數據庫技術丨GaussDB(DWS)數據同步狀態查看方法
摘要:針對數據同步狀態查看方法,GaussDB(DWS)提供了豐富的系統函數、視圖、工具等能夠直觀地對同步進度進行跟蹤,尤爲是爲方便定位人員使用,gs_ctl工具已集合了大部分相關係統函數的調用,可作到在任什麼時候間,從未啓動、啓動、重建到運行時的關鍵信息顯示。
1 背景概述:
1.1DN高可用架構模型
要理解或描述數據同步的過程機制,須要首先要了解GaussDB(DWS)的DN高可用架構,理解涉及數據同步的各組件的關係、數據類型、數據流向、設計原理和目的。sql
GaussDB(DWS)的DN高可用架構爲主、備、從備架構。即在分佈式環境中,完整的集羣數據採用分片技術分佈在多個DN組上,每組DN承擔一個數據分片,包括:一個主DN、一個備DN和一個從備DN。主和備各有一份完整的數據,從備上通常不存儲數據,僅在備機故障時作數據的暫存。組件之間關係如圖1所示:數據庫
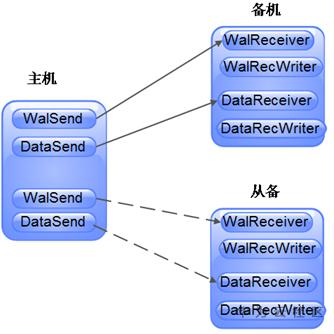
圖1 DN高可用架構關係圖架構
主、備、從備高可用架構下,主、備及主、從備之間均會創建流複製通道。流複製又分爲日誌複製和數據頁複製。日誌複製用於同步主DN因爲WAL機制刷到磁盤上的XLOG,同步到備DN進行回放。數據頁複製用於同步批量導入的行存數據、或列存CU文件。須要注意的一點是,從備僅用於存放XLOG和數據,回放(replay)僅發生在備DN上。運維
1.2 數據同步涵蓋範圍
數據同步就是涉及集羣中主、備節點以及從備節點之間的日誌複製數據的傳輸、回放,數據頁複製數據的傳輸、追趕,備機重建等過程。GaussDB(DWS)集羣高可用實踐WAL(Write Ahead Logging)思想,並經過各組件的主備的數據同步、倒換、重建等機制,保證數據庫單實例遭遇Crash後,具有故障恢復及自愈的能力,保護數據庫中數據的可靠性和完整性,最終實現集羣對外業務連續性的過程。分佈式
這些主要的過程有:函數
(1)主備之間的正常流複製工具
每組DN獨立承擔一個數據分片,所以要求各個DN主與備必須強同步。爲保證DN的主備強同步,數據在主DN操做時產生日誌,事務提交時將日誌同步給備DN。備機對接收到的XLOG進行回放(replay),將日誌轉爲數據。另外,列存和行存批插場景下,備機正常時,新增(變動)數據會發往備機。使用數據頁同步相對於日誌同步少了磁盤IO,能夠提高同步效率,減少RTO。spa
(2)備機追趕線程
爲了解決單節點故障後集羣寫事務可用,DN的高可用設計引入從備這個實例。一旦備DN故障,數據將發送給從備,仍然保證了數據寫兩份的原則,事務照樣能夠提交。但主機會對BCM文件裏面的標記位置狀態位。BCM文件中每一bit位(除預留位外)對應數據文件中每一頁(8k)狀態。設計
當備機從新啓動的時候,會鏈接主機作數據頁追趕(catchup)。追趕機制分爲全量和增量兩種。全量catchup機制,不依賴於從備,主機遞歸掃描本地默認表空間和自定義表空間下的全部BCM文件,而後查看狀態位來確認哪些數據文件須要發送給備機。增量catchup機制依賴於從備,主機通知從備遍歷其從備上暫存的數據頁,將變動的數據頁列表發往主機,主機直接按照從備發來的變動列表,將變動數據發往備機。
