python 雜項
答案就是用json模塊:css
<<<<<<<<<<<<<<<<<<<<<<<html
print(' ,'.join(x for x in sss))也能夠node
print(' ,'.join(unicode(x) for x in sss))python
<<<<<<<<<<<<<<<<<<<<<<<mysql
a = {u'content': {u'address_detail': {u'province': u'\u5409\u6797\u7701', u'city': u'\u957f\u6625\u5e02', u'street_number': u'', u'district': u'', u'street': u'', u'city_code': 53}, u'point': {u'y': u'43.89833761', u'x': u'125.31364243'}, u'address': u'\u5409\u6797\u7701\u957f\u6625\u5e02'}, u'status': 0, u'address': u'CN|\u5409\u6797|\u957f\u6625|None|CERNET|0|0'}jquery
print json.dumps(a).decode('unicode-escape')nginx
輸出:
{"content": {"address_detail": {"province": "吉林省", "city": "長春市", "street_number": "", "district": "", "street": "", "city_code": 53}, "address": "吉林省長春市", "point": {"y": "43.89833761", "x": "125.31364243"}}, "status": 0, "address": "CN|吉林|長春|None|CERNET|0|0"}git
<<<<<<<<<<<<<<<<<<<<<<<github
例如:web
- import json
- data=[{u'\u663e\u793a': [u'python', u'\u8bd5\u9a8c'], u'\u6570\u91cf': 22, u'\u8bed\u8a00': u'python'}]
- data_c = u'\u663e\u793a'
- print data
- print data_c
- res_data=json.dumps(data,ensure_ascii=False,encoding="gb2312")
- print res_data
在沒有進行格式轉換時,輸出爲:
>>>[{u'\u663e\u793a': [u'python', u'\u8bd5\u9a8c'], u'\u6570\u91cf': 22, u'\u8bed\u8a00': u'python'}]
>>>顯示
可見非列表中的數據在輸出時是會轉換成中文顯示出來的,但列表中的unicode數據不會。
轉換後,輸出爲:
>>>[{"顯示": ["python", "試驗"], "數量": 22, "語言": "python"}]
若是後面這種輸出是想要的格式,那麼就利用現成的json模塊將原列表格式轉換爲json字符串輸出,並設置好編碼格式,就能夠了。
當還須要再用這部分用來顯示的數據,譬如之後何時又想直接用python來讀取log文件中這種看起來比較方便的帶中文的僞列表,那麼再用json.loads轉換回去便可。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
105.
uvloop 使得 asyncio 更快. 實際上,比nodejs,gevent,以及其餘任何Python異步框架至少快兩倍 .uvloop asyncio 基於性能的測試接近於Go程序.
asyncio 和 uvloop
https://coyee.com/article/10773-uvloop-blazing-fast-python-networking104. python 一行代碼實現的功能呢~~~~
python -m SimpleHTTPServer 8080 # python2
python3 -m http.server 8080 # python3
a,b =b,a
103. requests 高級用法
http://docs.python-requests.org/zh_CN/latest/user/advanced.html#streaming-requests
102.
100.
python 鏈式調用 return self
99.
基於python3.5+的web框架sanic中文入門教程
98. Python黑魔法 --- 異步IO( asyncio) 協程
97. iterm2 MAC控制檯
96. 不錯的python 可視化調試工具:
http://blog.jobbole.com/52090/
更好的調試器
pdb的直接替代者:
ipdb(easy_install ipdb) – 相似ipython(有自動完成,顯示顏色等)
pudb(easy_install pudb) – 基於curses(相似圖形界面接口),特別適合瀏覽源代碼
95. profile
profile是python的標準庫。能夠統計程序裏每個函數的運行時間,而且提供了多樣化的報表
94. timeit 給函數計時的庫
93. 不錯的jQuery庫
http://mbraak.github.io/jqTree/
92. 很快的異步IO
https://pypi.python.org/pypi/asynchttp/
91. 鴨子類型
90. unicode, ascii, utf-8
知 77e5
乎 4e4e
日 65e5
報 62a5
每個字符對應一個十六進制數字。計算機只懂二進制,所以,嚴格按照unicode的方式(UCS-2),應該這樣存儲:
UTF-8是這樣作的:1. 單字節的字符,字節的第一位設爲0,對於英語文本,UTF-8碼只佔用一個字節,和ASCII碼徹底相同;2. n個字節的字符(n>1),第一個字節的前n位設爲1,第n+1位設爲0,後面字節的前兩位都設爲10,這n個字節的其他空位填充該字符unicode碼,高位用0補足。這樣就造成了以下的UTF-8標記位:0xxxxxxx
知 11100111 10011111 10100101
乎 11100100 10111001 10001110
日 11100110 10010111 10100101
報 11100110 10001010 10100101
和上邊的方案對比一下,英文短了,每一箇中文字符卻多用了一個字節。可是整個字符串只用了17個字節,比上邊的18個短了一點點。下邊是課後做業:請將」It's 知乎日報「的GB2312和GBK碼(自行google)轉成二進制。不考慮歷史因素,從技術角度解釋爲何在unicode和UTF-8大行其道的同時,GB2312和GBK仍在普遍使用。劇透:一切都是爲了節省你的硬盤和流量。
80. sqlalchemy 重複查詢一個值, 即便數據庫值變了, 即便del 查詢結果,再從新查詢,結果依然不變........!!!!!!!!!!!!!!
