Performance Without the Event Loop
英文原文html
譯文git
本文基於我今年早些時候在 OSCON 所作的一場演講。爲了簡明扼要,並針對我在演講後收到的一些反饋意見進行了編輯。程序員
談到 Go 的時候,一個常見的說法是,Go 是一種在服務器上運行良好的語言;靜態二進制文件、強大的併發性和高性能。github
本文重點討論最後兩項,Go 語言和它的運行時是如何透明地讓程序員編寫高度可伸縮的網絡服務器,而沒必要擔憂線程管理或 I/O 阻塞。編程
須要高效編程語言的一個依據
但在我開始技術討論以前,我想用兩個指標來講明 Go 語言的目標市場。緩存
摩爾定律
oft mis 援引摩爾定律稱,每平方英寸晶體管的數量大約每 18 個月翻一番。服務器
然而,時鐘頻率倒是一個功能徹底不一樣的特性,十年 Intel 設計的 Pentium 4 就在時鐘頻率上達到了峯值,並在那以後 CPU 的時鐘頻率一直在倒退。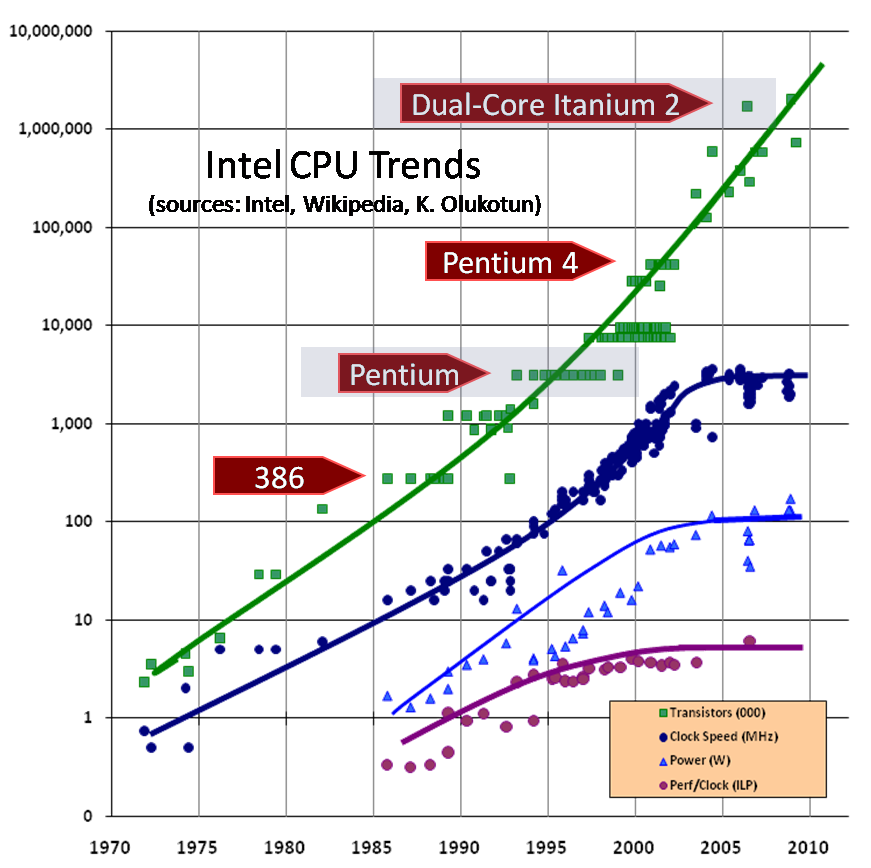
Image credit: Herb Sutter (Dr. Dobb’s Journal, March 2005)網絡
空間和功率限制

Sun Enterprise e450—about the size of a bar fridge, about the same power consumption. Image credit: eBay多線程
這是 SUN 公司的 e450。當我開始個人職業生涯時,他們是這個行業的主力。架構
這些東西是很是大的。三個這樣的機器疊在一塊兒,將裝滿 19 英寸的架子。它們每一個功率大約 500 瓦。
在過去的十年裏,數據中心已經從空間受限轉向電力受限。在我參與的前兩次數據中心部署中,當機架僅僅裝滿 1/3 時,咱們就達到了用電上限。
因爲計算密度提升得如此之快,數據中心空間再也不是一個問題。然而,現代服務器在更小的體積內消耗了更多的能源,這使得給機房降溫更加困難,但同時也是相當重要的。
在宏觀層面上受到功率上限的限制,你沒法爲一個機架 1200 瓦 1RU serverser 得到足夠的功率配額,而在微觀層面上,每個微小的硅片上消耗了數百瓦能源。
能源被消耗到哪裏去了?

