Attention Is All You Need
Attention Is All You Need
還在用 RNN 作 NLP ?NLP迎來新紀元了!快來學習下如今最火的BERT用的Transformer模型吧。
谷歌團隊在18年提出的用於生成詞向量的BERT算法在NLP的11項任務中取得了效果的大幅提高,堪稱2018年深度學習領域最振奮人心的消息。而BERT算法的最重要的部分谷歌團隊在17年發表的論文《Attention Is All You Need》中提出的Transformer的概念。
首先咱們來複習下基於RNN的Seq2Seq模型中的attention機制,來經過下面的動畫來大概瞭解下attention機制是用來幹嗎的。
在機器翻譯中經常使用的 Seq2Seq 模型中,加入 attention 機制是將每個 encoder 的 RNN 的隱層都傳遞給decoder ,decoder 再作以下的 attention 分析,
前端

下圖是 attention 分析的細節:
Attention 機制就是將decoder 的 hidden state 和與每個encoder的hidden state 的作一個匹配程度的分析,而後給出一個評分,這裏評分的機制有不少,能夠用一個小的網絡也能夠用線性計算,而後將這些score 用Softemax歸一化,再和相對應的hi相乘,再把全部的hi累加起來造成新的hidden state。也就是說,評分高的hidden state所佔的比重多,評分低的就佔比少。
先初始化一個hidden state 和一個 end 標記的向量做爲輸入,獲得一個hidden state: h4, 再把h4 和以前在encoder裏面獲得的全部隱藏狀態h1,h2,h3作attention分析,獲得最後的C4,而後將C4和h4 拼起來一塊兒輸入到一個前饋網絡獲得第一個詞的輸出。接下來就是將第一層的輸出和獲得的h4,做爲下一層的輸入,作一樣的操做,一直這樣繼續下去直到輸出 end 標記。
<br />在對 attention 有一個大概的概念以後,咱們來正式講下這篇論文,論文做者提出了一個Transformer 的模型,這個模型的特色主要在它是徹底基於 attention 機制來作 NLP,直接放棄了RNN和CNN,也就是爲何這篇論文叫Attention Is All You Need的緣由。放棄了RNN以後有一個很大的好處就是整個模型在訓練的時候有更好的並行性,訓練時間能夠大大減小,由於用RNN模型的時候在encoder裏面單詞都要一個一個順序輸入,而在若是用Transformer能夠直接輸入一句句子。模型結構以下圖所示:<br /> 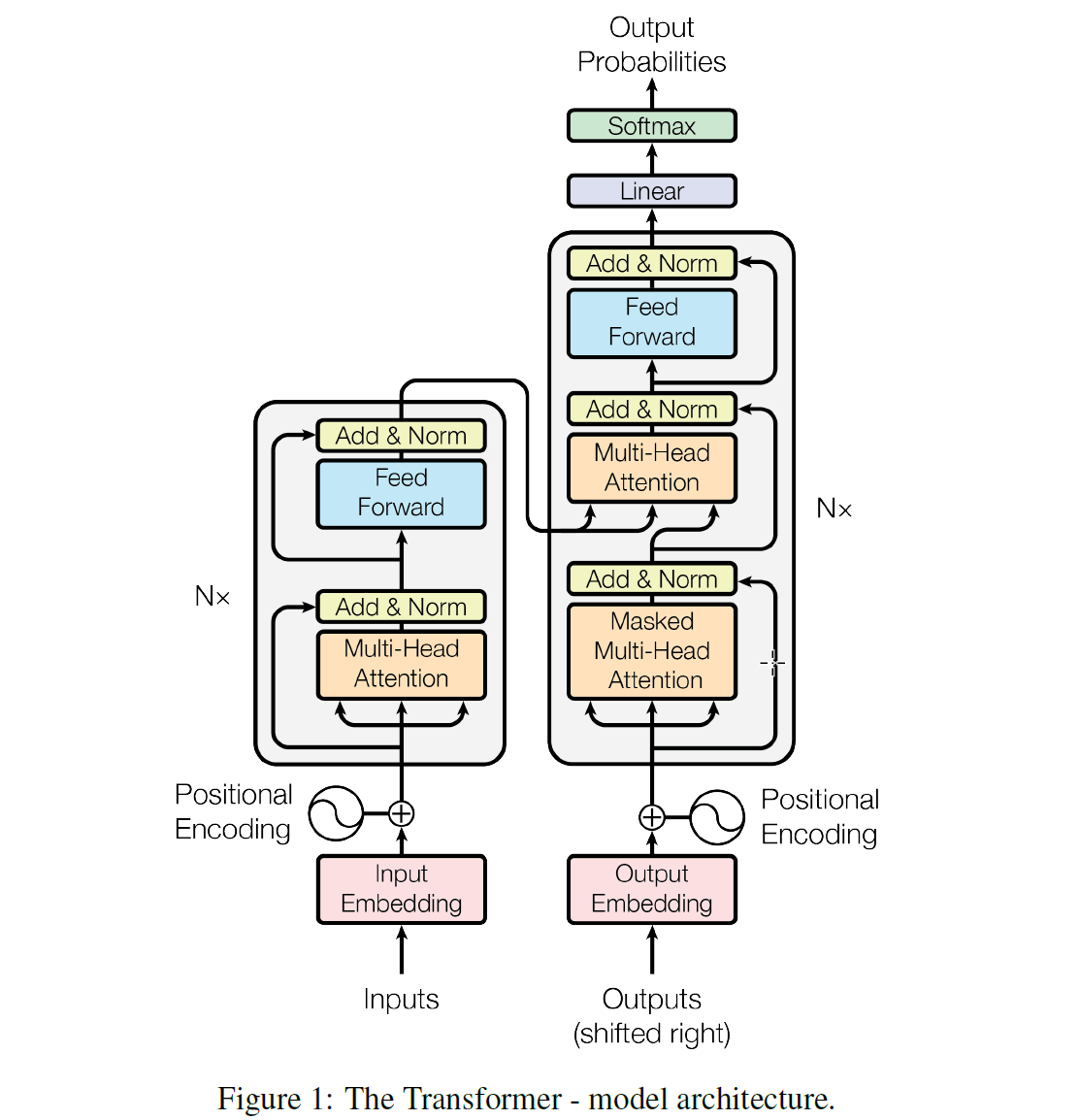<br />這個模型看上去很複雜,其實相對於RNN,要更簡單一點,下面咱們一點一點講。