100天搞定機器學習|Day60 遇事不決,XGBoost
XGBoost 是一種集大成的機器學習算法,可用於迴歸,分類和排序等各類問題,在機器學習大賽及工業領域被普遍應用。成功案例包括:網頁文本分類、顧客行爲預測、情感挖掘、廣告點擊率預測、惡意軟件分類、物品分類、風險評估、大規模在線課程退學率預測。html
XGBoost是初學者最值得深度理解的模型之一,它將決策樹、boosting、GBDT 等知識點串聯起來,強烈建議你們都手擼一波。
本文我將從XGBoost淵源及優勢、模型原理及優化推導、XGBoost模型參數解析、調參實例,XGBoost可視化等方面介紹XGBoost。提醒一下,XGBoost 是在 GBDT 基礎上的改進,閱讀本文需對 GBDT 有必定的瞭解,不熟悉的同窗能夠看一下前篇: 100天搞定機器學習|Day58 機器學習入門:硬核拆解GBDT算法
XGBoost淵源及優點
在數據建模中,常常採用Boosting方法,該方法將成百上千個分類準確率較低的樹模型組合起來,成爲一個準確率很高的預測模型。這個模型會不斷地迭代,每次迭代就生成一顆新的樹。但在數據集較複雜的時候,可能須要幾千次迭代運算,這將形成巨大的計算瓶頸。多線程
針對這個問題,華盛頓大學的陳天奇博士開發的XGBoost(eXtreme Gradient Boosting)基於C++經過多線程實現了迴歸樹的並行構建,並在原有Gradient Boosting算法基礎上加以改進,從而極大地提高了模型訓練速度和預測精度。app
XGBoost 主要優點以下:機器學習
一、GBDT在優化時只用到一階導數信息,XGBoost同時用到了一階和二階導數,還支持自定義損失函數,前提是損失函數可一階和二階求導;函數
二、加入了正則項,用於控制模型的複雜度,防止過擬合;學習
三、借鑑了隨機森林的作法,支持列抽樣(隨機選擇特徵),不只能下降過擬合,還能減小計算;優化
四、尋找最佳分割點時,實現了一種近似法,還考慮了稀疏數據集、缺失值的處理,大大提高算法的效率;線程
五、支持並行;code
六、近似直方圖算法,用於高效地生成候選的分割點;
七、在算法實現時作了不少優化,大大提高了算法的效率,內存空間不夠時,利用了分塊、預取、壓縮、多線程協做的思想。
XGBoost模型原理及優化推導
XGBoost其實也是GBDT的一種,仍是加性模型和前向優化算法。
加法模型就是說強分類器由一系列弱分類器線性相加而成。通常組合形式以下:
$$F_M(x;P)=\sum_{m=1}^n\beta_mh(x;a_m)$$
其中,$h(x;a_m)$就是一個個的弱分類器,$a_m$是弱分類器學習到的最優參數,$β_m$就是弱學習在強分類器中所佔比重,P是全部$α_m$和$β_m$的組合。這些弱分類器線性相加組成強分類器。
前向分步就是說在訓練過程當中,下一輪迭代產生的分類器是在上一輪的基礎上訓練得來的。也就是能夠寫成這樣的形式:
$$F_m (x)=F_{m-1}(x)+ \beta_mh_m (x;a_m)$$
XGBoost 的模型是什麼樣子的呢?
