騰訊會議突圍背後:端到端實時語音技術是如何保障交流通暢的?
騰訊會議去年推出,疫情期間兩個月急速擴容,日活躍帳戶數已超過1000萬,成爲了當前中國最多人使用的視頻會議應用。騰訊會議突圍背後,是如何經過端到端實時語音技術保障交流通暢的?本文是騰訊多媒體實驗室音頻技術中心高級總監商世東老師在「雲加社區沙龍online」的分享整理,從實時語音通訊的發展歷程,到5G下語音通訊體驗的將來,爲你一一揭曉。
1、通訊系統的衍變
1. 從模擬電話到數字電話
說到騰訊會議背後的實時語音端到端解決方案,你們可能第一時間就想到了PSTN電話,從貝爾實驗室創造模擬電話開始,通過一百多年的發展,整個語音通訊、語音電話系統經歷了很大一部分變化。尤爲是最近三十年來,語音通話由模擬信號變爲數字信號,從固定電話變爲移動電話,從電路交換到如今的分組交換。算法
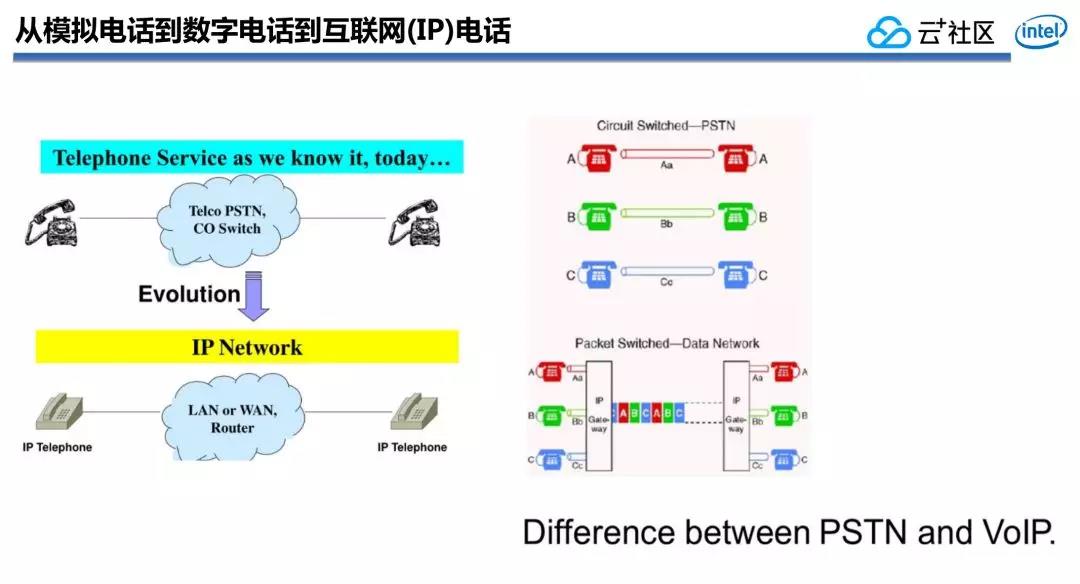
之前的PSTN電話系統,用的都是老式模擬話機。而後數字相對模擬電話的優點是顯而易見的,尤爲在通話語音質量上抗干擾,抗長距離信號衰減的能力明顯優於模擬電話和系統,因此電話系統演進的第一步就是從終端從模擬電話升級到了數字電話,網絡也升級到了ISDN(綜合業務數字網),能夠支持數字語音和數據業務。後端
ISDN的最重要特徵是可以支持端到端的數字鏈接,而且可實現話音業務和數據業務的綜合,使數據和話音可以在同一網絡中傳遞。可是本質上,ISDN仍是電路交換網絡系統。瀏覽器
所謂的電路交換,就是兩個電話之間有一條專有的電路鏈接。基於專有電路鏈接的好處就是通話質量穩定。保證了鏈路的穩定性和通訊的質量,同時也保證了整個通訊的私密性。可是,這種基於電路交換的PSTN電話系統帶來的弊端也很明顯,尤爲是打長途電話的時候。長途電話是基於專有線路,因此價格會很是昂貴。服務器
同時,這一階段,基於IP的互聯網開始蓬勃發展,已通話爲目的的通訊終端也開始了從電路交換到分組交換的演進。如上圖所示,分組交換的好處就是:能夠分享帶寬,整個鏈路鏈接並非通話雙方專享,而是不少電話共享的。共享帶來的好處就是成本大幅度降低,同時,也進一步推進了整個電話語音通訊技術的不斷髮展。網絡
2. 從數字電話到IP電話
從2000年左右,當網絡開始經歷開始從電路交換到IP分組交換這樣的衍進過程中,近十年你們又開始面臨一個新的挑戰:整個網絡、通訊的終端較之前變得紛繁複雜,更加多樣化。架構

之前主要就是電話與電話之間的通話,如今你們可使用各類基於IP網絡的客戶端,好比PC、移動App,電話等通話,電話到電話間能夠經過傳統的電路交換,也能夠是基於IP網絡的數字電話。這樣就致使了一個很顯著的問題:整個網絡開始變得異常複雜,異常多樣化,終端也變成異樣多樣化。app
在這樣一個衍進過程中,如何保證它們之間的互通性?傳統的電話終端,跟不一樣互聯網電話終端之間怎樣解決互聯互通的問題,又如何保證通話的質量和通話的體驗呢?框架
3. H323與SIP協議
對於語音通話,無論是基於VoIP技術,仍是基於傳統的電路交換的電話,都有兩個問題須要解決:首先須要註冊到電話網裏去,註冊進去之後,在撥打電話的過程當中,還須要弄清如下這些問題:怎樣創建一個電話、怎樣維護這個電話,以及最後怎樣關閉這個電話?機器學習
電話創建起來之後還要進行能力協商,若是是IP電話,能力協商的本質就是雙方交換彼此的IP和端口地址,創建邏輯通道才能進行通話。
在PSTN電話網絡向IP電話網絡衍進的過程中,出現了兩個很是有意思的協議族,第一個是H323協議。這個協議來自國際電信聯盟ITO,它是傳統制定電報電信標準的國際化組織。還有一個協議來自於互聯網IETF(互聯網工做組)制定的有關Internet各方面的不少標準。這兩個標準協議的國際化組織各自推出相應的面對互聯網通話的一整套解決方案。