CMOS Inverter. Image credit: Wikipedia
這是一個反向器,多是最簡單的邏輯門之一。若是輸入 A 爲高,那麼輸出 Q 爲低,反之亦然。
今天全部的消費電子產品都是用 CMOS 邏輯構建的。CMOS 表明互補金屬氧化物半導體。互補部分是關鍵。CPU 內部的每一個邏輯元件都由一對晶體管實現,一個開關打開,另外一個開關關閉。
當電路接通或斷開時,沒有電流直接從源極流向漏極。然而,在過渡期間有一個短暫的時期,兩個晶體管都導電,形成直接短路。
功耗,和所以致使的散熱,與每秒晶體管狀態轉換的次數成正比——CPU 時鐘頻率。
[1]
CMOS power consumption is not only caused by the short circuit current when the circuit is switching. Additional power consumption comes from charging the output capacitance of the gate, and leakage current through the MOSFET gate increases as the size of the transistor decreases. You can read more about this from in a the lecture materials from CMU’s ECE322 course. Bill Herd has a published a series of articles on how CMOS works.
CPU 特徵尺寸的下降主要是爲了下降功耗。減小電力消耗並不只僅意味着「綠色」。其主要目標是將功耗和散熱保持在致使 CPU 損壞的水平如下。
隨着時鐘頻率的降低,以及與功耗的直接衝突,性能的提升主要來自於微體系結構的調整和深奧的向量指令,它們對通常計算沒有直接的用處。總的來講,每個微架構(5 年一個週期)的變化在每一代中最多產生 10%的改進,最近只有 4-6%。
「免費午飯結束了」
但願如今你已經很清楚,硬件並無變得更快。若是性能和規模對你很重要,那麼你會贊成個人觀點,即至少在傳統意義上,靠堆硬件來解決這個問題的日子已經結束了。正如赫伯•薩特(Herb Sutter)所言:「免費午飯結束了。」
你須要一種高效的語言,由於低效的語言在生產上,在規模上,在資本支出的基礎上都是不合理的。
須要併發編程語言的一個依據
個人第二個論點緊跟着個人第一個論點。CPU 並無變快,而是變寬了。這就是晶體管的發展方向,這並不使人驚訝。

Image credit: Intel
多線程並行,或者如 Intel 所稱的超線程,容許一個內核在添加少許硬件的同時並行執行多個指令流。英特爾使用超線程來人爲地細分處理器市場,甲骨文和富士通更積極地將超線程應用到他們的產品中,每一個處理器核使用 8 或 16 個硬件線程。
自上世紀 90 年代末以來,Pentium Pro 就實現了 quad socket,如今大多數服務器都支持 dual socket 或者 quad socket 設計,dual socket 已成爲主流。晶體管數量的增長使得整個 CPU 處理單元能夠與同一硅片上的同級 CPU 處理單元共存。移動部件上的雙核,桌面部件上的四核,甚至服務器部件上的更多核如今都成爲了現實。在預算容許的狀況下,您能夠在服務器中購買儘量多的核心。
