Web前端面試題寶典【精編版】

過了八月,立刻到了金九銀十的跳槽季,找工做的時候曾一週面試了十多家公司,從一開始被面試官虐的體無完膚到最後對答如流,過程當中經歷了多少挑燈夜戰的晚上,惡補前端知識,努力的付出終會有回報,最終得到了心儀的offer,全部的一切都是值得的。整理一下面試過程當中遇到的高頻題目,這些都是精簡後的真題,就算不能百分百涵蓋,至少也囊括七、8%了,若是面試過程當中的你能回答出百分之八十左右的題目,不出大的紕漏offer基本上也就穩收囊中了,剩下的百分之二十是面試官測試你的技術極限在哪裏,也會所以來決定你的薪資。javascript
不要以爲面試題目多,難度大,不少知識掌握不了就抱着僥倖心態以爲問不到,我想說的是任何行業都適用二八定律,努力成爲你本身行業那百分之二十拔尖的人。總而言之就是發展本身才是硬道理,發展的好會遭人嫉妒,這是正常的,不然你得多普通呀。不只要在專業方面須要進步,當專業發展遇到天花板時說明須要擴維了。學習不要太功利,每每看似無用的東西反而在某個時候會有大用處。只有感到痛苦咱們才能成長,溫馨區只有兩個: 媽媽的子宮和死去的狀態,前一個地方咱們回不去,後一個地方咱們不想去,只能掙扎着克服一切克服的了抑或克服不了的事兒,堅持堅持就過去了,等回頭看時都是p大的事兒,你們一塊兒加油!php
H5/C3/ES6/JS
Html5
h五、css三、es6的新屬性
h5新特性:css
- 拖拽釋放(Drag and drop) API
- 語義化更好的內容標籤(header,nav,footer,aside,article,section)
- 音頻、視頻API(audio,video)
- 畫布(Canvas) API
- 地理(Geolocation) API
- 本地離線存儲 localStorage 長期存儲數據,瀏覽器關閉後數據不丟失;
- sessionStorage 的數據在瀏覽器關閉後自動刪除
- 表單控件:calendar、date、time、email、url、search
- 新的技術:webworker, websocket, Geolocation
移除的元素:html
- 純表現的元素:basefont,big,center,font, s,strike,tt,u;
- 對可用性產生負面影響的元素:frame,frameset,noframes
H5的特色
- 更簡潔,可是在實際開發中要注意書寫規範
- 標籤的語義化
- 語法更寬鬆
BFC
BFC(塊級格式化上下文),一個建立了新的BFC的盒子是獨立佈局的,盒子內元素的佈局不會影響盒子外面的元素,在同一個BFC中的兩個相鄰的盒子在垂直方向發生margin重疊的問題。前端
BFC是指瀏覽器中建立了一個獨立的渲染區域,該區域內全部元素的佈局不會影響到區域外元素的佈局,這個渲染區域只對塊級元素起做用。vue
觸發BFC的方式(如下任意一條就能夠)
- html根元素
- float屬性不爲none
- position不爲visible,爲absolute或fixed。
- display爲inline-block, table-cell, table-caption, flex, inline-flex
- overflow不爲visible
BFC佈局與普通文檔流佈局區別
(注:字體加粗的觸發BFC的條件都支持)html5
普通文檔流佈局規則java
1. 浮動的元素是不會被父級計算高度node
2. 非浮動元素會覆蓋浮動元素的位置(兄弟關係的元素)。react
3. 給子級添加margin-top會傳遞給父級
4.兩個相鄰元素上下margin會重疊
BFC佈局規則
1.浮動的元素會被父級計算高度(高度坍塌)
(1)給父級添加浮動float
(2)給父級添加overflow:hidden; 觸發了BFC(子元素浮動,父元素沒有高度時使用,該方法不能和定位一塊兒使用)
(3)給父級添加display:inline-block;
(4)給父級添加定位position:absolute/fixed;
2. 非浮動元素不會覆蓋浮動元素位置
(1)非浮動元素float的值不爲none
(2)非浮動元素加overflow:hidden觸發了BFC。
(3)非浮動元素display:inline-block;
(4)給非浮動元素或者浮動元素添加position定位,添加的元素會覆蓋在未添加的元素上面
3. 給子級添加margin-top不會傳遞給父級
(1)給父級添加浮動float
(2)給父級添加overflow:hidden;
(3)給子級添加display:inline-block;
(4)給父級添加定位position:absolute/fixed;
Form中的獲取數據的兩個方式get和post的區別?
- get是從服務器上獲取數據,post是向服務器傳送數據。
- get是把參數數據隊列加到提交表單的ACTION屬性所指的URL中,值和表單內各個字段一一對應,在URL中能夠看到。post是經過HTTP post機制,將表單內各個字段與其內容放置在HTML HEADER內一塊兒傳送到ACTION屬性所指的URL地址。用戶看不到這個過程。get是顯式提交,post是隱式提交。
- 對於get方式,服務器端用Request.QueryString獲取變量的值,對於post方式,服務器端用Request.Form獲取提交的數據。
- get傳送的數據量較小,不能大於2KB。post傳送的數據量較大,通常被默認爲不受限制。
- get安全性很是低,post安全性較高。可是執行效率卻比Post方法好。
何時使用get何時使用post?
- get方式的安全性較Post方式要差些,包含機密信息的話,建議用Post數據提交方式;
- 在作數據查詢時,建議用Get方式;而在作數據添加、修改或刪除時,建議用Post方式;
Html中form裏的action方法的get與post方法區別是什麼?
get:
- 經過GET提交數據,用戶名和密碼將明文出如今URL上,由於登陸頁面有可能被瀏覽器緩存,GET請求請提交的數據放置在HTTP請求協議頭
- 或者其餘人查看瀏覽器的歷史紀錄,那麼別人就能夠拿到你的帳號和密碼了,除此以外,使用GET提交數據還可能會形成Cross-site request forgery攻擊,因此不安全
- GET請求有長度限制
post:
- POST數據放在body(POST提交的數據則放在實體數據),POST請求數據不能被緩存下來
- POST請求參數不會被保存在瀏覽器歷史或 web 服務器日誌中。
- POST請求沒有長度限制
參考:form裏面的action和method(post和get的方法)使用
https://www.cnblogs.com/May-d...
漸進加強和優雅降級的概念以及區別
漸進加強 progressive enhancement:針對低版本瀏覽器進行構建頁面,保證最基本的功能,而後再針對高級瀏覽器進行效果、交互等改進和追加功能達到更好的用戶體驗。
優雅降級 graceful degradation:一開始就構建完整的功能,而後再針對低版本瀏覽器進行兼容。
區別:優雅降級是從複雜的現狀開始,並試圖減小用戶體驗的供給,而漸進加強則是從一個很是基礎的,可以起做用的版本開始,並不斷擴充,以適應將來環境的須要。降級(功能衰減)意味着往回看;而漸進加強則意味着朝前看,同時保證其根基處於安全地帶。
如何處理HTML5新標籤的瀏覽器兼容問題?
支持HTML5新標籤:
IE8/IE7/IE6支持經過 document.createElement 方法產生的標籤,能夠利用這一特性讓這些瀏覽器支持 HTML5 新標籤,瀏覽器支持新標籤後,還須要添加標籤默認的樣式(固然最好的方式是直接使用成熟的框架、使用最多的是html5shim框架):
<!--[if lt IE 9]> <script> src="http://html5shim.googlecode.com/svn/trunk/html5.js"</script> <![endif]-->
如何區分HTML和HTML5
DOCTYPE聲明新增的結構元素、功能元素
文檔碎片
若是咱們要在一個ul中添加100個li,若是不使用文檔碎片,那麼咱們就須要使用append常常100次的追加,這會致使瀏覽器一直不停的渲染,是很是消耗資源的。可是若是咱們使用文檔碎片了,咱們能夠先將100個li添加到文檔碎片中,而後直接把這個文檔碎片追加到ul中便可。因此文檔碎片其實就是一個臨時的倉庫。
以下代碼在document.body中添加5個span:
for(var i=0;i<5;i++)
{
var op = document.createElement("span");
var oText = document.createTextNode(i);
op.appendChild(oText);
document.body.appendChild(op);
}
對於少許的更新,一條條循環插入的運行也還能夠。可是,當要向document中添加大量數據(好比1w條),若是像上面的代碼同樣,逐條添加節點,整個過程會十分緩慢,性能極差。
也能夠建一個新的節點,例如div,先將span添加到div上,而後再將div添加到body:
var oDiv = document.createElement("div");
for(var i=0;i<10000;i++)
{
var op = document.createElement("span");
var oText = document.createTextNode(i);
op.appendChild(oText);
oDiv.appendChild(op);
}
document.body.appendChild(oDiv);
但這樣會在body中多添加一個div節點。用文檔碎片就不會產生這種節點,引入createDocumentFragement()方法,它的做用是建立一個文檔碎片,把要插入的新節點先插入它裏面,而後再一次性地添加到document中。
代碼以下:
//先建立文檔碎片
var oFragmeng = document.createDocumentFragment();
for(var i=0;i<10000;i++)
{
var op = document.createElement("span");
var oText = document.createTextNode(i);
op.appendChild(oText);
//先附加在文檔碎片中
oFragmeng.appendChild(op);
}
//最後一次性添加到document中
document.body.appendChild(oFragmeng);
瀏覽器內核
IE: trident內核
Firefox:gecko內核
Safari:webkit內核
Opera:之前是presto內核,Opera現已改用Google Chrome的Blink內核
Chrome:Blink(基於webkit,Google與Opera Software共同開發)
什麼是viewport?
viewport是視口,在瀏覽器中用來顯示網頁的某一塊區域,以合理的比例顯示內容。
CSS3
css3新特性
- CSS3實現圓角(border-radius),盒子陰影(box-shadow),文本陰影(text-shadow)
- 漸變(gradient):線性漸變、徑向漸變,旋轉(transform)
- 有關製做動畫的三個屬性:transform、transition、animation
- transform:translate移動、scale縮放、rotate旋轉、skew傾斜
- animation動畫 keyframes關鍵幀
- 增長了更多的CSS選擇器 多背景 rgba
- 在CSS3中惟一引入的僞元素是 ::selection.
- 媒體查詢,多欄佈局
- border-color、border-image、border-radius
- filter:blur()虛化圖片
css3的優點
- 讓頁面效果看起來很是炫酷,用戶體驗更高。
- 有利於開發和維護,還能提升網站的性能,增長網站的可訪問性,可用性。
- 使網站能適配更多的設備,利於seo網站優化,提升網站的搜索排名。
css sprites如何使用
將導航背景圖片,按鈕背景圖片等有規則的合併成一張背景圖,即將多張圖片合爲一張整圖,而後用「background-position」來實現背景圖片的定位技術。
CSS元素類型
塊狀元素,內聯元素(行內元素),內聯塊元素(行內塊元素)
空元素有哪一些
br hr
標準盒模型和怪異盒模型
CSS中Box model是分爲兩種:W3C標準和IE標準盒子模型
在標準模式下,一個塊的總寬度 = width + margin+padding+border
在怪異模式下,一個塊的總寬度=width+margin(即width已經包含了padding和border的值)
大多數瀏覽器採用W3C標準模型,而IE中則採用Micreosoft本身的標準。
怪異模式是"部分瀏覽器在支持W3C標準的同時還保留了原來的解析模式",怪異模式主要表如今IE內核的瀏覽器。
當不對doctype進行定義時,會觸發怪異模式。
標準盒模型和怪異盒模型的轉化
怪異盒模型:box-sizing:border-box
標準盒模型:box-sizing:content-box
列出display的值,說明他們的做用
display屬性與屬性值 (18個屬性值)
屬性值:block/inline/inline-block/none/list-item/table-header-group/table-footer-group/table
做用:塊狀元素和內聯元素之間的轉換。
- Block塊狀顯示:相似在元素後面添加換行符,也就是說其餘元素不能在其後面並列顯示。或者就是讓元素豎排顯示。
- inline內聯顯示:在元素後面刪除換行符,多個元素能夠在一行內並列顯示。或者就是讓元素橫排顯示。
- 當元素設置了float屬性後,就至關於該元素具有塊狀元素顯示的特色;能夠加寬高。
- Inline-block行內塊元素顯示:元素的內容以塊狀顯示,行內的其餘元素顯示在同一行。(只有行內塊這一個元素類型支持vertical-align屬性)
img,input垂直對齊方式{vertical-align:top/bottom/middle;}
- none 此元素不會被顯示。隱藏且不佔位
position的值:relative和absolute分別是相對誰進行定位的
position:定位屬性,檢索對象的定位方式;
定位都脫離層。
語法:position:static /absolute/relative/fixed
absoluted/relative/fixed 對定位有效,對層級屬性Z-index有效。
取值:
- static:默認值,無特殊定位,對象遵循HTML原則;
- absolute:絕對定位,將對象從文檔流中拖離出來,使用left/right/top/bottom等屬性相對其最接近的一個並有定位設置的父元素(祖先元素|祖先元素不包含叔叔級的)進行絕對定位;若是不存在這樣的父對象,則依據根元素(html)瀏覽器進行定位,而其層疊經過z-index屬性定義,能夠脫離當前的大容器,而且不佔位。float脫離半層。
- relative :相對定位,該對象的文檔流位置不動,將依據right,top,left,bottom(相對定位)等屬性在正常文檔流中偏移位置;其層疊經過z-index屬性定義
通常給父層級添加relative屬性值
相對於自身位置進行偏移
元素設置:margin:0 auto時:
(1)box爲相對定位時(相對自身),居中
(2)box爲絕對定位時(相對於根元素HTML),向左
- fixed:(固定定位)未支持,對象定位聽從絕對定位方式(absolute);可是要遵照一些規範(IE6瀏覽器不支持此定位);跟絕對定位同樣的都是脫離文檔流,不佔位,而且永遠相對於當前瀏覽器的可視窗口進行位置偏移。
absolute是否是必定須要設置相對定位
absolute不必定必須找到position單詞修飾的祖先元素,若是找不到就相對瀏覽器進行定位。
解釋下浮動和它的工做原理
語法:float:none/left/right;
float浮動脫離半層
float:定義網頁中其它文本如何環繞該元素顯示
嵌套浮動元素的父級要有高度,否則會高度塌陷,解決辦法,添加overflow:hidden;(注意不能與定位一塊兒使用)
浮動的目的:就是讓豎着的東西橫着來
有三個取值:
left:元素活動浮動在文本左面
right:元素浮動在右面
none:默認值,不浮動。
清除浮動的方法
- 在結尾處添加空div標籤clear:both;
- 萬能清除浮動法(給浮動元素的父元素添加)class名.clear,哪一個須要清除就給哪一個元素命名爲clear ;一個元素能夠取多個class名,中間用空格隔開)。
:after{content:".";clear:both;display:block;height:0;overflow:hidden;visibility:hidden;}
.clear{zoom:1}
- 父級div定義height
- 父級div定義overflow:hidden
- 父級div定義overflow:auto
- 父級div也一塊兒浮動
- 父級div定義display:table
- 結尾處加br標籤clear:both
參考:幾種經常使用的清除浮動方法
https://www.cnblogs.com/nxl09...
爲什麼要清除浮動
浮動框不屬於文檔流中的普通流,當元素浮動以後,不會影響塊級元素的佈局,只會影響內聯元素佈局。此時文檔流中的普通流就會表現得該浮動框不存在同樣的佈局模式。當包含框的高度小於浮動框的時候,此時就會出現「高度塌陷」。
CSS3動畫的實現種類
CSS3屬性中有關於製做動畫的三個屬性:
Transition(過渡),Transform(轉換),Animation(動畫)
animation和transition的區別
相同點:都是隨着時間改變元素的屬性值。
不一樣點:transition須要觸發一個事件(hover事件target事件或click事件等)纔會隨時間改變其css屬性; 而animation在不須要觸發任何事件的狀況下也能夠顯式的隨着時間變化來改變元素css的屬性值,從而達到一種動畫的效果,css3的animation就須要明確的動畫屬性值。
transition觸發後只能運動一次,animation能夠設定運動的循環次數。
Animation-->在這個動畫以前,先看Keyframes關鍵幀,支持animation動畫的只有webkit內核的瀏覽器
如何讓chrome支持小於12px的文字?(css3中的縮放形式)
<style>
p span{
font-size:10px;
-webkit-transform:scale(0.8);
display:block;
}
</style>
<p><span>haorooms博客測試10px</span></p>
iframe的優缺點
優勢:
- 解決加載緩慢的第三方內容如圖標和廣告等的加載問題
- Security sandbox
- 並行加載腳本
缺點:
- iframe會阻塞主頁面的Onload事件
- 即時內容爲空,加載也須要時間
- 沒有語意
迴流和重繪
- 當render tree中的一部分(或所有)由於元素的規模尺寸,佈局,隱藏等改變而須要從新構建。這就稱爲迴流。每一個頁面至少須要一次迴流,就是在頁面第一次加載的時候。
- 當render tree中的一些元素須要更新屬性,而這些屬性只是影響元素的外觀,風格,而不會影響佈局的,好比background-color。則就叫稱爲重繪。
注:迴流必將引發重繪,而重繪不必定會引發迴流
迴流就至關於整個頁面發生了DOM上的變化 重繪就是樣式發生了改變
區別:
他們的區別很大:
迴流必將引發重繪,而重繪不必定會引發迴流。好比:只有顏色改變的時候就只會發生重繪而不會引發迴流
當頁面佈局和幾何屬性改變時就須要迴流
好比:添加或者刪除可見的DOM元素,元素位置改變,元素尺寸改變——邊距、填充、邊框、寬度和高度,內容改變
CSS選擇符
類型選擇符,id選擇符,class選擇符,通配符,羣組選擇符,包含選擇符,僞類選擇符(僞類選擇符CSS中已經定義好的選擇器,不能隨便取名),僞對象選擇符(設置在對象後發生的內容,用來和content屬性一塊兒使用 )
CSS選擇符的權重
css中用四位數字表示權重,權重的表達方式如:0,0,0,0
類型選擇符的權重爲0001
class選擇符的權重爲0010
id選擇符的權重爲0100
子選擇符的權重爲0000
屬性選擇符的權重爲0010
僞類選擇符的權重爲0010
僞元素選擇符的權重爲0001
包含選擇符的權重:爲包含選擇符的權重之和
羣組選擇符的權重:爲各自的權重
內聯樣式的權重爲1000
繼承樣式的權重爲0000
*通配符選擇器權重爲0
垂直水平居中
CSS2有定位
讓一個元素實現垂直水平居中:
(1)給當前元素後面添加<span></span>空標籤,代碼不換行,必須寫在一行上。
(2)給當前元素和span添加display:inline-block;轉換爲內聯塊元素。
(3)給span添加height屬性,與父級同高;
(4)給當前元素和span添加vertical-align:middle;實現垂直居中。
(5)給父元素添加text-align:center;實現水平居中。
讓一個圖片實現垂直水平居中:
(1)給當前元素後面添加<span></span>空標籤,代碼不換行,必須寫在一行上。
(2)給span添加display:inline-block;轉換爲內聯塊元素。(圖片自己就是內聯塊元素,不須要再轉換)
(3)給span添加height屬性,與父級同高;
(4)給當前元素和span添加vertical-align:middle;實現垂直居中。
(5)給父元素添加text-align:center;實現水平居中。
水平居中:text-align:center:(1)對文本有效;(2)對內聯元素、內聯塊元素有效。
當前元素爲有寬度的塊元素時,能夠用margin:0 auto;實現水平居中。
垂直居中:vertical-align:middle;只對內聯塊元素有效。
用定位讓元素或圖片實現垂直水平居中:
(1)給父元素定位:position:relative;
(2)給子元素加絕對定位:position:absolute;
(3)給子元素添加座標屬性:top:0;left:0;right:0;bottom:0;margin:auto;
至關於給元素提供了四個參照範圍
讓一個元素在當前瀏覽器窗口垂直水平居中:
第一種方法:(1)給元素添加固定定位:position:fixed;
(2)給元素添加座標屬性:top:0;left:0;right:0;bottom:0;margin:auto;
第二種方法:(1)給元素添加固定定位position:fixed;
(2)top:50%;left:50%;
(3)margin:-元素高度/2px 0 0 -元素寬度/2px;
中心點的移動:從左上移到中心點
c3有彈性盒佈局
給父元素添加:
display:flex;
justify-content: center;
align-items: center;
利用位移(定位加位移)
父元素:
positive:relative;
子元素:
position: absolute;
top:50%;
left:50%;
transform: translate(-元素寬度/2px,-元素高度/2px);
兩種引入外部樣式表link和import之間的區別
差異1:本質的差異:link屬於XHTML標籤,而@import徹底是CSS提供的一種方式。
差異2:加載順序的差異:當一個頁面被加載的時候(就是被瀏覽者瀏覽的時候),link引用的CSS會同時被加載,而@import引用的CSS會等到頁面所有被下載完再被加載。因此有時候瀏覽@import加載CSS的頁面時開始會沒有樣式(就是閃爍),網速慢的時候還挺明顯。
差異3:兼容性的差異:@import是CSS2.1提出的,因此老的瀏覽器不支持,@import只有在IE5以上的才能識別,而link標籤無此問題。
差異4:使用dom(document object model文檔對象模型 )控制樣式時的差異:當使用javascript控制dom去改變樣式的時候,只能使用link標籤,由於@import不是dom能夠控制的。
簡述src與href的區別
src用於替換當前元素,href用於在當前文檔和引用資源之間確立聯繫。
src是source的縮寫,指向外部資源的位置,指向的內容將會嵌入到文檔中當前標籤所在位置;在請求src資源時會將其指向的資源下載並應用到文檔內,例如js腳本,img圖片和frame等元素。
<script src =」js.js」></script>
當瀏覽器解析到該元素時,會暫停其餘資源的下載和處理,直到將該資源加載、編譯、執行完畢,圖片和框架等元素也如此,相似於將所指向資源嵌入當前標籤內。這也是爲何將js腳本放在底部而不是頭部。
href是Hypertext Reference的縮寫,指向網絡資源所在位置,創建和當前元素(錨點)或當前文檔(連接)之間的連接,若是咱們在文檔中添加
<link href="common.css" rel="stylesheet"/>
那麼瀏覽器會識別該文檔爲css文件,就會並行下載資源而且不會中止對當前文檔的處理。這也是爲何建議使用link方式來加載css,而不是使用@import方式。
僞類選擇器
一、結構性僞類選擇器
①:first-child選擇某個元素的第一個子元素;IE6不支持:first-child選擇器
②:last-child選擇某個元素的最後一個子元素;
③:nth-child()選擇某個元素的一個或多個特定的子元素;
④:nth-last-child()選擇某個元素的一個或多個特定的元素,從這個元素的最後一個元素開始算;
⑤:nth-of-type()選擇指定類型的元素;
nth-of-type相似於:nth-child,不一樣的是他只計算選擇指定的元素類型。
⑥:nth-last-of-type()選擇指定的元素,從元素的最後一個開始計算;
⑦:first-of-type選擇一個上級元素下的第一個同類元素;
⑧:last-of-type選擇一個上級元素的最後一個同類元素;
⑨:only-child選擇的元素是它的父元素的惟一 一個子元素;
⑩:only-of-type選擇一個元素是它的上級元素的惟一一個相同類型的子元素;
僞元素選擇器
::first-line ::first-letter ::before ::after
CSS3新增:::selection 用來改變瀏覽網頁選中文本的默認效果
CSS3中主要用兩個"::"和一個":"來區分僞類和僞元素
用CSS寫一個三角形
aside{
width:1px;
height:1px;
border:50px solid #fff;
border-bottom-color:red;
}
設置寬高爲0或者1像素,須要哪一個方向的三角形,就給哪一個方向的邊框單獨加顏色。
font屬性的簡寫
說明:font的屬性值應按如下次序書寫(各個屬性之間用空格隔開)
順序: font-style font-weight font-size / line-height font-family
css實現文字溢出顯示省略號
- 容器寬度:width:value;
- 強制文本在一行內顯示:white-space:nowrap;
- 溢出內容爲隱藏:overflow:hidden;
- 溢出文本顯示省略號:text-overflow:ellipsis;
聖盃佈局
left:左浮動;
right:右浮動;
center:overflow:hidden;
順序:左右中,左浮右浮。
自適應兩欄佈局
html,body{height:100%;}高度寫百分比時,須要聲明body和html的高度爲100%。
佈局:一左一右,左半部分浮動,非浮動元素會覆蓋浮動元素的位置。
給右半部分添加overflow:hidden;
自適應,非浮動元素不加寬度。
只適用於pc端,比較簡單的佈局。
CSS3兼容
各主流瀏覽器都定義了私有屬性,以便讓用戶體驗 CSS3 的新特性。例如,
- Webkit 類型瀏覽器(如 Safari、Chrome)的私有屬性是以
-webkit-前綴開始, - Gecko 類型的瀏覽器(如 Firefox)的私有屬性是以
-moz-前綴開始, - Konqueror 類型的瀏覽器的私有屬性是以
-khtml-前綴開始, - Opera 瀏覽器的私有屬性是以
-o-前綴開始, - 而 Internet Explorer 瀏覽器的私有屬性是以
-ms-前綴開始(目前只有 IE 8+ 支持-ms-前綴)。
什麼是Css Hack?ie6,7,8的hack分別是什麼?
針對不一樣的瀏覽器寫不一樣的CSS code的過程,就是CSS hack。
#test {
width:300px;
height:300px;
background-color:blue; /*firefox*/
background-color:red\9; /*all ie*/
background-color:yellow; /*ie8*/
+background-color:pink; /*ie7*/
_background-color:orange; /*ie6*/ }
:root #test { background-color:purple\9; } /*ie9*/
@media all and (min-width:0px){ #test {background-color:black;} } /*opera*/
@media screen and (-webkit-min-device-pixel-ratio:0){ #test {background-color:gray;} } /*chrome and safari*/
ES6
ES6的新特性
(1)let關鍵字:let關鍵字聲明變量,只要遇到大括號,就造成做用域。
(2)const:const聲明的變量,一旦被聲明,就沒有辦法被修改。
(3)箭頭函數
(4)變量的解構賦值
(5)字符串模板:使用反引號`表示,使用${變量|函數}嵌入代碼
(6)數組的一些方法:
- Array.from():將僞數組轉成真數組。(極少數的地方會用)
- copyWithin()瞭解:複製指定內容覆蓋指定內容(指定數組的下標六、7替換下標2及之後)
- find() 功能:查找符合條件的第一個元素。
- findIndex(); 功能:查找符合條件的第一個元素的下標。
(7)Object.assign 合併對象
(8)第七種數據類型Symbol
(9)Set和Map集合
(10)Promise對象
(11)class定義類
箭頭函數中this的指向
箭頭函數:箭頭函數自己是沒有this和arguments的,在箭頭函數中引用this其實是調用的是定義時的上一層做用域的this。 這裏強調的是上一層做用域,是由於對象是不能造成獨立的做用域的。
例如:
var obj = {
say: function() {
var f1 = ()=>{
console.log("1111",this);
}
f1();
}
}
var o = obj.say;
o();//f1執行時,say函數指向window,因此f1中的this指向window
obj.say();//f1執行時,say函數指向obj,因此f1中的this指向obj;
var ojb = {
pro: {
getPro: ()=>{
console.log(this);
}
}
}
obj.pro.getPro();//this指向的是window,由於箭頭函數定義時,getPro的上一級是pro,是一個對象,不能造成單獨的做用域,故指向window。
參考:箭頭函數中的this指向
https://blog.csdn.net/sinat_3...
ES6新增了那些關於數組的方法
-
Array.from 這個東西就是把一些集合,或者長的像數組的僞數組轉換成真的數組,好比arguments,js選擇器找到dom集合,還有對象模擬的數組。
var obj = {'0' : 1,length : 1} Array.from(obj / arguments / 僞數組) //返回的是一個數組Array.from還有第二個參數,是一個回調函數,功能相似map Array.from( [1, 2, 3], item => item * 2 )
-
Array.of
Array.of(1, 2, 3, 4) //把參數合併成一個數組返回,若是參數爲空,則返回一個空數組
-
find/findIndex
//find 返回數組中第一個符合條件的元素, findIndex返回索引 [1, 2, 3, 4, 5].find(function(item){ return item > 3 } -
fill
數組中的每個元素替換成指定值 let arr = [1, 2, 3, 4] arr.fill(5) //arr全變成了5 指定範圍替換 arr.fill(6, 1, 3) //arr=[1,6,6,4]
-
entries/keys/values
let arr=['a', 'b', 'c'] for(let key of arr.keys()){} //取鍵 for(let value of arr.values()){} //取值 for(let [key, value] of arr.entries()){} //都取 -
includes
var a = function(){} [1, 2, 3, 4, a].includes(a) //true
var和let的區別
let關鍵字聲明變量,只要遇到大括號,就造成做用域。
咱們把let關鍵字,造成的做用域,叫作塊級做用域。
let命令的特性
(1)let不存在變量提高
var命令會發生」變量提高「現象,即變量能夠在聲明以前使用,值爲undefined。
let命令不存在變量提高的行爲,它所聲明的變量必定要在聲明後使用,不然報錯。
(2)暫時性死區
只要塊級做用域內存在let命令聲明變量以前,該變量都是不可用的。
這在語法上,稱爲「暫時性死區」 temporal dead zone,簡稱 TDZ。
(3)不容許重複聲明
let不容許在相同做用域內,重複聲明同一個變量。
const命令
const聲明的變量不得改變值,這意味着,const一旦聲明變量,就必須當即初始化,不能留到之後賦值。
const聲明一個只讀的常量。一旦聲明,常量的值就不能改變。
const聲明的常量能夠更改值嗎
const a = [1, 2, 3];
a.push(4);
console.log(a)// 輸出[1,2,3,4]
const實際上保證的,並非變量的值不得改動,而是變量指向的那個內存地址所保存的數據不得改動。對於簡單類型的數據(數值、字符串、布爾值),值就保存在變量指向的那個內存地址,所以等同於常量。但對於複合類型的數據(主要是對象和數組),變量指向的內存地址,保存的只是一個指向實際數據的指針,const只能保證這個指針是固定的(即老是指向另外一個固定的地址),至於它指向的數據結構是否是可變的,就徹底不能控制了。所以,將一個對象聲明爲常量必須很是當心。
const foo = {};
// 爲 foo 添加一個屬性,能夠成功
foo.prop = 123;
foo.prop // 123
// 將 foo 指向另外一個對象,就會報錯
foo = {}; // TypeError: "foo" is read-only
上面代碼中,常量foo儲存的是一個地址,這個地址指向一個對象。不可變的只是這個地址,即不能把foo指向另外一個地址,但對象自己是可變的,因此依然能夠爲其添加新屬性。
參考:let 和 const 命令
http://es6.ruanyifeng.com/#do...
let const var 的區別?
一、let是es6新增的聲明變量的方式 ,其特色是:
(1)做用域是塊級做用域(在ES6以前,js只存在函數做用域以及全局做用域)
if(1){
let a=1;
console.log(a)
}
(2)不存在變量聲明提早;
console.log(b); //ReferenceError: b is not defined let b=2;
(3) 不能重複定義
let a=1; let a=2; console.log(a);//Identifier 'a' has already been declared
(4)存在暫時性死區:能夠這樣來理解
var a=1;
if(1){
console.log(a);
let a=2;
}
① 在一個塊級做用域中,變量惟一存在,一旦在塊級做用域中用let聲明瞭一個變量,那麼這個變量就惟一屬於這個塊級做用域,不受外部變量的影響;
② 不管在塊中的任何地方聲明瞭一個變量,那麼在這個塊級做用域中,任何使用這個名字的變量都是指這個變量,不管外部是否有其餘同名的全局變量;
③ 暫時性死區的本質就是,只要一進入當前做用域,所要使用的變量就已經存在了,可是不可獲取,只有等到聲明變量的那一行代碼出現,才能夠獲取和使用該變量。
④ 暫時性死區的意義:讓咱們標準化代碼。將全部的變量的聲明放在做用域的最開始。
二、 const通常用來聲明常量,且聲明的常量是不容許改變的,只讀屬性,所以就要在聲明的同時賦值。const與let同樣,都是塊級做用域,存在暫時性死區,不存在變量聲明提早,不容許重複定義
const A=1;(從新給常量A賦值會報錯 )A=3;// Uncaught TypeError: Assignment to constant variable.(錯誤:賦值給常量)
三、 var 是es6以前 js用來聲明變量的方法,其特性是:
(1)var的做用域是函數做用域,在一個函數內利用var聲明一個變量,則這個變量只在這個函數內有效
function test(){
var a=1;
console.log(a);//函數未調用 輸出的是undefined 函數調用輸出的是1
}
console.log(a);//ReferenceError:a is not defined
(2)存在變量聲明提早(雖然變量聲明提早,但變量的賦值並無提早,所以下面的程序不會報錯,但a的值爲undefined)
function test(){
console.log(a);//undefined
var a=3/a=3(隱式聲明)
}
參考:let,const以及var三者的區別,面試常常會問哦!
https://blog.csdn.net/lydia11...
第七種數據類型Symbol
https://www.jianshu.com/p/f40...
Symbol函數會生成一個惟一的值
能夠理解爲Symbol類型跟字符串是接近的
但每次生成惟一的值,也就是每次都不相等,
至於它等於多少,並不重要,這對於一些字典變量,比較有用
每一個Symbol實例都是惟一的。所以,當你比較兩個Symbol實例的時候,將總會返回false
應用場景:能夠使用Symbol來做爲對象屬性名(key)
在這以前,咱們一般定義或訪問對象的屬性時都是使用字符串,而如今,Symbol可一樣用於對對象屬性的定義和訪問,當使用了Symbol做爲對象的屬性key後,Symbol類型的key是不能經過Object.keys()或者for…in來枚舉的,它被包含在對象自身的屬性名集合(property names)之中。因此,利用該特性,咱們能夠把一些不須要對外操做和訪問的屬性使用Symbol來定義。也正由於這樣一個特性,當使用JSON.stringfy()將對象轉換成JSON字符串的時候,Symbol屬性也會被排除在輸出內容以外,咱們能夠利用這一特色來更好的設計咱們的數據對象,讓"對內操做"和"對外選擇性輸出"變得更加優雅。
數組的解構賦值
請實現該缺乏的內部代碼,交換兩個數的值
ES5:交換
var res = (function(x,y){
let temp = x;
x= y;
y = temp;
return {
x:x,
y:y
}
})(1,2)
console.log(res.x)
console.log(res.y)
ES6:數組解構賦值
var res = (function (x, y) {
[y,x] = [x,y]
return {
x: x,
y: y
}
})(1, 2)
console.log(res.x)
console.log(res.y)
參考:數組的擴展
http://es6.ruanyifeng.com/?se...
ES6中構造函數內super關鍵字的使用
super關鍵字用於訪問和調用一個對象的父對象上的函數,是用來繼承屬性的 ES6 初始化對象的屬性,在構造函數中使用時,super關鍵字將單獨出現,而且必須在使用this關鍵字以前使用。
JavaScript
TypeScript
TypeScript 是 JavaScript 的一個超集,支持 ECMAScript 6 標準。
const hello : string = "Hello World!"
console.log(hello)
讓js語言更加的嚴謹
JS裏面新建函數的方法?
- 經過new
var func = new Function("參數","函數體")
var func = new Function(「num1」,「num2」,「return num1 + num2」)
var result = func(1,1)
console.log(result)//2
- 經過函數表達式
var sum = function(num1,num2){
return num1 + num2
}
var result = sum(10,20)
console.log(result)
- 經過函數聲明
function sum(num1,num2){
//上面的邏輯
}
DOM流
什麼是事件流
事件流:描述的就是從頁面中接受事件的順序。
分有事件冒泡與事件捕獲兩種。
DOM事件流的三個階段
- 事件捕獲階段
- 處於目標階段
- 事件冒泡階段
參考:DOM事件流
https://www.cnblogs.com/cmyou...
阻止事件冒泡和默認行爲的方法
event.preventDefault() 阻止默認行爲
event.stopPropagation() 阻止冒泡
非W3C標準:
e.cancelBubble=true 阻止事件冒泡
return false 阻止默認行爲
return false 表明即阻止事件冒泡,又阻止了默認行爲
事件委託的實現流程
- 找到要添加事件的節點:父節點、或者祖父節點
- 把事件添加在找到的父節點上
- 經過target觸發對象,找到複合條件的元素節點,進行後續操做
IE:window.event.srcElement
標準:event.targe
window.onload = function(){
var oUl = document.getElementById('ull');
var aLi = document.getElementsByTagName('li');
oUl.onmouseover = function(ev){
var event = ev||window.event; // 獲取event對象
var target = ev.target || ev.srcElement; // 獲取觸發事件的目標對象
if(target.nodeName.toLowerCase() == 'li'){ //判斷目標對象是否是li
target.style.background = 'red';
}
}
代碼中加了一個標籤名的判斷,主要緣由是若是不加判斷,當你鼠標移入到父級oUL上面的時候,整個列表就會變紅,這不是咱們想要的結果,因此要判斷一下。
target.nodeName 彈出的名字是大寫的,因此須要轉換大小寫再比較。
事件委託的實現是利用事件冒泡的機制
事件冒泡:由裏向外逐漸觸發
事件捕獲:由外向裏逐漸觸發
事件監聽器
- 可以給一個事件,添加多個函數
- 精確地刪除某一個事件某一個函數(經過函數名)
- 會對稱重複添加的函數,自動去重
*事件監聽器是用來解決傳統事件綁定的問題,通常狀況下(99%)用傳統的事件綁定
數據類型
Javascript的基本數據類型
Number:數字(整數,浮點數float)
Array:數組
Object:對象
布爾類型:Boolean a==b
特殊類型:Null、Undefined、NaN
console.log(1+」2"+"2") //122 console.log(「1"-'2'+'2') //-12 console.log(‘A'+"B"+"2") //ab2 console.log(「A」-"B"+2)//NaN
JavaScript建立對象的幾種方式
工廠方式,構造函數方式,原型模式,混合構造函數原型模式,動態原型方式
null和undefined的區別
null == undefined //true
null !==undefined
undefined:
(1)變量被聲明瞭,但沒有賦值時,就等於undefined。
(2) 調用函數時,應該提供的參數沒有提供,該參數等於undefined。
(3)對象沒有賦值的屬性,該屬性的值爲undefined。
(4)函數沒有返回值時,默認返回undefined。
null是空值,解除一段關係,把對象賦值成一個空指針,避免內存泄漏,不用的DOM對象通常指向爲空,例如:arr = null,不佔用內存。
數據類型不一樣:
typeof (undefined):undefined
typeof(null):object
補充:0和null的區別
0是一個數值,是天然數,有大小
0不等於null
call和apply和bind的區別
三者都是強制改變this的指向
在說區別以前仍是先總結一下三者的類似之處:
一、都是用來改變函數的this對象的指向的。
二、第一個參數都是this要指向的對象。
三、均可以利用後續參數傳參。
傳參數的區別:
參數形式不一樣,call(obj, pra, pra)後面是單個參數。apply(obj, [args])後面是數組。
Object.call(this,obj1,obj2,obj3) call須要一個一個傳參
Object.apply(this,arguments) apply能夠傳遞數組
call與apply都屬於Function.prototype的一個方法,因此每一個function實例都會有call/apply屬性。fn.call,fn是函數,函數下面有一個call方法,fn調用。二者傳遞參數不一樣,call函數第一個參數都是要傳入當前對象的對象,apply不是,apply傳入的是一個參數數組,也就是將多個參數組合成爲一個數組傳入。Call傳入則是直接的參數列表,Call方法能夠將一個函數的對象上下文從初始的上下文改爲由thisObj指定的新對象。

