一文帶你解析:JVM調優的核心點是什麼?
1 JVM 簡單結構圖
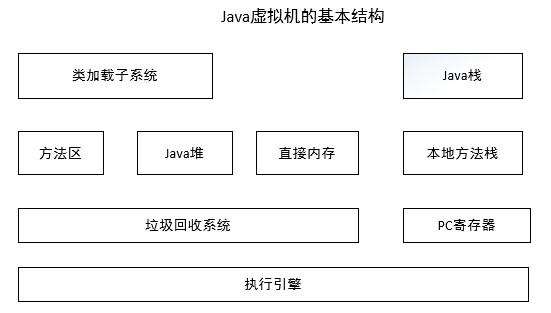
1.1 類加載子系統與方法區:
類加載子系統負責從文件系統或者網絡中加載 Class 信息,加載的類信息存放於一塊稱爲方法區的內存空間。除了類的信息外,方法區中可能還會存放運行時常量池信息,包括字符串字面量和數字常量(這部分常量信息是 Class 文件中常量池部分的內存映射)。 java
1.2 Java 堆
java 堆在虛擬機啓動的時候創建,它是 java 程序最主要的內存工做區域。幾乎全部的 java 對象實例都存放在 java 堆中。堆空間是全部線程共享的,這是一塊與 java 應用密切相關的內存空間。 linux
1.3 直接內存
java 的 NIO 庫容許 java 程序使用直接內存。直接內存是在 java 堆外的、直接向系統申請的內存空間。一般訪問直接內存的速度會優於 java 堆。所以出於性能的考慮,讀寫頻繁的場合可能會考慮使用直接內存。因爲直接內存在 java 堆外,所以它的大小不會直接受限於 Xmx 指定的最大堆大小,可是系統內存是有限的,java 堆和直接內存的總和依然受限於操做系統能給出的最大內存。 程序員
1.4 垃圾回收系統
垃圾回收系統是 java 虛擬機的重要組成部分,垃圾回收器能夠對方法區、java 堆和直接內存進行回收。其中,java 堆是垃圾收集器的工做重點。和 C/C++不一樣,java 中全部的對象空間釋放都是隱式的,也就是說,java 中沒有相似 free()或者 delete()這樣的函數釋放指定的內存區域。對於再也不使用的垃圾對象,垃圾回收系統會在後臺默默工做,默默查找、標識並釋放垃圾對象,完成包括 java 堆、方法區和直接內存中的全自動化管理。 算法
1.5 Java 棧
每個 java 虛擬機線程都有一個私有的 java 棧,一個線程的 java 棧在線程建立的時候被建立,java 棧中保存着幀信息,java 棧中保存着局部變量、方法參數,同時和 java 方法的調用、返回密切相關。 windows
1.6 本地方法棧
本地方法棧和 java 棧很是相似,最大的不一樣在於 java 棧用於方法的調用,而本地方法棧則用於本地方法的調用,做爲對 java 虛擬機的重要擴展,java 虛擬機容許 java 直接調用本地方法(一般使用 C 編寫) tomcat
1.7 PC 寄存器
PC(Program Counter)寄存器也是每個線程私有的空間,java 虛擬機會爲每個 java 線程建立 PC 寄存器。在任意時刻,一個 java 線程老是在執行一個方法,這個正在被執行的方法稱爲當前方法。若是當前方法不是本地方法,PC 寄存器就會指向當前正在被執行的指令。若是當前方法是本地方法,那麼 PC 寄存器的值就是 undefined 服務器
1.8 執行引擎
執行引擎是 java 虛擬機的最核心組件之一,它負責執行虛擬機的字節碼,現代虛擬機爲了提升執行效率,會使用即時編譯(just in time)技術將方法編譯成機器碼後再執行。 網絡
Java HotSpot Client VM(-client),爲在客戶端環境中減小啓動時間而優化的執行引擎;本地應用開發使用。(如:eclipse) 多線程
Java HotSpot Server VM(-server),爲在服務器環境中最大化程序執行速度而設計的執行引擎。應用在服務端程序。(如:tomcat) 併發
Java HotSpot Client 模式和 Server 模式的區別
當虛擬機運行在-client 模式的時候,使用的是一個代號爲 C1 的輕量級編譯器, 而-server 模式啓動的虛擬機採用相對重量級,代號爲 C2 的編譯器. C2 比 C1 編譯器編譯的相對完全,服務起來以後,性能更高
JDK 安裝目錄/jre/lib/(x86、i386、amd32、amd64)/jvm.cfg
文件中的內容,-server 和-client 哪個配置在上,執行引擎就是哪個。若是是 JDK1.5 版本且是 64 位系統應用時,-client 無效。
--64 位系統內容
-server KNOWN
-client IGNORE
