JavaScript:V8編譯過程
衆所周知ECMAScript語言類型分爲:Undefined,Null,Boolean,String,Symbol,Number,和Object。咱們常說前六種數據類型爲基礎類型,Object爲引用類型或者說複雜類型數據。那麼咱們有想過爲何說Undefined,Null,Boolean,String,Symbol,Number爲基礎類型,而Object爲引用類型?在沒有本身看ECMAScript規範以前我沒有認真思考過這個問題,你們都這麼說,並且不少書上也是這麼寫的,就這麼認定了。javascript
在ECMAScript規範中並無指出Undefined,Null,Boolean,String,Symbol,Number爲基礎類型,Object爲引用類型。咱們來看看規範怎麼講的:前端
4.3.2primitive valuejava
member of one of the types Undefined, Null, Boolean, Number, Symbol, or String as defined in clause 6 NOTEA primitive value is a datum that is represented directly at the lowest level of the language implementation.git
在規範的第六章定義的Undefined, Null, Boolean, Number, Symbol, 和String是原始值,原始值直接表明語言實現的最底層的數據。github
4.3.3object編程
member of the type Object An object is a collection of properties and has a single prototype object. The prototype may be the null value.數組
對象是屬性的集合,並有一個原型對象。原型能夠爲空值。瀏覽器
規範中並無區分基礎數據類型和引用數據類型,那麼爲何在JavaScript中會有這兩個概念呢?這與JavaScript引擎內存管理有關,下面咱們就來聊聊JavaScript引擎編譯原理。ruby
語言類型
計算機不能直接理解任何除機器語言之外的語言,咱們一般寫的代碼是高級語言,計算機不能直接理解,因此必需要將寫的高級語言代碼翻譯成機器語言,計算機才能執行程序。性能優化
目前編程語言主要分爲編譯型語言和解釋型語言,編譯型語言是在代碼運行前編譯器將編程語言轉換成機器語言,運行時不須要從新翻譯,直接使用編譯的結果就好了。而解釋型語言也是須要將編程語言轉換成機器語言,可是是在運行時轉換的。很明顯解釋型語言的執行速度是慢於編譯型語言,解釋型語言每次執行都須要把源碼轉換一次才能執行。
