法爲: 編輯相應的panel, 選擇Alert, 配置須要監控的查詢及其閾值。
-
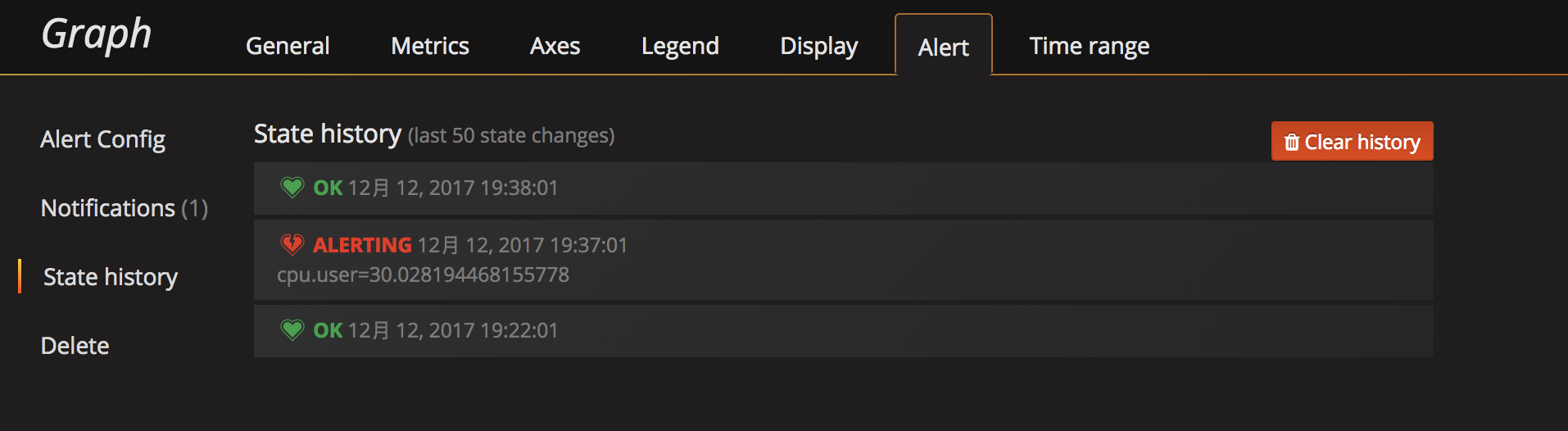
點擊
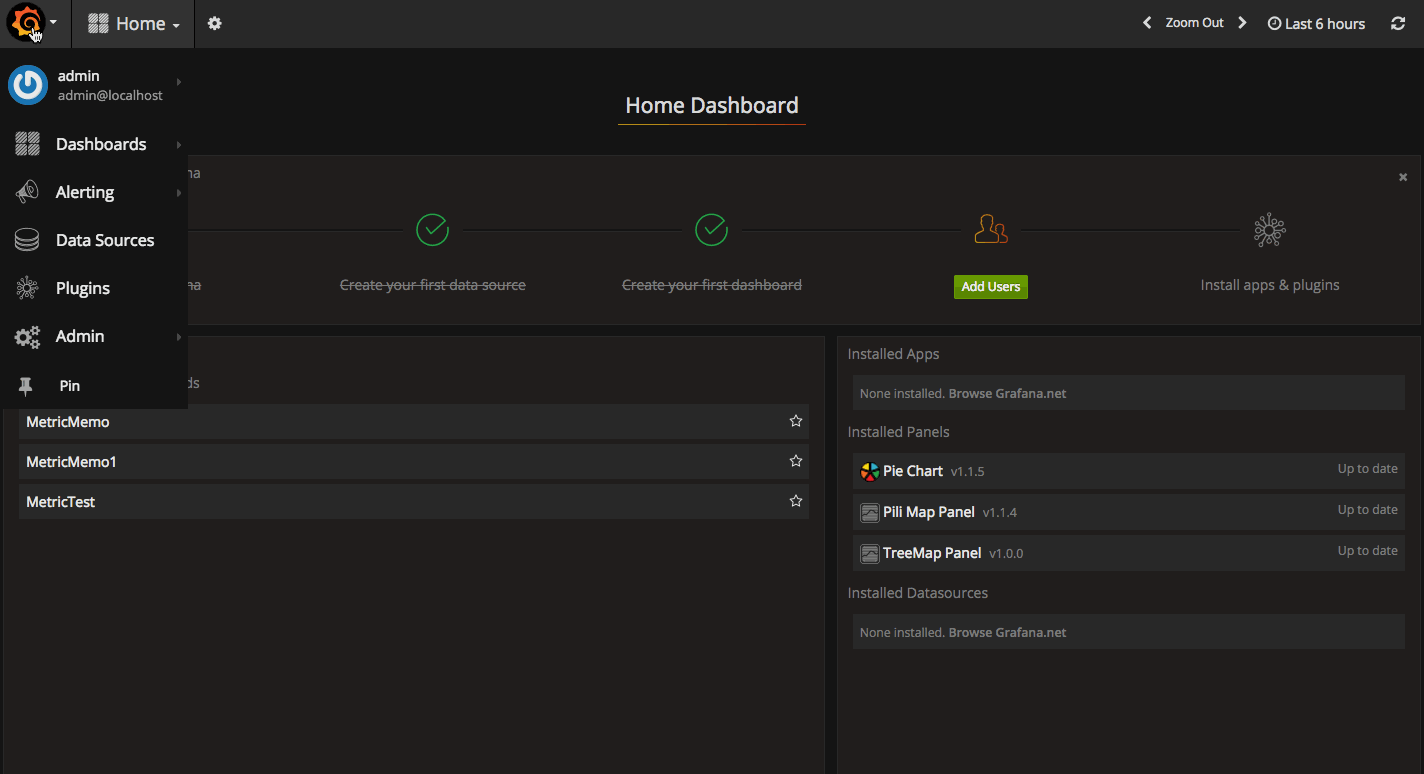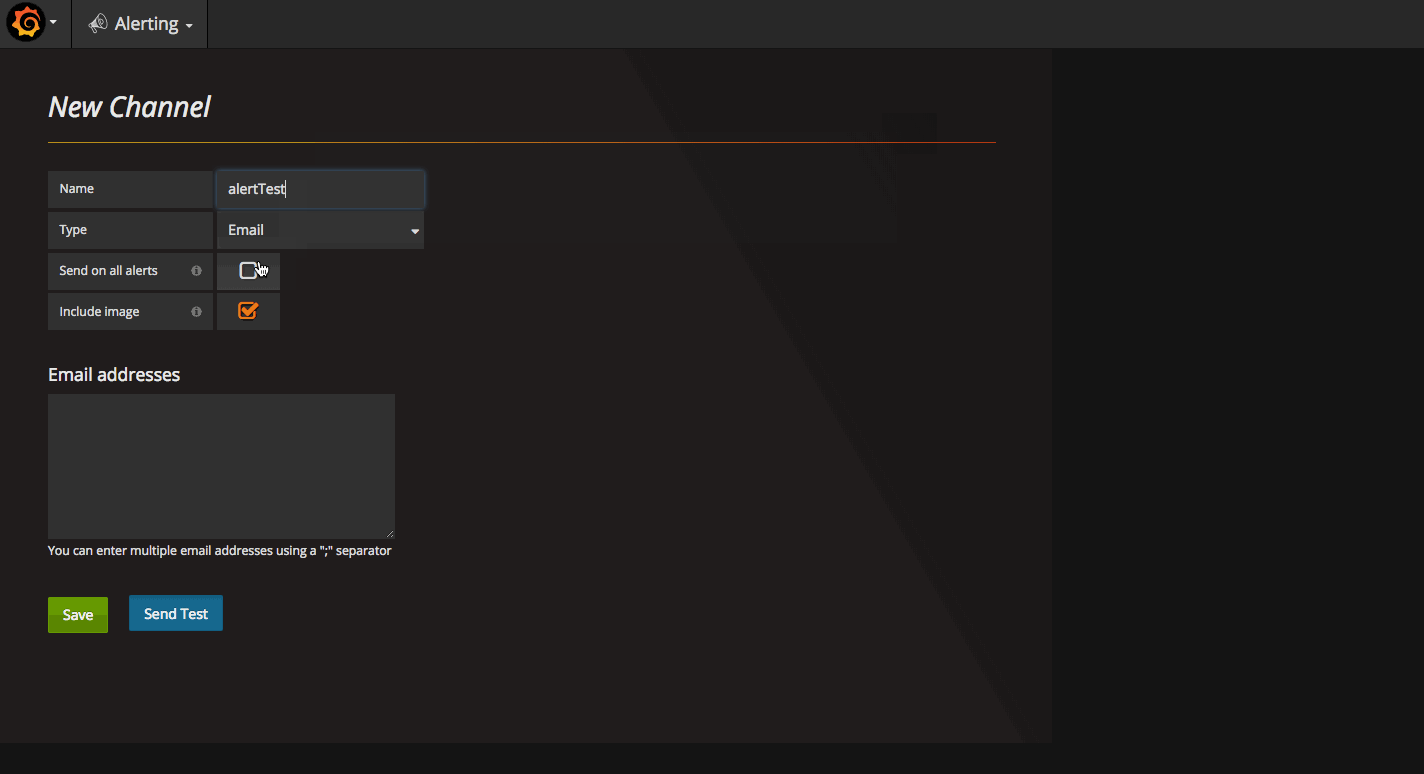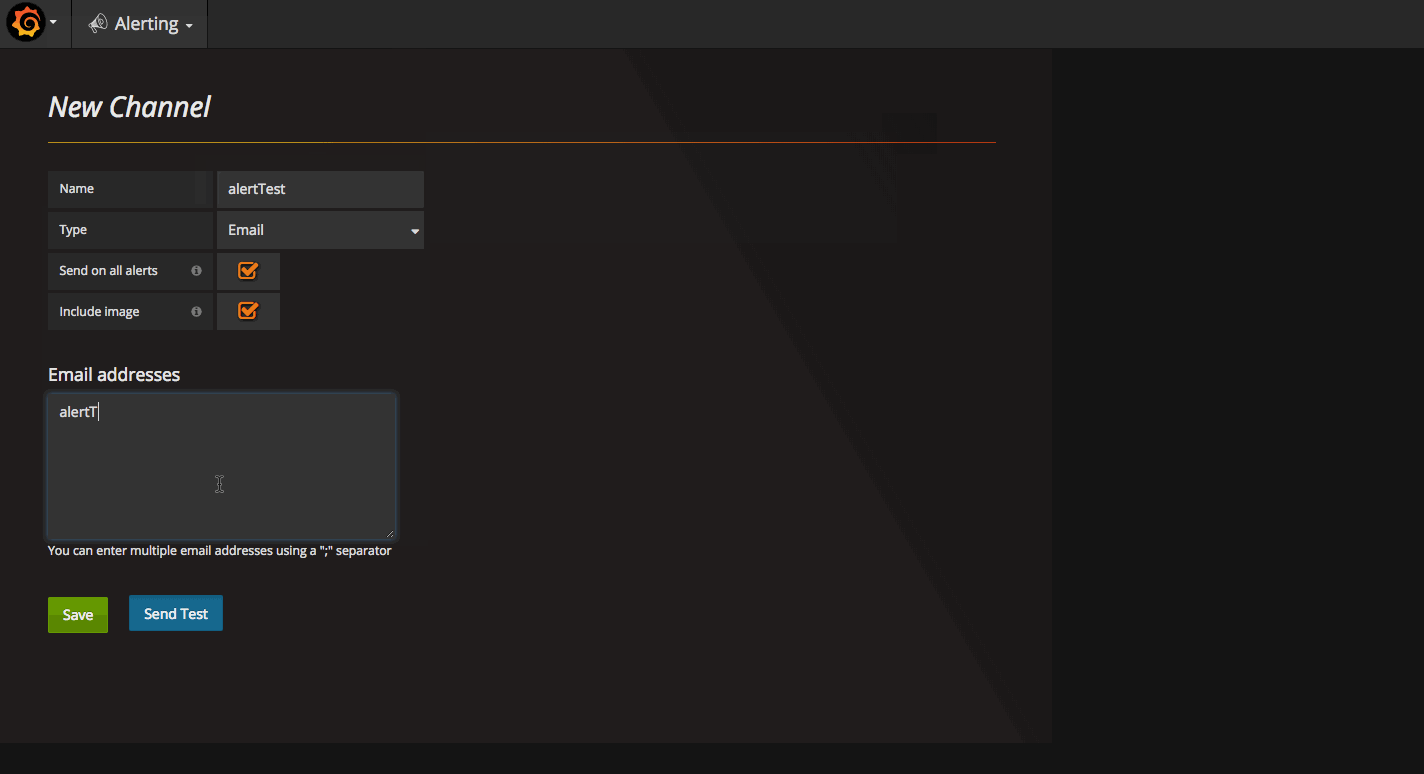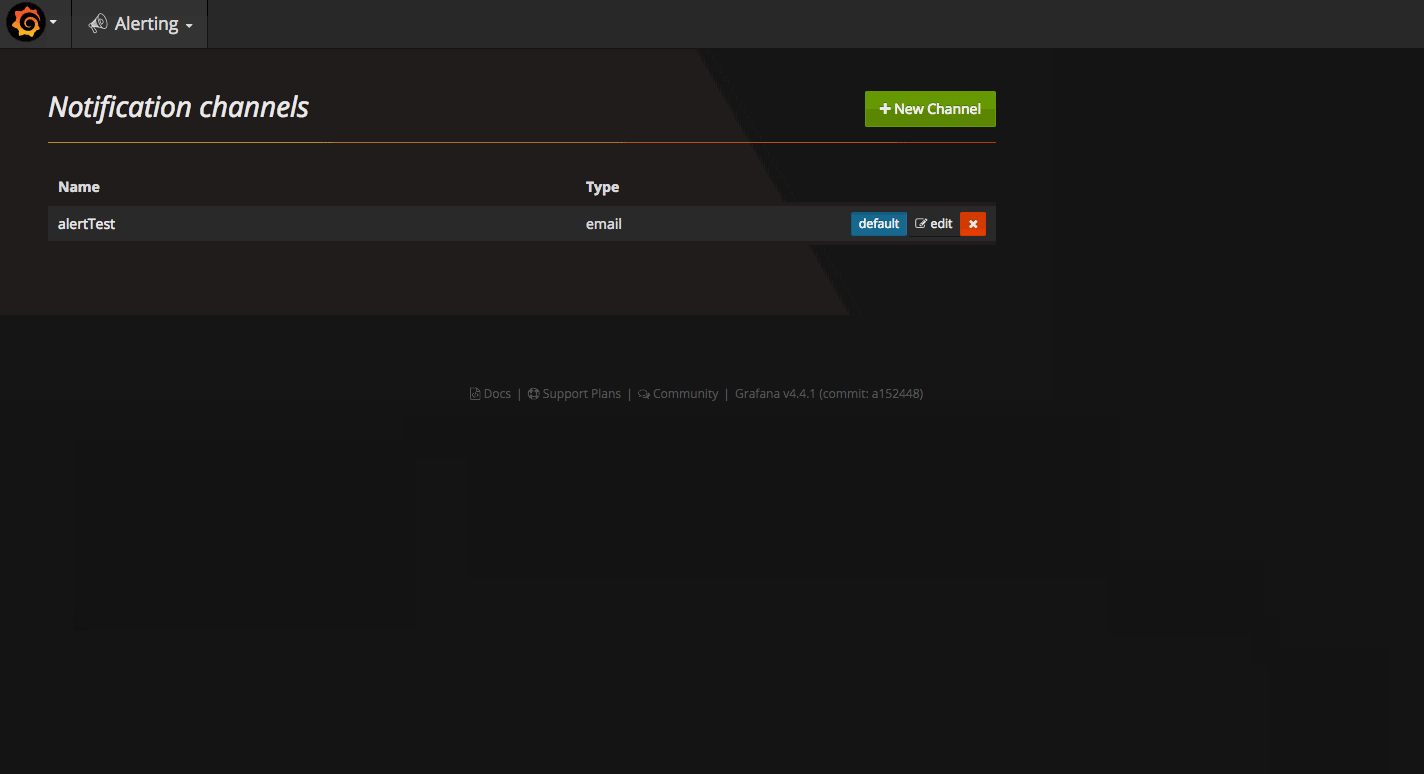
State history能夠看到報警歷史。
-
當有報警信息產生時,能夠收到報警郵件。
更多關於 Grafana 告警功能的配置能夠參考 Grafana 告警文檔