--32 位系統內容
-server KNOWN
-client KNOWN
注意:在部分JDK1.6 版本和後續的JDK 版本(64 位系統)中,-client 參數已經不起做用
了,Server 模式成爲惟一
2 堆結構及對象分代
2.1 什麼是分代,分代的必要性是什麼
Java 虛擬機根據對象存活的週期不一樣,把堆內存劃分爲幾塊,通常分爲新生代、老年代和永久代(對 HotSpot 虛擬機而言),這就是 JVM 的內存分代策略。
堆內存是虛擬機管理的內存中最大的一塊,也是垃圾回收最頻繁的一塊區域,咱們程序全部的對象實例都存放在堆內存中。給堆內存分代是爲了提升對象內存分配和垃圾回收的效率。試想一下,若是堆內存沒有區域劃分,全部的新建立的對象和生命週期很長的對象放在一塊兒,隨着程序的執行,堆內存須要頻繁進行垃圾收集,而每次回收都要遍歷全部的對象,遍歷這些對象所花費的時間代價是巨大的,會嚴重影響咱們的 GC 效率。
有了內存分代,狀況就不一樣了,新建立的對象會在新生代中分配內存,通過屢次回收仍然存活下來的對象存放在老年代中,靜態屬性、類信息等存放在永久代中,新生代中的對象存活時間短,只須要在新生代區域中頻繁進行 GC,老年代中對象生命週期長,內存回收的頻率相對較低,不須要頻繁進行回收,永久代中回收效果太差,通常不進行垃圾回收,還能夠根據不一樣年代的特色採用合適的垃圾收集算法。分代收集大大提高了收集效率,這些都是內存分代帶來的好處。
2.2 分代的劃分
Java 虛擬機將堆內存劃分爲新生代、老年代和永久代,永久代是 HotSpot 虛擬機特有的概念(JDK1.8 以後爲 metaspace 替代永久代),它採用永久代的方式來實現方法區,其餘的虛擬機實現沒有這一律念,並且 HotSpot 也有取消永久代的趨勢,在 JDK 1.7 中 HotSpot 已經開始了"去永久化",把本來放在永久代的字符串常量池移出。永久代主要存放常量、類信息、靜態變量等數據,與垃圾回收關係不大,新生代和老年代是垃圾回收的主要區域。
內存簡圖以下:
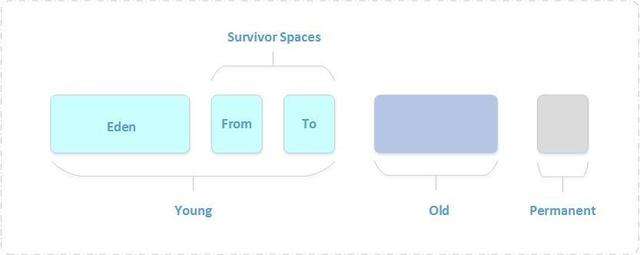
2.2.1 新生代(Young Generation)
新生成的對象優先存放在新生代中,新生代對象朝生夕死,存活率很低,在新生代中,常規應用進行一次垃圾收集通常能夠回收 70% ~ 95% 的空間,回收效率很高。
HotSpot 將新生代劃分爲三塊,一塊較大的 Eden(伊甸)空間和兩塊較小的 Survivor(倖存者)空間,默認比例爲 8:1:1。劃分的目的是由於 HotSpot 採用複製算法來回收新生代,設置這個比例是爲了充分利用內存空間,減小浪費。新生成的對象在 Eden 區分配(大對象除外,大對象直接進入老年代),當 Eden 區沒有足夠的空間進行分配時,虛擬機將發起一次
Minor GC。
GC 開始時,對象只會存在於 Eden 區和 From Survivor 區,To Survivor 區是空的(做爲保留區域)。GC 進行時,Eden 區中全部存活的對象都會被複制到 To Survivor 區,而在 From Survivor 區中,仍存活的對象會根據它們的年齡值決定去向,年齡值達到年齡閥值(默認爲 15,新生代中的對象每熬過一輪垃圾回收,年齡值就加 1,GC 分代年齡存儲在對象的 header 中)的對象會被移到老年代中,沒有達到閥值的對象會被複制到 To Survivor 區。接着清空 Eden 區和 From Survivor 區,新生代中存活的對象都在 To Survivor 區。接着, From Survivor 區和 To Survivor 區會交換它們的角色,也就是新的 To Survivor 區就是上次 GC 清空的 From Survivor 區,新的 From Survivor 區就是上次 GC 的 To Survivor 區,總之,無論怎樣都會保證 To Survivor 區在一輪 GC 後是空的。GC 時當 To Survivor 區沒有足夠的空間存放上一次新生代收集下來的存活對象時,須要依賴老年代進行分配擔保,將這些對象存放在老年代中。
2.2.2 老年代(Old Generationn)