H323協議族解決方案貫徹了ITO組織一向的嚴謹,大包大攬的做風,整個協議族定義的很是完整和詳細。從應用層到下面的傳輸層,使用H.225協議註冊電話,用H225.0協議創建和維護電話,以及用H245在整個電話過程中進行各類能力協商,進行IP地址的交換......這樣一整套協議的制定,包括下面傳輸音視頻使用RTP協議進行碼流的傳輸,用RTCP協議進行整個碼流的帶寬控制,統計信息的上報,以及整個RTP協議上的音視頻編碼格式設置。整個H323協議族定義得很是詳細而又完整,能夠用作互聯網上進行音視頻通話的標準。
這個標準被不少大公司採用,像思科和微軟的產品都遵循過H323標準。可是即便H323標準定義得如此完整和詳細,它的市場推動速度卻依然很慢。
而SIP協議來自IETF互聯網工做組,互聯網工做組的風格是開放和靈活的,因此他的整個協議也徹底繼承了其一向的開放與靈活的思路。總體架構很是簡單,SIP協議相對於H.323來講,並不規定媒體流具體是什麼,只規定信令。整個SIP是利用互聯網上已有的被普遍採用的像HTPP協議進行傳輸,整個message包所有都是用文本格式寫的。因此在它各個不一樣的Entity之間,包括電話、Prosy、DNS、Location servier之間的通訊是開放而又靈活的。
它不規定具體內容,只規定整個SIP協議有什麼框架,什麼樣的網絡結構,SIP模塊之間互相通訊遵循什麼協議,例如用SDP協議來進行通訊。通訊格式也不是二進制,而H323協議就是二進制格式,很是難以擴展和閱讀。
SIP協議很是開放和靈活,因而被不少公司和產品普遍採用,用在互聯網通話過程當中的通話創建,通話維護。可是它也有自身的弊端,那就是各個廠商之間的SIP解決方案每每難以互聯互通。
H232和SIP協議,因爲它們之間的定位不一樣,兩家國際標準化組織的風格不一樣,在市場上也沒有絕對的一家獨大,各自都保留相應的市場份額。也正是由於有了H323或者SIP協議的出現,才使互聯網上基於IP音視頻的通話有了可能。
騰訊會議系統裏面的音頻解決方案正是這兩個協議族和框架,在整個信令的解決方案上採用了H323協議,跟PSTN電話進行互聯互通。在互聯網和VoIP客戶端之間採用SIP協議進行互聯互通。
4. VoIP技術面臨的困難和挑戰
VoIP技術是基於當前這樣複雜IP網絡環境中,一樣面臨不少挑戰。在電路交換中,由於資源是獨佔的,雖然貴可是質量能夠獲得保證。可是基於VoIP的解決方案是分組網絡,不是獨佔資源,就會面臨不少網絡架構上的挑戰,以及來自聲學方面的挑戰。
(1)丟包挑戰
網絡架構上的第一挑戰是丟包,由於不是獨有,並且整個UDP協議也不保證整個包必定送達目的地。
(2)延時挑戰
第二個挑戰是延時。整個IP網絡存在不少交換機、存在各類中間交換節點,在各交換節點會產生延時。
(3)Jitter
第三個挑戰是分組交換獨有的一個概念:Jitter。就是對於延時的變化,雖然從發送的時間上來看,第一個包發出的時間比第二個包要早,可是到達目的地卻多是第二個包先到,致使就算收到第二個包,可是沒有收到第一個包,語音也不能放出來。
(4)回聲問題
VoIP電話相對於PSTN電話,會面臨延時帶來的挑戰,致使咱們在Echo的處理上也和傳統大爲不一樣。
傳統電話不少時候不用考慮Echo,由於本地電話基本延時都能控制在50毫秒之內,人眼是分辨不出來究竟是回聲仍是本身的講話聲音。可是互聯網上由於Delay增大,甚至可能超過150毫秒,因此必需要把回聲問題很好地解決,不然人耳聽起來會感受很是不舒服。
(5)帶寬問題
另外整個網絡的帶寬,也跟通話質量息息相關。若是容量不夠,對於VoIP通話路數和質量也會有很大的影響。

5. 騰訊會議的音視頻解決方案
下圖所示的是VoIP協議棧裏面的一個主要框架,H323協議、SIP協議,它們各自在整個OSI集成網絡模型中對應什麼樣的Layer,不一樣Layer之間是怎樣進行交互的。
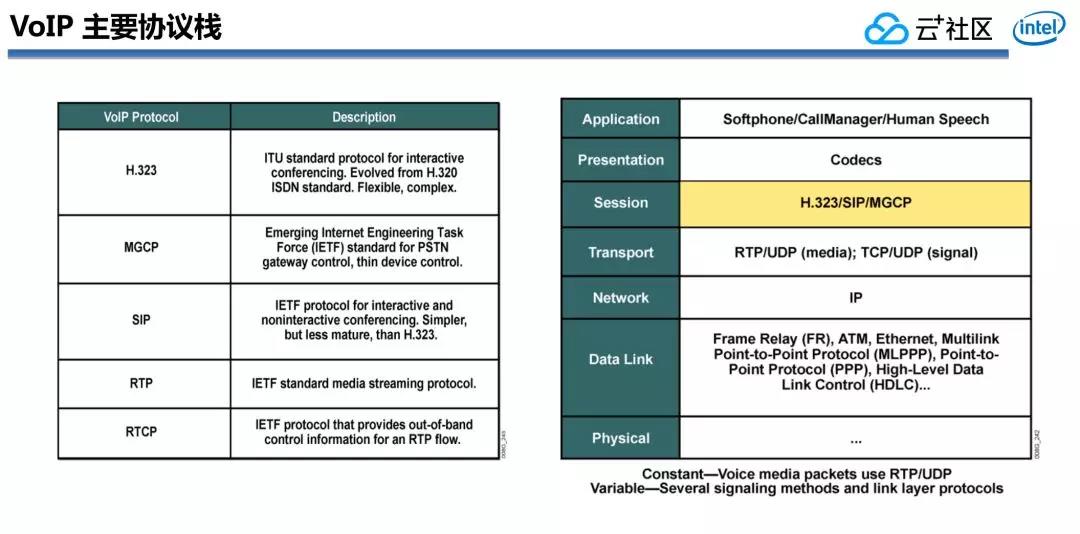
在整個騰訊會議語音通訊裏,H323和SIP信令怎樣才能把呼叫創建起來,創建起來之後最重要的音視頻媒體流在網上又是怎麼傳輸的呢?
