Oracle 中總計和小計使用的函數
@[TOC](總計和小計、逐行累計求和)
### 1、總計和小計使用函數
#### 一、rollup
group by 咱們都知道,是一個分組函數,用於針對某一列作分組操做。
可是當它搭配其餘的函數一塊兒使用的時候,就像一對男女孩,撞出不同的火花。
==rollup(字段1,字段2,.....)
rollup和group by一塊兒使用,能夠針對每個分組返回一個小計行,以及爲全部的分組返回一個總計行(一個字段就是返回總計行,多個字段就是返回每個分組的一個小計行和一個總計行)==
實踐是檢驗真理的惟一標準,那咱們來實踐一下,咱們先來快速建立一個表。有多快,很快很快的那種。運維
```handlebars
CREATE TABLE EMP (
"EMPNO" NUMBER(4) NOT NULL ,
"ENAME" VARCHAR2(10 BYTE) ,
"JOB" VARCHAR2(9 BYTE) ,
"SAL" NUMBER(7,2) ,
"DEPTNO" NUMBER(2)
)
INSERT INTO "SCOTT"."EMP" VALUES ('1', '張三', '開發', '10000', '10');
INSERT INTO "SCOTT"."EMP" VALUES ('2', '李四', '運維', '6000', '20');
INSERT INTO "SCOTT"."EMP" VALUES ('3', '王五', '測試', '6000', '30');
INSERT INTO "SCOTT"."EMP" VALUES ('4', '麻子', '開發', '12000', '10');
```
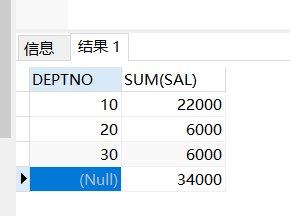
==當咱們的rollup裏面只有一個字段的時候,就返回一個總計行==函數
```handlebars
select deptno,sum(sal) from emp
group by rollup(deptno);
查詢結果:
10 22000
20 6000
30 6000
34000
```
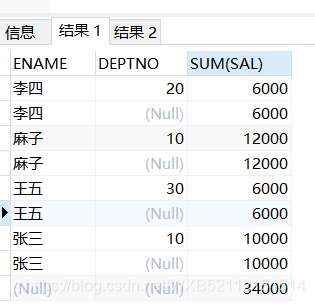
==當咱們傳遞兩個列字段的時候,就會按照第一個字段進行分組,返回一個小計行,最後返回一個總計行==測試
```handlebars
select ENAME,DEPTNO,sum(sal) from emp group by rollup(ENAME,DEPTNO);
李四 20 6000
李四 6000
麻子 10 12000
麻子 12000
王五 30 6000
王五 6000
張三 10 10000
張三 10000
34000code
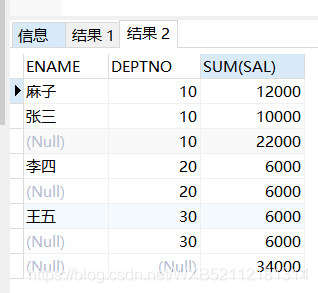
select ENAME,DEPTNO,sum(sal) from emp group by rollup(DEPTNO,ENAME);
麻子 10 12000
張三 10 10000
10 22000
李四 20 6000
20 6000
王五 30 6000
30 6000
34000
```
根據rollup()傳入的第一個字段不一樣,返回的結果是不同的。個人理解是,rollup()傳遞多字段的時候,會==先對多字段進行分組,而後對第一個字段進行分組==,好比上面的ename是第一個字段,多字段分組後就有四種,而後對第一字段分組後還剩四種,而且返回一個小計行,最後返回一個總計行
#### 二、cube
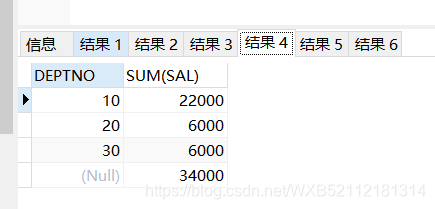
cube()傳遞一個字段的時候,和rollup是同樣的結果blog
```handlebars