爲了利用這些額外的核心,您須要一種能有效開發出併發程序的編程語言。
處理器單元, 線程 和 goroutines
Go 有 goroutines,這是它能有效開發出併發程序的基礎。我想先退一步,來看看產生 goroutines 的歷史背景。
處理器單元
起初,計算機在批處理模型中一次運行一個任務。在 60 年代,對更多交互形式的計算的渴望致使了多處理,或分時操做系統的發展。到了 70 年代,這一想法已經在網絡服務器、ftp、telnet、rlogin 以及後來 Tim Burners-Lee 的 CERN httpd 上獲得了很好的應用,這些服務器經過劃分子進程來處理每一個傳入的網絡鏈接。
在分時系統中,操做系統經過記錄當前進程的狀態,而後恢復另外一個進程的狀態,從而在活動進程之間快速切換 CPU,從而保持併發的假象。這稱爲上下文切換。
上下文切換

Image credit: Immae (CC BY-SA 3.0)
上下文切換有三個主要成本。
- 內核須要存儲該進程的全部 CPU 寄存器的內容,而後恢復另外一個進程的值。由於進程切換能夠在進程執行的任何位置發生,因此操做系統須要存儲全部這些寄存器的內容,由於它不知道當前正在使用哪些寄存器
[2]
This is an oversimplification. In some cases the operating system can avoid saving and restoring infrequently used architectural registers by starting the the process in a mode where access to floating point or MMX/SSE registers will cause the program to fault, thereby informing the kernel that the process will now use those registers and it should from then on save and restore them. - 內核須要將 CPU 的虛擬地址刷新爲物理地址映射(TLB 緩存)
[3]
Some CPUs have what is known as a tagged TLB. In the case of tagged TLB support the operating system can tell the processor to associate particular TLB cache entries with an identifier, derived from the process ID, rather than treating each cache entry as global. The upside is this avoids flushing out entries on each process switch if the process is placed back on the same CPU in short order. - 操做系統上下文切換的開銷,以及選擇下一個進程佔用 CPU 的調度程序函數的開銷。
因爲與硬件相關,這些成本相對固定,而且依賴於上下文切換之間所作的工做量來攤銷它們的成本-快速上下文切換每每會超過上下文切換之間所作的工做量。
線程