(1)實時語音通訊:RTP協議
業界對於實時語音通訊廣泛採用的是RTP協議,RTP協議是基於UDP協議。由於它是UDP協議,因此跟TCP不太同樣,它並不能保證無丟包,它是隻要有包就想盡辦法傳送目的地。

RTP在語音通信的過程當中確定不能直接跑在UDP上,由於語音通話對於丟包,抖動致使的語音卡頓很是敏感,可是也不能採用TCP協議,由於帶來的延時太大。
因此目前你們都會採用RTP協議。RTP協議有一些機制,有兩個典型的字段:Sequence Number 和 Time Stamp。經過這兩個字段保證到達接收端的語音包在不連續或者亂序的狀況下依然能經過必定的機制解決這個問題,在抖動不過大、丟包不過大的狀況下不至於使語音通訊的質量太低。
同時RTP協議裏面,對於電話系統來講,語音通話存在多路流的狀況。多人講話,有音頻、有視頻,因此RTP定義了SRSC Identifier,不一樣的SRSC對應不一樣的音頻流,無論是客戶端仍是服務器均可以根據狀況進行混音或者混流的操做。
(2)Opus語音引擎
基於互聯網的VoIP解決方案其實有不少選擇,從最先的H32三、G.711系列開始前先後後二三十年有幾十種標準出現,可是目前Opus大有一統江湖的趨勢。
從下圖能夠看出,整個Opus 覆蓋了很寬的bite rate,從幾kbps到幾十kbps,Opus不光支持語音,也能夠很好的支持到音樂場景,未來騰訊會議業務範圍在音樂場景上也會佔有必定的比例。
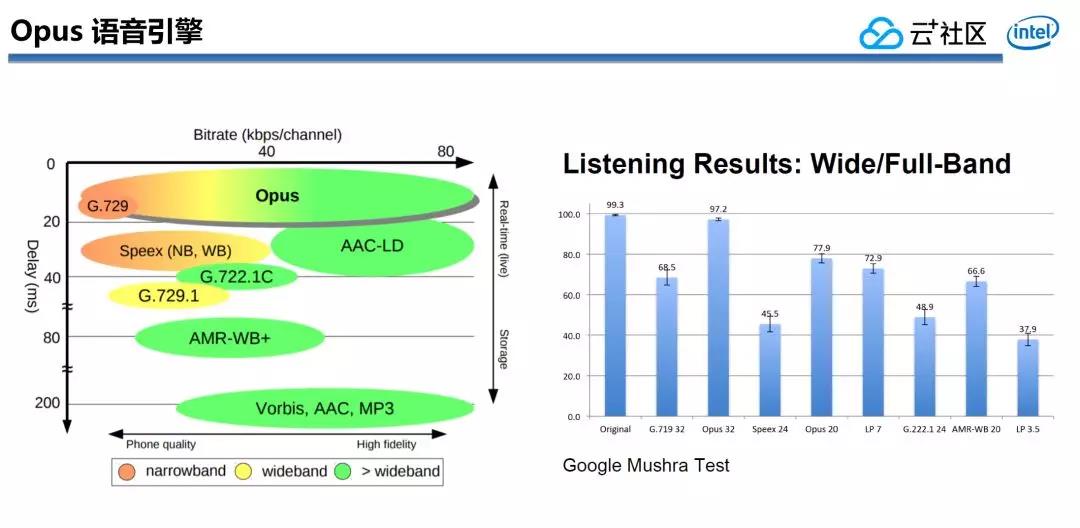
同時Opus仍是一個低延時的語音引擎,由於在實時語音通信中延時顯得至關重要,延時超過200毫秒對於實時語音通訊來講是顯然不行的。
2、騰訊會議用戶痛點和技術難點
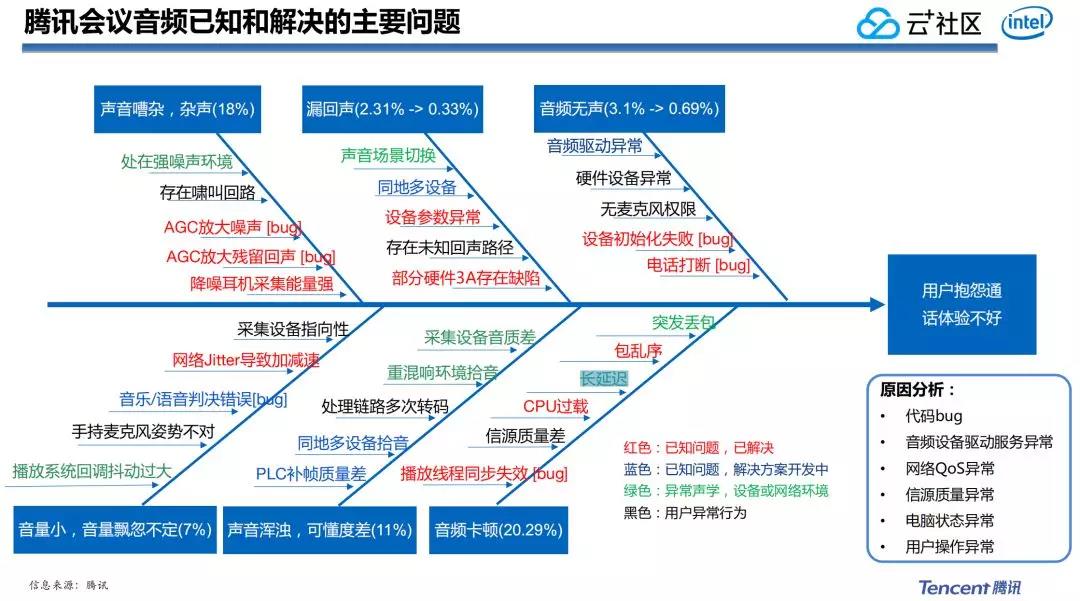
在真正使用技術解決騰訊會議當中的音頻問題的時候,仍是能碰到不少的難點和痛點。咱們在騰訊會議開發過程中發現,用戶在實際的使用體驗過程當中,因爲各類各樣的緣由,致使出現許多問題。
1. 常見聲音問題
(1)無聲問題
首先是無聲問題,例如經過VoIP客戶端或者經過電話入會過程中就能碰到無聲問題,像驅動異常,硬件設備異常,無麥克風權限,設備初始化,電話打斷等也能形成無聲問題。
(2)漏回聲
在實時語音過程中還會出現漏回聲的問題,在傳統的PSTN電話系統中基本不存在回聲,由於延時比較低,並且大部分電話都是話筒模式,不多使用外放。可是使用VoIP客戶端,好比說PC和手機終端,愈來愈多的人喜歡使用外放,而不須要把耳機放在耳朵,這樣就容易產生回聲問題。
(3)聲音嘈雜
一樣還有聲音嘈雜的問題,好比在移動場景,室外,或者是辦公室裏辦公,你們使用VoIP客戶端會常常聽到辦公室裏的敲鍵盤聲音、水杯喝水的聲音,這些嘈雜聲在之前使用普通電話話筒模式下並不明顯。
(4)音量小,飄忽不定
還會有音量小,音量飄忽不定的狀況出現,這也是跟使用的外設和使用的場景相關。像基於PC、Mac或者移動設備的系統播放回調太高,系統CPU載入太高,手持麥克風姿式不對,音樂語音判斷錯誤,還有網絡Jitter致使加減速,這些狀況都會致使會議語音過程當中碰到各類各樣的問題,而在之前的通話裏面基本上沒有這些問題。