select DEPTNO,sum(sal) from emp group by cube(DEPTNO) order by deptno;
10 22000
20 6000
30 6000
34000
```
可是cube()傳遞多個字段的時候,就和rollup()不同了,cube()對多字段的處理是先對全部的多字段進行分組,而後==對第一個字段進行分組,再對第二個字段進行分組,意思就是兩種分組合起來了==,從下面的結果咱們就能夠看出來,好比第二個字段是deptno,分組後會把相同的10作爲一組,因此能夠看到根據ename分組會產生一個小計行,再根據deptno分組後產生了一個小計行,最後返回一個總計行。就等於在rollup()的基礎上,咱們多了幾行分組的結果排序
```handlebars
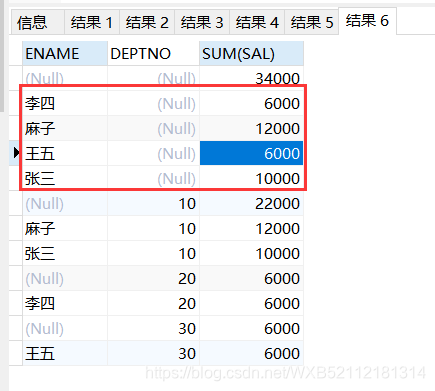
select ENAME,DEPTNO,sum(sal) from emp group by cube(ENAME,DEPTNO);
34000
10 22000
20 6000
30 6000
李四 6000
李四 20 6000
麻子 12000
麻子 10 12000
王五 6000
王五 30 6000
張三 10000
張三 10 10000圖片
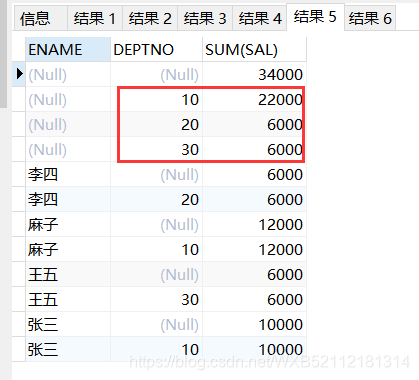
select ENAME,DEPTNO,sum(sal) from emp group by cube(DEPTNO,ENAME);
34000
李四 6000
麻子 12000
王五 6000
張三 10000
10 22000
麻子 10 12000
張三 10 10000
20 6000
李四 20 6000
30 6000
王五 30 6000
```開發
#### 三、grouping
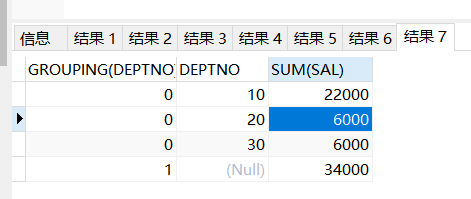
GROUPING函數能夠接受一列,返回0或者1。==若是列值爲空,那麼GROUPING()返回1;若是列值非空,那麼返回0==。GROUPING只能在使用ROLLUP或CUBE的查詢中使用。個人理解就是==用來填充使用rollup()和cube()產生的null值==it
```handlebars
select grouping(deptno),DEPTNO,sum(sal) from emp group by rollup(DEPTNO) ;
0 10 22000
0 20 6000
0 30 6000
1 34000
```
咱們使用==decode函數或case when==來填充爲null的值。
==DECODE(value,if 條件1,then 值1,if 條件2,then 值2,...,else 其餘值)==io
```handlebars
select decode(grouping(deptno),1,'總計',DEPTNO) deptno,sum(sal) from emp group by rollup(DEPTNO) ;
10 22000
20 6000
30 6000
總計 34000
```
!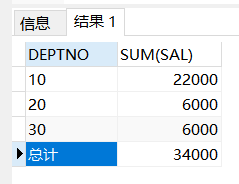
能夠看到咱們把第一次查詢結果中的null填充了一個「總計」,這裏使用的是rollup()配合,使用cube()也是同樣的。
#### 四、grouping sets
grouping sets()傳遞多字段就是分別對字段進行分組了,產生的結果就是多個字段分別分組後合起來的行。
```handlebars
select ENAME,DEPTNO,sum(sal) from emp group by grouping sets(ENAME,DEPTNO);
王五 6000
李四 6000