(3)主備倒換
當主DN故障時,須要對備DN進行failover,failover後備DN升爲主DN來接管業務。因此failover時,備DN須要鏈接從備DN,向從備DN請求數據,以補齊備DN比主DN缺乏的數據。failover的過程是備DN獨立完成的,不須要和主DN進行交互。
(4)備機重建
重建功能主要目的是單點故障修復,備機重建方式按照實現分爲全量重建和增量重建,均和主DN進行交互。全量重建是備機清空數據目錄,保留配置文件,向主機發送全量重建請求,主機將本身的數據目錄除了配置文件外,所有發給備機,重建後啓動備機。增量重建是一種以主DN文件爲基準,按照文件塊對備DN文件進行校驗,若是備DN文件的某個文件塊校驗不一致,則主機將此文件塊發給備DN,寫入文件對應的文件塊中。與全量重建相比較,拷貝的數據量和WAL日誌量都更少,代價更小。
從以上這些數據同步過程當中,咱們發現表如今運維上一個明顯的特色是,這些過程有可能會時間花費較長,一旦同步過程當中出現異常問題,其內部關鍵過程信息輸出對於問題分析定位十分重要。所以,GaussDB(DWS)提供了豐富的系統函數、視圖、工具等能夠直觀地對同步進度進行跟蹤,尤爲是爲方便定位人員使用,gs_ctl工具已集合了大部分相關係統函數的調用,可作到在任什麼時候間,從未啓動、啓動、重建到運行時的關鍵信息顯示。
2 方法總結
2.1 系統視圖
總結涉及數據同步的系統視圖如表1所示。具體參數、返回值定義請參考相應版本的產品文檔手冊。

2.2 系統函數
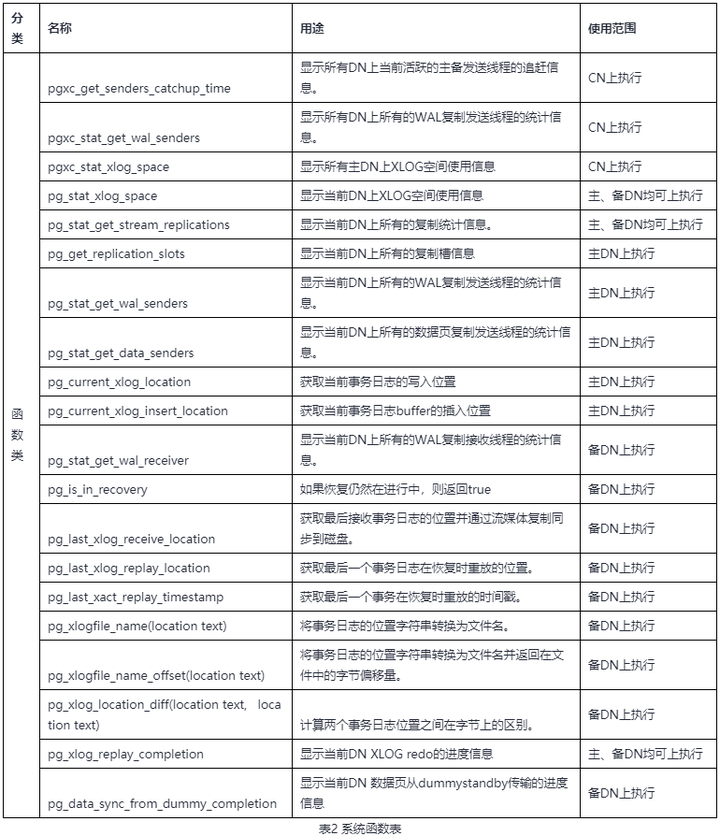
總結涉及數據同步的系統函數如表2所示。具體參數、返回值定義請參考相應版本的產品文檔手冊。
2.3 經常使用工具
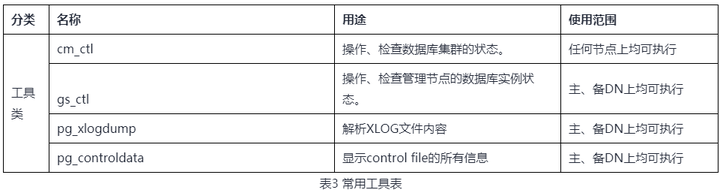
總結涉及數據同步的經常使用工具如表3所示。具體工具說明、參數定義請參考相應版本的產品文檔手冊中的定義。
3 應用場景
3.1 查看DN實例Redo進度
當DN實例crash發生時,咱們能夠經過回放XLOG日誌中記錄的數據變化還原crash前的操做。這個就是所謂的redo/recovery過程。若是須要redo的XLOG比較多,或者遇到某種特殊日誌類型,對DN實例進行啓動,啓動過程時間就會有些長。
DN實例啓動過程當中,若是指望查看XLOG redo的進度。最方便的是使用gs_ctl query工具對指定DN實例路徑進行狀態查詢,結果中能夠顯示xlog redo的進度,如圖2所示。此外,在DN實例能夠接受gsql鏈接時(啓動到最小恢復點以前是拒絕鏈接的),也可直接在當前DN上執行pg_xlog_replay_completion 函數來獲取XLOG redo進度信息。

圖2 DN實例啓動時XLOG Redo進度查詢
啓動Redo進度相關信息(Xlog replay info)包括:
- replay_start:Xlog Redo的起始LSN 。DN實例啓動XLOG redo過程時,記錄replay_start。
- replay_current:Xlog Redo的當前replay的LSN。
- replay_end:DN本地接收到的最大XLOG lsn。