(5)聲音渾濁,可懂度差
還有聲音渾濁,可懂度差的問題,如今的實時通話場景比之前複雜的多,假如是在重混響的場景下,或者採集設備不好的環境下面通話,就容易致使聲音的音質比較差。
(6)音頻卡頓
還有像聲音卡頓的問題,這個是全部使用VoIP通話過程中你們都容易經歷到的。聲音卡頓你們第一時間會想到是和網絡相關,可是實際解決問題的過程中,咱們發現有不少的緣由都有可能致使音頻卡頓。網絡雖然佔了很大一塊,但不是全部的緣由。
好比在信源質量差的時候進行聲音信號處理的過程當中會出現卡頓,由於一些很小的語音會被當成噪聲消掉。一樣,CPU過載,播放線程同步失效也會致使卡段,處理回聲採集播放不一樣步的時候,致使漏回聲的現象也會出現卡頓。因此在會議過程中,會有來自不少方面的緣由,致使最後的音質受損。
(7)寬帶語音變窄帶語音
另外咱們還發現了一個頗有意思的現象,咱們公司內部不少在使用IP電話,話機和話機之間的通訊音質一般比較好,可是一旦切入到騰訊會議就會發現話音由原來寬帶的變成了窄帶。
爲何會這樣?不少時候是跟咱們公司IP系統採用的網絡拓撲結構有很大關係。由於不少公司內部不少網段並不能實現互聯互通,這個時候每每須要通過轉碼,提供轉碼服務的語音網關爲了保證最大的兼容性,每每會將原來高品質的語音通話直接轉碼成G.711,這個是三四十年前使用的窄帶標準,能保證最大的兼容性,全部話機和系統都支持,可是音質相應的也會變成窄帶的了。
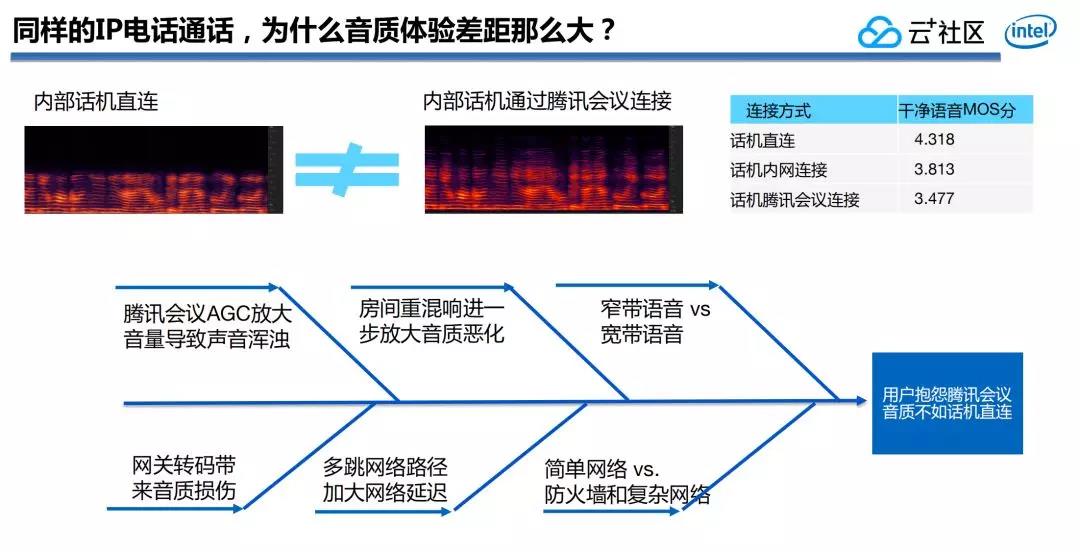
寬帶的語音、窄帶語音,以及房間的重混響,都會致使音質受損,並且咱們發現重混響對人耳的影響跟整個音量大小有關係,當你以爲音量不適合或者過響的時候,那麼在重混響的房間裏音質可能會進一步受損,再加上卡頓或者嘈雜聲等多種因素聚合一起的時候,基於VoIP的通話音質就會受到很大挑戰。
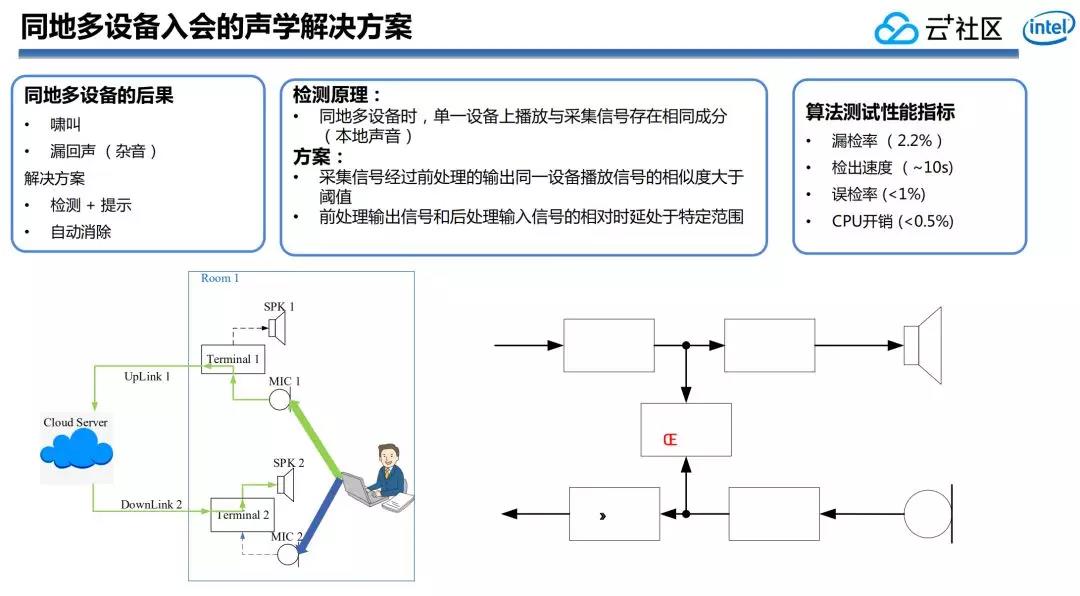
2. 同地多設備入會挑戰
在使用騰訊會議的過程中,還會出現同地多設備的問題。在之前使用電話的場景下,你們基本不會碰到這樣的問題,由於一個房間就一個電話,不存在多個電話、多個聲學設備在同一個地方入會的情形。如今隨着會議解決方案的普及,每一個人電腦上面都能安裝一個協同會議的客戶端,你們習慣性帶着電腦參加會議,分享屏幕和PPT內容。每一個人都進入會議,把他的屏幕分享打開,一會兒會發現,在一個會議室裏面出現了不少個終端在同一個房間入會,一樣多個聲學設備在同一個地方入會,馬上帶來問題就是有回聲。
對於單個設備來講,能夠捕捉到播放信號做爲參考,進而解決回聲問題。可是對於多個設備來講,好比我這檯筆記本的麥克風處理程序是怎麼也不可能拿到另一我的的揚聲器播放出來的聲音參考信號的,因爲網絡延時和當時CPU的狀況不同,這麼作是不現實的。因此一般只能在本機解決簡單的回聲問題,對一樣房間多個聲源設備播放的聲音沒有很好辦法處理。稍微好一點的狀況就是產生漏回聲,差一點的就會直接產生嘯叫。

騰訊會議有一個檢測方案,咱們利用多個設備互相存在的相關性,解決這樣一個同地多設備入會的問題,下文還會詳細展開。
3、AI技術提高會議音頻體驗
在騰訊會議裏面,咱們還採用了什麼樣方法,來提升用戶的通話體驗呢?