C、C++就是屬於編譯型語言,編輯源代碼、編譯和運行是所有分離的,互相是一個職責鏈的形勢。咱們寫完源碼後,通過編譯連接、最後獲得本地二進制代碼,而後交給操做系統。

ruby、JavaScript等就是屬於典型的解釋型語言,也是腳本語言,腳本不須要進行編譯,而是在運行過程當中直接被解釋器解釋同時調用操做系統資源運行。對於JavaScript而言,解釋器就是JavaScript引擎,早期的JavaScript引擎,也是採用這樣的方式編譯JavaScript代碼的,可是早期V8引擎就不是這種的編譯過程了,下面會講到。
java也被歸類爲解釋型語言,這有爭議,也有人說java是編譯型語言,其實不用太關心java是什麼類型的語言,咱們瞭解下java是怎麼編譯的,java代碼的處理過程和上面講述的解釋型語言編譯過程有些相似,可是處理過程要複雜些,分爲了兩個階段:編譯和解釋:
- 編譯:首先是像
C++語言同樣的編譯器,編譯java代碼,可是和C++編譯器生成機器代碼不一樣,經過編譯器先轉換成抽象語法樹,後轉換成字節碼,字節碼是一種中間代碼。 - 解釋:而後就是運行字節碼,主要依靠的就是
java虛擬機(JVM)加載字節碼,使用解釋執行這些字節碼,將字節碼轉成機器碼。字節碼能夠不受操做系統和平臺的限制,藉助java虛擬機也就實現了跨平臺的功能,因此一直說java是跨平臺的,就是這麼跨的。
Java的處理過程加入了JIT的概念,JIT能夠將字節碼轉爲本地代碼而後執行,會提升執行效率,JIT主要是起到優化性能的做用。不少JavaScript引擎也用到了。
JavaScript被歸類弱類型解釋型語言,由於是弱類型語言,也能夠說是動態類型語言。相比較而言,C++或者java等是靜態類型語言,他們在編譯的時候就可以知道每一個變量的類型。而JavaScript在編輯的時候無法知道其變量的數據類型,只有在運行的時候才能肯定,這致使JavaScript面臨着性能方面的巨大壓力。在運行時計算和決定數據類型,會帶來很嚴重的性能損失,這也致使JavaScript運行效率比C++、java要低不少,爲了提升運行效率,不少廠商在作努力,目前作的比較好的就是Chrome的V8引擎,V8引擎是JavaScript引擎。
JavaScript的執行是依賴JavaScript引擎,JavaScript引擎相似JVM,是一個專門處理JavaScript腳本的虛擬機,JavaScript引擎目前有不少:SpiderMonkey、JavaScriptCore、Chakra、V8等,現代JavaScript引擎都引入了Java虛擬機和C++編譯器的衆多技術,和早期的JavaScript引擎工做方式有很大的不一樣:
早期由解釋器來解釋它們便可,就是將源代碼轉變成抽象語法樹,而後在抽象語法樹上解釋執行,早期的JavaScriptCore就是這樣工做的,後面改進了。隨着將Java虛擬機的JIT技術引入,如今的作法是將抽象語法樹轉成中間表示(也就是字節碼),而後經過JIT技術轉成本地代碼。也有些作法直接從抽象語法樹生成本地代碼的JIT技術,例如早期的V8。