這致使線程的被設計開發出來,線程在概念上與進程相同,但共享相同的內存空間。因爲線程共享地址空間,因此它們的調度比進程更輕鬆,所以建立和切換更快。
線程仍然有一個昂貴的上下文切換成本;必須保留許多狀態。Goroutines 將線程的概念又向前推動了一步。
Goroutines
goroutine 不是依賴內核來管理它們之間的調度,而是經過協做的方式調度的。goroutine 之間的切換隻發生在預先設計好的時間點,當顯式調用 Go 運行時調度程序時。goroutine 被調度器搶佔的主要緣由包括:
- 在 Channel(Go 特有的語言特性,另外一個是 goroutine)上產生阻塞的收發操做。
- Go 語言中 go 這個關鍵字的使用,雖然不能保證新的 goroutine 會當即被調度。
- 文件操做和網絡操做等系統調用。
- 因爲進入內存垃圾回收週期而被暫停。
換句話說,goroutine 的調度會在這些時間點發生,在不能獲得更多數據,一個 goroutine 沒法繼續執行時; 或者是在執行環境中,一個 goroutine 須要更多內存空間時。
許多 goroutine 在 Go 運行時被多路複用到一個操做系統線程上。這使得 goroutines 的制形成本和切換成本都很低。在一個進程中有成千上萬的 goroutine 是正常的,成百上千的 goroutine 是低於預期的。
從語言的角度來看,調度看起來像一個函數調用,而且具備相同的語義。編譯器知道當前正在使用寄存器並自動保存它們。線程調用包含一個特定 goroutine 棧的調度器,這個調度器返回另一個不一樣的 goroutine 棧。將此與線程應用程序進行比較,在線程應用程序中,能夠在任什麼時候間、任何指令搶佔線程。
這致使每一個 Go 進程的操做系統線程相對較少,而 Go 的 runtime 負責將一個可運行的 goroutine 分配給一個空閒的操做系統線程。
棧的管理
在前一節中,我討論了 goroutine 如何減小管理(有時是數十萬個)過多併發執行線程時的開銷。goroutine 還有另外一個方面,那就是堆棧管理。
進程地址空間
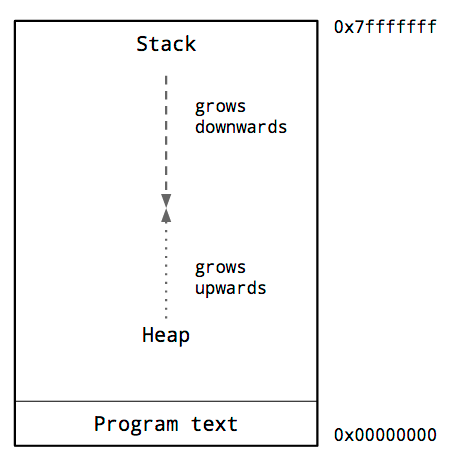
這是一個典型的進程內存佈局圖。咱們感興趣的關鍵是堆和棧的位置。
在進程的地址空間中,堆一般位於內存的底部,位於程序代碼之上,並向上增加。
堆棧位於虛擬地址空間的頂部,並向下增加。
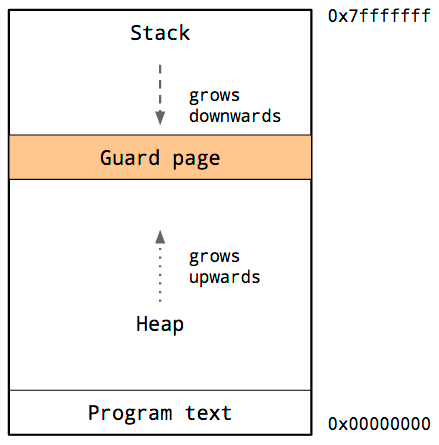
由於堆和棧相互覆蓋將是災難性的,因此操做系統在堆棧和堆之間安排了一個不可訪問的內存區域。
這稱爲保護頁,它有效地限制了進程的棧大小,一般按幾兆字節的順序。
線程棧
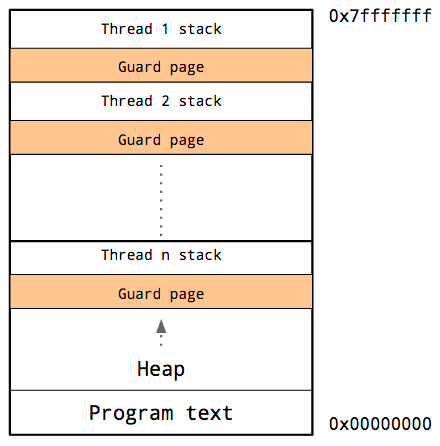
線程共享相同的地址空間,所以對於每一個線程,它必須有本身的棧和本身的保護頁。
因爲很難預測特定線程的棧需求,所以必須爲每一個線程的棧保留大量內存。並寄但願於需求會比這低,同時做爲警惕的保護頁永遠不會被觸發。
缺點是,隨着程序中線程數量的增長,可用地址空間的數量會減小。
管理 Goroutine 的棧
早期的進程模型容許程序員查看堆和棧,一邊觀察其是否足夠大,而沒必要爲此擔憂。缺點是複雜而昂貴的子進程模型。
線程稍微改善了這種狀況,但要求程序員猜想最合適的棧大小;過小,程序將停止;太大,虛擬地址空間將耗盡。
咱們已經看到,Go 運行時將大量 goroutine 調度到少許線程上,可是這些 goroutine 的棧需求如何呢?