至此,一個詳細的服務器性能監控系統搭建完成啦,快去體驗吧!
附其餘高級用法
- 1. 【性能監控】 -使用LR監控windows系統服務器
- 2. JMeter監控服務器性能入門
- 3. 服務器性能監控
- 4. 性能監控與服務器監控
- 5. 掌控——構建Linux系統Nagios監控服務器
- 6. 監控寶服務器與服務性能監控配置
- 7. 5分鐘Serverless實踐:構建無服務器的圖片分類系統
- 8. Apache服務器性能監控
- 9. 服務器性能監控tips
- 10. 服務器性能監控命令
- 更多相關文章...
- • Git 服務器搭建 - Git 教程
- • ASP.NET Web Forms - HTML 服務器控件 - ASP.NET 教程
- • Docker容器實戰(七) - 容器眼光下的文件系統
- • Spring Cloud 微服務實戰(三) - 服務註冊與發現
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 「插件」Runner更新Pro版,幫助設計師遠離996
- 2. 錯誤 707 Could not load file or assembly ‘Newtonsoft.Json, Version=12.0.0.0, Culture=neutral, PublicKe
- 3. Jenkins 2018 報告速覽,Kubernetes使用率躍升235%!
- 4. TVI-Android技術篇之註解Annotation
- 5. android studio啓動項目
- 6. Android的ADIL
- 7. Android卡頓的檢測及優化方法彙總(線下+線上)
- 8. 登錄註冊的業務邏輯流程梳理
- 9. NDK(1)創建自己的C/C++文件
- 10. 小菜的系統框架界面設計-你的評估是我的決策
- 1. 【性能監控】 -使用LR監控windows系統服務器
- 2. JMeter監控服務器性能入門
- 3. 服務器性能監控
- 4. 性能監控與服務器監控
- 5. 掌控——構建Linux系統Nagios監控服務器
- 6. 監控寶服務器與服務性能監控配置
- 7. 5分鐘Serverless實踐:構建無服務器的圖片分類系統
- 8. Apache服務器性能監控
- 9. 服務器性能監控tips
- 10. 服務器性能監控命令