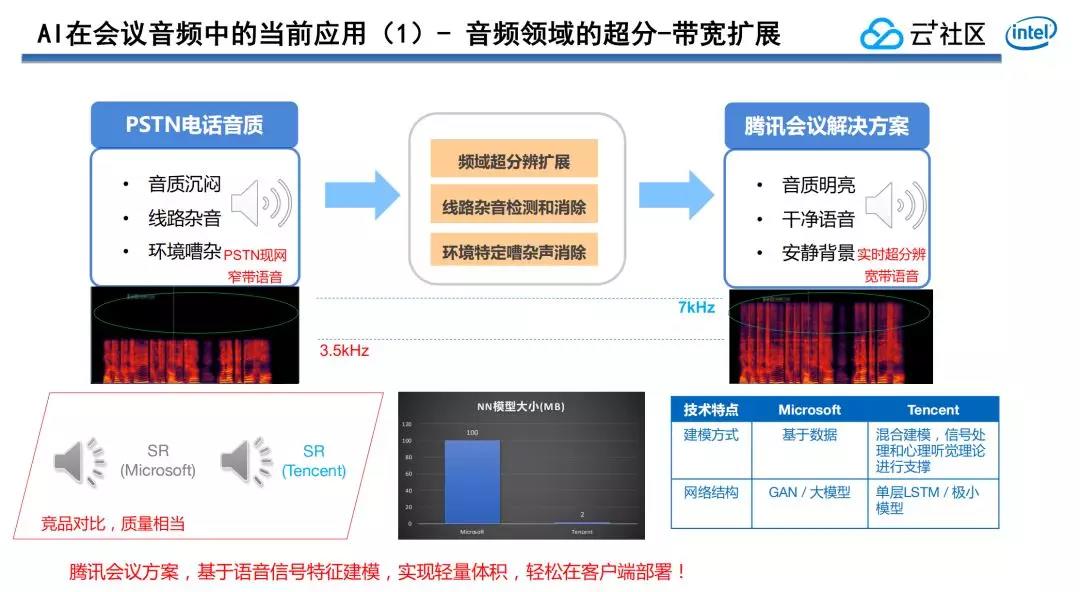
1. 音頻領域的超分—頻寬拓展
第一,咱們在通信會議裏針對一些窄帶語音,特別是來自PSTN的窄帶語音,作了窄帶到寬帶超分辨率擴展。
由於傳統的PSTN電話,音質頻率上限是3.4KHZ,人耳的直接聽感就是聲音不夠明亮,聲音細節不夠豐富,跟VoIP電話比起來,顯得差強人意。藉助AI技術,根據低頻的信息進行預測生成,把高頻的份量很好的補償出來,讓原來聽起來比較沉悶,不夠豐富的語音變得更加明亮,聲音音質變得更加豐滿。
2. 丟包隱藏技術
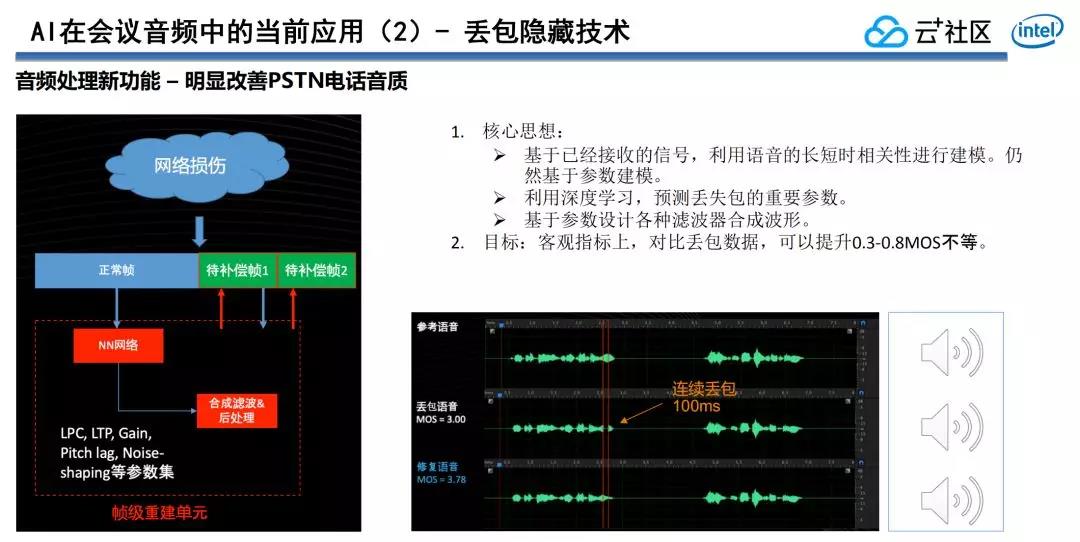
第二,藉助人工智能解決IP網絡裏面臨的丟包挑戰,丟包這個問題自己有不少種解決方案,在傳輸層面能夠解決,經過FEC方案在網絡層面均可以解決。可是網絡層面解決丟包問題自己侷限性,無論是ARQ仍是FEC方案都會伴隨着帶寬的增長或者是延時的增長,形成很差的體驗。
在聲學層面上,語音信號或者是語言幀之間是存在必定的相關性的。正常人說話的時候,一個字節大概時長爲200毫秒,假設一秒最多說五個字,每一個字段時長爲200毫秒,對於咱們語音幀來講,以20毫秒爲單位時長進行編包。經過丟包隱藏技術,並不須要每個包都要收到,丟的語音包只要不是特別多的像突發大批量的丟包,而只是零星的丟包,或者是網絡抖動帶來的丟包狀況,均可以在聲學上經過數字信號處理技術和機器深度學習的技術把這些丟包彌補還原出來。
這樣在對語音幀的參數進行編碼的時候,咱們能夠經過一些數字信號處理技術和深度學習技術把丟失的參數預測出來,在信號層面經過各類濾波器把丟失掉的信號合成出來,再跟網絡傳輸層自己的FEC或者AIQ技術結合起來,能夠很好解決網絡上丟包和抖動的挑戰。
3. 降噪語言加強
語音通訊另一個很強的需求就是降噪,你們都不想聽到環境噪聲,最想關注的就是語音自己。傳統的降噪技術,通過了三四十年的發展,無論是基於統計學或者是其餘的方法已經能夠很好的解決傳統平穩噪聲的降噪,可以準確估計出平穩噪聲。
可是對於如今常見的非平穩,突發的聲音的降噪,經典的語音處理技術就相形見絀了。騰訊會議音頻解決方案是利用機器學習方法來訓練模型,不斷學習突發噪聲自己具備的特性,如噪聲頻譜特性等,最終很好的把這些傳統的數字信號技術解決不了的如鍵盤聲、鼠標聲、喝水水杯聲、手機震動聲等等這些突發的聲音消除掉。

4. 語音音樂分類器
另外會議須要考慮音樂的存在場景,好比老師給學生講課,時常會作一些視頻內容的分享,這個時候就會存在高品質的背景音樂出現。若是咱們的方案僅僅能處理語音,卻不能處理音樂,對咱們的一些應用場景就會有比較大的限制,因此以下圖所示,咱們研發了這樣的語音音樂分類器,可以很好的將背景音樂集成到會議音頻中去。

4、音頻質量評估體系
對於像騰訊會議這樣支持上千萬DAU的互聯網產品來講,對於音頻的實時監控和音質評估是很是重要的。咱們在整個騰訊會議開發期間,很大程度上借鑑實施了基於ITO國際電信聯盟對於通訊音質的測試評估方案,以下圖所示,在音質測試評估方案中,咱們配備了標準的人工頭,標準的參考設備,來對總體語音通話的音質進行測試和評估。

整套評估方案咱們參考了ITU,3GPP的標準,對在不一樣的聲源環境,不一樣的測試碼流,不一樣的聲源條件下,各類不一樣的測試場景都有完整的定義,對於單向的語音通話,雙講,消除漏回聲,降噪,評估語音SMOS和NMOS分數都有相應的標準。
如何對騰訊會議處理過的音質信號進行打分,怎樣判斷音質是否知足要求?咱們已經造成了一整套完整的語音質量評估體系,來對整個端到端的語音通訊質量進行評估。
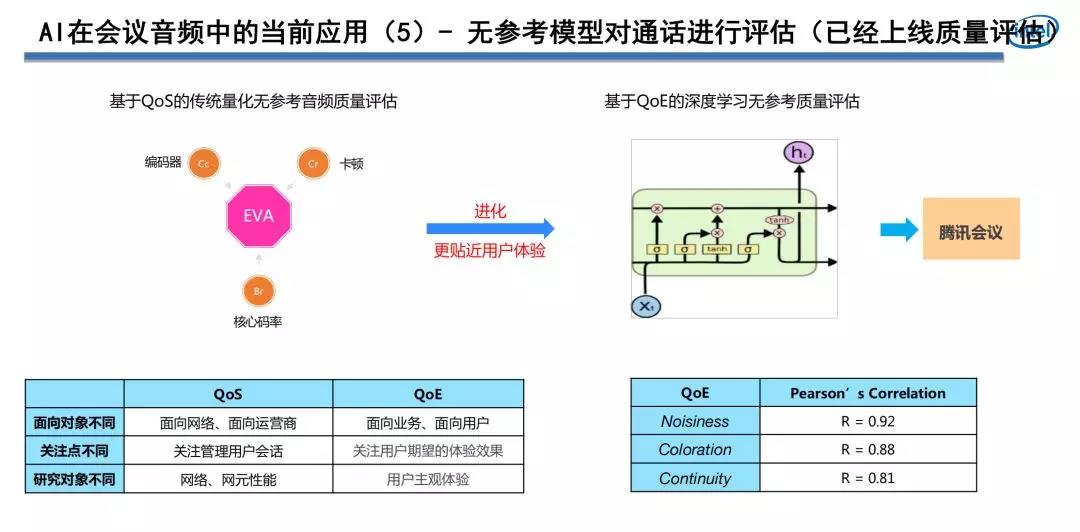
之前在整個語音通話過程中,無參考的音質評估廣泛基於QoS參數模型的評估方案,更可能是從使用的編碼器類型,通話過程中是否有丟包,延遲多少,整個音質使用的碼流是多少,這些點出發,再根據參數推導出整個通話過程當中的音質是怎樣的。
這種方案對於運營商或者網絡規劃部門比較有用,由於他能夠拿到這些參數。對於用戶來講,就沒有那樣的直觀感覺了。
