HTML5語音合成Speech Synthesis API簡介
要在前端實現語音合成,即將文字講述出來,一開始考慮用百度tts語音合成的方法,後來發現html5 自己就支持語音合成。就直接用html5的咯,百度的那個還有調用次數限制,配置還麻煩
1、關於HTML5語音Web Speech API
HTML5中和Web Speech相關的API實際上有兩類,一類是「語音識別(Speech Recognition)」,另一個就是「語音合成(Speech Synthesis)」,這兩個名詞聽上去很高大上,實際上指的分別是「語音轉文字」,和「文字變語音」。html
而本文要介紹的就是這裏的「語音合成-文字變語音」。爲何稱爲「合成」呢?比方說你Siri發音「你好,世界!」 其實是把「你」、「好」、「世」、「界」這4個字的讀音給合併在一塊兒,所以,稱爲「語音合成」。前端
「語音識別」和「語音合成」看上去像是正反兩方面,應該帶有鏡面氣質,實際上,至少從兼容性來看,二者並沒有法直接對等。html5
「語音識別(Speech Recognition)」目前的就Chrome瀏覽器和死忠小弟Opera瀏覽器默認支持,而且須要webkit私有前綴: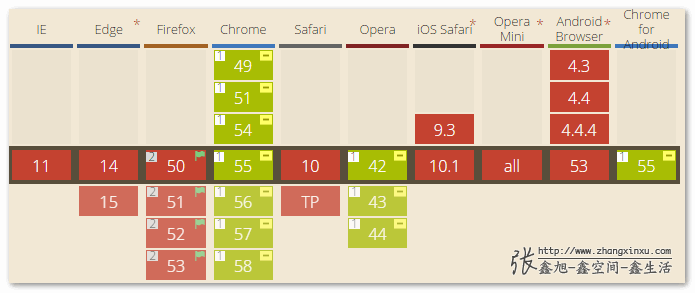 web
web
可是,「語音合成(Speech Synthesis)」的兼容性要好上太多了,以下圖: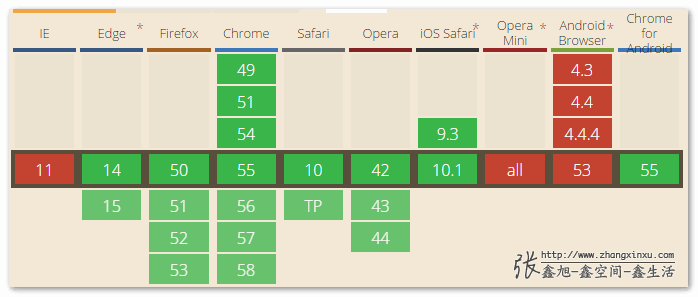 chrome
chrome
因此,本文主要介紹下理論上更爲適用的HTML5 Speech Synthesis API。不過在此以前,Speech Recognition API仍是簡單提一下。數組
Speech Recognition API也就是語音識別功能,須要麥克風等音頻輸入設備的支持,在Chrome瀏覽器下,實際上能夠添加簡單的屬性就可讓部分控件有語音識別功能,一行JS都不須要寫,這個我以前有專門寫文章介紹過:「漸進使用HTML5語言識別, so easy!」瀏覽器
就是在輸入框上加一個x-webkit-speech屬性便可,例如:服務器
<input x-webkit-speech />
然而,我剛剛打開demo頁面一測試,發現原來有的麥克風(下圖爲之前截圖)竟然不見了。。。。看來已經被chrome無情拋棄了!網絡

好吧,就當我上面的內容,什麼都沒說過。不過有一點是能夠確定的,就是原來輸入框上的那個語音識別底層就是使用的Speech Recognition API,所以存在必定的共性,比方說文字內容識別須要google服務器返回,所以功能就與網絡環境有很大關係,比方說google被牆了,或者網速很慢了,都有可能致使識別出現異常。數據結構
使用的基本套路以下:
- 建立SpeechRecognition的新實例。因爲到目前爲止,瀏覽器尚未普遍支持,因此須要
webKit的前綴:var newRecognition = webkitSpeechRecognition();
- 設置是持續聽仍是聽到聲音以後就關閉接收。經過設置
continuous屬性值實現。通常聊天溝通使用false屬性值,若是是寫文章寫公衆號之類的則能夠設置爲true,以下示意:newRecognition.continuous = true;
- 控制語音識別的開啓和中止,可使用start()和stop()方法:
// 開啓 newRecognition.start(); // 中止 newRecognition.stop();
- 對識別到的結果進行處理,可使用一些事件方法,比方說
onresult:newRecognition.onresult = function(event) { console.log(event); }event是個對象,我家裏電腦不知道什麼緣由,沒法成功返回識別內容,顯示網絡錯誤,可能由於牆的緣故:
因此,我從網上找了下大體數據結構:
{ .. results: { 0: { 0: { confidence: 0.695017397403717, transcript: "你好,世界" }, isFinal:true, length:1 }, length:1 }, .. }
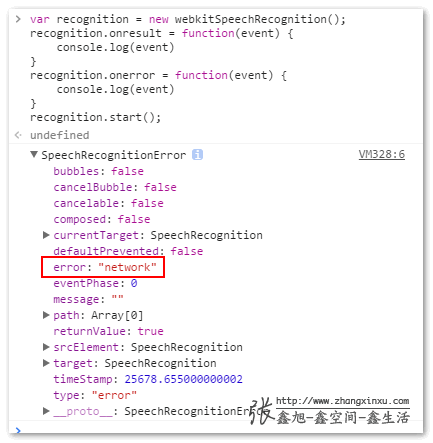
除了result事件外,還有其餘一些事件,例如,soundstart、speechstart、error等。
2、關於語音合成Speech Synthesis API
先從最簡單的例子提及,若是想讓瀏覽器讀出「你好,世界!」的聲音,能夠下面的JS代碼:
var utterThis = new window.SpeechSynthesisUtterance('你好,世界!');
window.speechSynthesis.speak(utterThis);
沒錯,只須要這麼一點代碼就足夠了,你們能夠在本身瀏覽器的控制檯裏面運行上面兩行代碼,看看有沒有讀出聲音。
上面代碼出現了兩個長長的對象,SpeechSynthesisUtterance和speechSynthesis,就是語音合成Speech Synthesis API的核心。
首先是SpeechSynthesisUtterance對象,主要用來構建語音合成實例,例如上面代碼中的實例對象utterThis。咱們能夠直接在構建的時候就把要讀的文字內容寫進去:
var utterThis = new window.SpeechSynthesisUtterance('你好,世界!');
又或者是使用實例對象的一些屬性,包括:
text– 要合成的文字內容,字符串。lang– 使用的語言,字符串, 例如:"zh-cn"voiceURI– 指定但願使用的聲音和服務,字符串。volume– 聲音的音量,區間範圍是0到1,默認是1。rate– 語速,數值,默認值是1,範圍是0.1到10,表示語速的倍數,例如2表示正常語速的兩倍。pitch– 表示說話的音高,數值,範圍從0(最小)到2(最大)。默認值爲1。
所以上面的代碼也能夠寫做:
var utterThis = new window.SpeechSynthesisUtterance(); utterThis.text = '你好,世界!';
不只如此,該實例對象還暴露了一些方法:
onstart– 語音合成開始時候的回調。onpause– 語音合成暫停時候的回調。onresume– 語音合成從新開始時候的回調。onend– 語音合成結束時候的回調。
接下來是speechSynthesis對象,主要做用是觸發行爲,例如讀,停,還原等:
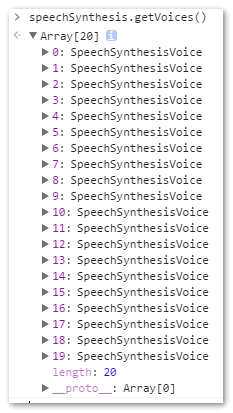
speak()– 只能接收SpeechSynthesisUtterance做爲惟一的參數,做用是讀合成的話語。stop()– 當即終止合成過程。pause()– 暫停合成過程。resume()– 從新開始合成過程。getVoices– 此方法不接受任何參數,用來返回瀏覽器支持的語音包列表,是個數組,例如,在個人電腦下,Firefox瀏覽器返回的語言包是兩個:而在chrome瀏覽器下,數量就很驚人了:
雖然數量不少,是有種給人中看不中用的感受,爲何這麼說呢!在個人chrome瀏覽器下,不知道爲何,不會讀任何聲音,可是一樣的demo見面,公司的電腦就能夠,我後來仔細查了一下,有可能(20%可能性)是我家裏的電腦win7版本是閹割版,沒有安裝或配置TTS引擎。
手機Safari瀏覽器也不會讀。
