Protocol Buffers 序列化協議及應用
Protocol Buffers是Google開發一種數據描述語言,可以將結構化數據序列化,可用於數據存儲、通訊協議等方面。據Google官方文檔介紹,如今Google內部已經有48,162個消息類型定義在12,183個proto文件中。本文會從快速入門、語言規範、編碼協議、性能評估等幾個方面對Prototol Buffers進行介紹。java


不瞭解Protocol Buffers的同窗能夠把它理解爲更快、更簡單、更小的JSON或者XML,區別在於Protocol Buffers是二進制格式,而JSON和XML是文本格式。python

相對於XML,Protocol Buffers的具備以下幾個優勢:git
- 簡潔
- 體積小:消息大小隻須要XML的1/10 ~ 1/3
- 速度快:解析速度比XML快20 ~ 100倍
- 使用Protocol Buffers的編譯器,能夠生成更容易在編程中使用的數據訪問代碼
- 更好的兼容性,Protocol Buffers設計的一個原則就是要可以很好的支持向下或向上兼容。

看一個簡單的對比例子,表達一個用戶的三個基本的屬性,若是使用XML消息體大小爲82 bytes。github
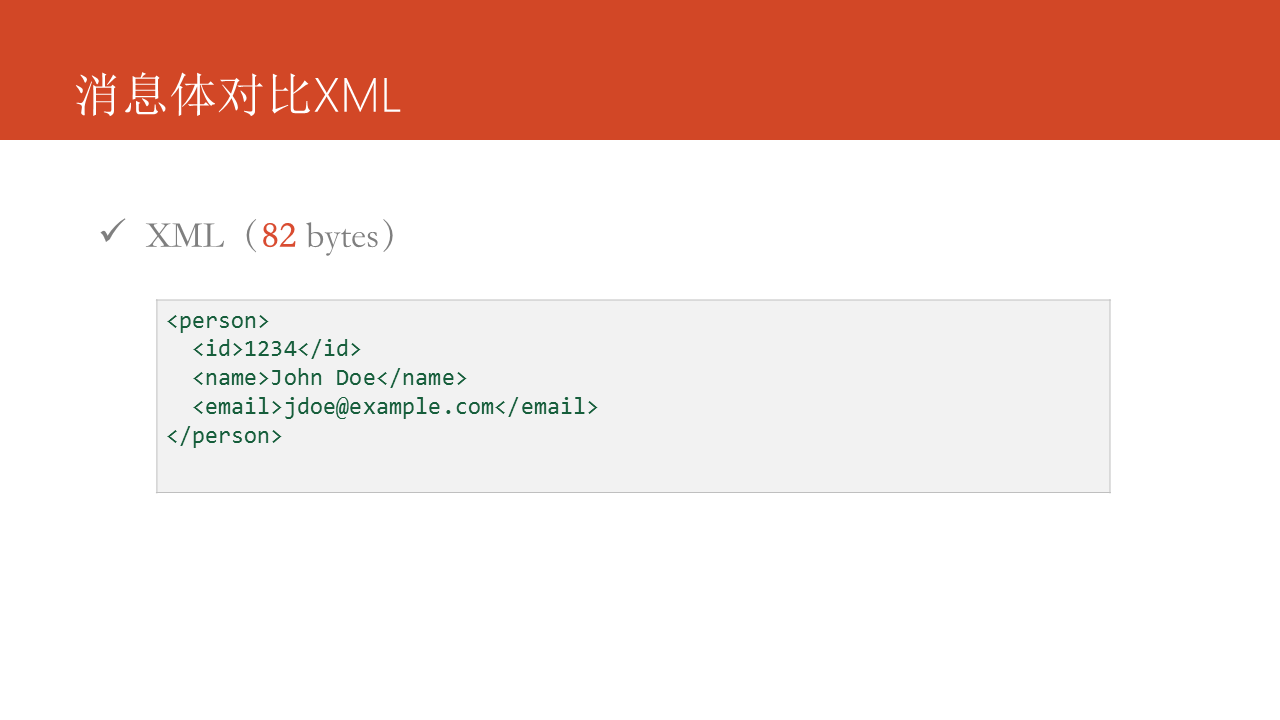
若是使用JSON消息體大小爲56 bytes。編程

使用Protocol Buffers咋則只須要 31 bytes,看到這些二進制數據你們能夠暫時忽略,後面會具體分析這些二進制數據是如何編碼的。json

接下來先看一個簡單的入門示例,在該例子中咱們從準備環境開始,編寫proto文件,到最後使用Protocol Buffers編譯器生成代碼,再到具體的使用。ruby