對於用戶來講,能直觀感覺到的就是:是否存在漏回聲,語音通話是否連續,通話音質是否天然等等。對於用戶來講更多會關注QoE角度,從我的體驗角度來看整個通話體驗是否獲得滿意。咱們把QoE指標進一步細化,主要看通話過程當中的嘈雜聲程度,整個通話語音的色彩度(通話語音的天然度),是否有變聲和機械音,或者其餘聽起來不天然的聲音,以及整個通話過程當中語音是否存在卡頓?
人講話自己是有卡頓的,我說一個字後會短暫停一下再說下一個字。這種卡頓跟網絡丟包和網絡抖動帶來的卡頓是有明顯區別的,咱們經過數字信號處理方案和機器學習技術從QoE這三個不一樣維度,對音頻進行無參考語音通訊打分,這樣就能從現網上得知,用戶使用的通訊會議效果是怎樣的。以下圖所示,用咱們的無參考打分模型,跟有參考的數據進行擬合,能夠看出,擬合的程度很是高。

基於無參考語音通話模型咱們對現網通話質量能夠有較好的把握,不須要拿到具體某一個語音的參考信號,僅僅根據播放端收到的信號,就能知道通話質量如今是否正常,若是不正常問題大概出如今什麼地方。
5、會議音頻系統的將來展望
在會議音頻領域,除了通話之外,還有關於會議轉錄的需求。
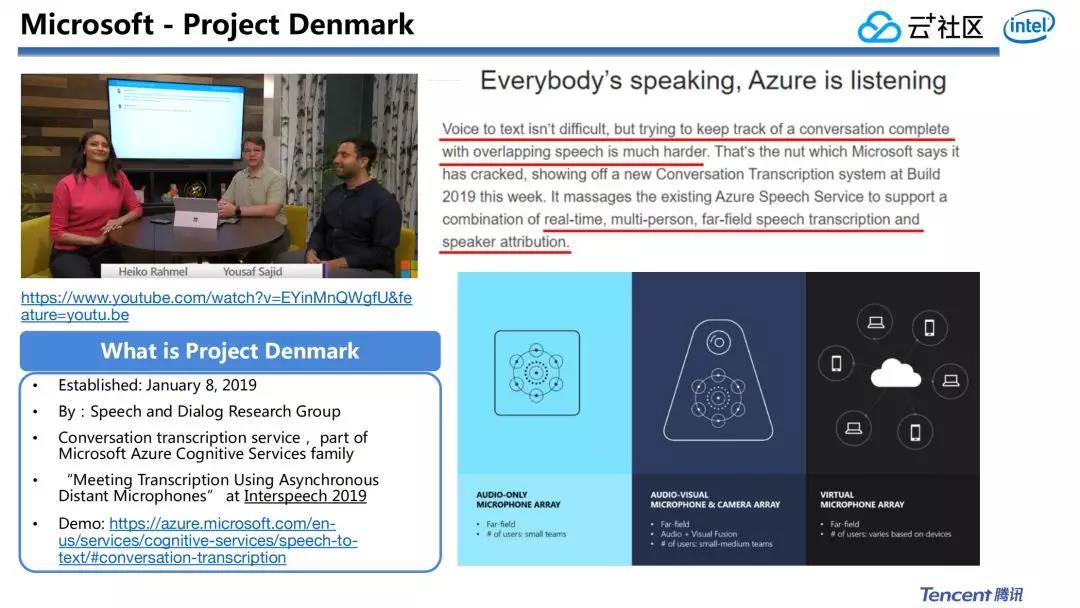
微軟2019年年初宣佈—Project Denmark,能夠用手機和Pad採集不一樣會議講話人的聲音,而且把不一樣講話人聲音進行分離。咱們知道,在一個會議室多我的同時說話,講話人聲音單純用ASR進行語音識別是沒法實現的。最理想方法是把不一樣講話人分離出來,再分別接ASR的後端進行語音到文字的轉換。
一旦語音轉成文字之後,後面就能夠作不少事情,好比生成會議紀要,對內容進行檢索,能夠郵件發出來給沒有參加會議的人瀏覽觀看等等。
思科也在作一樣的事情,思科近期收購了一家公司,這個公司也是作會議內容轉錄。
可是會議人聲轉錄這裏面會存在幾個問題:ASR識別。ASR識別提供了不少很好的語言識別解決方案,好比對方言的識別,對基礎的專有名詞的識別,ASR也提供了比較好的方案先後端進行調試。

對於同一房間多人開會的會議音頻轉錄來講最大挑戰是:如何在多人會議場景下對連續說話人進行檢測和切換?假如我說話的時候被別人打斷了,或者是兩我的講話的聲音重疊在一塊兒,這個時候怎麼有效把聲音進行切割分離呢?若是多人說話在時間線上不相關,這個時候切割相對是比較容易的,經過聲音識別把不一樣講話人識別出來就能夠了。
可是若是他們說話有重疊的時候怎麼進一步分離呢?包括切割出來信號怎麼進行聚類,剛纔講了幾句,後面又講幾句,中間又插進來一些別的人說話,怎麼把我以前講的和以後講的話聚合到一塊兒?這些相關的技術對於整個會議轉錄來講都是很是重要的,目前有不少公司也在這方面加大投入,騰訊也有在作這樣的事情。
除了會議轉錄需求以外,整個VoIP技術也是在不斷的演進過程中。經常聽到有人問:整個5G對於語音通信意味着什麼?有人以爲語音5G帶寬那麼大,語音通話帶寬這麼小,沒有太大意義。
其實否則,5G其實會爲VoIP技術提供更大更好的舞臺。首先是帶寬對於會議語音通信的推進做用,雖然語音自己的帶寬很小,只有幾十kbps,可是對於會議音頻來講狀況遠比這個複雜。會議當中除了傳輸語音以外,還能夠傳輸高品質的音頻,高品質的音頻就不是十幾K能夠搞定的。會議講話人也可能不僅是一路,會議當中同時開麥就會有好幾路產生,這種狀況下對於會議音頻的帶寬消耗是很快的,在網絡條件不容許的狀況下就有可能致使網絡擁塞。而5G一旦把帶寬上限拉大之後,會爲會議音頻提供更大更好的舞臺,咱們能夠提供更優質和更高品質的音質。
5G也能夠極大改善延時,幾百毫秒的延時其實很大一部分都是消耗在傳輸延時上,可是5G能夠令傳輸延時下降到原來的十分之一,對於整個實時可交互性體驗是很大的提升。
因此5G技術的發展,能爲語音通話更好的聲音體驗,更沉浸式的體驗。只要帶寬不受限制,讓在會議音頻上實現基於AR、VR帶來的沉浸式體驗成爲可能,當延時大幅度縮減之後,會議交互性也會更好。若是交互性能更進一步提升,其實跟人面對面溝通就沒有太大的區別了,這就是技術帶來的發展。
從整個商業角度來講,咱們看到不少的變化正在發生。像融合通訊,更可能是做爲service被愈來愈多場景使用,如今愈來愈少的人採用電話設備,都是採用雲的方式,由於帶來的初始成本下降是很是顯著的。