$$\hat{y}i = \sum{k=1}^K f_k(x_i), f_k \in \mathcal{F}$$
- 其中 K 是樹的棵數。
- $f$是迴歸樹,$f(x)=w_{q(x)}$,知足$(q: R^m \rightarrow T, w \in R^T)$
- q表示每棵樹的結構,它會將一個訓練樣本實例映射到相對應的葉子索引上。
- T是樹中的葉子數。
- 每一個對應於一個獨立的樹結構q和葉子權重w。
- $\mathcal{F}$ 是全部迴歸樹組成的函數空間。
與決策樹不一樣的是,每棵迴歸樹包含了在每一個葉子上的一個連續分值,咱們使用來表示第i個葉子上的分值。對於一個給定樣本實例,咱們會使用樹上的決策規則(由q給定)來將它分類到葉子上,並經過將相應葉子上的分值(由w給定)作求和,計算最終的預測值。
XGBoost的學習
爲了在該模型中學到這些函數集合,咱們會對下面的正則化目標函數作最小化:
$$\text{obj}(\theta) = \sum_i^n l(y_i, \hat{y}i) + \sum{k=1}^K \Omega(f_k)$$
其中:$l$ 是損失函數,常見的有 2 種:
平方損失函數:$l(yi,yi)=(y_i−yi)2$
邏輯迴歸損失函數:$l(yi,yi)=y_i\ln\left(1+e{-\hat{y}_i}\right)+\left(1-y_i\right)\ln\left(1+e^{\hat{y}_i}\right)$
$Ω(Θ)$: 正則化項,用於懲罰複雜模型,避免模型過度擬合訓練數據。經常使用的正則有L1正則與L2正則:
L1正則(lasso): $Ω ( w ) = λ∣∣w∣∣_1$
L2正則: $Ω ( w ) = \lambda ||w||^2$
下一步就是對目標函數進行學習,每一次保留原來的模型不變,加入一個新的函數$f$到咱們的模型中。
$$\begin{split}\hat{y}_i^{(0)} &= 0\
\hat{y}_i^{(1)} &= f_1(x_i) = \hat{y}_i^{(0)} + f_1(x_i)\
\hat{y}_i^{(2)} &= f_1(x_i) + f_2(x_i)= \hat{y}i^{(1)} + f_2(x_i)\
&\dots\
\hat{y}i^{(t)} &= \sum{k=1}^t f_k(x_i)= \hat{y}i^{(t-1)} + f_t(x_i)\end{split}$$
其中,$\hat{y_i}^{(t)}$爲第i個實例在第t次迭代時的預測,咱們須要添加樹 $f_t$,而後最小化下面的目標函數:
$$
\begin{split}\text{obj}^{(t)} & = \sum{i=1}^n l(y_i, \hat{y}i^{(t)}) + \sum{i=1}^t\Omega(f_i) \
& = \sum{i=1}^n l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \Omega(f_t) + \mathrm{constant}\end{split}
$$
假設損失函數使用的是平方損失$l(yi,yi)=(y_i−yi)2$ ,則上式進一步寫爲:
$$
\begin{split}\text{obj}^{(t)} & = \sum_{i=1}^n (y_i - (\hat{y}i^{(t-1)} + f_t(x_i)))^2 + \sum{i=1}^t\Omega(f_i) \
& = \sum_{i=1}^n [2(\hat{y}_i^{(t-1)} - y_i)f_t(x_i) + f_t(x_i)^2] + \Omega(f_t) + \mathrm{constant}\end{split}
$$
如今,咱們採用泰勒展開來定義一個近似的目標函數:
$\text{obj}^{(t)} = \sum_{i=1}^n [l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t) + \mathrm{constant}$
其中:
$$\begin{split}g_i &= \partial_{\hat{y}_i^{(t-1)}} l(y_i, \hat{y}i^{(t-1)})\
h_i &= \partial{\hat{y}_i{(t-1)}}2 l(y_i, \hat{y}_i^{(t-1)})\end{split}$$
$g_i,h_i$分別是loss function上的一階梯度和二階梯度。
忘記基礎知識的同窗順便重溫一下泰勒公式吧
泰勒公式(Taylor’s Formula)是一個用函數在某點的信息描述其附近取值的公式。其初衷是用多項式來近似表示函數在某點周圍的狀況。