JavaScript引擎
目前如今的JavaScript引擎對JavaScript的處理過程和java類似,畢竟引入了java編譯技術,可是仍是有區別,java處理分了兩個階段:編譯和解釋,經過編譯器將源代碼解析生成字節碼,後在經過JVM將字節碼轉成機器碼後運行。JavaScript引擎編譯把編譯和解釋這兩個階段結合起來了,都在JavaScript引擎中執行,目前JavaScript引擎主要包含如下部分:
- 編譯器:將源代碼編譯成抽象語法樹,在某些引擎(如
JavaScriptCore,如今的V8)中還包括將抽象語法樹轉換成字節碼 - 解釋器:在某些引擎(如
JavaScriptCore)中,解釋器主要是接受字節碼,解釋執行字節碼,但早期V8引擎中沒有解釋器 JIT工具:將字節碼或者抽象語法樹轉換成本地代碼,優化用- 垃圾回收器和分析工具(
profiler):負責垃圾回收和收集引擎中的信息,幫助改善引擎的性能和功效
上圖就是JavaScript引擎的編譯過程,目前大部分JavaScript引擎都是按照上面的流程對JavaScript進行編譯,首先用編譯器將源代碼轉換成抽象語法樹而後再轉換成字節碼,解釋器解析執行字節碼,生成本地代碼。
V8引擎
爲何在本文講述V8引擎的編譯過程,V8是一個開源項目,在性能方面要優於其餘JavaScript引擎,Chrome 使用的V8引擎,瀏覽器市場佔有率很大,而且Node也是基於V8研發的,V8也支持衆多的操做系統和硬件架構,V8具備表明性,V8自08年發佈以來,性能一直在穩步的提升:
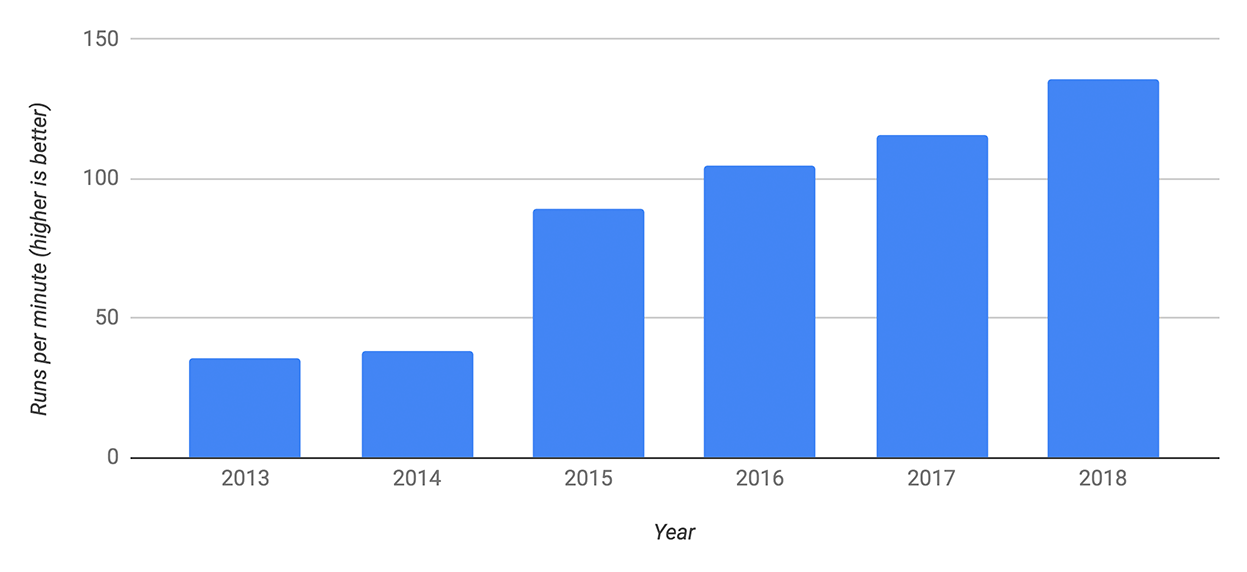
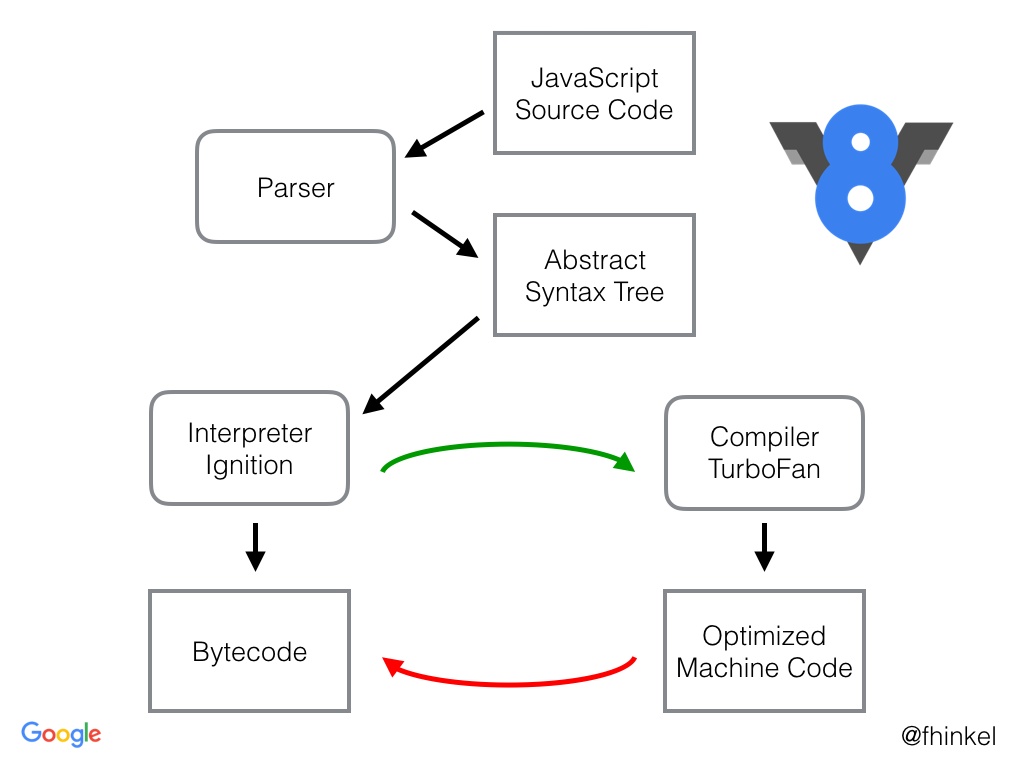
下面是V8引擎執行的整個過程,主要包括瞭如下幾個模塊:
parse:負責將JavaScript源代碼轉換成抽象語法樹(AST)Ignition:interpreter,解釋器,將AST轉換成字節碼(Bytecode),解析執行字節碼,同時也收集TurboFan優化編譯所須要的信息TurboFan:compiler,JIT編譯器,利用Ignitio所收集的類型信息,將Bytecode轉換爲優化的機器碼Orinoco:garbage collector,垃圾回收模塊,負責將程序再也不須要的內存空間回收
生成抽象語法樹
V8引擎首先是經過編譯器(parse)將源代碼解析抽象語法樹(AST),生成AST分爲兩個階段,一是詞法分析,二是語法分析:
- 詞法分析:將源代碼拆成最小的、不可再分的詞法單元(
token)。例如程序var a = 2;。這段程序一般會被分解成這些詞法單元:var、a、=、2、;。五個詞法單元。空格是否會被看成詞法單元,取決於空格在這門語言是否具備意義,在JavaScript中,空格是不會被看成詞法單元。 - 語法分析:這個過程是將詞法單元流(數組)轉換成一個由元素逐級嵌套所組成的表明了程序語法結構的樹,這個樹被稱爲抽象語法樹(