call和apply當即修改this,Bind綁定的時候不會立馬去執行,當函數調用的時候bind纔會執行。
參考:javascript中apply、call和bind的區別
https://www.cnblogs.com/cosir...
break和continue的區別
break 終止當前循環的
continue 跳過此次循環,直接進入下一次循環。
聲明提高
程序運行以前,有一個預編譯。
預編譯,會將代碼從頭看到尾,將須要的資源(內存)準備好。
而後纔開始運動。
代碼運行結果
var a; alert(typeof a); alert(b); //報錯 var c = null; alert(typeof c)
運行結果:Undefined/報錯:b is not defined
var a; alert(typeof a); alert(typeof b); //undefined var c = null; alert(typeof c)
運行結果:Undefined/undefined/object
typeof:即便你沒有定義這個變量也不會報錯 只會彈出undefined
alert(typeof typeof undefined) // string
運行結果:string
var bb = 1;
function aa(bb) {
bb = 2;
alert(bb);
}
aa(bb); //2
alert(bb);//1 沒有更改全局變量
運行結果:2 1
var bb = 1;
function aa() {
bb = 2;
alert(bb);
}
aa(bb); //2
alert(bb);//1 沒有更改全局變量
運行結果:2 2
若是外部不傳入bb,至關於你又聲明瞭一個bb,因此結果是2 2
function Foo() {
var i = 0;
return function () {
console.log(i++);
}
}
var f1 = Foo();
f2 = Foo();
f1();//0 f1執行 打印i的值 i++是後+
f1();//1 f1維護本身的i
f2();//0 f2是一個新的函數 拿到的是新的i變量
運行結果:0 1 0
已知前端頁面中,有以下table。請添加用戶交互效果,當用戶點擊該表格的某一行的時候,該行背景色設置爲紅色的代碼。
<table id="t1">
<tr></tr>
<tr></tr>
...
<tr></tr>
</table>
用jq來實現:讓當前點擊的對象改變背景顏色
var trDoms = document.getElementsByTagName("tr")
for (var i = 0; i < trDoms.length; i++) {
trDoms[i].onclick = function () {
this.style.background = "red"
console.log(i)
}
}
運行結果:3 3 3
想實現打印結果爲:0 1 2,應如何操做?
第一種方法:獲取對應索引
var trDoms = document.getElementsByTagName("tr")
for (var i = 0; i < trDoms.length; i++) {
trDoms[i].index = i;
trDoms[i].onclick = function () {
this.style.background = "red"
console.log(this.index)
}
}
第二種方法:閉包
var trDoms = document.getElementsByTagName("tr")
for (var i = 0; i < trDoms.length; i++) {
trDoms[i].onclick = function (i) {
return function(){
console.log(i)
}
}(i)
}
第三種方法:var改爲let做用域
var trDoms = document.getElementsByTagName("tr")
for (let i = 0; i < trDoms.length; i++) {
trDoms[i].onclick = function () {
console.log(i)
}
}
請問如下結果會輸出什麼
for (var i = 0; i < 5; i++) {
console.log(i);
}// 0 1 2 3 4
for (var i = 0; i < 5; i++) {
setTimeout(function () {
console.log(i);
}, 1000 * i);
} // 異步打印5個5
for (var i = 0; i < 5; i++) {
(function (i) {
setTimeout(function () {
console.log(i);
}, 1000 * i);
})(i);
} // 異步打印 0 1 2 3 4 (閉包寫法)
for (var i = 0; i < 5; i++) {
(function () {
setTimeout(function () {
console.log(i);
}, 1000 * i);
})(i);
} // 打印5個5(function不傳i,i就是全局的i)
for (var i = 0; i < 5; i++) {
setTimeout((function () {
console.log(i);
})(i), 1000 * i);
} // 0 1 2 3 4
var myObject = {
foo: "bar",
func: function () {
var self = this;
console.log("outer func:",this.foo);//bar
console.log("outer func:",self.foo);//bar
(function () {
console.log("inner func",this.foo); //undefined 即時函數中this指向window
console.log("inner func",self.foo); //bar
})();
}
}
myObject.func();
(function () {
var a = b = 1; //聲明局部變量 外部訪問不到局部變量
})();
console.log(typeof a); //undefined 外部訪問不到內部聲明的局部變量
console.log(typeof b); //number
function DateDemo() {
for (var i = 0, j = 0; i < 10, j < 6; i++ , j++) {
k = i + j;
}
return k;
}
var t = DateDemo()
console.log(t)//10:5+5
設計模式
設計模式的分類
整體來講設計模式分爲三大類:
建立型模式,共五種:工廠方法模式、抽象工廠模式、單例模式、建造者模式、原型模式。
結構型模式,共七種:適配器模式、裝飾器模式、代理模式、外觀模式、橋接模式、組合模式、享元模式。
行爲型模式,共十一種:策略模式、模板方法模式、觀察者模式、迭代子模式、責任鏈模式、命令模式、備忘錄模式、狀態模式、訪問者模式、中介者模式、解釋器模式。
其實還有兩類:併發型模式和線程池模式。
閉包
閉包是什麼
閉包是指有權訪問另外一個函數做用域中變量的函數,建立閉包的最多見的方式就是在一個函數內建立另外一個函數,經過另外一個函數訪問這個函數的局部變量,利用閉包能夠突破做用鏈域,將函數內部的變量和方法傳遞到外部。
閉包的特性
- 函數內再嵌套函數
- 內部函數能夠引用外層的參數和變量
- 參數和變量不會被垃圾回收機制回收
閉包的做用
閉包用的多的兩個做用:讀取函數內部的變量值;讓這些變量值始終保存着(在內存中)。
同時須要注意的是:閉包慎用,不濫用,不亂用,因爲函數內部的變量都被保存在內存中,會致使內存消耗大。
閉包的優勢
- 既不聲明全局變量
- 又能進行累加
- 但願一個變量常駐在內存當中,避免全局變量污染
- 能夠聲明私有成員
閉包的缺點
濫用閉包函數會形成內存泄露,由於閉包中引用到的包裹函數中定義的變量都永遠不會被釋放,因此咱們應該在必要的時候,及時釋放這個閉包函數。
用一個案例解釋閉包的做用
執行say667()後,say667()閉包內部變量會存在,而閉包內部函數的內部變量不會存在。使得Javascript的垃圾回收機制GC不會收回say667()所佔用的資源,由於say667()的內部函數的執行須要依賴say667()中的變量。這是對閉包做用的很是直白的描述。
function say667() {
// Local variable that ends up within closure
var num = 666;
var sayAlert = function() { alert(num);
}
num++;
return sayAlert;
}
var sayAlert = say667();
sayAlert() //執行結果應該彈出的667
參考:
什麼是閉包(closure),爲何要用它?
https://www.cnblogs.com/lqzwe...
什麼是閉包?寫一個簡單的閉包?
答:個人理解是,閉包就是可以讀取其餘函數內部變量的函數。在本質上,閉包就是將函數內部和函數外部鏈接起來的一座橋樑.

閉包的主要應用場景
- 匿名自執行函數
- 緩存
- 封裝
- 實現類和繼承
參考; javascript中的閉包主要在哪些地方用到
https://zhidao.baidu.com/ques...
爲何要使用匿名函數自執行函數,好處是什麼
定義變量時須要加上var,不然會默認添加到全局對象的屬性上,或者別的函數可能誤用這些變量;或者形成全局對象過於龐大,影響訪問速度(由於變量的取值是須要從原型鏈上遍歷的), 實際中有的函數只調用一次使用自執行函數也是很好的。
咱們建立了一個匿名的函數,並當即執行它,因爲外部沒法引用它內部的變量,所以在執行完後很快就會被釋放,關鍵是這種機制不會污染全局對象。
哪些操做會形成內存泄漏
內存泄漏指任何對象在您再也不擁有或須要它以後仍然存在。
垃圾回收器按期掃描對象,並計算引用了每一個對象的其餘對象的數量。若是一個對象的引用數量爲 0(沒有其餘對象引用過該對象),或對該對象的唯一引用是循環的,那麼該對象的內存便可回收。
- setTimeout 的第一個參數使用字符串而非函數的話,會引起內存泄漏。
- 閉包
- 控制檯日誌
- 循環(在兩個對象彼此引用且彼此保留時,就會產生一個循環)
參考:
Js內存泄漏及解決方案
https://www.cnblogs.com/carek...
JS哪些操做會形成內存泄漏?
https://www.jianshu.com/p/763...
Javascript中的垃圾回收機制
在Javascript中,若是一個對象再也不被引用,那麼這個對象就會被GC回收。若是兩個對象互相引用,而再也不被第3者所引用,那麼這兩個互相引用的對象也會被回收。由於函數a被b引用,b又被a外的c引用,這就是爲何 函數a執行後不會被回收的緣由。
JS 垃圾回收機制的原理
內存泄漏:再也不用到的內存,沒有及時釋放,就叫作內存泄漏。解決內存的泄露,垃圾回收機制會按期找出那些再也不用到的內存(變量),而後釋放其內存。
如今各大瀏覽器一般採用的垃圾回收機制有兩種方法:標記清除,引用計數。
-
標記清除:js中最經常使用的垃圾回收方式就是標記清除。當變量進入環境時,例如,在一個函數中聲明一個變量,就將這個變量標記爲"進入環境",從邏輯上講,永遠不能釋放進入環境變量所佔用的內存,由於只要執行流進入相應的環境,就可能會用到它們。而當變量離開環境時,則將其標記爲"離開環境"。
function test(){ var a = 10; *//*被標記*"*進入環境*"* var b = "hello"; *//*被標記*"*進入環境*"* test(); *//*執行完畢後以後,*a*和*b*又被標記*"*離開環境*"*,被回收 -
引用計數:語言引擎有一張"引用表",保存了內存裏面全部資源(一般是各類值)的引用次數。若是一個值的引用次數是0,就表示這個值再也不用到了,所以能夠將這塊內存釋放。若是一個值再也不須要了,引用數卻不爲0,垃圾回收機制沒法釋放這塊內存,從而致使內存泄漏。
const arr = [1,2,3,4]; console.log("hello world")
上面的代碼中,數組[1,2,3,4]是一個值,會佔用內存。變量arr是僅有的對這個值的引用,所以引用次數爲1。儘管後面的代碼沒有用到arr,它是會持續佔用內存。
若是增長一行代碼,解除arr對[1,2,3,4]引用,這塊內存就能夠被垃圾回收機制釋放了。
let arr = [1,2,3,4];
console.log("hello world");
arr = null;
上面代碼中,arr重置爲null,就解除了對[1,2,3,4]的引用,引用次數變成了0,內存就能夠釋放出來了。
所以,並非說有了垃圾回收機制,程序員就輕鬆了。你仍是須要關注內存佔用:那些很佔空間的值,一旦再也不用到,你必須檢查是否還存在對它們的引用。若是是的話,就必須手動解除引用
JavaScript this指針、閉包、做用域
this:指向調用上下文
閉包:內層做用域能夠訪問外層做用域的變量
做用域:定義一個函數就開闢了一個局部做用域,整個js執行環境有一個全局做用域
原型鏈
JavaScript原型,原型鏈 ? 有什麼特色?

* 原型對象也是普通的對象,是對象一個自帶隱式的 proto 屬性,原型也有可能有本身的原型,若是一個原型對象的原型不爲null的話,咱們就稱之爲原型鏈。
* 原型鏈是由一些用來繼承和共享屬性的對象組成的(有限的)對象鏈。
* JavaScript的數據對象有那些屬性值?
writable:這個屬性的值是否能夠改。
configurable:這個屬性的配置是否能夠刪除,修改。
enumerable:這個屬性是否能在for…in循環中遍歷出來或在Object.keys中列舉出來。
value:屬性值。
* 當咱們須要一個屬性的時,Javascript引擎會先看當前對象中是否有這個屬性, 若是沒有的話,就會查找他的Prototype對象是否有這個屬性。
function clone(proto) {
function Dummy() { }
Dummy.prototype = proto;
Dummy.prototype.constructor = Dummy;
return new Dummy(); //等價於Object.create(Person);
}
function object(old) {
function F() {};
F.prototype = old;
return new F();
}
var newObj = object(oldObject);
Javascript如何實現繼承?
原型鏈繼承,借用構造函數繼承,組合繼承,寄生式繼承,寄生組合繼承
數組
for-of和for-in的區別
遍歷數組的時候:
for-of經過key直接拿數組裏面的值
for-in經過key拿數組的索引
遍歷對象的時候:
for-in經過key拿屬性值
for-of不能夠遍歷對象
遍歷對象的方法,for of爲何不能遍歷對象?
for-of能夠遍歷的:arr/map/string,由於他們中實現了Symbol.iterator屬性
for of如何遍歷對象
注意:for-of目前js實現的對象有array,string,argument以及後面更高級的set,Map
當咱們遍歷對象的時候能夠使用for-in,不過這種遍歷方式會把原型上的屬性和方法也給遍歷出來,固然咱們能夠經過hasOwnProperty來過濾掉除了實例對象的數據,可是for-of在object對象上暫時沒有實現,可是咱們能夠經過Symbol.iterator給對象添加這個屬性,咱們就能夠使用for-of了,代碼以下:
var p = {
name:'kevin',
age:2,
sex:'male'
}
Object.defineProperty(p,Symbol.iterator,{
enumberable:false,
configurable:false,
writable:false,
value:function(){
var _this = this;
var nowIndex = -1;
var key = Object.keys(_this);
return {
next:function(){
nowIndex++;
return {
value:_this[key[nowIndex]],
done:(nowIndex+1>key.length)
}
}
}
}
})
//這樣的話就能夠直接經過for-of來遍歷對象了
for(var i of p){
console.log(i) //kevin,2,male
}
for-in遍歷數組存在的問題(for-in更適合遍歷對象)
var myArray = [1,2,4,5,6,7]
myArray.name = "殺馬特"
Array.prototype.method = function(){
console.log("length",this.length)
}
for(var index in myArray){
console.log("myArray",myArray[index])
}
使用for in 也能夠遍歷數組,可是會存在如下問題:
index索引爲字符串型數字,不能直接進行幾何運算 遍歷順序有可能不是按照實際數組的內部順序 使用for in會遍歷數組全部的可枚舉屬性,包括原型。例如上慄的原型方法method和name屬性 因此for in更適合遍歷對象,不要使用for in遍歷數組。

使用for-of遍歷數組:
//for-of遍歷數組
var myArray = [1, 2, 4, 5, 6, 7]
myArray.name = "殺馬特"
Array.prototype.method = function () {
console.log("length", this.length)
}
for (var index of myArray) {//這裏的index輸出的是value而不是索引
console.log("index", index)
}

