ELK 性能(4) — 大規模 Elasticsearch 集羣性能的最佳實踐
ELK 性能(4) — 大規模 Elasticsearch 集羣性能的最佳實踐
介紹
集羣規模node
- 集羣數:6
總體集羣規模:python
- 300 Elasticsearch 實例
- 141 物理服務器
- 4200 CPU 核心
- 38TB RAM
- 1.5 Pb 存儲
索引日誌:正則表達式
- 100 億/天
- 400k/秒
內容
開場白
健康提示apache
- 將 Elasticsearch 集羣的名稱 「elasticsearch」 進行重命名。當網絡內有兩個以上的集羣時,就會發現這樣作所帶來的好處。
爲了防止誤刪除,設置參數json
action.destructive_requires_name=true
- 始終使用 SSD 。這並非可選的。
- 須要至少 10G 的帶寬。
採用監護人制度,開發併發布本身的版本。緩存
擴展
擴展 Elasticsearch 集羣
影響到 Elasticsearch 集羣的因素
CPUruby
- 核心數 > 時鐘速度
內存服務器
- 文檔的數量
- 分片的數量
磁盤 I/O網絡
- SSD 持續寫的速率
網絡帶寬併發
- 至少 10G 的帶寬保證快速恢復與從新索引
影響到集羣內存的因素
- 段內存(segment memory):~4b RAM/文檔 = ~4Gb/10億行日誌
- 字段數據內存(field data memory):幾乎與段內存至關
- 過濾器緩存(filter cache):~1/4 到 1/2 的段內存,取決於搜索的內容
- 剩下的全部(50% 的系統內存)用做操做系統文件的緩存
- 沒法得到足夠的內存
影響到集羣I/O的因素
- SSD 持續寫速率
- 計算片恢復的速度(假設一個節點失敗):
- 片大小(Shard Size)=(日存儲量 / 分片的數量)
- (每一個節點上分片的數量 * 片大小)/ (磁盤寫速度 / 節點分片的數量)
- 例如:30Gb 分片,每一個節點 2 個分片,250Mbps 的寫速度:
- (2 * 30Gb)/ 125Mbps = 8 mintues
- 恢復彈性所能忍受的時間
- 能夠忍受失去多少節點
- 一臺服務器多個節點會增長恢復所需的時間
影響到網絡的因素
- 10G 至少
- 10 分鐘恢復 vs 50+ 分鐘恢復
- 1G 瓶頸:網絡上線
- 10G 瓶頸:磁盤速度
擴展 Logstash 集羣
擴展 Logstash 的 CPU
- 規則 1:買所能承受的儘量快的 CPU 核心
- 規則 2:參見第一條
- 更多的過濾 = 更多的 CPU
監控
| Marvel | 自研 |
|---|---|
| 易用 | 須要花時間開發 |
| 數據存入 ES | 與本身的系統集成 |
| 不少分析度量 | |
| 沒有集成 | 重複造輪子 |
| 成本高 | 免費 |
監控 Elasticsearch
度量在多個地方都有暴露:
_cat API
包括了大多數度量,易讀
_stats API,_nodes API
涵蓋全部,JSON格式,易於解析
- 發送到 Graphite
建立 dashboards
監控系統
- SSD 性能
- 監控 Logstash 報管道阻塞的頻率,並找出緣由
- 動態的磁盤空間閥值
- ((服務器的數量 - 失敗的數量)/ 服務器的數量)- 15%
- 100 服務器
- 最多容許 6 個失敗
磁盤空間預警的閥值 =((100 - 6)/ 100)- 15%
磁盤空間預警的閥值 = 79%
- 根據集羣增長與移除節點的數量配置並管理系統
- 額外的 15% 是用來提供申請並準備更多節點的時間
擴展 Logstash
影響 Logstash 性能的因素
- 日誌行的長度
- Grok 模式的複雜度 - 正則表達式很是慢
- 插件的使用
GC
- 增長的堆大小
超線程
- 度量,並關閉
重複測量
將日誌以 JSON 格式輸出並無帶來很大的好處,除非不使用 grok,kv 等。Logstash 仍是須要將字符串轉換成爲 ruby 的 hash
GC 垃圾回收
- 缺省配置一般是能夠的
- 確保記錄了 GC 的圖
- Ruby 會很容易的建立不少對象:在作伸縮擴展時須要監控 GC
在寫插件時須要時刻記住 GC
很差的:1_000_000.times { "This is a string" }
user time 0.130000 好用法:foo = 'This is a string'; 1_000_000.times { foo }
user time 0.060000
插件性能基準
- 如何創建基準
- 度量某些過濾器
- 度量更多的過濾器
- 計算每一個過濾器的成本
- 社區提供的過濾器只是在大多數狀況下適用
- 對於特殊的場景須要本身開發
- 易於使用
- 在測評時執行至少 5 分鐘的時間,使用大數據集
- 創建基準的吞吐量:Python,StatsD,Graphite
Logstash 簡單配置,10m 行 apache 日誌,沒有過濾:
input { file { path => "/var/log/httpd/access.log" start_position => "beginning" } } output { stdout { codec => "dots" } }Python 腳本將 Logstash 輸出到 statsd :
sudo pip install statsd #!/usr/bin/env python import statsd, sys c = statsd.StatsClient('localhost', 8125) while True: sys.stdin.read(1) c.incr('logstash.testing.throughput', rate=0.001)爲何咱們不用 statsd 輸出插件?它會下降輸出的速度!