AST)。var a = 2;的抽象語法樹中可能會有一個叫作VariableDeclaration的頂級節點,接下來是一個叫做Identifier(它的值是a)的子節點,以及一個叫作AssignmentExpression的子節點。AssignmentExpression節點有一個叫作NumericLiteral(它的值是2)的子節點。
上面就是var a = 2生成抽象語法樹的一個過程,能夠藉助在線工具查看。
AST是源代碼語法結構的一種抽象表示,計算機不是識別源代碼,因此須要將源代碼轉換成計算機能識別的機器碼,AST也只是這一過程當中的一步。
講到這裏,有一個詞有必要說起,Babel,前端同窗對這個應該很熟悉,有的ES6語法如今瀏覽器還不支持,須要將ES6語法轉成ES5語法,這一個過程就要藉助Babel來實現,Babel是一個JavaScript編譯器,分了三個階段:解析、轉譯、生成。將ES6源碼解析成AST,再將ES6語法的AST轉成ES5的AST,最後利用它來生成ES5源代碼,這就是Babel的基本實現原理。
ESLint原理也大體相同,檢測流程也是將源碼轉換成AST,在利用AST來檢測代碼規範。
AST在計算機科學中是一個很重要的概念,須要瞭解下,能更好的幫助咱們理解本身寫的代碼。Vue的編譯也用到了AST。
生成字節碼
上面已經講述了將JavaScript源代碼轉換成AST,如今須要將AST轉換成字節碼。前面有提到早期的V8引擎v5.6版本以前,不會將AST轉換成字節碼,直接將AST轉換成機器碼。有兩個編譯器:
full-codegen:簡單且快速的編譯器,能夠生成簡單但相對較慢的機器碼Grankshaft:較爲複雜的JIT編譯器,能夠生成高度優化的機器碼
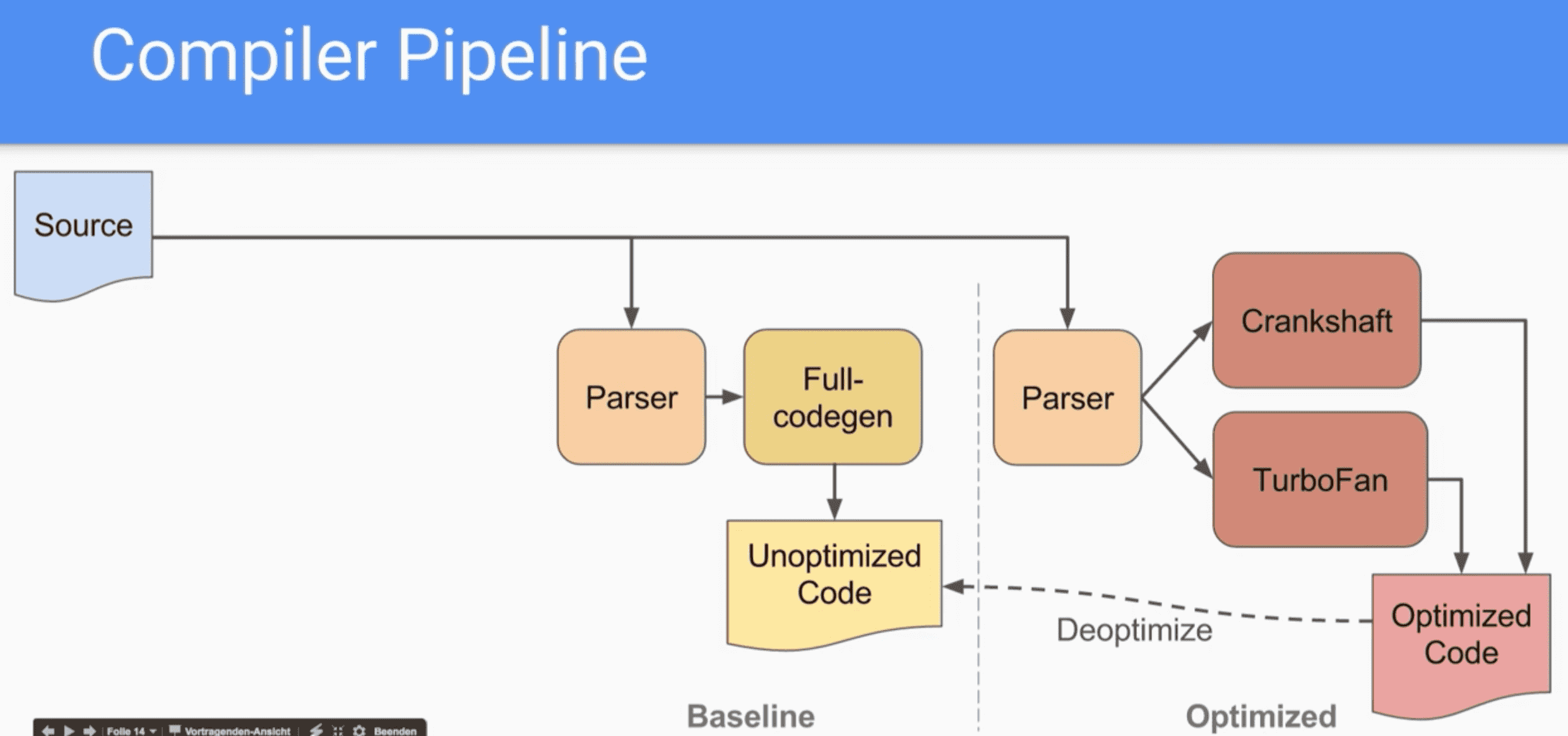
首次執行JavaScript代碼,直接經過full-codegen編譯器將AST轉換成機器碼,跳過了轉換成字節碼這一過程,這樣使得它能夠很是快速地執行機器碼。
這樣作的主要目的在於減小轉成字節碼這一中間過程的轉換時間,提升代碼的執行速度,這一切也都是在頁面加載的時候完成,這樣能夠提升優化的可能,執行性能會有比較大的提升,可是缺點也很明顯:
- 會帶來內存佔用過大的問題,由於將抽象語法樹所有生成了機器碼,而機器碼相比字節碼佔用內存大不少
- 某些
JavaScript使用場景使用解釋器更爲合適,解析成字節碼,有些代碼不必生成機器碼,進而儘量的減小了機器碼佔用內存過大的問題 - 由於沒有中間表示,會減小優化的機會,由於少了一箇中間表示層
在發佈v5.6版以前,爲了作性能優化也作了不少工做,爲了減小生成機器碼,嘗試了大量延遲解析和編譯(Lazy parsing and compiling)的工做。例如,對於一段代碼,若是這段代碼中的函數沒有在初始化調用,則該調用過程將會被「延遲」進行,直到第一次函數調用時再編譯該函數對應的代碼。