須要 db.session.remove()
---再Flask中, remove 會被flask框架會在一個請求結束後自動調用, 當不用flask框架的時候,必須本身去調用
79. requests 庫指定編碼
78. 指定json的解碼
dd = json.loads(j_str, encoding='utf-8') #dd中的字符串都是unicode
77. unicode轉utf-8
xxx.encode('utf-8')
76. 判斷編碼
import chardet
chardet.detect(strxxx)
75. str轉dict
eval("{'a':1,'b':2}")
74. 類,實例,和其它對象的內建函數
issubclass(subclass, supclass) #類是不是另外一個類的子類或者子孫類
isinstance(obj1, class1) #實例是不是類的實例
hasattr(),getattr(),setattr(),delattr()
dir(), type
super(type[.obj]) #返回此type類的子類
vars() 返回屬性和值
73. python動態建立類
http://www.jb51.net/article/109377.htm
72.
python -m xxx.py
做用是:把xxx.py文件當作模塊啓動
可是我一直不明白當作模塊啓動到底有什麼用。python xxx.py和python -m xxx.py有什麼區別!
自問自答:
- python xxx.py
- python -m xxx.py
這是兩種加載py文件的方式:
一、叫作直接運行
二、至關於import,叫作當作模塊來啓動
不一樣的加載py文件的方式,主要是影響——sys.path 這個屬性。sys.path 就至關於liunx中的PATH。
71.
a. [python]用profile協助程序性能優化
http://www.cnblogs.com/btchenguang/archive/2012/02/03/2337112.html
c. 想 測試一行代碼的運行時間,在 Python中比較方便,能夠直接使用timeit
70.
引用jquery.cookie.js
console.log('get cookie'+ $.cookie('username'));
69. 模板獲取cookie
咱們還能夠在模板中獲取cookie,而後渲染模板.
test.html:
<h1>My name is {{request.cookies.get('Name')}}</h1>
68.
環境變量是進程環境的屬性之一,當你用os.system去執行的時候,其實是:
1 fork一個子進程
2 子進程exec另外一個shell程序,執行你要執行的命令,好比你source,其實是exec一個shell進程再source,因此子進程的環境變量被你改了
可是你這個python進程不受任何影響
要修改當前進程的環境變量,用os.putenv,或操做os.environ這個字典(實際上並非dict的直接實例,而是一個用法和dict基本同樣的對象),這倆的區別參考os模塊的文檔
67. python的源碼doc,比網上教程更清晰
def __init__(self, fget=None, fset=None, fdel=None, doc=None): # known special case of property.__init__
"""
property(fget=None, fset=None, fdel=None, doc=None) -> property attribute
fget is a function to be used for getting an attribute value, and likewise
fset is a function for setting, and fdel a function for del'ing, an
attribute. Typical use is to define a managed attribute x:
class C(object):
def getx(self): return self._x
def setx(self, value): self._x = value
def delx(self): del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")
Decorators make defining new properties or modifying existing ones easy:
class C(object):
@property
def x(self):
"I am the 'x' property."
return self._x
@x.setter
def x(self, value):
self._x = value
@x.deleter
def x(self):
del self._x
# (copied from class doc)
66. python 獲取Linux環境變量:
os.environ
os.environ['XXX']
os.environ.get('XX')
65. Reason: unsafe use of relative rpath libmysqlclient.18.dylib in /Users/xiaofeier312/.python-eggs/MySQL_python-1.2.5-py2.7-macosx-10.12-intel.egg-tmp/_mysql.so with restricted binar
https://stackoverflow.com/questions/6383310/python-mysqldb-library-not-loaded-libmysqlclient-18-dylib#answer-13421926
64. sqlite SQLALCHEMY
不支持create_time = db.Column(db.TIMESTAMP(True), nullable=True, server_default=text('NOW()'))
op_time = db.Column(db.DateTime, nullable=True,
server_default=text('CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP'))
63.
PYTHON MYSQLDB (python和python虛擬環境路徑不能太深,不然安裝包會報錯,!!!)
wget http://sourceforge.net/projects/mysql-python/files/mysql-python/1.2.3/MySQL-python-1.2.3.tar.gz
https://sourceforge.net/projects/mysql-python/files/mysql-python/
https://sourceforge.net/projects/mysql-python/
62. 異步任務神器 Celery 簡明筆記
http://python.jobbole.com/84041/
http://blog.csdn.net/apple9005/article/details/54430104
61.
__init__.py的做用有以下幾點:
1. 至關於class中的def __init__(self):函數,用來 初始化模塊。
2. 把所在目錄看成一個package處理
3. from-import 語句導入子包時須要用到它。 若是沒有用到, 他們能夠是空文件。
60. 列表的每個元素顯示爲一行
print( '\n'.join(listX))
59. Python協程庫 greenlet,stackless,gevent,eventlet
主要用於IO密集型, 計算型不適合
http://blog.csdn.net/zeroctu/article/details/54893763
58. import time
a='2022-03-11 23:11:01'
ti=time.strptime(a, '%Y-%m-%d %H%M%S')
>>>ti>>time.struct_time
>>>ti.tm_year>>2022, >>>ti.tm_hour>>23 >>>ti.....................
h_time = time.strftime('%H%M%S', ti)
>>>h_time >>'23:11:01'
57. mysql取出來的編碼要看清,print出來是u'XXX',須要先str.encode("UTF-8"), 才能jsonify()
56. js alert顯示json
alert(JSON.stringify( data ));
54. os.system()的返回值爲Linux返回的狀態,不能返回命令查詢結果
http://www.javashuo.com/article/p-muivenes-dq.html
用os.popen()能夠差返回結果
53.