在新生代中經歷了屢次(具體看虛擬機配置的閥值)GC 後仍然存活下來的對象會進入老年代中。老年代中的對象生命週期較長,存活率比較高,在老年代中進行 GC 的頻率相對而言較低,並且回收的速度也比較慢。
2.2.3 永久代(Permanent Generationn)
永久代存儲類信息、常量、靜態變量、即時編譯器編譯後的代碼等數據,對這一區域而
言,Java 虛擬機規範指出能夠不進行垃圾收集,通常而言不會進行垃圾回收。
3 垃圾回收算法及分代垃圾收集器
3.1 垃圾收集器的分類
3.1.1 次收集器
Scavenge GC,指發生在新生代的 GC,由於新生代的 Java 對象大多都是朝生夕死,因此 Scavenge GC 很是頻繁,通常回收速度也比較快。當 Eden 空間不足覺得對象分配內存時,會觸發 Scavenge GC。
通常狀況下,當新對象生成,而且在 Eden 申請空間失敗時,就會觸發 Scavenge GC,對 Eden 區域進行 GC,清除非存活對象,而且把尚且存活的對象移動到 Survivor 區。而後整理 Survivor 的兩個區。這種方式的 GC 是對年輕代的 Eden 區進行,不會影響到年老代。由於大部分對象都是從 Eden 區開始的,同時 Eden 區不會分配的很大,因此 Eden 區的 GC 會頻繁進行。於是,通常在這裏須要使用速度快、效率高的算法,使 Eden 去能儘快空閒出來。
當年輕代堆空間緊張時會被觸發
相對於全收集而言,收集間隔較短
3.1.2 全收集器
Full GC,指發生在老年代的 GC,出現了 Full GC 通常會伴隨着至少一次的 Minor GC(老年代的對象大部分是 Scavenge GC 過程當中重新生代進入老年代),好比:分配擔保失敗。Full GC 的速度通常會比 Scavenge GC 慢 10 倍以上。當老年代內存不足或者顯式調用 System.gc() 方法時,會觸發 Full GC。
當老年代或者持久代堆空間滿了,會觸發全收集操做可使用 System.gc()方法來顯式的啓動全收集
全收集通常根據堆大小的不一樣,須要的時間不盡相同,但通常會比較長。
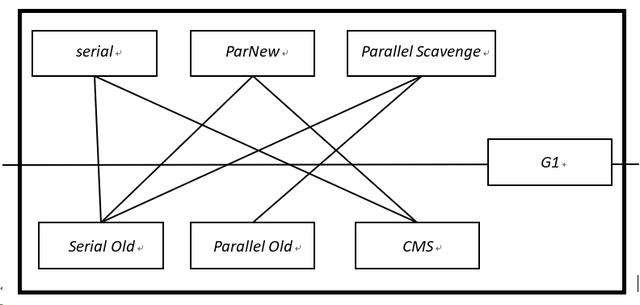
3.1.3 垃圾回收器的常規匹配
3.2 常見垃圾回收算法
3.2.1 引用計數(Reference Counting)
比較古老的回收算法。原理是此對象有一個引用,即增長一個計數,刪除一個引用則減小一個計數。垃圾回收時,只用收集計數爲 0 的對象。此算法最致命的是沒法處理循環引用的問題。
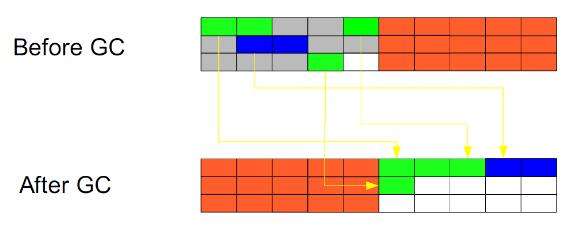
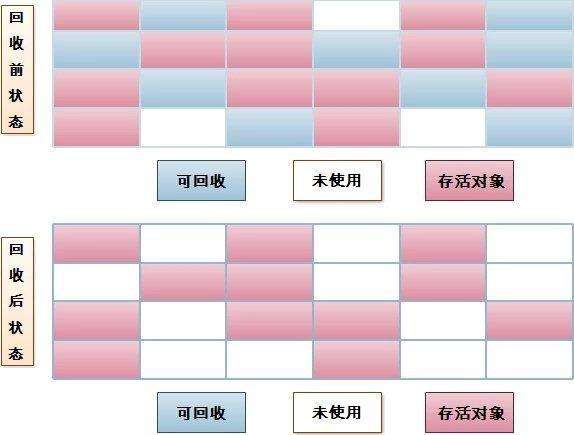
3.2.2 複製(Copying)
此算法把內存空間劃爲兩個相等的區域,每次只使用其中一個區域。垃圾回收時,遍歷當前使用區域,把正在使用中的對象複製到另一個區域中。此算法每次只處理正在使用中的對象,所以複製成本比較小,同時複製過去之後還能進行相應的內存整理,不會出現"碎片"問題。固然,此算法的缺點也是很明顯的,就是須要兩倍內存空間。簡圖以下:
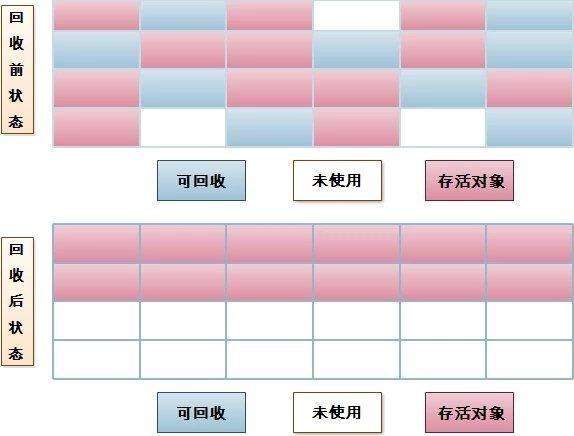
3.2.3 標記-清除(Mark-Sweep)
此算法執行分兩階段。第一階段從引用根節點開始標記全部被引用的對象,第二階段遍歷整個堆,把未標記的對象清除。此算法須要暫停整個應用,同時,會產生內存碎片。簡圖以下:
3.2.4 標記-整理(Mark-Compact)
此算法結合了"標記-清除"和"複製"兩個算法的優勢。也是分兩階段,第一階段從根節點開始標記全部被引用對象,第二階段遍歷整個堆,把清除未標記對象而且把存活對象 "壓縮"到堆的其中一塊,按順序排放。此算法避免了"標記-清除"的碎片問題,同時也避免了"複製"算法的空間問題。簡圖以下:
3.3 分代垃圾收集器
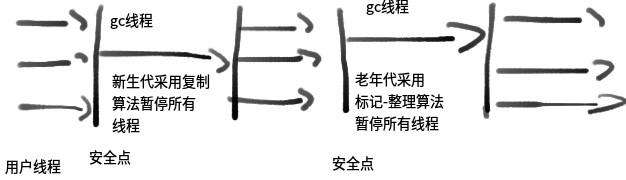
3.3.1 串行收集器(Serial)
Serial 收集器是 Hotspot 運行在 Client 模式下的默認新生代收集器, 它的特色是:只用一個 CPU(計算核心)/一條收集線程去完成 GC 工做, 且在進行垃圾收集時必須暫停其餘全部