經過full-codegen編譯器生成機器碼後,經過數據分析器(Profiler)採集一些信息,這些信息會提供給Grankshaft編譯器。
Grankshaft編譯器,主要針對熱點代碼進行優化。從上面的編譯過程能夠看到,該編譯器也是基於源代碼進行分析,同時構建Hydroger圖並基於此來進行優化分析最,終生成更高效的機器碼,這是一個逐步漸進的優化過程。同時,當發現優化後代碼的性能還不如未優化的代碼,V8將退回原來的代碼,也就是反優化。
儘管一直在作優化,可是優化層仍是在機器碼上,機器碼自己佔用內存就很大。Grankshaft編譯器雖然也是作JIT優化的,可是Grankshaft每次解析仍是從源代碼從新解析的。
後面官方在V8的v5.6版仍是將AST轉換成字節碼這一過程加上了,回到了字節碼的懷抱中。引進了Ignition解釋器,經過Ignition解釋器將AST轉換成字節碼。
V8從新引進Ignition解釋器,將AST轉換成字節碼後,內存佔用顯著降低了,同時也可使用JIT編譯器作進一步的優化。
上圖就是十大流行手機端網站的測試,能夠發現他們的內存佔用顯著降低。
字節碼是介於AST和機器碼之間的一種代碼,須要將其轉換成機器碼後才能執行,字節碼能夠理解爲是機器碼的一種抽象。不太須要具體理解字節碼是什麼,只須要知道這是個中間代碼。
Ignition設計的目的是爲V8創建一個解釋器來執行低層級的字節碼,以便讓哪些只被運行一次或者非熱點的代碼以字節碼的形式更加緊湊的存儲。因爲字節碼更小,編譯的時間也將大幅減小。同時字節碼可以直接傳給TurboFan圖生成器,從而在TurboFan裏面優化函數時,能夠避免從新解析JavaScript源代碼。也就是說TurboFan的編譯是基於字節碼,而不是源代碼。
Ignition解釋器的引入也就徹底替代了full-codegen,Crankshaft也被徹底拋棄了,Crankshaft不能解析優化字節碼,後面被TurboFan編譯器替代了。
生成機器碼
Ignition解釋器除了能夠快速生成未優化的字節碼外,還負責執行字節碼。第一次執行字節碼時,也會收集分析數據,解釋器會逐條解釋。若是發現hot代碼(即一段代碼被重複執行屢次),生成的字節碼和分析數據則會被傳給TurboFan編譯器,它會依據分析數據生成高度優化的機器碼。當再次執行這段代碼時,只須要執行編譯後的機器碼。
TurboFan編譯器是JIT優化編譯器,開始在Ignition解釋器中運行字節碼。在某些時候,引擎肯定代碼很熱並啓動TurboFan前端,這是TurboFan的一部分,它處理集成分析數據和構建代碼的基本機器表示。而後將其發送到另外一個線程上的TurboFan,以進一步改進代碼。V8引擎是多線程的,TurboFan編譯和生成字節碼不在同一個線程上。
