Mongodb Geo2d索引原理
騰訊雲技術社區-掘金主頁持續爲你們呈現雲計算技術文章,歡迎你們關注!javascript
做者:孔德雨java
Mongodb的geo索引是其一大特點,本文從原理層面講述geo索引中的2d索引的實現mongodb
2d 索引的建立與使用
經過 架構
db.coll.createIndex({"lag":"2d"}, {"bits":int}))複製代碼
來建立一個2d索引,索引的精度經過bits來指定,bits越大,索引的精度就越高。更大的bits帶來的插入的overhead能夠忽略不計。測試
經過大數據
db.runCommand({
geoNear: tableName,
maxDistance: 0.0001567855942887398,
distanceMultiplier: 6378137.0,
num: 30,
near: [ 113.8679388183982, 22.58905429302385 ],
spherical: true|false})複製代碼
來查詢一個索引,其中spherical:true|false 表示應該如何理解建立的2d索引,false表示將索引理解爲平面2d索引,true表示將索引理解爲球面經緯度索引。這一點比較有意思,一個2d索引能夠表達兩種含義,而不一樣的含義是在查詢時被理解的,而不是在索引建立時。優化
2d索引的理論
Mongodb 使用一種叫作Geohash的技術來構建2d索引,可是Mongodb的Geohash並無使用國際通用的每一層級32個grid的Geohash描述方式(見wiki geohash)。而是使用平面四叉樹的形式。以下圖:ui

很顯然的,一個2bits的精度能把平面分爲4個grid,一個4bits的精度能把平面分爲16個grid。2d索引的默認精度是長寬各爲26,索引把地球分爲(2^26)(2^26)塊,每一塊的邊長估算爲雲計算
2*PI*6371000/(1<<26) = 0.57 米複製代碼
mongodb的官網上說的60cm的精度就是這麼估算出來的:spa
By default, a 2d index on legacy coordinate pairs uses 26 bits of precision, which is roughly equivalent to 2 feet or 60 centimeters of precision using the default range of -180 to 180.
2d索引在Mongodb中的存儲
上面咱們講到Mongodb使用平面四叉樹的方式計算Geohash。事實上,平面四叉樹僅存在於運算的過程當中,在實際存儲中並不會被使用到。
插入
對於一個經緯度座標[x,y],MongoDb計算出該座標在2d平面內的grid編號,該編號爲是一個52bit的int64類型,該類型被用做btree的key,所以實際數據是按照 {GeoHashId->RecordValue}的方式被插入到btree中的。
查詢
對於geo2D索引的查詢,經常使用的有geoNear和geoWithin兩種。geoNear查找距離某個點最近的N個點的座標並返回,該需求能夠說是構成了LBS服務的基礎(陌陌,滴滴,摩拜), geoWithin是查詢一個多邊形內的全部點並返回。咱們着重介紹使用最普遍的geoNear查詢。
geoNear的查詢過程
geoNear的查詢語句以下:
db.runCommand(
{
geoNear: "places", //table Name
near: [ -73.9667, 40.78 ] , // central point
spherical: true, // treat the index as a spherical index
query: { category: "public" } // filters
maxDistance: 0.0001531 // distance in about one kilometer
}
)複製代碼
geoNear能夠理解爲一個從起始點開始的不斷向外擴散的環形搜索過程。以下圖所示:
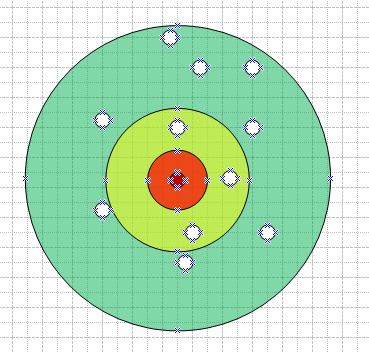
因爲圓自身的性質,外環的任意點到圓心的距離必定大於內環任意點到圓心的距離,因此以圓環進行擴張迭代的好處是:
1)減小須要排序比較的點的個數
2)可以儘早發現知足條件的點從而返回,避免沒必要要的搜索
集密度估算
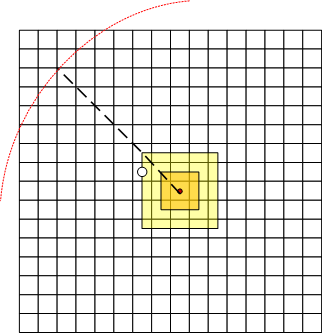
那麼,如何肯定初始迭代步長呢,mongoDB認爲初始迭代步長和點集密度相關。
geoNear 會根據點集的密度來肯定迭代的初始步長。估算步驟以下:
1)從最小步長默認爲60cm向外以矩形範圍搜索,若是範圍內有至少一個點,則中止搜索,轉3)不然轉 2)
2)步長倍增,繼續步驟1)
3)以矩形對角線長度的三倍做爲初始迭代步長。
圓環覆蓋與索引前綴原理
上面咱們說過,每一次的搜索都是以圓環爲單位進行的,可是真實存入Btree中的是{GeoHashId->RecordValue},計算出與圓環相交的全部邊長60cm的格子的GeoHash的值並在Btree中搜素絕對是一個很是愚蠢的作法,由於若是圓環的面積很大,光是枚舉全部的GeoHash就有上百萬個*。
可是換個角度來看,其實以地球爲一個總體去看待存儲的點,絕對是稀疏的。這個稀疏的性質使得咱們能夠粗略的以平面四叉樹的角度自上而下的找出與圓環相交的四叉樹中間節點。
整個平面與圓環必然是相交的,因而將平面一分爲四,剔除不相交的部分,對於每一個留下來的子平面,繼續一分爲四,剔除不相交的部分,通過多輪迭代,留下來的子平面的GeoHash都是該子平面中全部grid的索引前綴,以下面四幅圖所示:
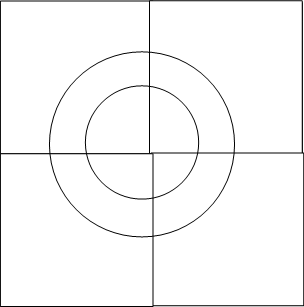
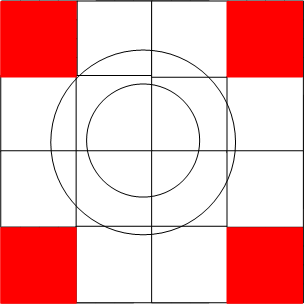

上面四幅圖中,分別爲整個平面被四叉樹劃分0,1,2,3次後與圓環的相交狀況,若是繼續往下細分,所造成的圖形就愈來愈逼近整個圓環。MongoDB中使用參數internalGeoNearQuery2DMaxCoveringCells來限制最多逼近到多少個子平面與圓環相交,默認爲16。
咱們注意到,上述平面劃分過程爲四叉樹的分裂過程,每一次分裂都使得遞歸搜索的子平面與父平面有相同的GeoHash前綴(這裏須要思考爲何,可能不太明顯),所以每個子平面能夠對應於BTree中一段連續的Range(這裏又是爲何?),也正所以,該參數越大,會使得須要搜索的子平面越少,可是會使得Btree的Range搜索更趨向於隨機化搜索,致使更多的IO。咱們知道Btree更適合於作Range搜索,因此對該參數的調整須要慎重。
展望
MongoDB原生的geoNear接口是國內各大LBS應用的主流選擇。騰訊雲的MongoDB專家通過測試發現,在點集稠密的狀況下,MongoDB原生的geoNear接口效率會急劇降低,單機甚至不到1000QPS。騰訊雲MongoDB對此進行了持續的優化,在不影響效果的前提下,geoNear的效率有10倍以上的提高,建議你們選擇騰訊雲MongoDB最爲LBS應用的存儲方案。
相關推薦
MongoDB複製集原理
基於用戶畫像大數據的電商防刷架構
MongoDb Mmap引擎分析
- 1. M14-MongoDB索引原理及使用
- 2. 索引原理
- 3. Mongodb地理空間索引
- 4. Mongodb 地理位置索引
- 5. mongoDB 學習筆記(四)索引 索引管理 空間索引
- 6. MongoDB 索引
- 7. [MongoDB]索引
- 8. MongoDB的索引
- 9. mongoDB 索引
- 10. Mongodb索引
- 更多相關文章...
- • SQLite 索引(Index) - SQLite教程
- • MySQL索引簡介 - MySQL教程
- • ☆技術問答集錦(13)Java Instrument原理
- • Java Agent入門實戰(三)-JVM Attach原理與使用
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. vs2019運行opencv圖片顯示代碼時,窗口亂碼
- 2. app自動化 - 元素定位不到?別慌,看完你就能解決
- 3. 在Win8下用cisco ××× Client連接時報Reason 422錯誤的解決方法
- 4. eclipse快速補全代碼
- 5. Eclipse中Java/Html/Css/Jsp/JavaScript等代碼的格式化
- 6. idea+spring boot +mabitys(wanglezapin)+mysql (1)
- 7. 勒索病毒發生變種 新文件名將帶有「.UIWIX」後綴
- 8. 【原創】Python 源文件編碼解讀
- 9. iOS9企業部署分發問題深入瞭解與解決
- 10. 安裝pytorch報錯CondaHTTPError:******
- 1. M14-MongoDB索引原理及使用
- 2. 索引原理
- 3. Mongodb地理空間索引
- 4. Mongodb 地理位置索引
- 5. mongoDB 學習筆記(四)索引 索引管理 空間索引
- 6. MongoDB 索引
- 7. [MongoDB]索引
- 8. MongoDB的索引
- 9. mongoDB 索引
- 10. Mongodb索引