人工智能技術將來也會爲語音通信帶來愈來愈好的體驗,如前文提到的智能降噪、智能丟包補償技術就能夠很好解決原來的一些問題,進而提供比原來PSTN網絡更好的音質體驗。
WebRTC技術也將會獲得普及,WebRTC也有一整套的協議族,在瀏覽器裏獲得廣泛支持之後,VoIP技術藉助WebRTC能在不少場景裏獲得普遍的應用。由於VoIP技術獲得普遍的普及,在In-app communications裏的應用也會愈來愈多。
IoT領域VoIP技術也出現了上升趨勢,家裏的智能音箱、智能冰箱等設備將來都會帶一些通信功能,經過IP網絡進行鏈接。
Smarter VoIP assistants技術也會獲得更多的發展, Smarter VoIP assistants是基於VoIP通話過程當中提供的人工智能語音助手,來解決通信過程當中的語音問題。

6、Q&A
Q:老師關於實時音視頻通訊能夠推薦經典的書和開源項目嗎?
A:WebRTC就是很好的開源項目,基於WebRTC書籍也有,在網絡上搜索WebRTC也有很好的博客,關於WebRTC架構,裏面核心的技術都有比較好的介紹,上網能夠搜到。
Q:關於本地多設備的解決方案,能詳細講解一下嗎?
A:本地多設備是這樣,雖然本機的採集能夠拿到本機的信號,從而能夠作回聲抵消,可是本地的採集是不可能拿到房間裏面另一個設備的播放信號的,這是同地多設備問題的核心所在。咱們雖然不能拿到另一個設備的播放信號做爲參考,可是這個本地播放設備,跟同房間另一個播放設備之間存在很強的相關性。由於他們都來自於一樣的聲源,只是通過不一樣的網絡,不一樣的設備播放出來的時候,會有不一樣的失真和延時。因此咱們不必定能作到同地多設備致使的嘯叫或者回聲抑制,可是必定作到同地多設備的檢測,一旦檢測同地多設備的時候,就能夠用不一樣的產品策略來解決這個問題。由於同地多設備消除是很是困難,假若有三五個設備同時入會,打開麥克風,這簡直就是災難,要解決這個問題帶來聲學挑戰對於CPU消耗會很是大,很不值得,因此作好檢測就能夠了。
Q:不少直播間都在使用WebRTC,老師談談WebRTC是否有發展前景?
A:WebRTC頗有發展前景,它首先是開源項目。WebRTC在實時音視頻傳輸的時候,特別是對於網絡NAT技術,網絡穿越技術解決方案上都有很獨到的地方。WebRTC對於音視頻自己的編解碼,音頻的前處理都有一些相關的方案,WebRTC在不少場景都是很不錯的解決方案。
Q:重混響失音,怎麼樣提升語音清晰度?
A:第一是多通道採集。使用麥克風陣列技術,經過方向性,好比說我在這個房間講話,個人聲音通過牆壁和桌子反射之後會被麥克風採集,形成干擾。若是麥克風是陣列形式,就能夠很好對講話人進行聲源追蹤,儘可能只採集個人直達聲,而屏蔽掉來自牆壁和桌面的反射聲,這樣能夠很好的解決重混響問題。對於單通道麥克風的聲音採集,無論是經典的數字信號處理技術,仍是機器學習均可以解決這個問題,但由於畢竟是一個過濾處理,有可能會致使音質受損,因此在單通道條件下去作混響處理,並非一件很容易的事。
Q:VoIP和VoLTE相比,有什麼優缺點?
A:VoIP和VoLTE走的思路不同。VoLTE傳輸的音視頻流,須要QoS保障,語音比較高,發生網絡擁塞優先傳輸語音,數據能夠等等,差幾十毫秒沒有關係。因此VoLTE必定是保證帶寬,保證低延時的。從QoS角度來說,VoLTE有必定優點,可是當5G帶寬高速公路愈來愈好以後,會發現VoLTE和VoIP相比就沒有太多優點了。隨着將來5G的大規模普及,VoIP質量能夠作得很是好。
Q:老師,出現卡頓時的具體解決的方法是什麼?
A:出現卡頓具體解決方案有不少,關鍵要看卡頓的具體緣由是什麼。是網絡致使的卡頓,仍是設備自己致使的卡頓,若是是網絡致使的卡頓就要看是網絡丟包致使仍是抖動致使的,FEC技術能夠解決必定的丟包問題,若是是抖動過大,就把Jitter包放大一點,雖然延時受損,可是能夠解決抖動帶來的卡頓。若是是設備自己有問題,多是CPU佔用率太高,調度不過來。有時候信源也會致使卡頓,好比我忽然轉過頭說話,麥克風定向採集個人講話聲音和原先聲音不匹配,這個時候就會忽然聽到聲音變小,後臺音效處理也會出現卡頓,因此卡頓緣由比較複雜,須要分析緣由有針對性的加以解決。
Q:大型直播,好比賽事比賽,發佈會等直播,主要是用hls、flv等,5G時代是否能夠用WebRTC技術呢?