生成器表達式
在前面一期「這樣寫代碼更優雅」的文章裏面曾經介紹過列表推導式(list comprehension),生成器表達式與列表推導式長的很是像,可是它倆返回的對象不同,前者返回生成器對象,後者返回列表對象。
|
1
2
3
4
5
6
|
>>> g = (x*2
for
x
in
range(10))
>>>
type
(g)
<
type
'generator'
>
>>> l = [x*2
for
x
in
range(10)]
>>>
type
(l)
<
type
'list'
>
|
52. enumerate,用於遍歷可迭代(iterable)的對象,如列表,字符串,字典,元組
for index, item in enumerate(listX):
print index, item
~~~~~~~~~~~~~~~~
如何判斷一個對象是否可迭代:
>>> from collections import Iterable
>>> isinstance('abc',Iterable)
True
更多: http://blog.csdn.net/business122/article/details/7608176
51. Python多線程,協程
http://python.jobbole.com/81546/
50. python 面向對象
49 QUEUE python隊列
http://www.cnblogs.com/itogo/p/5635629.html
48. python flask等等-伯樂在線
http://python.jobbole.com/category/tools/
47.
屬性函數(property)
http://python.jobbole.com/80955/ ;
46.
像map()函數這種可以接收函數做爲參數的函數,稱之爲高階函數(Higher-order function)。
高階函數除了能夠接受函數做爲參數外,還能夠把函數做爲結果值返回。
45. RE模塊
http://www.cnblogs.com/XXCXY/p/5180237.html
http://www.cnblogs.com/XXCXY/p/5180237.html
Python 提供了兩種不一樣的原始操做基於正則表達式: re.match()檢查是否只在字符串的開頭匹配而re.search()檢查是否在任何地方 (這是默認狀況下,Perl 作的) 的字符串匹配。
舉個例子:
44.
max()返回最大值 max([1,3,4,2])
min()
zip並行遍歷:
name=['a','b','c']
age=[2,33,44]
zip(name,age)
返回 [('a',2),('b',22),('c',44)]
~~~~~~~~~~~~~~~~~~~~
map 並行遍歷
http://www.cnblogs.com/XXCXY/p/5180237.html
~~~~~~~~~~~~~~~~~~~~
reduce 歸併
reduce()函數也是Python內置的一個高階函數。
reduce()函數接收的參數和 map()相似,一個函數 f,一個list,但行爲和 map()不一樣,reduce()傳入的函數 f 必須接收兩個參數,reduce()對list的每一個元素反覆調用函數f,並返回最終結果值。
例如,編寫一個f函數,接收x和y,返回x和y的和:
|
1
2
|
def
f(x, y):
return
x
+
y
|
調用 reduce(f, [1, 3, 5, 7, 9])時,reduce函數將作以下計算:
|
1
2
3
4
5
|
先計算頭兩個元素:f(
1
,
3
),結果爲
4
;
再把結果和第
3
個元素計算:f(
4
,
5
),結果爲
9
;
再把結果和第
4
個元素計算:f(
9
,
7
),結果爲
16
;
再把結果和第
5
個元素計算:f(
16
,
9
),結果爲
25
;
因爲沒有更多的元素了,計算結束,返回結果
25
。
|
上述計算其實是對 list 的全部元素求和。雖然Python內置了求和函數sum(),可是,利用reduce()求和也很簡單。
reduce()還能夠接收第3個可選參數,做爲計算的初始值。若是把初始值設爲100,計算:
|
1
|
reduce
(f, [
1
,
3
,
5
,
7
,
9
],
100
)
|
結果將變爲125,由於第一輪計算是:
計算初始值和第一個元素:f(100, 1),結果爲101。
~~~~~~~~~~~~~~~~~~~~chr(intx) 返回數字對應的字母/編碼
ord('z') 返回z的asc碼
hex()整數轉化爲十六進制字符串
oct()八位
repr 以字符串顯示
43.