張三 10000
麻子 12000
30 6000
20 6000
10 22000
```
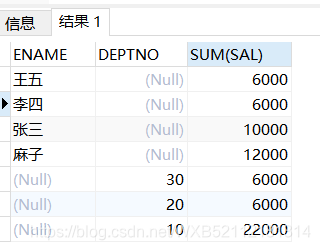
從結果咱們能夠看出,分別針對ename分組產生四行結果和對deptno分組產生三行結果。
#### 五、grouping_id
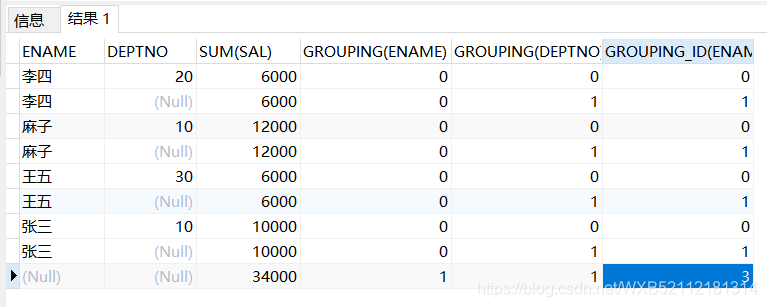
grouping_id()配合grouping()函數使用,會根據grouping()的值來決定,好比==grouping(字段1)爲0,grouping(字段2)爲1,則grouping_id(字段1,字段2)的結果就是1,若是grouping(字段1)爲1,grouping(字段2)爲0,則grouping_id(字段1,字段2)的結果就是2,若是grouping(字段1)爲1,grouping(字段2)爲1,則grouping_id(字段1,字段2)的結果就是3,==
```handlebars
select ename,deptno,sum(sal),
grouping(ename),
grouping(deptno),
grouping_id(ename,deptno)
from emp group by rollup(ename,deptno) ;
李四 20 6000 0 0 0
李四 6000 0 1 1
麻子 10 12000 0 0 0
麻子 12000 0 1 1
王五 30 6000 0 0 0
王五 6000 0 1 1
張三 10 10000 0 0 0
張三 10000 0 1 1
34000 1 1 3
```
### 2、逐行累計求和方法(OVER函數)
#### 一、sum(字段) over(partition by 字段1 order by 字段2....)
==over(partition by 字段1 order by 字段2....)
按字段1指定的字段進行分組排序,或者說按字段字段2的值進行分組排序==
```handlebars
select deptno,sal,
sum(sal) over (partition by deptno order by deptno) 逐行累計求和
from emp;
10 10000 22000
10 12000 22000
20 6000 6000
30 6000 6000
select deptno,sal,sum(sal) over ( order by deptno) 逐行累計求和from emp10 10000 2200010 12000 2200020 6000 2800030 6000 34000```從上面的結果咱們能夠看出,加了==partition by deptno==就會根據指定字段分組逐行累加求和,不然所有逐行累加求和。
- 1. oracle中函數的使用
- 2. 總結:MYSQL和ORACLE中經常使用到的函數
- 3. MySQL中統計函數的使用
- 4. 【轉】Oracle中sign函數和decode函數的使用
- 5. Oracle中trunc函數、round 函數、ceil函數和floor函數的使用
- 6. SQLSERVER 使用 ROLLUP 彙總數據,實現分組統計,總計(合計),小計
- 7. mysql 函數小計
- 8. ORACLE統計分析函數
- 9. Oracle 分組統計函數
- 10. 柵格計算器中con()函數和setnull()函數的用法
- 更多相關文章...
- • 在Spring中使用Redis - Redis教程
- • Redis中使用Lua語言 - Redis教程
- • 使用Rxjava計算圓周率
- • TiDB 在摩拜單車在線數據業務的應用和實踐
-
每一个你不满意的现在,都有一个你没有努力的曾经。