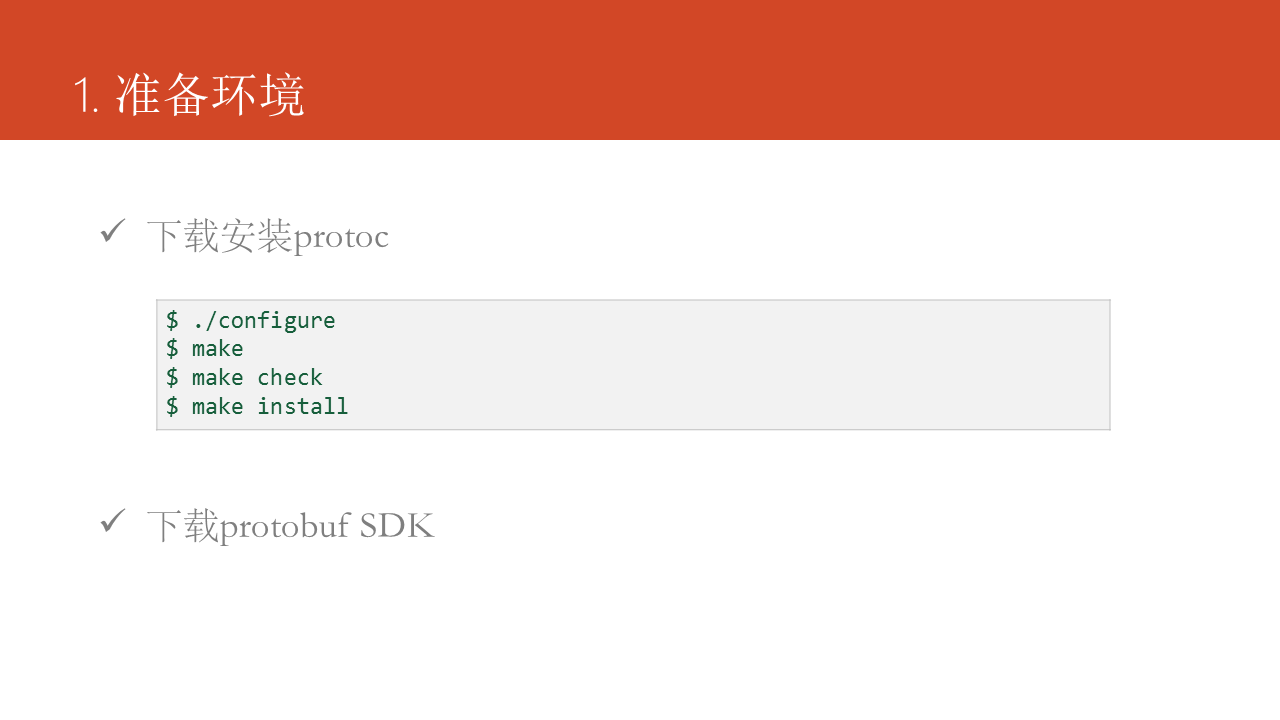
從https://github.com/google/protobuf下載編譯安裝protoc,並下載Protobuf SDK。框架
開始編寫proto文件,使用message關鍵字定義消息類型,消息中每一個字段須要指定字段類型和字段序號。同一個message中字段性能