的工做線程("Stop The World" -後面簡稱 STW)。可使用-XX:+UseSerialGC 打開。
雖然是單線程收集, 但它卻簡單而高效, 在 VM 管理內存不大的狀況下(收集幾十 M~一兩百 M 的新生代), 停頓時間徹底能夠控制在幾十毫秒~一百多毫秒內。
3.3.2 並行收集器(ParNew)
ParNew 收集器實際上是前面 Serial 的多線程版本, 除使用多條線程進行 GC 外, 包括 Serial 可用的全部控制參數、收集算法、STW、對象分配規則、回收策略等都與 Serial 徹底同樣(也是 VM 啓用 CMS 收集器-XX: +UseConcMarkSweepGC 的默認新生代收集器)。因爲存在線程切換的開銷, ParNew 在單 CPU 的環境中比不上 Serial, 且在經過超線程技術實現的兩個 CPU 的環境中也不能 100%保證能超越 Serial. 但隨着可用的 CPU 數量的增長, 收集效率確定也會大大增長(ParNew 收集線程數與 CPU 的數量相同, 所以在 CPU 數量過大的環境中, 可用-XX:ParallelGCThreads=<N>參數控制 GC 線程數)。
3.3.3 Parallel Scavenge 收集器
與 ParNew 相似, Parallel Scavenge 也是使用複製算法, 也是並行多線程收集器. 但與其餘收集器關注儘量縮短垃圾收集時間不一樣, Parallel Scavenge 更關注系統吞吐量:
系統吞吐量=運行用戶代碼時間/(運行用戶代碼時間+垃圾收集時間)
停頓時間越短就越適用於用戶交互的程序-良好的響應速度能提高用戶的體驗;而高吞吐量則適用於後臺運算而不須要太多交互的任務-能夠最高效率地利用CPU時間,儘快地完成程序的運算任務. Parallel Scavenge 提供了以下參數設置系統吞吐量:

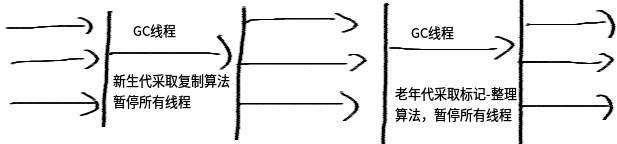
3.3.4 Serial Old 收集器
Serial Old 是 Serial 收集器的老年代版本, 一樣是單線程收集器,使用"標記-整理"算法
3.3.5 Parallel Old 收集器
Parallel Old 是 Parallel Scavenge 收集器的老年代版本, 使用多線程和"標記-整理"算法, 吞吐量優先, 主要與 Parallel Scavenge 配合在注重吞吐量及 CPU 資源敏感系統內使用;
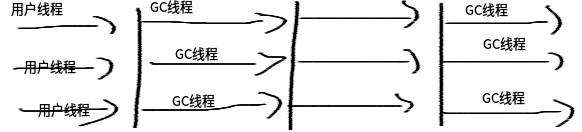
3.3.6 CMS 收集器(Concurrent Mark Sweep)
CMS(Concurrent Mark Sweep)收集器是一款具備劃時代意義的收集器, 一款真正意義上的併發收集器, 雖然如今已經有了理論意義上表現更好的 G1 收集器, 但如今主流互聯網企業線上選用的還是 CMS(如 Taobao、微店).
CMS是一種以獲取最短回收停頓時間爲目標的收集器(CMS又稱多併發低暫停的收集器), 基於"標記-清除"算法實現, 整個 GC 過程分爲如下 4 個步驟:
1. 初始標記(CMS initial mark)
2. 併發標記(CMS concurrent mark: GC Roots Tracing 過程)
3. 從新標記(CMS remark)
4. 併發清除(CMS concurrent sweep: 已死對象將會就地釋放, 注意:此處沒有壓縮)
其中 1,3 兩個步驟(初始標記、從新標記)仍需 STW. 但初始標記僅只標記一下 GC Roots 能直接關聯到的對象, 速度很快; 而從新標記則是爲了修正併發標記期間因用戶程序繼續運行而致使標記產生變更的那一部分對象的標記記錄, 雖然通常比初始標記階段稍長, 但要遠小於併發標記時間.

CMS 特色:
1. CMS 默認啓動的回收線程數=(CPU 數目+3)4
當 CPU 數>4 時, GC 線程通常佔用不超過 25%的 CPU 資源, 可是當 CPU 數<=4 時, GC 線程可能就會過多的佔用用戶 CPU 資源, 從而致使應用程序變慢, 總吞吐量下降.