- replay_percent:Xlog Redo的當前完成的百分比。(replay_current - replay_start)*100 / (replay_end - replay_start)的計算值。
依據replay_current的變化,能夠看到XLOG redo的推動。
依據replay_percent和啓動開始時間,能夠推測DN實例啓動到正常狀態的所需時間。
3.2 查看備機Failover進度
當主機發生故障時,咱們須要將備機failover成主機,此時備機須要鏈接從備同步XLOG和數據頁文件。若是須要同步的XLOG比較多,或者遇到某種特殊日誌類型,或者數據文件比較多時,對備DN實例進行failover,過程時間就會有些長。
備機failover升主過程當中,若是指望查看XLOG redo和數據頁文件同步的進度。最方便的是使用gs_ctl query工具對指定DN實例路徑進行狀態查詢,結果中能夠顯示xlog redo的進度和從備數據同步的進度,如圖3所示。此外,在DN實例能夠接受gsql鏈接時,也可直接在當前DN上執行pg_data_sync_from_dummy_completion 函數來獲取從備數據文件同步的進度信息。
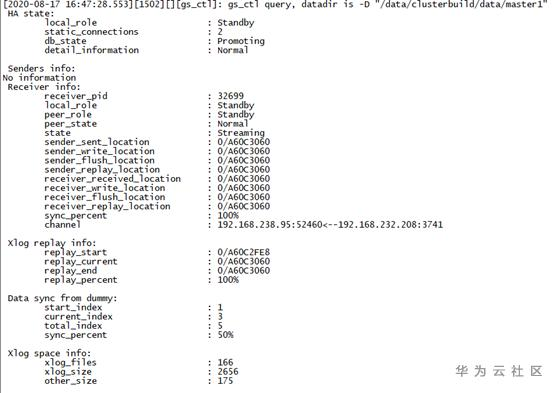
圖3 備機Failover進度查詢
Failover Redo進度相關信息(Xlog replay info),字段含義同Start Redo,區別在於,備DN在處理failover請求鏈接從備時候獲取最新的replay lsn更新了replay_start。
Failover數據頁文件進度相關信息(Data sync from dummy)包括:
- start_index:數據頁文件同步的起始編號。
- current_index:數據頁文件同步的當前編號。
- total_index:數據頁文件同步的最大編號。
- sync_percent:數據頁文件當前完成的百分比。(current_index - start_index) *100/ (total_index - start_index + 1) 的計算值。
依據current_index的變化,能夠看到數據頁同步的推動。
依據sync_percent和failover開始時間,能夠推測DN實例failover到正常狀態的所需時間。
3.3 查看備機Catchup進度
當備機從新啓動的時候,會鏈接主機作數據頁追趕(catchup)。若是須要傳輸的數據頁比較多,或者由於業務形成的鎖衝突,catchup 時間就會比較長,備DN長時間不能成爲Normal狀態。
若是指望查看數據頁catchup的進度,能夠在CN上執行select * from pgxc_get_senders_catchup_time()可進行當前活躍的主備發送線程的追趕信息顯示,如圖4所示。

圖4 集羣上catchup進度查詢
也能夠在相應的主DN上執行select * from pg_get_senders_catchup_time可進行當前活躍的主備發送線程的追趕信息顯示。完成後,看到的是剛結束的catchup過程信息,如圖5所示。