for循環和forEach循環 哪一個能夠中止
for循環能夠經過break中止,forEach通常是沒有辦法終止跳出。
如何實現forEach的終止跳出?
思路1 break 不能用,不可行,執行後會報錯!
var arr = ['a','b','c']
arr.forEach((item,index) => {
if(item === 'b') break
console.log(item)
})
思路2 return false 會跳出當前的遍歷執行==》a,c
var arr = ['a','b','c']
arr.forEach((item,index) => {
if(item === 'b') return false
console.log(item)
})
思路3 try...catch 語句跳出異常 //a exit done
try {
arr.forEach((item,index) => {
if(item === 'b') throw new Error('exist')
console.log(item)
})
} catch (e) {
if(e.message=='exist'){
console.log(e.message)
throw e
}
} finally {
console.log('done')
}
程序最後能夠終止退出循環,因此使用try...catch經過拋出異常的方式來終止程序繼續執行是可行。
arr.map arr.filter arr.reduce的做用分別是?
【arr.map】
遍歷數組一般使用for循環,ES5的話也能夠使用forEach,ES5具備遍歷數組功能的還有map、filter、some、every、reduce、reduceRight等,只不過他們的返回結果不同。可是使用foreach遍歷數組的話,使用break不能中斷循環,使用return也不能返回到外層函數
arr.map循環遍歷,而且將符合條件的元素放入一個新數組返回
var arr = [1,2,3]
let b = [];
//map循環遍歷,而且返回一個新數組
let a = arr.map(item=>{
if(item>2){
b.push(item)
return b
}
})
console.log(b) //返回符合條件的新數據[3]
由於react中沒有v-for指令,因此循環渲染的時候須要用到arr.map方法來渲染視圖
【arr.filter】
arr.filter 過濾器 能夠過濾掉不符合要求的元素,內部返回false就直接過濾掉了,將符合條件的數據返回,也是不影響原數組。
//過濾器
arr = arr.filter(item=>{
return item>2
})
console.log(arr) //過濾出來符合條件的數據[3]
【arr.reduce】
reduce爲數組中每個元素依次執行回調函數,不包括數組中被刪除或從未被賦值的元素,接收四個參數:初始值(或者上一次回調函數的返回值),當前元素值,當前索引,調用reduce的數組。reduce方法能夠搞定的東西for循環或者forEach方法有時候也能夠搞定。
var newArr = [4,5,6,7]
newArr.reduce((res,currentValue,index,arr)=>{//第一個參數爲一個回調函數
console.log(res,currentValue,index) //4,5,1
})
//res:默認爲第一個值(4),currentValue:當前值(5),index:當前值的索引(1)
let result = newArr.reduce((res,currentValue,index,arr)=>{
console.log(res,currentValue) //第一次:4,5;第二次:9,6;第三次:15,7
return res+currentValue//第一次:9;第二次:15;第三次:22;最後結果爲22
},10)//第二個參數爲一個初始值,這裏給它賦值爲10
console.log(result)//如今res就變成了10,currentValue變成了4,依次累加,10+22 初始值+累加值
Filter、forEach、map、reduce之間的區別聯繫?
做用
every():對數組中的每一項運行給定函數,若是該函數對每一項都返回 true ,則返回 true。
some():對數組中的每一項運行給定函數,若是該函數對任一項返回 true ,則返回 true
filter():對數組中的每一項運行給定函數,返回該函數會返回 true 的項組成的數組。
forEach():對數組中的每一項運行給定函數。這個方法沒有返回值。
map():對數組中的每一項運行給定函數,返回每次函數調用的結果組成的數組。
相同點
他們的參數都同樣:
-
在每一項上運行的函數(該函數有三個參數)
- 函數第一個參數:數組項的值
- 函數第二個參數:數組項的索引
- 函數第三個參數:數組對象自己
- 運行該函數的做用域對象——影響this的值(可選)
區別
filter()、forEach()、map()、some()、every()都是對數組的每一項調用函數進行處理。
區別: – some()、every()的返回值 :true / false – filter()、map()的返回值 :一個新數組 – forEach()無返回值。
使用filter()、forEach()、map()、some()、every()都不改變原數組。
參考:js小記:filter()、forEach()、map()、reduce()、reduceRight()的區別
https://blog.csdn.net/b954960...
splice()
splice(index,len,[item]) 註釋:該方法會改變原始數組。
//刪除起始下標爲1,長度爲1的一個值(len設置1,若是爲0,則數組不變) var arr = ['a','b','c','d']; arr.splice(1,1); console.log(arr); //['a','c','d']; //替換起始下標爲1,長度爲1的一個值爲‘ttt’,len設置的1 var arr = ['a','b','c','d']; arr.splice(1,1,'ttt'); console.log(arr); //['a','ttt','c','d'] var arr = ['a','b','c','d']; arr.splice(1,0,'ttt'); console.log(arr); //['a','ttt','b','c','d'] 表示在下標爲1處添加一項'ttt'
slice()
slice()方法能夠基於當前數組獲取指定區域元素 [start, end)
格式:數組.slice(start, end);
參數:start和end都是下標,[start, end),獲取指定範圍內的元素,生成新數組。(原數組是不會改變的。)
返回值:提取出來元素組成的新數組。
split()和join()的區別
join函數獲取一批字符串,而後用分隔符字符串將它們鏈接起來,從而返回一個字符串。
split()函數獲取一個字符串,而後在分隔符處將其斷開,從而返回一批字符串。
可是,這兩個函數之間的區別在於join能夠使用任何分割字符串將多個字符串鏈接起來,而split()只能使用一個字符分隔符將字符串斷開。
簡單地說,若是你用split(),是把一串字符串(根據某個分隔符)分紅若干個元素存放在一個數組裏。而join是把數組中的字符串鏈接成一個長串,能夠大致上認爲是split的逆操做。
push、pop、shift、unshift
-
push()方法能夠在數組的末屬添加一個或多個元素 -
shift()方法把數組中的第一個元素刪除 -
unshift()方法能夠在數組的前端添加一個或多個元素 -
pop()方法把數組中的最後一個元素刪除
參考:數組的push()、pop()、shift()和unshift()方法
https://blog.csdn.net/qwe5027...
數組的方法
解析連接www.qq.com?name=jack&age=18&id=100,獲取其中的查詢參數,並格式爲js對象的代碼:如: {name:」jack」,age:18,id:100}
var str = "www.qq.com?name=jack&age=18";
var str2 = str.substring(str.lastIndexOf(「?")+1); //索引從後往前找
var arr = str2.split(「&」);//經過&符號去切割 切割成以下形式[‘name = jack’,’age=18’,'id=100']
var json = {};
for(var i=0;i<arr.length;i++){ //循環遍歷數組的長度
var newArr = arr[i].split(「=「); //拿到每個字符串 拿到以後經過split進行切割 [‘name’,’jack’]
json[newArr[0]] = newArr[1]; // key名=value
}
考查知識點:數組截取方法/數組中字符串操做/對象的中括號會不會用
對象的、數組的、字符串的相關的使用的比較多的方法
下列代碼的運行結果是:
var array1 = [1,2]; var array2 = array1; // 數組指向的是同一個地址 array1[0] = array2[1]; // 把array[1]拿出來放在array1[0]的位置變成2,2 array2.push(3); console.log(array1);// [2,2,3] console.log(array2);// [2,2,3]
var arr = [1,2]
arr2 = arr;//arr2和arr1指向的是同一塊內存空間
arr2.push(3)
console.log(arr) //[1,2,3]
var arr = [1,2]
arr2 = arr
arr = [1,2,3] //arr 指向了新的內存空間
arr2.push(4)
console.log(arr)//[1,2,3]
console.log(arr2)//[1,2,4]
var a = {n:1}
var b = a;
a.x = a = {n:2}
console.log(a); //a賦值了一個新的地址 輸出{n:2}
console.log(b); //b指向的是a原來的地址 輸出{n:1,x:{n:2}}
JS數組去重
- 利用splice方法
var arr = [10, 20, 30, 40, 50, 40, 30, 20, 20, 20, 20, 10];
function norepeat(arr){
for(var i = 0; i < arr.length - 1; i++){
for(var j = i + 1; j < arr.length; j++){
if(arr[i] === arr[j]){
arr.splice(j,1);
j--
}
}
}
}
alert(arr);//10,20,30,40,50,40,30,20,20,20,20,10
norepeat(arr);
alert(arr);//10,20,30,40,50
- 倒序刪除
//倒序刪除
function norepeat(arr){
for(var i = arr.length -1; i > 0; i--){
for(var j = i - 1;j >= 0; j--){
if(arr[i] === arr[j]){
arr.splice(j,1);
}
}
}
}
alert(arr);//10,20,30,40,50,40,30,20,20,20,20,10
norepeat(arr);
arr.reverse();
alert(arr);//10,20,30,40,50
- 利用對象的屬性不會重複這一特性,校驗數組元素是否重複
function unique(arr){
var obj = {};
var result = [];
for(var i=0;i<arr.length;i++){
if(!obj[arr[i]]){
result.push(arr[i]);
obj[arr[i]] = true; //將每一個數做爲key,屬性值值爲true,當key名相同時,判斷屬性值是否爲false,不爲false則不push進數組
}
}
return result;
}
- ES6中新增了數據類型set,set的一個最大的特色就是數據不重複。Set函數能夠接受一個數組(或類數組對象)做爲參數來初始化,利用該特性也能作到給數組去重。
Set集合是默認去重複的,但前提是兩個添加的元素嚴格相等,因此5和"5"不相等,兩個new出來的字符串不相等。
下面展現了一種極爲精巧的數組去重的方法
var newarr = [...new Set(array)];
//拓展 固定寫法
alert(arr);//10,20,30,40,50,40,30,20,20,20,20,10
//下述寫法的值,就是去重之後的數組。
arr = [...new Set(arr)];
alert(arr);//10,20,30,40,50
跨域
什麼是跨域
因爲 Javascript 同源策略的存在使得一個源中加載來自其它源中資源的行爲受到了限制。即會出現跨域請求禁止。
通俗一點說就是若是存在協議、域名、端口或者子域名不一樣服務端,或一者爲IP地址,一者爲域名地址(在跨域問題上,域僅僅是經過「 url的首部 」來識別而不會去嘗試判斷相同的IP地址對應着兩個域或者兩個域是否同屬同一個IP),之中任意服務端旗下的客戶端發起請求其它服務端資源的訪問行動都是跨域的,而瀏覽器爲了安全問題通常都限制了跨域訪問,也就是不容許跨域請求資源。
同源策略
- 同協議
- 同域名
- 同端口號
解決跨域問題的主流方案是什麼
- Jsonp 利用script標籤發起get請求不會出現跨域禁止的特色實現
- window.name+iframe 藉助中介屬性window.name實現
- html5的 postMessage 主要側重於前端通信,不一樣域下頁面之間的數據傳遞
- Cors須要服務器設置header:Access-Control-Allow-Origin
- Nginx反向代理 能夠不須要目標服務器配合,不過須要Nginx中轉服務器,用於轉發請求(服務端之間的資源請求不會有跨域限制)
參考:Nginx反向代理、CORS、JSONP等跨域請求解決方法總結
https://blog.csdn.net/diudiu5...
cors實現請求跨域
https://blog.csdn.net/badmoon...
JQuery跨域方式
- 修改ajax的請求頭(儘可能不要用)
改爲"Access-control-Allow-Origin"
- 經過PHP文件做爲中轉站,進行間接跨源(爬蟲)
- JSONP跨域
JSONP原理
動態建立script標籤,src屬性鏈接接口地址,callback參數就是服務器返回給咱們的數據。
缺點:jsonp只支持get請求方式,post方式不支持。
JSONP跨域的流程
- 在資源加載進來以前定義好一個函數,這個函數接收一個參數(數據),函數裏面利用這個參數作一些事情。
- 而後須要的時候經過script標籤加載對應的遠程文件資源。
- 當遠程文件加載進來的時候,就會去執行咱們前面定義好的函數,而且把數據當作這個函數中的參數傳進去。
JSONP跨域的缺點
- 它只支持GET請求而不支持POST等其它類型的HTTP請求;
- 它只支持跨域HTTP請求這種狀況,不能解決不一樣域的兩個頁面之間如何進行JavaScript調用的問題
- json文件不能用jsonp方法。
AJAX
什麼是AJAX
AJAX是一種用於快速建立動態網頁的技術,經過在後臺與服務器進行少許數據交換,AJAX能夠實現網頁實現異步更新,這意味着能夠在不加載整個網頁的狀況下,對網頁的某部分進行更新。
傳統的網頁(不使用AJAX)若是須要更新內容,必須重載整個網頁。
AJAX的原理
思路:先解釋異步,再解釋ajax如何使用
Ajax的原理簡單來講經過XmlHttpRequest對象來向服務器發異步請求,從服務器得到數據,而後用javascript來操做DOM而更新頁面。這其中最關鍵的一步就是從服務器得到請求數據。要清楚這個過程和原理,咱們必須對 XMLHttpRequest有所瞭解。
XMLHttpRequest是ajax的核心機制,它是在IE5中首先引入的,是一種支持異步請求的技術。簡單的說,也就是javascript能夠及時向服務器提出請求和處理響應,而不阻塞用戶。達到無刷新的效果。
AJAX的優勢
AJAX不是新的編程語言,而是一種使用現有標準的新方法。
AJAX最大的優勢是在不從新加載整個頁面的狀況下,能夠與服務器交換數據並更新部分網頁內容。
AJAX不須要任何瀏覽器插件,但須要用戶容許JavaScript在瀏覽器上運行。
AJAX的缺點
- AJAX幹掉了Back和History功能,即對瀏覽器機制的破壞。 在動態更新頁面的狀況下,用戶沒法回到前一個頁面狀態,由於瀏覽器僅能記憶歷史記錄中的靜態頁面。一個被完整讀入的頁面與一個已經被動態修改過的頁面之間的差異很是微妙;用戶一般會但願單擊後退按鈕可以取消他們的前一次操做,可是在Ajax應用程序中,這將沒法實現。
- 安全問題技術同時也對IT企業帶來了新的安全威脅,ajax技術就如同對企業數據創建了一個直接通道。這使得開發者在不經意間會暴露比之前更多的數據和服務器邏輯。ajax的邏輯能夠對客戶端的安全掃描技術隱藏起來,容許黑客從遠端服務器上創建新的攻擊。還有ajax也難以免一些已知的安全弱點,諸如跨站點腳步攻擊、SQL注入攻擊和基於credentials的安全漏洞等。
- 對搜索引擎的支持比較弱。若是使用不當,AJAX會增大網絡數據的流量,從而下降整個系統的性能。
AJAX狀態碼說明
1**:請求收到,繼續處理
2**:操做成功收到,分析、接受
3**:完成此請求必須進一步處理
4**:請求包含一個錯誤語法或不能完成
5**:服務器執行一個徹底有效請求失敗
AJAX的流程
- 聲明Ajax對象xhr,建立 XMLHttpRequest 實例
IE8之後纔有以下聲明的方式
var xhr = new XMLHttpRequest();
XMLHttpRequest()是AJAX的原生對象
- 一旦新建實例,就能夠使用
open()方法發出 HTTP 請求。
填寫請求信息,發出 HTTP 請求
第一個參數:請求方式:get/post
第二個參數:url(統一資源定位符)
第三個參數:true/false true異步,false同步
xhr.open('GET', 'http://www.example.com/page.php', true);
- 向服務器發送請求
xhr.send(),正在發送請求
- 等待數據響應,接收服務器傳回的數據
xhr.onreadystatechange = function(){}
在回調函數中進行請求狀態readyState的監控
當 readyState 等於 4 且狀態爲 200 時,表示響應內容解析完成,能夠在客戶端調用了。
返回的內容:
responseText:返回以文本形式存放的內容
responseXML:返回XML形式的內容
- 更新網頁數據
AJAX中的GET和POST請求
get通常用來進行查詢操做,url地址有長度限制,請求的參數都暴露在url地址當中,若是傳遞中文參數,須要本身進行編碼操做,安全性較低。
post請求方式主要用來提交數據,沒有數據長度的限制,提交的數據內容存在於http請求體中,數據不會暴漏在url地址中。
GET 仍是 POST?
與 POST 相比,GET 更簡單也更快,而且在大部分狀況下都能用。
然而,在如下狀況中,請使用 POST 請求:
- 沒法使用緩存文件(更新服務器上的文件或數據庫)
- 向服務器發送大量數據(POST 沒有數據量限制)
- 發送包含未知字符的用戶輸入時,POST 比 GET 更穩定也更可靠
AJAX如何實現跨域
理解跨域的概念:協議、域名、端口都相同才同域,不然都是跨域。
出於安全考慮,服務器不容許ajax跨域獲取數據,可是能夠跨域獲取文件內容,因此基於這一點,能夠動態建立script標籤,使用標籤的src屬性訪問js文件的形式獲取js腳本,而且這個js腳本中的內容是函數調用,該函數調用的參數是服務器返回的數據,爲了獲取這裏的參數數據,須要事先在頁面中定義回調函數,在回調函數中處理服務器返回的數據,這就是解決跨域問題的主流解決方案。
一個頁面從輸入URL到頁面加載顯示完成,這個過程當中都發生了什麼?
分爲4個步驟:
- 當發送一個 URL 請求時,無論這個 URL 是 Web 頁面的 URL 仍是 Web 頁面上每一個資源的 URL,瀏覽器都會開啓一個線程來處理這個請求,同時在遠程 DNS 服務器上啓動一個 DNS 查詢。這能使瀏覽器得到請求對應的 IP 地址。
- 瀏覽器與遠程 Web 服務器經過 TCP 三次握手協商來創建一個 TCP/IP 鏈接。該握手包括一個同步報文,一個同步-應答報文和一個應答報文,這三個報文在 瀏覽器和服務器之間傳遞。該握手首先由客戶端嘗試創建起通訊,然後服務器應答並接受客戶端的請求,最後由客戶端發出該請求已經被接受的報文。
- 一旦 TCP/IP 鏈接創建,瀏覽器會經過該鏈接向遠程服務器發送 HTTP 的 GET 請求。遠程服務器找到資源並使用 HTTP 響應返回該資源,值爲 200 的 HTTP 響應狀態表示一個正確的響應。
- 此時,Web 服務器提供資源服務,客戶端開始下載資源。
從用戶輸入URL,到瀏覽器呈現給用戶頁面,通過了什麼過程?
用戶輸入URL,瀏覽器獲取到URL
瀏覽器(應用層)進行DNS解析(若是輸入的是IP地址,此步驟省略)
根據解析出的IP地址+端口,瀏覽器(應用層)發起HTTP請求,請求中攜帶(請求頭header(也可細分爲請求行和請求頭)、請求體body),
header包含:
請求的方法(get、post、put..)
協議(http、https、ftp、sftp...)
目標url(具體的請求路徑已經文件名)
一些必要信息(緩存、cookie之類)
body包含:
請求的內容
請求到達傳輸層,tcp協議爲傳輸報文提供可靠的字節流傳輸服務,它經過三次握手等手段來保證傳輸過程當中的安全可靠。經過對大塊數據的分割成一個個報文段的方式提供給大量數據的便攜傳輸。
到網絡層, 網絡層經過ARP尋址獲得接收方的Mac地址,IP協議把在傳輸層被分割成一個個數據包傳送接收方。
數據到達數據鏈路層,請求階段完成
接收方在數據鏈路層收到數據包以後,層層傳遞到應用層,接收方應用程序就得到到請求報文。
接收方收到發送方的HTTP請求以後,進行請求文件資源(如HTML頁面)的尋找並響應報文。
發送方收到響應報文後,若是報文中的狀態碼錶示請求成功,則接受返回的資源(如HTML文件),進行頁面渲染。
fetch
什麼是fetch?
fetch號稱是AJAX的替代品,是在ES6出現的,使用了ES6中的promise對象。Fetch是基於promise設計的。Fetch的代碼結構比起ajax簡單多了,參數有點像jQuery ajax。可是,必定記住fetch不是ajax的進一步封裝,而是原生js,沒有使用XMLHttpRequest對象。
try {
let response = await fetch(url);
let data = response.json();
console.log(data);
} catch(e) {
console.log("Oops, error", e);
}
fetch的優勢
- 符合關注分離,沒有將輸入、輸出和用事件來跟蹤的狀態混雜在一個對象裏。
- 更好更方便的寫法
fetch的優點
- 語法簡潔,更加語義化
- 基於標準 Promise 實現,支持 async/await
- 同構方便,使用 isomorphic-fetch
- 更加底層,提供的API豐富(request, response)
- 脫離了XHR,是ES規範裏新的實現方式
fetch的劣勢
- fetch只對網絡請求報錯,對400,500都當作成功的請求,服務器返回 400,500 錯誤碼時並不會 reject,只有網絡錯誤這些致使請求不能完成時,fetch 纔會被 reject。
- fetch默認不會帶cookie,須要添加配置項: fetch(url, {credentials: 'include'})
- fetch不支持abort,不支持超時控制,使用setTimeout及Promise.reject的實現的超時控制並不能阻止請求過程繼續在後臺運行,形成了流量的浪費
- fetch沒有辦法原生監測請求的進度,而XHR能夠
axios
axios是什麼
Axios 是一個基於 promise 的 HTTP 庫,能夠用在瀏覽器和 node.js 中,主要是用於向後臺發起請求的。
axios的用途
(1)向後臺發送ajax請求數據。
(2) axios能夠支持高併發請求,能夠同時請求多個接口。
(3) axios能夠防止CSRF/XSRF(跨站請求僞造)釣魚網站。
(4)axios提供了攔截器、catch捕獲。
封裝axios
Get
import axios from 'axios'
export default ({url,data})=>{
return axios.get(url,{
params:data
})
}
Post
import axios from 'axios'
import qs from 'querystring'
export default ({url,data})=>{
return axios.post(url,qs.stringify(data))
}
利用axios實現數據請求
引入axios以後就能夠在實例/組件上掛載一個$http屬性,用這個就能夠進行數據交互了。
提供了一個get方法,執行this.$http.get().then()能夠異步執行,拿到promise對象的值
axios如何防止CSRF(跨站攻擊)
在a頁面登陸註冊成功後時候跳轉到b頁面,b頁面能夠獲取你的cookie信息,把你的用戶信息攔截到,而後惡意向別的網站散發一些郵件或者其餘的東西,當你使用axios以後,就能夠防止這種攻擊,a頁面存儲的時候往cookie添加一個惟一個key,b頁面若是是別的域名是獲取不到這個key的,釣魚網站就是把b頁面這個域名篡改到別的位置去了,因此它沒法獲取到key值,也就拿不到用戶信息,這樣能夠防止釣魚網站的威脅。
如何在項目中經過路由守衛來實現登陸攔截?講一個在項目中使用路由守衛的案例?
攔截器的工做流程:

第一步:路由攔截
首先在定義路由的時候就須要多添加一個自定義字段requireAuth,用於判斷該路由的訪問是否須要登陸。若是用戶已經登陸,則順利進入路由, 不然就進入登陸頁面。
const routes = [
{
path: '/',
name: '/',
component: Index
},
{
path: '/repository',
name: 'repository',
meta: {
requireAuth: true, // 添加該字段,表示進入這個路由是須要登陸的
},
component: Repository
},
{
path: '/login',
name: 'login',
component: Login
}
];
定義完路由後,咱們主要是利用vue-router提供的鉤子函數beforeEach()對路由進行判斷。
router.beforeEach((to, from, next) => {
if (to.meta.requireAuth) { // 判斷該路由是否須要登陸權限
if (store.state.token) { // 經過vuex state獲取當前的token是否存在
next();
}
else {
next({
path: '/login',
query: {redirect: to.fullPath} // 將跳轉的路由path做爲參數,登陸成功後跳轉到該路由
})
}
}
else {
next();
}
})
其中,to.meta中是咱們自定義的數據,其中就包括咱們剛剛定義的requireAuth字段。經過這個字段來判斷該路由是否須要登陸權限。須要的話,同時當前應用不存在token,則跳轉到登陸頁面,進行登陸。登陸成功後跳轉到目標路由。
登陸攔截到這裏就結束了嗎?並無。這種方式只是簡單的前端路由控制,並不能真正阻止用戶訪問須要登陸權限的路由。還有一種狀況即是:當前token失效了,可是token依然保存在本地。這時候你去訪問須要登陸權限的路由時,實際上應該讓用戶從新登陸。
這時候就須要結合 http 攔截器 + 後端接口返回的http 狀態碼來判斷。(具體方法見下一題目)
axios+vue如何在前端實現登陸攔截?(路由攔截、http攔截)
登陸流程控制中,根據本地是否存在token判斷用戶的登陸狀況,可是即便token存在,也有可能token是過時的,因此在每次的請求頭中攜帶token,後臺根據攜帶的token判斷用戶的登陸狀況,並返回給咱們對應的狀態碼,然後咱們能夠在響應攔截器中,根據狀態碼進行一些統一的操做。
// 先導入vuex,由於咱們要使用到裏面的狀態對象
// vuex的路徑根據本身的路徑去寫
import store from '@/store/index';
// 請求攔截器axios.interceptors.request.use( //axios的一個方法,用於請求以前攔截
config => {
// 每次發送請求以前判斷vuex中是否存在token
// 若是存在,則統一在http請求的header都加上token,這樣後臺根據token判斷你的登陸狀況
// 即便本地存在token,也有可能token是過時的,因此在響應攔截器中要對返回狀態進行判斷
const token = store.state.token;
token && (config.headers.Authorization = token); (Authorization是後端自定義的名字) // 判斷vuex中是否存在token,若是存在的話,則在每一個http請求時header都加上token
return config; //再把這個請求發送給咱們的後臺
},
error => {
return Promise.error(error); //若是有錯誤直接返回報錯的相關內容
})
若是後臺傳遞過來的狀態碼是失效狀態,就須要在response響應攔截器中清除本地token和清空vuex中token對象,經過commit觸發mutations方法來同步更改vuex中的狀態,清空token以後跳轉到登陸頁面,讓用戶從新登陸。
// 清除token
localStorage.removeItem('token');
store.commit('loginSuccess', null);
// 跳轉登陸頁面,並將要瀏覽的頁面fullPath傳過去,登陸成功後跳轉須要訪問的頁面
setTimeout(() => {
router.replace({
path: '/login',
query: {
redirect: router.currentRoute.fullPath
}
});
}, 1000);
完整方法見:vue中Axios的封裝和API接口的管理
https://juejin.im/post/5b55c1...
vue+axios 前端實現登陸攔截(路由攔截、http攔截)
https://www.cnblogs.com/guoxi...
一個axios的簡單教程
https://www.jianshu.com/p/13c...
axios與fetch、ajax區別?
(1)fetch和axios差很少,都是基於promise的,fetch沒有封裝xhr(ajax的原生對象),是新的語法,默認不傳cookie,也監聽不到請求的進度,axios能夠監聽到請求的進度。
(2)axios返回一個promise對象,拿到對象以後再去.then能夠拿到resolve以後的內容。
axios.get(url,{params:{}}).then(res=>{}).catch(err=>{});
axios.post(url,{}).then(res=>).catch(err=>{});
(3)ajax主要是利用callback回調函數的形式。
JQuery中的ajax:$.ajax({url,data,success(){}}) 在回調函數獲取數據
axios 和 ajax 的使用方法基本同樣,只有個別參數不一樣;
axios({
url: 'http://jsonplaceholder.typicode.com/users',
method: 'get',
responseType: 'json', // 默認的
data: {
//'a': 1,
//'b': 2,
}
}).then(function (response) {
console.log(response);
console.log(response.data);
}).catch(function (error) {
console.log(error);
})
$.ajax({
url: 'http://jsonplaceholder.typicode.com/users',
type: 'get',
dataType: 'json',
data: {
//'a': 1,
//'b': 2,
},
success: function (response) {
console.log(response);
}
})
參考:ajax和axios、fetch的區別
https://www.jianshu.com/p/8bc...
JSON
什麼是 JSON ?
- JSON 指的是 JavaScript 對象表示法(JavaScript Object Notation)
- JSON 是輕量級的文本數據交換格式
- JSON 獨立於語言:JSON 使用 Javascript語法來描述數據對象,可是 JSON 仍然獨立於語言和平臺。JSON 解析器和 JSON 庫支持許多不一樣的編程語言。 目前很是多的動態(PHP,JSP,.NET)編程語言都支持JSON。
- JSON 具備自我描述性,更易理解
與 XML 相同之處
- JSON 是純文本
- JSON 具備"自我描述性"(人類可讀)
- JSON 具備層級結構(值中存在值)
- JSON 可經過 JavaScript 進行解析
- JSON 數據可以使用 AJAX 進行傳輸
與 XML 不一樣之處
- 沒有結束標籤
- 更短
- 讀寫的速度更快
- 可以使用內建的 JavaScript eval() 方法進行解析
- 使用數組
- 不使用保留字
爲何使用 JSON?
對於 AJAX 應用程序來講,JSON 比 XML 更快更易使用:
使用 XML
- 讀取 XML 文檔
- 使用 XML DOM 來循環遍歷文檔
- 讀取值並存儲在變量中
使用 JSON
- 讀取 JSON 字符串
- 用 eval() 處理 JSON 字符串
js中想要把json字符串轉化爲js對象的方式
- JSON.parse()
- eval()
假設咱們有一個json字符串
var str = '{"friends":[{"name":"梅梅","age":29,"sex":"女"},' +
'{"name":"李華","age":18,"sex":"男"}]' +
'}';
使用 JSON.parse()方法來轉化
var str = '{"friends":[{"name":"梅梅","age":29,"sex":"女"},' +
'{"name":"李華","age":18,"sex":"男"}]' +
'}';
JSON.parse(str);
使用 eval()方法傳化:
var str = '{"friends":[{"name":"梅梅","age":29,"sex":"女"},' +
'{"name":"李華","age":18,"sex":"男"}]' +
'}';
eval('('+str+')');
注意點: 經過 eval 來轉化,若是返回的字符串內容是一個數組,能夠直接轉化,若是返回的字符串內容是一個對象,必須在字符串的先後加上()
當字符串內容是一個數組時 ,eval()的轉化方式:
var arr = '[{"name":"唐老鴨","sex":"男"},{"name":"紅太狼","sex":"女"}]';
eval(arr);
#### JSON.parse() 和 eval() 的區別
- eval方法不會去檢查給的字符串是否符合json的格式,而JSON.parse解析不知足json格式的字符串時,會報錯。
-
若是給的字符串中存在js代碼eval也會一併執行,好比下面的代碼段:
var str1 = '{"log":alert("我被會執行的")}'; eval("("+str1+")");執行該代碼片斷,會將 alert 語句做爲js代碼來執行,若是咱們在開發中建議使用JSON.parse來轉化,這樣能夠避免不少隱患,好比,咱們訪問第三方提供的接口,返回的串中包含 window.location.href這樣的內容,那麼執行了就會跳轉到不明網站,好危險,因此最好仍是使用JSON.parse()來解析。
JSON.parse()
JSON 一般用於與服務端交換數據。
在接收服務器數據時通常是字符串。
咱們能夠使用 JSON.parse() 方法將數據轉換爲 JavaScript 對象。
JSON.parse(text[, reviver])
JSON.stringify()
JSON 一般用於與服務端交換數據。
在向服務器發送數據時通常是字符串。
咱們能夠使用 JSON.stringify() 方法將 JavaScript 對象轉換爲字符串。
JSON.stringify(value[, replacer[, space]])
Promise
同步異步函數的區別
同步:阻塞,當前程序必須等前面一個程序執行完畢之後,纔可以執行。
異步:非阻塞,前一個程序是否執行完畢,不影響後面程序的執行。
promise、async、await
async函數返回的是一個 Promise 對象,能夠使用 then 方法添加回調函數,async 函數內部 return 語句返回的值,會成爲 then 方法回調函數的參數。當函數執行的時候,一旦遇到await就會先返回,等到異步操做完成,再接着執行函數體內後面的語句。
await只能用在異步函數中,使用await必需要先使用async,命令後面返回的是Promise對象,運行結果多是rejected,因此最好把await命令放在try...catch代碼塊中。
Promise的概念
我理解的Promise就是一套爲處理異步狀況的方法。先建立一個promise對象來註冊一個委託,其中包括委託成功及失敗後的處理函數。而後基於這種表述方式,來將promise應用到各類異步處理的狀況中。
promise寫法案例
var promise = getAsyncPromise('fileA.txt');
promise.then( function(result){
// 成功時的處理辦法
}).catch( function(error){
// 失敗時的處理辦法
})
// 返回一個promise對象
promise三個狀態
pending(進行中)、fulfilled(已成功)和rejected(已失敗)
Promise 實際就是一個對象, 從它能夠得到異步操做的消息,Promise 對象有三種狀態,pending(進行中)、fulfilled(已成功)和rejected(已失敗)。Promise 的狀態一旦改變以後,就不會在發生任何變化,將回調函數變成了鏈式調用。
Promise的設計思想是,全部異步任務都返回一個Promise實例。Promise實例有一個then方法,用來指定下一步的回調函數。
總的來講,傳統的回調函數寫法使得代碼混成一團,變得橫向發展而不是向下發展。Promise就是解決這個問題,使得異步流程能夠寫成同步流程。
Promise構造函數
JavaScript 提供原生的Promise構造函數,用來生成 Promise 實例。
var promise = new Promise(function (resolve, reject) {
// ...
if (/* 異步操做成功 */){
resolve(value);
} else { /* 異步操做失敗 */
reject(new Error());
}
});
上面代碼中,Promise構造函數接受一個函數做爲參數,該函數的兩個參數分別是resolve和reject。它們是兩個函數,由JavaScript引擎提供,不用本身實現。
resolve函數的做用是,將Promise實例的狀態從"未完成"變爲"成功"(即從pending變爲fulfilled),在異步操做成功時調用,並將異步操做的結果,做爲參數傳遞出去。reject函數的做用是,將Promise實例的狀態從"未完成"變爲"失敗"(即從pending變爲rejected),在異步失敗時調用,並將異步操做報出的錯誤,做爲參數傳遞出去。
Promise的優缺點
Promise 的優勢在於,讓回調函數變成了規範的鏈式寫法,程序流程能夠看得很清楚。它有一整套接口,能夠實現許多強大的功能,好比同時執行多個異步操做,等到它們的狀態都改變之後,再執行一個回調函數;再好比,爲多個回調函數中拋出的錯誤,統一指定處理方法等等。
並且,Promise 還有一個傳統寫法沒有的好處:它的狀態一旦改變,不管什麼時候查詢,都能獲得這個狀態。這意味着,不管什麼時候爲 Promise 實例添加回調函數,該函數都能正確執行。因此,你不用擔憂是否錯過了某個事件或信號。若是是傳統寫法,經過監聽事件來執行回調函數,一旦錯過了事件,再添加回調函數是不會執行的。
Promise 的缺點是,編寫的難度比傳統寫法高,並且閱讀代碼也不是一眼能夠看懂。你只會看到一堆then,必須本身在then的回調函數裏面理清邏輯。
Promise的優勢
promise優勢主要解決回調地獄問題,使得本來的多層級的嵌套代碼,變成了鏈式調用,讓代碼更清晰,減小嵌套數。
Promise的缺點
首先,沒法取消Promise,一旦新建它就會當即執行,沒法中途取消。其次,若是不設置回調函數,Promise內部拋出的錯誤,不會反應到外部。當處於Pending狀態時,沒法得知目前進展到哪個階段(剛剛開始仍是即將完成)。
Promise的all方法
all方法是promise是類上自帶的方法,併發讀取,失敗一個都失敗了,時間只是一個讀取的時間
第一個參數 傳遞的是數組,數組裝的是一個個promise對象
調用後會再次返回一個promise實例
最好的寫法
Promise.all([read('./name.txt'),read('./age.txt')]).then(([name,age])=>{
//data就是promise執行成功的結果類型是數組
console.log({name,age});
}).catch((err)=>{
console.log(err)
})
Promise的race方法
Promise.race ([promise1,promise2..])
當參數裏的任意一個promise成功或失敗後,該函數就會返回,並使用這個promise對象的值進行resolve或reject
let promise1 = ajax({method:'GET',url:'/x.json'});
let promise2 = ajax({method:'GET',url:'/y.json'});
Promise.all([promise1,promise2]).then(function(){
console.log('兩個promise都執行完成了')
});
Promise.race([promise1,promise2]).then(function(){
console.log('有一個promise先執行完成了')
})
參考:簡單理解Promise
https://www.jianshu.com/p/c8f...
存儲
本地存儲(Local Storage )和cookies(儲存在用戶本地終端上的數據)之間的區別是什麼?
Cookies:服務器和客戶端均可以訪問;大小隻有4KB左右;有有效期,過時後將會刪除;
本地存儲:只有本地瀏覽器端可訪問數據,服務器不能訪問本地存儲,直到故意經過POST或者GET的通道發送到服務器;每一個域5MB;沒有過時數據,它將保留直到用戶從瀏覽器清除或者使用Javascript代碼移除。
cookie 4kb 隨http請求發送到服務端 後端能夠幫助前端設置cookie
session 放在服務端 通常存放用戶比較重要的信息
(token 令牌 token ==> cookie /localstorage) vuex
localStorage 本地存儲(h5的新特性 draggable canvas svg)
5M 純粹在本地客戶端 多個標籤頁共享數據
sessionStorage 會話級別的存儲
往本地頁面中存值的方法(localStorage.setItem(key,value))
講一下cookie、sessionstorage、localstorage
相同點:都存儲在客戶端
不一樣點:
1.存儲大小
- cookie數據大小不能超過4k。
- sessionStorage和localStorage 雖然也有存儲大小的限制,但比cookie大得多,能夠達到5M或更大。
2.有效時間
- localStorage 存儲持久數據,瀏覽器關閉後數據不丟失除非主動刪除數據;
- sessionStorage 數據在當前瀏覽器窗口關閉後自動刪除。
- cookie 設置的cookie過時時間以前一直有效,即便窗口或瀏覽器關閉
3.數據與服務器之間的交互方式
- cookie的數據會自動的傳遞到服務器,服務器端也能夠寫cookie到客戶端
- sessionStorage和localStorage不會自動把數據發給服務器,僅在本地保存。
定義一個對象,裏面包含用戶名、電話,而後將其存入localStorage的代碼
var json = {username:"張三",phone:17650246248}
for(var key in json){
localStorage.setItem(key,json[key]);
}
cookie和session的區別
- 保持狀態:cookie保存在瀏覽器端,session保存在服務器端
- 使用方式:若是不在瀏覽器中設置過時時間,cookie被保存在內存中,生命週期隨瀏覽器的關閉而結束,這種cookie簡稱會話cookie。若是在瀏覽器中設置了cookie的過時時間,cookie被保存在硬盤中,關閉瀏覽器後,cookie數據仍然存在,直到過時時間結束才消失。
- 存儲內容:cookie只能保存字符串類型,以文本的方式;session經過相似與Hashtable的數據結構來保存,能支持任何類型的對象(session中可含有多個對象)
- 存儲的大小:cookie:單個cookie保存的數據不能超過4kb;session大小沒有限制。
- 安全性:cookie:針對cookie所存在的攻擊:Cookie欺騙,Cookie截獲;session的安全性大於cookie。
- 應用場景:
cookie:(1)判斷用戶是否登錄過網站,以便下次登陸時可以實現自動登陸(或者記住密碼)。若是咱們刪除cookie,則每次登陸必須重新填寫登陸的相關信息。
(2)保存上次登陸的時間等信息。
(3)保存上次查看的頁面
(4)瀏覽計數
session:Session用於保存每一個用戶的專用信息,變量的值保存在服務器端,經過SessionID來區分不一樣的客戶。
(1)網上商城中的購物車
(2)保存用戶登陸信息
(3)將某些數據放入session中,供同一用戶的不一樣頁面使用
(4)防止用戶非法登陸
- 缺點:
cookie:
(1)大小受限
(2)用戶能夠操做(禁用)cookie,使功能受限
(3)安全性較低
(4)有些狀態不可能保存在客戶端。
(5)每次訪問都要傳送cookie給服務器,浪費帶寬。
(6)cookie數據有路徑(path)的概念,能夠限制cookie只屬於某個路徑。
session:
(1)Session保存的東西越多,就越佔用服務器內存,對於用戶在線人數較多的網站,服務器的內存壓力會比較大。
(2)依賴於cookie(sessionID保存在cookie),若是禁用cookie,則要使用URL重寫,不安全
(3)建立Session變量有很大的隨意性,可隨時調用,不須要開發者作精確地處理,因此,過分使用session變量將會致使代碼不可讀並且很差維護。
WebStorage
WebStorage的目的是克服由cookie所帶來的一些限制,當數據須要被嚴格控制在客戶端時,不須要持續的將數據發回服務器。
WebStorage兩個主要目標:
(1)提供一種在cookie以外存儲會話數據的路徑。
(2)提供一種存儲大量能夠跨會話存在的數據的機制。
Localstroage與SessionStorage存儲的區別
HTML5的WebStorage提供了兩種API:localStorage(本地存儲)和sessionStorage(會話存儲)。
- 生命週期:localStorage:localStorage的生命週期是永久的,關閉頁面或瀏覽器以後localStorage中的數據也不會消失。
localStorage除非主動刪除數據,不然數據永遠不會消失。
sessionStorage的生命週期是在僅在當前會話下有效。sessionStorage引入了一個「瀏覽器窗口」的概念,sessionStorage是在同源的窗口中始終存在的數據。只要這個瀏覽器窗口沒有關閉,即便刷新頁面或者進入同源另外一個頁面,數據依然存在。可是sessionStorage在關閉了瀏覽器窗口後就會被銷燬。同時獨立的打開同一個窗口同一個頁面,sessionStorage也是不同的。
- 存儲大小:localStorage和sessionStorage的存儲數據大小通常都是:5MB
- 存儲位置:localStorage和sessionStorage都保存在客戶端,不與服務器進行交互通訊。
- 存儲內容類型:localStorage和sessionStorage只能存儲字符串類型,對於複雜的對象能夠使用ECMAScript提供的JSON對象的stringify和parse來處理
- 獲取方式:localStorage:window.localStorage;;sessionStorage:window.sessionStorage;。
- 應用場景:localStoragese:經常使用於長期登陸(+判斷用戶是否已登陸),適合長期保存在本地的數據。sessionStorage:敏感帳號一次性登陸;
WebStorage的優勢
- 存儲空間更大:cookie爲4KB,而WebStorage是5MB;
- 節省網絡流量:WebStorage不會傳送到服務器,存儲在本地的數據能夠直接獲取,也不會像cookie同樣美詞請求都會傳送到服務器,因此減小了客戶端和服務器端的交互,節省了網絡流量;
- 對於那種只須要在用戶瀏覽一組頁面期間保存而關閉瀏覽器後就能夠丟棄的數據,sessionStorage會很是方便;
- 快速顯示:有的數據存儲在WebStorage上,再加上瀏覽器自己的緩存。獲取數據時能夠從本地獲取會比從服務器端獲取快得多,因此速度更快;
- 安全性:WebStorage不會隨着HTTP header發送到服務器端,因此安全性相對於cookie來講比較高一些,不會擔憂截獲,可是仍然存在僞造問題;
- WebStorage提供了一些方法,數據操做比cookie方便;
WebStorage的方法
setItem (key, value) —— 保存數據,以鍵值對的方式儲存信息。
getItem (key) —— 獲取數據,將鍵值傳入,便可獲取到對應的value值。
removeItem (key) —— 刪除單個數據,根據鍵值移除對應的信息。
clear () —— 刪除全部的數據
key (index) —— 獲取某個索引的key
Token
token是"令牌"的意思,服務端生成一串字符串,做爲客戶端請求的一段標識。用戶登陸的時候生成一個token,並將token返回客戶端,客戶端將收到的token放在cookie裏,下次用戶向服務端發送請求的時候,服務端只須要對比token。
做用:進行身份驗證,避免表單重複提交。
在ajax請求後臺時token添加到哪裏
在ajax請求的標頭中加Token
1 function GetDateForServiceCustomer(userId) {
2 $.ajax({
3 url: 'http://*******/api/orders',
4 data: {
5 currUserId: userId,
6 type: 1
7 },
8 beforeSend: function(request) {
9 request.setRequestHeader("Authorization", token);
10 },
11 dataType: 'JSON',
12 async: false,//請求是否異步,默認爲異步
13 type: 'GET',
14 success: function (list) {
15 },
16 error: function () {
17 }
18 });
19 }