2.沒法處理浮動垃圾, 可能出現 Promotion Failure、Concurrent Mode Failure 而致使另外一次 Full GC 的產生: 浮動垃圾是指在 CMS 併發清理階段用戶線程運行而產生的新垃圾. 因爲在 GC 階段用戶線程還需運行, 所以還須要預留足夠的內存空間給用戶線程使用, 致使 CMS 不能像其餘收集器那樣等到老年代幾乎填滿了再進行收集. 所以 CMS 提供了
-XX:CMSInitiatingOccupancyFraction 參數來設置 GC 的觸發百分比 ( 以及 -XX:+UseCMSInitiatingOccupancyOnly 來啓用該觸發百分比), 當老年代的使用空間超過該比例後 CMS 就會被觸發(JDK 1.6 以後默認 92%). 但當 CMS 運行期間預留的內存沒法知足程序須要, 就會出現上述 Promotion Failure 等失敗, 這時 VM 將啓動後備預案: 臨時啓用 Serial Old 收集器來從新執行Full GC(CMS一般配合大內存使用, 一旦大內存轉入串行的Serial GC, 那停頓的時間就是你們都不肯看到的了).
3.最後, 因爲 CMS 採用"標記-清除"算法實現, 可能會產生大量內存碎片. 內存碎片過多可能會致使沒法分配大對象而提早觸發 Full GC. 所以 CMS 提供了 -XX:+UseCMSCompactAtFullCollection 開關參數, 用於在 Full GC 後再執行一個碎片整理過程. 但內存整理是沒法併發的, 內存碎片問題雖然沒有了, 但停頓時間也所以變長了, 所以 CMS 還提供了另一個參數-XX:CMSFullGCsBeforeCompaction 用於設置在執行 N 次不進行內存整理的 Full GC 後, 跟着來一次帶整理的(默認爲 0: 每次進入 Full GC 時都進行碎片整理).
3.3.7 分區收集- G1 收集器
G1(Garbage-First)是一款面向服務端應用的收集器, 主要目標用於配備多顆 CPU 的服務器治理大內存.
- G1 is planned as the long term replacement for the Concurrent Mark-Sweep Collector
(CMS).
-XX:+UseG1GC 啓用 G1 收集器.
與其餘基於分代的收集器不一樣, G1 將整個 Java 堆劃分爲多個大小相等的獨立區域 (Region), 雖然還保留有新生代和老年代的概念, 但新生代和老年代再也不是物理隔離的了, 它們都是一部分 Region(不須要連續)的集合.如:
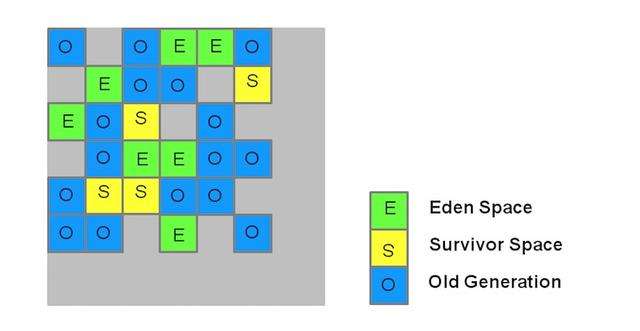
每塊區域既有可能屬於 O 區、也有多是 Y 區, 所以不須要一次就對整個老年代/新生代回收. 而是當線程併發尋找可回收的對象時, 有些區塊包含可回收的對象要比其餘區塊多不少. 雖然在清理這些區塊時 G1 仍然須要暫停應用線程, 但能夠用相對較少的時間優先回收垃圾較多的 Region. 這種方式保證了 G1 能夠在有限的時間內獲取儘量高的收集效率.
G1的新生代收集跟ParNew相似: 存活的對象被轉移到一個/多個Survivor Regions. 若是存活時間達到閥值, 這部分對象就會被提高到老年代.如圖:
其特定是:一整塊堆內存被分爲多個 Regions. 存活對象被拷貝到新的 Survivor 區或老年代. 年輕代內存由一組不連續的 heap 區組成, 這種方法使得能夠動態調整各代區域尺寸.
Young GC 會有 STW 事件, 進行時全部應用程序線程都會被暫停. 多線程併發 GC.
G1 老年代GC 特色以下: 併發標記階段
1 在與應用程序併發執行的過程當中會計算活躍度信息.
2 這些活躍度信息標識出那些regions 最適合在STW 期間回收(which regions will be best to reclaim during an evacuation pause).
3 不像CMS 有清理階段.
再次標記階段
1 使用Snapshot-at-the-Beginning(SATB)算法比CMS 快得多.
2 空region 直接被回收.
拷貝/清理階段(Copying/Cleanup Phase)
1 年輕代與老年代同時回收.
2 老年代內存回收會基於他的活躍度信息.