函數$f(x)$在$x_0$處的基本形式以下
$$
\begin{align}
f(x) &= \sum_{n=0}\infty\frac{f{(n)}(x_0)}{n!}(x-x_0)^n
\&= f(x_0) +f^{1}(x_0)(x-x_0)+ \frac{f{2}(x_0)}{2}(x-x_0)2 + \cdots + \frac{f{(n)}(x_0)}{n!}(x-x_0)n
\end{align}
$$
還有另一種常見的寫法,$x^{t+1} = x^t + \Delta x$,將$f(x{t+1})$在$xt$處進行泰勒展開,得:
$$\begin{align}
f(x^{t+1}) &= f(x^t) +f{1}(xt)\Delta x+ \frac{f{2}(xt)}{2}\Delta x^2 + \cdots
\end{align}$$
如今,咱們去掉常量,而後從新認識一下咱們新的目標函數:
$$\sum_{i=1}^n [g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t)$$
定義$I_j = {i|q(x_i)=j}$是葉子 j 的實例集合。
$\Omega(f) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2$
將正則項帶入,展開目標函數:
$$
\begin{split}\text{obj}^{(t)} &\approx \sum_{i=1}^n [g_i w_{q(x_i)} + \frac{1}{2} h_i w_{q(x_i)}^2] + \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2\
&= \sum^T_{j=1} [(\sum_{i\in I_j} g_i) w_j + \frac{1}{2} (\sum_{i\in I_j} h_i + \lambda) w_j^2 ] + \gamma T\end{split}$$
看起來有點複雜,令:
$G_j = \sum_{i\in I_j} g_i$,$H_j = \sum_{i\in I_j} h_i$,上式簡化爲:
$$
\text{obj}^{(t)} = \sum^T_{j=1} [G_jw_j + \frac{1}{2} (H_j+\lambda) w_j^2] +\gamma T
$$
上式中$w_j$是相互獨立的,$G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2$是平方項。
對於一個肯定的結構$q(x)$,咱們能夠計算最優的權重$w_j^{\ast}$:
$$
\begin{split}w_j^\ast &= -\frac{G_j}{H_j+\lambda}\
\end{split}
$$
將$w_j{\ast}$帶入上式,計算獲得的loss最優解${obj}*$:
$$\begin{align}
Obj^{\ (t)} &=\sum_{j=1}^T \left(G_jw_j + \frac{1}{2} (H_j + \lambda) w_j^2\right) +\gamma T\
&=\sum_{j=1}^T \left(- \frac{G_j^2}{H_j+\lambda} + \frac{1}{2} \frac{G_j^2}{H_j+\lambda} \right) +\gamma T\
&=- \frac{1}{2}\sum_{j=1}^T \left({\color{red}{\frac{G_j^2}{H_j+\lambda}} } \right) +\gamma T \tag{2-8}
\end{align}$$
${obj}^*$能夠做爲一個得分函數(scoring function)來衡量一棵樹結構$q(x)$的質量。
咱們有了一個方法來衡量一棵樹有多好,如今來看XGBoost優化的第二個問題:如何選擇哪一個特徵和特徵值進行分裂,使最終咱們的損失函數最小?
XGBoost特徵選擇和切分點選擇指標定義爲:
$$
\begin{align}
gain=\underbrace{\frac{G_L2}{H_L+\lambda}}_{左節點得分}+\underbrace{\frac{G_R2}{H_R+\lambda}}{右節點得分}-\underbrace{\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}}{切分前得分}-\gamma
\end{align}
$$
具體如何分裂?