參考:在ajax請求後臺時在請求標頭RequestHeader加token
https://www.cnblogs.com/zfdcp...
協議
HTTPS與HTTP的一些區別
- HTTPS協議須要到CA申請證書,通常免費證書不多,須要交費。
- HTTP協議運行在TCP之上,全部傳輸的內容都是明文,HTTPS運行在SSL/TLS之上,SSL/TLS運行在TCP之上,全部傳輸的內容都通過加密的。
- HTTP和HTTPS使用的是徹底不一樣的鏈接方式,用的端口也不同,前者是80,後者是443。
- HTTPS能夠有效的防止運營商劫持,解決了防劫持的一個大問題。
HTTP1.0和HTTP2.0有什麼區別
新的二進制格式(Binary Format),HTTP1.x的解析是基於文本。基於文本協議的格式解析存在自然缺陷,文本的表現形式有多樣性,要作到健壯性考慮的場景必然不少,二進制則不一樣,只認0和1的組合。基於這種考慮HTTP2.0的協議解析決定採用二進制格式,實現方便且健壯。
多路複用(MultiPlexing),即鏈接共享,即每個request都是是用做鏈接共享機制的。一個request對應一個id,這樣一個鏈接上能夠有多個request,每一個鏈接的request能夠隨機的混雜在一塊兒,接收方能夠根據request的 id將request再歸屬到各自不一樣的服務端請求裏面。
header壓縮,如上文中所言,對前面提到過HTTP1.x的header帶有大量信息,並且每次都要重複發送,HTTP2.0使用encoder來減小須要傳輸的header大小,通信雙方各自cache一份header fields表,既避免了重複header的傳輸,又減少了須要傳輸的大小。
服務端推送(server push),同SPDY同樣,HTTP2.0也具備server push功能。
參考:HTTP1.0、HTTP1.1 和 HTTP2.0 的區別
https://www.cnblogs.com/helua...
Websocket
WebSocket 是 HTML5 開始提供的一種在單個 TCP 鏈接上進行全雙工通信的協議。
WebSocket 使得客戶端和服務器之間的數據交換變得更加簡單,容許服務端主動向客戶端推送數據。在 WebSocket API 中,瀏覽器和服務器只須要完成一次握手,二者之間就直接能夠建立持久性的鏈接,並進行雙向數據傳輸。
在 WebSocket API 中,瀏覽器和服務器只須要作一個握手的動做,而後,瀏覽器和服務器之間就造成了一條快速通道。二者之間就直接能夠數據互相傳送。
如今,不少網站爲了實現推送技術,所用的技術都是 Ajax 輪詢。輪詢是在特定的的時間間隔(如每1秒),由瀏覽器對服務器發出HTTP請求,而後由服務器返回最新的數據給客戶端的瀏覽器。這種傳統的模式帶來很明顯的缺點,即瀏覽器須要不斷的向服務器發出請求,然而HTTP請求可能包含較長的頭部,其中真正有效的數據可能只是很小的一部分,顯然這樣會浪費不少的帶寬等資源。
HTML5 定義的 WebSocket 協議,能更好的節省服務器資源和帶寬,而且可以更實時地進行通信。
WebSocket特色
(1)創建在 TCP 協議之上,服務器端的實現比較容易。
(2)與 HTTP 協議有着良好的兼容性。默認端口也是80和443,而且握手階段採用 HTTP 協議,所以握手時不容易屏蔽,能經過各類 HTTP 代理服務器。
(3)數據格式比較輕量,性能開銷小,通訊高效。
(4)能夠發送文本,也能夠發送二進制數據。
(5)沒有同源限制,客戶端能夠與任意服務器通訊。
(6)協議標識符是ws(若是加密,則爲wss),服務器網址就是 URL。
scoket套接字編程
網絡上的兩個程序經過一個雙向的通訊鏈接實現數據的交換,這個鏈接的一端稱爲一個socket。
若是將http比做轎車的話,那麼socket就至關於發動機。
websocket跟 socket 的區別
軟件通訊有七層結構,下三層結構偏向與數據通訊,上三層更偏向於數據處理,中間的傳輸層則是鏈接上三層與下三層之間的橋樑,每一層都作不一樣的工做,上層協議依賴與下層協議。基於這個通訊結構的概念。
Socket 其實並非一個協議,是應用層與 TCP/IP 協議族通訊的中間軟件抽象層,它是一組接口。當兩臺主機通訊時,讓 Socket 去組織數據,以符合指定的協議。TCP 鏈接則更依靠於底層的 IP 協議,IP 協議的鏈接則依賴於鏈路層等更低層次。
WebSocket 則是一個典型的應用層協議。
總的來講:Socket 是傳輸控制層協議,WebSocket 是應用層協議。
webScoket如何兼容低瀏覽器
- Adobe Flash Socket
- ActiveX HTMLFile (IE)
- 基於 multipart 編碼發送 XHR
- 基於長輪詢的 XHR
參考:WebSocket解釋及如何兼容低版本瀏覽器
https://www.cnblogs.com/pengc...
模塊化開發
模塊、函數、組件分別是什麼?
模塊:在webpack中,經過import引入的文件叫作模塊。(js/css/png)
函數:是一些功能的合集。
組件:指的是頁面的某一部分。
類是什麼?類被編譯成什麼?
類:
class Banner extends React.Component{ //es6寫法
}
ES5:經過模塊定義類 ES6中定義的類也被編譯成這樣
function Banner(){ //構造函數
}
組件化與模塊化的區別,或者說怎麼實現組件化開發,模塊化開發
組件化:針對的是頁面中的整個完整的功能模塊,劃分紅瀏覽器能夠識別的每一個模塊,例如頭部Header、底部Footer、Banner。優勢:代碼複用、便於維護。
模塊化:就是系統功能分離或獨立的功能部分的方法,通常指的是單一的某個東西,例如:js、css
模塊化開發的規範
(1)commonJS:自上而下同步進行 會阻塞 用在服務端
使用模塊:const 變量名 = require("包名字")
聲明模塊:module.exports = {
對外的名字:函數
}
(2)AMD:異步加載文件 不會阻塞 用在瀏覽器端
define方法用於定義模塊,RequireJS要求每一個模塊放在一個單獨的文件裏。
使用模塊:require("模塊名",function(模塊對象)){
return 模塊對象.函數();//回調函數
}
(3)CMD規範 中國人發明的,ECMA6來了就廢棄了。
amd和cmd的區別
amd是require.js上的一個規範,cmd是sea.js的一個規範。
其實CMD與AMD規範並沒什麼本質的區別,區別在於他們對依賴模塊的執行時機處理不一樣。雖然二者都是異步加載模塊,可是AMD依賴前置,js能夠方便知道依賴模塊是誰,要依賴什麼js那就先加載進來,至於你要依賴這些js來幹嘛得先等着,等我加載完了資源再商量;而CMD就近依賴,須要使用這個依賴模塊時,我再加載進來用。
這就比如什麼呢?就好像我今晚要看5集三國演義。AMD是先打開五個窗口,分別是1~5集,都緩衝着先,反正等下每集我都要看的;CMD則是先打開第一集的窗口,等到我第一集看完了,想看第二集了,就再跳轉到第二集。
如今使用頻率最高的,也是你們公認的好的模塊化規範,是CommonJS。 後端(node.js)
require.js
實現了AMD規範的JavaScript工具庫
RequireJS的基本思想是,經過define方法,將代碼定義爲模塊;經過require方法,實現代碼的模塊加載。
require.js的誕生,就是爲了解決這兩個問題:
(1)實現了js文件的異步加載,避免網頁失去響應
(2)管理模塊之間的依賴性,便於代碼的編寫和維護
common.js
CommonJS就很簡單了,一個js文件要輸出去,只需使用module.export={xxx:你要輸出的內容},而在另一個js中,你要引用什麼,就經過var xxxx=require("xxxx")引用進來就好了,這玩意並非異步加載模塊,而是同步一次性加載出來。
common.js與require.js與sea.js的區別:


配置模塊化開發
<1>在頭部引入
<script scr = "js/require.js" defer async = "true" data-main = "js/main"></script>
main.js管理當前頁面的js文件,每個頁面都有本身的不一樣名字的main.js文件.
路徑以dist文件爲主
在外部修改文件,不容許修改dist中的文件,gulp會自動同步修改.
<2>在main中經過require.config配置當前頁面須要的模塊路徑
配置模塊的依賴路徑:
shim:{
//因爲jquery-cookie是基於jquery庫封裝的,因此要先引入jquery再引入jquery-cookie
"jquery-cookie":['jquery'],
//聲明一下,不是AMD規範的模塊
"parabola":{
exports:"_"
}
}
<3>編寫CSS樣式/JS代碼
編寫JS代碼:
- 先封裝成函數
- 再經過對象的形式對外暴露
define(["jquery"],function($){
function slide(){
$(function(){
function show(){
console.log("hello world");
}
return{
slide:slide,
show:show
}
})
<4>在main.js中加載
//配置當前整個項目全部模塊的路徑
require.config({
paths:{
"slide":"slide"
},
require(["slide"],function(slide){
slide.show();
slide.slide();
})
前端構建集成工具(打包)
什麼是前端集成解決方案?
FIS(Front-end Integrated Solution)是專爲解決前端開發中自動化工具、性能優化、模塊化框架、開發規範、代碼部署、開發流程等問題的工具框架。
前端集成解決方案解決了前端哪些問題?
- 開發團隊代碼風格不統一,如何強制開發規範。
- 前期開發的組件庫如何維護和使用
- 如何模塊化前端項目
- 服務器部署前必須壓縮,檢查流程如何簡化,流程如何完善。
你使用過哪些前端構建集成?你用過什麼打包工具?
- Gulp
gulp是工具鏈、構建工具,能夠配合各類插件作js壓縮,css壓縮,less編譯,替代手工實現自動化工做
(1)構建工具
(2)自動化
(3)提升效率用
- webpack
webpack是文件打包工具,能夠把項目的各類js文、css文件等打包合併成一個或多個文件,主要用於模塊化方案,預編譯模塊的方案
(1)打包工具
(2)模塊化識別
(3)編譯模塊代碼方案用
webpack打包
一款模塊化打包工具,webpack是基於配置的,經過配置一些選項來讓webpack執行打包任務
webpack在打包的時候,依靠依賴關係圖,在打包的時候要告知webpack兩個概念:入口和出口
plugins:在webpack編譯用的是loader,可是有一些loader沒法完成的任務,交由插件(plugin)來完成,插件的時候須要在配置項中配置plugins選項,值是數組,能夠放入多個插件使用,而通常的插件都是一個構造器,咱們,咱們只需在plugins數組中放入該插件的實例便可。
loader:在webpack中專門有一些東西用來編譯文件、處理文件,這些東西就叫loader。
webpack都用過哪些loader?
url-loader 能夠將css中引入的圖片(背景圖)、js中生成的img圖片處理一下,生成到打包目錄裏
url-loader/file-loader 將圖片轉成base64
html-withimg-loader 能夠將html中img標籤引入的img圖片打包到打包目錄
css-loader 能夠將引入到js中的css代碼給抽離出來
style-loader 能夠將抽離出來的css代碼放入到style標籤中
sass-loader/less-loader sass/less預編譯
postcss-loader 兼容前綴
babel-loader 將es6轉成es5轉成大部分瀏覽器能夠識別的語法
vue-loader 把vue組件轉換成js模塊
爲什麼要轉譯此模塊? 能夠動態的渲染一些數據,對三個標籤作了優化 <template> 寫虛擬dom <script> 寫es6語法 <style> 默承認以用scss語法,提供了做用域 而且開發階段提供了熱加載功能
注意:webpack中loader的使用是從後往前的
webpack都用過哪些plugins?
- html-webpack-plugin:這個插件能夠選擇是否依據模板來生成一個打包好的html文件,在裏面能夠配置、title、template、filename、minify等選項。
- optimize-css-assets-webpack-plugin:壓縮css插件
- extract-text-webpack-plugin:樣式合併
- webpack.optimize.UglifyJsPlugin:js合併
webpack入口屬性
- entry 入口文件
- output出口文件
Gulp打包
gulp:基於流的前端自動化構建工具,基於流的任務式工具.pipe()
gulp的特色:自動化 基於流 插件不少
Gulp 的特色:
* 自動化 - Gulp 爲你的工做流而服務,自動運行那些費事費力任務。
* 平臺透明 - Gulp 被集成到各類 IDE 中,而且除了 NodeJS 以外,其餘如 PHP、.NET、Java 平臺均可以使用 Gulp。
* 強大生態系統 - 你能夠使用 npm 上 2000+ 的插件來構造你的工做流。
* 簡單 - Gulp 只提供幾個 API,這能夠很快地學習和上手。
Gulp 原生API
在進階Gulp時,必須熟悉API中的四個方法的使用,在這裏簡單歸納一下,更多信息查閱API。
- gulp.src(globs[, options])
返回符合匹配規則的虛擬文件對象流(Vinyl files)。
- gulp.dest(path[, options])
用來指定要生成的文件的目錄,目錄路徑爲path。
- gulp.task(name[, deps], fn)
定義一個流任務,任務名爲name。
- gulp.watch(glob[, opts], tasks)
監視文件的變化,執行操做。
Gulp插件
gulp-scss 編譯css文件(注意:windows下使用 gulp-sass)
gulp-connect 來啓動一個服務器
gulp-concat 合併js文件
gulp-uglify js文件壓縮
gulp-rename重命名
gulp-minify-css 壓縮css
gulp-babel 將es6代碼轉成es5
webpack和gulp有什麼區別
- gulp是基於流的構建工具:all in one的打包模式,輸出一個js文件和一個css文件,優勢是減小http請求,萬金油方案。gulp強調的是前端開發的工做流程,咱們能夠經過配置一系列的task,定義task處理的事務(例如文件壓縮合並、雪碧圖、啓動server、版本控制等),而後定義執行順序,來讓gulp執行這些task,從而構建項目的整個前端開發流程。
PS:簡單說就一個Task Runner。
- webpack是模塊化管理工具:all in js,使用webpack能夠對模塊進行壓縮、預處理、打包、按需加載等。webpack是一個前端模塊化方案,更側重模塊打包,咱們能夠把開發中的全部資源(圖片、js文件、css文件等)都當作模塊,經過loader(加載器)和plugins(插件)對資源進行處理,打包成符合生產環境部署的前端資源。
PS:webpack is a module bundle
雖然都是前端自動化構建工具,但看他們的定位就知道不是對等的。 gulp嚴格上講,模塊化不是他強調的東西,他旨在規範前端開發流程。 webpack更是明顯強調模塊化開發,而那些文件壓縮合並、預處理等功能,不過是他附帶的功能。
webpack和gulp有什麼關係
Gulp和webpack在定義和用法上來講都不衝突,能夠結合來使用。
gulp應該與grunt比較,而webpack應該與browserify(網上太多資料就這麼說,這麼說是沒有錯,不過單單這樣一句話並不能讓人清晰明瞭)。
gulp與webpack上是互補的,仍是可替換的,取決於你項目的需求。若是隻是個vue或react的單頁應用,webpack也就夠用;若是webpack某些功能使用起來麻煩甚至沒有(雪碧圖就沒有),那就能夠結合gulp一塊兒用。
Gulp應該和Grunt比較
Gulp / Grunt 是一種工具,可以優化前端工做流程。好比自動刷新頁面、combo、壓縮css、js、編譯less等等。簡單來講,就是使用Gulp/Grunt,而後配置你須要的插件,就能夠把之前須要手工作的事情讓它幫你作了。
devDependencies和dependencies的區別
區別是:
dependencies 程序正常運行須要的包。
devDependencies 是開發須要的包,好比 一些單元測試的包之類的。
一個node package有兩種依賴,一種是dependencies一種是devDependencies,
其中前者依賴的項該是正常運行該包時所須要的依賴項,
然後者則是開發的時候須要的依賴項,像一些進行單元測試之類的包。
若是將包下載下來在包的根目錄裏運行npm install默認會安裝兩種依賴,若是隻是單純的使用這個包而不須要進行一些改動測試之類的,能夠使用npm install --production,只安裝dependencies而不安裝devDependencies。
若是是經過如下命令進行安裝npm install packagename那麼只會安裝。dependencies,若是想要安裝devDependencies,須要輸入。npm install packagename --dev。
參考文章:
gulp與webpack的區別
https://www.cnblogs.com/loves...
前端集成解決方案(webpack、gulp)
https://blog.csdn.net/qishuix...
CSS預處理器
什麼是CSS預處理器?
CSS 預處理器定義了一種新的語言,其基本思想是,用一種專門的編程語言,爲 CSS 增長了一些編程的特性,將 CSS 做爲目標生成文件,而後開發者就只要使用這種語言進行編碼工做。
通俗的說,「CSS 預處理器用一種專門的編程語言,進行 Web 頁面樣式設計,而後再編譯成正常的 CSS 文件,以供項目使用。CSS 預處理器爲 CSS 增長一些編程的特性,無需考慮瀏覽器的兼容性問題」,例如你能夠在 CSS 中使用變量、簡單的邏輯程序、函數(如右側代碼編輯器中就使用了變量$color)等等在編程語言中的一些基本特性,可讓你的 CSS 更加簡潔、適應性更強、可讀性更佳,更易於代碼的維護等諸多好處。
都有哪些經常使用的CSS預處理器?
SCSS、LESS、Stylus
Sass預編譯的特性
- 它使用本身語法並編譯爲可讀的CSS
- 能夠在更少的時間內輕鬆的編寫CSS代碼
- 是一個開源的預處理器,被解析爲CSS
- 能夠兼容全部的CSS版本
爲何要用sass?
- 它是預處理語言,它爲CSS提供縮進語法(它本身的語法)
- 它容許更有效的編寫代碼和易於維護
- 它使用可重複使用的方法,邏輯語句和一些內置的函數
- 它提供了比平面CSS好的結構格式和文檔樣式
Sass和Scss有什麼區別?
Sass 和 SCSS 實際上是同一種東西,咱們平時都稱之爲 Sass,二者之間不一樣之處有如下兩點:
文件擴展名不一樣,Sass 是以「.sass後綴爲擴展名,而 SCSS 是以「.scss」後綴爲擴展名;
語法書寫方式不一樣,Sass 是以嚴格的縮進式語法規則來書寫,不帶大括號({})和分號(;),而 SCSS 的語法書寫和咱們的 CSS 語法書寫方式很是相似。
Sass語法
(1)聲明變量
普通變量:$美圓符號+變量名稱:變量值,定義以後能夠在全局範圍內使用
默認變量:sass 的默認變量僅須要在值後面加上*!default 便可。sass 的默認變量通常是用來設置默認值,而後根據需求來覆蓋的,覆蓋的方式也很簡單,只須要從新聲明下變量便可
特殊變量:通常狀況下,咱們定義的變量都是屬性值,能夠直接使用,可是若是變量做爲屬性或者其餘的特殊狀況下,必須使用#{$variable}的形式進行調用。
#{$variable} 就是取值的一種特殊形式,符合特殊用法。
全局變量:全局變量——在變量的後面加上[!global]便可聲明全局變量。
(2)sass嵌套-選擇器嵌套
SASS 中的嵌套主要說的是選擇器嵌套和屬性嵌套兩種方式,正常項目中一般使用的都是選擇器嵌套方案
【注】在嵌套的過程當中,若是須要用到父元素,在 SASS 中經過&符號引用父屬性
(3)sass嵌套-屬性嵌套
嵌套屬性——不經常使用
所謂屬性嵌套,是指某些屬性擁有一樣的單詞開頭,如:border-left,border-color
都是以 border 開頭的,因此就出現了屬性嵌套語法
(4)sass混合-Mixin
sass 中能夠經過@mixin 聲明混合,能夠傳遞參數,參數名稱以$開始,多個參數之間使用
逗號分隔,@mixin 的混合代碼塊由@include 來調用
混合能使咱們重用一整段sass代碼,同時也能夠給其傳遞參數。
定義一個混合,需用到@mixin關鍵字,後面跟本身定義的名字,若須要傳參,則在名字以後加一對單括號(),同時在裏面定義參數變量。經過調用@include關鍵字,來調用這段混合。
(5)sass繼承拓展-@extend
在 SASS 中,經過繼承/擴展來減小重複代碼,可讓一個選擇器去繼承另外一個選擇中全部
的樣式。
繼承某個樣式的同時,也會繼承樣式的擴展。
(6)Partitials和@import
Partials 是用來定義公共樣式或者組件的樣式的,專門用於被其餘的 scss 文件 import進行使用的,在 SCSS 文件中引入指令@import 在引入 Partials 文件時,不須要添加下劃線。詳細參考案例代碼。
(7)sass註釋
SASS 中提供了三種註釋
多行註釋 在編譯輸出的 css 文件中會保留,壓縮輸出格式中不會保留 --style compressed
/*
* 多行註釋
*/
單行註釋 在輸出 css 文件時不保留
// 單行註釋
強制註釋 在多行註釋的開頭,添加感嘆號!表示強制保留
/*!
* 強制註釋
*/
混合樣式,怎麼調用,調用需不須要攜帶參數
無參數混合