經常使用的內置函數
| 內置方法 | 說明 |
| __init__(self,...) | 初始化對象,在建立新對象時調用 |
| __del__(self) | 釋放對象,在對象被刪除以前調用 |
| __new__(cls,*args,**kwd) | 實例的生成操做 |
| __str__(self) | 在使用print語句時被調用 |
| __getitem__(self,key) | 獲取序列的索引key對應的值,等價於seq[key] |
| __len__(self) | 在調用內聯函數len()時被調用 |
| __cmp__(stc,dst) | 比較兩個對象src和dst |
| __getattr__(s,name) | 獲取屬性的值 |
| __setattr__(s,name,value) | 設置屬性的值 |
| __delattr__(s,name) | 刪除name屬性 |
| __getattribute__() | __getattribute__()功能與__getattr__()相似 |
| __gt__(self,other) | 判斷self對象是否大於other對象 |
| __lt__(slef,other) | 判斷self對象是否小於other對象 |
| __ge__(slef,other) | 判斷self對象是否大於或者等於other對象 |
| __le__(slef,other) | 判斷self對象是否小於或者等於other對象 |
| __eq__(slef,other) | 判斷self對象是否等於other對象 |
| __call__(self,*args) | 把實例對象做爲函數調用 |
http://www.cnblogs.com/hongfei/p/3858256.html
42. range(11) 0到10
range(1,22) 1到21
range(2,222,3) 2到222,步驟爲3
xrange(22)
xrange會生成一個迭代器,而不是像range那樣直接返回一個List
41. random
random.randint(1,22) 1到22間隨機生成一個整數
random.random() 默認生成一個0,1之間的浮點數
random.uniform(0,22) 默認返回一個0到22間的浮點數
random.randrange(0,9999,50) 隨機取一個0,9999之間的 步伐爲50的數
random.choice('asd') 隨機返回一個字母
random.choice(['d','fddd','gs']) 隨機返回一個字符串
random.sample(['a','s','d','f'],2) 隨機取出兩個字母
items=[1,2,3,4,5]
random.shuffle(items) 洗牌,打亂順序
40.
字符串操做
s.strip(rm) 刪除s字符串中開頭、結尾處,位於 rm刪除序列的字符
s.lstrip(rm) 刪除s字符串中開頭處,位於 rm刪除序列的字符
s.rstrip(rm) 刪除s字符串中結尾處,位於 rm刪除序列的字符
d='asasaaasssdasasbasasaaa'
d.strip('as') 返回 ‘dasasb'
~~~~~~~~
s.replace('aa', 'b', 3) 去掉字符串的aa,換爲b,次數爲3
s.split('b',4) 遇到b則分割,去掉b自己
~~~~~~~~~~~
str1.count('ab') 查詢字符串中‘ab'的個數
str1.find('cd') 查詢第一次出現‘cd'的位置
str1.rfind('as') 查詢最後一次出現‘as'的位置
~~~~~~~~~~
斷定
isalnum(),#是否全是字母和數字,並至少有一個字符
isalpha(),是否全是字母,並至少有一個字符
isdigit(),是否全是數字,並至少有一個字符 ,若是是全數字返回True,不然返回False
islower(),#S中的字母是否全是小寫
isupper(),#S中的字母是不是大寫
isspace(),#是否全是空白字符,並至少有一個字符
istitle(),S是不是首字母大寫的
startswith(prefix[, start[, end]]), #是否以prefix開頭
endswith(suffix[,start[, end]]),#以suffix結尾
備註:
這些函數都比較簡單,顧名知義。須要注意的是*with()函數族能夠接受可選的 start, end 參數,善加利用,能夠優化性能。
另,自 Py2.5 版本起,*with() 函數族的 prefix 參數能夠接受 tuple 類型的實參,當實參中的某人元素可以匹配,即返回 True。
~~~~~~~~~~~~~~~~~~~~~~~
':'.join(listA) A的元素中間插入一個冒號,而後返回字符串
一樣使用與字典與元組
os.path.join('/root/,'/lib','/c') 將lying合併
~~~~~~~~~~~~~~
http://www.cnblogs.com/diege/archive/2012/10/01/2709790.html
39.
38. json json字典,json類等轉換json
http://blog.csdn.net/seetheworld518/article/details/49536247
jsonstr = json.dumps(dict)
dict = json.loads(jsonstr)
37. list
6.五、列表腳本操做符
列表對+和*的操做符與字符串類似。+號用於組合列表,*號用於重複列表,例如:
#3
print [1, 2, 3] + [4, 5, 6];
#[1, 2, 3, 4, 5, 6]
print ['Hi!'] * 4;
#['Hi!', 'Hi!', 'Hi!', 'Hi!']
print 3 in [1, 2, 3] #
True
for x in [1, 2, 3]:
print x, #1 2 3
6.六、列表截取
6.七、列表函數&方法

list.count(obj) 統計某個元素在列表中出現的次數
list.extend(seq) 在列表末尾一次性追加另外一個序列中的多個值(用新列表擴展原來的列表)
list.index(obj) 從列表中找出某個值第一個匹配項的索引位置,索引從0開始
list.insert(index, obj) 將對象插入列表
list.pop(obj=list[-1]) 移除列表中的一個元素(默認最後一個元素),而且返回該元素的值
list.remove(obj) 移除列表中某個值的第一個匹配項list.reverse() 反向列表中元素,倒轉
list.sort([func]) 對原列表進行排序
36.