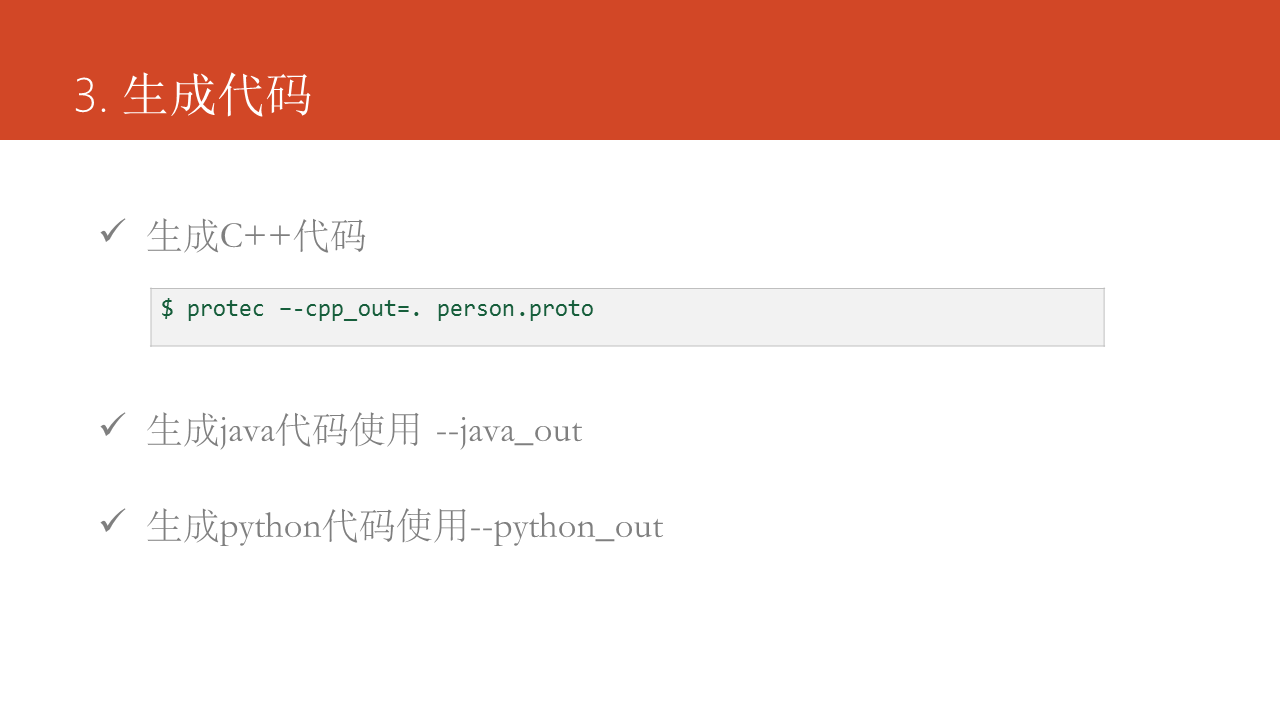
使用protoc命令生成代碼,使用--cpp_out、--java_out、--python_out命令選項能夠生成C++、Java、Python代碼,在最新版本Protocol Buffers v3中還加入了ruby語言的支持。測試
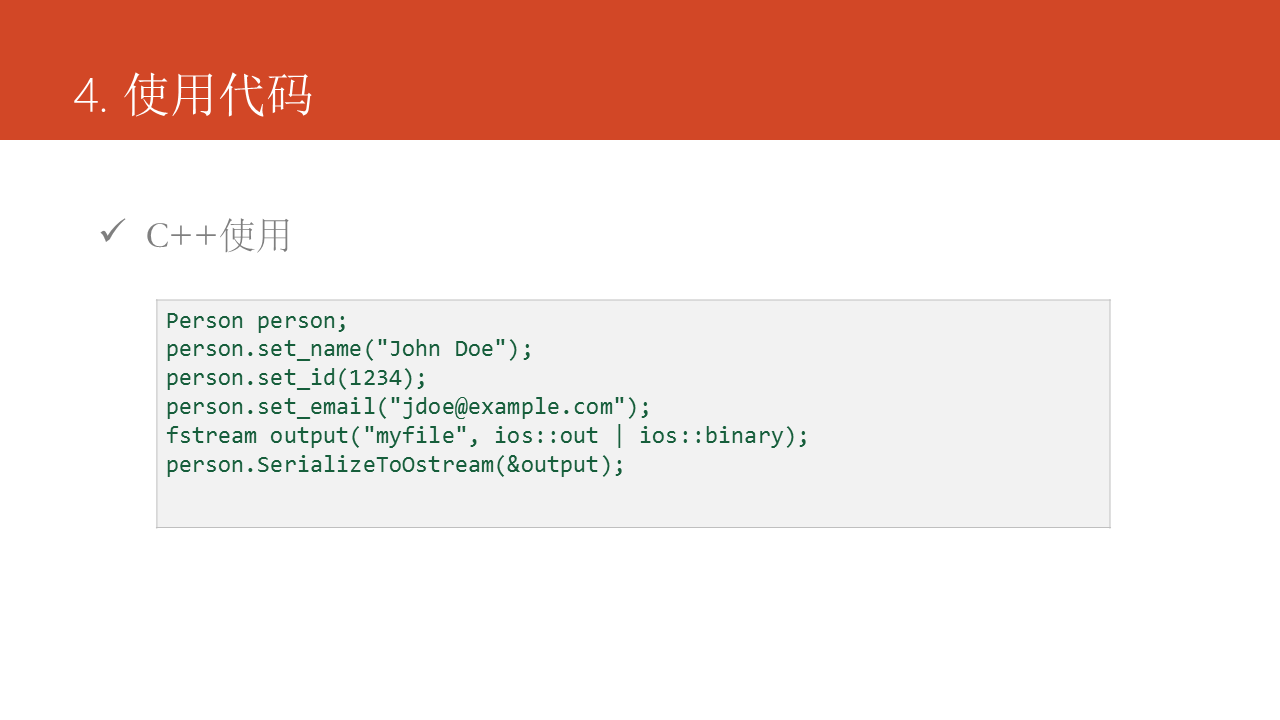
生成代碼的代碼能夠直接加入到本身的代碼工程中使用,以C++語言爲例:
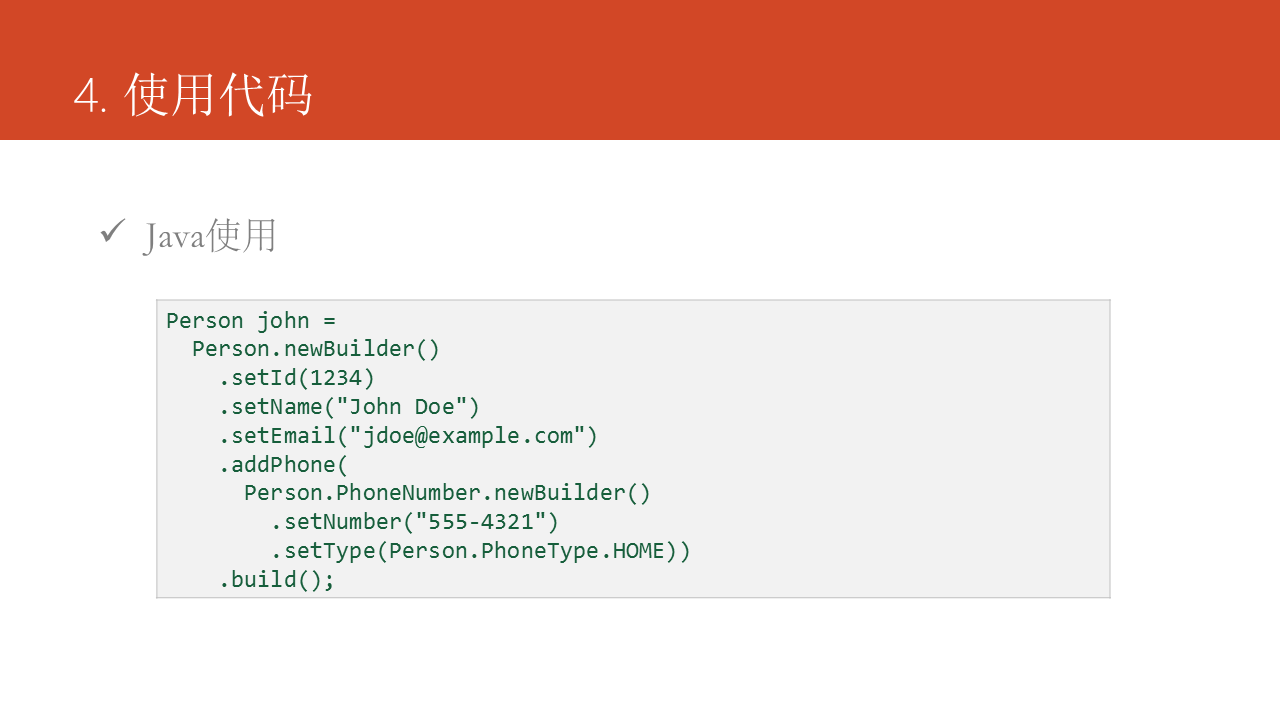
這是一段Java語言的使用示例:
接下來會詳細說明如何定義proto文件:

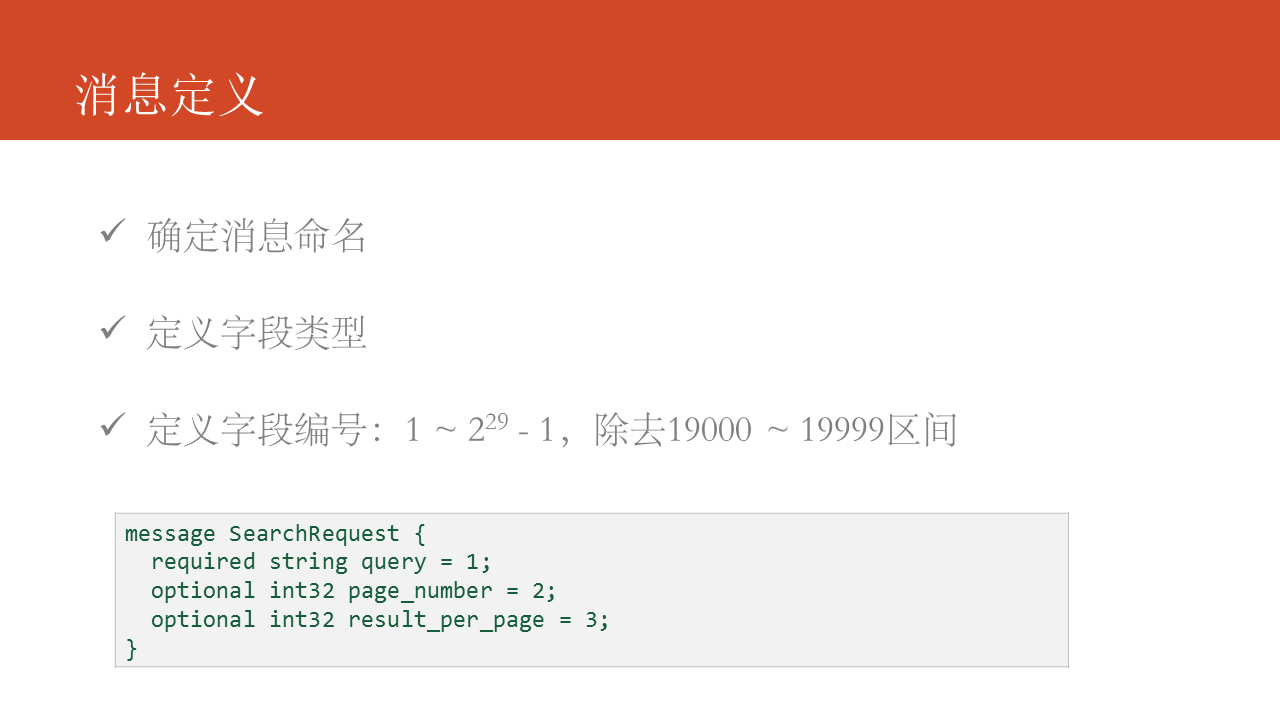
在消息定義中,咱們須要肯定三個問題:
- 肯定消息命名,給消息取一個有意義的名字。
- 指定字段的類型
- 定義字段的編號,在Protocol Buffers中,字段的編號很是重要,字段名僅僅是做爲參考和生成代碼用。須要注意的是字段的編號區間範圍,其中19000 ~ 19999被Protocol Buffers做爲保留字段。
字段約束,required指定該字段必須賦值,禁止爲空(在v3中該約束被移除);optional指定字段爲可選字段,能夠爲空,對於optional字段還可使用[default]指定默認值,若是沒有指定,則會使用字段類型的默認值;使用repeated指定字段爲集合。

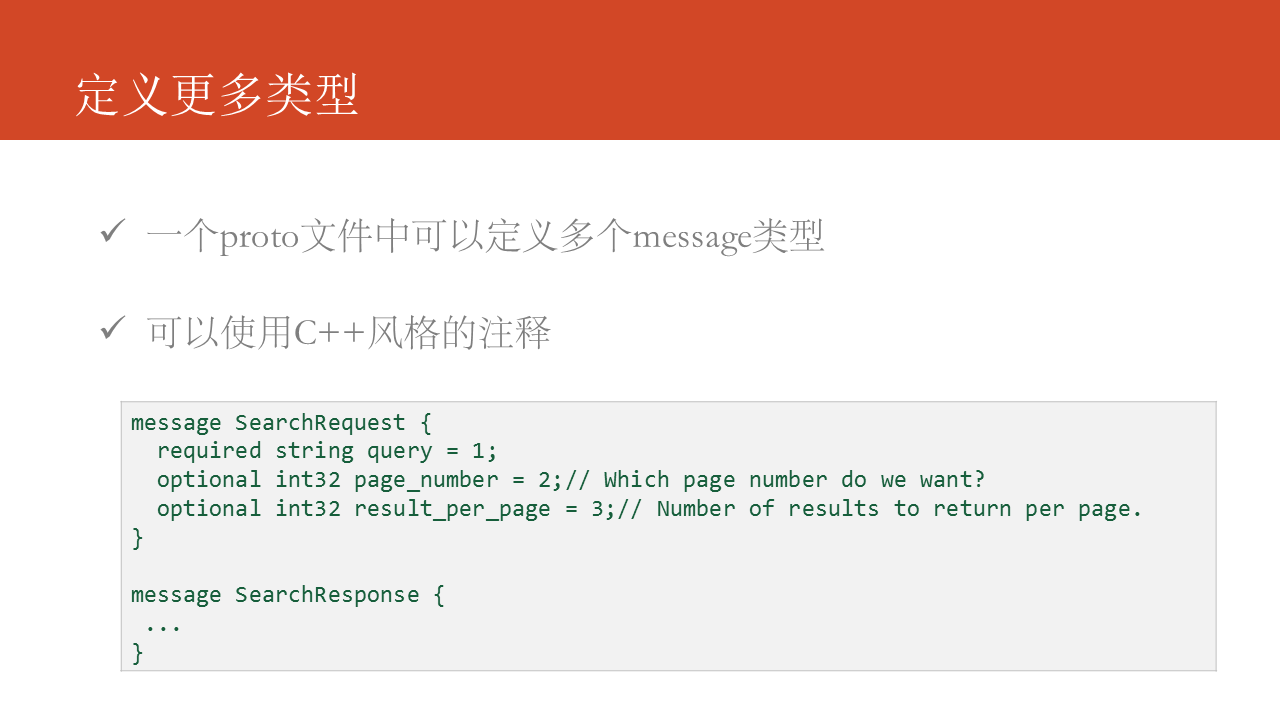
在一個proto文件中能夠同時定義多個message類型,生成代碼時根據生成代碼的目標語言不一樣,處理的方式不太同樣,如Java會針對每一個message類型生成一個.java文件。還可使用C++風格的註釋。
在Protocol Buffers中提供了不少的標量類型,供咱們在定義字段類型時使用。