在TurboFan運行時,V8會繼續在Ignition解釋器中執行字節碼。在某個時候,TurboFan已經完成,有了可執行的機器碼,可與之繼續執行。
由Ignition解釋器收集的分析數據被TurboFan使用,主要是經過一種稱爲推測優化(Speculative Optimization)的技術生成高度優化的機器碼。TurboFan會查看過去看到的值類型,並假設未來咱們將看到相同類型的值,這可使得TurboFan省去不少不須要處理的狀況。若是假設失敗了,那麼就會返回到解析字節碼,這也就是反優化(deoptimization)。
到這裏把V8對JavaScript的編譯過程大體的講完了,如今在回過頭再看下面這張圖應該也很清楚了。沒有很詳細講解各個步驟,V8引擎涉及到的東西太多了,短期內也比較難的把V8整個內容梳理出來,這也不是一篇文章能講清楚,考慮接下來的文章中儘量的以V8的角度來寫。
目前現代JavaScript引擎的編譯過程大部分都是相似的,核心原理是一致的,主要區別在於不一樣的引擎有不一樣的優化層,意思就是不一樣的引擎解釋器和編譯器的數量不同,主要在於使用解釋器快速生成代碼或者使用優化編譯器生成高校代碼之間存在一個基本權衡。經過添加更多優化層讓咱們作出更細粒度的決策,可是以額外的複雜性和開銷爲代價。此外,在優化級別和生成代碼所佔用的內存之間也存在折衷。其實歸根結底爲了讓引擎性能更優。感興趣的同窗能夠本身去了解下其餘引擎的編譯過程~
到這裏,還沒回答開篇提出來的問題,爲何會將數據類型分爲基礎類型和引用類型,這和引擎的內存管理有關,關於V8的內存管理,下篇文章和你們一塊兒聊聊,內容也不少。
結語
文章若有不正確的地方歡迎各位大佬指正,也但願有幸看到文章的同窗也有收穫,一塊兒成長!
--------------------------本文首發於我的公衆號---------------------
- 1. 編譯過程
- 2. openwrt編譯過程
- 3. OpenWRT 編譯過程
- 4. c++編譯過程
- 5. Android編譯過程
- 6. android 編譯過程
- 7. C++編譯過程
- 8. APP編譯過程
- 9. gcc 編譯過程
- 10. GCC編譯過程
- 更多相關文章...
- • Eclipse 編譯項目 - Eclipse 教程
- • Rust 併發編程 - RUST 教程
- • Java 8 Stream 教程
- • YAML 入門教程
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 編譯過程
- 2. openwrt編譯過程
- 3. OpenWRT 編譯過程
- 4. c++編譯過程
- 5. Android編譯過程
- 6. android 編譯過程
- 7. C++編譯過程
- 8. APP編譯過程
- 9. gcc 編譯過程
- 10. GCC編譯過程