字典
35. python 返回的對象,打印出來的看似是列表,好比os.environ, 可是不能當列表用, 須要看源碼,用os.environ.copy()才能返回dict
34. python os模塊
os.name
os.listdir()
os.getcwd()
os.remove()
os.rmdir()
os.mkdir()
~~~~~~~~~~
os.listdir(dirname):列出dirname下的目錄和文件
os.getcwd():得到當前工做目錄
os.curdir:返回當前目錄('.')
os.chdir(dirname):改變工做目錄到dirname
os.path.isdir(name):判斷name是否是一個目錄,name不是目錄就返回false
os.path.isfile(name):判斷name是否是一個文件,不存在name也返回false
os.path.exists(name):判斷是否存在文件或目錄name
os.path.getsize(name):得到文件大小,若是name是目錄返回0
os.path.abspath(name):得到絕對路徑
os.path.normpath(path):規範path字符串形式
os.path.split(name):分割文件名與目錄(事實上,若是你徹底使用目錄,它也會將最後一個目錄做爲文件名而分離,同時它不會判斷文件或目錄是否存在)
os.path.splitext():分離文件名與擴展名
os.path.join(path,name):鏈接目錄與文件名或目錄
os.path.basename(path):返回文件名
os.path.dirname(path):返回文件路徑
一、os.path方法
經過傳入須要遍歷的目錄,列出目錄下的全部文件並統計文件數,os提供的path模塊能對目錄很是靈活的操做。
import os,sys
def listdir(dir,file):
file.write(dir + '\n')
fielnum = 0
list = os.listdir(dir) #列出目錄下的全部文件和目錄
for line in list:
filepath = os.path.join(dir,line)
if os.path.isdir(filepath): #若是filepath是目錄,則再列出該目錄下的全部文件
myfile.write(' ' + line + '\\'+'\n')
for li in os.listdir(filepath):
myfile.write(' '+li + '\n')
fielnum = fielnum + 1
elif os.path: #若是filepath是文件,直接列出文件名
myfile.write(' '+line + '\n')
fielnum = fielnum + 1
myfile.write('all the file num is '+ str(fielnum))
dir = raw_input('please input the path:')
myfile = open('list.txt','w')
二、os.walk方法
os模塊提供的walk方法很強大,可以把給定的目錄下的全部目錄和文件遍歷出來。
方法:os.walk(path),遍歷path,返回一個對象,他的每一個部分都是一個三元組,('目錄x',[目錄x下的目錄list],目錄x下面的文件)
import os
def walk_dir(dir,fileinfo,topdown=True):
for root, dirs, files in os.walk(dir, topdown):
for name in files:
print(os.path.join(name))
fileinfo.write(os.path.join(root,name) + '\n')
for name in dirs:
print(os.path.join(name))
fileinfo.write(' ' + os.path.join(root,name) + '\n')
dir = raw_input('please input the path:')
fileinfo = open('list.txt','w')
walk_dir(dir,fileinfo)
33. python chardet
chardet('sss') 能夠查看編碼
32 python 邏輯運算順序
not 1 or 1, 先算not 而後是 and or
表5.2 運算符優先級
| 運算符 | 描述 |
|---|---|
| lambda | Lambda表達式 |
| or | 布爾「或」 |
| and | 布爾「與」 |
| not x | 布爾「非」 |
| in,not in | 成員測試 |
| is,is not | 同一性測試 |
| <,<=,>,>=,!=,== | 比較 |
| | | 按位或 |
| ^ | 按位異或 |
| & | 按位與 |
| <<,>> | 移位 |
| +,- | 加法與減法 |
| *,/,% | 乘法、除法與取餘 |
| +x,-x | 正負號 |
| ~x | 按位翻轉 |
| ** | 指數 |
| x.attribute | 屬性參考 |
| x[index] | 下標 |
| x[index:index] | 尋址段 |
| f(arguments...) | 函數調用 |
| (experession,...) | 綁定或元組顯示 |
| [expression,...] | 列表顯示 |
| {key:datum,...} | 字典顯示 |
| 'expression,...' | 字符串轉換 |
31
python-將字符串轉換爲字典
>>> a='{"name":"yct","age":10}'
支持字符串和數字,其他格式的好像不支持:
30.
python不錯的文檔
http://www.open-open.com/code/tags/Python
29.
" xyz ".strip() # returns "xyz"
" xyz ".lstrip() # returns "xyz "
" xyz ".rstrip() # returns " xyz"
" x y z ".replace(' ', '') # returns "xyz"
28.
- hasattr(object, name)
說明:判斷對象object是否包含名爲name的特性(hasattr是經過調用getattr(ojbect, name)是否拋出異常來實現的)。
參數object:對象。
參數name:特性名稱。
示例:
27. with語句
http://www.ibm.com/developerworks/cn/opensource/os-cn-pythonwith/
26. 相對導入(不能在__main__中用)

25.
24.
func() is a result of call to func
func is a object of the function
23.
22.
老大 2016/4/13 11:28:34
https://www.douban.com/note/491745257/ ;
老大 2016/4/13 11:28:59
python部分:
1.urllib.urlencode(query, doseq=0)
接受參數形式爲:[(key1, value1), (key2, value2),...] 和 {'key1': 'value1', 'key2': 'value2',...}
返回的是形如'key2=value2&key1=value1'字符串。
>>>urllib.urlencode({'name': u'老王'.encode('utf8'), 'sex': u'男'.encode('utf8')})
'name=%E8%80%81%E7%8E%8B&sex=%E7%94%B7'
2.urllib.quote(s, safe='/')
接受參數s爲字符串,safe是指定某字符不被urlencode,默認爲'/',
如指定'+'、'/'不需轉換,傳 '+/' 和 '+ /' 都可。另外此方法會將「空格」轉換爲「%20」
>>> urllib.quote(u'老王 /+'.encode('utf8'))
'%E8%80%81%E7%8E%8B%20/%2B'
3.urllib.quote_plus(s, safe='')
此方法的源碼爲:
def quote_plus(s, safe=''):
"""Quote the query fragment of a URL; replacing ' ' with '+'"""
if ' ' in s:
s = quote(s, safe + ' ')
return s.replace(' ', '+')
return quote(s, safe)
能夠看出它比quote多一些功能,可是會將「空格」轉換成「加號」,默認safe爲空。
>>> urllib.quote_plus(u'老王 /+'.encode('utf8'))
'%E8%80%81%E7%8E%8B+%2F%2B'
具體使用哪一個方法,看需求。
urlencode部分:
並非全部相關字符都須要轉碼,有哪些字符須要urlencode而且爲何?