<br />在Transformer中一樣的有 encoders 和 decoders,encoder 對輸入進行編碼,decoder 對編碼獲得的結果進行解碼,下圖以黑盒的形式表現了模型的主要結構,輸入被傳輸進 encoder,encoder 會傳出一部份內容到 decoder,也會傳一部份內容到下一層的 encoder,encoder 和 decoder 都有一個 Self-Attention 模塊和 一個前饋網絡模塊,decoder 比 encoder 多一個 Encoder-Decoder Attention 模塊,<br /> 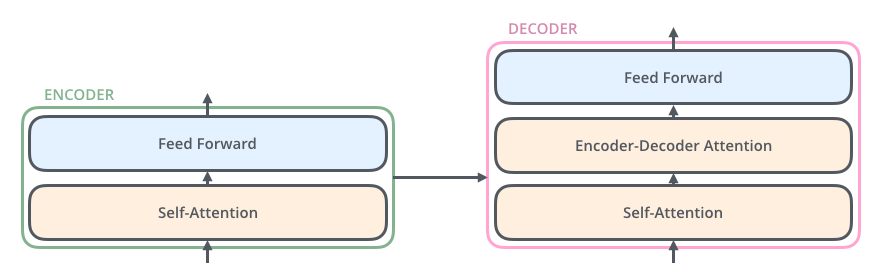<br />這裏的 Self-Attention 模塊是整個結構的核心,咱們先用一個例子來幫助你們理解下什麼是Self-Attention:<br />這裏有句句子:The animal didn't cross the street because it was too tired <br />要讓計算機理解這句句子,須要讓計算機搞清楚裏面的
複製代碼
it 是指代那個單詞,是street仍是animal?也就是給輸入的句子中每一個單詞之間一個相關性程度的斷定。前文RNN的例子中的attention是輸入與輸出之間的attention,而self-attention是句子內部之間的attention。經過attention機制咱們能夠獲得以下圖的詞彙之間的關聯程度,It與The animal關聯程度最高。
算法
在大概理解了什麼是 Self-Attention 以後咱們來看論文中做者是如何設計模型來作這種機制的。做者將設計的模型稱爲Scaled Dot-Product Attention,以下圖所示做者從輸入中提取出了三個矩陣:Q,K,V。經過以下公式來作 Self-Attention 分析。
咱們以機器翻譯的例子來看這三個矩陣是如何提取的:
在這個例子中,首先利用word embedding 技術將句子的詞彙轉換成向量,獲得這裏x1,x2向量做爲模型的輸入,論文裏面的標準模型的詞向量是512維,而後利用每一個xi向量構建出三種向量:q (Query) , k (Key) ,v(Value),構建方法是用xi對這裏的 Wq , Wk 和 Wv三個矩陣作內積,這裏矩陣裏面的數值也是做爲參數學出來的。獲得的三種向量他們的維度是能夠和輸入的xi不同的,論文裏面用的是64。而後下圖是評分的機制:
將每一個q向量分別與其餘全部k向量作內積,獲得全部有向量在這個qi位置上所佔的比重。也就是咱們要的Score,獲得的score就表明了每一個向量在當前位置所佔的權值,而後爲了讓學習過程當中的gradient更加穩定,做者將這些score作了一個縮放(除以根號dk),接下來就是把這些獲得的新的 scores 去乘對應單詞的value向量,最後再總的加起來獲得這裏的 z1也就是咱們要處理的Attention事後的結果。小編認爲做者在這裏給向量取的名字的意思是:q(Query)是每一個單詞像其餘全部單詞作一個詢問,而k(Key)是蘊含了詞彙之間關係的信息,給每一個單詞的Query提供關係數值。而 v(Value) 蘊含的是詞彙信息。但這也只是小編的猜想,論文中做者並無明確說明。數學模型上就只是簡單的向量之間的內積。通過這樣的例子相信上面的公式應該很好理解了:
在實際的模型中,做者對剛剛的模型作了進一步的改進,做者稱這個模型爲Multi-head attention,整個模型主要就是將多個Scale Dot-Product Attention 模型堆疊起來,組成成新的模型(每一個小模型對應一個head,因此叫Multi-Head)以下圖所示:
咱們仍是用上面那句話的例子來講明這樣作的好處,以下圖所示:
這張圖是兩個 head 獲得的attention效果,能夠看到 it在一個head中主要把attention集中在animal,而另外一個集中在了 tired 上,很明顯這樣的對語義的理解是有幫助的。下面咱們來看下具體結構:
和前面的模型同樣,咱們將輸入作線性運算生成Q,K,V矩陣,不一樣的是咱們這裏定義8組不一樣的Wq,Wk,Wv,生成八組不一樣的Q,K,V矩陣,也就是論文裏說的 8 個head,而後將8組不一樣的QKV 用 這個公式生成 8組 attention z0到z7,而後將z0-z7拼接起來和這裏的W0作內積,獲得最終的編碼結果 Z ,用來輸入到後面的前向網絡。
聰明的你看到這裏確定會發現這個模型直接放棄RNN會有一個缺點就是丟失了必定的詞彙的順序信息,就是哪一個單詞在前哪一個單詞在後都是對句子的意思是有影響的。因此做者提出了用Postional encoding 的方法來彌補這個不足。以下圖所示:
當輸入的詞彙通過 embedding 以後獲得的向量並非直接輸入模型,而是要加上一個位置信息的向量,位置向量的計算公式如上圖所示,做者在論文中並無具體講爲何用這樣的公式,只說了由於這裏用的三角函數可讓不一樣位置的PE值相互線性表示。做者也嘗試了經過學習的方法來作這個位置信息,並取得了一樣好的效果,可是用這裏的公式計算速度更快。
模型的核心 Self-Attention 到此就講完了,咱們下面來看看 encoders 和 decoders 是如何一塊兒工做的:
Input 通過剛剛講的一系列的encode過程後,咱們將每一層 encoder 生成的 K 和 V矩陣傳給decoder,而後decoder輸出和以前的RNN模型同樣也是一個詞一個詞的輸出。
decoder先對本身當前獲得的內容作一個self-attention,生成的編碼事後的 z 輸入到前饋網絡,網絡的輸出再輸入到下一層的Encoder-Decoder Attention 模塊(從圖片中能夠看出做者用在網絡的設計上用了殘差網絡的結構,把輸入加到輸出再傳給下一層),Encoder-Decoder Attention 模塊的機構是和Self-Attention 模塊是同樣的,只是在獲取Q , K , V矩陣的時候,模塊只對前一層的輸入生成Q矩陣,而K和V矩陣從對應層的 encoder 中獲取,也就是解碼encoder中的內容。
當獲得decoder的最後一層輸出後,咱們將輸出進行一個線性運算和softmax歸一化獲得每一個單詞的機率,取機率最大的單詞輸出。以下圖所示:
實驗:
做者用這個模型作了英德的翻譯,下圖是不一樣超參數的模型之間效果的對比:
能夠看出這裏最後一行最大的模型在BLEU評分上獲得了最好的效果。
同時做者也作了英法的翻譯與其餘模型進行了對比:
能夠看出最大的Transformer模型不光是在BLEU評分上比RNN\CNN高,並且計算量也更加少。
點此觀看論文相關直播課程
關於咱們
Mo(網址:momodel.cn)是一個支持 Python 的人工智能在線建模平臺,能幫助你快速開發、訓練並部署模型。c#
Mo 人工智能俱樂部 是由網站的研發與產品設計團隊發起、致力於下降人工智能開發與使用門檻的俱樂部。團隊具有大數據處理分析、可視化與數據建模經驗,已承擔多領域智能項目,具有從底層到前端的全線設計開發能力。主要研究方向爲大數據管理分析與人工智能技術,並以此來促進數據驅動的科學研究。網絡
目前俱樂部每兩週在杭州舉辦線下論文分享與學術交流。但願能匯聚來自各行各業對人工智能感興趣的朋友,不斷交流共同成長,推進人工智能民主化、應用普及化。
ide
- 1. Attention Is All You Need
- 2. Attention is all you need
- 3. 《Attention Is All You Need》
- 4. Attention Is All You Need簡析
- 5. 【筆記】Attention Is All You Need
- 6. 【算法】Attention is all you need
- 7. attention is all you need筆記
- 8. Transformer【Attention is all you need】
- 9. 譯文 Attention Is All You Need
- 10. Attention Is All You Need 筆記
- 更多相關文章...
- • XML Schema all 元素 - XML Schema 教程
- • XSL-FO 與 XSLT - XSL-FO 教程
- • 爲了進字節跳動,我精選了29道Java經典算法題,帶詳細講解
- • RxJava操作符(七)Conditional and Boolean
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. Attention Is All You Need
- 2. Attention is all you need
- 3. 《Attention Is All You Need》
- 4. Attention Is All You Need簡析
- 5. 【筆記】Attention Is All You Need
- 6. 【算法】Attention is all you need
- 7. attention is all you need筆記
- 8. Transformer【Attention is all you need】
- 9. 譯文 Attention Is All You Need
- 10. Attention Is All You Need 筆記