放在一塊兒
logstash -f logstash.conf | pv -W | python throughput.py 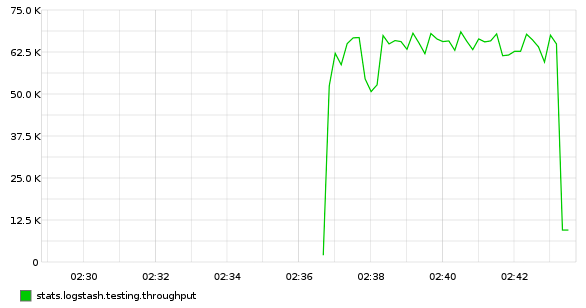
插件性能 Grok
增長一個簡單的 Grok
grok { match => [ "message", "%{ETSY_APACHE_ACCESS}" ] }在只有一個 worker 時,性能降低 80%

增長 worker 的數量,吞吐量仍然降低了 33%:65k/s -> 42k/s
-w <num_cpu_cores>
插件性能 kv
加一個 kv 過濾器
kv { field_split => "&" source => "qs" target => "foo" }吞吐量基本不變,有 10% 的降低(40k/s)
吞吐量變化較大主要由於 GC 的壓力
kv 很慢,如下是一個用來查詢字符串的
splitkv插件kvarray = text.split(@field_split).map { |afield| pairs = afield.split(@value_split) if pairs[0].nil? || !(pairs[0] =~ /^[0-9]/).nil? || pairs[1].nil? || (pairs[0].length < @min_key_length && !@preserve_keys.include?(pairs[0])) next end if !@trimkey.nil? # 2 if's are faster (0.26s) than gsub (0.33s) #pairs[0] = pairs[0].slice(1..-1) if pairs[0].start_with?(@trimkey) #pairs[0].chop! if pairs[0].end_with?(@trimkey) # BUT! in-place tr is 6% faster than 2 if's (0.52s vs 0.55s) pairs[0].tr!(@trimkey, '') if pairs[0].start_with?(@trimkey) end if !@trimval.nil? pairs[1].tr!(@trimval, '') if pairs[1].start_with?(@trimval) end pairs } kvarray.delete_if { |x| x == nil } return Hash[kvarray]
splitkv以前的 CPU 佔用率是 100% ,以後的佔用率是 33% 。
Elasticsearch 的輸出
- Logstash 的輸出設置直接影響了 Logstash 所在機器的 CPU
- 將 flush_size 從 500 改到 5000 ,或更多
- 將 idle_flush_time 從 1s 改到 5s ,
- 增長輸出線程 workers
- 結果受日誌行的影響
- 調整,等待 15 分鐘,而後觀察
當使用缺省的 500 flush_size 時,Logstash 集羣的峯值會達到 50% ,處理能力在每秒 ~40k 日誌行。將這個值改到 10k 時,同時增長 idle_flush_time 到 5s 。處理能力在每秒 ~150k 日誌行,同時 CPU 佔用會降低到 25% 。
Pipeline 管道性能
Logstash 2.3 以前
…/vendor/…/lib/logstash/pipeline.rb SizedQueue.new(20) -> SizedQueue.new(500)
Logstash 2.3 以後
—pipeline-batch-size=500
最好在調優最後改變這個參數。管道的性能受輸出插件性能的影響。
測試配置變動
增長上下文
發現管道的延遲
mutate { add_field => [ "index_time", "%{+YYYY-MM-dd HH:mm:ss Z}" ] }logstash 服務器處理日誌行
mutate { add_field => [ "logstash_host", "<%= node[:fqdn] %>" ] }對日誌行進行哈希,實現重放
hashid插件能夠避免重複行~10% 降低
服務器上的配置
describe package('logstash'),
:if => os[:family] == 'redhat' do
it { should be_installed }
end
describe command('chef-client') do
its(:exit_status) { should eq 0 }
end
describe command('logstash -t -f ls.conf.test') do
its(:exit_status) { should eq 0 }
end
describe command('logstash -f ls.conf.test') do
its(:stdout) { should_not match(/parse_fail/) }
end
describe command('restart logstash') do
its(:exit_status) { should eq 0 }
end
describe command('sleep 15') do
its(:exit_status) { should eq 0 }
end
describe service('logstash'),
:if => os[:family] == 'redhat' do
it { should be_enabled }