21.
20.
模塊(module)
__doc__: 文檔字符串。若是模塊沒有文檔,這個值是None。
*__name__: 始終是定義時的模塊名;即便你使用import .. as 爲它取了別名,或是賦值給了另外一個變量名。
*__dict__: 包含了模塊裏可用的屬性名-屬性的字典;也就是可使用模塊名.屬性名訪問的對象。
__file__: 包含了該模塊的文件路徑。須要注意的是內建的模塊沒有這個屬性,訪問它會拋出異常!
1 import fnmatch as m
2 print m.__doc__.splitlines()[0] # Filename matching with shell patterns.
3 print m.__name__ # fnmatch
4 print m.__file__ # /usr/lib/python2.6/fnmatch.pyc
5 print m.__dict__.items()[0] # ('fnmatchcase', <function fnmatchcase="" at="" 0xb73deb54="">)</function>
2.2. 類(class)
__doc__: 文檔字符串。若是類沒有文檔,這個值是None。
*__name__: 始終是定義時的類名。
*__dict__: 包含了類裏可用的屬性名-屬性的字典;也就是可使用類名.屬性名訪問的對象。
__module__: 包含該類的定義的模塊名;須要注意,是字符串形式的模塊名而不是模塊對象。
*__bases__: 直接父類對象的元組;但不包含繼承樹更上層的其餘類,好比父類的父類。
1 print Cat.__doc__ # None
2 print Cat.__name__ # Cat
3 print Cat.__module__ # __main__
4 print Cat.__bases__ # (<type ?object?="">,)
5 print Cat.__dict__ # {'__module__': '__main__', ...}</type>
2.3. 實例(instance)
實例是指類實例化之後的對象。
*__dict__: 包含了可用的屬性名-屬性字典。
*__class__: 該實例的類對象。對於類Cat,cat.__class__ == Cat 爲 True。
1 print cat.__dict__
2 print cat.__class__
3 print cat.__class__ == Cat # True
2.4. 內建函數和方法(built-in functions and methods)
根據定義,內建的(built-in)模塊是指使用C寫的模塊,能夠經過sys模塊的builtin_module_names字段查看都有哪些模塊是內建的。這些模塊中的函數和方法可使用的屬性比較少,不過通常也不須要在代碼中查看它們的信息。
__doc__: 函數或方法的文檔。
__name__: 函數或方法定義時的名字。
__self__: 僅方法可用,若是是綁定的(bound),則指向調用該方法的類(若是是類方法)或實例(若是是實例方法),不然爲None。
*__module__: 函數或方法所在的模塊名。
2.5. 函數(function)
這裏特指非內建的函數。注意,在類中使用def定義的是方法,方法與函數雖然有類似的行爲,但它們是不一樣的概念。
__doc__: 函數的文檔;另外也能夠用屬性名func_doc。
__name__: 函數定義時的函數名;另外也能夠用屬性名func_name。
*__module__: 包含該函數定義的模塊名;一樣注意,是模塊名而不是模塊對象。
*__dict__: 函數的可用屬性;另外也能夠用屬性名func_dict。
不要忘了函數也是對象,可使用函數.屬性名訪問屬性(賦值時若是屬性不存在將新增一個),或使用內置函數has/get/setattr()訪問。不過,在函數中保存屬性的意義並不大。
func_defaults: 這個屬性保存了函數的參數默認值元組;由於默認值老是靠後的參數纔有,因此不使用字典的形式也是能夠與參數對應上的。
func_code: 這個屬性指向一個該函數對應的code對象,code對象中定義了其餘的一些特殊屬性,將在下文中另外介紹。
func_globals: 這個屬性指向當前的全局命名空間而不是定義函數時的全局命名空間,用處不大,而且是隻讀的。
*func_closure: 這個屬性僅當函數是一個閉包時有效,指向一個保存了所引用到的外部函數的變量cell的元組,若是該函數不是一個內部函數,則始終爲None。這個屬性也是隻讀的。
下面的代碼演示了func_closure:
01 #coding: UTF-8
02 def foo():