其中,17是普通話大陸:
另外,
getVoices的獲取是個異步的過程,所以,你能夠直接在控制檯輸入,speechSynthesis.getVoices()返回的是一個空數組,不要緊,多試幾回,或者搞個定時器之類的。

3、語音合成Speech Synthesis API有什麼用
對於盲人或弱視用戶,每每會藉助一些輔助設備或者軟件訪問咱們的網頁,其原理是經過觸摸或定位某些元素髮出聲音,來讓用戶感知內容。
有了語音合成Speech Synthesis API,對於這類用戶,以及開發人員本身,都會帶來必定的便利性。首先對於視覺有障礙的用戶,他們就不須要再安裝其餘軟件或購買其餘設備,就能夠無障礙地訪問咱們的產品。對於開發人員本身,咱們的無障礙建設能夠變得更加靈活,不必定要百分百契合ARIA無障礙規範(可參見我以前文章「WAI-ARIA無障礙網頁應用屬性徹底展現」),由於咱們能夠直接讓瀏覽器合成我想要的語音內容,例如,VoiceOver在對一些標籤讀取的時候,總會附帶一句「標誌性內容」,就算對於我這樣專業從業者,這個詞也是有點生澀難懂的,咱們其實能夠把這個語音合成交給本身,使用更通俗易懂的詞反饋給用戶,我想體驗上應該是更好的。
至少我會在17年,嘗試在一些產品上推進這方面工做的建設。
另一個就是二維碼識別,有時候肉眼看得眼睛疼,加個按鈕讓用戶聽。
等等~
- 1. HTML5語音合成Speech Synthesis API簡介
- 2. HTML5 之音頻合成(Speech Synthesis)
- 3. 語音合成vocoder(五) synthesis
- 4. HTML5語音合成
- 5. 百度語音合成api
- 6. 語音識別(語音轉文字)&& 語音合成(文字轉語音)
- 7. 語音識別與語音合成
- 8. HTML5 Web Speech API,讓網站更有趣
- 9. 語音合成 | FastSpeech:Fast,Robust and Controllable Text to Speech論文閱讀
- 10. 語音合成Parallel Neural Text-to-Speech論文閱讀
- 更多相關文章...
- • Thymeleaf簡介 - Thymeleaf 教程
- • jQuery Mobile 簡介 - jQuery Mobile 教程
- • Github 簡明教程
- • Kotlin學習(一)基本語法
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Window下Ribbit MQ安裝
- 2. Linux下Redis安裝及集羣搭建
- 3. shiny搭建網站填坑戰略
- 4. Mysql8.0.22安裝與配置詳細教程
- 5. Hadoop安裝及配置
- 6. Python爬蟲初學筆記
- 7. 部署LVS-Keepalived高可用集羣
- 8. keepalived+mysql高可用集羣
- 9. jenkins 公鑰配置
- 10. HA實用詳解
- 1. HTML5語音合成Speech Synthesis API簡介
- 2. HTML5 之音頻合成(Speech Synthesis)
- 3. 語音合成vocoder(五) synthesis
- 4. HTML5語音合成
- 5. 百度語音合成api
- 6. 語音識別(語音轉文字)&& 語音合成(文字轉語音)
- 7. 語音識別與語音合成
- 8. HTML5 Web Speech API,讓網站更有趣
- 9. 語音合成 | FastSpeech:Fast,Robust and Controllable Text to Speech論文閱讀
- 10. 語音合成Parallel Neural Text-to-Speech論文閱讀