能夠指定字段的類型爲其餘message類型,如圖中的示例代碼所示:

還可使用import關鍵字導入其餘proto文件,這有利於你進行本身的proto文件的規劃和整理。

在proto文件中消息的類型還能夠嵌套,如你定義的message類型僅做爲另一個Message的字段類型。

爲了便於擴展,在proto文件中可使用extensions關鍵字預留一部分字段編號出來,以便於後期給第三方擴展時使用。

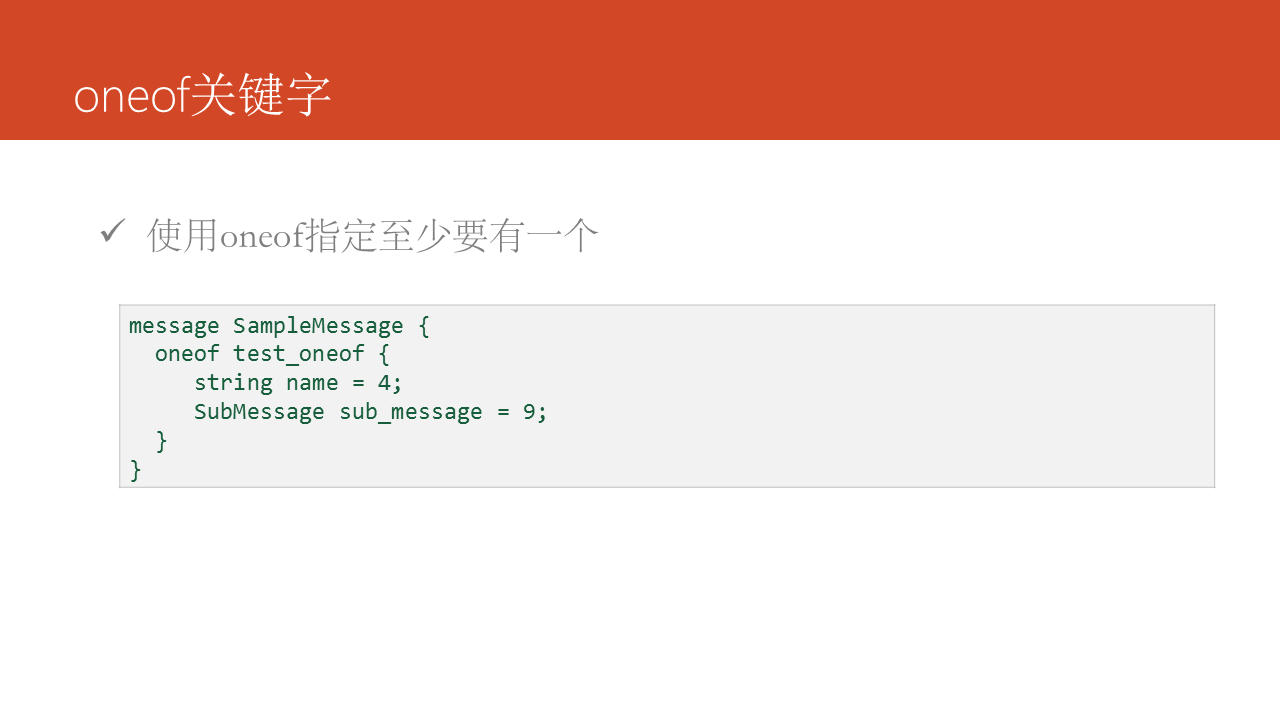
oneof關鍵字指定一組字段中,至少要有一個字段必須賦值。如在用戶登陸系統中,使用郵箱和用戶名均可以登陸該系統,因此一般會要求至少提供用戶名或者郵箱。
在這一部分總咱們會仔細分析,Protocol Buffers序列化後的二進制代碼的編碼協議,不知道這些並不會影響咱們使用Protocol Buffers,可是瞭解以後有助於咱們更好的使用Protocol Buffers和進行調試。