版本控制工具
SVN優缺點(集中式版本管理控制工具)
優勢:
一、 管理方便,邏輯明確,符合通常人思惟習慣。
二、 易於管理,集中式服務器更能保證安全性。
三、 代碼一致性很是高。
四、 適合開發人數很少的項目開發。
缺點:
一、 服務器壓力太大,數據庫容量暴增。
二、 若是不能鏈接到服務器上,基本上不能夠工做,看上面第二步,若是服務器不能鏈接上,就不能提交,還原,對比等等。
三、 不適合開源開發(開發人數很是很是多,可是Google app engine就是用svn的)。可是通常集中式管理的有很是明確的權限管理機制(例如分支訪問限制),能夠實現分層管理,從而很好的解決開發人數衆多的問題。
Git優缺點(分佈式版本管理控制工具)
優勢:
一、適合分佈式開發,強調個體。
二、公共服務器壓力和數據量都不會太大。
三、速度快、靈活。
四、任意兩個開發者之間能夠很容易的解決衝突。
五、能夠離線工做。
缺點:
一、學習週期相對而言比較長。
二、不符合常規思惟。
三、代碼保密性差,一旦開發者把整個庫克隆下來就能夠徹底公開全部代碼和版本信息。
GIT經常使用命令
git add * /文件名 將想要快照的內容寫入緩存區
git commit -m "當前提交的日誌"
git push -u origin master 提交代碼
git status 查看當前工做區提交狀態
git diff 比對 暫存區和工做區版本的區別
git checkout 切換分支命令
git reset --hard 版本號 恢復到指定的版本
GIT解決衝突
Git在push時若是版本比服務器上的舊,會提示先進行pull。問題是pull時若是服務器上的版本與你本地的版本在源文件修改上有衝突,那麼在解決衝突前push都會失敗。用git status能夠查看衝突文件。
接下來用git diff指令查看具體哪裏起衝突
這裏還有一些其餘指令,在衝突規模比較大的時候能夠很方便的確認哪裏不對。
git diff --ours:看本體分支對源文件的改動
git diff --theirs:看服務器分支對源文件的改動
git diff --base:看雙方對源文件的改動,base和不加base的區別就是base選項會現實雙方改動中即便不衝突的部分,默認diff則只會顯示衝突部分。
參考:
Git 衝突的解決方法
https://www.jianshu.com/p/938...
git衝突解決的方法
https://www.cnblogs.com/nickn...
GIT和SVN的區別
最核心的區別Git是分佈式的,而Svn不是分佈的
Git把內容按元數據方式存儲,而SVN是按文件
Git的內容的完整性要優於SVN: GIT的內容存儲使用的是SHA-1哈希算法。這能確保代碼內容的完整性,確保在遇到磁盤故障和網絡問題時下降對版本庫的破壞。
SVN的特色是簡單,只是須要一個放代碼的地方時用是OK的。
Git的特色版本控制能夠不依賴網絡作任何事情,對分支和合並有更好的支持(固然這是開發者最關心的地方),不過想各位能更好使用它,須要花點時間嘗試下
SVN和Git對比結果
- git是分佈式的scm,svn是集中式的。(最核心)
- git是每一個歷史版本都存儲完整的文件,便於恢復,svn是存儲差別文件,歷史版本不可恢復。(核心)
- git可離線完成大部分操做,svn則不能。
- git有着更優雅的分支和合並實現。
- git有着更強的撤銷修改和修改歷史版本的能力
- git速度更快,效率更高。
基於以上區別,git有了很明顯的優點,特別在於它具備的本地倉庫。
JQuery
JQuery中獲取網頁元素的方法
//$的數據類型是一個函數
//alert(typeof $); //function
//$("#div1").css("background-color","red"); //id是div1
//$(".box").css("background-color","blue"); //classname是box
//$("ul .box").css("background-color","blue");//ul下的classname爲box
//$("div").css("background-color","green");//div標籤
//$("[name=hello]").css("background-color","orange");//name爲hello
//$("div[id=div1]").css("background-color","orange");
JQuery中的工具方法
• type() 輸出當前常量/變量的數據類型
• trim() 刪除字符串的首尾空格
• inArray() 查找某一個元素,在數組中的下標
• proxy() 功能相似bind,預設this
• noConflict() 給$起一個別名
• parseJSON() 功能相似JSON.parse()
• $.makeArray() 將僞數組轉成數組。
JQuery插件方法
$.extend() 拓展工具方法
$.fn.extend() 拓展JQ的方法
設計思想:高內聚低耦合
談一下Jquery中的bind、live、delegate、on的區別?
on()方法-1.9版本整合了以前的三種方式的新事件綁定機制
.on( events [, selector ] [, data ], handler(eventObject) )
- 使用.bind()方法是很浪費資源的,由於它要匹配選擇器中的每一項而且挨個設置相同的事件處理程序
- 建議中止使用.live()方法,由於它已經被棄用了,因爲他有不少的問題
- .delegate()方法「很划算」用來處理性能和響應動態添加元素的時候
- 新的.on()方法主要是能夠實現.bind() .live() 甚至 .delegate()的功能
- 建議使用.on()方法,若是你的項目使用了1.7+的jQuery的話
參考:jQuery方法區別:click() bind() live() delegate()區別
https://www.cnblogs.com/zagel...
關於jquery的事件委託-bind,live,delegate,on的區別
https://blog.csdn.net/qq_4216...
拖拽的三劍客
mousedown:記錄被拖拽物體和鼠標按下位置相對距離
mousemove:讓拖拽物體跟隨鼠標去走,保持按下相對距離
mouseup:結束拖拽
Window.onload與$(document).ready(function(){})的區別是什麼?
Window.onload:頁面中只會出現一次,頁面中全部元素都必須加載完畢纔會去執行 。 $(document).ready()是JQ中的,能夠執行屢次 而且能夠簡寫爲:
$(function(){}) ,不須要等頁面中全部元素加載,只須要dom掛載進來就能夠執行回調函數。
一、執行時間上的區別:window.onload必須等到頁面內(包括圖片的)全部元素加載到瀏覽器中後才能執行。而$(document).ready(function(){})是DOM結構加載完畢後就會執行。
二、編寫個數不一樣:window.onload不能同時寫多個,若是有多個window.onload,則只有最後一個會執行,它會把前面的都覆蓋掉。$(document).ready(function(){})則不一樣,它能夠編寫多個,而且每個都會執行。
三、簡寫方法:window.onload沒有簡寫的方法,$(document).ready(function(){})能夠簡寫爲$(function(){})。
另外:因爲在$(document).ready()方法內註冊的事件,只要DOM就緒就會被執行,所以可能此時元素的關聯文件未下載完,例如與圖片有關的HTML下載完畢,而且已經解析爲DOM樹了,但頗有可能圖片還未加載完畢,因此例如圖片的高度和寬度這樣的屬性此時不必定有效。
要解決這個問題,能夠使用JQuery中另外一個關於頁面加載的方法---load()方法。load()方法會在元素的onload事件中綁定一個處理函數。若是處理函數綁定在元素上,則會在元素的內容加載完畢後觸發。如:$(window).load(function(){})=====window.onload = function(){}
Jquery中如何將數組轉化爲json字符串,而後再轉化回來?
var arr = [{usernname:"張三",age:10}]
console.log($.parseJSON(JSON.stringify(arr)));
正則表達式
電話號碼
function checkPhone(){
var phone = document.getElementById('phone').value;
if(!(/^1(3|4|5|6|7|8|9)\d{9}$/.test(phone))){
alert("手機號碼有誤,請重填");
return false;
}
}
郵箱號碼
^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
Vue—漸進式 JavaScript 框架
Vue相關概念
Vue的誕生
注意下Vue的誕生時間,面試官若是問你是從何時開始接觸而且使用Vue的,你若是回答用了五、6年了那場面就十分尷尬了。
Vue漸進式框架的理解?
在聲明式渲染(視圖模板引擎)的基礎上,咱們能夠經過添加組件系統(components)、客戶端路由(vue-router)、大規模狀態管理(vuex)來構建一個完整的框架。更重要的是,這些功能相互獨立,你能夠在覈心功能的基礎上任意選用其餘的部件,不必定要所有整合在一塊兒。能夠看到,所說的「漸進式」,其實就是Vue的使用方式,同時也體現了Vue的設計的理念。
拓展:Vue2.0 中,「漸進式框架」和「自底向上增量開發的設計」這兩個概念是什麼?
https://www.zhihu.com/questio...
虛擬DOM
什麼是虛擬DOM?
咱們知道操做DOM的代價是昂貴的,因此vue2.0採用了虛擬DOM來代替對真實DOM的操做,最後經過某種機制來完成對真實DOM的更新,渲染視圖。
所謂的虛擬DOM,其實就是用JS來模擬DOM結構,把DOM的變化操做放在JS層來作,儘可能減小對DOM的操做 (我的認爲主要是由於操做JS比操做DOM快了不知道多少倍,JS運行效率高)。而後對比先後兩次的虛擬DOM的變化,只從新渲染變化了的部分,而沒有變化的部分則不會從新渲染。
必需要注意一點的是:JS模擬的DOM結構並無模擬全部DOM節點上的屬性、方法(由於DOM節點自己的屬性很是多,這也是DOM操做耗性能的一個點),而是隻模擬了一部分和數據操做相關的屬性和方法。
Virual DOM是用JS對象記錄一個dom節點的副本,當dom發生更改時候,先用虛擬dom進行diff,算出最小差別,而後再修改真實dom。 當用傳統的方式操做DOM的時候,瀏覽器會從構建DOM樹開始從頭至尾執行一遍流程,效率很低。而虛擬DOM是用javascript對象表示的,而操做javascript是很簡便高效的。虛擬DOM和真正的DOM有一層映射關係,不少須要操做DOM的地方都會去操做虛擬DOM,最後統一一次更新DOM,於是能夠提升性能。
虛擬DOM的缺點
- 代碼更多,體積更大
- 內存佔用增大
- 小量的單一的dom修改使用虛擬dom成本反而更高,不如直接修改真實dom快
VUE中虛擬dom操做流程
- 在內存中構建虛擬dom樹
- 將內存中虛擬dom樹渲染成真實dom結構
- 數據改變的時候,將以前的虛擬dom樹結合新的數據生成新的虛擬dom樹
- 將這次生成好的虛擬dom樹和上一次的虛擬dom樹進行一次比對(diff算法進行比對)
- 會將對比出來的差別進行從新渲染
參考:vue2.0的虛擬DOM渲染思路分析
https://www.jb51.net/article/...
v-for循環渲染爲何要設置key值?虛擬DOM與key值的關係?
(1)跟diff算法有關:若是在兩個元素之間插入新元素,若是沒有key的話,就須要把原位置的元素卸載了,把新元素插進來,而後依次卸載,會打亂後續元素的排列規則,若是有key值,只須要插入到對應位置便可,不會改變其餘元素的走向。
(2)爲了減免一些出錯問題:例如在數組中,原本第一個是選中的,這時候咱們再去添加新元素,若是沒有key的話,那麼新添加進來的元素就會被選中,加上key就是爲了不出現這樣的問題。
參考:Vue 虛擬DOM與key屬性
https://blog.csdn.net/weixin_...
虛擬DOM的Diff算法
虛擬DOM中,在DOM的狀態發生變化時,虛擬DOM會進行Diff運算,來更新只須要被替換的DOM,而不是所有重繪。
在Diff算法中,只平層的比較先後兩棵DOM樹的節點,沒有進行深度的遍歷。
computed計算屬性跟watch監聽的區別
參考:淺談VUE虛擬dom
https://blog.csdn.net/mrliber...
設計模式
VUE的設計模式MVVM
vue中採用了mvvm的設計模式,是從mvc/mvp演變過來的,mvvm主要解決了mvc反饋不及時的問題,或者實現了自動同步的功能。
也就是說model層改變的時候,咱們不須要手動取更改dom。而vm幫助咱們實現了這個效果,改變屬性後該屬性對應view會自動更新,view與model之間沒有必然的聯繫,靠vm將二者進行關聯。
MVC設計模式(單向通訊)
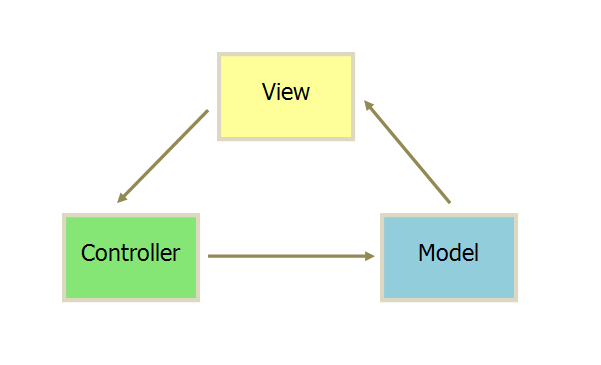
- 視圖(View):用戶界面。
- 控制器(Controller):業務邏輯
- 模型(Model):數據保存
- View 傳送指令到 Controller
- Controller 完成業務邏輯後,要求 Model 改變狀態
- Model 將新的數據發送到 View,用戶獲得反饋
MVP設計模式
MVP 模式將 Controller 更名爲 Presenter,同時改變了通訊方向。
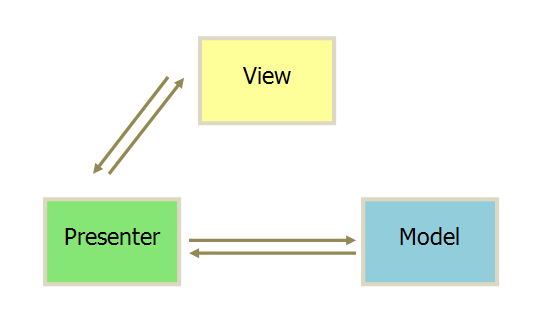
- 各部分之間的通訊,都是雙向的。
- View 與 Model 不發生聯繫,都經過 Presenter 傳遞。
- View 很是薄,不部署任何業務邏輯,稱爲"被動視圖"(Passive View),即沒有任何主動性,而 Presenter很是厚,全部邏輯都部署在那裏。
MVVM設計模式
MVVM 模式將 Presenter 更名爲 ViewModel,基本上與 MVP 模式徹底一致。
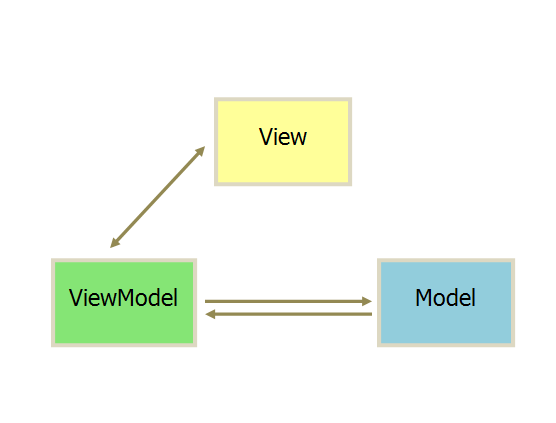
惟一的區別是,它採用雙向綁定(data-binding):View的變更,自動反映在 ViewModel,反之亦然。Angular 和 Ember 都採用這種模式。
參考:MVC,MVP 和 MVVM 的圖示
http://www.ruanyifeng.com/blo...
MVC、MVP、MVVM三種區別及適用場合
https://blog.csdn.net/victory...
MVVM解決了什麼問題
mvvm就是爲了解決mvc反饋不及時的問題
MVVM與MVC的區別
MVVM實現了View和Model的自動同步,也就是當Model屬性改變時,咱們不用再本身手動操做Dom元素,來改變View的顯示,而是改變屬性後該屬性對應View層顯示會自動改變(雙向數據綁定原理)。
爲何model層數據更改的時候,vm就能夠知道數據改變了呢?(vue的mvm框架的雙向綁定原理是什麼)
雙向數據綁定:
當視圖改變動新模型層
當模型層改變動新視圖層
在Vue中,使用了雙向綁定技術,就是View的變化能實時讓Model發生變化,而Model的變化也能實時更新到View。Vue採用數據劫持&發佈-訂閱模式的方式,vue在建立vm的時候,會將數據配置在實例當中,而後經過Object.defineProperty對數據進行操做,爲數據動態添加了getter與setter方法,當獲取數據的時候會觸發對應的getter方法,當設置數據的時候會觸發對應的setter方法,從而進一步觸發vm的watcher方法,而後數據更改,vm則會進一步觸發視圖更新操做。
參考:剖析Vue原理&實現雙向綁定MVVM
https://segmentfault.com/a/11...
雙向數據綁定的實現
要實現Vue中的雙向數據綁定,大體能夠劃分三個模塊:Observer、Compile、Watcher
- Observer 數據監聽器
負責對數據對象的全部屬性進行監聽(數據劫持),監聽到數據發生變化後通知訂閱者。 - Compiler 指令解析器
掃描模板,並對指令進行 解析,而後綁定指定事件。 - Watcher 訂閱者
關聯Observer和Compile,可以訂閱並收到屬性變更的通知,執行指令綁定的相應操做,更新視圖。
let data = {
message:"hello world!"
}
let vm = new Vue({
el:"#app",
data
});
// console.log(data);
// console.log(vm.$data);
//Object.defineProperty es5提供的 ie8不支持 原理
let _data={
}
let middle = 123;
Object.defineProperty(_data,"msg",{ //給某個對象賦了一個屬性 屬性中提供了get方法和set方法
get(){
return middle; 調用_data.msg至關於調用get方法 直接返回123
},
set(val){
// _data.msg = val;
middle = val; 設置完以後middle=4
}
});
console.log(_data.msg);//獲取屬性的時候,就會執行getter方法
_data.msg = 4;//設置屬性的時候,就會執行setter方法 至關於給這個對象設置msg屬性爲4
console.log(_data.msg);
this.$nextTick()
用swiper時,有沒有出現圖片劃不動的狀況,緣由是什麼?你怎麼解決的?
【VUE】swiper實例化後會出現劃不動現象,產生的緣由是原本這個地方是沒有swiper-slide這個數據的,後續咱們發送了ajax請求他纔會動態生成swiperslide,banners數據立馬改變了,它內部會生成新的虛擬dom和上一次虛擬dom結構做對比,而後產生新的真實dom,這個過程須要時間,可是咱們立馬實例化了,因此等到真實dom渲染完成後實例化早就結束了。解決方法就是,咱們必需要等到由於數據改變了引起新的真實dom渲染完成後纔會執行的操做,就能夠避免這樣的問題。
因此咱們須要把實例化的過程寫在this.$nextTick的回調函數中,在這個函數裏面進行的操做就是等到數據更新而引起的頁面當中新的虛擬dom所渲染成的真實dom真正渲染出來以後才執行,簡單來講就是等到頁面所有渲染完成後。
created(){
this.$http.get("/api/v2/movie/in_theaters",{
params:{
count:6
}
}).then(res=>{
console.log(res)
this.banners = res.data.subjects
//問題:異步請求 數據改變了 產生新的虛擬dom 須要與上一次虛擬dom結構對比 diff算法更新差別對比須要必定時間 數據渲染完成後直接實例化 就可能致使虛擬dom對比完成以後生成新的虛擬dom 這個實例化的代碼早就執行完畢了
this.$nextTick(()=>{//這個方法的做用就是 數據更改引起新的虛擬dom更新完畢 生成真實dom後 纔會進入此函數的回調函數中 因此在這個回調函數中就能夠拿到因數據改變而更新生成的真實dom
new Swiper(".home-banner",{
loop:true
})
})
})
this.$nextTick() 主要做用是等數據改變引起dom從新渲染完成以後纔會執行
能夠在實例化配置項中進行以下配置 (本身瞭解一下,可是面試官通常就想讓你說this.$nextTick()這個知識點)
observer:true,
observeParents:true//修改swiper子元素的話,會自動幫助咱們初始化swiper
生命週期
【初始化階段(4個)】
(1)beforeCreate
此鉤子函數不能獲取到數據,dom元素也沒有渲染出來,此鉤子函數不會用來作什麼事情。
(2)created
此鉤子函數,數據已經掛載了,可是dom節點仍是沒有渲染出來,在這個鉤子函數裏面,若是同步更改數據的話,不會影響運行中鉤子函數的執行。能夠用來發送ajax請求,也能夠作一些初始化事件的相關操做。
(3)beforeMount
表明dom節點立刻要被渲染出來了,可是尚未真正的渲染出來,此鉤子函數跟created鉤子函數基本同樣,也能夠作一些初始化數據的配置。
(4)mounted
是生命週期初始化階段的最後一個鉤子函數,數據已經掛載完畢了,真實dom也能夠獲取到了。
【運行中階段(2個)】
(5)beforeUpdate
運行中鉤子函數beforeUpdate默認是不會執行的,當數據更改的時候,纔會執行。數據更新的時候,先調用beforeUpdate,而後數據更新引起視圖渲染完成以後,再會執行updated。運行時beforeUpdate這個鉤子函數獲取的數據仍是更新以前的數據(獲取的是更新前的dom內容),在這個鉤子函數裏面,千萬不能對數據進行更改,會形成死循環。
(6)updated
這個鉤子函數獲取的數據是更新後的數據,生成新的虛擬dom,跟上一次的虛擬dom結構進行比較,比較出來差別(diff算法)後再渲染真實dom,當數據引起dom從新渲染的時候,在updated鉤子函數裏面就能夠獲取最新的真實dom了。
【銷燬階段(2個)】
(7)beforeDestroy
切換路由的時候,組件就會被銷燬了,銷燬以前執行beforeDestroy。在這個鉤子函數裏面,咱們能夠作一些善後的操做,例如能夠清空一下全局的定時器(created鉤子函數綁定的初始化階段的事件)、清除事件綁定。
(8)destoryed
組件銷燬後執行destroyed,銷燬後組件的雙向數據綁定、事件監聽watcher相關的都被移除掉了,可是組件的真實dom結構仍是存在在頁面中的。
官網這張生命週期流程圖要熟練掌握,在面試官問到的時候最好能將這張圖畫出來,針對每一個函數的功能作詳細解答,整個過程至少保持在3-5分鐘。若是面試官頗有耐心,還想繼續聽你說下去,能夠拓展keep-alive標籤的active和deactive這兩個生命週期函數,屬於加分項。

組件
什麼是組件?
WEB中的組件其實就是頁面組成的一部分,比如是電腦中的每個元件(如硬盤、鍵盤、鼠標),它是一個具備獨立的邏輯和功能或界面,同時又能根據規定的接口規則進行相互融合,變成一個完整的應用。
頁面就是由一個個相似這樣的部分組成的,好比導航、列表、彈窗、下拉菜單。頁面只不過是這些組件的容器,組件自由組合造成功能完整的界面,當不須要某個組件,或者想要替換某個組件時,能夠隨時進行替換和刪除,而不影響整個應用的運行。
【注】前端組件化的核心思想就是將一個巨大複雜的東西拆分紅粒度合理的小東西。
頁面中能被複用的內容都被稱之爲組件,你所能看到的一些結構,像頭部Header、Footer、Banner均可以被封裝成一個組件去複用,組件就是集成了html、css、js、image的一個聚合體。
使用組件的好處?
(1)提升開發效率
(2)方便重複使用
(3)簡化調試步驟
(4)提高整個項目的可維護性
(5)便於協同開發
組件的特性
高內聚,低耦合
爲何要封裝組件?
(1)解耦
(2)提高組件複用性
組件封裝的案例
<div id="demo">
<v-header></v-header>
</div>
<template id="header">
<div>
{{msg}}<input/>
</div>
</template>
var Header = {
template:"#header",
data(){
return {
msg:"v-header的msg!!!"
}
}
};
new Vue({
el:"#demo",
components:{
"v-header":Header
}
});
組件中的data是什麼類型?爲何是一個函數?
實例中的data是什麼類型?
爲何實例中的data是一個對象,組件中的data是一個函數?
爲了防止組件與組件之間的數據共享,讓做用域獨立,data是函數內部返回一個對象,讓每一個組件或者實例能夠維護一份被返回對象的獨立的拷貝。組件能夠被複用,可是數據不能共享,每一個組件管理本身的數據更新,不能影響其餘組件的數據。
參考:data必須是一個函數(VUE官網)
https://vue.docschina.org/v2/...
組件的 data 選項必須是一個函數,以便每一個實例均可以維護「函數返回的數據對象」的彼此獨立的數據副本。

vue組件傳值
父子組件通訊
一、父子組件經過prop傳遞數據
父組件能夠將一條數據傳遞給子組件,這條數據能夠是動態的,父組件的數據更改的時候,子組件接收的也會變化
子組件被動的接收父組件的數據,子組件不要再更改這條數據了。
組件實例的做用域是孤立的,父組件不能直接使用子組件的數據,子組件也不能直接使用父組件的數據。
父組件在調用子組件的時候給子組件傳遞數據:
<template id="father">
<div class="father">
<p>我是父組件,這是個人fMsg:{{fMsg}}</p>
<input type = "text" v-model = "fMsg">
<hr>
<son msg = "你好"></son>
</div>
</template>
父組件給子組件傳遞數據的時候,子組件須要利用props的屬性來肯定本身的預期數據,若是兒子沒有經過props屬性接受傳遞過來的數據,則數據會以自定義屬性的方式,放在兒子最外層的根元素上面。

子組件經過props來接受父組件傳遞過來的數據,而且經過{{msg}}使用
components:{
son:{
template:"<div>我是son子組件!這是父組件傳遞給個人msg:{{msg}}</div>",
//接收父組件傳遞來的屬性 msg
props:["msg"]
}
}

二、父組件經過v-bind指令傳遞自身變量給子組件
咱們能夠用 v-bind 來動態地將 prop 綁定到父組件的數據。每當父組件的數據變化時,該變化也會傳導給子組件。
<template id="father">
<div class="father">
<p>我是父組件,這是個人fMsg:{{fMsg}}</p>
<input type = "text" v-model = "fMsg">
<hr>
<!-- <son msg = "你好"></son> -->
<son :msg = "fMsg"></son>
</div>
</template>
若是若是父組件傳遞屬性給子組件的時候鍵名有'-'
<son :f-msg = "fMsg"></son>
子組件接收、使用的時候寫成小駝峯的模式
components:{
son:{
template:"<div>我是son子組件!這是父組件傳遞給個人msg:{{fMsg}}</div>",
//接收父組件傳遞來的屬性 msg
props:["fMsg"]
}
}
三、父子組件依靠應用類型的地址傳遞共享數據
單向數據流
Prop 是單向綁定的:當父組件的屬性變化時,將傳遞給子組件,可是反過來不會。這是爲了防止子組件無心間修改了父組件的狀態,來避免應用的數據流變得難以理解。
<template id="father">
<div class="father">
<input type = "text" v-model = "message">
<hr>
<son :message = "message"></son>
</div>
</template>
<template id = "son">
<div>
<p>這是子組件</p>
<input type = "text" v-model = "message"></input>
</div>
</template>
另外,每次父組件更新時,子組件的全部 prop 都會更新爲最新值。這意味着你不該該在子組件內部改變 prop。若是你這麼作了,Vue 會在控制檯給出警告。

因此若是咱們想實現父子間的數據共享,依靠的就是應用類型的地址傳遞,應將message寫成對象的形式,傳遞的時候將對象傳遞給子組件,子組件引用的時候使用對象的value值。
<template id="father">
<div class="father">
<input type = "text" v-model = "message.value">
<hr>
<!-- 傳遞的時候將對象傳遞給子組件 -->
<son :message = "message"></son>
</div>
</template>
<template id = "son">
<div>
<p>這是子組件</p>
<!-- 引用的時候使用對象的value值 -->
<input type = "text" v-model = "message.value"></input>
</div>
</template>
這時候更改父組件的value值,子組件的數據同步更改,子組件修改value值的時候也同步修改了父組件的數據。這是由於無論是子組件仍是父組件,咱們操做的都是同一個對象,父組件直接把引用類型的地址傳遞給子組件,子組件沒有直接修改對象,只是更改了裏面的屬性值。
父組件若是將一個引用類型的動態數據傳遞給子組件的時候,數據會變成雙向控制的,子組件改數據的時候父組件也能接收到數據變化,由於子組件改的時候不是在改數據(地址),而是在改數據裏的內容,也就是說引用類型數據的地址始終沒有變化,不算改父組件數據。
注意:在 JavaScript 中對象和數組是引用類型,指向同一個內存空間,若是 prop 是一個對象或數組,在子組件內部改變它會影響父組件的狀態。 message:{val:""}
$父子間數據共享(雙向控制),基本不會使用,違背了單向數據流(父=》子)$
四、viewmodel關係鏈
在組件間能夠用過ref造成ref鏈,組件還擁有一個關係鏈($parent),經過這兩種鏈;理論來講,任意的兩個組件均可以互相訪問,互相進行通訊。
$parent:父組件
$children:子組件
$root:根組件

當子組件在set方法中修改父組件傳遞過來的值時,系統會報錯,由於子組件不能修改父組件的數據。
Vue.component("bbb",{
template:"#bbb",
props:["msg"],
computed:{
/* ownMessage(){
return this.msg;
} */
ownMessage:{
get(){
return this.msg;
},
set(val){
this.msg = val //系統報錯:子組件不能更改父組件傳遞的數據
}
}
}
})

因此這時候要使用$parent,讓父組件本身更改本身的數據
set(val){
// this.msg = val //系統報錯:子組件不能更改父組件傳遞的數據
// console.log(this)
// 至關於父組件本身更改了msg數據
this.$parent.msg = val;
}
五、父組件經過ref標記獲取子組件的數據
父組件在調用子組件的時候使用ref作標記
<template id="aaa">
<div>
<button @click = "get">點擊獲取bbb數據</button>
<!-- 組件間不只能夠用過$root/$parent/$children來獲取對應關係的組件,父組件還能夠主動的經過ref爲子組件作標記 -->
<bbb ref = "b"></bbb>
</div>
</template>
父組件的this屬性上有$refs標記,經過refs標記拿到子組件

// 經過ref標記更改子組件的數據 // this.$refs.b.message = "哈哈"
組件間不只能夠用過$parent/children/root來獲取對應關係的組件,父組件還能夠主動的經過ref爲子組件作標記 也能夠給dom作標記,也會造成ref鏈,也能夠交互.
<button ref="btn" @click="get">get</button> <bbb ref="b></bbb>

注意多個子組件標記的是同一個鍵名,獲取到的應該是一個數組
<bbb ref = "b" v-for = "(item,index) in 3" :key = "index"></bbb>