可使用徹底貪婪算法(exact greedy algorithm),在全部特徵上,枚舉全部可能的劃分。

- 基於當前節點嘗試分裂決策樹,默認分數score=0,G和H爲當前須要分裂的節點的一階二階導數之和。
- 對特徵序號 k=1,2...K:$G_L=0, H_L=0$
- 將樣本按特徵k從小到大排列,依次取出第i個樣本,依次計算當前樣本放入左子樹後,左右子樹一階和二階導數和:
$G_L = G_L+ g_{ti}, G_R=G-G_L$
$H_L = H_L+ h_{ti}, H_R=H-H_L$ - 嘗試更新最大的分數:
$$score = max(score, \frac{1}{2}\frac{G_L^2}{H_L + \lambda} + \frac{1}{2}\frac{G_R^2}{H_R+\lambda} - \frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} -\gamma)$$ - 基於最大score對應的劃分特徵和特徵值分裂子樹。
- 若是最大score爲0,則當前決策樹創建完畢,計算全部葉子區域的$w_{tj}$, 獲得弱學習器$h_t(x)$,更新強學習器$f_t(x)$,進入下一輪弱學習器迭代.若是最大score不是0,則繼續嘗試分裂決策樹。
原理推導(精簡版)
下面是XGBoost原理推導的精簡版,方便同窗們複習使用。
$$
\begin{align*}
\begin{array}{l}
\text{預測模型: }F(x)=\sum_{i=1}^Tw_if_i(x)\
\text{目標函數: }objt=\sum_{i=1}NL(y_i,F_i^t(x_i))+\Omega(f_t)\
\because obj^t=\sum_{i=1}^NL(y_i,F_i^t(x_i))+\Omega(f_t)\\
~~~~~~~~~=\sum_{i=1}^NL(y_i,F_i^{t-1}(x_i)+w_tf_t(x_i))+\Omega(f_t)\\
\text{由泰勒公式: }f(x+\Delta x)\thickapprox f(x)+\nabla f(x)\Delta x+\frac{1}{2}\nabla^2 f(x)\Delta x^2\\
\therefore obj^t\thickapprox\sum_{i=1}^N[L(y_i,F_i^{t-1}(x_i))+\nabla _{F_{t-1}}L(y_i,F_i^{t-1}(x_i))w_tf_t(x_i)\\
~~~~~~~~~~~~~~~\frac{1}{2}\nabla _{F_{t-1}}^2L(y_i,F_i^{t-1}(x_i))w_t^2f_t^2(x_i)]+\Omega(f_t)\\
\text{令 $g_i=\nabla _{F_{t-1}}L(y_i,F_i^{t-1}(x_i))$}\\
~~~~~~h_i=\nabla _{F_{t-1}}^2L(y_i,F_i^{t-1}(x_i))\\
~~~obj^t\thickapprox \sum_{i=1}^N[L(y_i,F_i^{t-1}(x_i))+g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)\\