it { should be_running }
end
describe port(5555) do
it { should be_listening }
end
Input
input {
generator {
lines => [ '<Apache access log>' ]
count => 1
type => "access_log"
}
generator {
lines => [ '<Application log>' ]
count => 1
type => "app_log"
}
}
Filter
filter {
if [type] == "access_log" {
grok {
match => [ "message", "%{APACHE_ACCESS}" ]
tag_on_failure => [ "parse_fail_access_log" ]
}
}
if [type] == "app_log" {
grok {
match => [ "message", "%{APACHE_INFO}" ]
tag_on_failure => [ "parse_fail_app_log" ]
}
}
}
Output
output {
stdout {
codec => json_lines
}
}
小結
更快的 CPU
CPU 核心數 > CPU 時鐘速度
- 增長管道的大小
更多內存
18Gb+ 防止頻繁 GC
- 橫向擴展
- 爲日誌行添加上下文
- 編寫本身的插件
對全部的東西進行性能評測
擴展 Elasticsearch
默認基準
Logstash 輸出: 默認選項 + 4 workers
Elasticsearch: 默認選項 + 1 shard, no replicas
影響索引的因素
- 日誌行的長度與分析,默認映射
- doc_values - 必須
- 使用更多的 CPU 時間
- 索引時使用更多的磁盤空間,磁盤 I/O
- 有助於下降內存的使用
- 若是發現 fielddata 使用過多內存,定位佔用最多的,而後將它們移到 doc_values
- 爲恢復保留足夠的帶寬
- CPU
- 分析
映射
默認映射會建立大量 .raw 字段
- doc_values
- 合併
- 恢復
- 內存
- 索引的緩衝
- GC
- 段(segment)數量和未優化的索引
- 網絡
恢復的速度
更快的網絡 == 更短的恢復延遲
影響內存的因素
以 32Gb 堆爲例的分佈狀況:
- Field data: 10%
- Filter cache: 10%
- Index buffer: 500Mb
- Segment cache (~4 bytes per doc):
每一個節點可存儲的文檔數
- 32Gb - ( 32G / 10 ) - ( 32G / 10 ) - 500Mb = ~25Gb (段內存)
- 25Gb / 4b = 6.7bn 個文檔(全部片的總和)
- 10bn docs / day, 200 shards = 50m docs/shard
- 1 daily shard per node: 6.7bn / 50m / 1 = 134 days
- 5 daily shards per node: 6.7bn / 50m / 5 = 26 days
Doc Values
- Doc values 能夠下降內存開銷
- Doc values 會消耗 CPU 和存儲
部分字段使用 doc_values:
1.7G Aug 11 18:42 logstash-2015.08.07/7/index/_1i4v_Lucene410_0.dvd
全部字段使用 doc_values:
106G Aug 13 20:33 logstash-2015.08.12/38/index/_2a9p_Lucene410_0.dvd
不要盲目地爲全部字段開啓 doc_values
- 找到使用最頻繁的字段,而後將它們轉換成 Doc Values
- curl -s 'http://localhost:9200/_cat/fielddata?v' | less -S
示例
total request_uri _size owner ip_address 117.1mb 11.2mb 28.4mb 8.6mb 4.3mb 96.3mb 7.7mb 19.7mb 9.1mb 4.4mb 93.7mb 7mb 18.4mb 8.8mb 4.1mb 139.1mb 11.2mb 27.7mb 13.5mb 6.6mb 96.8mb 7.8mb 19.1mb 8.8mb 4.4mb 145.9mb 11.5mb 28.6mb 13.4mb 6.7mb 95mb 7mb 18.9mb 8.7mb 5.3mb 122mb 11.8mb 28.4mb 8.9mb 5.7mb 97.7mb 6.8mb 19.2mb 8.9mb 4.8mb 88.9mb 7.6mb 18.2mb 8.4mb 4.6mb 96.5mb 7.7mb 18.3mb 8.8mb 4.7mb 147.4mb 11.6mb 27.9mb 13.2mb 8.8mb 146.7mb 10mb 28.7mb 13.6mb 7.2mb
內存小結
- 實例使用 128Gb 或 256Gb RAM
根據硬件配置優化 RAM
Haswell/Skylake Xeon CPUs 有 4 個內存通道
Elasticsearch 多個實例
爲每一個實例分配本身的名稱 node.name
CPU
CPU 密集型操做
- 索引:分析,合併,壓縮
- 搜索:計算,解壓縮
寫壓力
- CPU 核心數受併發的索引操做影響
- 核心數 優於 CPU 頻率值
基準
爲何這麼慢?