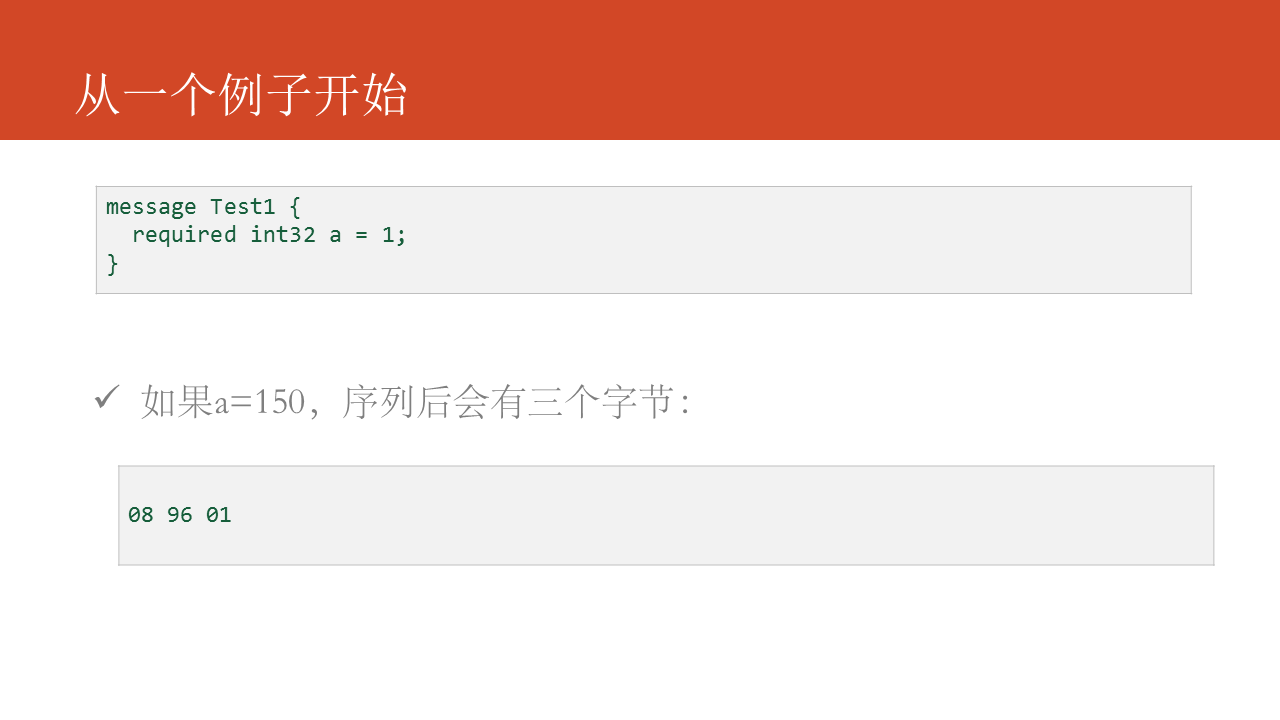
先從一個簡單的例子開始,如圖中的代碼所示,咱們有這樣一個消息定義,在使用中給a賦值爲150,最終編碼獲得的結果是 08 96 01,爲何編碼的結果是這樣,其中08又表明什麼?後續一一爲你介紹。
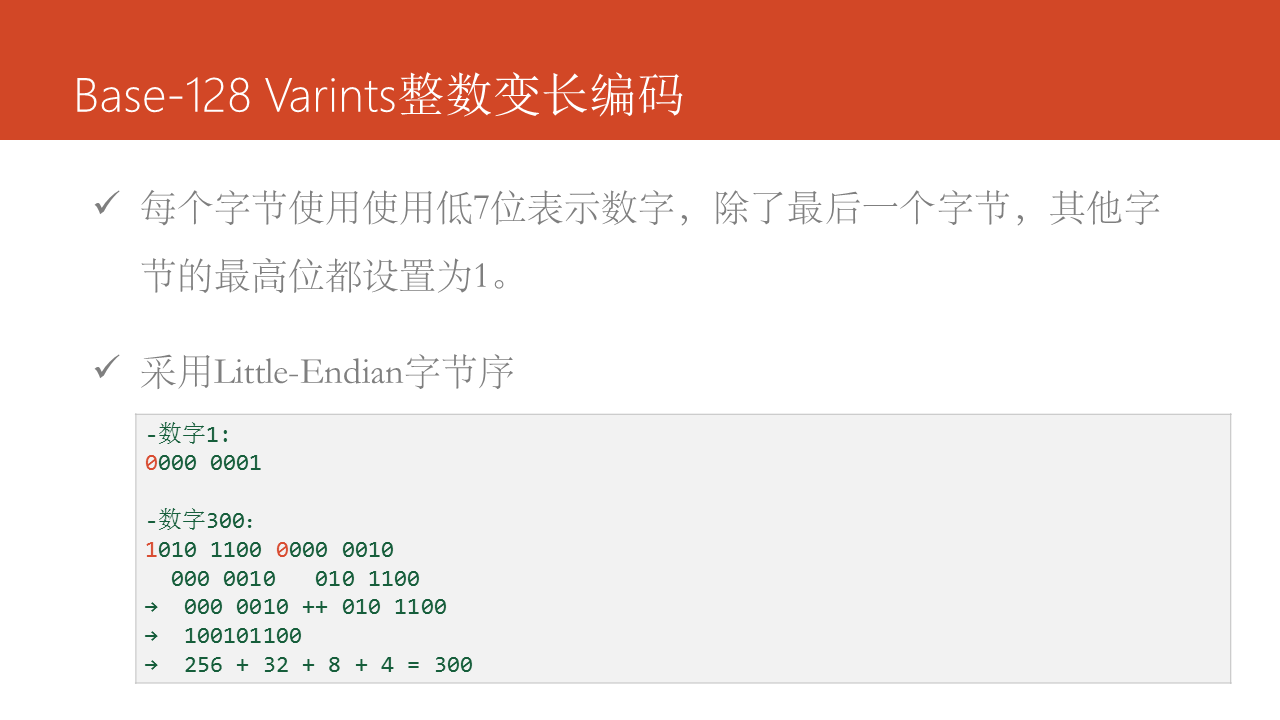
在Protocol Buffers中採用Base-128變長編碼,所謂變長編碼是和定長編碼相對的,定長編碼使用固定字節數來表示,如int32類型的數字固定使用4 bytes表示,而變長編碼是須要幾個字節就使用幾個字節,如對於int32類型的數字1來講,只須要1 bytes足夠。Base-128變長編碼的原則就兩條:
- 每一個字節使用使用低7位表示數字,除了最後一個字節,其餘字節的最高位都設置爲1。
- 採用Little-Endian字節序
一個Protocol Buffers的消息包含一系列字段key/value,每一個字段由一個變長32位整數做爲字段頭,後面跟隨字段體。字段頭的格式以下:
(field_number << 3) | wire_type -field_number: 字段序號 -wire_type: 字段編碼類型