03 n = 1
04 def bar():
05 print n # 引用非全局的外部變量n,構造一個閉包
06 n = 2
07 return bar
08
09 closure = foo()
10 print closure.func_closure
11 # 使用dir()得知cell對象有一個cell_contents屬性能夠得到值
12 print closure.func_closure[0].cell_contents # 2
由這個例子能夠看到,遇到未知的對象使用dir()是一個很好的主意 :)
2.6. 方法(method)
方法雖然不是函數,但能夠理解爲在函數外面加了一層外殼;拿到方法裏實際的函數之後,就可使用2.5節的屬性了。
__doc__: 與函數相同。
__name__: 與函數相同。
*__module__: 與函數相同。
im_func: 使用這個屬性能夠拿到方法裏實際的函數對象的引用。另外若是是2.6以上的版本,還可使用屬性名__func__。
im_self: 若是是綁定的(bound),則指向調用該方法的類(若是是類方法)或實例(若是是實例方法),不然爲None。若是是2.6以上的版本,還可使用屬性名__self__。
im_class: 實際調用該方法的類,或實際調用該方法的實例的類。注意不是方法的定義所在的類,若是有繼承關係的話。
1 im = cat.sayHi
2 print im.im_func
3 print im.im_self # cat
4 print im.im_class # Cat
19.在其它的服務器中,發生,CSS不能加載:
【悟空】隨風 2016/4/12 15:22:16
咋解決的啊
【妖精】sunday 2016/4/12 15:23:07
nginx配置文件中,加入了 include mime.types 就能夠了
18. Django queryDict to python dict:
好比type(request.POST) is queryDict,不支持 for i in request.POST,只能先轉換成python dict
mydict = request.POST.dict()
17.刪除表後從新建表:
怎麼也建不成,暫時只能刪除庫(不只要刪除工程裏的migrations文件,還要刪除庫裏的django-migrations表) 》 建空庫 》python manage.py makemigrations > python manage.py migrate
16.python連接mysql有3個驅動:
Ctrl + Alt + H調用層次結構
14.搭建django開發環境
a. 安裝python3.5,加入path
b.下載get-pip.py
c.安裝pip > cmd下> python get-pip.py
d.安裝django> pip install django==1.9.5(路徑: python3.5/scripts)
e.python shell > import django驗證 django.__version__
f.安裝pycharm4 輸入驗證碼
g.copy the django-admin.py file(at python3.5/Scripts folder) to where you want to create your django project
h. Create project: python django-admin.py startproject YOURPROJECTNAME
i. Create your app: python manage.py createapp NAME
13 坑。。 locals()不能亂用,啊
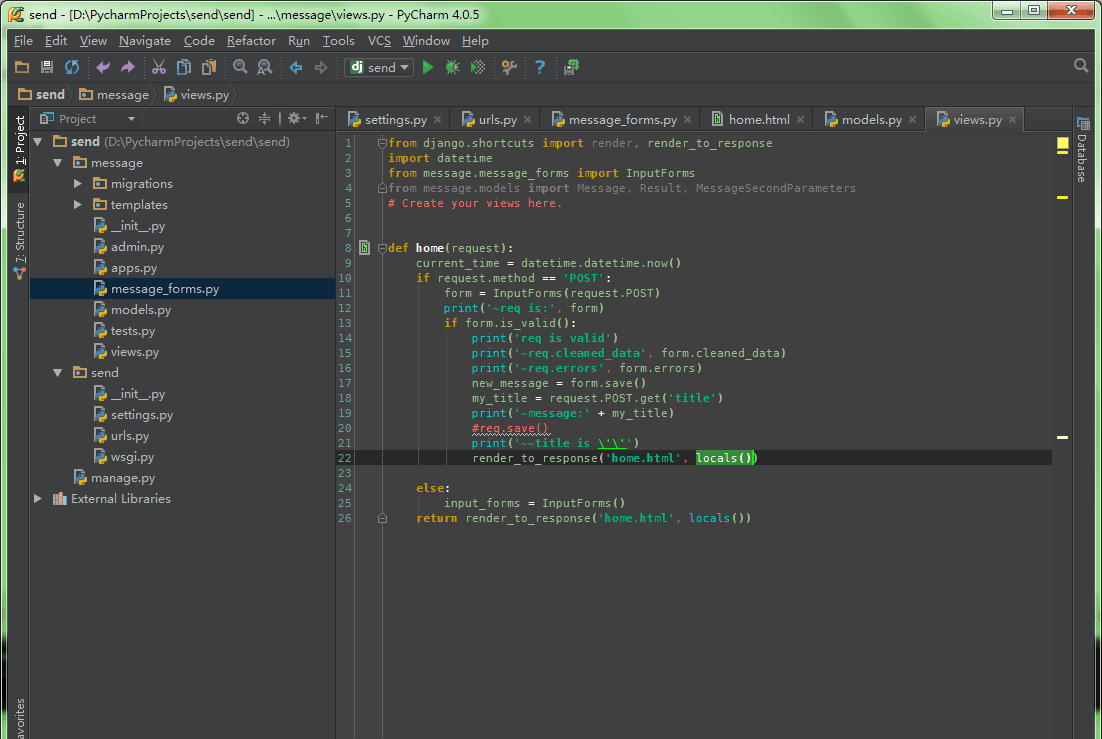
12. Error
#req = Message(title = request.POST.get('title'))
req = message_forms.InputForms(request.POST) #Create a new Form instance from POST data
new_message = req.save()
mytitle = request.POST.get('title')
print('~message:' + mytitle)
django實戰、學習:
http://my.oschina.net/yidao620c/blog/343174?fromerr=7KiTeNbu
python manage.py migrate 保存改變
python manage.py sqlmigrations APP 001 #查看sql語句
9.