4 JVM 優化
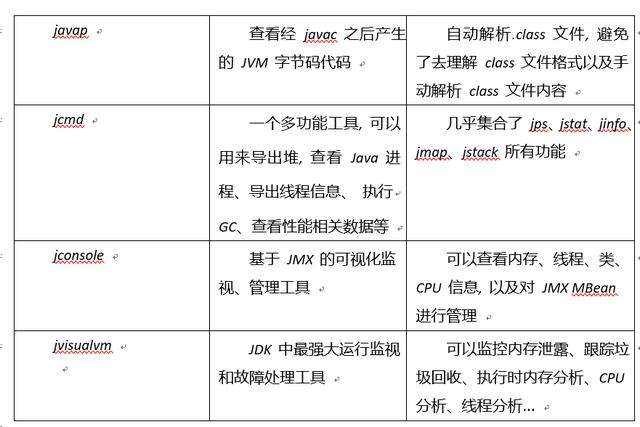
4.1 JDK 經常使用 JVM 優化相關命令
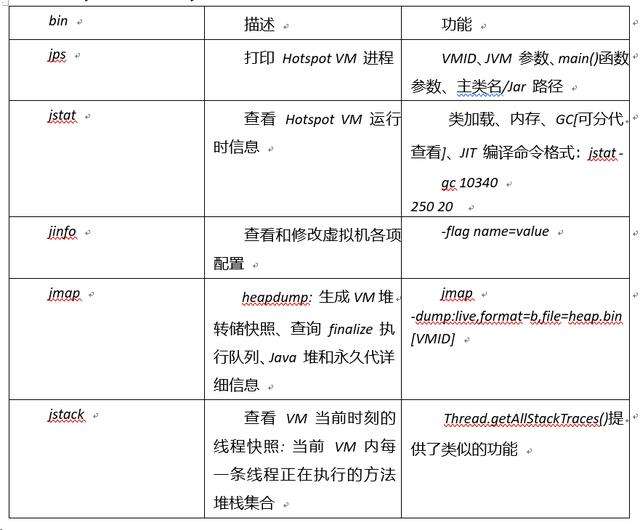
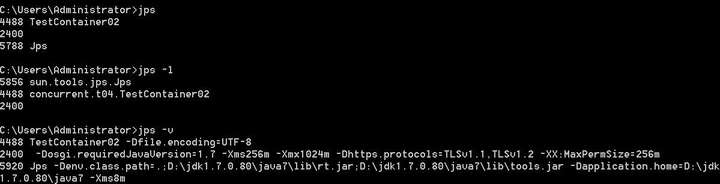
4.1.1 jps
jps - l
顯示線程 id 和執行線程的主類名
jps -v
顯示線程 id 和執行線程的主類名和 JVM 配置信息
4.1.2 jstat
jstat -參數 線程 id 執行時間(單位毫秒) 執行次數
jstat -gc 4488 30 10
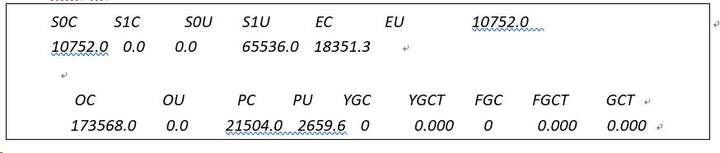
SXC - survivor 初始空間大小,單位字節。
SXU - survivor 使用空間大小, 單位字節。
EC - eden 初始空間大小
EU - eden 使用空間大小
OC - old 初始空間大小
OU - old 使用空間大小
PC - permanent 初始空間大小
PU - permanent 使用空間大小
YGC - youngGC 收集次數
YGCT - youngGC 收集使用時長, 單位秒
FGC - fullGC 收集次數
FGCT - fullGC 收集使用時長
GCT - 總計收集使用總時長 YGCT+FGCT
4.1.3 jvisualvm
一個 JDK 內置的圖形化 VM 監視管理工具
4.1.4 visualgc 插件
重啓 jvisualvm 工具
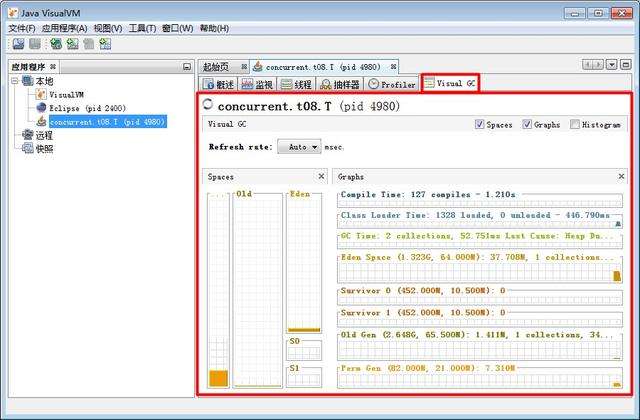
4.2 JVM 常見參數
配置方式:java [options] MainClass [arguments]
options - JVM 啓動參數。 配置多個參數的時候,參數之間使用空格分隔。
參數命名: 常見爲 -參數名
參數賦值: 常見爲 -參數名=參數值 | -參數名:參數值
4.2.1 內存設置
-Xms:初始堆大小,JVM 啓動的時候,給定堆空間大小。
-Xmx:最大堆大小,JVM 運行過程當中,若是初始堆空間不足的時候,最大能夠擴展到多少。
-Xmn:設置年輕代大小。整個堆大小=年輕代大小+年老代大小+持久代大小。持久代通常固定大小爲 64m,因此增大年輕代後,將會減少年老代大小。此值對系統性能影響較大,
Sun 官方推薦配置爲整個堆的 3/8。
-Xss: 設置每一個線程的 Java 棧大小。JDK5.0 之後每一個線程 Java 棧大小爲 1M,之前每一個線程堆棧大小爲 256K。根據應用的線程所需內存大小進行調整。在相同物理內存下,減少這個值能生成更多的線程。可是操做系統對一個進程內的線程數仍是有限制的,不能無限生成,經驗值在 3000~5000 左右。
-XX:NewSize=n:設置年輕代大小
-XX:NewRatio=n:設置年輕代和年老代的比值。如:爲 3,表示年輕代與年老代比值爲 1:
3,年輕代佔整個年輕代+年老代和的 1/4
-XX:SurvivorRatio=n:年輕代中 Eden 區與兩個 Survivor 區的比值。注意 Survivor 區有兩個。
如:3,表示 Eden:Survivor=3:2,一個 Survivor 區佔整個年輕代的 1/5
-XX:MaxPermSize=n:設置持久代大小
-XX:MaxTenuringThreshold:設置垃圾最大年齡。若是設置爲 0 的話,則年輕代對象不通過 Survivor 區,直接進入年老代。對於年老代比較多的應用,能夠提升效率。若是將此值設置爲一個較大值,則年輕代對象會在 Survivor 區進行屢次複製,這樣能夠增長對象再年輕代的存活時間,增長在年輕代即被回收的機率。
4.2.2 內存設置經驗分享
JVM 中最大堆大小有三方面限制:相關操做系統的數據模型(32-bt 仍是 64-bit)限制;系統的可用虛擬內存限制;系統的可用物理內存限制。32 位系統 下,通常限制在 1.5G~2G; 64 爲操做系統對內存無限制。
Tomcat 配置方式: 編寫catalina.bat|catalina.sh,增長JAVA_OPTS 參數設置。windows 和 linux 配置方式不一樣。windows - set "JAVA_OPTS=%JAVA_OPTS% 自定義參數";linux -
JAVA_OPTS="$JAVA_OPTS 自定義參數" 常見設置:
-Xmx3550m -Xms3550m -Xmn2g -Xss128k 適合開發過程的測試應用。要求物理內存大於 4G。
-Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4
-XX:MaxPermSize=160m -XX:MaxTenuringThreshold=0 適合高併發本地測試使用。且大數據對