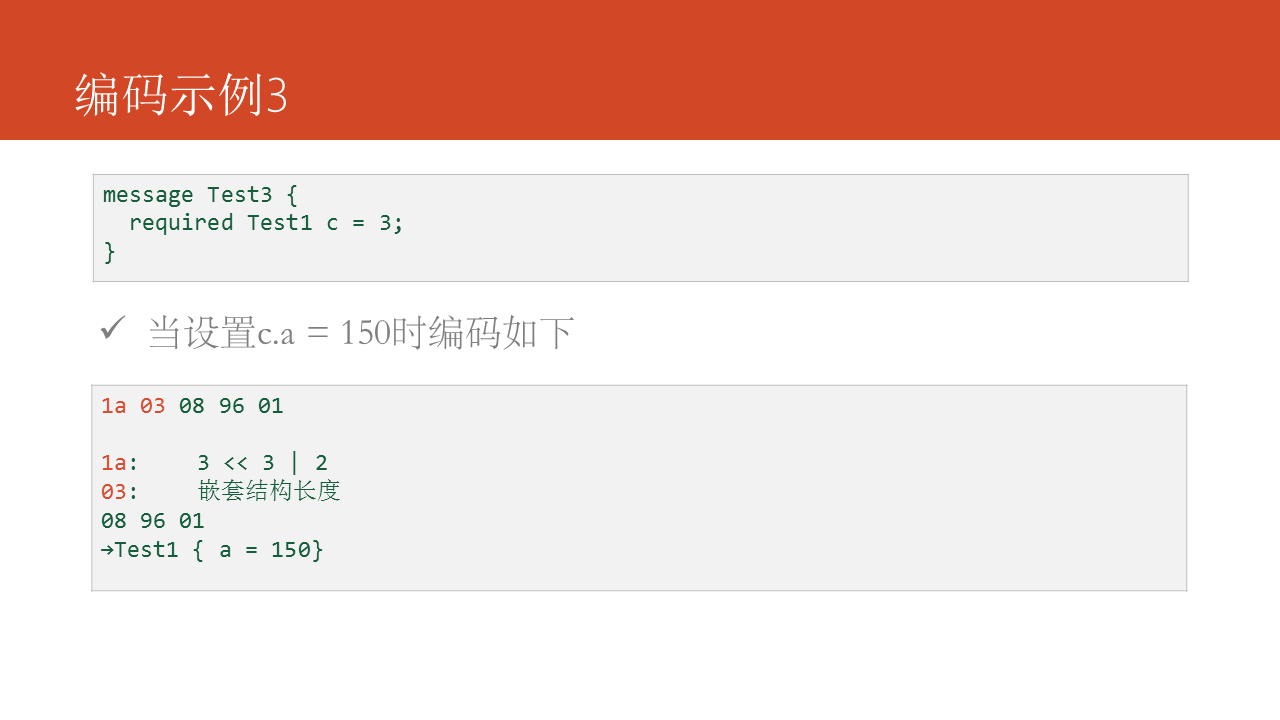
這裏是詳細的字段說明,其中三、4已經放棄:



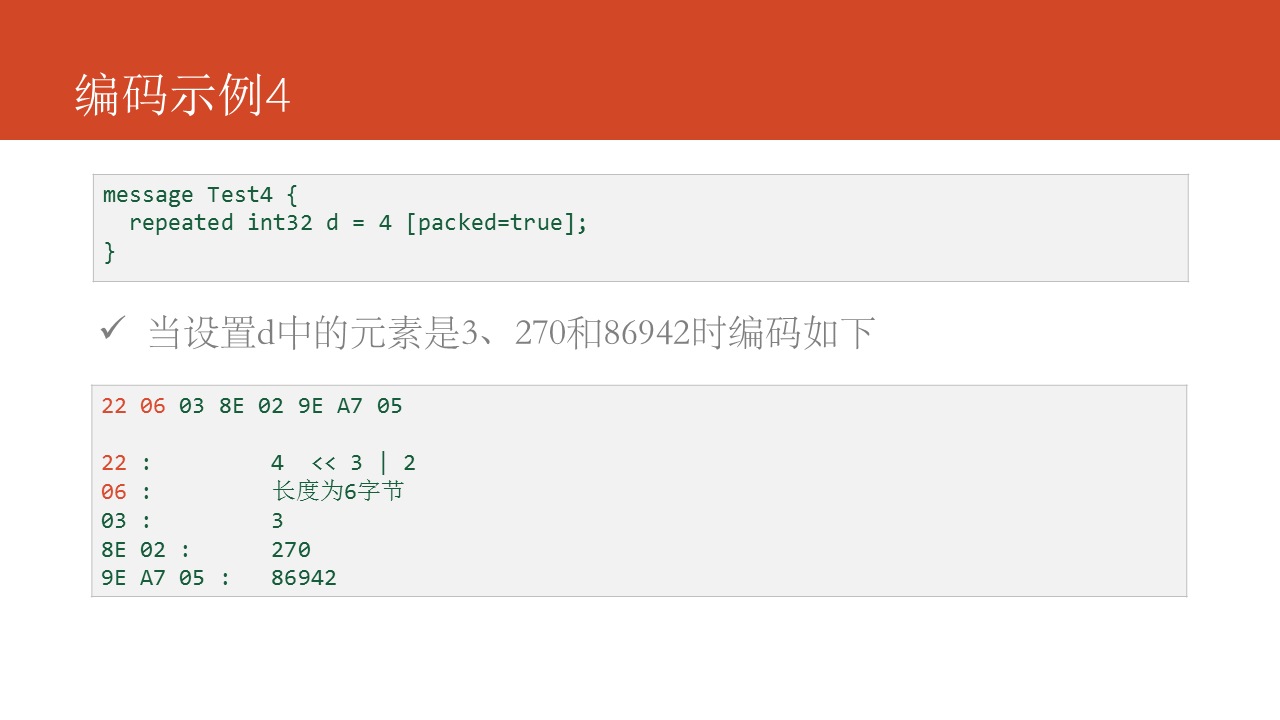

接下來咱們對Protocol Buffers的性能作一些測試。

在測試過程當中,咱們使用一個統一的消息體格式,主要評估如下兩個性能指標:
- 序列化速度
- 報文大小


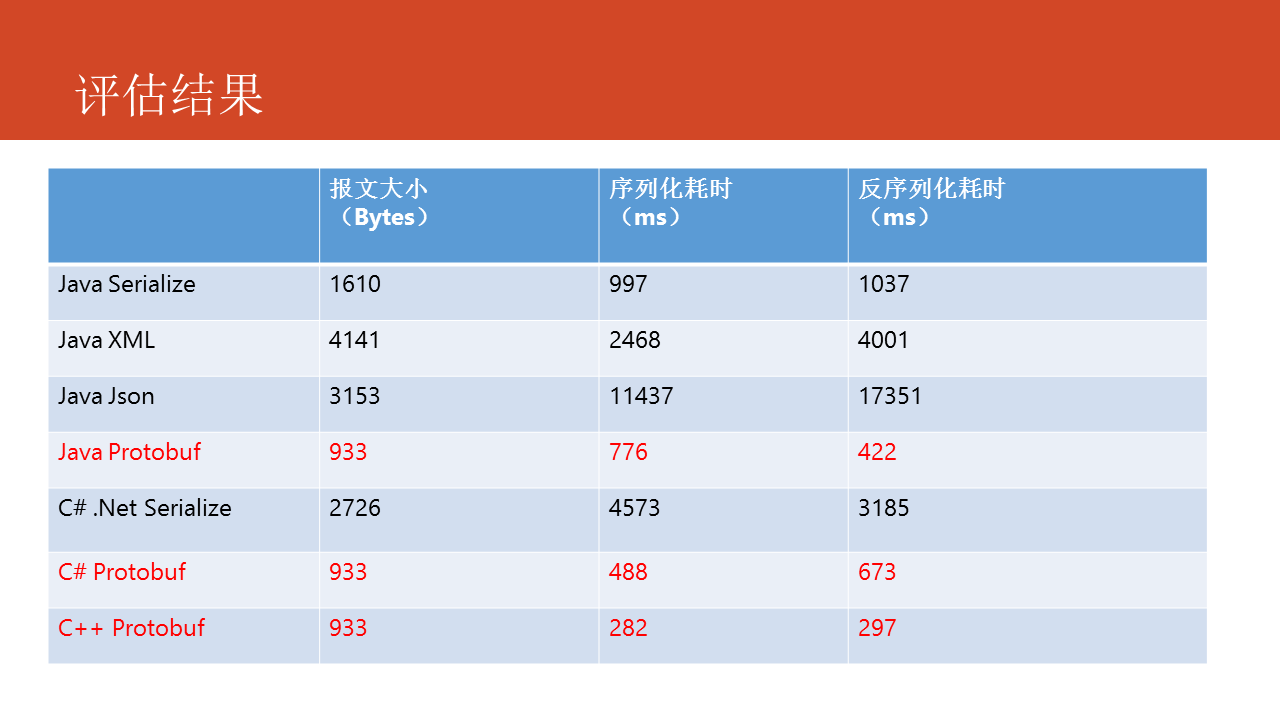


儘管Protocol Buffers有序列化速度快、報文體積小以及更好的兼容性等優勢,但同時也有一些缺點,在使用時要根據實際狀況來選擇使用。
- 缺少自描述,可讀性差,可使用TextFormat
- 適用於內部服務和存儲,而不適合直接對外公開,如Open API,protobuf v3將加入對json的支持,可解決此問題

與Protocol Buffers相似的框架有微軟出的Bond和Facebook出的Thrift,感興趣的同窗能夠去下載研究一下。

- 1. protocol buffers 序列化數據
- 2. Protocol Buffers
- 3. 【協議】MessagePack, Protocol Buffers和Thrift序列化框架原理和比較說明
- 4. Protocol Buffers 學習
- 5. Protocol buffer序列化及其在微信藍牙協議中的應用
- 6. Protocol Buffers 簡介
- 7. Protocol Buffers (protobuf)簡介
- 8. Google Protocol Buffers 概述
- 9. protobuf【protocol buffers】詳解
- 10. Dubbo協議及序列化
- 更多相關文章...
- • XML 應用程序 - XML 教程
- • ASP.NET MVC - Internet 應用程序 - ASP.NET 教程
- • 適用於PHP初學者的學習線路和建議
- • Flink 數據傳輸及反壓詳解
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. eclipse設置粘貼字符串自動轉義
- 2. android客戶端學習-啓動模擬器異常Emulator: failed to initialize HAX: Invalid argument
- 3. android.view.InflateException: class com.jpardogo.listbuddies.lib.views.ListBuddiesLayout問題
- 4. MYSQL8.0數據庫恢復 MYSQL8.0ibd數據恢復 MYSQL8.0恢復數據庫
- 5. 你本是一個肉體,是什麼驅使你前行【1】
- 6. 2018.04.30
- 7. 2018.04.30
- 8. 你本是一個肉體,是什麼驅使你前行【3】
- 9. 你本是一個肉體,是什麼驅使你前行【2】
- 10. 【資訊】LocalBitcoins達到每週交易比特幣的7年低點