A:兩個場景不同,直播的時候可能會跳動,或者VOD播放的時候若是延時比較大也沒有關係,延時超過200毫秒,500毫秒,甚至1秒都沒事,直播雖然晚一秒也不妨礙觀看和體驗。可是實時語音通訊就不能夠,超過300毫秒,甚至打電話1秒以後纔回過來這確定不行。我不以爲它們會用RTC技術,它們仍是會用RTMP推流,或者HLS切包發送這樣的技術,由於雖然會帶來延時,可是在網絡抖動處理,包括其餘不少方面都能處理得更好。因此適用的場景不同,將來作不一樣技術的考慮點也會不同。
Q:同地多設備沒有辦法拿到其餘設備的參考聲音,經過什麼辦法作到回聲消除?
A:同地多設備是沒有拿到其餘設備的參考聲音,可是實際上採集聲音之間仍是存在必定的相關性的,在算法上能夠作出判斷和處理。
Q:深度學習算法對於音頻前處理相對於之前傳統的方法有什麼區別?
A:有區別,傳統的數字信號處理方法在不一樣的場景下很難作到精準的定位,好比一些傳統的數字信號處理技術,對於突發的噪聲沒有很好的處理辦法。可是這種非線性的聲音用深度學習算法能夠處理得很好,在擬合的時候可以把傳統方式處理很差的問題,如殘留回聲、突發噪聲、降噪問題包括聚合的問題更好的解決。
Q:騰訊會議是在WebRTC框架嗎?
A:不是,騰訊會議不是在WebRTC框架下開發的。
Q:IoT應用就是智能傢俱產品應用嗎?
A:是,愈來愈多智能傢俱會使用IoT技術,如智能音箱等將來更多也會集成語音通訊的技術。
Q:語音問題是一直存在的,很好奇騰訊會議是經過什麼來收集和了解到那些問題的?一個在線的視頻語音產品怎麼監測用戶語音的視頻質量?
A:咱們須要無參考語音評估系統,有了無參考語音評估系統,就能夠知道現網通訊當中的語言質量是怎麼樣的,是否存在問題,是什麼樣的問題,問題出如今哪一個區域、哪一個時間段,或者發生在哪一個外設上等等。
Q:對聲源定位,麥克風陣列有什麼好的分享嗎?
A:聲源定位,麥克風陣列上有不少技術能夠作,如DOA技術,麥克風陣列技術,傳統算法都是用來作語音信號處理的,上面有不少引伸的技術發展出來,具體能夠參考谷歌上的詳細介紹,回答得更有深度,我這裏粗粗介紹一下。
Q:音頻質量的主觀、客評估手段用哪一個參數來評估比較合適?
A:主觀評估就是召集人來打分,對於客觀評估,ITO對應有一個P863標準,參考這樣的語音標準對客觀指標進行打分,能夠更進一步評估噪聲卡頓,語音質量等。
Q:老師,關於丟包處理補償處理,以前學校通訊課程上老師有講過交叉幀處理的方式而後讓丟失的包分佈在各個幀,利用幀數據之間的關聯來補償丟包?騰訊會議的丟包處理也是相似這樣的處理嗎,深度學習處理的大致思路是什麼呢?
A:學校老師在課堂講的是針對突發大丟包的狀況,把包分散到各個不一樣分組裏面,收到組裏面突發丟失的那一塊之後能夠經過FEC技術將收到包復原出來。和這裏不太同樣,分組交織能夠解決必定的丟包問題,可是代價是延時過大,你把一個包或者多個包分到不一樣組,交織開來,收集的時候必須等全部包都收集完之後,才能把語音流復原出來,這樣就會帶來語言延時過大的問題。
Q:穿透轉發服務器搭建方面,騰訊能提供服務嗎?
A:關於WebRTC提供的穿越技術,騰訊雲也提供解決方案,可是騰訊會議使用的相關技術是供騰訊會議使用的,若是在你的解決方案裏須要騰訊雲提供針對網絡穿越的NAT相關技術,是能夠作到的。
Q:請問質量評估是否能夠這樣作:本地進行抽樣,而後異步傳送(由於不須要實時,因此能夠直接用TCP發送)給服務端,服務端對一樣區間的實時音頻流的數據進行抽樣,來做對比。
A:在測試過程中能夠作,在現網當中固然也能夠作,可是自己抽樣會有很大侷限性。像騰訊會議這樣千萬級DAU的產品,不太可能進行抽樣,抽樣對於評價現網也有很大侷限性,咱們更多建議經過無參考質量評估的手段搭建模型,對現網全部的數據進行實時評估。
講師簡介
商世東,騰訊多媒體實驗室高級總監,於2019年初加入騰訊多媒體實驗室,擔任多媒體實驗室音頻技術中心高級總監。加入騰訊前,商世東於2010年組建了杜比北京工程團隊,任職杜比北京和悉尼工程團隊高級總監9年。加入騰訊後,帶領多媒體實驗室音頻技術中心,負責實時音視頻SDK中的音頻引擎,音頻處理的設計和開發工做。
關注雲加社區公衆號,回覆「在線沙龍」,便可獲取老師演講PPT~
- 1. 騰訊會議突圍背後:端到端實時語音技術是如何保障交流通暢的?
- 2. SpringBoot & 後端技術交流
- 3. 騰訊的前端工程師,是如何精進技術的?
- 4. 先後端如何通訊
- 5. 騰訊FPGA雲-背後的技術
- 6. 前端如何實現即時通訊?
- 7. 騰訊技術開放日 | 保障視頻連線畫質清晰且流暢,騰訊會議有這些優化實踐
- 8. 騰訊C2B一年後,金融雲如何突圍?
- 9. 後端技術交流社羣
- 10. 後端進階技術交流羣
- 更多相關文章...
- • 數據庫涉及到哪些技術? - MySQL教程
- • Hibernate的快照技術 - Hibernate教程
- • Docker容器實戰(一) - 封神Server端技術
- • 使用阿里雲OSS+CDN部署前端頁面與加速靜態資源
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Duang!超快Wi-Fi來襲
- 2. 機器學習-補充03 神經網絡之**函數(Activation Function)
- 3. git上開源maven項目部署 多module maven項目(多module maven+redis+tomcat+mysql)後臺部署流程學習記錄
- 4. ecliple-tomcat部署maven項目方式之一
- 5. eclipse新導入的項目經常可以看到「XX cannot be resolved to a type」的報錯信息
- 6. Spark RDD的依賴於DAG的工作原理
- 7. VMware安裝CentOS-8教程詳解
- 8. YDOOK:Java 項目 Spring 項目導入基本四大 jar 包 導入依賴,怎樣在 IDEA 的項目結構中導入 jar 包 導入依賴
- 9. 簡單方法使得putty(windows10上)可以免密登錄樹莓派
- 10. idea怎麼用本地maven