// 經過下標修改對應的數值 this.$refs.b[0].message = "哈哈"
子父組件通訊
一、子組件經過父組件傳遞的方法來更改父組件的數據
父組件能夠將更改自身數據的方法傳遞給子組件,子組件調用這個方法的時候,就能夠給父組件傳遞數據,父組件被動的接收子組件的數據。
子組件聲明一條自身的msg
Vue.component("son",{
template:"#son",
// 子組件接收父組件傳遞過來的方法
props:["change"],
data(){
return{
msg:"我是子組件"
}
}
})
父組件先聲明一條本身的數據
data(){
return{
// 父組件先聲明一條本身的數據
parentMsg:""
}
}
再寫一個能夠更改自身數據的方法
methods:{
// 寫一個能夠更改自身數據的方法
change(msg){
this.parentMsg = msg
}
}
將寫好的change方法傳遞給子組件
<template id="father">
<div>
<p>這是父組件</p>
<p>子組件傳遞過來的值是:{{parentMsg}}</p>
<hr>
<!-- 調用子組件的時候,將更改自身數據的方法傳遞給子組件 -->
<son :change = "change"></son>
</div>
</template>
子組件經過props接收父組件傳遞過來的change方法
props:["change"]
給p標籤添加點擊事件,點擊即觸發change方法,同時將自身的msg傳遞給父組件,至關於父組件的change方法被執行。
<template id="son">
<div>
<p>子組件說:{{msg}}</p>
<p @click = "change(msg)">點擊我觸發父親的change方法</p>
</div>
</template>
父組件能夠在頁面中渲染子組件傳遞過來的數據
<p>子組件傳遞過來的值是:{{parentMsg}}</p>
二、經過自定義事件實現子父通訊
每個組件或者實例都會有自定義事件,和觸發事件的能力,父組件給子組件綁定一個自定義事件,這個事件的處理程序倒是父組件的一個方法,當子組件觸發這個事件的時候,至關於父組件的方法被執行。
父組件想獲取子組件的數據時,在調用子組件的時候給子組件綁定一個自定義事件change-event
<template id="father">
<div>
<p>這是父組件</p>
<p>子組件傳遞過來的值是:{{parentMsg}}</p>
<hr>
<!-- 給子組件綁定一個自定義事件 -->
<son @change-event = "change"></son>
</div>
</template>
在子組件中定義一個點擊事件,點擊p標籤執行changeWord方法
<p @click = "changeWord">點擊我觸發父親的change方法</p>
在方法中編寫changeWord方法,經過this.$emit來觸發綁定在本身身上的自定義事件,第一個參數爲事件名稱change-event,第二個參數爲觸發這個函數的時候給他傳遞的數值:自身的msg。
methods:{
changeWord(){
//觸發自身綁定的change事件
this.$emit("change-event",this.msg)//第一個參數爲觸發事件的名字,第二個參數爲觸發這個函數的時候給他傳遞的數值
}
}
一旦觸發綁定在自身上的自定義事件,至關於父組件的change方法被執行。
兄弟組件通訊
一、經過viewmodel關係鏈
定義哥哥組件,給哥哥組件添加一個點擊事件,點擊觸發hitLittle方法
<template id = "big-brother">
<div>
<p>我是哥哥</p>
<button @click = "hitLittle">打弟弟</button>
</div>
</template>
定義弟弟組件,給弟弟組件添加一個p標籤,由crying數據控制其顯示與隱藏
<template id="little-brother">
<div>
<p>我是弟弟</p>
<p v-if = "crying">嗚嗚嗚</p>
</div>
</template>
在弟弟組件的data中聲明crying數據,默認爲false
Vue.component("little-brother",{
template:"#little-brother",
data(){
return{
crying:false
}
}
})
在哥哥組件的methods中定義hitLittle方法,經過viewmodel關係鏈更改弟弟組件中的crying方法
Vue.component("big-brother",{
template:"#big-brother",
methods:{
hitLittle(){
//在兄弟組件之間的通訊,能夠採用關係鏈和ref鏈去使用,解決兄弟之間通訊問題。
this.$parent.$children[1].crying = true;//讓littel改變自身的crying狀態
}
}
})
二、viewmodel關係鏈+ref鏈
在弟弟組件中添加ref標記
<little-brother ref = "little"></little-brother>
在哥哥組件的hitLittle方法中經過viewmodel和ref鏈配合使用更改弟弟組件中的crying數據
hitLittle(){
//在兄弟組件之間的通訊,能夠採用關係鏈和ref鏈去使用,解決兄弟之間通訊問題。
// this.$parent.$children[1].crying = true;//讓littel改變自身的crying狀態
//viewmodel鏈和ref鏈配合使用
this.$parent.$refs.little.crying = true;
}
三、eventbus事件總線
建立一個空的實例
var angle = new Vue();
弟弟組件本身定義一個更改自身狀態的方法
methods:{
cry(){
this.crying = true
}
}
在mounted生命週期函數中綁定一個自定義事件,第一個參數爲自定義事件名,第二個函數爲須要處理的函數
mounted(){
// 綁定一個自定義事件,第一個參數爲自定義事件名,第二個函數爲須要處理的函數
angle.$on("hit-little",this.cry)
}
在哥哥組件中觸發自定義事件
hitLittle(){
//觸發little-brother組件的hit-little事件
angle.$emit("hit-little")
}
keep-alive緩存
keep-alive在項目中如何應用?
當在組件之間進行切換的時候,你有時會想保持這些組件的狀態,以免反覆重渲染致使的性能問題。當從a頁面跳轉到b頁面再跳轉回a頁面時,能夠不用再次進行數據請求,直接從緩存裏面獲取數據,減小性能消耗。
例如咱們來展開說一說這個多標籤界面:
你會注意到,若是你選擇了一篇文章,切換到 Archive 標籤,而後再切換回 Posts,是不會繼續展現你以前選擇的文章的。這是由於你每次切換新標籤的時候,Vue 都建立了一個新的 currentTabComponent 實例。
從新建立動態組件的行爲一般是很是有用的,可是在這個案例中,咱們更但願那些標籤的組件實例可以被在它們第一次被建立的時候緩存下來。爲了解決這個問題,咱們能夠用一個 <keep-alive> 元素將其動態組件包裹起來。
keep-alive的生命週期函數
當組件在<keep-alive>內被切換時,它的actived和deactived這兩個生命週期鉤子函數將會被對應執行,初始化操做放在actived裏面,一旦切換組件,由於組件沒有被銷燬,因此它不會執行銷燬階段的鉤子函數,因此移除操做須要放在deactived裏面,在裏面進行一些善後操做,這個時候created鉤子函數只會執行一次,銷燬的鉤子函數一直沒有執行。
keep-alive的屬性
Keep-alive提供了兩個屬性:容許組件有條件的緩存
include:我只須要緩存哪一些組件
exclude:除了這個組件以外其餘組件都會被緩存
原理:
在created的時候,將須要緩存的虛擬dom節點放到cache中,在render的時候根據name再進行取出。
keep-alive只能在組件切換的標籤中進行緩存
<keep-alive include="indexCom">
<router-view/>
</keep-alive>
使用傳統寫法比較麻煩,咱們能夠在須要被緩存的頁面的路由中添加keepAlive:true字段
{
path: '/',
name: 'index',
meta:{
keepAlive:true //該字段代表頁面須要緩存
},
component: resolve=>require(["@/page/index"],resolve)
}
在組件切換的時候,檢查下原數據上面有沒有keepAlive這個屬性,若是有的話就keep-alive緩存一下,沒有的話就該怎麼顯示怎麼顯示。
<keep-alive> <router-view v-if="$route.meta.keepAlive"></router-view> </keep-alive> <router-view v-if="!$route.meta.keepAlive"></router-view>
指令
說一下vue經常使用的內置指令
一、v-bind:響應並更新DOM特性;例如:v-bind:href v-bind:class v-bind:title v-bind:bb
二、v-on:用於監聽DOM事件; 例如:v-on:click v-on:keyup
三、v-model:數據雙向綁定;用於表單輸入等;例如:<input v-model="message">
四、v-show:條件渲染指令,爲DOM設置css的style屬性
五、v-if:條件渲染指令,動態在DOM內添加或刪除DOM元素
六、v-else:條件渲染指令,必須跟v-if成對使用
七、v-for:循環指令;例如:<li v-for="(item,index) in todos"></li>
八、v-else-if:判斷多層條件,必須跟v-if成對使用;
九、v-text:更新元素的textContent;例如:<span v-text="msg"></span> 等同於 <span>{{msg}}</span>;
十、v-html:更新元素的innerHTML;
十一、v-pre:不須要表達式,跳過這個元素以及子元素的編譯過程,以此來加快整個項目的編譯速度;例如:<span v-pre>{{ this will not be compiled }}</span>;
十二、v-cloak:不須要表達式,這個指令保持在元素上直到關聯實例結束編譯;
1三、v-once:不須要表達式,只渲染元素或組件一次,隨後的渲染,組件/元素以及下面的子元素都當成靜態頁面不在渲染。
如何註冊自定義指令
使用Vue.directive(id,definition)註冊全局自定義指令,接收兩個參數,指令ID以及定義對象。使用組件的directives選項註冊局部自定義指令。
自定義指令的鉤子函數
一個指令定義對象能夠提供以下幾個鉤子函數 (均爲可選):
bind:只調用一次,指令第一次綁定到元素時調用。在這裏能夠進行一次性的初始化設置。
inserted:被綁定元素插入父節點時調用 (僅保證父節點存在,但不必定已被插入文檔中)。
update:所在組件的 VNode 更新時調用,可是可能發生在其子 VNode 更新以前。指令的值可能發生了改變,也可能沒有。可是你能夠經過比較更新先後的值來忽略沒必要要的模板更新 (詳細的鉤子函數參數見下)。componentUpdated:指令所在組件的 VNode 及其子 VNode 所有更新後調用。
unbind:只調用一次,指令與元素解綁時調用。
拓展:自定義指令(VUE官網)
https://cn.vuejs.org/v2/guide...
v-model是什麼?
v-model是用於表單的據雙向綁定的指令
如何本身去實現一個v-model數據綁定?
兩個步驟:
- v-bind 綁定了一個value的屬性
-
v-on 把當前元素綁定到了一個事件上
<template> <div class="logs"> logs!!! <p><input type="text" v-model="msg"></p> <p>{{msg}}</p> <hr> <p><input type="text" :value="msg2" @input="msg2 = $event.target.value"></p> <p>{{msg2}}</p> </div> </template> <script> export default { name:"logs", data(){ return { msg:"helloworld", msg2:"" } } } </script>
v-if和v-show的區別
v-if 是「真正」的條件渲染,由於它會確保在切換過程當中條件塊內的事件監聽器和子組件適當地被銷燬和重建。 v-if 也是惰性的:若是在初始渲染時條件爲假,則什麼也不作——直到條件第一次變爲真時,纔會開始渲染條件塊。 相比之下,v-show 就簡單得多——無論初始條件是什麼,元素老是會被渲染,而且只是簡單地基於 CSS 進行切換。 通常來講,v-if 有更高的切換開銷,而 v-show 有更高的初始渲染開銷。所以,若是須要很是頻繁地切換,則使用 v-show 較好;若是在運行時條件不多改變,則使用 v-if 較好。
路由守衛
講一下都有哪些路由守衛?
全局前置守衛:router.beforeEach 在路由切換開始時候調用
全局後置守衛:roter.afterEach 在路由切換離開時候調用
局部路由守衛:beforeEnter 寫在路由對象裏
組件內的守衛:
beforeRouteEnter 路由進入到這個組件以前調用,不能獲取當前組件對象 this
beforeRouteUpdate 在組件被複用時調用
beforeRouteLeave 路由離開這個組件以後調用,能獲取當前組件對象 this
路由守衛中的參數都是什麼意思
每一個鉤子方法接收三個參數:
- to: Route: 即將要進入的目標,路由對象
- from: Route: 當前導航正要離開的路由
- next: Function: 必定要調用該方法來 resolve 這個鉤子。執行效果依賴 next 方法的調用參數。
- next(): 進行管道中的下一個鉤子。若是所有鉤子執行完了,則導航的狀態就是 confirmed (確認的)。
- next(false): 中斷當前的導航。若是瀏覽器的 URL 改變了(多是用戶手動或者瀏覽器後退按鈕),那麼 URL 地址會重置到 from 路由對應的地址。
- next(‘/’) 或者 next({ path: ‘/’ }): 跳轉到一個不一樣的地址。當前的導航被中斷,而後進行一個新的導航。
確保要調用 next 方法,不然鉤子就不會被 resolved。
具體說一下每一個路由守衛的功能
導航守衛(路由鉤子/路由守衛/導航守衛/導航鉤子/路由生命週期)
正如其名,
vue-router 提供的導航守衛主要用來經過跳轉或取消的方式守衛導航。有多種機會植入路由導航過程當中:全局的,單個路由獨享的,,或者組件級的。
在某些狀況下,當路由跳轉前或跳轉後、進入、離開某一個路由前、後,須要作某些操做,就能夠使用路由鉤子來監聽路由的變化。
全局守衛
(1)全局前置守衛beforeEach
當一個導航觸發時,全局前置守衛按照建立順序調用。守衛是異步解析執行,此時導航在全部守衛 resolve 完以前一直處於 等待中,因此頁面不會加載任何內容。

必定要在路由守衛中調用next()方法來resolve這個鉤子
// 全局前置路由
router.beforeEach((to,from,next)=>{
console.log("beforeEach:全局前置守衛")
// 必定要調用next()方法來resolve這個鉤子
next();
})

(2)全局後置守衛afterEach
也能夠註冊全局後置鉤子,然而和前置守衛不一樣的是,這些鉤子不會接受 next 函數也不會改變導航自己:
// 全局後置鉤子
router.afterEach((to,from)=>{
if (to.path === "/list/audio") {
alert("已經進入list列表audio頁面")
}
})
局部守衛
路由獨享的守衛
在路由配置上直接定義beforeEnter守衛:
{ path :"/mine",component:()=>import("../views/Mine"),beforeEnter(to,from,next){
console.log("進入到mine頁面了")
next();
}}
組件內的守衛
最後,你能夠在路由組件內直接定義如下路由導航守衛:
-
beforeRouteEnter
在進入該組件以前執行,該路由守衛中獲取不到實例this,由於此時組件實例還沒被建立。
beforeRouteEnter守衛 不能 訪問this,由於守衛在導航確認前被調用,所以即將登場的新組件還沒被建立。在Home.vue中添加beforeRouteEnter:
beforeRouteEnter(to,from,next){ console.log("beforeRouteEnter:進入組件以前",this) next() }打印this,顯示undefined
不過,你能夠經過傳一個回調給
next來訪問組件實例。在導航被確認的時候執行回調,而且把組件實例做爲回調方法的參數。beforeRouteEnter (to, from, next) { next(vm => { // 經過 `vm` 訪問組件實例 }) }注意
beforeRouteEnter是支持給next傳遞迴調的惟一守衛。對於beforeRouteUpdate和beforeRouteLeave來講,this已經可用了,因此不支持傳遞迴調,由於沒有必要了。 -
beforeRouteLeave
在離開該組件以前執行,該路由守衛中能夠訪問組件實例"this"。
在Home.vue中添加beforeRouteLeave:
beforeRouteLeave(to,from,next){ console.log("beforeRouteLeave:離開組件以前",this) next() }此時能夠打印組件實例"this"
這個離開守衛一般用來禁止用戶在還未保存修改前忽然離開。該導航能夠經過
next(false)來取消。 -
beforeRouteUpdate(2.2 新增)
當一個組件被重複調用的時候執行該守衛
在Deatil.vue中添加beforeRouteUpdate:
beforeRouteUpdate(to,from,next){ console.log("beforeRouteUpdate") next() }