\because L(y_i,F_i^{t-1}(x_i)) \text{ 是常量}\\
\therefore \text{目標函數:}\\
~~~obj^t=\sum_{i=1}^N[g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)+C\\
\text{用葉子節點集合以及葉子節點得分表示 ,每一個樣本都落在一個葉子節點上:}\\
f_t(x)=m_q(x),~~m\in R^T,~~q:R^d\rightarrow\{1,2,3,...,T\}\\
\Omega(f_t)=\gamma T+ \frac{1}{2}\lambda \sum_{i=1}^Tm_j^2,\\
\text{$T$ 是第 $t$ 棵樹葉子結點總數}\\
\text{$m_j$ 是第j個葉子結點的權重}\\
\text{定義第 $j$ 個葉子節點所在的樣本爲 $I_j=\{i|j=q(x_i)\}$}\\
\text{新的目標函數:}\\
obj^t=\sum_{i=1}^N[g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)\\
~~~~~~~=\sum_{i=1}^N[g_iw_tm_q(x_i)+\frac{1}{2}h_iw_t^2m_q^2(x_i)]+\gamma T+ \frac{1}{2}\lambda \sum_{i=1}^Tm_j^2\\
~~~~~~~=\sum_{j=1}^T[(\sum_{i \in I_j}g_i)w_tm_j+\frac{1}{2}(\sum_{i \in I_j}h_iw_t^2+\lambda )m_j^2]+\gamma T\\
\text{令: $G_j=\sum_{i \in I_j}g_i$ , $H_j=\sum_{i \in I_j}h_i$ }\\
obj^t=\sum_{j=1}^T[G_jw_tm_j+\frac{1}{2}(H_jw_t^2+\lambda)m_j^2]+\gamma T\\
\text{對二次函數優化問題:}\\
m_j^*=-\frac{G_j^2w_t}{H_jw_t^2+\lambda}\\
obj^*=-\frac{1}{2}\sum_{j=1}^T\frac{G_j^2w_t^2}{H_jw_t^2+\lambda}+\gamma T\\
\text{令 $w_t=1$ :}\\
m_j^*=-\frac{G_j}{H_j+\lambda}\\
obj^*=-\frac{1}{2}\sum_{j=1}^T\frac{G_j^2}{H_j+\lambda}+\gamma T\\
\text{因此當咱們新增一個切分點增益爲:}\\
gain=\underbrace{\frac{G_L^2}{H_L+\lambda}}_{左節點得分}+\underbrace{\frac{G_R^2}{H_R+\lambda}}_{右節點得分}-\underbrace{\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}}_{切分前得分}-\gamma