數據庫命令
There are several commands which you will use to interact with migrations and Django’s handling of database schema:
migrate, which is responsible for applying migrations, as well as unapplying and listing their status.
makemigrations, which is responsible for creating new migrations based on the changes you have made to your models.
sqlmigrate, which displays the SQL statements for a migration.
showmigrations, which lists a project’s migrations.
8. http://www.cnblogs.com/lhj588/archive/2012/05/24/2516040.html ;
Django model字段類型清單
7.
通過上網搜索得知,MySQLdb並不支持Python3.5,所以只能找別的類庫代替。解決方法:使用pymysql代替MySQLdb,由於二者的用法徹底一致,步驟:1. PIP install pymysql
2. 執行成功後,打開__init__.py,添加以下:
import pymysql
pymysql.install_as_MySQLdb()
3. 從新執行python manage.py syncdb,成功。
6. django book2.0 chapter 8 14/17 page
包裝視圖 -
使用一個視圖包裝達到目的。 花點時間來看看這個:
def requires_login(view):
def new_view(request, *args, **kwargs):
if not request.user.is_authenticated():
return HttpResponseRedirect('/accounts/login/')
return view(request, *args, **kwargs)
return new_view
函數requires_login,傳入一個視圖函數view,而後返回一個新的視圖函數new_view.這個新的視圖函數new_view
在函數requires_login內定義 處理request.user.is_authenticated()這個驗證,從而決定是否執行原來的view函
數
如今,咱們能夠從views中去掉if not request.user.is_authenticated()驗證.咱們能夠在URLconf中很容易的用
requires_login來包裝實現.
5. django book2.0 chapter 8 13/17 page
get_view = kwargs.pop('GET', None)
post_view = kwargs.pop('POST', None)
if request.method == 'GET' and get_view is not None:
return get_view(request, *args, **kwargs)
elif request.method == 'POST' and post_view is not None:
return post_view(request, *args, **kwargs)
raise Http404
這裏,咱們重構method_splitter(),去掉了GET和POST兩個關鍵字參數,改而支持使用*args和和**kwargs(注意*
號) 這是一個Python特性,容許函數接受動態的、可變數量的、參數名只在運行時可知的參數。 若是你在函數
定義時,只在參數前面加一個*號,全部傳遞給函數的參數將會保存爲一個元組. 若是你在函數定義時,在參數前面加
兩個*號,全部傳遞給函數的關鍵字參數,將會保存爲一個字典
4.
查看django判斷文件的mimetype類型
import mimetypes
mimetypes.guess_type('t.css')
Django, Admin返回的CSS文件類型是application/x-css ,應該是text/css, 致使css沒法加載
上面不是有knownfiles = [
在裏面新建個文件
【八戒】愛
2016/2/23
添加進去
knownfiles = [
r"C:/Python34/mime.types",
編輯這個文件C:/Python34/mime.types添加
application/x-css css
text/css css
3.
C:\Python27\Lib\site-packages\Django-1.7.1-py2.7.egg\django\bin\mysite>python manage.py migrate
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~·····
這是由於舊版本和新的版本命令已經不同 的問題。
我用的是django =1.8.3,
寫好本身的model之後能夠換成這樣的命令來生成數據庫表:
python manage.py makemigrations books
而後:python manage.py sqlmigrate books 0001
這樣就能夠CREATE TABLE 了。
建議看最新版的英文版本數來學習。
2. http://segmentfault.com/a/1190000002754242
1.
http://www.cnblogs.com/Impulse/archive/2011/11/21/2256816.html
Django 新人開發的十個注意點
- 1. 5. 雜項
- 2. linux雜項
- 3. 雜項_convert
- 4. 雜項
- 5. LAMP5-雜項+Discuz3.2
- 6. Emacs雜項
- 7. Python雜項:迴文數判斷
- 8. 雜項之python利用pycrypto實現RSA
- 9. python學習筆記(四)--雜項
- 10. 雜項之rabbitmq
- 更多相關文章...
- • PHP 雜項 函數 - PHP參考手冊
- • XSD 雜項 數據類型 - XML Schema 教程
- • YAML 入門教程
- • 算法總結-股票買賣
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. vs2019運行opencv圖片顯示代碼時,窗口亂碼
- 2. app自動化 - 元素定位不到?別慌,看完你就能解決
- 3. 在Win8下用cisco ××× Client連接時報Reason 422錯誤的解決方法
- 4. eclipse快速補全代碼
- 5. Eclipse中Java/Html/Css/Jsp/JavaScript等代碼的格式化
- 6. idea+spring boot +mabitys(wanglezapin)+mysql (1)
- 7. 勒索病毒發生變種 新文件名將帶有「.UIWIX」後綴
- 8. 【原創】Python 源文件編碼解讀
- 9. iOS9企業部署分發問題深入瞭解與解決
- 10. 安裝pytorch報錯CondaHTTPError:******
- 1. 5. 雜項
- 2. linux雜項
- 3. 雜項_convert
- 4. 雜項
- 5. LAMP5-雜項+Discuz3.2
- 6. Emacs雜項
- 7. Python雜項:迴文數判斷
- 8. 雜項之python利用pycrypto實現RSA
- 9. python學習筆記(四)--雜項
- 10. 雜項之rabbitmq