在vue項目中哪裏用到過路由守衛?舉一個使用到路由守衛的案例
咱們想實現當路由變化的時候頭部信息動態更改,咱們先把內容寫成這種樣式:
template中:
<div class = "left">
<i :class = "['fa','fa-' + icon]"></i>
<span>{{title}}</span>
</div>
data中:
data(){
return{
icon:"home",
title:"豆瓣首頁",
}
},
這時候就須要用到路由守衛,當路由切換的時候能夠作一些業務邏輯,首先須要引入全局路由
import router from "@/router"
在全局前置路由守衛router.beforeEach中,使用switch語句來匹配,根據路由name屬性來設置對應的title和icon:
created(){
router.beforeEach((to,from,next)=>{
switch(to.name){
case "home":
this.title = "豆瓣首頁"
this.icon = "home"
break;
case "audio":
this.title = "豆瓣影音"
this.icon = "audio-description"
break;
case "broadcast":
this.title = "豆瓣廣播"
this.icon = "caret-square-o-left"
break;
case "group":
this.title = "豆瓣小組"
this.icon = "group"
break;
case "mine":
this.title = "豆瓣個人"
this.icon = "cog"
break;
default:
break;
}
next();
})
}
路由
什麼是SPA單頁應用?你怎麼理解單頁應用?
如今的應用都流行SPA(single page application),傳統的項目大多使用多頁面結構,須要切換內容的時候咱們每每會進行單個html文件的跳轉,這個時候受網絡、性能影響,瀏覽器會出現不定時間的空白界面,用戶體驗很差。
單頁面應用就是用戶經過某些操做更改地址欄url以後,動態地進行不一樣模板內容的無刷新切換,用戶體驗好。
單頁應用的優勢
- 更好的用戶體驗,讓用戶在web感覺natvie的速度和流暢;
- 經典MVC開發模式,先後端各負其責。
- 一套Server API,多端使用(web、移動APP等)
- 重前端,業務邏輯所有在本地操做,數據都須要經過AJAX同步、提交;
Vue切換路由的方法?vue-router的原理?
Vue中會使用官方提供的vue-router插件來使用單頁面,原理就是經過檢測地址欄變化後將對應的路由組件進行切換(卸載和安裝)。
- 引入vue-router,若是是在腳手架中,引入VueRouter以後,須要經過Vue.use來註冊插件
- 建立router路由器
- 建立路由表並配置在路由器中
- 在根實例裏注入router,目的是爲了讓全部的組件裏都能經過this.$router/route來使用路由的相關功能api
- 利用router-view來指定路由切換的位置
- 使用router-link來建立切換的工具,默認會渲染成a標籤,添加to屬性來設置要更改的path信息,且會根據當前路由的變化爲a標籤添加對應的router-link-active/router-link-exact-active(徹底匹配成功)類名。
router-link標籤的屬性
<router-link> 組件支持用戶在具備路由功能的應用中(點擊)導航。 經過 to 屬性指定目標地址,默認渲染成帶有正確連接的 標籤,能夠經過配置 tag 屬性生成別的標籤。另外,當目標路由成功激活時,連接元素自動設置一個表示激活的 CSS 類名。
to
router-link的to屬性,默認寫的是path(路由的路徑),能夠經過設置一個對象,來匹配更多。
<router-link tag = "li" :to = "{name:'detail',params:{id:'1'},query:{title:'最近%E經過配置 tag 屬性生成別的標籤。另外,當目標路由成功激活時,連接元素自動設置一個表示激活的 CSS 類名。
**to**
router-link的to屬性,默認寫的是path(路由的路徑),能夠經過設置一個對象,來匹配更多。
<router-link tag = "li" :to = "{name:'detail',params:{id:'1'},query:{title:'最近播放'}}">個人歌單</router-link>
**name** name是要跳轉的路由的名字,也能夠寫path來指定路徑,可是用path的時候就不能使用params傳參,params是傳路由參數,query傳queryString參數。 **replace** > 路由跳轉到不一樣的url默認是push的過程,當用戶點擊瀏覽器後退按鈕式時,則回到以前url,replace屬性能夠控制router-link的跳轉不被記錄。 依次點擊首頁——列表——音頻——視頻——個人,點擊返回按鈕時,依次返回以前的url。  在List.vue的<router-link>標籤中添加replace屬性,則該標籤內的跳轉不會被記錄
<router-link
v-for = "nav in navs"
:key = "nav.id"
:to = "{name:nav.name}"
active-class = "title"
replace
>
{{nav.title}}
</router-link>
再依次點擊首頁——列表——音頻——視頻——個人,點擊返回按鈕時,能夠看到從音頻——視頻之間的跳轉沒有被記錄。  **active-class** <router-link>且會根據當前路由的變化爲a標籤添加對應的router-link-active/router-link-exact-active(徹底匹配成功)類名,咱們能夠經過它來爲標籤設置不一樣的選中樣式。
<style lang="scss">
.router-link-active{
color:blue;
}
.router-link-exact-active{
color:red; font-weight:900;
}
</style>
標籤切換時,選中狀態的顯示效果:  還能夠經過<router-link>的active-class屬性給a標籤添加指定一個activeClass名,經過設置這個class的樣式,來設置標籤選中時的狀態,功能相似於router-link-exact-active。
<router-link
v-for = "nav in navs"
:key = "nav.id"
:to = "nav.path"
active-class = "title"
>
{{nav.title}}
</router-link>
設置.title樣式
<style lang = "scss" scoped>
.title{
color:aquamarine;
}
</style>
顯示效果:  **tag** <router-link>默認渲染成帶有正確連接的a標籤,能夠經過配置 tag 屬性生成別的標籤。
<ul>
<router-link tag = "li">個人歌單</router-link> <router-link tag = "li">最近播放</router-link> </ul>
 #### 路由跳轉的方式 1. <router-link> 組件支持用戶在具備路由功能的應用中(點擊)導航。 經過 to 屬性指定目標地址,默認渲染成帶有正確連接的a標籤,能夠經過配置 tag 屬性生成別的標籤。另外,當目標路由成功激活時,連接元素自動設置一個表示激活的 CSS 類名。 2. 編程式導航:this.$router.replace This.$router.go #### 一級路由的實現 1. 若是不是使用腳手架建立的項目,須要手動安裝vue-router路由模塊。
cnpm install vue-router -S
2. 引入vue-router,若是是在腳手架中,引入VueRouter以後,須要經過Vue.use來註冊插件。
import Vue from 'vue'
import Router from 'vue-router'
Vue.use(Router)//讓vue能夠使用vue-router插件
註冊vue-router插件以後,this上就有了$route/router屬性。  3. 建立router路由器,並導出。
let router = new Router({
routes:[ ]
})
export default router;
4. 在根實例裏注入router
new Vue({
//掛載router router,//爲了可讓組件使用this.$route,this.$router的一些api屬性或者方法 store, render: h => h(App)
}).$mount('#app')
此時組件能夠經過this.$router/router來使用路由相關功能的api。  5. 建立router路由表
let router = new Router({
routes:[
{
path:"/home",component:Home
},
{
path: "/list", component: List
},
{
path: "/mine", component: Mine
}
]
})
6. 在App.vue中利用router-view來指定路由切換的位置
<template>
<div id="app"> Hello app.vue! <!-- 顯示路由組件的位置 --> <router-view></router-view> </div>
</template>
路由切換效果:  7. 使用router-link來建立切換路由的工具
<div>
<router-link to = "/home">首頁</router-link>
<router-link to = "/list">列表</router-link>
<router-link to = "/mine">個人</router-link>
</div>
 <router-link>會渲染成a標籤,添加to屬性來設置要更改的path信息  #### 二級路由(路由嵌套) 在建立路由表的時候,能夠爲每個路由對象建立children屬性,值爲數組,在這個裏面又能夠配置一些路由對象來使用多級路由,注意:一級路由path前加'/',二級路由前不須要加'/'。
{ path :"/list",component:()=>import("../views/List"),children:[
// 二級路由前不須要加「/」
{ path: "audio", component: () => import("../views/Audio") },
{ path: "video", component: () => import("../views/Video") }
]}
> 二級路由組件的切換位置依然由router-view來指定(指定在父級路由組件的模板中)。 #### 動態路由 在router路由表中配置動態路由,下面的代碼就是給detail路由配置接收id的參數,多個參數繼續在後面設置。
// 配置動態路由
{ path:"/detail/:id",component:()=>import("../views/Detail.vue")}
在頁面中經過<router-link>的to屬性傳遞參數:
<ul>
<router-link tag = "li" to = "/detail/1">個人歌單</router-link> <router-link tag = "li" to = "/detail/2">最近播放</router-link> </ul>
在Detail.vue中打印this.$route.params.id
export default {
created(){
//獲取動態路由傳遞過來的參數
console.log(this.$route.params.id)
}
}
在頁面中經過$route.params.id渲染獲取到的動態id
<template>
<div class = "detail">
我是詳情頁,個人動態id是:{{$route.params.id}}
</div>
</template>
<router-view class="view one"></router-view>
<router-view class="view two" name="a"></router-view>
<router-view class="view three" name="b"></router-view>
一個視圖使用一個組件渲染,所以對於同個路由,多個視圖就須要多個組件。確保正確使用 `components` 配置 (帶上 s):
const router = new VueRouter({
routes: [
{
path: '/',
components: {
default: Foo,
a: Bar,
b: Baz
}
}
]
})
參考:命名識圖(VUE官網) https://router.vuejs.org/zh/guide/essentials/named-views.html#%E5%B5%8C%E5%A5%97%E5%91%BD%E5%90%8D%E8%A7%86%E5%9B%BE #### Vue路由傳參有幾種方式 **路由參數** 在router路由表中配置動態路由,下面的代碼就是給detail路由配置接收id的參數,多個參數繼續在後面設置。
// 配置動態路由
{ path:"/detail/:id",component:()=>import("../views/Detail.vue")}
在頁面中經過<router-link>的to屬性傳遞參數:
<ul>
<router-link tag = "li" to = "/detail/1">個人歌單</router-link> <router-link tag = "li" to = "/detail/2">最近播放</router-link> </ul>
在Detail.vue中打印this.$route.params.id
export default {
created(){
//獲取動態路由傳遞過來的參數
console.log(this.$route.params.id)
}
}
在頁面中經過$route.params.id渲染獲取到的動態id
<template>
<div class = "detail">
我是詳情頁,個人動態id是:{{$route.params.id}}
</div>
</template>
 **queryString參數** queryString參數不須要在路由表設置接收,直接設置?後面的內容:
<ul>
<router-link tag = "li" to = "/detail/1?title=個人歌單">個人歌單</router-link> <router-link tag = "li" to = "/detail/2?title=最近播放">最近播放</router-link> </ul>
在路由組件中經過this.$route.query接收
export default {
created(){
//獲取動態路由傳遞過來的參數
console.log(this.$route.params.id,this.$route.query.title)
}
}
打印結果:  頁面渲染效果:  上面的參數傳遞也能夠寫成對象的形式:
<!-- 寫成對象的形式 -->
<router-link tag = "li" :to = "{path:'/detail/2',query:{title:'最近播放'}}">最近播放</router-link>
**經過prop將路由與組件解耦** 在組件中接收路由參數須要this.$route.params.id,代碼冗餘,如今能夠在路由表裏配置props:true。
{ path:"/detail/:id",component:()=>import("../views/Detail.vue"),name:"detail",props:true}
在路由組件中能夠經過props接收id參數去使用
props:["id"],
在頁面中就能夠經過{{id}}的方式來使用路由傳遞的參數
個人動態id是:{{id}}
#### 路由模式 > 爲了構建SPA(單頁面應用),須要引入前端路由系統,這也就是Vue-router存在的意義。前端路由的核心,就在於:改變視圖的同時不會向後端發出請求。 hash和history這兩個方法應用於瀏覽器的歷史記錄站,在當前已有的back、forward、go 的基礎之上,它們提供了對歷史記錄進行修改的功能。只是當它們執行修改是,雖然改變了當前的URL,但你瀏覽器不會當即向後端發送請求。 **hash:即地址欄URL中的#符號(此hsah 不是密碼學裏的散列運算)** 路由有兩種模式:hash、history,默認會使用hash模式  好比這個URL:http://www.baidu.com/#/hello, hash 的值爲#/hello。它的特色在於:hash 雖然出現URL中,但不會被包含在HTTP請求中,對後端徹底沒有影響,所以改變hash不會從新加載頁面。 **history:利用了HTML5 History Interface 中新增的pushState() 和replaceState() 方法。(須要特定瀏覽器支持)** 若是url裏不想出現醜陋hash值(#),在new VueRouter的時候配置mode值爲history來改變路由模式,本質使用H5的histroy.pushState方法來更改url,不會引發刷新。
// 默認會使用hash模式
mode:"history",
 > history模式,會出現404 的狀況,須要後臺配置。 **hash模式和history模式在發生404錯誤時:** 1. hash模式下,僅hash符號以前的內容會被包含在請求中,當用戶訪問https://www.baidu.com/#/home時實際請求的是:https://www.baidu.com/。所以對於後端來講,即便沒有作到對路由的全覆蓋,頁面也不會返回404錯誤; 2. history模式下,前端的url必須和實際向後端發起請求的url 一致,由於咱們的應用是個單頁客戶端應用,若是後臺沒有正確的配置,當用戶在瀏覽器直接訪問 https://www.baidu.com/home/detail,缺乏對/home/detail的路由處理,就會返回 404錯誤,這就很差看了。  因此呢,你要在服務端增長一個覆蓋全部狀況的候選資源:若是 URL 匹配不到任何靜態資源,則應該返回同一個 index.html 頁面,這個頁面就是你 app 依賴的頁面。 #### hash哈希路由的原理
window.onload = function(){
//當hash發生變化的時候, 會產生一個事件 onhashchange
window.onhashchange = function(){
console.log( '你的hash改變了' );
//location對象是 javascript內置的(自帶的)
console.log( location );
}
}
上例,咱們已經經過hash( 就是錨文本 ) 變化, 觸發了onhashchange事件, 就能夠把hash變化與內容切換對應起來,就實現了單頁路由的應用! 監控hash值變化,hash一旦變化,頁面內容變化,實現無刷新切換。 參考:js單頁hash路由原理與應用實戰 https://www.cnblogs.com/ghostwu/p/7357381.html #### 路由的懶加載 當打包構建應用時,JavaScript 包會變得很是大,影響頁面加載。若是咱們能把不一樣路由對應的組件分割成不一樣的代碼塊,而後當路由被訪問的時候才加載對應組件,這樣就更加高效了。結合 Vue 的異步組件和 Webpack 的代碼分割功能,輕鬆實現路由組件的懶加載。 懶加載也叫延遲加載,即在須要的時候進行加載,隨用隨載。在單頁應用中,若是沒有應用懶加載,運用webpack打包後的文件將會異常的大,形成進入首頁時,須要加載的內容過多,延時過長,會出現長時間的白屏,即便作了loading也是不利於用戶體驗,而運用懶加載則能夠將頁面進行劃分,須要的時候加載頁面,能夠有效的分擔首頁所承擔的加載壓力,減小首頁加載用時。簡單的說就是:進入首頁時不用一次加載過多資源,形成頁面加載用時過長。 懶加載寫法:
// 路由的懶加載方式
{ path :"/home",component:()=>import("../views/Home")},// 當我訪問/home首頁時,頁面纔去加載Home組件,減小首頁加載的時長
{ path :"/list",component:()=>import("../views/List")},
{ path :"/mine",component:()=>import("../views/Mine")}
非按需加載則會把全部的路由組件塊的js包打在一塊兒。當業務包很大的時候建議用路由的按需加載(懶加載)。 按需加載會在頁面第一次請求的時候,把相關路由組件塊的js添加上。 參考:路由的懶加載(VUE官網) https://router.vuejs.org/zh/guide/advanced/lazy-loading.html #### 經過正則匹配路由
// The matching uses path-to-regexp, which is the matching engine used
// by express as well, so the same matching rules apply.
// For detailed rules, see https://github.com/pillarjs/p...
const router = new VueRouter({
mode: 'history',
base: __dirname,
routes: [
{ path: '/' },
// params are denoted with a colon ":"
{ path: '/params/:foo/:bar' },
// a param can be made optional by adding "?"
{ path: '/optional-params/:foo?' },
// a param can be followed by a regex pattern in parens
// this route will only be matched if :id is all numbers
{ path: '/params-with-regex/:id(\\d+)' },
// asterisk can match anything
{ path: '/asterisk/*' },
// make part of th path optional by wrapping with parens and add "?"
{ path: '/optional-group/(foo/)?bar' }
]
})
官方例子github地址:https://github.com/vuejs/vue-router/blob/next/examples/route-matching/app.js ### Vuex #### 什麼是Vuex? vuex是一個專門爲vue構建的狀態集管理工具,vue和react都是基於組件化開發的,項目中包含不少的組件,組件都會有組件嵌套,想讓組件中的數據被其餘組件也能夠訪問到就須要使用到Vuex。 #### #### Vuex主要解決了什麼問題? Vuex主要是爲了解決多組件之間狀態共享問題,它強調的是集中式管理(組件與組件之間的關係變成了組件與倉庫之間的關係)把數據都放在一個倉庫中管理,使用數據的時候直接從倉庫中獲取,若是倉庫中一個數據改變了, 那麼全部使用這個數據的組件都會更新。Vuex把組件與組件之間的關係解耦成組件與倉庫之間的關係,方便數據維護。 #### Vuex的流程?Vuex的核心?  (1)將須要共享的狀態掛載到state上:this.$store.state來調用 建立store,將狀態掛載到state上,在根實例裏面配置store,以後咱們在組件中就能夠經過this.$store.state來使用state中管理的數據,可是這樣使用時,當state的數據更改的時候,vue組件並不會從新渲染,因此咱們要經過計算屬性computed來使用,可是當咱們使用多個數據的時候這種寫法比較麻煩,vuex提供了**mapState輔助函數**,幫助咱們在組件中獲取並使用vuex的store中保存的狀態。 (2)咱們經過getters來建立狀態:經過this.$store.getters來調用 能夠根據某一個狀態派生出一個新狀態,vuex也提供了**mapGetters輔助函數**來幫助咱們在組件中使用getters裏的狀態。 (3)使用mutations來更改state:經過this.$store.commit來調用 咱們不能直接在組件中更改state,而是須要使用mutations來更改,mutations也是一個純對象,裏面包含不少更改state的方法,這些方法的形參接收到state,在函數體裏更改,這時,組件用到的數據也會更改,實現響應式。vuex提供了mapMutations方法來幫助咱們在組件中調用mutations 的方法。 (4)使用actions來處理異步操做:this.$store.dispatch來調用 Actions相似於mutations,不一樣在於:Actions提交的是mutations,而不是直接變動狀態。Actions能夠包含任意異步操做。也就是說,若是有這樣的需求:在一個異步操做處理以後,更改狀態,咱們在組件中應該先調用actions,來進行異步動做,而後由actions調用mutations來更改數據。在組件中經過this.$store.dispatch方法調用actions的方法,固然也能夠使用mapMutations來輔助使用。 簡便版流程:
組件使用數據且經過異步動做更改數據的一系列事情:
1.生成store,設置state
2.在根實例中注入store
3.組件經過計算屬性或者mapState來使用狀態
4.用戶產生操做,調用actions的方法,而後進行異步動做
5.異步動做以後,經過commit調用mutations的方法
6.mutations方法被調用後,更改state
7.state中的數據更新以後,計算屬性從新執行來更改在頁面中使用的狀態
8.組件狀態被更改,建立新的虛擬dom
9.組件的模板更新以後從新渲染在dom中
#### 什麼狀況下用到vuex? 使用Vuex的狀況:多組件間頻繁通訊
目前市場上有兩種使用vuex的狀況,
第一種:將須要共享、須要管理的狀態放入vuex中管理,也就是說在必要時使用
第二種:將全部的數據都交由vuex管理,由vuex來承擔更多的責任,組件變得更輕量級,視圖層更輕
#### 項目中使用到vuex的一些場景? (1)購物車數據共享 (2)用戶登陸 (3)打開窗口,出現一個表單數據,而後關閉窗口,再次打開還想出現,就使用vuex #### Vuex的項目結構 Vuex 並不限制你的代碼結構。可是,它規定了一些須要遵照的規則: 1. 應用層級的狀態應該集中到單個 store 對象中。 2. 提交 **mutation** 是更改狀態的惟一方法,而且這個過程是同步的。 3. 異步邏輯都應該封裝到 **action** 裏面。 只要你遵照以上規則,如何組織代碼隨你便。若是你的 store 文件太大,只需將 action、mutation 和 getter 分割到單獨的文件。 對於大型應用,咱們會但願把 Vuex 相關代碼分割到模塊中。下面是項目結構示例:
├── index.html
├── main.js
├── api
│ └── ... # 抽取出API請求
├── components
│ ├── App.vue
│ └── ...
└── store
├── index.js # 咱們組裝模塊並導出 store 的地方
├── actions.js # 根級別的 action
├── mutations.js # 根級別的 mutation
└── modules
├── cart.js # 購物車模塊
└── products.js # 產品模塊
來源:項目結構(VUE官網) https://vuex.vuejs.org/zh/guide/structure.html#%E9%A1%B9%E7%9B%AE%E7%BB%93%E6%9E%84 #### vuex與local storage有什麼區別 1. 區別:vuex存儲在內存,localstorage(本地存儲)則以文件的方式存儲在本地,永久保存;sessionstorage( 會話存儲 ) ,臨時保存。localStorage和sessionStorage只能存儲字符串類型,對於複雜的對象能夠使用ECMAScript提供的JSON對象的stringify和parse來處理。 2. 應用場景:vuex用於組件之間的傳值,localstorage,sessionstorage則主要用於不一樣頁面之間的傳值。 3. 永久性:當刷新頁面(這裏的刷新頁面指的是 --> F5刷新,屬於清除內存了)時vuex存儲的值會丟失,sessionstorage頁面關閉後就清除掉了,localstorage不會。 注:不少同窗以爲用localstorage能夠代替vuex, 對於不變的數據確實能夠,可是當兩個組件共用一個數據源(對象或數組)時,若是其中一個組件改變了該數據源,但願另外一個組件響應該變化時,localstorage,sessionstorage沒法作到,緣由就是區別1。 ### Slot插槽 > vue裏提供了一種將父組件的內容和子組件的模板整合的方法:內容分發,經過slot插槽來實現。 在組件標籤內部寫入的內容默認的會被替換掉,若是想要在組件的模板裏使用這些內容,就在對應的位置寫上slot標籤,這個slot標籤就表明着這些內容。 #### 匿名槽口 在父組件中使用子組件的時候,在子組件標籤內部寫的內容,在子組件的模板中能夠經過<slot></slot>來使用
<div id = "app">
<aaa>
<h3>slot槽口插入的內容</h3>
</aaa>
</div>
<template id="aaa">
<div class = "aaa">
<slot></slot>
<p>我是aaa組件</p>
</div>
</template>
 #### 具名槽口 父組件在子組件標籤內寫的多個內容咱們能夠給其設置slot屬性來命名,在子組件的模板經過使用帶有name屬性的slot標籤來放置對應的slot,當slot不存在的時候,slot標籤內寫的內容就出現。 slot上面經過name屬性指定槽口名稱,而後使用的時候經過slot="槽口名稱"。
<div id = "app">
<aaa>
<!-- <h3>slot槽口插入的內容</h3> -->
<p slot = "s1">在上面的內容</p>
<p slot = "s2">在下面的內容</p>
</aaa>
</div>
<template id="aaa">
<div class = "aaa">
<slot name = "s1"></slot>
<p>我是aaa組件</p>
<slot name = "s2"></slot>
</div>
</template>
 slot插槽讓咱們在原有模版的基礎上,定製更加多樣化的組件。 #### 做用域插槽 當咱們想在父組件中訪問子組件內部的一些數據時,就須要在子組件內部的<slot>元素上動態綁定一個自定義屬性,將數據傳遞到自定義屬性上,經過slot傳遞給父組件使用。
<slot :teacher="teacher"></slot>
綁定到<slot>元素上的屬性咱們稱之爲slot props。如今,在父組件中咱們能夠經過slot-scope給包含全部插槽 prop 的對象命名爲prop,以後就能夠經過prop來使用子組件中的數據了。
<template slot-scope="prop">
老師姓名:{{prop.teacher.name}} 老師年齡:{{prop.teacher.age}}
</template>
 #### v-slot > `v-slot` 指令自 Vue 2.6.0 起被引入,提供更好的支持 `slot` 和 `slot-scope` 特性的 API 替代方案。在接下來全部的 2.x 版本中`slot` 和 `slot-scope` 特性仍會被支持,但已經被官方廢棄,且不會出如今 Vue 3 中。 如今咱們使用 `v-slot` 重構上面的代碼:
<template v-slot:default="prop">
老師姓名:{{prop.teacher.name}} 老師年齡:{{prop.teacher.age}}
</template>
一個不帶 `name` 的 `<slot>` 出口會帶有隱含的名字「default」,使用時能夠簡化爲`v-slot="prop「`。 **具名槽口** 子組件中經過name屬性給槽口設定名稱
<slot name="student" :student='student'></slot>
父組件中經過`v-slot:名稱`的方式來使用具名槽口
<template v-slot:student="prop">
學生姓名:{{prop.student.name}} 學生年齡:{{prop.student.age}}
</template>
當咱們在父組件中屢次調用子組件時,能夠經過設置不一樣的樣式,來設定子組件中數據的展現形式。
### 主流js框架對比
#### Vue和React的區別
(1)react銷燬組件的時候,會將組件的dom結構也移除,vue則否則,在調用destory方法銷燬組件的時候,組件的dom結構仍是存在於頁面中的,this.$destory組件結構仍是存在的,只是移除了事件監聽。
(2)react中沒有指令
(3)在vue中,data屬性是利用object.defineProperty處理過的,更改data的數據的時候會觸發數據的getter和setter,可是react中沒有作這樣的處理,若是直接更改的話,react是沒法得知的。
**react更改狀態**:在setState中,傳入一個對象,就會將組件的狀態中鍵值對的部分更改,還能夠傳入一個函數,這個回調函數必須向上面方式同樣的一個對象函數能夠接受prevState和props。
(4)react中屬性是不容許更改的,狀態是容許更改的。react中組件不容許經過this.state這種方式直接更改組件的狀態。自身設置的狀態,能夠經過setState來進行更改。
拓展:對比其餘框架(Vue官網給出的詳細解釋)
https://vue.docschina.org/v2/guide/comparison.html
#### Vue和JQuery的區別
jQuery是使用選擇器($)選取DOM對象,對其進行賦值、取值、事件綁定等操做,其實和原生的HTML的區別只在於能夠更方便的選取和操做DOM對象,而數據和界面是在一塊兒的。
好比須要獲取label標籤的內容:`$("lable").val();`,它仍是依賴DOM元素的值。
Vue則是經過Vue對象將數據和View徹底分離開來了。對數據進行操做再也不須要引用相應的DOM對象,能夠說數據和View是分離的,他們經過Vue對象這個vm實現相互的綁定。這就是傳說中的MVVM。
- vue適用的場景:複雜數據操做的後臺頁面,表單填寫頁面
- jquery適用的場景:好比說一些html5的動畫頁面,一些須要js來操做頁面樣式的頁面
然而兩者也是能夠結合起來一塊兒使用的,vue側重數據綁定,jquery側重樣式操做,動畫效果等,則會更加高效率的完成業務需求
參考:jquery和vue對比
https://www.cnblogs.com/MR-YY/p/6898464.html
#### react與vue之間的相同點和不一樣點?
**相同點:**
1.都支持ssr服務器端渲染,vue:nuxt;react:next。
2.都有Virtual DOM,組件化開發,經過props參數進行父子組件數據的傳遞,都實現組件之間的模塊化webComponent規範。
3.數據驅動視圖,數據改變視圖發生更改。
4.都有支持native的方案,React的React native,Vue的weex(終端的原生端端解決方案)
5.都有管理狀態集工具,React有redux,Vue有本身的Vuex(自適應vue,量身定作)
**不一樣點:**
1. React嚴格上只針對MVC的view層(用戶界面的javascript庫),Vue則是MVVM模式。
2. virtual DOM不同:vue會跟蹤每個組件的依賴關係,不須要從新渲染整個組件樹。而對於React而言,每當應用的狀態被改變時,所有組件都會從新渲染,因此react中會須要shouldComponentUpdate這個生命週期函數方法來進行控制。
3. 組件寫法不同:React推薦的作法是 JSX + inline style, 也就是把HTML和CSS全都寫進JavaScript了,即'all in js';Vue推薦的作法是webpack+vue-loader的單文件組件格式,即html,css,js寫在同一個文件;
4. 數據綁定: vue實現了數據的雙向綁定,react沒有實現。
5. state對象在react應用中不可變的,須要使用setState方法更新狀態;在vue中,state對象不是必須的,數據由data屬性在vue對象中管理。
## React—用於構建用戶界面的 JavaScript 庫
### 組件
#### 建立組件的方式
一、無狀態函數式組件
建立純展現組件,只負責根據傳入的`props`來展現,不涉及到要`state`狀態的操做,是一個只帶有一個`render`方法的組件類。
二、組件是經過**React.createClass**建立的(ES5)
三、React.Component
在es6中直接經過class關鍵字來建立
組件其實就是一個構造器,每次使用組件都至關於在實例化組件
react的組件必須使用render函數來建立組件的虛擬dom結構
組件須要使用ReactDOM.render方法將其掛載在某一個節點上
組件的首字母必須大寫
`React.Component`是以ES6的形式來建立`react`的組件的,是React目前極爲推薦的建立有狀態組件的方式,相對於 `React.createClass`能夠更好實現代碼複用。將上面`React.createClass`的形式改成`React.Component`形式以下:
class Greeting extends React.Component{
constructor (props) {
super(props);
this.state={
work_list: []
}
this.Enter=this.Enter.bind(this); //綁定this
}
render() {
return (
<div>
<input type="text" ref="myWork" placeholder="What need to be done?" onKeyUp={this.Enter}/>
<ul>
{
this.state.work_list.map(function (textValue) {
return <li key={textValue}>{textValue}</li>;
})
}
</ul>
</div>
);
}
Enter(event) {
var works = this.state.work_list;
var work = this.refs.myWork.value;
if (event.keyCode == 13) {
works.push(work);
this.setState({work_list: works});
this.refs.myWork.value = "";
}
}
}
##### 關於this `React.createClass`建立的組件,其每個成員函數的`this`都有`React`自動綁定,任什麼時候候使用,直接使用`this.method`便可,函數中的`this`會被正確設置 `React.Component`建立的組件,其成員函數不會自動綁定`this`,須要手動綁定,不然`this`不能獲取當前組件實例對象 ##### React.Component三種手動綁定this的方法 1.在構造函數中綁定
constructor(props) {
super(props); this.Enter = this.Enter.bind(this);
}
2.使用bind綁定
<div onKeyUp={this.Enter.bind(this)}></div>
3.使用arrow function綁定
<div onKeyUp={(event)=>this.Enter(event)}></div>
#### 咱們在實際應用中應該選擇哪一種方法來建立組件呢? - 只要有可能,儘可能使用無狀態組件建立形式 - 不然(如須要state、生命週期方法等),使用`React.Component`這種es6形式建立組件 無狀態組件與有狀態的組件的區別爲? 沒有狀態,沒有生命週期,只是簡單的接受 props 渲染生成 DOM 結構 無狀態組件很是簡單,開銷很低,若是可能的話儘可能使用無狀態組件。 無狀態的函數建立的組件是無狀態組件,它是一種只負責展現的純組件 無狀態組件能夠使用純函數來實現。
const Slide = (props)=>{return (<div>.....</div>)}這就是無狀態組件(函數方式定義組件) 能夠簡寫爲 const Slide = props =>(<div>......</div>)
#### React父子組件通訊 (1)this.props (2)ref鏈 (3)Redux ### 高階組件 #### 高階組件是什麼?如何理解? 什麼是高級組件?首先你得先了解請求ES6中的class只是語法糖,本質仍是原型繼承。可以更好的進行說明,咱們將不會修改組件的代碼。而是經過提供一些可以包裹組件的組件, 並經過一些額外的功能來加強組件。這樣的組件咱們稱之爲高階組件(Higher-Order Component)。 高階組件(HOC)是React中對組件邏輯進行重用的高級技術。但高階組件自己並非React API。它只是一種模式,這種模式是由React自身的組合性質必然產生的。 說到高階組件,就先得說到高階函數了,高階函數是至少知足下列條件的函數: 一、接受一個或多個函數做爲輸入 二、輸出一個函數 #### 高階組件定義 類比高階函數的定義,高階組件就是接受一個組件做爲參數,在函數中對組件作一系列的處理,隨後返回一個新的組件做爲返回值。 #### 高階組件的缺點 高階組件也有一系列的缺點,首先是被包裹組件的靜態方法會消失,這其實也是很好理解的,咱們將組件當作參數傳入函數中,返回的已經不是原來的組件,而是一個新的組件,原來的靜態方法天然就不存在了。若是須要保留,咱們能夠手動將原組件的方法拷貝給新的組件,或者使用hoist-non-react-statics之類的庫來進行拷貝。 參考:淺談React高階組件 https://www.jb51.net/article/137272.htm #### 使用過哪些高階組件 1. withRouter高階組件,能夠根據傳入的組件生成一個新的組件,而且爲新組件添加上router相關的api。 2. connect 用於鏈接容器組件與UI組件,connect(mapStateToProps,mapDispatchToProps)(ui組件),當狀態改變的時候,容器組件內部由於經過store.subscribe能夠監聽狀態的改變,給ui組件傳入新的屬性,返回容器組件(智能組件),這個函數返回什麼,ui組件props上就會掛載什麼,ui組件的屬性上就就會有改變狀態的方法了,用的話經過this.props.方法名。 ### 虛擬dom ####React高性能的體現:虛擬DOM 在Web開發中咱們總須要將變化的數據實時反應到UI上,這時就須要對DOM進行操做。而複雜或頻繁的DOM操做一般是性能瓶頸產生的緣由(如何進行高性能的複雜DOM操做一般是衡量一個前端開發人員技能的重要指標)。 React爲此引入了虛擬DOM(Virtual DOM)的機制:在瀏覽器端用Javascript實現了一套DOM API。基於React進行開發時全部的DOM構造都是經過虛擬DOM進行,每當數據變化時,React都會從新構建整個DOM樹,而後React將當前整個DOM樹和上一次的DOM樹進行對比,獲得DOM結構的區別,而後僅僅將須要變化的部分進行實際的瀏覽器DOM更新。並且React可以批處理虛擬DOM的刷新,在一個事件循環(Event Loop)內的兩次數據變化會被合併,例如你連續的先將節點內容從A-B,B-A,React會認爲A變成B,而後又從B變成A UI不發生任何變化,而若是經過手動控制,這種邏輯一般是極其複雜的。 儘管每一次都須要構造完整的虛擬DOM樹,可是由於虛擬DOM是內存數據,性能是極高的,部而對實際DOM進行操做的僅僅是Diff分,於是能達到提升性能的目的。這樣,在保證性能的同時,開發者將再也不須要關注某個數據的變化如何更新到一個或多個具體的DOM元素,而只須要關心在任意一個數據狀態下,整個界面是如何Render的。 #### 爲何虛擬dom會提高代碼性能? 虛擬DOM就是JavaScript對象,就是在沒有真實渲染DOM以前作的操做。 真實dom的比對變成了虛擬dom的比對(js對象的比對) 虛擬dom裏面比對,涉及到diff算法。 key值 (key值相同dom能夠直接進行復用) #### react的diff算法實現流程 1.DOM結構發生改變-----直接卸載並從新create 2.DOM結構同樣-----不會卸載,可是會update變化的內容 3.全部同一層級的子節點.他們均可以經過key來區分-----同時遵循1.2兩點 (其實這個key的存在與否只會影響diff算法的複雜度,換言之,你不加key的狀況下,diff算法就會以暴力的方式去根據一二的策略更新,可是你加了key,diff算法會引入一些另外的操做) React會逐個對節點進行更新,轉換到目標節點。而最後插入新的節點,涉及到的DOM操做很是多。diff總共就是移動、刪除、增長三個操做,而若是給每一個節點惟一的標識(key),那麼React優先採用移動的方式,可以找到正確的位置去插入新的節點 #### diff算法和fiber算法的區別 diff算法是同步進行更新和比較,必須同步執行完一個操做再進行下一個操做,所耗時間比較長,JavaScript是單線程的,一旦組件開始更新,主線程就一直被React控制,這個時候若是再次執行交互操做,就會卡頓。 React Fiber重構這種方式,渲染過程採用切片的方式,每執行一下子,就歇一下子。若是有優先級更高的任務到來之後呢,就會先去執行,下降頁面發生卡頓的可能性,使得React對動畫等實時性要求較高的場景體驗更好。 #### 如何理解React中key? keys是什麼幫助 React 跟蹤哪些項目已更改、添加或從列表中刪除。 每一個 keys 在兄弟元素之間是獨一無二的。 keys 使處理列表時更加高效,由於 React 能夠使用子元素上的 keys 快速知道元素是新的仍是在比較樹時才被移動。 keys 不只使這個過程更有效率,並且沒有 keys ,React 不知道哪一個本地狀態對應於移動中的哪一個項目。
例如:數組循環出來三項,每一項前面有一個多選框,假設第一個多選框勾選了,而後我再動態添加新的元素,會發現新添加的元素就會被勾選了,這就是個問題!設置key值,這樣的話就能夠解決了。
####JSX 語法 在vue中,咱們使用render函數來構建組件的dom結構性能較高,由於省去了查找和編譯模板的過程,可是在render中利用createElement建立結構的時候代碼可讀性較低,較爲複雜,此時能夠利用jsx語法來在render中建立dom,解決這個問題,可是前提是須要使用工具來編譯jsx JSX是一種語法,全稱:javascript xml JSX語法不是必須使用的,可是由於使用了JSX語法以後會下降咱們的開發難度,故而這樣的語法又被成爲語法糖。 react.js中有React對象,幫助咱們建立組件等功能 HTML 中全部的信息咱們均可以用 JavaScript 對象來表示,可是用 JavaScript 寫起來太長了,結構看起來又不清晰,用 XML的方式寫起來就方便不少了。 因而 React.js 就把 JavaScript 的語法擴展了一下,**讓 JavaScript 語言可以支持這種直接在 JavaScript 代碼裏面編寫相似 XML 標籤結構的語法,這樣寫起來就方便不少了**。**編譯的過程會把相似 XML 的 JSX 結構轉換成 JavaScript 的對象結構**。 在不使用JSX的時候,須要使用React.createElement來建立組件的dom結構,可是這樣的寫法雖然不須要編譯,可是維護和開發的難度很高,且可讀性不好。 所謂的 JSX 其實就是 JavaScript 對象,因此使用 React 和 JSX 的時候必定要通過編譯的過程: > JSX代碼 — > 使用react構造組件,bable進行編譯—> JavaScript對象 — `ReactDOM.render()函數進行渲染`—>真實DOM元素 —>插入頁面 另: - JSX就是在js中使用的xml,可是,這裏的xml不是真正的xml,只能借鑑了一些xml的語法,例如: 最外層必須有根節點、標籤必須閉合 - jsx借鑑xml的語法而不是html的語法緣由:xml要比html嚴謹,編譯更方便 #### webpack中,是藉助loader完成的jsx代碼的轉化,仍是babel? 在vue中,藉助webpack提供的vue-loader來幫助咱們作一些轉化,讓vue代碼能夠在瀏覽器中執行。 react中沒有react-loader來進行代碼的轉化,而是採用babel裏面babel-preset-react來實現的。 #### 調用setState以後,發生了什麼?
constructor(props){
super(props);
this.state = {
age:1
}
}
經過調用this.setState去更新this.state,不能直接操做this.state,請把它當成不可變的。 調用setState更新this.state,他不是立刻就會生效的,他是異步的。因此不要認爲調用完setState後能夠立馬獲取到最新的值。 多個順序執行的setState不是同步的一個接着一個的執行,會加入一個異步隊列,而後最後一塊兒執行,即批處理。 setState是異步的,致使獲取dom可能拿的仍是以前的內容,因此咱們須要在setState第二個參數(回調函數)中獲取更新後的新的內容。
this.setState((prevState)=>({
age:++prevState.age
}),()=>{
console.log(this.state.age) //獲取更新後的最新的值
});
#### React實現異步請求 redux中間件 一般狀況下,action只是一個對象,不能包含異步操做 redux-thunk中間件 redux-thunk原理: -能夠接受一個返回函數的actionCreators,若是這個actionCreators返回的是一個函數,就執行它,若是不是,就按照原來的next(action)執行 -若是不安裝redux-thunk中間件,actionCreators只能返回一個對象 -安裝了redux-thunk中間件以後,actionCreators能夠返回一個函數了,在這個函數裏面能夠寫異步操做的代碼 -redux中間件,建立出來的action在到達reducer之間,加強了dispatch的派發功能 ####refs的做用業務場景? 經過ref對dom、組件進行標記,在組件內部經過this.refs獲取到以後,進行操做
<ul ref='content'><li>國內新聞</li></ul>
...
this.refs.content.style.display = this.state.isMenuShow?'block':'none'
ref用於給組件作標記,例如獲取圖片的寬度與高度。 非受控組件,input輸入框,獲取輸入框中的數據,能夠經過ref作標記。
<input ref={el=>this.input = el}/>
#### ref是一個函數,爲何? 避免組件之間數據相互被引用,形成內存泄漏
class Test extends React.Component{
componentDidMount(){
console.log(this.el);
}
render(){
//react在銷燬組件的時候會幫助咱們清空掉ref的相關引用,這樣能夠防止內存泄漏等一系列問題。
return <div ref={el=>this.el=el}></div>
}
}
#### 受控組件與非受控組件的區別 受控組件與非受控組件是相對於表單而言。 受控組件: 受到數據的控制。組件的變化依靠數據的變化,數據變化了,頁面也會跟着變化了。輸入框受到數據的控制,數據只要不變化,input框輸什麼都不行,一旦使用數據,從狀態中直接獲取。
<input value={this.state.value}/>
非受控組件: 直接操做dom,不作數據的綁定。經過refs來獲取dom上的內容進行相關的操做。
<input ref={el=>this.el=el}/> //不須要react組件作管理
*數據驅動是react核心。* #### 實現監聽滾動高度
class Test extends React.Component{
constructor(props){
super(props);
this.handleWidowScroll = this.handleWidowScroll.bind(this);
}
handleWidowScroll(){
this.setState({
top:document.body.scrollTop
})
}
componentDidMount(){//綁定監聽事件
window.addEventListener("scroll",this.handleWindowScroll);
}
componentWillUnmount(){//移除監聽事件
window.removeEventListener("scroll",this.handleWindowScroll);
}
}
####React中data爲何返回一個函數 爲了防止組件與組件之間的數據共享,讓做用域獨立,data是函數內部返回一個對象,讓每一個組件或者實例能夠維護一份被返回對象的獨立的拷貝。 ### 路由 #### react-router4的核心思想是什麼? 路由也變成組件了,因此它是很是靈活的(NavLink Route)。 vue中的路由須要單獨的配置 vue-router。 #### react-router的兩種模式是什麼? hashHistory # 不須要後端服務器的配置 browserHistory / 須要後端服務器的配置 (後端人員不清楚路由重定向等相關的概念) #### hash路由的實現原理 經過onhashchange事件監聽路由的改變,一旦路由改變,這個事件就會被執行,就能夠拿到更改後的哈希值,經過更改後的哈希值就可讓咱們的頁面進行一個關聯,一旦路由發生改變了,整個頁面狀態就會發生改變,可是整個頁面是沒有發生任何http請求的,整個頁面處於一種無刷新狀態。 - hash模式背後的原理是`onhashchange`事件,能夠在`window`對象上監聽這個事件:
window.onhashchange = function(event) {
console.log(event.oldURL, event.newURL); let hash = loaction.hash //經過location對象來獲取hash地址 console.log(hash) // "#/notebooks/260827/list" 從#號開始
}
由於hash發生變化的url都會被瀏覽器記錄下來,從而你會發現瀏覽器的前進後退均可以用 ,這樣一來,儘管瀏覽器沒有請求服務器,可是頁面狀態和url一一關聯起來,後來人們給它起了一個霸氣的名字叫**前端路由**,成爲了單頁應用標配。 *spa單頁應用:根據頁面地址的不一樣來實現組件之間的切換,整個頁面處於一種無刷新狀態。* #### history路由 隨着history api的到來,前端路由開始進化了,前面的**hashchange,你只能改變#後面的url片斷,而history api則給了前端徹底的自由** history api能夠分爲兩大部分:切換和修改 【切換路由/修改路由】 (1)切換歷史狀態 包括括` back、forward`、`go`三個方法,對應瀏覽器的前進,後退,跳轉操做
history.go(-2);//後退兩次
history.go(2);//前進兩次
history.back(); //後退
hsitory.forward(); //前進
(2)修改歷史狀態 包括 了`pushState、replaceState`兩個方法,這兩個方法接收三個參數:stateObj,title,url。 #### 兩種模式的區別是什麼? 在hash模式下,前端路由修改的是#中的信息,而瀏覽器請求時是不帶它玩的,因此沒有問題。可是在history下,你能夠自由的修改path,當刷新時,若是服務器中沒有相應的響應或者資源,會分分鐘刷出一個404來,須要後端人員去作一個配置。 ### 生命週期 #### react的生命週期函數 【初始化階段】: (1)getDefaultProps:實例化組件以後,組件的getDefaultProps鉤子函數會執行 這個鉤子函數的目的是爲組件的實例掛載默認的屬性 這個鉤子函數只會執行一次,也就是說,只在第一次實例化的時候執行,建立出全部實例共享的默認屬性,後面再實例化的時候,不會執行getDefaultProps,直接使用已有的共享的默認屬性 理論上來講,寫成函數返回對象的方式,是爲了防止實例共享,可是react專門爲了讓實例共享,只能讓這個函數只執行一次 組件間共享默認屬性會減小內存空間的浪費,並且也不須要擔憂某一個實例更改屬性後其餘的實例也會更改的問題,由於組件不能本身更改屬性,並且默認屬性的優先級低。 (2)getInitialState:爲實例掛載初始狀態,且每次實例化都會執行,也就是說,每個組件實例都擁有本身獨立的狀態。 (3)componentWillMount:執行componentWillMount,至關於Vue裏的created+beforeMount,這裏是在渲染以前最後一次更改數據的機會,在這裏更改的話是不會觸發render的從新執行。 (4)**render**:渲染dom `render()`方法必須是一個純函數,他不該該改變`state`,也不能直接和瀏覽器進行交互,應該將事件放在其餘生命週期函數中。 若是`shouldComponentUpdate()`返回`false`,`render()`不會被調用。 (5)componentDidMount:至關於Vue裏的mounted,多用於操做真實dom 【運行中階段】 當組件mount到頁面中以後,就進入了運行中階段,在這裏有5個鉤子函數,可是這5個函數只有在數據(屬性、狀態)發送改變的時候纔會執行 (1)componentWillReceiveProps(nextProps,nextState) 當父組件給子組件傳入的屬性改變的時候,子組件的這個函數纔會執行。初始化props時候不會主動執行 當執行的時候,函數接收的參數是子組件接收到的新參數,這個時候,新參數尚未同步到this.props上,多用於判斷新屬性和原有屬性的變化後更改組件的狀態。 (2)接下來就會執行shouldComponentUpdate(nextProps,nextState),這個函數的做用:當屬性或狀態發生改變後控制組件是否要更新,提升性能,返回true就更新,不然不更新,默認返回true。 接收nextProp、nextState,根據根據新屬性狀態和原屬性狀態做出對比、判斷後控制是否更新 若是`shouldComponentUpdate()`返回`false`,`componentWillUpdate`,`render`和`componentDidUpdate`不會被調用。 (3)componentWillUpdate,在這裏,組件立刻就要從新render了,多作一些準備工做,千萬千萬,不要在這裏修改狀態,不然會死循環 至關於Vue中的beforeUpdate (4)render,從新渲染dom (5)componentDidUpdate,在這裏,新的dom結構已經誕生了,至關於Vue裏的updated 【銷燬階段】 **當組件被銷燬以前的一剎那,會觸發componentWillUnmount,臨死前的掙扎** 至關於Vue裏的beforeDestroy,因此說通常會作一些善後的事情,例如使定時器無效,取消網絡請求或清理在`componentDidMount`中建立的任何監聽。  #### 爲何Vue中有destroyed,而react卻沒有componentDidUnmount Vue在調用$destroy方法的時候就會執行beforeDestroy,而後組件被銷燬,這個時候組件的dom結構還存在於頁面結構中,也就說若是想要對殘留的dom結構進行處理必須在destroyed處理,可是react執行完componentWillUnmount以後把事件、數據、dom都所有處理掉了,因此根本不須要其餘的鉤子函數了 #### React中怎麼樣就算組件被銷燬: 1. 當父組件從渲染這個子組件變成不渲染這個子組件的時候,子組件至關於被銷燬 2. 調用ReactDOM.unmountComponentAtNode(node) 方法來將某節點中的組件銷燬 #### 哪一個生命週期裏面發送ajax? AJAX請求應該在componentDidMount生命週期事件中。 #### 如何避免ajax數據從新獲取? 將全部的數據存儲在redux中進行管理,既能夠解決該問題。 #### 爲何不把請求數據的操做寫在componentWillMount中而寫在componentDidMount中? (1)此鉤子函數在16版本中會被頻繁調用:15.X版本用的是diff算法,不會被頻繁調用,而React下一代調和算法Fiber會經過開始或中止渲染的方式優化應用性能,其會影響到comonentWillMount的觸發次數,對於componentWillMount這個生命週期的調用次數就會變得不肯定。React可能會屢次頻繁調用componentWillMount,若是咱們將ajax請求放到componentWillMount函數中,那麼顯而易見就會被觸發屢次,天然也就不是好的選擇。 (2)componentWillMount()將在React將來版本(官方說法 17.0)中被棄用。爲了不反作用和其餘的訂閱,官方都建議使用componentDidMount()代替。這個方法是用於在服務器渲染上的惟一方法。 #### componentWillReceiveProps調用時機? #### componentWillReceiveProps調用時機? 初始化父組件第一次將數據傳遞給子組件的時候不會去執行,只有屬性props改變的時候,子組件的鉤子函數纔會觸發執行。 #### 受控組件與非受控組件的區別 父組件能夠將本身的屬性傳遞給子組件,子組件經過this.props調用。 非受控組件;不會受到數據(state)的控制,由DOM自己進行管理,輸入框的內容發生改變了,直接經過ref進行標記,而後直接獲取使用便可。 ### Redux #### 你會把數據統一放入到redux中管理,仍是共享數據放在redux中管理? 把全部的數據放入到redux中管理。(props,state) 項目一旦有問題,能夠直接定位問題點。 組件擴展的時候,後續涉及到傳遞的問題。原本的話,本身使用數據,可是後來公用,還須要考慮如何傳遞。 redux中存儲數據能夠存儲至少5G以上的數據。 目的就是方便數據統一,好管理。 #### React鏈接Redux用到什麼? react-redux輔助工具 核心組件:Provider提供者,屬性上經過store將數據派給容器組件,connect用於鏈接容器組件與UI組件。 引入provider,哪一個地方須要用到狀態和屬性,就包裹一下,而且一旦有狀態改變,就會監聽到,而且將最新的狀態返回給UI組件。
ReactDOM.render(
<Provider store = {store}>
<Router>
<App />
</Router>
</Provider>, document.getElementById('root'));
connect()(UI組件) ==》返回一個容器組件 這個方法參數是state=>store.getState() 這個方法返回什麼,UI組件的屬性上就是有什麼 當狀態改變的時候,容器組件就會監聽狀態的變化,而且把更新後的狀態經過屬性的方法傳遞給UI組件 由於容器組件已經幫助咱們實現了store.subscribe方法的訂閱,這時候就不須要constructor函數和監聽函數,容器組件就會自動訂閱狀態的變化,UI組件經過this.props來獲取函數中返回的state,這時候當咱們對state進行操做的時候,狀態就會改變,視圖從新渲染,componentWillReceiveProps這個鉤子函數就會執行,實現了對狀態改變的事實監聽。 connect中有兩個參數,一個是映射狀態到組件屬性(mapStateToProps),一個是映射方法到組件屬性(mapDispatchToProps),最終內部返回一個容器組件幫助咱們作監聽操做,一旦狀態更改,UI組件就會從新渲染。 connect(mapStateToProps,mapDispatchToProps)(ui組件) 容器組件內部幫你作了 store.subscribe() 狀態變化 ==> 容器組件監聽狀態改變了 ==> 經過屬性的方式給ui組件傳遞 把`store.getState()`的狀態轉化爲展現組件的`props` 當咱們須要掛載不少方法的時候咱們能夠將之簡寫 首先咱們引入bindActionCreators
import {bindActionCreators} from "redux"
而後咱們使用bindActionCreators將全部操做狀態的方法所有取出來綁定到UI組件的屬性上,使用的時候直接經過this.props取便可。
//actionCreators很純粹了,須要建立action而後返回action便可!
//ui組件的屬性上就就會有改變狀態的方法了,用的話經過this.props.方法名
const mapDispatchToProps = dispatch=>{
return bindActionCreators(actionsCreators,dispatch)
}
connect(mapStateToProps,mapDispatchToProps)(UI組件)
#### Redux的組成 redux有四個組成部分: store:用來存儲數據 reducer:真正的來管理數據 actionCreator:建立action,交由reducer處理 view: 用來使用數據,在這裏,通常用react組件來充當  #### 何時用redux? 若是你不知道是否須要 Redux,那就是不須要它 只有遇到 React 實在解決不了的問題,你才須要 Redux 簡單說,若是你的UI層很是簡單,沒有不少互動,Redux 就是沒必要要的,用了反而增長複雜性。 - 用戶的使用方式很是簡單 - 用戶之間沒有協做 - 不須要與服務器大量交互,也沒有使用 WebSocket - 視圖層(View)只從單一來源獲取數據 **須要使用redux的項目**: - 用戶的使用方式複雜 - 不一樣身份的用戶有不一樣的使用方式(好比普通用戶和管理員) - 多個用戶之間能夠協做 - 與服務器大量交互,或者使用了WebSocket - View要從多個來源獲取數據 從組件層面考慮,什麼樣子的須要redux: - 某個組件的狀態,須要共享 - 某個狀態須要在任何地方均可以拿到 - 一個組件須要改變全局狀態 - 一個組件須要改變另外一個組件的狀態 redux的設計思想: 1. Web 應用是一個狀態機,視圖與狀態是一一對應的。 2. 全部的狀態,保存在一個對象裏面(惟一數據源)。 #### Redux的流程 Redux的流程: 1. 建立store: 從redux工具中取出createStore去生成一個store。 2. 建立一個reducer,而後將其傳入到createStore中輔助store的建立。 reducer是一個純函數,接收當前狀態和action,返回一個狀態,返回什麼,store的狀態就是什麼,須要注意的是,不能直接操做當前狀態,而是須要返回一個新的狀態。 想要給store建立默認狀態其實就是給reducer一個參數建立默認值。 3. 組件經過調用store.getState方法來使用store中的state,掛載在了本身的狀態上。 4. 組件產生用戶操做,調用actionCreator的方法建立一個action,利用store.dispatch方法傳遞給reducer 5. reducer對action上的標示性信息作出判斷後對新狀態進行處理,而後返回新狀態,這個時候store的數據就會發生改變, reducer返回什麼狀態,store.getState就能夠獲取什麼狀態。 6. 咱們能夠在組件中,利用store.subscribe方法去訂閱數據的變化,也就是能夠傳入一個函數,當數據變化的時候,傳入的函數會執行,在這個函數中讓組件去獲取最新的狀態。 #### reducer是一個純函數?你對純函數是怎麼理解的? reducer是state最終格式的肯定。它是一個純函數,也就是說,只要傳入參數相同,返回計算獲得的下一個 state 就必定相同。沒有特殊狀況、沒有反作用,沒有 API 請求、沒有變量修改,單純執行計算。 reducer對傳入的action進行判斷,而後返回一個經過判斷後的state,這就是reducer的所有職責 **Reducer 函數最重要的特徵是,它是一個純函數。也就是說,只要是一樣的輸入,一定獲得一樣的輸出。** 純函數是函數式編程的概念,必須遵照如下一些約束。 **不得改寫參數** **不能調用系統 I/O 的API** **不能調用Date.now()或者Math.random()等不純的方法,由於每次會獲得不同的結果** (1)只要是一樣的輸入,一定獲得一個一樣的輸出。 (2)千萬不能更改以前的狀態,必需要返回一個新狀態 (3)裏面不能有不純的操做,例如Math.random(),new Date(),io操做 #### redux中間件的原理是什麼?如何理解? 一般狀況下,action只是一個對象,不能包含異步操做,這致使了不少建立action的邏輯只能寫在組件中,代碼量較多也不便於複用,同時對該部分代碼測試的時候也比較困難,組件的業務邏輯也不清晰,使用中間件了以後,能夠經過actionCreator異步編寫action,這樣代碼就會拆分到actionCreator中,可維護性大大提升,能夠方便於測試、複用,同時actionCreator還集成了異步操做中不一樣的action派發機制,減小編碼過程當中的代碼量。 redux中間件就是指action到達store之間。store.dispatch(action)方法將action派發給了store 而且咱們的action只能是一個對象,需求的時候,就須要考慮到一些異步邏輯放在哪裏去實現? 採用中間件以後,action就能夠是一個函數的形式了,而且會把函數式的action轉成對象,在傳遞給store. **dispatch一個action以後,到達reducer以前,進行一些額外的操做,就須要用到middleware**。你能夠利用 Redux middleware 來進行日誌記錄、建立崩潰報告、調用異步接口或者路由等等。 **換言之,redux的中間件都是對store.dispatch()的加強** #### redux有哪些中間件? **作異步的操做在action裏面去實現!須要安裝redux中間件** redux-thunk redux-saga (基於配置文件 es7 async await) redux-promise #### redux-thunk原理 Redux-thunk是一個Redux中間件,位於 Action與 Strore中間,簡單的說,他就是對store.dispatch進行了一次升級,他經過改造store.dispatch,能夠使得store.dispatch能夠接受函數做爲參數。 能夠看出來redux-thunk最重要的思想,就是能夠接受一個返回函數的action creator。若是這個action creator 返回的是一個函數,就執行它,若是不是,就按照原來的next(action)執行。 正由於這個action creator能夠返回一個函數,那麼就能夠在這個函數中執行一些異步的操做。 ### React項目相關 #### 項目中遇到哪些問題?如何解決? **用於輪播圖組件的遠程數據已經請求回來了,而且也已經實例化完畢了。發現navbar能滑,可是滑不過去的現象** 緣由:由於咱們在ComponentDidMount中請求數據,這個操做是異步操做,不會阻止後續代碼,因此咱們一邊執行請求數據的代碼一邊實例化,數據還在請求中的時候,實例化已經開始執行,等數據回來的時候實例化已經早就結束了。 方法一:放入在**componentDidUpdate**鉤子函數裏面 問題:當頁面中的無關數據改變的時候一樣會走這個鉤子函數,那就會致使它從新執行。 因此咱們給Swiper的實例化起一個別名 在componentDidUpdate這個函數中if語句判斷它是否存在,若是不存在再去實例化,存在的話就不須要再去執行實例化操做。
//在這個鉤子函數裏面 就能夠獲取到因數據改變致使的虛擬dom從新渲染完成的真實dom結構了
componentDidUpdate(){
if(!this.swiper)this.initSwiper() //數據可能還在請求當中,可是這個實例化操做已經完畢了。等後續數據來了,實例化提早早就結束了。
}
方法二:會發現上面的方案會多寫一個鉤子函數,可不能夠在componentDidmount裏面實現此功能呢? 將實例化操做寫在獲取數據的回調函數裏
componentDidMount(){
//請求數據 更改navs
this.props.getNavs(()=>{
this.initSwiper()
})
}
在store/home/actionCreators文件中讓getNavs接收這個回調函數,在數據請求結束後執行callback回調函數。
import {Get} from "../../modules/axios-utils"
import {GET_NAV_INFO} from "./const"
export default {
getNavs(callback){
return dispatch=>{
Get({
url:"/sk/navs"
}).then(res=>{
let navs = res.data.data.object_list
dispatch({ type: GET_NAV_INFO,navs})
callback && callback()
})
}
}
}
咱們跳轉頁面的時候它會屢次請求數據,因此咱們須要在componentDidMount這個鉤子函數中判斷redux裏面navs是否存在,存在就不須要再發送請求了,這時候從別的頁面再跳轉回首頁就不會重複請求數據,可是數據劃不動,因此咱們須要在函數中再次執行Swiper初始化操做。
let {navs} = this.props;
if(navs){
this.initSwiper()
return false;
}
#### reducer中的深拷貝與淺拷貝 咱們進行改變狀態操做時,componentWillReceiveProps()這個函數沒有被觸發,說明視圖沒有檢測到狀態的改變。這時候咱們來到reducer.js這個文件中,查看執行添加操做的函數,咱們經過
let new_state = {...prevState}
這句代碼將prevState解構出來賦值給new_stat,,咱們往new_state中的todos數組push一個新內容,並無返回新的狀態,那是由於當咱們對new_state這個數組進行操做的時候,會影響到以前的prevState中的todos,由於todos是個引用類型,它和new_state中的todos指向同一塊內存空間,因此當咱們執行push操做的時候至關於更改了以前的狀態。在redux中規定,千萬不能對以前的狀態進行任何操做,必需要返回一個新狀態,內部以此爲依據來判斷到底有沒有新的狀態產生,根據以前狀態與新狀態的地址比較,更改以後的地址跟以前的地址是同一個的話,就說明沒有產生新狀態。因此即使咱們操做的是new_state中的todos,實際上咱們更改的也是prevState中的todos,因此不會有新的狀態產生。 因此咱們要使用深拷貝,拷貝出來一份同樣的數組,而且這個新數組的引用地址和以前的引用地址徹底不一樣。
ew_state.todos = new_state.todos.slice();
#### 深拷貝淺拷貝有什麼區別? **1. 淺拷貝: 將原對象或原數組的引用直接賦給新對象,新數組,新對象/數組只是原對象的一個引用。** **2. 深拷貝: 建立一個新的對象和數組,將原對象的各項屬性的「值」(數組的全部元素)拷貝過來,是「值」而不是「引用」** #### react,jquey,vue是否能夠共存在一個項目中? 能夠存在,互不干擾。
<div></div>
<div id="react"></div>
<div id="vue"></div>
ReactDOM.render(<App/>,document.getElementById("react"));
new Vue({el:"#vue",router,store});
## 服務端渲染SSR
#### 什麼是服務端渲染? 核心在於方便seo優化
後端先調用數據庫,得到數據以後,將數據和頁面元素進行拼裝,組合成完整的html頁面,再直接返回給瀏覽器,以便用戶瀏覽。 例如:[http://www.cnblogs.com/cate/design](http://www.cnblogs.com/cate/design)
#### 什麼是客戶端渲染? 分擔到客戶端
數據由瀏覽器經過ajax動態得到,再經過js將數據填充到dom元素上最終展現到網頁中,這樣的過程就叫作客戶端渲染。 例如:https://m.maizuo.com/v5/#/films/nowPlaying
#### 服務端渲染與客戶端渲染區別?
客戶端渲染不利於SEO搜索引擎優化
服務端渲染是能夠被爬蟲抓取到的,客戶端異步渲染是很難被爬蟲抓取到的
服務端渲染對SEO友好,通過服務端渲染的頁面,在網絡傳輸的時候,傳輸的是一個真實的頁面,因此爬蟲就會對這個頁面中的關鍵數據進行分析、收錄。
服務端渲染缺點就是 對服務器壓力比較大
客戶端渲染減輕了服務器端的渲染壓力,可以實現先後端分離開發
客戶端渲染缺點就是 對SEO至關的不友好
## 主流UI開發框架
#### 你都使用過哪些UI開發框架(類庫)?
VUE:Vant、Element、Mint UI、iView
React:Ant Design
移動端:Ant Design Mobile
PC端:Bootstrap、Ant Design
混合開發:MUI
#### 有沒有用一些腳手架的搭建?,腳手架有什麼做用?
Vue-cli create-react-app wepy-cli
包含基礎的依賴庫,只須要 npm install就能夠安裝,快速搭建項目。
#### Mint-UI用到哪些模塊,怎麼用,在vue裏怎麼註冊,引入
引入:
(1)完整引入
(2)按需引入