Goroutine 棧的增加過程
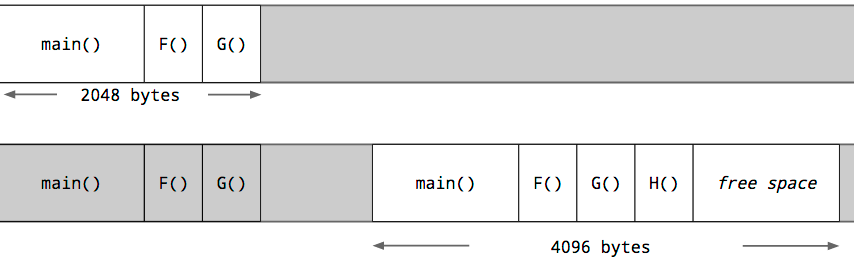
每一個 goroutine 都從堆中分配的一個小尺寸的棧開始。大小隨時間而變化,但在 Go 1.5 中,每個 goroutine 都以 2k 的分配開始棧。
Go 編譯器不使用保護頁,而是在每一個函數調用中插入一個檢查,以測試是否有足夠的棧空間供函數運行。若是有足夠的棧空間,函數將正常運行。(在函數的彙編代碼前面,由編譯器插入一段檢查代碼。這個動做能夠在函數定義前配置編譯器指令,禁用掉,不過要很是很是謹慎地使用)
若是空間不足,Go 進程的 runtime 將在堆上分配一個更大的棧空間,將當前棧的內容複製到新的棧空間,釋放舊的棧空間,而後從新啓動函數調用。
因爲這種檢查,goroutine 的初始堆棧能夠變得更小,這反過來又容許 Go 程序員將 goroutine 視爲廉價的資源。若是有足夠多的部分未被使用,Goroutine 棧也會收縮。這是在垃圾回收期間處理的。
集成的 network poller
2002 年,丹·凱格爾(Dan Kegel)發表了他所謂的c10k問題。簡單地說,如何編寫服務器軟件來處理天天至少 10000 個 TCP 會話。自從那篇論文撰寫以來,傳統觀點認爲高性能服務器須要原生線程(native threads),而最近的幾年,基於事件的循環代替了原生線程。
線程在調度成本和內存佔用方面有很高的開銷。事件循環下降了這些成本,可是這引入了回調驅動的複雜編程風格。
Go 爲程序員提供了一箭雙鵰解決方案。
Go 對 c10k 問題給出的解決方案
在 Go 中,系統調用一般是阻塞操做,這包括讀取和寫入文件描述符。Go 的 runtime 調度器經過找到一個空閒線程或生成另外一個線程來處理這個問題,以便在原始線程阻塞時繼續爲 goroutines 提供服務。實際上,這對於文件 IO 頗有效,由於少許阻塞線程能夠快速耗盡本地 IO 帶寬。
可是對於網絡套接字,按照設計,任什麼時候候幾乎全部的 goroutine 都將被阻塞,等待網絡 IO。在一個簡單的實現中,這將須要和 goroutine 同樣多的線程,全部線程都被阻塞,等待網絡流量。因爲 runtime 和 net 包之間的協做,集成到 Go 的 runtime 中的 network poller 能夠有效地處理這個問題。
在較早版本的 Go 中,network poller 是一個 goroutine,負責使用 kqueue 或 epoll 輪詢準備就緒通知。輪詢 goroutine 將經過 channel 與等待的 goroutine 通訊。這實現了避免每一個線程都作操做系統調用產生的瓶頸,而使用了經過 channel 發送消息這種通用喚醒機制。這意味着調度器不須要關心喚醒源,不須要把喚醒操做看的比較重要。
在 Go 的當前版本中,network poller 已經集成到 runtime 自己中。當 runtime 知道哪一個 goroutine 正在等待網絡套接字就緒時,它能夠在數據包到達時當即將 goroutine 放回相同的 CPU 上,從而減小延遲並增長吞吐量。
Goroutines, 棧管理和被集成了的 network poller
總之,goroutines 提供了一個強大的抽象,使程序員沒必要擔憂線程池或事件循環。
goroutine 的棧已經足夠大,而不須要考慮線程棧或線程池的大小。
被集成了的 network poller 容許程序員避免了複雜的回調風格代碼,同時仍然利用操做系統中可用的最有效的 IO 完成邏輯。
runtime 確保有足夠的線程來服務全部 goroutine 並保持 CPU 核處於活動狀態。
全部這些特性對 Go 程序員來講都是透明的。
原文做者相關文章:
- Hear me speak about Go performance at OSCON
- Go 1.1 performance improvements
- Go 1.2 performance improvements
- Go 1.1 performance improvements, part 2
歡迎轉載,請註明出處~
做者我的主頁
- 1. Understanding the node.js event loop
- 2. The Node.js Event Loop, Timers, and process.nextTick()
- 3. Event Loop
- 4. event loop
- 5. Event loop
- 6. 細談 Event Loop
- 7. 深刻Event Loop
- 8. Main event loop
- 9. Javascript event loop
- 10. 淺談 Event Loop
- 更多相關文章...
- • C# 事件(Event) - C#教程
- • Scala break 語句 - Scala教程
- • 爲了進字節跳動,我精選了29道Java經典算法題,帶詳細講解
- • 委託模式
-
每一个你不满意的现在,都有一个你没有努力的曾经。