\end{array}
\end{align*}
$$
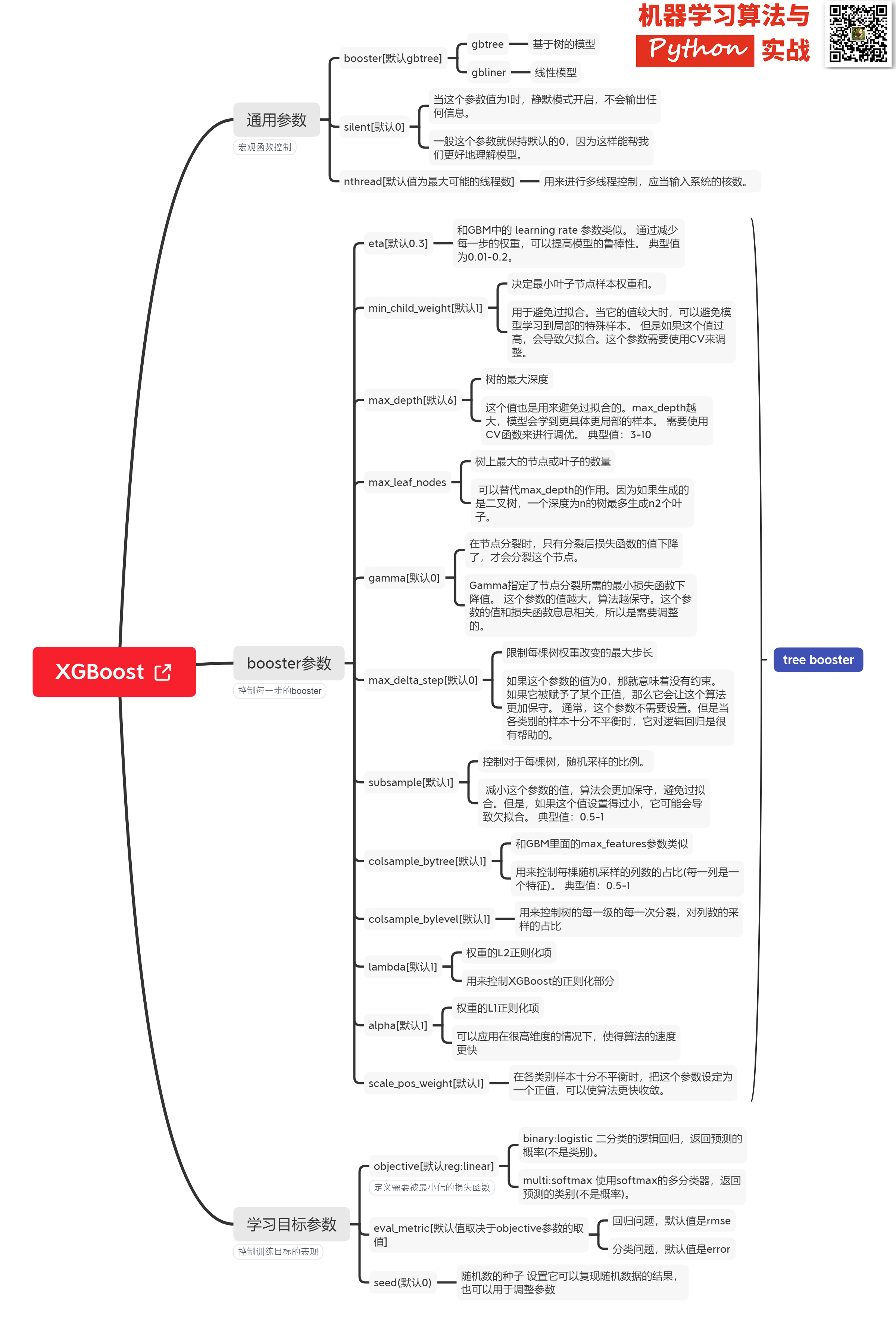
### Xgboost@sklearn模型參數解析
XGBoost的實現有原生版本,同時也有Scikit-learn版本,二者在使用上有一些微差別,這裏給出xgboost.sklearn 參數解釋。XGBoost使用**key-value**字典的方式存儲參數:
```
#部分重要參數
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分類的問題
'num_class': 10, # 類別數,與 multisoftmax 並用
'gamma': 0.1, # 用於控制是否後剪枝的參數,越大越保守,通常0.一、0.2這樣子。
'max_depth': 12, # 構建樹的深度,越大越容易過擬合
'lambda': 2, # 控制模型複雜度的權重值的L2正則化項參數,參數越大,模型越不容易過擬合。
'subsample': 0.7, # 隨機採樣訓練樣本
'colsample_bytree': 0.7, # 生成樹時進行的列採樣
'min_child_weight': 3,
'silent': 1, # 設置成1則沒有運行信息輸出,最好是設置爲0.
'eta': 0.007, # 如同窗習率
'seed': 1000,
'nthread': 4, # cpu 線程數
}
```
篇幅緣由,調參實例及XGBoost可視化且聽下回分解。
若有收穫,還請不吝給個**在看、收藏、轉發**
## 參考
https://www.cnblogs.com/pinard/p/10979808.html
https://www.biaodianfu.com/xgboost.html
https://www.zybuluo.com/vivounicorn/note/446479
https://www.cnblogs.com/chenjieyouge/p/12026339.html
- 1. 100天搞定機器學習
- 2. 100天搞定機器學習|Day22 機器爲何能學習?
- 3. 100天搞定機器學習|Day33-34 隨機森林
- 4. 100天搞定機器學習|Day9-12 支持向量機
- 5. 100天搞定機器學習|Day22 機器爲什麼能學習?
- 6. 100天搞定機器學習|Day55 最大熵模型
- 7. 100天搞定機器學習|Day15 樸素貝葉斯
- 8. 100天搞定機器學習|day40-42 Tensorflow Keras識別貓狗
- 9. 100天搞定機器學習(100-Days-Of-ML)(十三)隨機森林
- 10. 100天搞定機器學習|Day3多元線性迴歸
- 更多相關文章...
- • 您已經學習了 XML Schema,下一步學習什麼呢? - XML Schema 教程
- • 我們已經學習了 SQL,下一步學習什麼呢? - SQL 教程
- • Tomcat學習筆記(史上最全tomcat學習筆記)
- • 適用於PHP初學者的學習線路和建議
-
每一个你不满意的现在,都有一个你没有努力的曾经。