象相對較多(如 IO 流)
環境: 16G 物理內存,高併發服務,重量級對象中等(線程池,鏈接池等),經常使用對象
比例爲 40%(運行過程當中產生的對象 40%是生命週期較長的)
-Xmx10G -Xms10G -Xss1M -XX:NewRatio=3 -XX:SurvivorRatio=4 -XX:MaxPermSize=2048m
-XX:MaxTenuringThreshold=5
4.2.3 收集器設置
收集器配置的時候,次收集器和全收集器必須匹配。具體匹配規則參考 3.1.3
-XX:+UseSerialGC:設置串行收集器,年輕帶收集器, 次收集器
-XX:+UseParallelGC:設置並行收集器
-XX:+UseParNewGC:設置年輕代爲並行收集。可與 CMS 收集同時使用。JDK5.0 以上,JVM 會根據系統配置自行設置,因此無需再設置此值。
-XX:+UseParallelOldGC:設置並行年老代收集器,JDK6.0 支持對年老代並行收集。
-XX:+UseConcMarkSweepGC:設置年老代併發收集器,測試中配置這個之後,-XX:NewRatio 的配置失效,緣由不明。因此,此時年輕代大小最好用-Xmn 設置。
-XX:+UseG1GC:設置 G1 收集器
4.2.4 垃圾回收統計信息
相似日誌的配置信息。會有控制檯相關信息輸出。 商業項目上線的時候,不容許使用。必定使用 loggc
-XX:+PrintGC
-XX:+Printetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
4.2.5 並行收集器設置
-XX:ParallelGCThreads=n:設置並行收集器收集時最大線程數使用的 CPU 數。並行收集線程數。
-XX:MaxGCPauseMillis=n:設置並行收集最大暫停時間,單位毫秒。能夠減小 STW 時間。
-XX:GCTimeRatio=n:設置垃圾回收時間佔程序運行時間的百分比。公式爲 1/(1+n)併發收集器設置
-XX:+CMSIncrementalMode:設置爲增量模式。適用於單 CPU 狀況。
-XX:+UseAdaptiveSizePolicy:設置此選項後,並行收集器會自動選擇年輕代區大小和相應的 Survivor 區比例,以達到目標系統規定的最低相應時間或者收集頻率等,此值建議使用並行收集器時,一直打開。
-XX:CMSFullGCsBeforeCompaction=n:因爲併發收集器不對內存空間進行壓縮、整理,因此運行一段時間之後會產生"碎片",使得運行效率下降。此值設置運行多少次 GC 之後對內存空間進行壓縮、整理。
-XX:+UseCMSCompactAtFullCollection:打開對年老代的壓縮。可能會影響性能,可是能夠消除碎片
4.2.6 收集器設置經驗分享
關於收集器的選擇 JVM 給了三種選擇:串行收集器、並行收集器、併發收集器,可是
串行收集器只適用於小數據量的狀況,因此這裏的選擇主要針對並行收集器和併發收集器。默認狀況下,JDK5.0 之前都是使用串行收集器,若是想使用其餘收集器須要在啓動時加入相應參數。JDK5.0 之後,JVM 會根據當前系統配置進行判斷。
常見配置:並行收集器主要以到達必定的吞吐量爲目標,適用於科學計算和後臺處理等。
-Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
使用 ParallelGC 做爲並行收集器, GC 線程爲 20(CPU 核心數>=20 時),內存問題根據
硬件配置具體提供。建議使用物理內存的 80%左右做爲 JVM 內存容量。
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelOldGC
指定老年代收集器,在JDK5.0以後的版本,ParallelGC對應的全收集器就是ParallelOldGC。
能夠忽略
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
指定 GC 時最大暫停時間。單位是毫秒。每次 GC 最長使用 100 毫秒。能夠儘量提升
工做線程的執行資源。
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:+UseAdaptiveSizePolicy
UseAdaptiveSizePolicy 是提升年輕代 GC 效率的配置。次收集器執行效率。
併發收集器主要是保證系統的響應時間,減小垃圾收集時的停頓時間。適用於應用服務器、電信領域、互聯網領域等。
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC
指定年輕代收集器爲 ParNew,年老代收集器 ConcurrentMarkSweep,併發 GC 線程數爲 20(CPU 核心>=20),併發 GC 的線程數建議使用(CPU 核心數+3)/4 或 CPU 核心數【不推薦使用】。
-Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
CMSFullGCsBeforeCompaction=5 執行 5 次 GC 後,運行一次內存的整理。
UseCMSCompactAtFullCollection 執行老年代內存整理。能夠避免內存碎片,提升 GC 過程當中的效率,減小停頓時間。
4.2.7 簡單總結
年輕代大小選擇
響應時間優先的應用:儘量設大,直到接近系統的最低響應時間限制(根據實際狀況選擇)。在此種狀況下,年輕代收集發生的頻率也是最小的。同時,減小到達年老代的對象。
吞吐量優先的應用:儘量的設置大,可能到達 Gbit 的程度。由於對響應時間沒有要求,垃圾收集能夠並行進行,通常適合 8CPU 以上的應用。
年老代大小選擇
響應時間優先的應用:年老代使用併發收集器,因此其大小須要當心設置,通常要考慮併發會話率和會話持續時間等一些參數。若是堆設置小了,能夠會形成內存碎片、高回收頻率以及應用暫停而使用傳統的標記清除方式;若是堆大了,則須要較長的收集時間。
最優化的方案,通常須要參考如下數據得到:併發垃圾收集信息持久代併發收集次數
傳統GC信息花在年輕代和年老代回收上的時間比例減小年輕代和年老代花費的時間,通常會提升應用的效率
吞吐量優先的應用:通常吞吐量優先的應用都有一個很大的年輕代和一個較小的年老代。緣由是,這樣能夠儘量回收掉大部分短時間對象,減小中期的對象,而年老代存放長期存活對象。
較小堆引發的碎片問題,由於年老代的併發收集器使用標記、清除算法,因此不會對堆進行壓縮。當收集器回收時,他會把相鄰的空間進行合併,這樣能夠分配給較大的對象。可是,當堆空間較小時,運行一段時間之後,就會出現"碎片",若是併發收集器找不到足夠的空間,那麼併發收集器將會中止,而後使用傳統的標記、整理方式進行回收。若是出現"碎片",可能須要進行以下配置: -XX:+UseCMSCompactAtFullCollection:使用併發收集器時,開啓對年老代的壓縮。
-XX:CMSFullGCsBeforeCompaction=0:上面配置開啓的狀況下,這裏設置多少次 Full GC
後,對年老代進行壓縮
4.2.8 測試代碼

關注公衆號:程序員理想。可得到更多的技術教程與最新技術教學視頻。
- 1. JVM詳解——什麼是JVM、JVM優點
- 2. 【死磕JVM】什麼是JVM調優?
- 3. 什麼是你的核心競爭力?
- 4. 一文帶你讀懂什麼是docker
- 5. JVM調優,基本思路是什麼
- 6. Flutter介紹(是什麼?優勢?核心?)
- 7. SEO的核心是什麼
- 8. DBA核心的價值是什麼(一)
- 9. 數棧技術分享:一文帶你淺析什麼是Hadoop?
- 10. Spring核心是什麼
- 更多相關文章...
- • Hibernate是什麼 - Hibernate教程
- • MyBatis是什麼 - MyBatis教程
- • 三篇文章瞭解 TiDB 技術內幕 —— 談調度
- • 互聯網組織的未來:剖析GitHub員工的任性之源
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. CVPR 2020 論文大盤點-光流篇
- 2. Photoshop教程_ps中怎麼載入圖案?PS圖案如何導入?
- 3. org.pentaho.di.core.exception.KettleDatabaseException:Error occurred while trying to connect to the
- 4. SonarQube Scanner execution execution Error --- Failed to upload report - 500: An error has occurred
- 5. idea 導入源碼包
- 6. python學習 day2——基礎學習
- 7. 3D將是頁遊市場新賽道?
- 8. osg--交互
- 9. OSG-交互
- 10. Idea、spring boot 圖片(pgn顯示、jpg不顯示)解決方案
- 1. JVM詳解——什麼是JVM、JVM優點
- 2. 【死磕JVM】什麼是JVM調優?
- 3. 什麼是你的核心競爭力?
- 4. 一文帶你讀懂什麼是docker
- 5. JVM調優,基本思路是什麼
- 6. Flutter介紹(是什麼?優勢?核心?)
- 7. SEO的核心是什麼
- 8. DBA核心的價值是什麼(一)
- 9. 數棧技術分享:一文帶你淺析什麼是Hadoop?
- 10. Spring核心是什麼