圖5 主DN上catchup進度查詢
備機Catchup進度相關信息包括:
- catchup_type:"Incremental"或者"Full"。catchup方式爲全量仍是增量。
- catchup_bcm_filename:當前主機正在處理的一個BCM文件名稱。
- catchup_bcm_finished:catchup已操做完成的BCM文件數量。
- catchup_bcm_total:catchup總共須要操做的BCM文件數量。
- catchup_percent:catchup已經操做完成的百分。catchup_bcm_finished*100 / catchup_bcm_total 的計算值。
- catchup_remaining_time:依據已完成的進度,預估剩餘完成時間。
依據catchup_bcm_filename和catchup_bcm_finished的變化,能夠看到數據頁追趕的推動。
依據catchup_percent和catchup_remaining_time,能夠推測備DN實例追趕到正常狀態的所需時間。
3.4 查看DN實例XLOG空間使用情況
隨着數據庫的不斷運行,產生的日誌文件愈來愈多,若是由於節點故障或其它緣由有可能形成日誌文件不斷積累而充爆磁盤。爲了解此使用信息,最方便的是使用gs_ctl query工具對指定DN實例路徑進行狀態查詢,結果中能夠顯示該實例的XLOG空間使用信息,截圖示例請參見上面其它場景。此外,還提供系統函數 pgxc_stat_xlog_space、pg_stat_xlog_space 對數據庫集羣或單個實例進行查詢,例如使用pgxc_stat_xlog_space能夠獲取到整個集羣的CN、主DN的XLOG空間使用信息,如圖6所示。

圖6 Xlog空間使用查詢
XLOG空間使用信息(Xlog space info)包括:
- xlog_files:pg_xlog目錄下,去除backup、archive_status等子目錄,全部識別爲xlog文件的數目;
- xlog_size:pg_xlog目錄下,去除backup、archive_status等子目錄,全部識別爲xlog文件的大小之和,以MB單位顯示;
- other_size:pg_xlog目錄下backup、archive_status等子目錄文件的大小之和,以MB單位顯示。
- 1. 數據庫技術丨GaussDB(DWS)數據同步狀態查看方法
- 2. mysql 數據庫 鎖狀態查看
- 3. 查看MySQL數據庫狀態信息
- 4. Oracle數據庫查看用戶狀態
- 5. 查看Oracle數據庫狀態
- 6. 數據庫狀態檢查
- 7. linux shell mysql 數據庫主從同步狀態檢查告警
- 8. 數據同步-數據庫與數據庫之間的同步
- 9. 數據庫系統丨數據庫常用恢復技術
- 10. mysql8 同步數據庫到 mysql5 方法
- 更多相關文章...
- • 數據庫涉及到哪些技術? - MySQL教程
- • HTTP狀態碼 - HTTP 教程
- • Flink 數據傳輸及反壓詳解
- • TiDB 在摩拜單車在線數據業務的應用和實踐
-
每一个你不满意的现在,都有一个你没有努力的曾经。