[logstash-2016.06.15][0] stop throttling indexing:
numMergesInFlight=4, maxNumMerges=5
合併
第一步:將分片數從 1 提高到 5
第二步:禁用 merge throttling(ES < 2.0)
index.store.throttle.type: none
拆分 Hosts
當 CPU 接近最大時,須要加入更多節點
在不一樣 Hosts 上運行 Elasticsearch 以及 Logstash
吞吐量有 50% 的提高:13k/s -> 19k/s
超線程 Hyperthreading
超線程能夠提高 20% 的性能
CPU 治理
~15-30% 的性能提高。
# echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
存儲
磁盤 I/O
建議
- 使用 SSD
- RAID 0
- 軟 RAID 足夠
更多的建議
好的 SSD 很是重要
廉價 SSD 會大大下降性能
不要使用多個數據路徑,使用 RAID 0
大量的 translog 寫磁盤操做會是瓶頸
若是有大量段合併,可是 CPU 和 磁盤 I/O 還有空閒:
能夠嘗試提高值
index.merge.scheduler.max_thread_count
下降間隔(Durability)
index.translog.durability: async
Translog fsync() 值爲 5s ,足夠
集羣的恢復會吃掉大量磁盤 I/O
須要在恢復先後調整相應的參數
indices.recovery.max_bytes_per_sec: 300mb cluster.routing.allocation.cluster_concurrent_rebalance: 24 cluster.routing.allocation.node_concurrent_recoveries: 2
任何的持續 I/O 等待都意味着存在一個次優狀態
SSD 的選擇
消費級
- 慢速寫
- 廉價
- 低耐久性,天天相對較少的寫次數
企業級
- 快速寫
- 昂貴
- 高耐久性,天天相對較高的寫次數
大量讀
- 低耐久性,1-3 DWPD
- 低速讀,代價小
混合使用
- 中度耐久性,10 DWPD
- 平衡讀寫,中等價位
大量寫
- 高耐久性,25 DWPD
- 高速寫,代價高
基準
下降間隔後,基本仍然維持在 ~20-25k,但更平滑
爲何提高很小?Merging
$ curl -s 'http://localhost:9200/_nodes/hot_threads?threads=10' | grep %
73.6% (367.8ms out of 500ms) 'elasticsearch[es][bulk][T#25]'
66.8% (334.1ms out of 500ms) 'elasticsearch[es][[logstash][1]: Lucene Merge Thread #139]'
66.3% (331.6ms out of 500ms) 'elasticsearch[es][[logstash][3]: Lucene Merge Thread #183]'
66.1% (330.7ms out of 500ms) 'elasticsearch[es][[logstash][1]: Lucene Merge Thread #140]'
66.1% (330.4ms out of 500ms) 'elasticsearch[es][[logstash][4]: Lucene Merge Thread #158]'
62.9% (314.7ms out of 500ms) 'elasticsearch[es][[logstash][3]: Lucene Merge Thread #189]'
62.4% (312.2ms out of 500ms) 'elasticsearch[es][[logstash][2]: Lucene Merge Thread #160]'
61.8% (309.2ms out of 500ms) 'elasticsearch[es][[logstash][1]: Lucene Merge Thread #115]'
57.6% (287.7ms out of 500ms) 'elasticsearch[es][[logstash][0]: Lucene Merge Thread #155]'
55.6% (277.9ms out of 500ms) 'elasticsearch[es][[logstash][2]: Lucene Merge Thread #161]'
分層存儲
- 將更多訪問的索引放在更多的服務器上,並分配更多的內存以及更快的 CPU
- 將 「冷」 索引獨立存儲(SSD下仍然須要這麼作)
- 設置 index.codec: best_compression
- 移動索引,從新優化
- 構建 elasticsearch-curator 可讓事情變得簡單
爲何默認的配置 Merging 如此多?