## 移動端
### 移動端開發
#### 編寫移動端時的四個步驟
(1)添加mate聲明
在編輯器中輸入mate:vp按tab鍵
<meta charset="UTF-8"> <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
(2)寫移動端必須用怪異盒模型,box-sizing:border-box;
使用彈性盒佈局:display:flex;
(3)根據設計圖設置單位,rem相對於根元素。
**Iphone5:寬度640px;**
html:font-size:31.25vw;
31.25vw=100px=1rem;
**Iphone6:寬度750px;**
html:font-size:26.67vw;
26.675vw=100px=1rem;
(4)編寫一屏頁面:
html,body{height:100%;}
#### 移動設備單位
ppi/dpi (每英寸所擁有像素點的數量)
dpr > 設備像素比 (物理像素、邏輯像素)
邏輯像素就是css設置的像素
物理像素就是設備顯示的像素
dpr == 物理像素 / 邏輯像素
dpr 通常考慮的值 > 2或者3
若是移動端設計圖的寬度爲750/640 > 選擇的dpr爲2
若是移動端設計圖的寬度爲1080 > 選擇的dpr爲3
例:
若是設計圖爲640px
dpr爲2
若是從ps中量出元素寬度爲300px;
在css裏面設置的爲 300px / dpr(2) == 150px;
#### 頁面佈局有哪幾種方式
**固定佈局:**以像素做爲頁面的基本單位,無論設備屏幕及瀏覽器寬度,只設計一套尺寸;
**可切換的固定佈局:**一樣以像素做爲頁面單位,參考主流設備尺寸,設計幾套不一樣寬度的佈局。經過識別的屏幕尺寸或瀏覽器寬度,選擇最合適的那套寬度佈局;
**彈性佈局(百分比佈局):**以百分比做爲頁面的基本單位,能夠適應必定範圍內全部尺寸的設備屏幕及瀏覽器寬度,並能完美利用有效空間展示最佳效果;
**混合佈局:**同彈性佈局相似,能夠適應必定範圍內全部尺寸的設備屏幕及瀏覽器寬度,並能完美利用有效空間展示最佳效果;只是混合像素、和百分比兩種單位做爲頁面單位。
**佈局響應:**對頁面進行響應式的設計實現,須要對相同內容進行不一樣寬度的佈局設計,有兩種方式:pc優先(從pc端開始向下設計);
移動優先(從移動端向上設計);不管基於那種模式的設計,要兼容全部設備,佈局響應時不可避免地須要對模塊佈局作一些變化(發生佈局改變的臨界點稱之爲斷點)
####什麼是響應式設計?響應式設計的基本原理是什麼
響應式是指根據不一樣設備瀏覽器分辨率或尺寸來展現不一樣頁面結構、行爲、表現的設計方式。
響應式設計的基本原理是經過媒體查詢檢測不一樣的設備屏幕尺寸作處理。
####說說對於移動端頁面部局你都知道哪幾種佈局方案,並說明其各自特色及實現的方法
移動端佈局經常使用的有100%佈局,等比縮放佈局,或是混合佈局。
百分比佈局也稱做流式佈局,通常適用一些流式頁面的佈局;
等比縮放佈局能夠利用rem或vw等方式來實現;
### rem
#### rem和em的區別
rem(font size of the root element)是指相對於根元素 (html)的字體大小的單位
em是相對於父元素
#### rem方法的封裝
document.documentElement.style.fontSize = document.documentElement.clientWidth / 3.75 + "px"
window.onresize = function(){
document.documentElement.style.fontSize = document.documentElement.clientWidth / 3.75 + "px"
}
#### px和em的區別
px和em都是長度單位,區別是:px的值是固定的,指定是多少就是多少,計算比較容易。em得值不是固定的,而且em會繼承父級元素的字體大小。
瀏覽器的默認字體高都是16px。因此未經調整的瀏覽器都符合: 1em=16px。那麼12px=0.75em, 10px=0.625em。
### 彈性盒
####Flex彈性盒佈局
Flex容器:採用 Flex 佈局的元素的父元素;
Flex項目:採用 Flex 佈局的元素的父元素的子元素;
容器默認存在兩根軸:水平的主軸(main axis)和垂直的交叉軸(cross axis)。主軸的開始位置(與邊框的交叉點)叫作main start,結束位置叫作main end;交叉軸的開始位置叫作cross start,結束位置叫作cross end。
項目默認沿主軸排列。單個項目佔據的主軸空間叫作main size,佔據的交叉軸空間叫作cross size。
不兼容全部瀏覽器,不適合寫pc端,主要用於移動端。
彈性元素只能影響子元素,沒法影響全部的後代元素。
彈性佈局屬於css3只兼容高版本瀏覽器
#### Flex垂直居中
flex:彈性盒
justify-content 項目在主軸上的對齊方式
參數:center 居中/space-between 兩端對齊/space-around均分對齊
align-items 項目在交叉軸上的對齊方式
參數:center 居中
flex-direction 決定主軸的方向
row X軸/column Y軸
參考:Flex 佈局教程:語法篇
http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html
### 佈局方式
#### 媒體查詢如何實現?
媒體查詢 @media screen and (max-width:300px){ …} 最大寬度
#### Bootstrap12柵格系統
Row col col-md-4 col-md-4 col-md-4
在Bootstrap框架當中,每列基本被分爲12格,要使用柵格系統須要在該`<div>`標籤當中設置`class="container"`,而對於每一行則用`<div class="row">`包着,內部因爲有12格,所以能夠結合具體狀況分配比例,舉例:
<div class="container">
<!-- 定義柵格系統 -->
<div class="row">
<!-- 定義一行 -->
<div class="col-md-4">
<!-- 定義了三列,每列佔3格 -->
<img src="timg.jpg" width="300px">
</div>
<div class="col-md-4">
<img src="timg.jpg" width="300px">
</div>
<div class="col-md-4">
<img src="timg.jpg" width="300px">
</div>
</div>
<div class="row">
<!-- 定義了4列,分別佔六、三、二、1格 -->
<div class="col-md-6">
<img src="timg.jpg" width="300px">
</div>
<div class="col-md-3">
<img src="timg.jpg" width="300px">
</div>
<div class="col-md-2">
<img src="timg.jpg" width="300px">
</div>
<div class="col-md-1">
<img src="timg.jpg" width="300px">
</div>
</div>
</div>
#### Grid網格佈局 網格佈局(Grid)是最強大的 CSS 佈局方案。 它將網頁劃分紅一個個網格,能夠任意組合不一樣的網格,作出各類各樣的佈局。之前,只能經過複雜的 CSS 框架達到的效果,如今瀏覽器內置了。  參考:CSS Grid 網格佈局教程 http://www.ruanyifeng.com/blog/2019/03/grid-layout-tutorial.html 趨勢:flex和grid使佈局更簡單 https://www.cnblogs.com/hsprout/p/8277322.htm ## 混合開發&小程序 #### 混合開發模式 咱們知道混合開發的模式如今主要分爲兩種,H5工程師利用某些工具如DCLOUD產品、codorva+phonegap等等來開發一個外嵌native殼子的混合app。 還有就是應用比較普遍的,有native開發工程師和H5工程師一塊兒寫做開發的應用,在native的webview裏嵌入H5頁面,固然只是部分界面這麼作,這樣作的好處就是效率高,開發成本和維護成本都比較低,較爲輕量,可是有一個問題不可避免的會出現,就是js和native的交互。 #### 進入域後根據不一樣的狀況顯示不一樣的頁面(PC/MOBILE)
不少狀況下,一個應用會有PC和移動端兩個版本,而這兩個版本由於差異大,內容多,因此不能用響應式開發可是單獨開發,而域名只有一個,用戶進入域後直接返回對應設備的應用,作法主要有兩種:
- 前端判斷並跳轉
進入一個應用或者一個空白頁面後,經過navigator.userAgent來判斷用戶訪問的設備類型,進行跳轉 - 後端判斷並響應對應的應用
用戶地址欄進入域的時候,服務器能接收到請求頭上包含的userAgent信息,判斷以後返回對應
#### 小程序開發的形式 目前小程序開發主要有三種形式:原生、wepy、mpvue,其中wepy是騰訊的開源項目;mpvue是美團開源的一個開發小程序的框架,全稱mini program vue(基於vue.js的小程序),vue開發者使用了這個框架後,開發小程序的效率將獲得很大的提高。 #### wepy與mpvue如何選擇?  參考:使用mpvue開發微信小程序——原生微信小程序、mpvue、wepy對比 https://blog.csdn.net/fabulous1111/article/details/84289044 #### 微信小程序裏面各個部分是幹什麼的 這些文件能夠分爲四類,分別是以js、wxml、wxss和json結尾的文件。 以js結尾的文件,通常狀況下是負責功能的,好比,點擊一個按鈕,按鈕就會變顏色。 以wxml爲後綴的文件,通常狀況下負責佈局,好比,把按鈕放在屏幕的上方,仍是放在屏幕的正中間。 以wxss爲後綴的文件,是負責渲染的功能,好比,按鈕是什麼顏色,是正方形仍是圓形。 以json爲後綴的文件,這裏能夠暫時理解爲更改屏幕上方的標題的,也就是說明頁面的頂部標題。 參考:微信小程序裏面各個部分是幹什麼的 https://www.jianshu.com/p/3863f8b75336 ## 你常常瀏覽哪些技術網站 - 酷殼 - 掘金 - stackoverflow(國外) - 思否SegmentFault ## 前端開發的優化問題 ### 性能優化 #### 簡述一下你對web性能優化的方案? 一、儘可能減小 HTTP 請求 二、使用瀏覽器緩存 三、使用壓縮組件 四、圖片、JS的預載入 五、將腳本放在底部 六、將樣式文件放在頁面頂部 七、使用外部的JS和CS #### 如何優化項目 (1) 減小http請求次數:CSS Sprites(雪碧圖), JS、CSS源碼壓縮、圖片大小控制合適;網頁Gzip,CDN託管,data緩存 ,圖片服務器。 (2) 前端模板 JS+數據,減小因爲HTML標籤致使的帶寬浪費,前端用變量保存AJAX請求結果,每次操做本地變量,不用請求,減小請求次數 (3) 用innerHTML代替DOM操做,減小DOM操做次數,優化javascript性能。 (4) 當須要設置的樣式不少時設置className而不是直接操做style。 (5) 少用全局變量、緩存DOM節點查找的結果。減小IO讀取操做。 (6) 避免使用CSS Expression(css表達式)又稱Dynamic properties(動態屬性)。 (7) 圖片預加載,將樣式表放在頂部,將腳本放在底部 加上時間戳。 (8) 避免在頁面的主體佈局中使用table,table要等其中的內容徹底下載以後纔會顯示出來,顯示比div+css佈局慢。 #### 雅虎14條性能優化原則 | 1. 儘量的減小 HTTP 的請求數 | content | | --------------------------------------- | -------------- | | 2. 使用 CDN(Content Delivery Network) | server | | 3. 添加 Expires 頭(或者 Cache-control ) | server | | 4. Gzip 組件 | server | | 5. 將 CSS 樣式放在頁面的上方 | css | | 6. 將腳本移動到底部(包括內聯的) | javascript | | 7. 避免使用 CSS 中的 Expressions | css | | 8. 將 JavaScript 和 CSS 獨立成外部文件 | javascript css | | 9. 減小 DNS 查詢 | content | | 10. 壓縮 JavaScript 和 CSS (包括內聯的) | javascript css | | 11. 避免重定向 | server | | 12. 移除重複的腳本 | javascript | | 13. 配置實體標籤(ETags) | css | | 14. 使 AJAX 緩存 | | #### 你如何對網站的文件和資源進行優化? 1. 文件合併:目的是減小http請求 2. 文件壓縮:目的是直接減小文件下載的體積 3. 使用CDN(內容分發網絡來託管資源) 4. 緩存的使用:而且多個域名來提供緩存 5. GZIP壓縮JS和CSS文件 參考:你如何對網站的文件和資源進行優化? https://blog.csdn.net/xujie_0311/article/details/42418797 ### SEO優化 #### 一個單頁應用程序SEO友好嗎? 單頁應用實際是把視圖(View)渲染從Server交給瀏覽器,Server只提供JSON格式數據,視圖和內容都是經過本地JavaScript來組織和渲染。而搜索搜索引擎抓取的內容,須要有完整的HTML和內容,單頁應用架構的站點,並不能很好的支持搜索。 參考:單頁應用SEO淺談 http://www.chinaz.com/web/2014/1209/376090.shtml 一個單頁應用程序SEO友好嗎? https://baijiahao.baidu.com/s?id=1605476561507275196&wfr=spider&for=pc #### 網頁自身SEO優化(如何讓網站被搜索引擎搜索到) 1. 頁面主題優化 實事求是的寫下本身網站的名字,網站的名字要合理,最好包含網站的主要內容。 2. 頁面頭部優化 頁面頭部指的是代碼中部分,具體一點就是中的「Description(描述)」和「Keywords(關鍵字)」兩部分 3. 超連接優化 (1)採用純文本連接,少用,最好是別用Flash動畫設置連接,由於搜索引擎沒法識別Flash上的文字. (2)按規範書寫超連接,這個title屬性,它既能夠起到提示訪客的做用,也可讓搜索引擎知道它要去哪裏. (3)最好別使用圖片熱點連接,理由和第一點差很少。 4. 圖片優化(alt屬性,title屬性) 網絡爬蟲對title和alt友好,網絡優化時必須寫。 5. 爲網站製做一個「網站地圖」 6. PageRank(pr值,友情連接) 7. 靜態頁面與動態頁面 8. 避免大「體積」的頁面 9. 最重要的一點!合理的代碼結構 ### 框架性能優化 #### react性能優化 - 使用生產環境production版本的react.js - 重寫shouldComponentUpdate來避免沒必要要的dom操做,一旦返回true ,組件更新操做;返回false,就不會更新,節省性能。 - 使用key來幫助React識別列表中全部子組件的最小變化 - PureComponent 純組件 ,自帶shouldComponentUpdate,能夠對props進行淺比較,不會比較對象這些東西。 發現後面的props與前面的props同樣,就不會進行render了。
class Test extends React.PureComponent{ <div><Test a={10}/></div>
constructor(props){
super(props);
}
render(){
return <div>hello...{this.props.a}</div>
}
}
#### VUE性能優化 像VUE這種單頁面應用,若是沒有應用懶加載,運用webpack打包後的文件將會異常的大,形成進入首頁時,須要加載的內容過多,時間過長,會出現長時間的白屏,即便作了loading也是不利於用戶體驗,而運用懶加載則能夠將頁面進行劃分,須要的時候加載頁面,能夠有效的分擔首頁所承擔的加載壓力,減小首頁加載用時,簡單說就是:進入首頁不用一次加載過多資源形成的用時時長。
- 1. offer收割機-Web前端面試寶典【精編版-4】
- 2. web前端面試寶典
- 3. Web前端面試寶典(最新)
- 4. 前端面試寶典
- 5. Web前端經典面試試題(二)
- 6. Web前端經典面試試題(一)
- 7. Web前端經典面試試題(三)
- 8. web前端經典面試題
- 9. 前端面試-精簡版
- 10. 【面試】web前端經典面試題試題及答案-javaScript
- 更多相關文章...
- • Swift 字典 - Swift 教程
- • ASP.NET Web Forms - 母版頁 - ASP.NET 教程
- • 使用阿里雲OSS+CDN部署前端頁面與加速靜態資源
- • 爲了進字節跳動,我精選了29道Java經典算法題,帶詳細講解
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. offer收割機-Web前端面試寶典【精編版-4】
- 2. web前端面試寶典
- 3. Web前端面試寶典(最新)
- 4. 前端面試寶典
- 5. Web前端經典面試試題(二)
- 6. Web前端經典面試試題(一)
- 7. Web前端經典面試試題(三)
- 8. web前端經典面試題
- 9. 前端面試-精簡版
- 10. 【面試】web前端經典面試題試題及答案-javaScript