$ curl 'http://localhost:9200/_template/logstash?pretty'
看到了嗎?
"string_fields" : {
"mapping" : {
"index" : "analyzed", // <--- see?
"omit_norms" : true,
"type" : "string",
"fields" : {
"raw" : {
"ignore_above" : 256, // <--- see?
"index" : "not_analyzed", // <--- see?
"type" : "string" // <--- see?
}
}
},
"match_mapping_type" : "string",
"match" : "*"
}
使用自定義映射
"string_fields" : {
"mapping" : {
"index" : "not_analyzed",
"omit_norms" : true,
"type" : "string"
},
"match_mapping_type" : "string",
"match" : "*"
}
有那麼一點幫助
索引的性能
增長 bulk 線程池能夠控制索引的爆發
但同時也要注意,這會隱藏性能的問題
- 增長索引的緩衝
- 增長刷新的時間,1s 到 5s
- 將索引請求發送到多個 hosts
增長 worker 直到沒有明顯的性能提高爲止
num_cpu / 2
增長 flush_size 知道沒有明顯的性能提高爲止
10,000
- 磁盤 I/O 性能
索引協議
- HTTP
- Node
- Transport
- Transport 仍然是性能最好的,可是 HTTP 已經很是接近了
- Node 基本上不會使用
自定義映射模板
- 默認模板爲每一個字段額外生成 not_analyzed.raw 字段
- 分析每一個字段會佔用 CPU
- 額外的字段會吃掉更多磁盤空間
- 動態字段和 Hungarian 標記
- 使用開啓了動態字段的自定義映射模板,可是將它們設置爲 non_analyzed 剔除 .raw 字段,除非真的須要它。
- 這能夠將 Elasticsearch 集羣的 CPU 的使用率從 28% 降到 15%
消息的複雜度也十分相關
加 20k 的新行與平均 1.5k 的索引速率
截斷
ruby { code => "if event['message'].length > 10240 then event['message'] = event['message'].slice!(0,10240) end" }讓 Logstash 作更多的事情
索引的大小
按索引來調優分片
num_shards = (num_nodes - failed_node_limit) / (number_of_replicas + 1)
50 個節點,並容許最多 4 個節點失敗,replication 爲 1x:
num_shards = (50 - 4) / (1 + 1) = 23
若是分片大於 25Gb ,須要相應增長分片數
調優 indices.memory.index_buffer_size
index_buffer_size = num_active_shards * 500Mb
其中「active_shards」:指任何 5 分鐘內更新的分片
調試 refresh_interval
- 默認 1s - 過於頻繁
- 增長到 5s
- 更高的值會致使磁盤抖動
目標:將磁盤裏的緩衝儘量的移儲
例如:Samsung SM863 SSDs
DRAM buffer: 1Gb
Flush speed: 500Mb/sec
參考
參考來源:
2016.6 ELK: Moose-ively scaling your log system
結束
- 1. jquery性能最佳實踐
- 2. 騰訊雲Elasticsearch集羣規劃及性能優化實踐
- 3. Elasticsearch集羣規劃及性能優化實踐(筆記)
- 4. Hive性能調優的最佳實踐
- 5. mysql提升性能的最佳實踐
- 6. MySQL 的性能優化最佳實踐
- 7. Elasticsearch 最佳實踐!
- 8. 性能最佳實踐:MongoDB索引
- 9. 前端性能優化最佳實踐
- 10. 前端網頁性能最佳實踐
- 更多相關文章...
- • 網站主機 性能 - 網站主機教程
- • MySQL 5.7的新特性(新功能) - MySQL教程
- • JDK13 GA發佈:5大特性解讀
- • 互聯網組織的未來:剖析GitHub員工的任性之源
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Appium入門
- 2. Spring WebFlux 源碼分析(2)-Netty 服務器啓動服務流程 --TBD
- 3. wxpython入門第六步(高級組件)
- 4. CentOS7.5安裝SVN和可視化管理工具iF.SVNAdmin
- 5. jedis 3.0.1中JedisPoolConfig對象缺少setMaxIdle、setMaxWaitMillis等方法,問題記錄
- 6. 一步一圖一代碼,一定要讓你真正徹底明白紅黑樹
- 7. 2018-04-12—(重點)源碼角度分析Handler運行原理
- 8. Spring AOP源碼詳細解析
- 9. Spring Cloud(1)
- 10. python簡單爬去油價信息發送到公衆號